作者注: Claude Opus 4.7 基准测试深度解读: SWE-bench Verified 87.6%、SWE-bench Pro 64.3%、GPQA Diamond 94.2%,横扫 GPT-5.4 和 Gemini 3.1 Pro,附 API 调用实战。
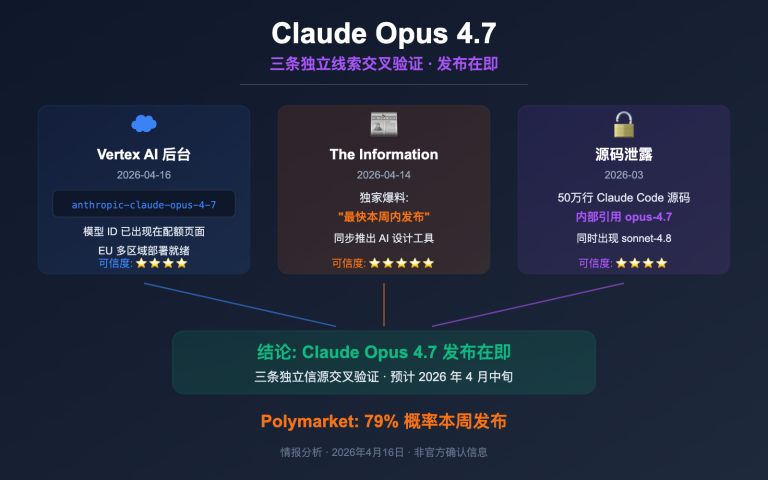
Anthropic 于 2026 年 4 月 16 日正式发布 Claude Opus 4.7,在 10 项核心基准中拿下 7 项领先。本文将从实际测评角度,深度解读 Claude Opus 4.7 benchmark 的核心数据和适用场景。
这不是官方宣传的复述,所有数据都来自第三方独立评测机构,包含优点也包含 Opus 4.7 在 web 搜索等场景的短板。
核心价值: 通过真实 benchmark 数据和使用体验,帮你判断 Claude Opus 4.7 是否值得切换、以及如何低成本上手。
💡 API 易已同步上线 Claude Opus 4.7 官方模型,充值 100 美金送 10% 起,综合相当于 8 折享用,支持 OpenAI 兼容接口一键替换。

Claude Opus 4.7 Benchmark 核心要点
| 基准项目 | Opus 4.7 成绩 | 对比 Opus 4.6 | 对比 GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅领先 |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅领先 |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ 多语言编程领先 |
| GPQA Diamond | 94.2% | – | ✅ 科学推理标杆 |
| Terminal-Bench 2.0 | 69.4% | – | ✅ 终端操作领先 |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅领先 |
| MCP-Atlas (工具调用) | 领先 GPT-5.4 +9.2 分 | – | ✅ Agent 场景最优 |
| Vision 多模态 | 98.5% | – | ✅ 视觉理解顶级 |
| BrowseComp (Web 搜索) | 79.3% | – | GPT-5.4: 89.3% ❌ 落后 |
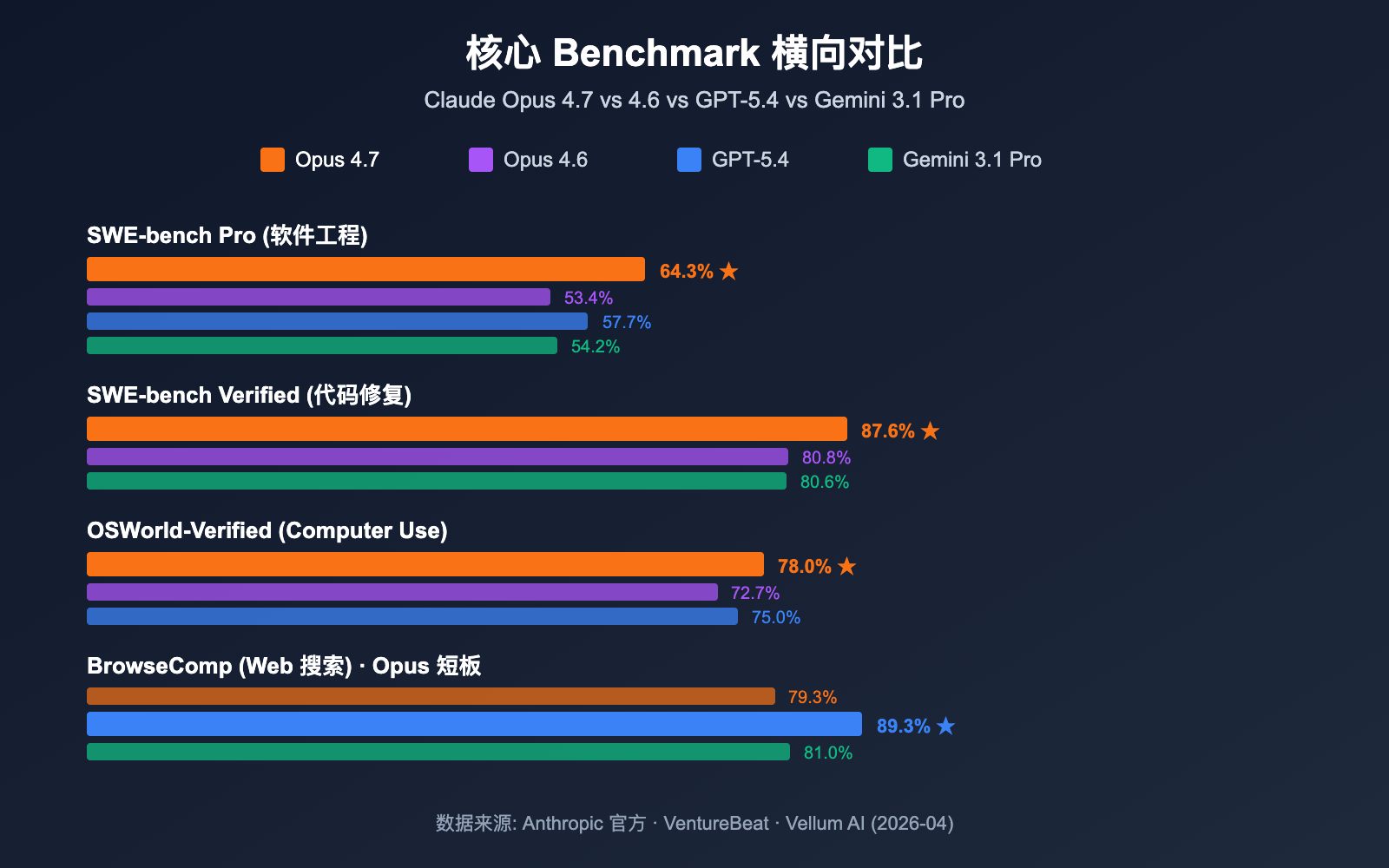
Claude Opus 4.7 基准测试核心亮点
Anthropic 2026 年 4 月 16 日发布 Claude Opus 4.7,定位为目前通用可用的最强大 LLM (VentureBeat 评价)。在与 GPT-5.4、Gemini 3.1 Pro 的 10 项直接对比中,Opus 4.7 拿下 7 项领先,其中 SWE-bench Pro 的领先幅度最大。
最值得关注的是 SWE-bench Pro 64.3% 这个数字——这是目前业界在真实软件工程任务上的最高成绩,比 GPT-5.4 的 57.7% 高出 6.6 个百分点,比 Opus 4.6 的 53.4% 跃升 10.9 个百分点。在 MCP-Atlas 工具调用基准上,Opus 4.7 领先 GPT-5.4 高达 9.2 分,这意味着它更适合 Agentic AI 场景,比如自动化工作流、代码生成 Agent、多步推理任务。

