title: "Claude Opus 4.7 Benchmark-Analyse: Ein neuer Maßstab für KI-Modelle"
Anmerkung des Autors: Tiefenanalyse der Claude Opus 4.7 Benchmarks: SWE-bench Verified 87,6 %, SWE-bench Pro 64,3 %, GPQA Diamond 94,2 %. Das Modell übertrifft GPT-5.4 und Gemini 3.1 Pro deutlich. Inklusive Praxisanleitung für API-Aufrufe.
Anthropic hat am 16. April 2026 offiziell Claude Opus 4.7 veröffentlicht, das in 7 von 10 Kern-Benchmarks die Führung übernommen hat. Dieser Artikel bietet eine fundierte Analyse der Benchmark-Daten von Claude Opus 4.7 und beleuchtet die idealen Einsatzszenarien aus einer praktischen Perspektive.
Dies ist keine bloße Zusammenfassung der offiziellen Pressemitteilung. Alle Daten stammen von unabhängigen Drittanbietern und beleuchten sowohl die Stärken als auch die Schwächen von Opus 4.7, etwa bei der Websuche.
Kernnutzen: Anhand echter Benchmark-Daten und Praxiserfahrungen erfahren Sie, ob sich ein Wechsel zu Claude Opus 4.7 lohnt und wie Sie kostengünstig damit starten können.
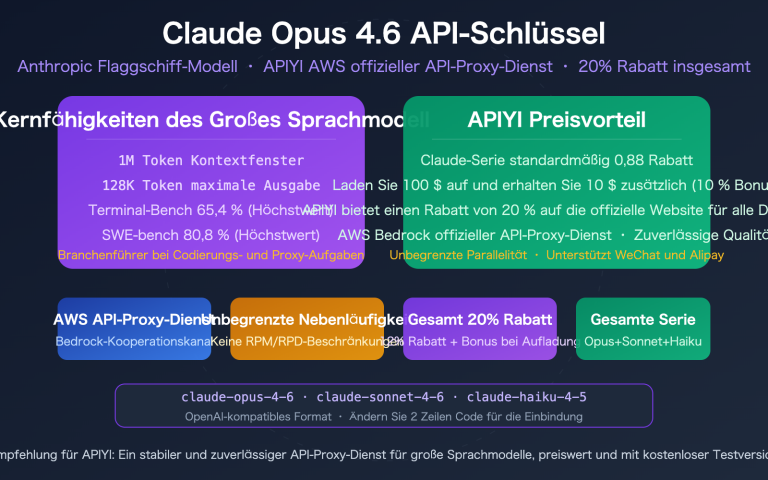
💡 APIYI unterstützt jetzt offiziell das Modell Claude Opus 4.7. Bei einer Aufladung von 100 USD erhalten Sie 10 % Bonus – das entspricht einem effektiven Rabatt von 20 %. Zudem wird die OpenAI-kompatible Schnittstelle für einen einfachen Austausch unterstützt.

