作者注:從多代理架構、編碼能力、推理性能、API 定價等 7 個維度深度對比 Claude Opus 4.6 和 Grok 4.20 Beta,幫助開發者根據場景選擇最適合的 AI 模型
2026 年 2 月,AI 行業迎來了兩款重磅模型的正面碰撞——Anthropic 在 2 月 5 日發佈了 Claude Opus 4.6,xAI 緊隨其後在 2 月中旬推出了 Grok 4.20(Beta)。兩者都將"多代理協作"作爲核心賣點,但架構思路截然不同。
核心價值: 看完本文,你將明確 Claude Opus 4.6 和 Grok 4.20 Beta 在編碼、推理、實時數據、API 可用性等維度的具體差異,從而根據自己的場景做出正確選擇。

Claude Opus 4.6 vs Grok 4.20 Beta 核心差異總覽
| 對比維度 | Claude Opus 4.6 | Grok 4.20 Beta |
|---|---|---|
| 開發方 | Anthropic | xAI(Elon Musk) |
| 發佈日期 | 2026 年 2 月 5 日(正式版) | 2026 年 2 月中旬(Beta) |
| 多代理架構 | Agent Teams(Lead + Teammates) | 4 Agents(Grok/Harper/Benjamin/Lucas) |
| 上下文窗口 | 200K 標準 / 1M Beta | 256K ~ 2M tokens |
| 最大輸出 | 128K tokens | 未公佈 |
| API 定價 | $5/$25 per MTok | 尚未公佈(4.1 參考: $0.20/$0.50) |
| API 可用性 | ✅ 已全面開放 | ❌ 尚未開放 |
| 獨家數據源 | 無 | X Firehose 實時推文數據 |
Claude Opus 4.6 vs Grok 4.20 Beta 定位差異
這兩款模型雖然都主打"多代理協作",但面向的用戶羣體和解決的問題有本質區別:
Claude Opus 4.6 的 Agent Teams 是面向開發者的生產力工具。它讓多個 Claude 實例在獨立上下文中並行編碼,由 Lead Agent 統籌協調,每個 Teammate 可以獨立讀寫文件、運行測試。這是一個已經可以在實際項目中使用的成熟功能。
Grok 4.20 Beta 的 4 Agents 是面向通用問題解決的推理增強。四個具有不同專業角色的代理(研究、邏輯、創意、協調)在內部並行思考並互相驗證,最終輸出更準確的答案。目前僅限 SuperGrok 用戶在對話界面使用。
🎯 選擇建議: 如果你是開發者,需要 AI 輔助寫代碼、調試、處理大型項目,Claude Opus 4.6 是當前更成熟的選擇,通過 API易 apiyi.com 可以直接調用。如果你更關注複雜推理、實時信息分析和多角度思考,Grok 4.20 Beta 值得關注。
