作者注:深度對比 2026 年 2 月同期發佈的 MiniMax-M2.5 和 GLM-5 兩大開源模型,從編碼、推理、智能體、速度、價格和架構 6 個維度解析各自擅長領域
2026 年 2 月 11-12 日,兩大中國 AI 公司幾乎同時發佈了各自的旗艦模型:智譜 GLM-5(744B 參數)和 MiniMax-M2.5(230B 參數)。兩者都採用 MoE 架構、MIT 開源協議,但在能力側重上形成了鮮明的差異化定位。
核心價值: 看完本文,你將清楚瞭解 GLM-5 擅長推理和知識可靠性,MiniMax-M2.5 擅長編碼和智能體工具調用,從而在具體場景中做出最優選擇。
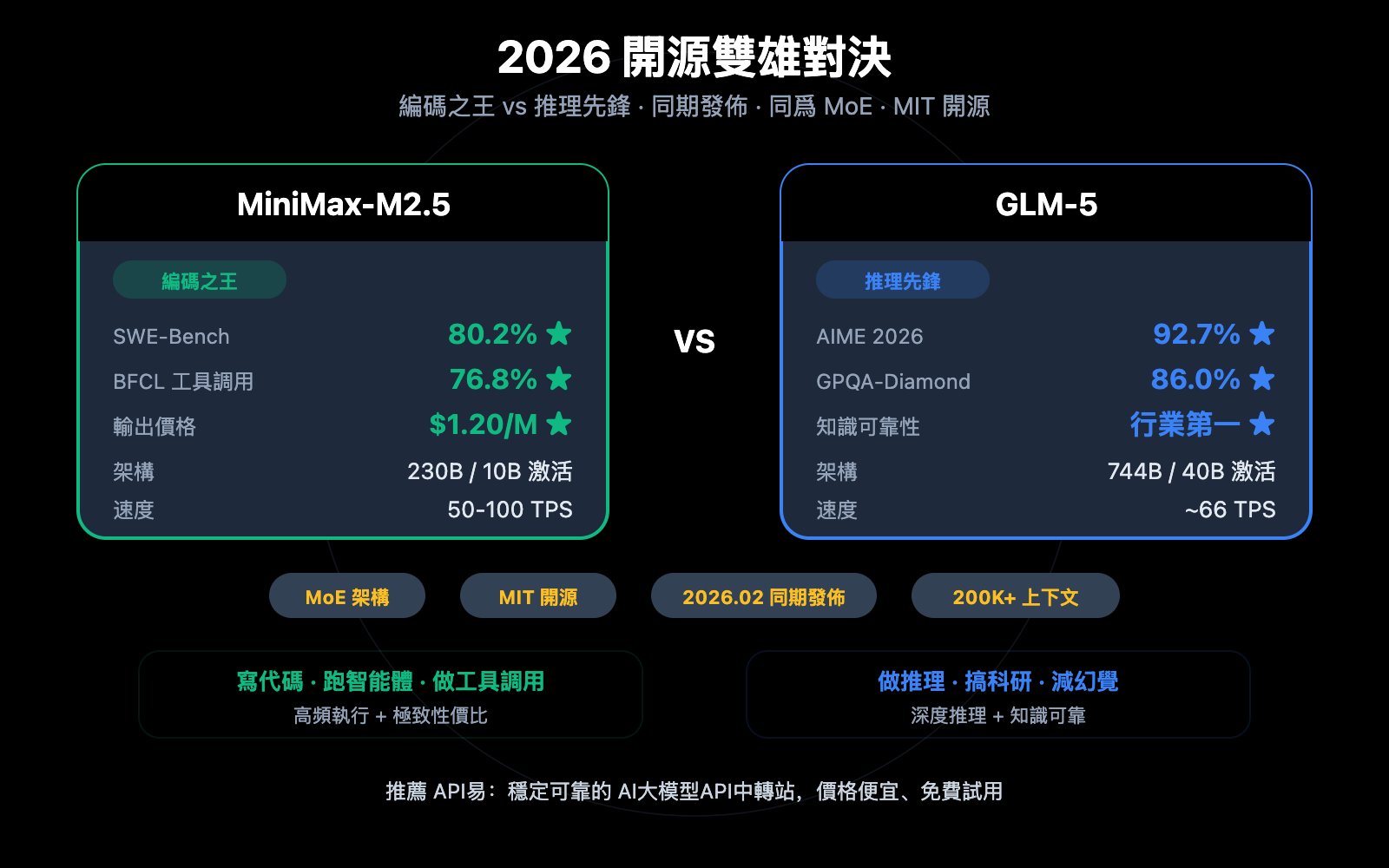
MiniMax-M2.5 與 GLM-5 核心差異總覽
| 對比維度 | MiniMax-M2.5 | GLM-5 | 優勢方 |
|---|---|---|---|
| SWE-Bench 編碼 | 80.2% | 77.8% | M2.5 領先 2.4% |
| AIME 數學推理 | — | 92.7% | GLM-5 擅長 |
| BFCL 工具調用 | 76.8% | — | M2.5 擅長 |
| BrowseComp 搜索 | 76.3% | 75.9% | 基本持平 |
| 輸出價格/M tokens | $1.20 | $3.20 | M2.5 便宜 2.7 倍 |
| 輸出速度 | 50-100 TPS | ~66 TPS | M2.5 Lightning 更快 |
| 總參數量 | 230B | 744B | GLM-5 更大 |
| 激活參數量 | 10B | 40B | M2.5 更輕量 |
MiniMax-M2.5 的核心優勢:編碼與智能體
MiniMax-M2.5 在編碼基準測試上表現突出。SWE-Bench Verified 80.2% 的得分不僅領先 GLM-5 的 77.8%,更超越了 GPT-5.2 的 80.0%,僅落後 Claude Opus 4.6 的 80.8%。在多文件協作的 Multi-SWE-Bench 中得分 51.3%,在工具調用的 BFCL Multi-Turn 中更是達到了 76.8%。
M2.5 的 MoE 架構僅激活 10B 參數(總量 230B 的 4.3%),使其成爲 Tier 1 模型中"最輕量"的選擇,推理效率極高。Lightning 版本可達 100 TPS,是當前最快的前沿模型之一。
GLM-5 的核心優勢:推理與知識可靠性
GLM-5 在推理和知識類任務上擁有顯著優勢。AIME 2026 數學推理得分 92.7%,GPQA-Diamond 科學推理 86.0%,Humanity's Last Exam(帶工具)50.4 分領先於 Claude Opus 4.5 的 43.4 分。
GLM-5 最突出的能力是知識可靠性——在 AA-Omniscience 幻覺評測中取得行業領先水平,比前代提升了 35 分。對於需要高精度事實輸出的場景,如技術文檔撰寫、學術研究輔助、知識庫構建,GLM-5 是更可靠的選擇。此外,GLM-5 的 744B 參數量和 28.5 萬億 Token 訓練數據賦予了它更深厚的知識儲備。