Claude Opus 4.7 与前代及竞品模型对比
| 维度 | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| 发布日期 | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| 上下文窗口 | 1M tokens (标准价) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agent/工具调用 | 最强 | 良好 | 强 | 良好 |
| Web 搜索 (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Vision 多模态 | 98.5% | 95% | 97% | 96.5% |
| 官方 API 价格 | $5 / $25 (输入/输出,每百万 token) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| API易 综合折扣 | 充值 100 美金送 10% 起 ≈ 8 折 | 同优惠 | 同优惠 | 同优惠 |
对比解读 (Claude Opus 4.7 vs 其他模型)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 在 BrowseComp 的 Web 搜索场景保持领先 (89.3% vs 79.3%)。但其在 SWE-bench Pro (57.7%) 和工具调用 (MCP-Atlas) 上明显落后于 Opus 4.7。相比之下,Claude Opus 4.7 在编程 Agent、代码生成、多步任务执行上更有优势,更适合开发者工作流。
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro 在长文本理解和多模态视频场景上仍保持领先。但在 SWE-bench Verified (80.6% vs 87.6%) 和 SWE-bench Pro (54.2% vs 64.3%) 上差距明显。相比之下,Claude Opus 4.7 在软件工程任务上几乎是断层领先,更适合生产级编程场景。
Claude Opus 4.7 vs Opus 4.6: Opus 4.6 在成本敏感场景下仍是稳定选择。但 4.7 的编程能力、Agentic 推理、Computer Use 都有大幅跃升,且 API 价格保持不变。对于需要处理复杂长链路任务的团队,4.7 几乎是必升级选择。
对比说明: 上述数据来源于 Anthropic 官方发布、VentureBeat、Vellum AI、Decrypt 等第三方评测机构,可通过 API易 apiyi.com 平台进行实测验证。
Claude Opus 4.7 快速上手
极简示例
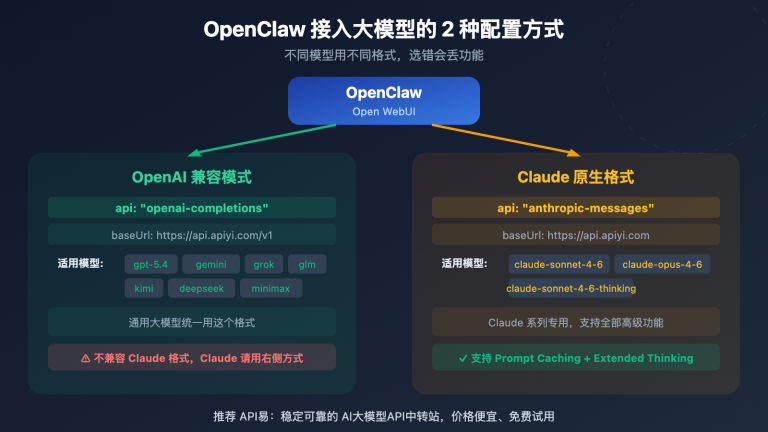
以下是通过 API 易调用 Claude Opus 4.7 的最简方式,使用 OpenAI 兼容接口:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "用 Python 写一个二叉树中序遍历的函数"}]