Claude Opus 4.6 vs Grok 4.20 Beta 多代理架構對比
兩款模型的多代理架構是最值得深入對比的核心差異。
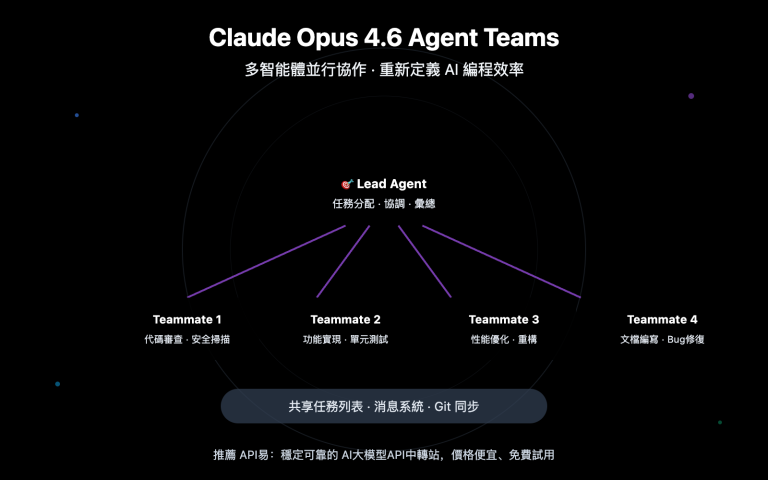
Claude Opus 4.6 Agent Teams 架構
Claude Opus 4.6 的 Agent Teams 採用顯式並行編碼模式:
| 組件 | 功能說明 | 特點 |
|---|---|---|
| Lead Agent | 主協調者 | 分配任務、綜合結果、統籌全局 |
| Teammates | 獨立工作代理 | 各自擁有完整上下文窗口 |
| 任務列表 | 共享協作狀態 | 依賴追蹤、自動解鎖 |
| 消息系統 | 代理間通信 | Teammates 可直接互發消息 |
Agent Teams 的關鍵技術特性:
- 獨立上下文: 每個 Teammate 擁有獨立的完整上下文窗口,不會相互干擾
- 文件級並行: 不同 Teammate 可以同時操作不同文件,實現真正的並行開發
- 實時協調: 通過共享任務列表和消息系統,Lead Agent 可以動態調整分工
- 規模化能力: 實測已支持 16 個 Agent 並行構建 Rust C 編譯器
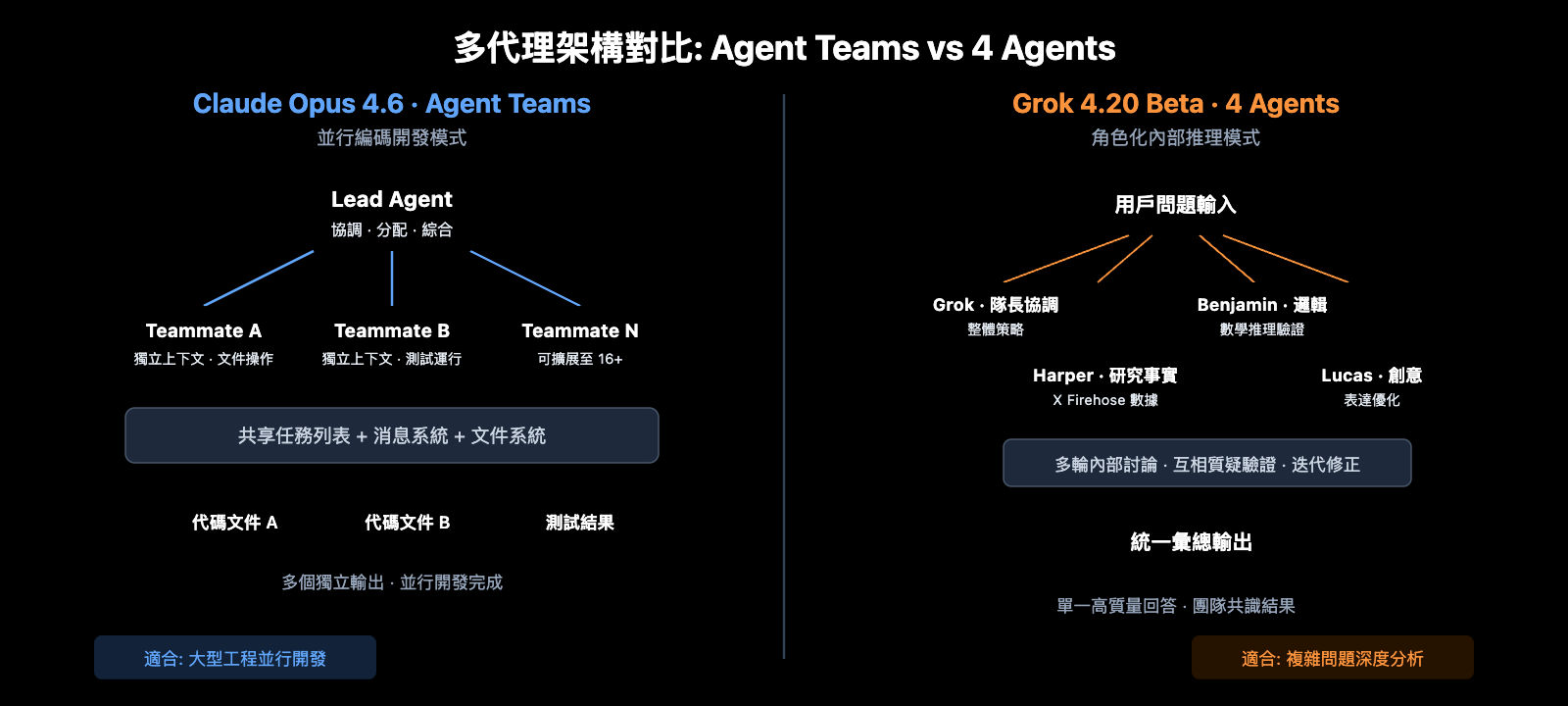
Grok 4.20 Beta 4 Agents 架構
Grok 4.20 Beta 的 4 Agents 採用角色化內部推理模式:
- Grok(隊長): 整體策略制定,最終答案合成
- Harper(研究專家): 實時搜索、資料覈查,接入 X Firehose 數據
- Benjamin(邏輯專家): 數學推理、編程驗證、精確計算
- Lucas(創意專家): 發散思維、表達優化、用戶體驗
4 Agents 的核心差異在於內部多輪討論和互評機制。Agent 之間會質疑彼此的結論,進行迭代修正,這種機制能有效降低幻覺。
Claude Opus 4.6 vs Grok 4.20 Beta 多代理架構核心區別
| 維度 | Claude Agent Teams | Grok 4 Agents |
|---|---|---|
| 協作目標 | 並行完成編碼任務 | 多角度分析同一問題 |
| 代理角色 | 功能等價(都是 Claude 實例) | 角色分化(研究/邏輯/創意/協調) |
| 工作方式 | 獨立上下文 + 共享文件系統 | 內部並行思考 + 多輪討論 |
| 可擴展性 | 可擴展至 16+ 代理 | 固定 4 個專業代理 |