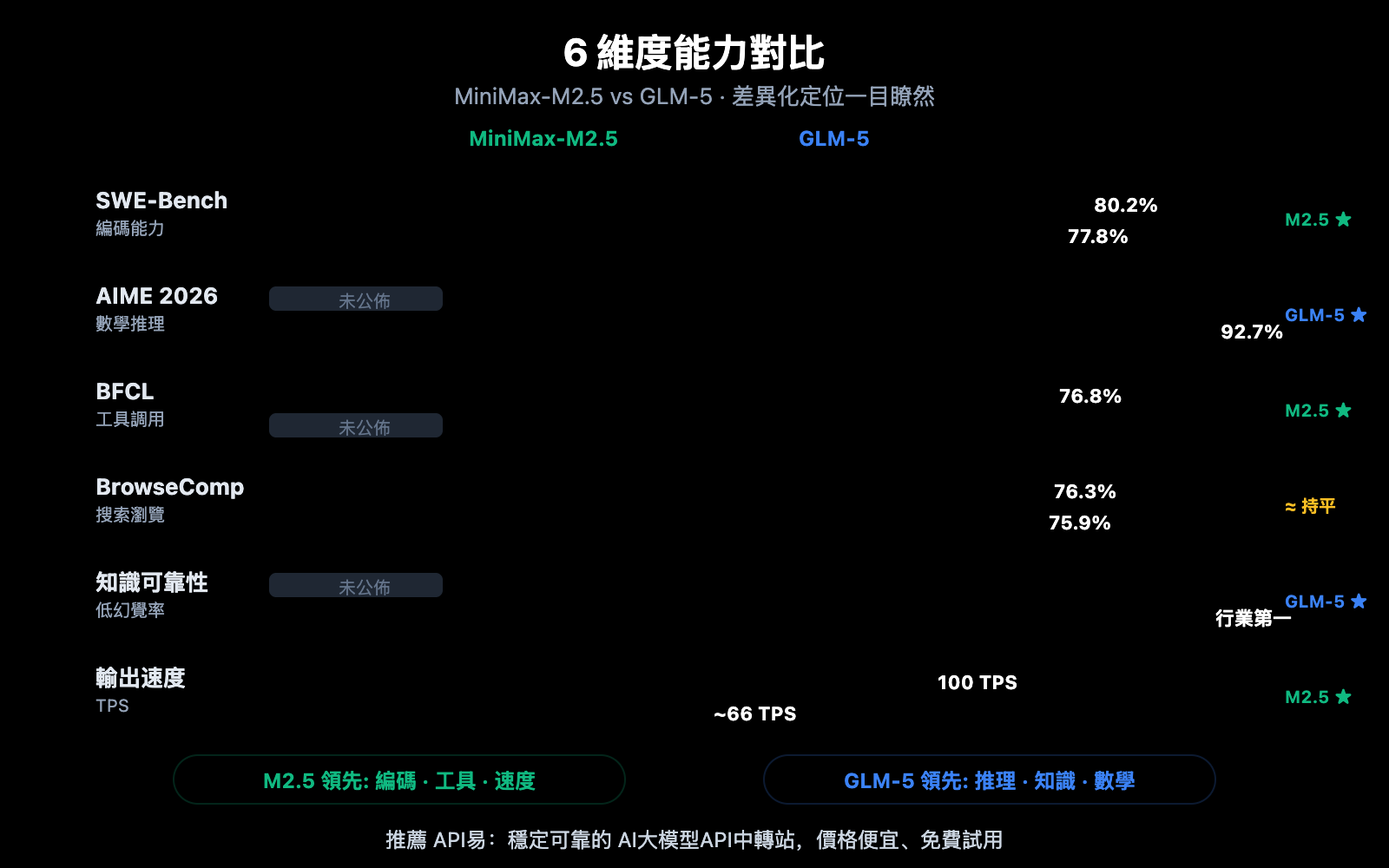
MiniMax-M2.5 對比 GLM-5 編碼能力詳細對比
編碼能力是當前開發者選擇 AI 模型時最關注的維度之一。兩個模型在這方面差距明顯。
| 編碼基準 | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (參考) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
MiniMax-M2.5 在 SWE-Bench Verified 上領先 GLM-5 達 2.4 個百分點(80.2% vs 77.8%)。這個差距在編碼基準上已經屬於顯著差異——M2.5 的編碼能力處於 Opus 4.6 級別,而 GLM-5 更接近 Gemini 3 Pro 級別。
GLM-5 在多語言編碼(SWE-Bench Multilingual 73.3%)和終端環境編碼(Terminal-Bench 56.2%)上有數據,展現了不同角度的編碼能力。但在最核心的 SWE-Bench Verified 上,M2.5 的優勢明確。
M2.5 在編碼效率上也有突出表現:完成 SWE-Bench 單任務僅需 22.8 分鐘,比前代 M2.1 提升 37%。這得益於其獨特的 "Spec-writing" 編碼風格——先進行架構分解,再高效實現,減少了無效的試錯循環。
🎯 編碼場景建議: 如果你的核心需求是 AI 輔助編碼(Bug 修復、代碼審查、功能實現),MiniMax-M2.5 是更優選擇。通過 API易 apiyi.com 可以同時接入兩個模型進行實際對比測試。
MiniMax-M2.5 對比 GLM-5 推理能力詳細對比
推理能力是 GLM-5 的核心優勢所在,尤其在數學和科學推理領域。
| 推理基準 | MiniMax-M2.5 | GLM-5 | 說明 |
|---|---|---|---|
| AIME 2026 | — | 92.7% | 奧林匹克級數學推理 |
| GPQA-Diamond | — | 86.0% | 博士級科學推理 |
| Humanity's Last Exam (w/tools) | — | 50.4 | 超越 Opus 4.5 的 43.4 |
| HMMT Nov. 2025 | — | 96.9% | 接近 GPT-5.2 的 97.1% |
| τ²-Bench | — | 89.7% | 電信領域推理 |
| AA-Omniscience 知識可靠性 | — | 行業領先 | 幻覺率最低 |
GLM-5 採用了名爲 SLIME(異步強化學習基礎設施)的新型訓練方法,大幅提升了後訓練效率。這使得 GLM-5 在推理任務上實現了質的飛躍:
- AIME 2026 得分 92.7%,接近 Claude Opus 4.5 的 93.3%,遠超 GLM-4.5 時代的水平
