Nota do autor: Análise profunda dos benchmarks do Claude Opus 4.7: 87,6% no SWE-bench Verified, 64,3% no SWE-bench Pro e 94,2% no GPQA Diamond, superando o GPT-5.4 e o Gemini 3.1 Pro, com exemplos práticos de invocação do modelo.
A Anthropic lançou oficialmente o Claude Opus 4.7 em 16 de abril de 2026, conquistando a liderança em 7 de 10 benchmarks principais. Este artigo apresenta uma análise detalhada dos dados e cenários de aplicação do Claude Opus 4.7 a partir de avaliações reais.
Esta não é uma repetição do material promocional oficial. Todos os dados provêm de agências de avaliação independentes de terceiros, incluindo tanto os pontos fortes quanto as limitações do Opus 4.7 em cenários como busca na web.
Valor fundamental: Através de dados reais de benchmark e experiência de uso, ajudaremos você a decidir se vale a pena migrar para o Claude Opus 4.7 e como começar a utilizá-lo com baixo custo.
💡 O APIYI já disponibilizou o modelo oficial Claude Opus 4.7. Com recargas a partir de 100 dólares, você recebe 10% de bônus, resultando em uma economia equivalente a 20%, com suporte a substituição por interface compatível com OpenAI.

Pontos principais do benchmark do Claude Opus 4.7
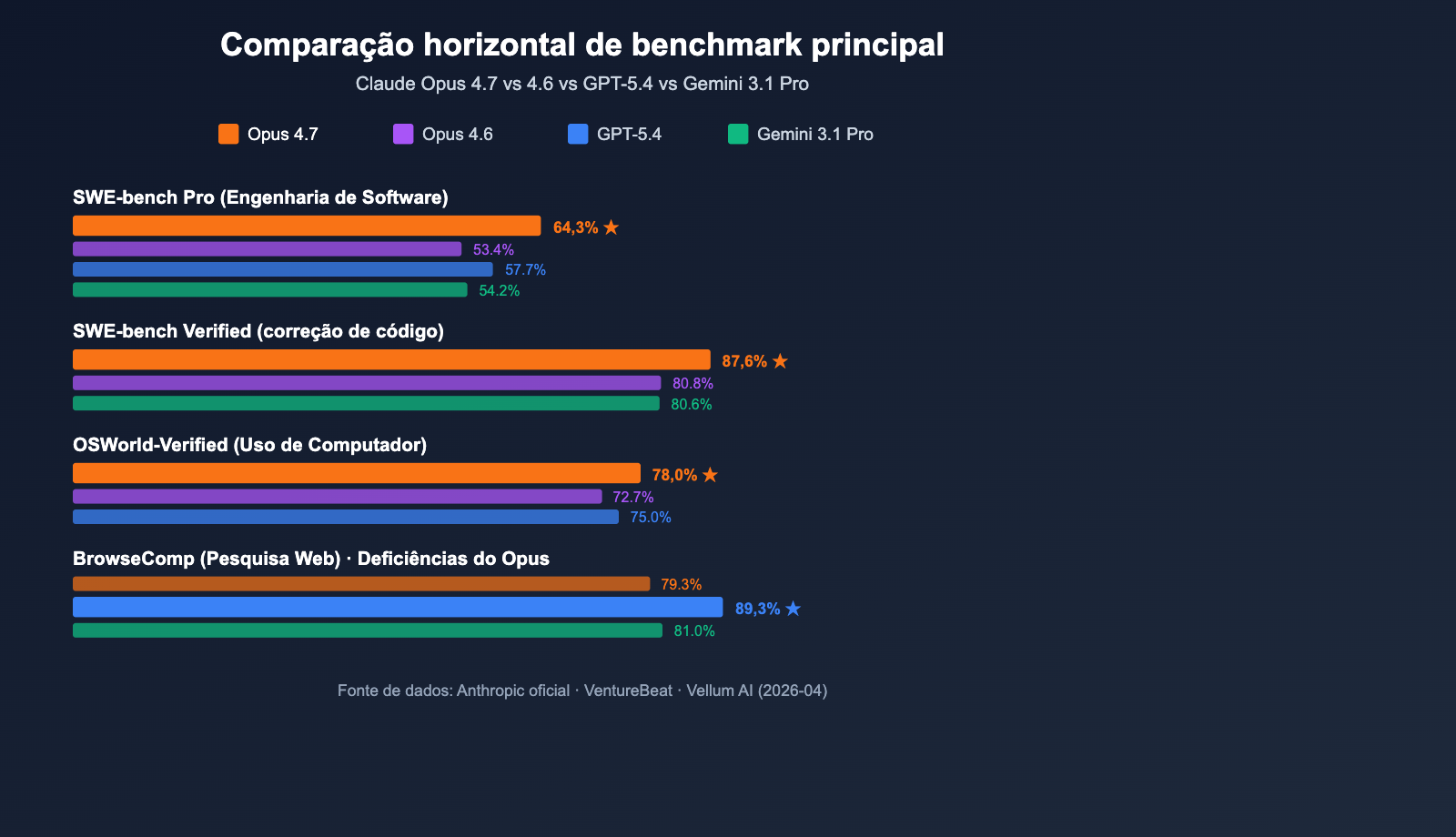
| Item de benchmark | Resultado do Opus 4.7 | Comparado ao Opus 4.6 | Comparado ao GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87,6% | 80,8% (+6,8) | Gemini 3.1 Pro: 80,6% ✅Líder |
| SWE-bench Pro | 64,3% | 53,4% (+10,9) | GPT-5.4: 57,7% / Gemini: 54,2% ✅Líder |
| SWE-bench Multilingual | 80,5% | 77,8% (+2,7) | ✅ Líder em programação multilíngue |
| GPQA Diamond | 94,2% | – | ✅ Referência em raciocínio científico |
| Terminal-Bench 2.0 | 69,4% | – | ✅ Líder em operações de terminal |
| OSWorld-Verified (Uso de computador) | 78,0% | 72,7% (+5,3) | GPT-5.4: 75,0% ✅Líder |
| MCP-Atlas (Invocação de ferramentas) | Líder GPT-5.4 +9,2 pontos | – | ✅ Melhor em cenários de agentes |
| Multimodal Visão | 98,5% | – | ✅ Topo em compreensão visual |
| BrowseComp (Busca Web) | 79,3% | – | GPT-5.4: 89,3% ❌ Atrás |
Destaques do benchmark do Claude Opus 4.7