Kernpunkte der Claude Opus 4.7 Benchmarks
| Benchmark-Projekt | Opus 4.7 Ergebnis | Vergleich Opus 4.6 | Vergleich GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
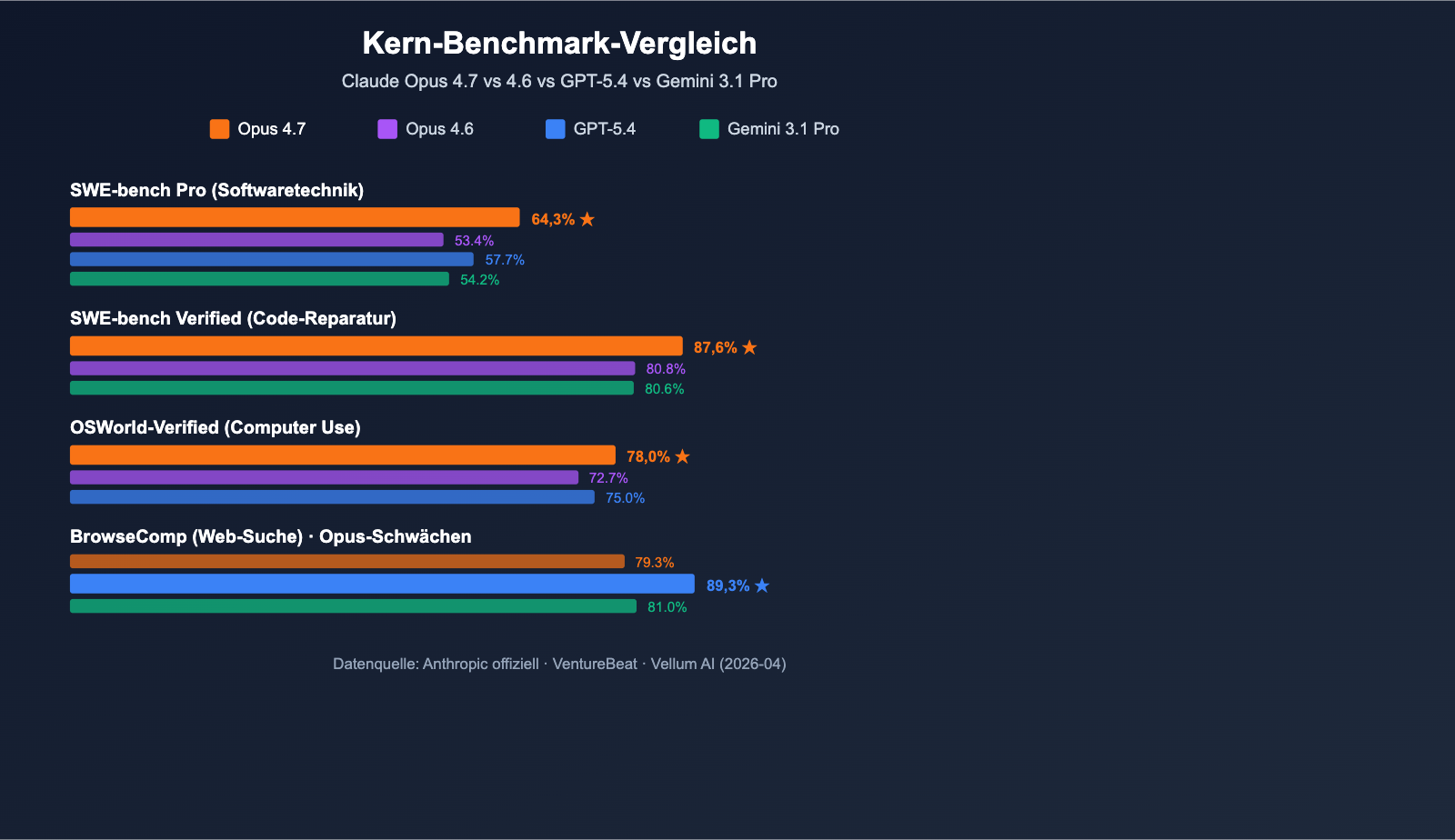
| SWE-bench Verified | 87,6 % | 80,8 % (+6,8) | Gemini 3.1 Pro: 80,6 % ✅ Führend |
| SWE-bench Pro | 64,3 % | 53,4 % (+10,9) | GPT-5.4: 57,7 % / Gemini: 54,2 % ✅ Führend |
| SWE-bench Multilingual | 80,5 % | 77,8 % (+2,7) | ✅ Führend bei mehrsprachiger Programmierung |
| GPQA Diamond | 94,2 % | – | ✅ Maßstab für wissenschaftliches Schlussfolgern |
| Terminal-Bench 2.0 | 69,4 % | – | ✅ Führend bei Terminal-Operationen |
| OSWorld-Verified (Computer Use) | 78,0 % | 72,7 % (+5,3) | GPT-5.4: 75,0 % ✅ Führend |
| MCP-Atlas (Tool-Aufruf) | Führend vor GPT-5.4 +9,2 Punkte | – | ✅ Optimal für Agenten-Szenarien |
| Vision multimodal | 98,5 % | – | ✅ Erstklassiges visuelles Verständnis |
| BrowseComp (Web-Suche) | 79,3 % | – | GPT-5.4: 89,3 % ❌ Rückstand |
Highlights der Claude Opus 4.7 Benchmarks
Mit der Veröffentlichung von Claude Opus 4.7 am 16. April 2026 positioniert Anthropic das Modell als das aktuell leistungsfähigste allgemein verfügbare Große Sprachmodell (laut VentureBeat). In einem direkten Vergleich mit GPT-5.4 und Gemini 3.1 Pro über 10 Kategorien hinweg konnte Opus 4.7 in 7 Bereichen die Führung übernehmen, wobei der Vorsprung bei SWE-bench Pro besonders hervorsticht.