- GPQA-Diamond 86.0% 的博士級科學推理能力,接近 Opus 4.5 的 87.0%
- Humanity's Last Exam 50.4 分(帶工具),超越 Opus 4.5 的 43.4 分和 GPT-5.2 的 45.5 分
GLM-5 最獨特的能力是知識可靠性。在 AA-Omniscience 幻覺評測中,GLM-5 比前代提升了 35 分,達到行業領先水平。這意味着 GLM-5 在回答事實性問題時更少"編造"內容,對於需要高精度信息輸出的場景價值極大。
MiniMax-M2.5 在推理方面的數據較少公開,其核心強化學習訓練集中在編碼和智能體場景。M2.5 的 Forge RL 框架側重於 20 萬+真實環境中的任務分解和工具調用優化,而非純推理能力。
對比說明: 如果你的核心需求是數學推理、科學分析或需要高可靠性的知識問答,GLM-5 更有優勢。建議通過 API易 apiyi.com 平臺實際測試兩者在你的具體推理任務上的表現差異。
MiniMax-M2.5 對比 GLM-5 智能體與搜索能力

| 智能體基準 | MiniMax-M2.5 | GLM-5 | 優勢方 |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5 工具調用領先 |
| BrowseComp (w/context) | 76.3% | 75.9% | 基本持平 |
| MCP Atlas | — | 67.8% | GLM-5 多工具協調 |
| Vending Bench 2 | — | $4,432 | GLM-5 長期規劃 |
| τ²-Bench | — | 89.7% | GLM-5 領域推理 |
兩個模型在智能體能力上呈現明顯的差異化:
MiniMax-M2.5 擅長"執行型"智能體:在需要頻繁調用工具、快速迭代、高效執行的場景中表現出色。BFCL 76.8% 意味着 M2.5 能夠精準地進行函數調用、文件操作、API 交互等工具使用,且工具調用輪次比前代減少 20%。M2.5 在 MiniMax 內部已有 80% 的新代碼由其生成,30% 的日常任務由其完成。
GLM-5 擅長"決策型"智能體:在需要深度推理、長期規劃、複雜決策的場景中更有優勢。MCP Atlas 67.8% 展現了大規模工具協調能力,Vending Bench 2 的 $4,432 模擬收入展現了長時間段業務規劃能力,τ²-Bench 89.7% 展現了特定領域的深度推理。
兩者在網頁搜索瀏覽能力上幾乎持平——BrowseComp 76.3% vs 75.9%,都是該領域的領先者。
🎯 智能體場景建議: 高頻工具調用和自動編碼選 M2.5;複雜決策和長期規劃選 GLM-5。API易 apiyi.com 平臺同時支持兩個模型,可按場景靈活切換。
MiniMax-M2.5 對比 GLM-5 架構與成本對比
| 架構與成本 | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| 總參數量 | 230B | 744B |