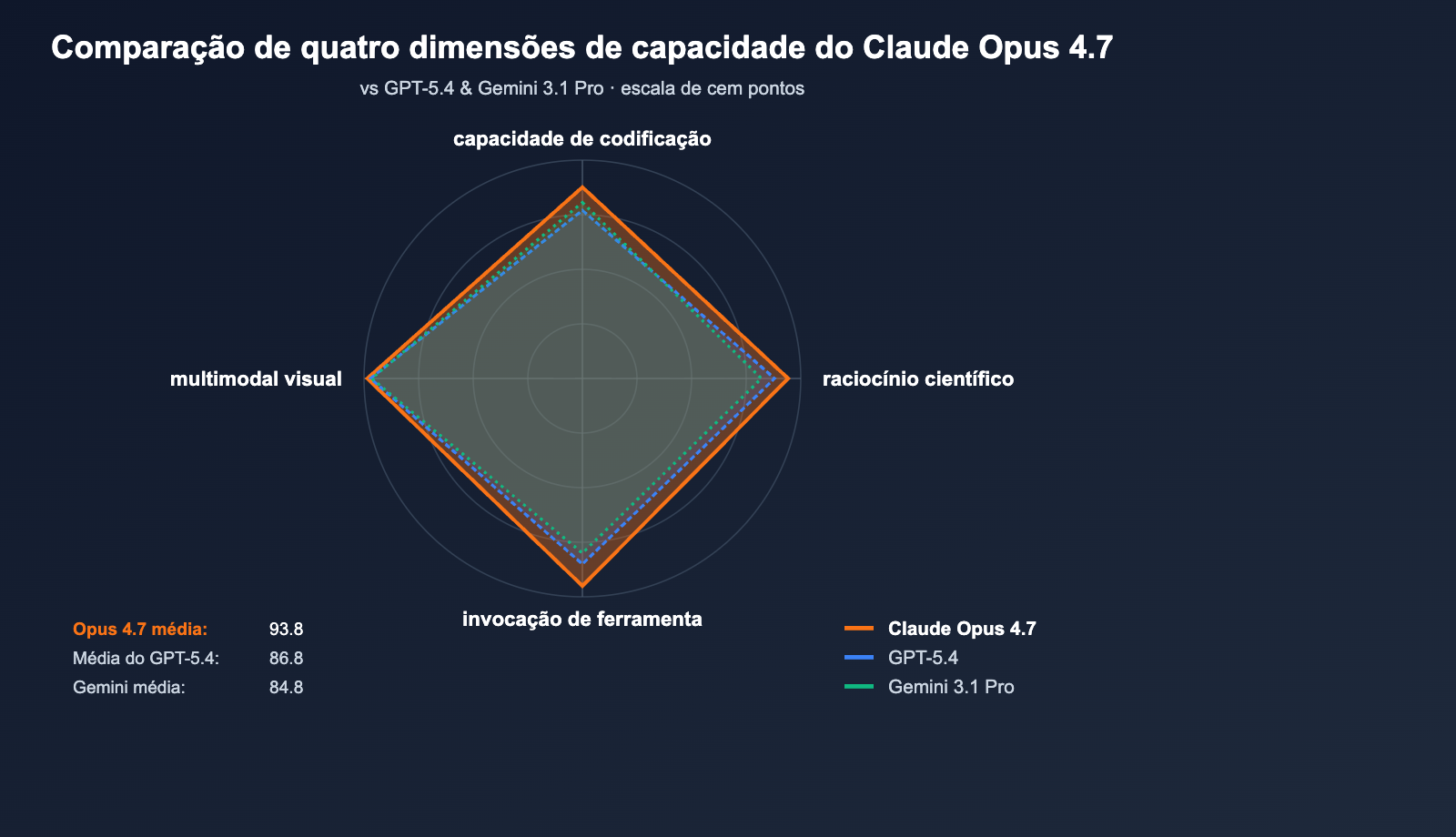
A Anthropic lançou o Claude Opus 4.7 em 16 de abril de 2026, posicionando-o como o LLM mais poderoso disponível para uso geral (segundo avaliação da VentureBeat). Em 10 comparações diretas com o GPT-5.4 e o Gemini 3.1 Pro, o Opus 4.7 conquistou a liderança em 7, com a maior margem observada no SWE-bench Pro.
O mais notável é o número 64,3% no SWE-bench Pro — o desempenho mais alto da indústria em tarefas reais de engenharia de software, superando os 57,7% do GPT-5.4 em 6,6 pontos percentuais e saltando 10,9 pontos sobre os 53,4% do Opus 4.6. No benchmark de invocação de ferramentas MCP-Atlas, o Opus 4.7 supera o GPT-5.4 em 9,2 pontos, o que significa que é mais adequado para cenários de IA Agêntica, como fluxos de trabalho automatizados, agentes de geração de código e tarefas de raciocínio de múltiplos passos.
title: "Claude Opus 4.7: Comparativo com gerações anteriores e concorrentes"
description: "Análise detalhada do Claude Opus 4.7, comparando performance, capacidades de codificação e custo com GPT-5.4 e Gemini 3.1 Pro."