Besonders bemerkenswert ist der Wert von 64,3 % bei SWE-bench Pro – dies ist das derzeit höchste Ergebnis in der Branche für reale Software-Engineering-Aufgaben. Es liegt 6,6 Prozentpunkte über GPT-5.4 (57,7 %) und stellt eine Steigerung von 10,9 Prozentpunkten gegenüber Opus 4.6 dar. Beim MCP-Atlas Benchmark für Tool-Aufrufe führt Opus 4.7 mit 9,2 Punkten vor GPT-5.4, was es zur idealen Wahl für Agentic-AI-Szenarien macht, wie etwa automatisierte Workflows, Code-Generierungs-Agenten und mehrstufige Schlussfolgerungsaufgaben.

Claude Opus 4.7 im Vergleich zu Vorgängern und Wettbewerbern
| Dimension | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Veröffentlichungsdatum | 16.04.2026 | 01/2026 | 03/2026 | 02/2026 |
| Kontextfenster | 1M Token (Standardpreis) | 200K | 400K | 1M |
| SWE-bench Pro | 64,3% | 53,4% | 57,7% | 54,2% |
| Agent/Tool-Aufruf | Stärkstes | Gut | Stark | Gut |
| Websuche (BrowseComp) | 79,3% | 72% | 89,3% | 81% |
| Vision multimodal | 98,5% | 95% | 97% | 96,5% |
| Offizieller API-Preis | 5$ / 25$ (Eingabe/Ausgabe, pro Mio. Token) | 5$ / 25$ | 4,5$ / 22$ | 4$ / 20$ |
| APIYI Gesamtrabatt | 100$ aufladen + 10% Bonus ≈ 20% Rabatt | Gleicher Rabatt | Gleicher Rabatt | Gleicher Rabatt |
Analyse des Vergleichs (Claude Opus 4.7 vs. andere Modelle)
Claude Opus 4.7 vs. GPT-5.4: GPT-5.4 führt weiterhin bei Websuch-Szenarien (BrowseComp, 89,3% vs. 79,3%). Bei SWE-bench Pro (57,7%) und Tool-Aufrufen (MCP-Atlas) liegt es jedoch deutlich hinter Opus 4.7. Claude Opus 4.7 bietet Vorteile bei Entwickler-Workflows, insbesondere bei Coding-Agenten, Code-Generierung und komplexen, mehrstufigen Aufgaben.
Claude Opus 4.7 vs. Gemini 3.1 Pro: Gemini 3.1 Pro bleibt führend bei der Analyse langer Texte und multimodaler Videos. Bei SWE-bench Verified (80,6% vs. 87,6%) und SWE-bench Pro (54,2% vs. 64,3%) ist der Abstand jedoch signifikant. Claude Opus 4.7 ist bei Software-Engineering-Aufgaben überlegen und eignet sich besser für produktive Programmierumgebungen.
Claude Opus 4.7 vs. Opus 4.6: Opus 4.6 bleibt eine solide Wahl für kostenkritische Anwendungen. Die Version 4.7 bietet jedoch massive Sprünge bei Programmierfähigkeiten, agentischer Schlussfolgerung und Computer-Use – bei gleichbleibenden API-Preisen. Für Teams, die komplexe Aufgaben bewältigen müssen, ist das Upgrade auf 4.7 fast unumgänglich.