| 激活參數量 | 10B | 40B |
| 激活比例 | 4.3% | 5.4% |
| 訓練數據 | — | 28.5 萬億 Token |
| 上下文窗口 | 205K | 200K |
| 最大輸出 | — | 131K |
| 輸入價格 | $0.15/M (標準版) | $1.00/M |
| 輸出價格 | $1.20/M (標準版) | $3.20/M |
| 輸出速度 | 50-100 TPS | ~66 TPS |
| 訓練芯片 | — | 華爲昇騰 910 |
| 訓練框架 | Forge RL | SLIME 異步 RL |
| 注意力機制 | — | DeepSeek Sparse Attention |
| 開源協議 | MIT | MIT |
MiniMax-M2.5 架構優勢分析
M2.5 的核心架構優勢在於"極致輕量"——僅激活 10B 參數就實現了接近 Opus 4.6 的編碼能力。這使得:
- 推理成本極低: 輸出價格 $1.20/M,僅爲 GLM-5 的 37%
- 推理速度極快: Lightning 版本 100 TPS,比 GLM-5 的 ~66 TPS 快 52%
- 部署門檻更低: 10B 激活參數在消費級 GPU 上也有部署可能性
GLM-5 架構優勢分析
GLM-5 的 744B 總參數和 40B 激活參數賦予了它更強的知識容量和推理深度:
- 更大的知識儲備: 28.5 萬億 Token 訓練數據,遠超前代
- 更深的推理能力: 40B 激活參數支持更復雜的推理鏈
- 國產算力自主: 全程使用華爲昇騰芯片訓練,實現算力獨立
- DeepSeek Sparse Attention: 高效處理 200K 長上下文
建議: 對於成本敏感的高頻調用場景,M2.5 的價格優勢明顯(輸出價格僅爲 GLM-5 的 37%)。建議通過 API易 apiyi.com 平臺實際測試兩者在你的任務上的性價比。
MiniMax-M2.5 對比 GLM-5 API 快速接入
通過 API易平臺可以統一接口同時調用兩個模型,方便快速對比:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 編碼任務測試 - M2.5 更擅長
code_task = "用 Rust 實現一個無鎖併發隊列"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 推理任務測試 - GLM-5 更擅長
reason_task = "證明所有大於 2 的偶數都可以表示爲兩個素數之和(哥德巴赫猜想的驗證思路)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
建議: 通過 API易 apiyi.com 獲取免費測試額度,針對你的具體場景分別測試兩個模型。編碼任務試 M2.5,推理任務試 GLM-5,找到最適合你的方案。
常見問題
Q1: MiniMax-M2.5 和 GLM-5 各自最擅長什麼?