)
print(response.choices[0].message.content)
查看完整实现代码 (含 xhigh Effort Mode 调用)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
调用 Claude Opus 4.7,支持 xhigh effort mode
Args:
prompt: 用户输入
effort_level: 推理努力等级,可选 "low" / "medium" / "high" / "xhigh"
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
Returns:
模型响应内容
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 复杂编程任务推荐使用 xhigh 模式
result = call_claude_opus_47(
prompt="设计并实现一个 LRU 缓存,支持 O(1) 的 get 和 put 操作",
effort_level="xhigh",
system_prompt="你是资深 Python 工程师,写出可读性和性能兼顾的代码"
)
print(result)
建议: 通过 API 易 apiyi.com 获取免费测试额度,快速验证 Claude Opus 4.7 在你场景下的效果。平台支持 Opus 4.7、GPT-5.4、Gemini 3.1 Pro 的统一 OpenAI 兼容接口,方便横向对比。充值活动 100 美金送 10% 起,综合相当于 8 折使用官方模型。
Claude Opus 4.7 实测表现与典型场景
适合 Claude Opus 4.7 的 4 类核心场景
- 🧑💻 大型代码重构: SWE-bench Verified 87.6% 证明其能理解跨文件上下文,适合 10 万行级代码库的架构调整、依赖升级、批量重构
- 🤖 Agent 自动化工作流: MCP-Atlas 工具调用领先 GPT-5.4 9.2 分,适合构建浏览器自动化、RPA、多步推理 Agent
- 🔬 科研辅助与推理: GPQA Diamond 94.2% 意味着研究生级别的学科推理能力,适合论文辅助、数据分析、假设验证
- 🖥️ Computer Use 桌面自动化: OSWorld-Verified 78.0% 领先行业,适合需要模拟鼠标键盘的自动化测试、UI 操作
不适合 Claude Opus 4.7 的场景
- 实时 Web 搜索: BrowseComp 79.3%,明显落后于 GPT-5.4 的 89.3%,此类场景建议切换 GPT-5.4
- 大规模低成本调用: 输出价格 $25/M tokens,日常对话类应用建议使用 Claude Haiku 或 GPT-5.4-mini
- 超短延迟要求: Opus 系列响应延迟高于 Sonnet/Haiku,实时交互场景慎选
Claude Opus 4.7 价格与成本估算
官方定价 vs API 易综合成本
| 项目 | 官方价格 (Anthropic) | API 易价格 (含充值赠送) |
|---|---|---|
| 输入 token | $5 / 百万 tokens | 同官方单价 |
| 输出 token | $25 / 百万 tokens | 同官方单价 |