Hinweis zum Vergleich: Die Daten basieren auf offiziellen Veröffentlichungen von Anthropic, VentureBeat, Vellum AI, Decrypt und anderen Drittanbietern. Sie können diese über die Plattform APIYI (apiyi.com) selbst testen.

Claude Opus 4.7 – Schneller Einstieg
Minimalistisches Beispiel
Hier ist der einfachste Weg, Claude Opus 4.7 über APIYI mit der OpenAI-kompatiblen Schnittstelle aufzurufen:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Schreibe eine Python-Funktion für die In-Order-Traversierung eines Binärbaums"}]
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen (inkl. Aufruf im xhigh Effort Mode)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Aufruf von Claude Opus 4.7 mit Unterstützung für den xhigh Effort Mode
Args:
prompt: Benutzereingabe
effort_level: Grad der logischen Schlussfolgerung, wählbar zwischen "low" / "medium" / "high" / "xhigh"
system_prompt: System-Eingabeaufforderung
max_tokens: Maximale Anzahl der Ausgabe-Token
Returns:
Antwortinhalt des Modells
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Fehler: {str(e)}"
# Für komplexe Programmieraufgaben wird der xhigh-Modus empfohlen
result = call_claude_opus_47(
prompt="Entwirf und implementiere einen LRU-Cache, der O(1) für get- und put-Operationen unterstützt",
effort_level="xhigh",
system_prompt="Du bist ein erfahrener Python-Entwickler. Schreibe Code, der sowohl lesbar als auch performant ist."
)
print(result)
Empfehlung: Holen Sie sich ein kostenloses Testguthaben über APIYI (apiyi.com), um die Leistung von Claude Opus 4.7 für Ihre Anwendungsfälle schnell zu validieren. Die Plattform unterstützt eine einheitliche OpenAI-kompatible Schnittstelle für Opus 4.7, GPT-5.4 und Gemini 3.1 Pro, was direkte Vergleiche erleichtert. Bei Aufladungen ab 100 USD gibt es 10 % Bonus, was effektiv einem Rabatt von 20 % gegenüber den offiziellen Modellpreisen entspricht.
Leistung von Claude Opus 4.7 und typische Einsatzszenarien
4 Kernszenarien für Claude Opus 4.7
- 🧑💻 Umfassendes Code-Refactoring: SWE-bench Verified 87,6 % belegen die Fähigkeit, Kontexte über mehrere Dateien hinweg zu verstehen – ideal für Architekturänderungen, Abhängigkeits-Upgrades und Refactoring in Codebasen mit 100.000 Zeilen.
- 🤖 Automatisierte Agenten-Workflows: Mit einer um 9,2 Punkte höheren Leistung bei MCP-Atlas-Tool-Aufrufen als GPT-5.4 eignet es sich hervorragend für Browser-Automatisierung, RPA und mehrstufige logische Agenten.
- 🔬 Wissenschaftliche Unterstützung und Schlussfolgerung: GPQA Diamond 94,2 % steht für logische Schlussfolgerungsfähigkeiten auf Graduiertenniveau – perfekt für die Unterstützung bei Forschungsarbeiten, Datenanalyse und Hypothesenprüfung.
- 🖥️ Computer Use Desktop-Automatisierung: Mit 78,0 % bei OSWorld-Verified branchenführend, ideal für automatisierte Tests und UI-Operationen, die Maus- und Tastatursimulation erfordern.
Szenarien, für die Claude Opus 4.7 weniger geeignet ist
- Echtzeit-Websuche: Mit 79,3 % bei BrowseComp liegt es deutlich hinter den 89,3 % von GPT-5.4. Für solche Szenarien empfiehlt sich der Wechsel zu GPT-5.4.
- Groß angelegte, kostengünstige Aufrufe: Bei einem Ausgabepreis von 25 USD/M Token sollten für alltägliche Chat-Anwendungen eher Claude Haiku oder GPT-5.4-mini verwendet werden.