MiniMax-M2.5 擅長編碼和智能體工具調用——SWE-Bench 80.2% 接近 Opus 4.6,BFCL 76.8% 行業第一。GLM-5 擅長推理和知識可靠性——AIME 92.7%、GPQA 86.0%、幻覺率行業最低。簡單記:寫代碼選 M2.5,做推理選 GLM-5。
Q2: 兩個模型價格差多少?
MiniMax-M2.5 標準版輸出價格 $1.20/M tokens,GLM-5 輸出價格 $3.20/M tokens,M2.5 便宜約 2.7 倍。如果選 M2.5 Lightning 高速版($2.40/M),則與 GLM-5 價格接近但速度更快。通過 API易 apiyi.com 平臺接入還可享受充值優惠。
Q3: 如何快速對比兩個模型的實際效果?
推薦通過 API易 apiyi.com 平臺統一接入:
- 註冊賬號獲取 API Key 和免費額度
- 準備 2 類測試任務:編碼類和推理類
- 同一任務分別調用 MiniMax-M2.5 和 GLM-5
- 對比輸出質量、響應速度和 Token 消耗
- 統一 OpenAI 兼容接口,切換模型只需改 model 參數
總結
MiniMax-M2.5 對比 GLM-5 的核心結論:
- 編碼首選 M2.5: SWE-Bench 80.2% vs 77.8%,M2.5 領先 2.4%,BFCL 工具調用 76.8% 行業第一
- 推理首選 GLM-5: AIME 92.7%、GPQA 86.0%、Humanity's Last Exam 50.4 分超越 Opus 4.5
- 知識可靠性 GLM-5 領先: AA-Omniscience 幻覺評測行業第一,事實性輸出更可信
- 性價比 M2.5 更優: 輸出價格僅爲 GLM-5 的 37%,Lightning 版本速度更快
兩個模型都是 MIT 開源、MoE 架構,但定位截然不同:M2.5 是"編碼和執行型智能體之王",GLM-5 是"推理和知識可靠性先鋒"。建議根據實際需求在 API易 apiyi.com 平臺上靈活切換使用,參與充值活動享受更優惠的價格。
📚 參考資料
-
MiniMax M2.5 官方公告: M2.5 核心編碼能力和 Forge RL 訓練細節
- 鏈接:
minimax.io/news/minimax-m25 - 說明: SWE-Bench 80.2%、BFCL 76.8% 等完整基準數據
- 鏈接:
-
GLM-5 官方發佈: 智譜 GLM-5 的 744B MoE 架構和 SLIME 訓練技術
- 鏈接:
docs.z.ai/guides/llm/glm-5 - 說明: 包含 AIME 92.7%、GPQA 86.0% 等推理基準數據
- 鏈接:
-
Artificial Analysis 獨立評測: 兩個模型的標準化基準測試和排名
- 鏈接:
artificialanalysis.ai/models/glm-5 - 說明: Intelligence Index、速度實測、價格對比等獨立數據
- 鏈接:
-
BuildFastWithAI 深度分析: GLM-5 全面基準測試和競品對比
- 鏈接:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - 說明: 與 Opus 4.5、GPT-5.2 的詳細對比表格
- 鏈接:
-
MiniMax HuggingFace: M2.5 開源模型權重
- 鏈接:
huggingface.co/MiniMaxAI - 說明: MIT 協議,支持 vLLM/SGLang 部署
- 鏈接:
作者: APIYI Team
技術交流: 歡迎在評論區分享你的模型對比測試結果,更多 AI 模型 API 接入教程可訪問 API易 apiyi.com 技術社區