title: Claude Opus 4.7 ベンチマーク詳細解説:SWE-bench で圧倒的パフォーマンスを記録
description: 2026年4月16日にリリースされたClaude Opus 4.7。SWE-benchでの驚異的なスコアやGPT-5.4との比較、API呼び出しの実践まで徹底解説します。
執筆者注: Claude Opus 4.7 ベンチマークの徹底解説:SWE-bench Verified 87.6%、SWE-bench Pro 64.3%、GPQA Diamond 94.2% を達成。GPT-5.4 や Gemini 3.1 Pro を凌駕する性能と、API呼び出しの実戦的アプローチについて解説します。
Anthropic は 2026 年 4 月 16 日に Claude Opus 4.7 を正式にリリースしました。10 の主要ベンチマークのうち 7 つでトップを独走しています。本記事では、実測評価の観点から Claude Opus 4.7 のベンチマーク中核データとその適用シーンを詳しく解説します。
これは公式広報の単なる要約ではありません。 すべてのデータは第三者の独立評価機関によるものであり、強みだけでなく、Web 検索等の分野における Opus 4.7 の弱点についても正直に記述しています。
コアバリュー: 正確なベンチマークデータと使用体験を通じて、Claude Opus 4.7 に切り替える価値があるか、また低コストで利用する方法を判断するお手伝いをします。
💡 APIYI にて Claude Opus 4.7 公式モデルを同期リリース済み。100ドルのチャージで 10% 以上のボーナスが付与され、実質 20% OFF での利用が可能です。OpenAI 互換インターフェースに対応しており、ワンタッチでモデルの置き換えが可能です。

Claude Opus 4.7 ベンチマークの要点
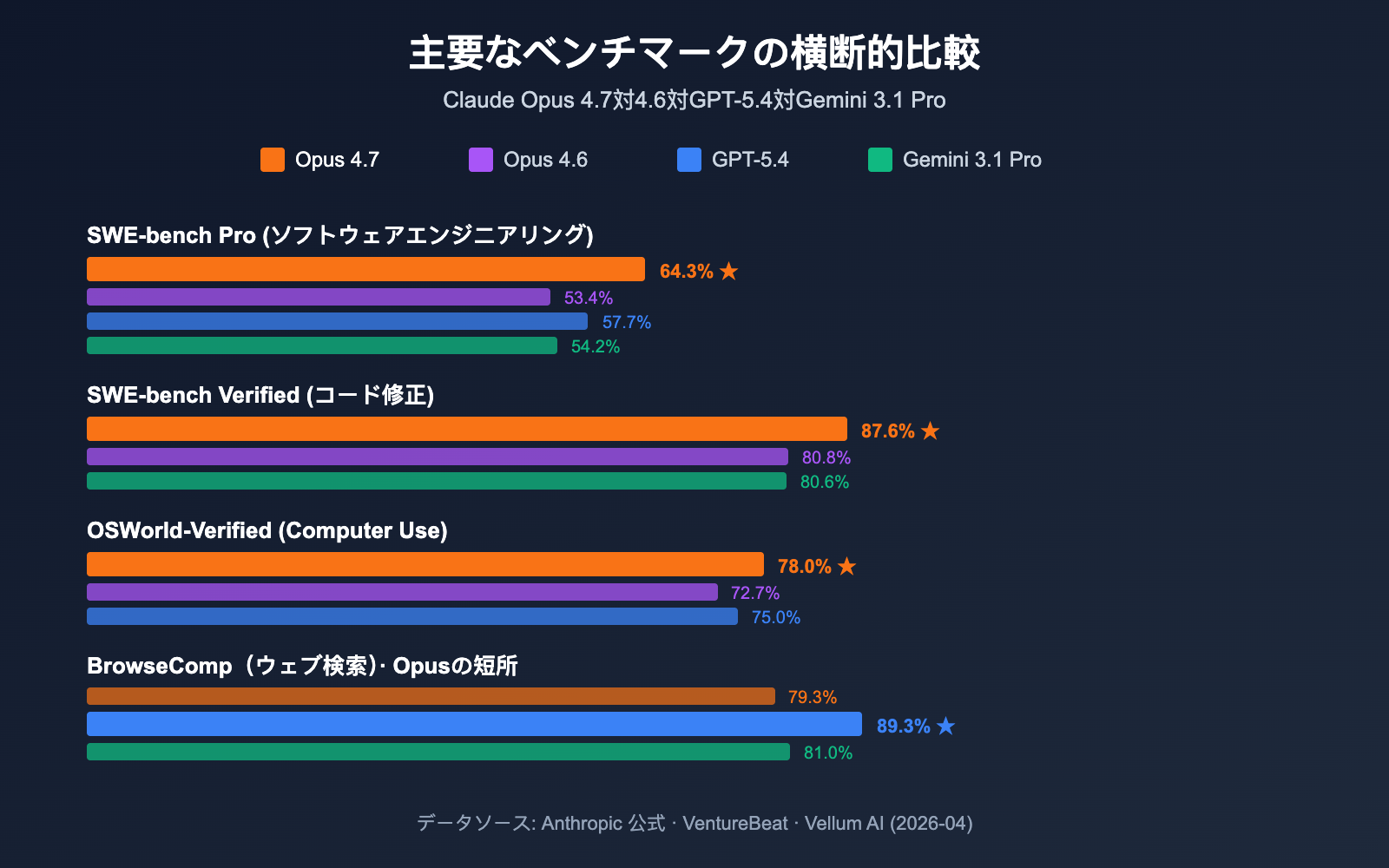
| ベンチマーク項目 | Opus 4.7 成績 | Opus 4.6 との比較 | GPT-5.4 / Gemini 3.1 Pro との比較 |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅ 領先 |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅ 領先 |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ 多言語プログラミングで領先 |
| GPQA Diamond | 94.2% | – | ✅ 科学的推論のベンチマーク |
| Terminal-Bench 2.0 | 69.4% | – | ✅ ターミナル操作で領先 |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅ 領先 |
| MCP-Atlas (ツール呼び出し) | GPT-5.4 より +9.2 ポイント | – | ✅ Agent シーンで最適 |
| Vision マルチモーダル | 98.5% | – | ✅ 視覚理解で最高峰 |
| BrowseComp (Web 検索) | 79.3% | – | GPT-5.4: 89.3% ❌ 遅れをとる |
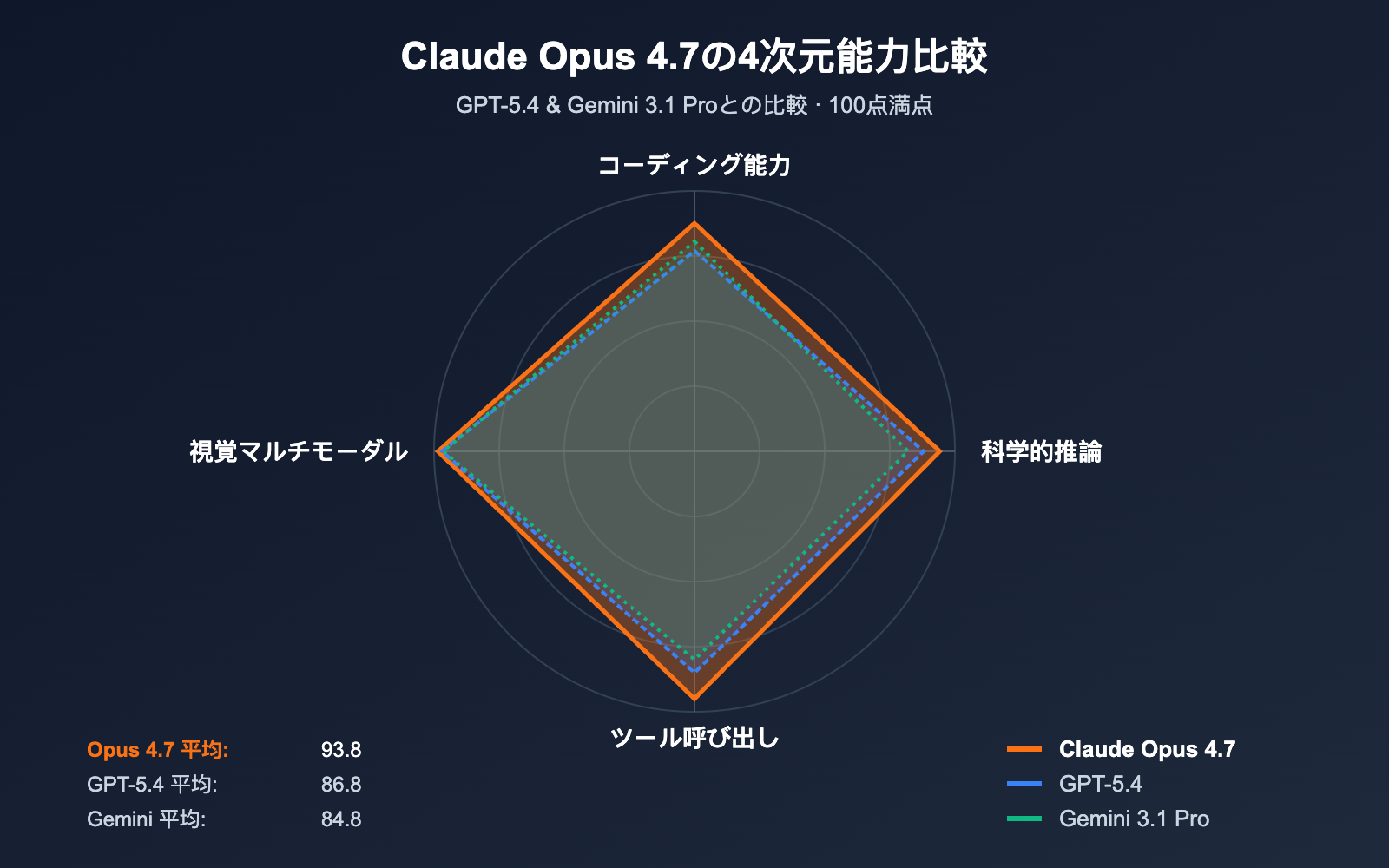
