Примечание автора: Глубокий разбор бенчмарков Claude Opus 4.7: SWE-bench Verified 87,6%, SWE-bench Pro 64,3%, GPQA Diamond 94,2%. Модель обходит GPT-5.4 и Gemini 3.1 Pro. Внутри — практические советы по API-вызовам.
16 апреля 2026 года Anthropic официально представила Claude Opus 4.7, которая заняла лидирующие позиции в 7 из 10 ключевых бенчмарков. В этой статье мы детально разберем основные показатели Claude Opus 4.7 и сценарии её применения с точки зрения реального тестирования.
Это не пересказ официального пресс-релиза. Все данные получены от независимых аналитических агентств и включают как сильные стороны, так и слабые места Opus 4.7 (например, в задачах веб-поиска).
Главная ценность: На основе реальных бенчмарков и опыта использования мы поможем вам понять, стоит ли переходить на Claude Opus 4.7 и как начать работу с ней с минимальными затратами.
💡 APIYI уже добавил поддержку официальной модели Claude Opus 4.7. При пополнении от 100 долларов вы получаете бонус от 10%, что в сумме дает скидку 20%. Поддерживается полная совместимость с API OpenAI для быстрой замены.

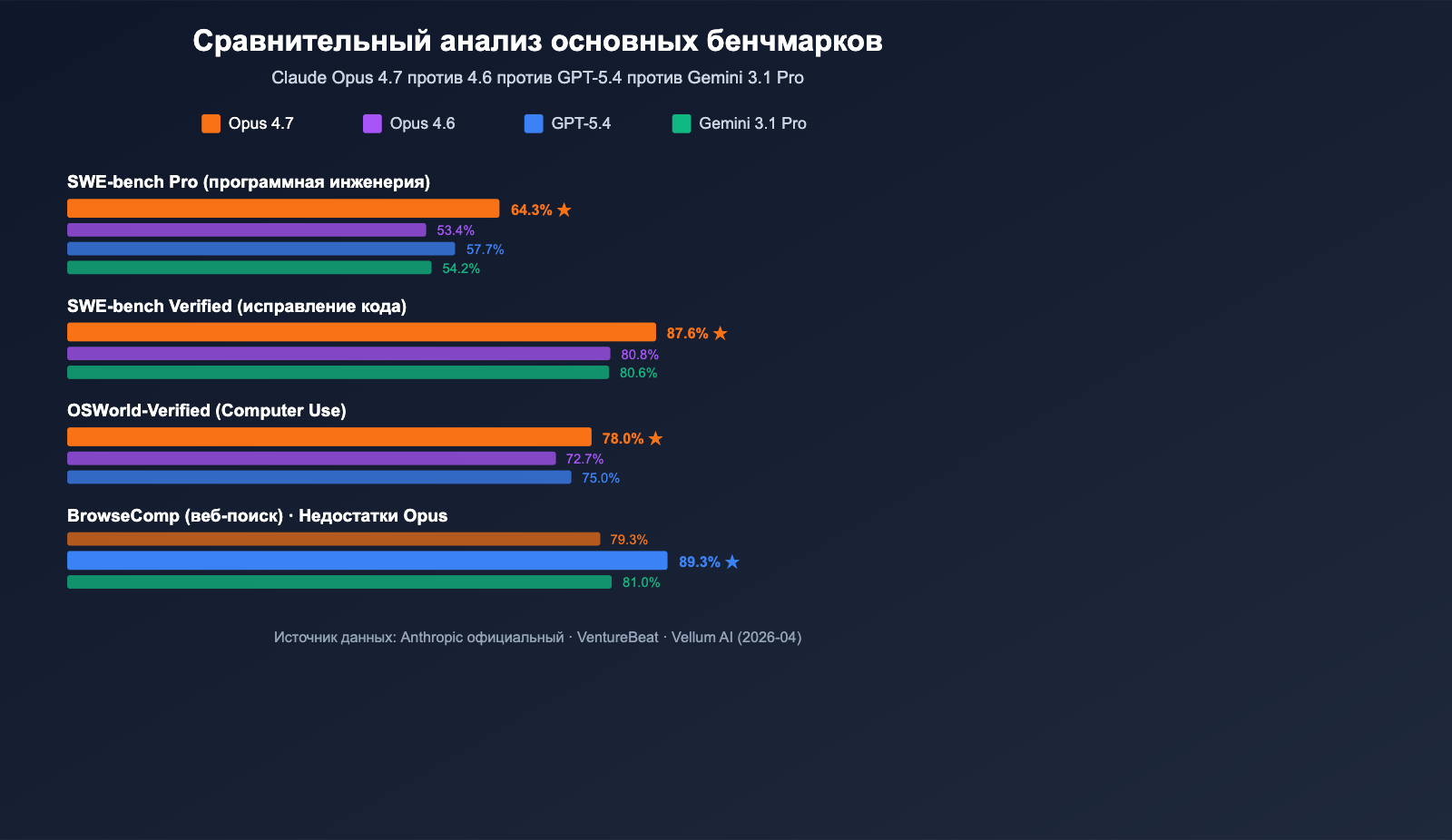
Основные показатели бенчмарков Claude Opus 4.7
| Бенчмарк | Результат Opus 4.7 | vs Opus 4.6 | vs GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87,6% | 80,8% (+6,8) | Gemini 3.1 Pro: 80,6% ✅ Лидер |
| SWE-bench Pro | 64,3% | 53,4% (+10,9) | GPT-5.4: 57,7% / Gemini: 54,2% ✅ Лидер |
| SWE-bench Multilingual | 80,5% | 77,8% (+2,7) | ✅ Лидер в многоязычном программировании |
| GPQA Diamond | 94,2% | — | ✅ Эталон научных рассуждений |
| Terminal-Bench 2.0 | 69,4% | — | ✅ Лидер в работе с терминалом |
| OSWorld-Verified (Computer Use) | 78,0% | 72,7% (+5,3) | GPT-5.4: 75,0% ✅ Лидер |
| MCP-Atlas (вызов инструментов) | Лидерство над GPT-5.4 +9,2 п. | — | ✅ Лучший выбор для агентов |
| Vision (мультимодальность) | 98,5% | — | ✅ Топовое визуальное понимание |
| BrowseComp (веб-поиск) | 79,3% | — | GPT-5.4: 89,3% ❌ Отставание |
Ключевые моменты тестирования Claude Opus 4.7