| 充值赠送 | 无 | 100 美金送 10% 起 |
| 综合等效折扣 | 无 | 约 8 折 (充值梯度越高赠送越多) |
| 支付方式 | 仅限美元信用卡 | 支持人民币、美元、多种方式 |
| 账单货币 | USD | RMB / USD 可选 |
成本提示: Opus 4.7 的新 tokenizer 在处理文本时会比 4.6 多消耗约 1x-1.35x tokens (根据内容类型波动)。虽然官方单价未涨,但实际账单成本可能上升约 20-30%。通过 API 易 apiyi.com 的充值赠送优惠,可以抵消这部分隐性成本,实际使用成本持平甚至低于 4.6 时代。
常见问题 FAQ
Q1: 什么是 Claude Opus 4.7?
Claude Opus 4.7 是 Anthropic 于 2026 年 4 月 16 日发布的旗舰大模型,在编码 (SWE-bench Verified 87.6%)、Agent 工具调用、科学推理 (GPQA Diamond 94.2%) 等多项基准上领先 GPT-5.4 和 Gemini 3.1 Pro。相比 Opus 4.6,它新增了 "xhigh effort" 深度推理模式,且官方价格未涨。
Q2: Claude Opus 4.7 和 GPT-5.4 哪个更好?
取决于场景。在编程 (SWE-bench Pro 64.3% vs 57.7%)、工具调用 (MCP-Atlas +9.2 分)、Computer Use (78.0% vs 75.0%) 上,Opus 4.7 明显领先;但在 Web 搜索 (BrowseComp 79.3% vs 89.3%) 上 GPT-5.4 保持优势。开发类工作流优选 Opus 4.7,联网搜索类优选 GPT-5.4。
Q3: Claude Opus 4.7 什么时候发布?国内什么时候能用?
官方发布日期为 2026 年 4 月 16 日,已上线 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry。国内开发者可通过 API 易 apiyi.com 等聚合平台同步使用官方模型,无需申请海外账号。
Q4: Claude Opus 4.7 最适合哪些实际项目?
主要适合以下场景:
- 大型代码重构: 跨文件上下文理解、依赖迁移、架构调整
- Agent 自动化: MCP 工具链、浏览器自动化、RPA 流程
- 科研与数据分析: 研究生级别推理、假设验证、论文辅助
- Computer Use 桌面自动化: UI 自动化测试、GUI 操作脚本
Q5: 如何通过 API 快速调用 Claude Opus 4.7?
推荐通过支持 OpenAI 兼容协议的聚合平台调用,3 步即可上手:
- 访问 API 易 apiyi.com 注册账号,获取 API Key
- 充值 100 美金获 10% 起赠送 (综合约 8 折),或先用免费额度测试
- 将 OpenAI SDK 的
base_url改为https://vip.apiyi.com/v1,model 填写claude-opus-4-7
API 易支持 Claude Opus 4.7、GPT-5.4、Gemini 3.1 Pro 等主流模型统一接入,便于横向对比切换。
Q6: Claude Opus 4.7 有哪些已知限制?