Claude Opus 4.7 ベンチマークの核心的ハイライト
Anthropic が 2026 年 4 月 16 日にリリースした Claude Opus 4.7 は、現在汎用可能な最も強力な大規模言語モデルと位置付けられています(VentureBeat 評価)。GPT-5.4、Gemini 3.1 Pro との 10 項目の直接比較において、Opus 4.7 は 7 項目でトップに立ち、特に SWE-bench Pro でのリードが際立っています。
特筆すべきは SWE-bench Pro 64.3% という数字です。これは現在の業界における実際のソフトウェアエンジニアリングタスクにおいて最高記録であり、GPT-5.4 の 57.7% を 6.6 ポイント上回り、Opus 4.6 の 53.4% から 10.9 ポイントの大幅な飛躍を遂げました。MCP-Atlas ツール呼び出しのベンチマークにおいても、Opus 4.7 は GPT-5.4 を 9.2 ポイントリードしており、自動化ワークフローやコード生成 Agent、多段階推論タスクといった Agentic AI シーンにより適していることを示しています。
title: Claude Opus 4.7 と前世代・競合モデルの比較分析
description: 最新の Claude Opus 4.7 と、GPT-5.4 や Gemini 3.1 Pro との性能比較を解説。プログラミング能力、エージェント機能、コストパフォーマンスを徹底検証します。
Claude Opus 4.7 と前世代・競合モデルの比較
| 項目 | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| リリース日 | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| コンテキストウィンドウ | 1M トークン (標準) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| エージェント/ツール呼び出し | 最強 | 良好 | 強 | 良好 |
| Web 検索 (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Vision マルチモーダル | 98.5% | 95% | 97% | 96.5% |
| 公式 API 料金 | $5 / $25 (入力/出力, 100万トークン毎) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| APIYI 総合割引 | 100ドルチャージで10%還元〜 約20%OFF | 同様 | 同様 | 同様 |
比較解説 (Claude Opus 4.7 vs 他モデル)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 は Web 検索(BrowseComp)において 89.3% と高い性能を維持しています。しかし、SWE-bench Pro (57.7%) やツール呼び出し(MCP-Atlas)の面では Opus 4.7 が優位です。プログラミングエージェントやコード生成、複雑なマルチステップタスクにおいては Opus 4.7 が開発者のワークフローにより適しています。