Выпущенная 16 апреля 2026 года, Claude Opus 4.7 позиционируется как самая мощная LLM общего назначения на текущий момент (по оценке VentureBeat). В прямом сравнении с GPT-5.4 и Gemini 3.1 Pro по 10 параметрам модель Opus 4.7 одержала победу в 7 из них, показав наиболее значительный отрыв в SWE-bench Pro.
Особого внимания заслуживает показатель SWE-bench Pro 64,3% — это лучший результат в индустрии для реальных задач разработки ПО. Он на 6,6 процентных пункта выше, чем у GPT-5.4 (57,7%), и на 10,9 пункта выше, чем у предыдущей версии Opus 4.6. В бенчмарке MCP-Atlas (вызов инструментов) Opus 4.7 опережает GPT-5.4 на 9,2 балла, что делает её идеальным решением для агентных AI-сценариев: автоматизации рабочих процессов, написания кода агентами и задач с многошаговым рассуждением.

Сравнение Claude Opus 4.7 с предыдущими версиями и моделями конкурентов
| Характеристика | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Дата релиза | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| Контекстное окно | 1 млн токенов (стандарт) | 200 тыс. | 400 тыс. | 1 млн |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Агенты/вызов инструментов | Лучший | Хорошо | Сильно | Хорошо |
| Web-поиск (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Мультимодальность (Vision) | 98.5% | 95% | 97% | 96.5% |
| Официальная цена API | $5 / $25 (вход/выход) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| Скидки APIYI | Бонус 10% от $100 ≈ скидка 20% | Аналогично | Аналогично | Аналогично |
Разбор сравнения (Claude Opus 4.7 против других моделей)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 по-прежнему удерживает лидерство в задачах веб-поиска (BrowseComp: 89.3% против 79.3%). Однако в тестах SWE-bench Pro (57.7%) и при работе с инструментами (MCP-Atlas) она заметно отстает от Opus 4.7. В задачах разработки, генерации кода и выполнении многошаговых сценариев Opus 4.7 выглядит гораздо предпочтительнее для рабочих процессов программистов.
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro все еще сильна в понимании длинных текстов и видео, но разрыв в инженерных задачах стал критическим. В тестах SWE-bench Verified (80.6% против 87.6%) и SWE-bench Pro (54.2% против 64.3%) преимущество Claude Opus 4.7 очевидно, что делает её идеальным выбором для продакшн-разработки.