| 輸出形式 | 各自獨立輸出(代碼/文件) | 統一彙總輸出(單一回答) |
| 適用場景 | 大型工程項目並行開發 | 複雜問題的深度分析 |
| 用戶可見性 | 可觀察各 Teammate 工作進度 | 僅可見最終合成輸出 |
💡 技術洞察: Claude Agent Teams 更像"一個公司的多個開發團隊並行做項目",而 Grok 4 Agents 更像"一個專家小組圍坐討論同一個難題"。兩種架構解決的是完全不同的問題。
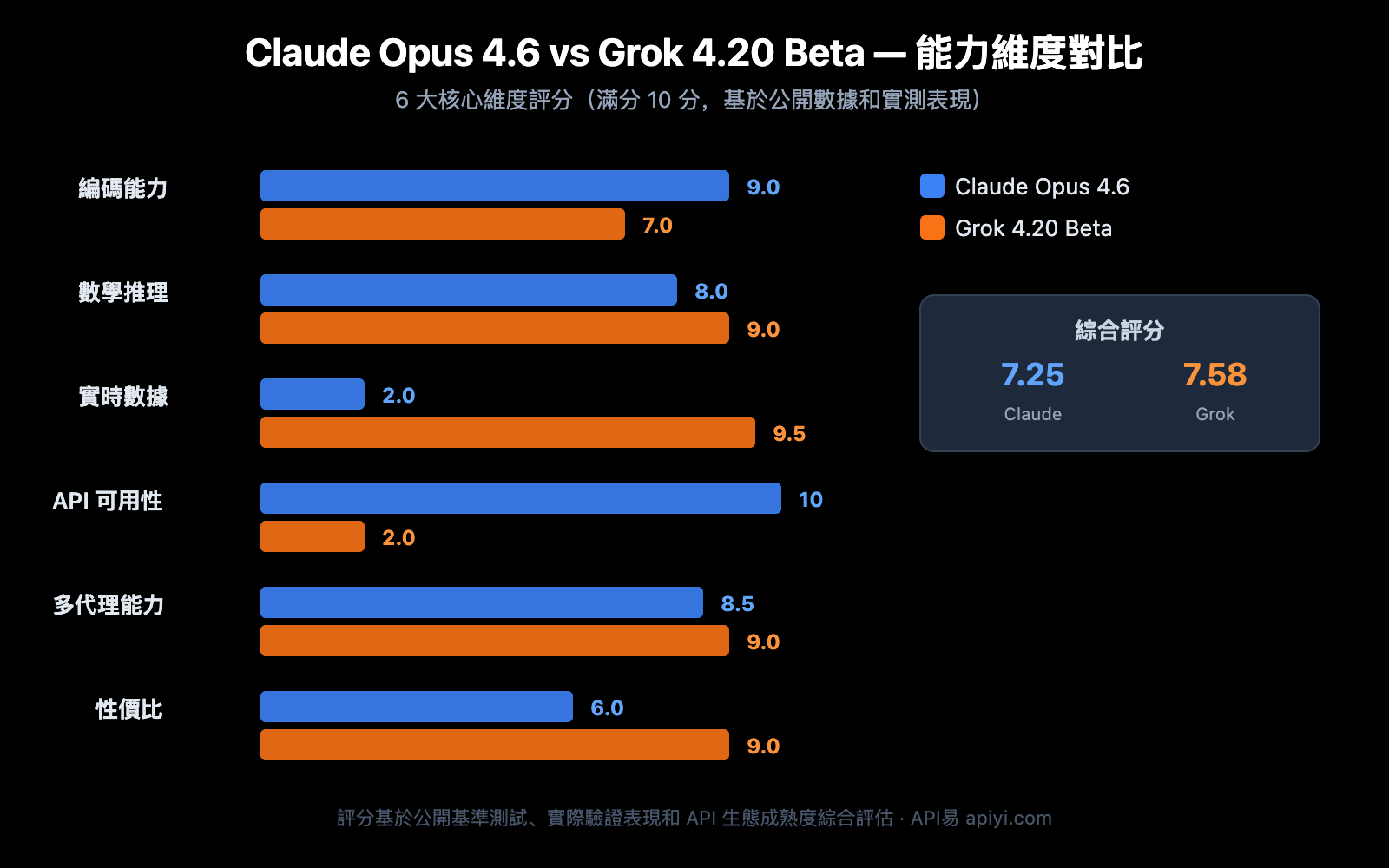
Claude Opus 4.6 vs Grok 4.20 Beta 基準性能對比
Claude Opus 4.6 已公佈的基準測試成績
Claude Opus 4.6 作爲正式發佈的模型,擁有完整的基準測試數據:
| 基準測試 | Claude Opus 4.6 | Claude Opus 4.5 | GPT-5.2 | 說明 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 65.4% | 59.8% | — | Agentic 編碼評估,行業最高 |
| ARC AGI 2 | 68.8% | 37.6% | 54.2% | 人類簡單但 AI 困難的推理 |
| GDPval-AA | +144 Elo | 基準線 | 對照組 | 經濟價值知識工作任務 |
| OSWorld | 72.7% | 66.3% | — | 計算機使用能力 |
| Humanity's Last Exam | 行業領先 | — | — | 複雜多學科推理 |
Claude Opus 4.6 在編碼領域的表現尤爲突出——在 Terminal-Bench 2.0 上取得了行業最高分,被評價爲"tasteful coder"(有品味的編碼者),特別擅長:
- 大型代碼庫的導航和理解
- 代碼審查和 Bug 檢測
- 前端開發從設計到功能實現
- 持續性 Agentic 編碼任務
Grok 4.20 Beta 已驗證的實際表現
Grok 4.20 Beta 尚無完整基準測試數據(仍在 Beta 階段),但其實際表現已在特定領域得到驗證:
- Alpha Arena 交易競賽: 所有參賽 AI 中唯一盈利(平均回報 12.11%,峯值 50%)
- 數學研究: 幫助數學家 Paata Ivanisvili 在 Bellman 函數領域取得新發現,約 5 分鐘推導出 U(p,q) 的精確公式
- 工程編碼: Elon Musk 公開認可"開始正確回答開放式工程問題"
- 實時數據處理: 依託 X Firehose 實現毫秒級市場情緒分析
Claude Opus 4.6 vs Grok 4.20 Beta API 可用性與定價