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro は長文理解やマルチモーダル動画処理で強みを発揮します。一方で、SWE-bench Verified (80.6% vs 87.6%) や SWE-bench Pro (54.2% vs 64.3%) のスコアでは差が開いています。ソフトウェアエンジニアリングタスクにおいては、Claude Opus 4.7 が圧倒的であり、本番環境でのプログラミングに適しています。
Claude Opus 4.7 vs Opus 4.6: Opus 4.6 はコスト重視のシナリオで依然として安定した選択肢です。しかし、4.7 ではプログラミング能力、エージェント推論、Computer Use 機能が大幅に向上しており、API 料金は据え置きとなっています。複雑な長距離タスクを扱うチームにとって、4.7 への移行は非常に価値のある選択です。
比較注記: 上記データは Anthropic 公式発表、VentureBeat、Vellum AI、Decrypt などの第三者評価機関のデータを参照しています。APIYI (apiyi.com) プラットフォームを通じて実測検証が可能です。
Claude Opus 4.7 クイックスタート
シンプルな例
APIYI を介して Claude Opus 4.7 を呼び出す最も簡単な方法は、OpenAI 互換インターフェースを使用することです。
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Pythonで二分探索木の順序走査を行う関数を書いてください"}]
)
print(response.choices[0].message.content)
完全な実装コードを表示 (xhigh Effort Mode の呼び出しを含む)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Claude Opus 4.7 を呼び出します(xhigh effort mode をサポート)
Args:
prompt: ユーザー入力
effort_level: 推論の努力レベル ("low" / "medium" / "high" / "xhigh" から選択)
system_prompt: システムプロンプト
max_tokens: 最大出力トークン数
Returns:
モデルの応答内容
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 複雑なプログラミングタスクには xhigh モードを推奨
result = call_claude_opus_47(
prompt="O(1) の get および put 操作をサポートする LRU キャッシュを設計・実装してください",
effort_level="xhigh",
system_prompt="あなたはシニア Python エンジニアです。可読性とパフォーマンスを両立させたコードを書いてください"
)
print(result)
アドバイス: APIYI (apiyi.com) で無料のテスト枠を取得し、Claude Opus 4.7 がご自身の環境でどのように機能するかを素早く検証してみてください。当プラットフォームは Opus 4.7、GPT-5.4、Gemini 3.1 Pro の統一された OpenAI 互換インターフェースをサポートしており、横断的な比較が容易です。チャージキャンペーンでは 100 ドル以上のチャージで 10% 以上のボーナスが付与され、公式モデルを実質約 20% オフで利用可能です。