Claude Opus 4.7 vs Opus 4.6: Версия 4.6 остается надежным решением для простых задач, где важна экономия. Однако 4.7 предлагает мощный скачок в способностях к рассуждению (Agentic reasoning) и работе с Computer Use, при этом стоимость API осталась прежней. Для команд, работающих над сложными проектами, обновление до 4.7 — необходимость.
Примечание к данным: Данные основаны на официальных релизах Anthropic, отчетах VentureBeat, Vellum AI, Decrypt и могут быть проверены в реальных условиях через платформу APIYI (apiyi.com).
Быстрый старт с Claude Opus 4.7
Минималистичный пример
Вот самый простой способ вызвать Claude Opus 4.7 через сервис-прокси APIYI, используя интерфейс, совместимый с OpenAI:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Напиши на Python функцию для обхода бинарного дерева в симметричном порядке"}]
)
print(response.choices[0].message.content)
Посмотреть полный код реализации (включая вызов xhigh Effort Mode)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Вызов Claude Opus 4.7 с поддержкой режима xhigh effort.
Args:
prompt: Ввод пользователя
effort_level: Уровень глубины рассуждений, возможные значения: "low" / "medium" / "high" / "xhigh"
system_prompt: Системный промпт
max_tokens: Максимальное количество токенов на выходе
Returns:
Ответ модели
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Для сложных задач по программированию рекомендуем использовать режим xhigh
result = call_claude_opus_47(
prompt="Разработай и реализуй кэш LRU с поддержкой операций get и put за O(1)",
effort_level="xhigh",
system_prompt="Ты — опытный Python-разработчик. Пиши код, сочетающий читаемость и производительность."
)
print(result)
Совет: Получите бесплатные тестовые лимиты на apiyi.com, чтобы быстро проверить работу Claude Opus 4.7 в ваших сценариях. Платформа предоставляет единый API, совместимый с OpenAI, для моделей Opus 4.7, GPT-5.4 и Gemini 3.1 Pro, что удобно для их сравнения. При пополнении баланса от 100 долларов вы получаете бонус от 10%, что фактически дает скидку около 20% по сравнению с официальными ценами.
Реальные показатели Claude Opus 4.7 и типичные сценарии
4 ключевых сценария для Claude Opus 4.7
- 🧑💻 Крупный рефакторинг кода: показатель 87.6% в бенчмарке SWE-bench Verified доказывает, что модель отлично понимает контекст между файлами. Идеально для смены архитектуры, обновления зависимостей и массового рефакторинга в проектах на 100 000+ строк кода.
- 🤖 Автоматизация рабочих процессов (Agent): по возможностям вызова инструментов (MCP-Atlas) модель опережает GPT-5.4 на 9.2 балла. Отлично подходит для создания агентов браузерной автоматизации, RPA и многошаговых рассуждений.
- 🔬 Научная деятельность и логические выводы: результат 94.2% в GPQA Diamond указывает на способности к рассуждениям уровня аспиранта. Подойдет для помощи в написании статей, анализа данных и проверки гипотез.
- 🖥️ Автоматизация рабочего стола (Computer Use): лидер индустрии с результатом 78.0% в OSWorld-Verified. Подходит для автоматизированного тестирования и действий в интерфейсе, требующих эмуляции мыши и клавиатуры.
Сценарии, где Claude Opus 4.7 не является лучшим выбором
- Поиск в реальном времени (Web Search): результат BrowseComp 79.3% заметно отстает от 89.3% у GPT-5.4. В таких задачах лучше переключиться на GPT-5.4.
- Масштабируемые дешевые вызовы: цена на вывод составляет $25/млн токенов. Для повседневных диалоговых приложений рекомендуется использовать Claude Haiku или GPT-5.4-mini.
- Задачи с жесткими требованиями к задержке: задержка ответа у серии Opus выше, чем у Sonnet или Haiku, поэтому для интерактивных сценариев в реальном времени выбирайте модели с умом.
Анализ цен и оценка стоимости Claude Opus 4.7
Официальные тарифы vs совокупная стоимость в APIYI
| Проект | Официальная цена (Anthropic) | Цена APIYI (с учетом бонусов) |
|---|---|---|
| Входящие токены | $5 / млн токенов | Тот же тариф |
| Исходящие токены | $25 / млн токенов | Тот же тариф |
| Бонус при пополнении | Нет | От 10% при пополнении от $100 |
| Эффективная скидка | Нет | Около 20% (зависит от суммы пополнения) |
| Способы оплаты | Только долларовые карты | Поддержка CNY, USD и др. |
| Валюта счета | USD | На выбор: RMB / USD |
Совет по оптимизации затрат: Новый токенизатор Opus 4.7 расходует примерно в 1–1,35 раза больше токенов при обработке текста по сравнению с версией 4.6 (зависит от типа контента). Хотя официальный тариф не изменился, фактические расходы могут вырасти на 20–30%. Бонусы при пополнении на APIYI (apiyi.com) позволяют полностью компенсировать эти скрытые издержки, делая стоимость использования такой же или даже ниже, чем во времена 4.6.