- Anforderungen mit extrem geringer Latenz: Die Antwortlatenz der Opus-Serie ist höher als bei Sonnet oder Haiku; bei Echtzeit-Interaktionen ist Vorsicht geboten.
Claude Opus 4.7 Preis- und Kostenkalkulation
Offizielle Preisgestaltung vs. APIYI Gesamtkosten
| Projekt | Offizieller Preis (Anthropic) | APIYI Preis (inkl. Bonusguthaben) |
|---|---|---|
| Input-Token | $5 / Million Token | Gleicher Stückpreis wie offiziell |
| Output-Token | $25 / Million Token | Gleicher Stückpreis wie offiziell |
| Aufladebonus | Keiner | 10% Bonus ab 100 USD |
| Effektiver Gesamtrabatt | Keiner | ca. 20% Rabatt (höherer Bonus bei höheren Stufen) |
| Zahlungsmethoden | Nur US-Kreditkarten | RMB, USD und diverse weitere Methoden |
| Abrechnungswährung | USD | Wahlweise RMB / USD |
Kostenhinweis: Der neue Tokenizer von Opus 4.7 verbraucht bei der Textverarbeitung etwa 1x bis 1,35x mehr Token als bei Version 4.6 (abhängig vom Inhaltstyp). Obwohl der offizielle Stückpreis gleich geblieben ist, können die tatsächlichen Abrechnungskosten um etwa 20–30 % steigen. Durch den Aufladebonus von APIYI (apiyi.com) können diese versteckten Kosten ausgeglichen werden, sodass die tatsächlichen Nutzungskosten auf dem Niveau der 4.6-Ära bleiben oder sogar darunter liegen.
Häufig gestellte Fragen (FAQ)
Q1: Was ist Claude Opus 4.7?
Claude Opus 4.7 ist das am 16. April 2026 von Anthropic veröffentlichte Flaggschiff-Großes Sprachmodell. Es führt in mehreren Benchmarks wie Programmierung (SWE-bench Verified 87,6 %), Agent-Tool-Aufrufe und wissenschaftliches Schlussfolgern (GPQA Diamond 94,2 %) vor GPT-5.4 und Gemini 3.1 Pro. Im Vergleich zu Opus 4.6 wurde ein "xhigh effort"-Modus für tiefgreifendes Schlussfolgern hinzugefügt, ohne dass sich der offizielle Preis erhöht hat.
Q2: Was ist besser: Claude Opus 4.7 oder GPT-5.4?
Das hängt vom Szenario ab. Bei der Programmierung (SWE-bench Pro 64,3 % vs. 57,7 %), Tool-Aufrufen (MCP-Atlas +9,2 Punkte) und Computer Use (78,0 % vs. 75,0 %) liegt Opus 4.7 deutlich vorn; bei der Websuche (BrowseComp 79,3 % vs. 89,3 %) behält GPT-5.4 jedoch die Oberhand. Für Entwicklungs-Workflows ist Opus 4.7 die erste Wahl, für webbasierte Suchaufgaben GPT-5.4.
Q3: Wann wurde Claude Opus 4.7 veröffentlicht und ist es in China verfügbar?
Das offizielle Veröffentlichungsdatum war der 16. April 2026. Es ist über die Claude API, Amazon Bedrock, Google Cloud Vertex AI und Microsoft Foundry verfügbar. Entwickler in China können über Aggregator-Plattformen wie APIYI (apiyi.com) synchron auf das offizielle Modell zugreifen, ohne ein ausländisches Konto beantragen zu müssen.
Q4: Für welche Projekte eignet sich Claude Opus 4.7 am besten?
Es eignet sich besonders für folgende Szenarien:
- Groß angelegtes Code-Refactoring: Verständnis von Kontexten über Dateien hinweg, Abhängigkeitsmigrationen, Architekturänderungen
- Agent-Automatisierung: MCP-Toolchains, Browser-Automatisierung, RPA-Prozesse
- Wissenschaft und Datenanalyse: Schlussfolgerungen auf Graduiertenniveau, Hypothesenprüfung, Unterstützung bei wissenschaftlichen Arbeiten
- Computer Use Desktop-Automatisierung: UI-Automatisierungstests, GUI-Skripte
Q5: Wie kann ich Claude Opus 4.7 schnell über die API aufrufen?