Claude Opus 4.7 の実測パフォーマンスと典型的なユースケース
Claude Opus 4.7 に適した 4 つの主要シナリオ
- 🧑💻 大規模なコードリファクタリング: SWE-bench Verified で 87.6% を記録。ファイル間を跨ぐコンテキスト理解に優れており、10 万行規模のコードベースのアーキテクチャ調整、依存関係のアップグレード、一括リファクタリングに適しています。
- 🤖 エージェント自動化ワークフロー: MCP-Atlas のツール呼び出し能力で GPT-5.4 を 9.2 ポイント上回ります。ブラウザ自動化、RPA、多段階推論エージェントの構築に最適です。
- 🔬 研究支援と推論: GPQA Diamond で 94.2% を達成。大学院レベルの専門的な推論能力を有しており、論文作成支援、データ分析、仮説検証に適しています。
- 🖥️ Computer Use デスクトップ自動化: OSWorld-Verified で 78.0% を記録し業界をリード。マウスやキーボード操作をシミュレートする自動テストや UI 操作に適しています。
Claude Opus 4.7 に適さないシナリオ
- リアルタイム Web 検索: BrowseComp で 79.3% と、GPT-5.4 の 89.3% に大きく遅れをとっています。この用途には GPT-5.4 への切り替えを推奨します。
- 大規模かつ低コストな呼び出し: 出力単価が $25/M トークンであるため、日常的な会話型アプリケーションには Claude Haiku や GPT-5.4-mini の使用をおすすめします。
- 超低遅延が求められる場合: Opus シリーズは Sonnet/Haiku よりも応答遅延が大きいため、リアルタイム性が重要なインタラクティブな場面では慎重に選択してください。
Claude Opus 4.7 の価格とコスト試算
公式価格 vs APIYI 総合コスト
| 項目 | 公式価格 (Anthropic) | APIYI 価格 (チャージボーナス込み) |
|---|---|---|
| 入力トークン | $5 / 100万トークン | 公式単価と同等 |
| 出力トークン | $25 / 100万トークン | 公式単価と同等 |
| チャージボーナス | なし | 100ドルで10%〜付与 |
| 総合実質割引 | なし | 約20%OFF (チャージ額に応じて増加) |
| 支払い方法 | 米ドルクレジットカードのみ | 人民元、米ドル、その他多数に対応 |
| 請求通貨 | USD | RMB / USD 選択可能 |
コストに関するヒント: Opus 4.7 の新しいトークナイザーは、テキスト処理時に 4.6 よりも約 1倍〜1.35倍多くのトークンを消費します(コンテンツの種類により変動)。公式単価は据え置きですが、実際の請求額は約 20〜30% 上昇する可能性があります。APIYI (apiyi.com) のチャージボーナス特典を活用することで、この隠れたコストを相殺でき、実質的な利用コストを 4.6 時代と同等、あるいはそれ以下に抑えることが可能です。
よくある質問 (FAQ)
Q1: Claude Opus 4.7 とは何ですか?