主要限制包括:
- Token 消耗增加: 新 tokenizer 比 4.6 多用 1x-1.35x tokens,实际账单可能上升 20-30%
- Web 搜索短板: BrowseComp 79.3%,落后 GPT-5.4,实时联网场景慎选
- 响应延迟: Opus 系列延迟高于 Sonnet/Haiku,实时对话类应用建议搭配轻量模型
- 官方单价较高: $5/$25 每百万 token,大规模调用推荐通过 API 易享受充值赠送优惠对冲成本
Q7: Claude Opus 4.7 的上下文窗口是多少?
Claude Opus 4.7 支持 100 万 (1M) tokens 上下文窗口,且为标准定价,无长上下文加价。这意味着可以在一次请求中处理整个中型代码仓库、长篇技术文档或完整会议记录,相当于约 75 万汉字或 200 个 PDF 页面。
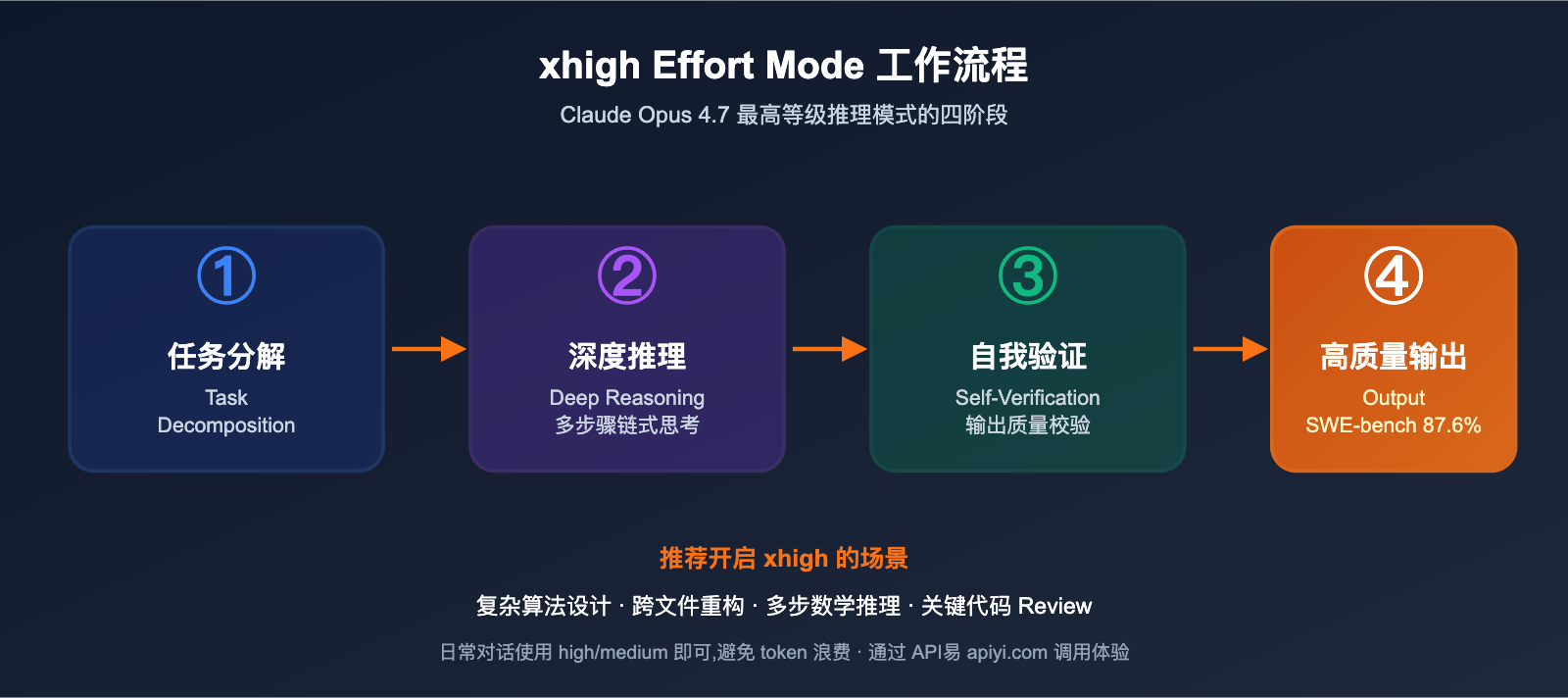
Q8: xhigh Effort Mode 是什么?什么时候用?