Claude Opus 4.7: Comparativo com gerações anteriores e concorrentes
| Dimensão | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Data de Lançamento | 16/04/2026 | Jan/2026 | Mar/2026 | Fev/2026 |
| Janela de contexto | 1M tokens (preço padrão) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agente/invocação do modelo | Mais forte | Bom | Forte | Bom |
| Busca Web (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Vision multimodal | 98.5% | 95% | 97% | 96.5% |
| Preço oficial da API | $5 / $25 (entrada/saída, por milhão de tokens) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| Desconto total APIYI | Recarga de $100 ganha 10% ou mais ≈ 20% off | Mesma oferta | Mesma oferta | Mesma oferta |
Análise comparativa (Claude Opus 4.7 vs outros modelos)
Claude Opus 4.7 vs GPT-5.4: O GPT-5.4 mantém a liderança em cenários de busca na web via BrowseComp (89.3% vs 79.3%). No entanto, ele fica visivelmente atrás do Opus 4.7 no SWE-bench Pro (57.7%) e na invocação do modelo (MCP-Atlas). Em contrapartida, o Claude Opus 4.7 leva vantagem em agentes de programação, geração de código e execução de tarefas de várias etapas, sendo mais adequado para fluxos de trabalho de desenvolvedores.
Claude Opus 4.7 vs Gemini 3.1 Pro: O Gemini 3.1 Pro continua na frente na compreensão de textos longos e cenários de vídeo multimodal. Contudo, a diferença é clara no SWE-bench Verified (80.6% vs 87.6%) e no SWE-bench Pro (54.2% vs 64.3%). O Claude Opus 4.7 apresenta uma liderança expressiva em tarefas de engenharia de software, sendo a escolha ideal para ambientes de programação de nível de produção.
Claude Opus 4.7 vs Opus 4.6: O Opus 4.6 continua sendo uma opção estável para cenários sensíveis a custos. Mas o 4.7 traz um salto significativo em capacidade de programação, raciocínio agente e uso de computador (Computer Use), mantendo o preço da API inalterado. Para equipes que precisam lidar com tarefas complexas e de longa duração, o 4.7 é praticamente uma atualização obrigatória.
Nota sobre a comparação: Os dados acima foram extraídos de lançamentos oficiais da Anthropic, VentureBeat, Vellum AI, Decrypt e outras instituições de avaliação terceiras, podendo ser verificados através de testes práticos na plataforma APIYI (apiyi.com).
Guia Rápido do Claude Opus 4.7
Exemplo Minimalista
Aqui está a maneira mais simples de realizar uma invocação do Claude Opus 4.7 através da APIYI, utilizando uma interface compatível com OpenAI:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Escreva uma função em Python para realizar uma travessia em ordem (in-order) em uma árvore binária"}]
)
print(response.choices[0].message.content)
Ver código de implementação completo (incluindo invocação do modo xhigh Effort)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Realiza a invocação do Claude Opus 4.7, com suporte ao modo xhigh effort
Args:
prompt: entrada do usuário
effort_level: nível de esforço de raciocínio, opções: "low" / "medium" / "high" / "xhigh"
system_prompt: comando do sistema
max_tokens: número máximo de tokens de saída
Returns:
conteúdo da resposta do modelo
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Erro: {str(e)}"
# Recomendado usar o modo xhigh para tarefas complexas de programação
result = call_claude_opus_47(
prompt="Projete e implemente um cache LRU que suporte operações de get e put em O(1)",
effort_level="xhigh",
system_prompt="Você é um engenheiro Python sênior, escreva um código que equilibre legibilidade e desempenho"
)
print(result)
Sugestão: Obtenha créditos de teste gratuitos através da APIYI apiyi.com para verificar rapidamente o desempenho do Claude Opus 4.7 no seu cenário. A plataforma oferece uma interface unificada compatível com OpenAI para Opus 4.7, GPT-5.4 e Gemini 3.1 Pro, facilitando comparações diretas. Em recargas, receba 10% de bônus ou mais, o que equivale a um desconto de 20% no uso dos modelos oficiais.