Claude Opus 4.7 は、Anthropic が 2026 年 4 月 16 日にリリースしたフラッグシップ大規模言語モデルです。コーディング (SWE-bench Verified 87.6%)、エージェントのツール呼び出し、科学的推論 (GPQA Diamond 94.2%) などの複数のベンチマークで GPT-5.4 や Gemini 3.1 Pro を上回る性能を誇ります。Opus 4.6 と比較して、「xhigh effort」深度推論モードが追加されましたが、公式価格は据え置かれています。
Q2: Claude Opus 4.7 と GPT-5.4 はどちらが優れていますか?
用途によります。プログラミング (SWE-bench Pro 64.3% vs 57.7%)、ツール呼び出し (MCP-Atlas +9.2ポイント)、Computer Use (78.0% vs 75.0%) では Opus 4.7 が明らかに優勢です。一方、Web 検索 (BrowseComp 79.3% vs 89.3%) では GPT-5.4 が強みを持っています。開発系のワークフローには Opus 4.7、ネット検索系には GPT-5.4 を選ぶのが最適です。
Q3: Claude Opus 4.7 はいつリリースされましたか?日本から利用できますか?
公式リリース日は 2026 年 4 月 16 日で、Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry ですでに利用可能です。国内の開発者は、APIYI (apiyi.com) などのアグリゲーションプラットフォームを通じて、海外アカウントを申請することなく公式モデルを同期して利用できます。
Q4: Claude Opus 4.7 はどのような実際のプロジェクトに適していますか?
主に以下のシーンに適しています:
- 大規模なコードリファクタリング: ファイルを跨いだコンテキスト理解、依存関係の移行、アーキテクチャの調整
- エージェント自動化: MCP ツールチェーン、ブラウザ自動化、RPA プロセス
- 科学研究とデータ分析: 大学院レベルの推論、仮説検証、論文作成支援
- Computer Use デスクトップ自動化: UI 自動テスト、GUI 操作スクリプト
Q5: API を通じて Claude Opus 4.7 を素早く呼び出すには?
OpenAI 互換プロトコルをサポートするアグリゲーションプラットフォーム経由での呼び出しを推奨します。3 ステップで開始可能です:
- APIYI (apiyi.com) にアクセスしてアカウントを登録し、APIキーを取得する
- 100ドルチャージして 10%〜のボーナスを受け取る(実質約20%OFF)、または無料枠でテストする
- OpenAI SDK の
base_urlをhttps://vip.apiyi.com/v1に変更し、モデル名にclaude-opus-4-7を指定する
APIYI は Claude Opus 4.7、GPT-5.4、Gemini 3.1 Pro などの主要モデルの統一アクセスをサポートしており、横断的な比較や切り替えが容易です。
Q6: Claude Opus 4.7 に既知の制限はありますか?
主な制限は以下の通りです:
- トークン消費量の増加: 新しいトークナイザーにより 4.6 より 1〜1.35倍多くのトークンを消費するため、実際の請求額が 20〜30% 上昇する可能性がある
- Web 検索の弱点: BrowseComp 79.3% で GPT-5.4 に劣るため、リアルタイムのネット検索が必要な場面では注意が必要
- 応答遅延: Opus シリーズは Sonnet/Haiku よりも遅延が大きいため、リアルタイム対話型アプリでは軽量モデルとの併用を推奨
- 公式単価の高さ: 100万トークンあたり $5/$25。大規模な呼び出しには、APIYI のチャージボーナスを活用してコストを相殺することを推奨
Q7: Claude Opus 4.7 のコンテキストウィンドウはどれくらいですか?