"xhigh effort" 是 Opus 4.7 新增的最高等级推理模式,模型会花费更多 token 和时间做多步思考与自我验证。推荐在以下场景开启:
- 复杂算法设计 (如 LRU 缓存、分布式一致性)
- 跨多文件的重构任务
- 需要多步逻辑链的数学推理
- 关键代码 Review 和漏洞审查
日常对话、简单 CRUD 编写等场景使用 high 或 medium 即可,避免不必要的 token 开销。
Claude Opus 4.7 核心要点 Key Takeaways
- 🏆 7 大榜单领先: SWE-bench Pro 64.3%、Verified 87.6%、GPQA 94.2%、MCP-Atlas 领先 GPT-5.4 9.2 分
- 💡 xhigh Effort Mode: 新增最高等级推理模式,适合复杂算法与跨文件重构
- 🚀 适合 Agent 场景: 工具调用和 Computer Use 全面领先,Agentic AI 首选模型
- ⚠️ Web 搜索短板: BrowseComp 落后 GPT-5.4 10 分,联网搜索场景建议对比选型
- 💰 API 易 8 折上手: 官方单价未涨,通过 apiyi.com 充值 100 美金送 10% 起,综合约 8 折
总结
Claude Opus 4.7 benchmark 数据清晰指向一个结论——它是当前编程和 Agent 场景下的最强通用模型。关键要点:
- 编程断层领先: SWE-bench Pro 64.3% 远超 GPT-5.4 和 Gemini 3.1 Pro,生产级代码任务首选
- Agent 工具调用王者: MCP-Atlas 领先 9.2 分,Computer Use 领先 3 分,自动化场景优选
- 实际成本需关注: 新 tokenizer 带来 20-30% 的隐性成本上涨,需配合聚合平台充值优惠对冲
如果你的工作重心在 AI 编程、Agent 开发、复杂推理任务上,Claude Opus 4.7 值得立刻切换。推荐通过 API 易 apiyi.com 快速体验——官方模型同步上线、OpenAI 兼容接口一键替换、充值 100 美金送 10% 起相当于 8 折享用,免去海外账号和美元支付的麻烦。
延伸阅读 Related Articles
如果你对 Claude Opus 4.7 benchmark 感兴趣,推荐继续阅读:
- 📘 Claude Opus 4.7 API 调用完整指南 – 了解 xhigh Effort Mode、Prompt Caching、工具调用的完整用法
- 📊 GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro 深度对比 – 掌握三大旗舰模型在各细分场景的选型决策
- 🚀 MCP 协议与 Claude Opus 4.7 Agent 实战 – 探索如何用 Opus 4.7 构建生产级 Agent 工作流
📚 参考资料
-
Anthropic 官方发布公告: Claude Opus 4.7 产品介绍和 benchmark 数据
- 链接:
anthropic.com/news/claude-opus-4-7 - 说明: 一手数据来源,包含全部官方基准测试成绩
- 链接:
-
VentureBeat 独立评测: Opus 4.7 在通用 LLM 中重回第一的分析
- 链接:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - 说明: 第三方独立视角,对 Opus 4.7 vs 竞品的综合对比
- 链接:
-
Vellum AI Benchmarks 解读: 逐项拆解 benchmark 方法论与可信度
- 链接:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 说明: 适合想深入理解基准测试方法的技术读者
- 链接:
-
Claude 官方 API 文档: 上下文窗口、pricing、tokenizer 说明
- 链接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 说明: 集成与调用的权威参考,含迁移指南
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论 Claude Opus 4.7 的使用体验,更多 API 调用资料可访问 API 易 docs.apiyi.com 文档中心