Desempenho Real e Cenários Típicos do Claude Opus 4.7
4 Categorias Principais Ideais para o Claude Opus 4.7
- 🧑💻 Refatoração de código em grande escala: O SWE-bench Verified de 87,6% comprova sua capacidade de entender o contexto entre arquivos, sendo ideal para ajustes de arquitetura, atualizações de dependências e refatorações em lote em bases de código de 100 mil linhas.
- 🤖 Fluxos de trabalho de automação com Agentes: Com o MCP-Atlas superando o GPT-5.4 em 9,2 pontos em chamadas de ferramentas, é perfeito para criar automação de navegadores, RPA e agentes de raciocínio de múltiplas etapas.
- 🔬 Apoio à pesquisa e raciocínio: Com 94,2% no GPQA Diamond, possui capacidade de raciocínio em nível de pós-graduação, ideal para auxílio em artigos científicos, análise de dados e verificação de hipóteses.
- 🖥️ Automação de desktop Computer Use: Lidera a indústria com 78,0% no OSWorld-Verified, sendo indicado para testes automatizados e operações de UI que exigem simulação de mouse e teclado.
Cenários onde o Claude Opus 4.7 NÃO é recomendado
- Pesquisa web em tempo real: O BrowseComp de 79,3% fica significativamente atrás dos 89,3% do GPT-5.4; para esses cenários, recomendamos mudar para o GPT-5.4.
- Chamadas em larga escala de baixo custo: O preço de saída é de US$ 25/M de tokens. Para aplicativos de conversa do dia a dia, recomendamos o Claude Haiku ou o GPT-5.4-mini.
- Requisitos de latência ultrabaixa: A latência de resposta da série Opus é superior à dos modelos Sonnet/Haiku, portanto, escolha com cautela para cenários de interação em tempo real.
Estimativa de Preços e Custos do Claude Opus 4.7
Preços Oficiais vs. Custo Total na APIYI
| Item | Preço Oficial (Anthropic) | Preço APIYI (inclui bônus de recarga) |
|---|---|---|
| Token de entrada | $5 / milhão de tokens | Mesmo preço oficial |
| Token de saída | $25 / milhão de tokens | Mesmo preço oficial |
| Bônus de recarga | Nenhum | 10% ou mais em recargas de $100 |
| Desconto efetivo | Nenhum | Aprox. 20% de desconto (varia conforme o nível de recarga) |
| Métodos de pagamento | Apenas cartão de crédito em USD | Suporta RMB, USD e diversos métodos |
| Moeda da fatura | USD | Opcional (RMB / USD) |
Dica de custo: O novo tokenizador do Opus 4.7 consome cerca de 1x a 1,35x mais tokens ao processar textos em comparação ao 4.6 (dependendo do tipo de conteúdo). Embora o preço unitário oficial não tenha aumentado, o custo real da fatura pode subir cerca de 20-30%. Com os bônus de recarga da APIYI (apiyi.com), você pode compensar esse custo oculto, mantendo o custo real de uso igual ou até menor do que na era do 4.6.
Perguntas Frequentes (FAQ)
Q1: O que é o Claude Opus 4.7?
O Claude Opus 4.7 é o Modelo de Linguagem Grande carro-chefe lançado pela Anthropic em 16 de abril de 2026. Ele supera o GPT-5.4 e o Gemini 3.1 Pro em vários benchmarks, como codificação (SWE-bench Verified 87.6%), invocação de ferramentas de agente e raciocínio científico (GPQA Diamond 94.2%). Comparado ao Opus 4.6, ele adiciona o modo de raciocínio profundo "xhigh effort", mantendo o preço oficial inalterado.
Q2: Qual é melhor: Claude Opus 4.7 ou GPT-5.4?