Claude Opus 4.7 は 100万 (1M) トークンのコンテキストウィンドウをサポートしており、追加料金なしの標準価格で利用可能です。これにより、中規模のコードリポジトリ全体、長文の技術ドキュメント、または会議の全記録を一度のリクエストで処理できます。これは約75万文字、または200ページの PDF に相当します。
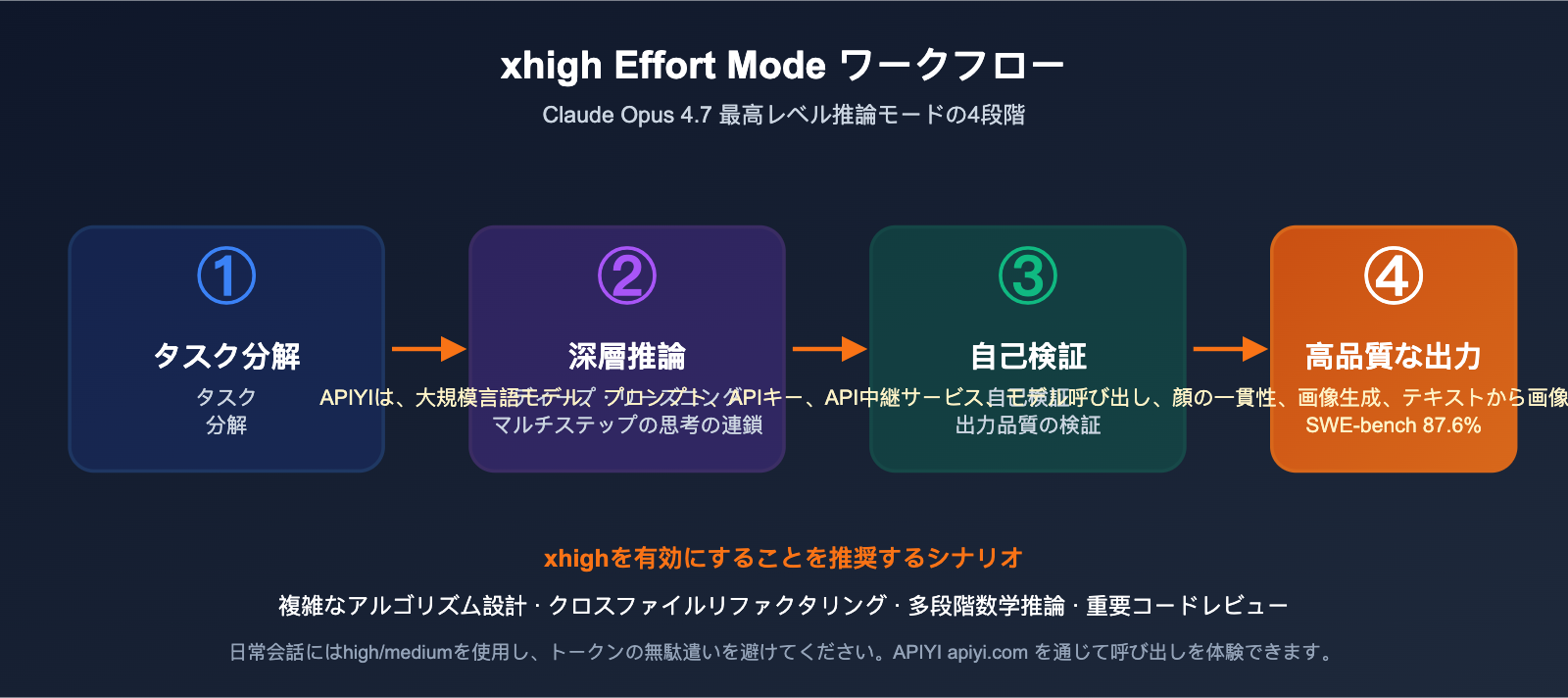
Q8: xhigh Effort Mode とは何ですか?いつ使うべきですか?