Часто задаваемые вопросы (FAQ)
Q1: Что такое Claude Opus 4.7?
Claude Opus 4.7 — это флагманская Большая языковая модель от Anthropic, выпущенная 16 апреля 2026 года. Она лидирует по многим бенчмаркам, включая написание кода (SWE-bench Verified 87,6%), вызов инструментов агентами и научные рассуждения (GPQA Diamond 94,2%), обходя GPT-5.4 и Gemini 3.1 Pro. По сравнению с Opus 4.6, в ней появился режим глубокого мышления "xhigh effort", при этом официальная цена осталась прежней.
Q2: Что лучше: Claude Opus 4.7 или GPT-5.4?
Зависит от задачи. В программировании (SWE-bench Pro 64,3% против 57,7%), вызове инструментов (MCP-Atlas +9,2 балла) и Computer Use (78,0% против 75,0%) Opus 4.7 заметно впереди. Однако в веб-поиске (BrowseComp 79,3% против 89,3%) GPT-5.4 сохраняет преимущество. Для разработки лучше выбрать Opus 4.7, для поиска информации — GPT-5.4.
Q3: Когда вышел Claude Opus 4.7 и можно ли его использовать в РФ?
Официальная дата релиза — 16 апреля 2026 года. Модель доступна через Claude API, Amazon Bedrock, Google Cloud Vertex AI и Microsoft Foundry. Разработчики могут использовать официальную модель через агрегаторы, такие как APIYI (apiyi.com), без необходимости регистрации зарубежных аккаунтов.
Q4: Для каких задач лучше всего подходит Claude Opus 4.7?
Модель идеально справляется со следующими сценариями:
- Масштабный рефакторинг кода: понимание контекста между файлами, миграция зависимостей, изменение архитектуры.
- Автоматизация агентов: цепочки инструментов MCP, автоматизация браузера, RPA-процессы.
- Наука и анализ данных: рассуждения уровня аспирантуры, проверка гипотез, помощь в написании статей.
- Автоматизация рабочего стола (Computer Use): UI-тестирование, скрипты для работы с GUI.
Q5: Как быстро подключить Claude Opus 4.7 через API?
Рекомендуем использовать агрегаторы с поддержкой протокола OpenAI. Всего 3 шага:
- Зарегистрируйтесь на APIYI (apiyi.com) и получите API-ключ.
- Пополните баланс от $100, чтобы получить бонус от 10% (общая скидка около 20%), или протестируйте модель на бесплатном лимите.
- В SDK OpenAI измените
base_urlнаhttps://vip.apiyi.com/v1, а в полеmodelукажитеclaude-opus-4-7.
APIYI поддерживает Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro и другие модели, что позволяет легко сравнивать их между собой.
Q6: Какие есть известные ограничения у Claude Opus 4.7?
Основные моменты:
- Рост расхода токенов: новый токенизатор потребляет на 20–30% больше токенов, чем 4.6.
- Слабость в веб-поиске: результат BrowseComp 79,3% уступает GPT-5.4, поэтому для задач с поиском в реальном времени лучше выбрать другую модель.
- Задержка ответа: серия Opus работает медленнее, чем Sonnet или Haiku, поэтому для чат-ботов в реальном времени лучше использовать более легкие модели.
- Высокая цена: при масштабных вызовах обязательно используйте бонусы APIYI для оптимизации затрат.
Q7: Какой размер контекстного окна у Claude Opus 4.7?
Claude Opus 4.7 поддерживает контекстное окно в 1 млн (1M) токенов без дополнительных наценок. Это позволяет обрабатывать за один запрос средний репозиторий кода, длинные технические документы или полные протоколы встреч (примерно 750 тыс. иероглифов или 200 страниц PDF).
Q8: Что такое режим xhigh Effort Mode и когда его использовать?
"xhigh effort" — это режим максимального уровня рассуждений в Opus 4.7. Модель тратит больше токенов и времени на многошаговое мышление и самопроверку. Рекомендуем включать его для:
- Проектирования сложных алгоритмов (например, LRU-кэши, распределенная согласованность).