Depende do cenário. Na programação (SWE-bench Pro 64.3% vs 57.7%), invocação de ferramentas (MCP-Atlas +9.2 pontos) e Computer Use (78.0% vs 75.0%), o Opus 4.7 lidera claramente; no entanto, o GPT-5.4 mantém a vantagem em buscas na web (BrowseComp 79.3% vs 89.3%). Para fluxos de trabalho de desenvolvimento, prefira o Opus 4.7; para buscas conectadas à internet, prefira o GPT-5.4.
Q3: Quando o Claude Opus 4.7 foi lançado? Já está disponível no país?
A data oficial de lançamento foi 16 de abril de 2026, e ele já está disponível na API do Claude, Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry. Desenvolvedores locais podem usar o modelo oficial através de plataformas agregadoras como a APIYI (apiyi.com), sem a necessidade de solicitar uma conta no exterior.
Q4: Para quais projetos práticos o Claude Opus 4.7 é mais indicado?
Ele é ideal para os seguintes cenários:
- Refatoração de código em larga escala: Compreensão de contexto entre arquivos, migração de dependências e ajustes de arquitetura
- Automação de Agentes: Cadeias de ferramentas MCP, automação de navegadores e fluxos RPA
- Pesquisa científica e análise de dados: Raciocínio de nível de pós-graduação, validação de hipóteses e auxílio em artigos
- Automação de desktop (Computer Use): Testes de automação de UI e scripts de operação de GUI
Q5: Como invocar o Claude Opus 4.7 rapidamente via API?
Recomendamos usar uma plataforma agregadora que suporte o protocolo compatível com OpenAI. Você pode começar em 3 passos:
- Acesse a APIYI (apiyi.com), registre uma conta e obtenha sua chave API
- Recarregue $100 para ganhar pelo menos 10% de bônus (desconto efetivo de cerca de 20%) ou teste primeiro com o saldo gratuito
- Altere a
base_urldo SDK da OpenAI parahttps://vip.apiyi.com/v1e defina o modelo comoclaude-opus-4-7
A APIYI suporta a integração unificada de modelos como Claude Opus 4.7, GPT-5.4 e Gemini 3.1 Pro, facilitando a comparação e a troca entre eles.
Q6: Quais são as limitações conhecidas do Claude Opus 4.7?
As principais limitações incluem:
- Aumento no consumo de tokens: O novo tokenizador usa 1x-1.35x mais tokens que o 4.6, podendo elevar a fatura em 20-30%
- Desempenho em buscas na web: Com 79.3% no BrowseComp, ele fica atrás do GPT-5.4; evite-o em cenários de busca em tempo real
- Latência de resposta: A série Opus tem latência maior que o Sonnet/Haiku; para aplicações de chat em tempo real, considere usar modelos mais leves
- Preço unitário oficial elevado: $5/$25 por milhão de tokens; para chamadas em larga escala, recomendamos usar a APIYI para aproveitar os bônus de recarga e compensar os custos
Q7: Qual é a janela de contexto do Claude Opus 4.7?
O Claude Opus 4.7 suporta uma janela de contexto de 1 milhão (1M) de tokens, com precificação padrão e sem taxas adicionais para contextos longos. Isso significa que você pode processar um repositório de código médio, documentos técnicos longos ou registros de reuniões completos em uma única solicitação, o que equivale a cerca de 750 mil caracteres chineses ou 200 páginas de PDF.