Wir empfehlen die Nutzung einer Aggregator-Plattform, die das OpenAI-kompatible Protokoll unterstützt. In 3 Schritten einsatzbereit:
- Registrieren Sie sich bei APIYI (apiyi.com) und erhalten Sie einen API-Schlüssel.
- Laden Sie 100 USD auf, um einen Bonus von 10 % (ca. 20 % Gesamtrabatt) zu erhalten, oder testen Sie das Modell zunächst mit dem kostenlosen Guthaben.
- Ändern Sie die
base_urlIhres OpenAI-SDKs aufhttps://vip.apiyi.com/v1und geben Sie als Modellclaude-opus-4-7an.
APIYI unterstützt die einheitliche Einbindung gängiger Modelle wie Claude Opus 4.7, GPT-5.4 und Gemini 3.1 Pro, was einen einfachen Vergleich und Wechsel ermöglicht.
Q6: Welche bekannten Einschränkungen hat Claude Opus 4.7?
Zu den Haupteinschränkungen gehören:
- Erhöhter Token-Verbrauch: Der neue Tokenizer verbraucht 1x-1,35x mehr Token als bei 4.6, was die Kosten um 20-30 % steigern kann.
- Schwächen bei der Websuche: Mit 79,3 % bei BrowseComp liegt es hinter GPT-5.4; für Echtzeit-Websuchen nur bedingt geeignet.
- Antwortlatenz: Die Opus-Serie hat eine höhere Latenz als Sonnet/Haiku; für Echtzeit-Dialoganwendungen empfehlen wir leichtere Modelle.
- Hoher offizieller Stückpreis: Bei $5/$25 pro Million Token empfiehlt sich für großflächige Aufrufe die Nutzung der Aufladeboni von APIYI zur Kostensenkung.
Q7: Wie groß ist das Kontextfenster von Claude Opus 4.7?
Claude Opus 4.7 unterstützt ein Kontextfenster von 1 Million (1M) Token bei Standardpreisgestaltung ohne Aufschläge für lange Kontexte. Das bedeutet, dass Sie in einer einzigen Anfrage ein komplettes mittelgroßes Code-Repository, lange technische Dokumentationen oder vollständige Besprechungsprotokolle verarbeiten können – das entspricht etwa 750.000 chinesischen Schriftzeichen oder 200 PDF-Seiten.
Q8: Was ist der xhigh Effort Mode und wann sollte man ihn nutzen?
"xhigh effort" ist der neue höchste Schlussfolgerungsmodus von Opus 4.7. Das Modell investiert mehr Token und Zeit in mehrstufiges Denken und Selbstvalidierung. Wir empfehlen die Aktivierung in folgenden Szenarien:
- Komplexe Algorithmenentwicklung (z. B. LRU-Caching, verteilte Konsistenz)
- Refactoring-Aufgaben über mehrere Dateien hinweg
- Mathematische Schlussfolgerungen, die mehrstufige Logikketten erfordern
- Kritische Code-Reviews und Sicherheitsüberprüfungen
Für alltägliche Dialoge oder einfache CRUD-Programmierung reichen high oder medium aus, um unnötige Token-Kosten zu vermeiden.
Claude Opus 4.7 – Die wichtigsten Erkenntnisse
- 🏆 Führend in 7 Benchmarks: 64,3 % bei SWE-bench Pro, 87,6 % bei Verified, 94,2 % bei GPQA; liegt bei MCP-Atlas 9,2 Punkte vor GPT-5.4.
- 💡 xhigh Effort Mode: Neuer Modus für höchste Schlussfolgerungskraft, ideal für komplexe Algorithmen und dateiübergreifendes Refactoring.
- 🚀 Ideal für Agent-Szenarien: Führend bei Werkzeugaufrufen und Computer Use; das Modell der Wahl für Agentic AI.