- Рефакторинга кода, затрагивающего множество файлов.
- Математических задач, требующих длинных логических цепочек.
- Критического ревью кода и поиска уязвимостей.
Для повседневных диалогов или простого CRUD-кода достаточно режимов high или medium, чтобы не тратить токены впустую.
Основные выводы по Claude Opus 4.7
- 🏆 Лидерство в 7 рейтингах: 64,3% в SWE-bench Pro, 87,6% в Verified, 94,2% в GPQA, а в MCP-Atlas модель опережает GPT-5.4 на 9,2 балла.
- 💡 Режим xhigh Effort: добавлен новый уровень推理模式, идеально подходящий для сложных алгоритмов и рефакторинга кода между файлами.
- 🚀 Идеально для Agent-сценариев: полное доминирование в вызовах инструментов и Computer Use, лучший выбор для Agentic AI.
- ⚠️ Слабое место — веб-поиск: в BrowseComp модель отстает от GPT-5.4 на 10 баллов, для задач с активным поиском в сети стоит рассмотреть альтернативы.
- 💰 Доступ к APIYI со скидкой 20%: официальные цены не изменились, а при пополнении баланса на 100$ через apiyi.com вы получаете бонус от 10%, что в сумме дает скидку около 20%.
Резюме
Бенчмарки Claude Opus 4.7 однозначно указывают на одно: это самая мощная универсальная модель для программирования и агентских задач на сегодняшний день. Главное:
- Отрыв в программировании: 64,3% в SWE-bench Pro значительно превосходит показатели GPT-5.4 и Gemini 3.1 Pro — это лучший выбор для задач промышленного уровня.
- Король вызова инструментов для агентов: преимущество в 9,2 балла в MCP-Atlas и на 3 балла в Computer Use делают её фаворитом для автоматизации.
- Внимание на реальные затраты: новый токенизатор увеличивает скрытые расходы на 20–30%, поэтому стоит использовать бонусы при пополнении через агрегаторы.
Если ваш фокус — AI-программирование, разработка агентов или сложные логические задачи, на Claude Opus 4.7 стоит переходить прямо сейчас. Рекомендуем попробовать через APIYI (apiyi.com): модели синхронизируются с официальными, поддерживается совместимый с OpenAI интерфейс для быстрой замены, а бонус в 10% при пополнении от 100$ позволяет экономить до 20%, избавляя от проблем с зарубежными аккаунтами и оплатой в долларах.
延伸阅读 Related Articles
Если вас заинтересовал бенчмарк Claude Opus 4.7, рекомендуем изучить следующие материалы:
- 📘 Полное руководство по вызову API Claude Opus 4.7 — узнайте всё о режиме xhigh Effort Mode, кэшировании промптов (Prompt Caching) и использовании инструментов.
- 📊 Глубокое сравнение: GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro — разберитесь в выборе между тремя флагманскими моделями для различных сценариев.
- 🚀 Протокол MCP и агенты на базе Claude Opus 4.7 — узнайте, как создавать рабочие процессы для продакшн-агентов с помощью Opus 4.7.
📚 参考资料
-
Официальный анонс Anthropic: Презентация продукта Claude Opus 4.7 и данные бенчмарков.
- Ссылка:
anthropic.com/news/claude-opus-4-7 - Примечание: Первоисточник данных, содержащий все официальные результаты тестирования.
- Ссылка:
-
Независимый обзор VentureBeat: Анализ возвращения Opus 4.7 на первое место среди универсальных LLM.
- Ссылка:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Примечание: Сторонний взгляд на комплексное сравнение Opus 4.7 с конкурентами.
- Ссылка:
-
Разбор бенчмарков от Vellum AI: Детальный анализ методологии тестирования и достоверности данных.
- Ссылка:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Примечание: Подойдет тем, кто хочет глубоко разобраться в принципах проведения бенчмарков.
- Ссылка:
-
Официальная API-документация Claude: Информация о контекстном окне, ценообразовании и токенизаторе.
- Ссылка:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Примечание: Авторитетный источник для интеграции и вызова моделей, включая руководство по миграции.
- Ссылка:
Автор: Техническая команда APIYI
Техническое сообщество: Приглашаем обсудить опыт использования Claude Opus 4.7 в комментариях. Больше материалов по вызову API доступно в центре документации APIYI по адресу docs.apiyi.com