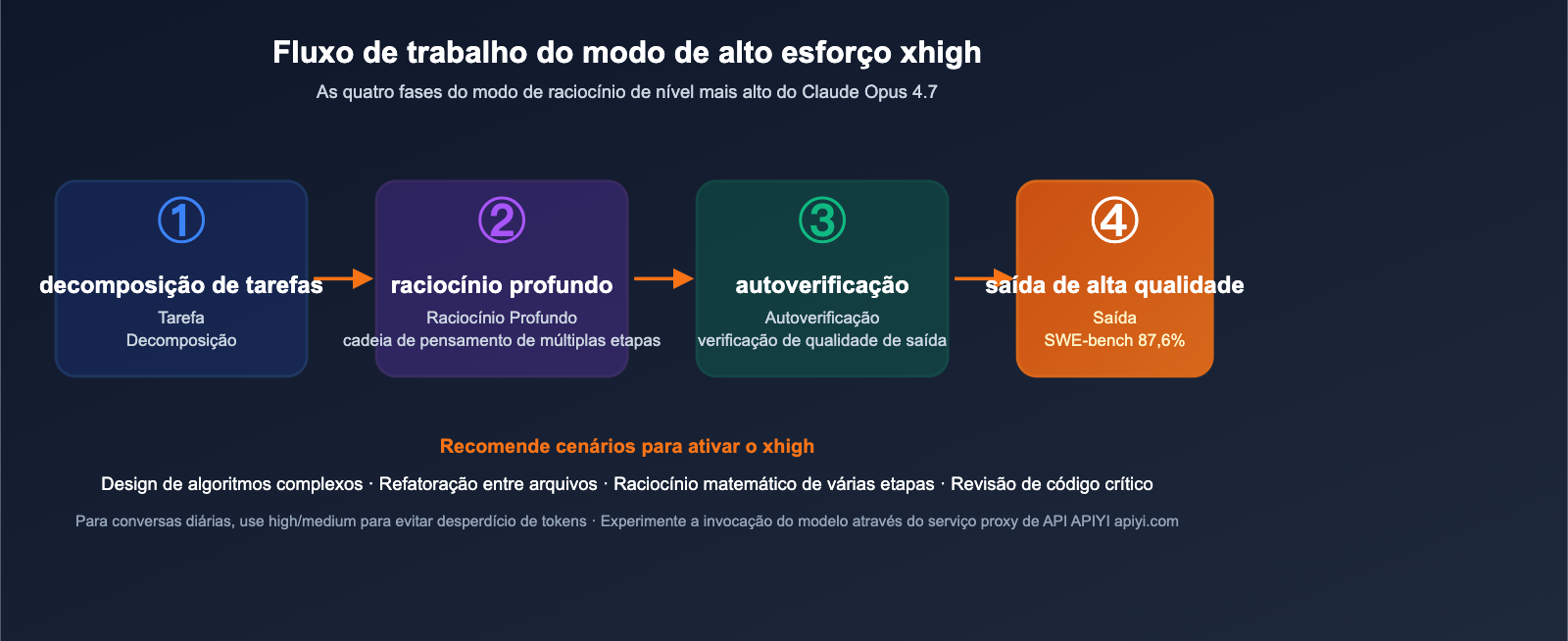
Q8: O que é o modo xhigh Effort? Quando usá-lo?
O "xhigh effort" é o nível mais alto de raciocínio adicionado ao Opus 4.7, onde o modelo gasta mais tokens e tempo realizando pensamentos de várias etapas e autoverificação. Recomendamos ativá-lo nos seguintes cenários:
- Design de algoritmos complexos (como cache LRU, consistência distribuída)
- Tarefas de refatoração que envolvem múltiplos arquivos
- Raciocínio matemático que exige cadeias lógicas complexas
- Revisão crítica de código e auditoria de vulnerabilidades
Para conversas diárias ou escrita de CRUD simples, usar high ou medium é suficiente, evitando gastos desnecessários de tokens.
Principais Pontos do Claude Opus 4.7
- 🏆 Liderança em 7 rankings: 64,3% no SWE-bench Pro, 87,6% no Verified, 94,2% no GPQA e 9,2 pontos à frente do GPT-5.4 no MCP-Atlas.
- 💡 Modo de Alto Esforço (xhigh Effort Mode): Novo nível máximo de raciocínio, ideal para algoritmos complexos e refatoração entre múltiplos arquivos.