- ⚠️ Schwäche bei der Websuche: 10 Punkte Rückstand auf GPT-5.4 bei BrowseComp; bei internetbasierten Aufgaben empfiehlt sich ein Vergleich.
- 💰 Etwa 20 % sparen mit APIYI: Die offiziellen Preise sind stabil, bei Aufladungen ab 100 USD über apiyi.com gibt es 10 % Bonus und mehr – das entspricht effektiv ca. 20 % Rabatt.
Fazit
Die Benchmark-Daten von Claude Opus 4.7 lassen einen klaren Schluss zu: Es ist derzeit das leistungsstärkste Universalmodell für Programmierung und Agent-Szenarien. Die wichtigsten Punkte:
- Überragende Programmierleistung: Mit 64,3 % bei SWE-bench Pro lässt es GPT-5.4 und Gemini 3.1 Pro weit hinter sich – die erste Wahl für Aufgaben in der produktiven Softwareentwicklung.
- König der Agent-Werkzeugaufrufe: Führend mit 9,2 Punkten bei MCP-Atlas und 3 Punkten bei Computer Use; die beste Wahl für Automatisierungsprozesse.
- Beachtung der tatsächlichen Kosten: Das neue Tokenizer-Format führt zu einem Anstieg der verdeckten Kosten um 20–30 %. Dies lässt sich jedoch durch Auflade-Boni auf Aggregator-Plattformen ausgleichen.
Wenn Ihr Schwerpunkt auf KI-Programmierung, Agent-Entwicklung oder komplexen Schlussfolgerungen liegt, sollten Sie sofort auf Claude Opus 4.7 umsteigen. Wir empfehlen den schnellen Zugriff über APIYI (apiyi.com) – offizielle Modellanbindung, sofortiger Austausch über OpenAI-kompatible Schnittstellen und durch den 10-%-Bonus bei 100 USD Aufladung sparen Sie effektiv 20 % und umgehen den Aufwand für Auslandskonten und Fremdwährungszahlungen.
延伸阅读 Related Articles
Wenn Sie sich für den Claude Opus 4.7 Benchmark interessieren, empfehlen wir Ihnen folgende weiterführende Artikel:
- 📘 Vollständiger Leitfaden für den Claude Opus 4.7 Modellaufruf – Erfahren Sie alles über den „High Effort Mode“, Prompt Caching und die Nutzung von Werkzeugaufrufen.
- 📊 GPT-5.4 vs. Claude Opus 4.7 vs. Gemini 3.1 Pro im Tiefenvergleich – Treffen Sie fundierte Entscheidungen bei der Modellauswahl für verschiedene Einsatzszenarien.
- 🚀 MCP-Protokoll und Claude Opus 4.7 Agent in der Praxis – Entdecken Sie, wie Sie mit Opus 4.7 produktionsreife Agent-Workflows aufbauen.
📚 Referenzen
-
Offizielle Ankündigung von Anthropic: Produktvorstellung und Benchmark-Daten zu Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Hinweis: Primärquelle mit allen offiziellen Ergebnissen der Benchmark-Tests.
- Link:
-
Unabhängiger Testbericht von VentureBeat: Analyse zur Rückkehr von Opus 4.7 an die Spitze der allgemeinen Großsprachmodelle
- Link:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Hinweis: Unabhängige Perspektive eines Drittanbieters mit einem umfassenden Vergleich von Opus 4.7 gegenüber der Konkurrenz.
- Link:
-
Analyse der Vellum AI Benchmarks: Detaillierte Aufschlüsselung der Benchmark-Methodik und deren Glaubwürdigkeit
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Hinweis: Ideal für technisch versierte Leser, die die Methoden hinter den Benchmarks tiefergehend verstehen möchten.
- Link:
-
Offizielle Claude API-Dokumentation: Informationen zu Kontextfenster, Preisen und Tokenizern
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Hinweis: Die maßgebliche Referenz für Integration und Modellaufruf, inklusive Migrationsleitfaden.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Wir freuen uns auf Ihre Erfahrungen mit Claude Opus 4.7 in den Kommentaren. Weitere Informationen zum Modellaufruf finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.