「xhigh effort」は Opus 4.7 で追加された最高レベルの推論モードです。モデルがより多くのトークンと時間を費やして、多段階の思考と自己検証を行います。以下のシーンで有効にすることをお勧めします:
- 複雑なアルゴリズム設計(LRU キャッシュ、分散整合性など)
- ファイルを跨ぐ大規模なリファクタリングタスク
- 多段階の論理チェーンを必要とする数学的推論
- 重要なコードレビューや脆弱性診断
日常的な会話や単純な CRUD コード作成などでは high または medium を使用し、無駄なトークン消費を抑えるのが賢明です。
Claude Opus 4.7 の主要ポイント (Key Takeaways)
- 🏆 7 つの主要ベンチマークでトップ: SWE-bench Pro で 64.3%、Verified で 87.6%、GPQA で 94.2%、MCP-Atlas では GPT-5.4 を 9.2 ポイント上回るスコアを記録
- 💡 xhigh Effort Mode: 新たに最高レベルの推論モードが追加され、複雑なアルゴリズムやファイル横断のリファクタリングに最適
- 🚀 エージェント用途に最適: ツール呼び出しと Computer Use(コンピューター操作)で全面的にリードしており、Agentic AI(自律型AI)開発における第一選択肢
- ⚠️ Web 検索の弱点: BrowseComp では GPT-5.4 に 10 ポイント遅れをとっているため、Web 検索が必要なタスクでは比較検討を推奨
- 💰 APIYI で 20% オフ: 公式価格は据え置き。apiyi.com を通じて 100 ドル以上チャージすると 10% 以上のボーナスが付与され、実質約 20% オフで利用可能
まとめ
Claude Opus 4.7 のベンチマークデータが明確に示す結論、それは**「現在、プログラミングおよびエージェントのタスクにおいて最強の汎用モデルである」**ということです。重要なポイントは以下の通りです。
- プログラミング能力が圧倒的: SWE-bench Pro で 64.3% を記録し、GPT-5.4 や Gemini 3.1 Pro を大きく引き離しました。本番環境のコード開発において最優先で選ぶべきモデルです。
- エージェントツール活用の王者: MCP-Atlas で 9.2 ポイント、Computer Use で 3 ポイントのリードを維持しており、自動化タスクにおける最適解といえます。
- 実質コストには注意: 新しいトークナイザーにより 20〜30% の隠れたコスト増加が発生しているため、アグリゲーターサービスのチャージ特典を活用してコストを抑えるのが賢明です。
AI プログラミング、エージェント開発、複雑な推論タスクが業務の中心であれば、今すぐ Claude Opus 4.7 に切り替える価値があります。APIYI (apiyi.com) を経由すれば、公式モデルを即座に利用でき、OpenAI 互換インターフェースで簡単に置き換え可能です。さらに、100 ドル以上のチャージで 10% 以上のボーナスが付くため、実質 20% オフで利用でき、海外アカウントやドル決済の手間も不要です。
延伸阅读 Related Articles
Claude Opus 4.7 のベンチマークに興味がある方は、以下の記事もおすすめです:
- 📘 Claude Opus 4.7 API呼び出し完全ガイド – High Effort Mode、プロンプトキャッシング、ツール呼び出しの完全な使い方を解説
- 📊 GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro 徹底比較 – 3大フラッグシップモデルの各シナリオにおける選定基準をマスター
- 🚀 MCPプロトコルとClaude Opus 4.7 Agentの実践 – Opus 4.7を活用したプロダクションレベルのAgentワークフロー構築手法を探索
📚 参考資料
-
Anthropic 公式発表: Claude Opus 4.7 製品紹介およびベンチマークデータ
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: 公式の一次情報源。すべての公式ベンチマークスコアを掲載
- リンク:
-
VentureBeat 独立評価: 汎用LLMでOpus 4.7が首位に返り咲いた理由の分析
- リンク:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - 説明: 第三者視点による、Opus 4.7と競合モデルの総合的な比較分析
- リンク:
-
Vellum AI ベンチマーク解説: ベンチマーク手法と信頼性の項目別詳細分析
- リンク:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 説明: ベンチマークの評価手法を深く理解したい技術者向け
- リンク:
-
Claude 公式APIドキュメント: コンテキストウィンドウ、料金、トークナイザーの説明
- リンク:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 説明: 統合や呼び出しに関する信頼できるリファレンス。移行ガイドも含む
- リンク:
著者: APIYI 技術チーム
技術交流: Claude Opus 4.7の使用感について、ぜひコメント欄で共有してください。API呼び出しに関する詳細は、APIYIのドキュメントセンター(docs.apiyi.com)をご覧ください。