- 🚀 Ideal para cenários de Agentes: Liderança absoluta em chamadas de ferramentas e uso de computador (Computer Use), sendo o modelo preferido para IA Agêntica.
- ⚠️ Limitação em busca na Web: 10 pontos atrás do GPT-5.4 no BrowseComp; recomenda-se comparar modelos para cenários que exigem busca online.
- 💰 Economize 20% com a APIYI: O preço oficial não aumentou, e ao recarregar 100 dólares via apiyi.com, você ganha a partir de 10% de bônus, resultando em um desconto efetivo de cerca de 20%.
Resumo
Os dados de benchmark do Claude Opus 4.7 apontam claramente para uma conclusão: ele é o modelo de uso geral mais poderoso atualmente para programação e cenários de agentes. Pontos-chave:
- Liderança destacada em programação: 64,3% no SWE-bench Pro, superando de longe o GPT-5.4 e o Gemini 3.1 Pro; a escolha ideal para tarefas de código em nível de produção.
- Rei das chamadas de ferramentas para Agentes: 9,2 pontos à frente no MCP-Atlas e 3 pontos à frente em Computer Use, sendo a melhor opção para automação.
- Atenção aos custos reais: O novo tokenizador traz um aumento de custo implícito de 20-30%, sendo necessário utilizar plataformas de agregação com bônus de recarga para compensar.
Se o seu foco de trabalho está em programação com IA, desenvolvimento de agentes e tarefas de raciocínio complexo, vale a pena migrar para o Claude Opus 4.7 imediatamente. Recomendamos experimentar rapidamente através da APIYI (apiyi.com) — modelos oficiais disponíveis instantaneamente, interface compatível com OpenAI para substituição com um clique e recargas a partir de 100 dólares com 10% de bônus, garantindo 20% de economia e evitando complicações com contas estrangeiras ou pagamentos em dólar.
延伸阅读 Related Articles
Se você se interessa pelo benchmark do Claude Opus 4.7, recomendo continuar a leitura:
- 📘 Guia Completo de Invocação de API do Claude Opus 4.7 – Aprenda o uso completo do modo de alto esforço (xhigh Effort Mode), cache de comando (Prompt Caching) e chamadas de ferramentas.
- 📊 Comparação Profunda: GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro – Domine a tomada de decisão na escolha dos três principais modelos para diferentes cenários.
- 🚀 Protocolo MCP e Prática de Agente com Claude Opus 4.7 – Explore como construir fluxos de trabalho de agentes em nível de produção usando o Opus 4.7.
📚 Referências
-
Comunicado Oficial da Anthropic: Introdução ao produto Claude Opus 4.7 e dados de benchmark.
- Link:
anthropic.com/news/claude-opus-4-7 - Nota: Fonte de dados primária, contendo todos os resultados oficiais dos testes de referência.
- Link:
-
Avaliação Independente da VentureBeat: Análise sobre o retorno do Opus 4.7 ao primeiro lugar entre os LLMs de uso geral.
- Link:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Nota: Perspectiva independente de terceiros com uma comparação abrangente entre o Opus 4.7 e seus concorrentes.
- Link:
-
Interpretação dos Benchmarks da Vellum AI: Decomposição item a item da metodologia e credibilidade dos benchmarks.
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Nota: Ideal para leitores técnicos que desejam entender profundamente os métodos de teste de referência.
- Link:
-
Documentação Oficial da API Claude: Explicações sobre janela de contexto, precificação e tokenizador.
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Nota: Referência autorizada para integração e invocação, incluindo guia de migração.
- Link:
Autor: Equipe Técnica APIYI
Troca Técnica: Sinta-se à vontade para discutir sua experiência com o Claude Opus 4.7 nos comentários. Para mais materiais sobre invocação de API, visite a central de documentação da APIYI em docs.apiyi.com.