對於開發者來說,API 可用性和成本是選擇模型的關鍵因素。
Claude Opus 4.6 API 定價詳情
| 項目 | 定價 | 說明 |
|---|---|---|
| 標準輸入 | $5 / MTok | 200K 上下文內 |
| 標準輸出 | $25 / MTok | 最大 128K tokens |
| 長上下文輸入 | $10 / MTok | 超過 200K 時自動切換 |
| 長上下文輸出 | $37.50 / MTok | 1M Beta 模式 |
| Prompt Caching | 最高節省 90% | 重複提示詞緩存 |
| Batch 處理 | 節省 50% | 異步批量請求 |
| Fast 模式 | $30/$150 per MTok | 2.5 倍速度 |
Claude Opus 4.6 的 API 已經在所有主要平臺上線:claude.ai、Anthropic API、Azure、AWS Bedrock 等。
Grok 4.20 Beta API 狀態
Grok 4.20 Beta 的 API 尚未開放。參考 Grok 4.1 的定價:
- 輸入: $0.20 / MTok
- 輸出: $0.50 / MTok
如果 Grok 4.20 保持類似的定價策略,其 API 成本將顯著低於 Claude Opus 4.6。但考慮到 4 Agents 架構需要運行四個並行代理,實際定價可能會有所上浮。
💰 成本建議: Claude Opus 4.6 已通過 API易 apiyi.com 上線,開發者可以直接獲取 API Key 開始調用。平臺提供靈活計費和免費測試額度,支持 Prompt Caching 等降本功能。Grok 4.20 API 一旦開放,API易也將在第一時間接入。
Claude Opus 4.6 vs Grok 4.20 Beta 適用場景推薦
選 Claude Opus 4.6 的場景
- 專業編碼開發: Agent Teams 並行編碼是當前最強的 AI 輔助開發方案,特別適合大型項目
- 前端工程: 被評爲"tasteful coder",從設計稿到功能代碼的轉換精準度行業領先
- 代碼審查和調試: 在大型代碼庫中操作更可靠,Bug 檢測能力提升顯著
- 企業級知識工作: GDPval-AA 評估中超越 GPT-5.2(+144 Elo),適合金融、法律等領域
- 需要立即可用的 API: 已全面開放 API,支持所有主流雲平臺
選 Grok 4.20 Beta 的場景
- 實時信息分析: X Firehose 數據接入是獨家優勢,適合輿情監控、市場分析
- 金融交易策略: Alpha Arena 競賽中唯一盈利的 AI,實時數據+量化分析的最佳組合
- 數學和科學研究: 已驗證輔助前沿數學研究的能力,適合需要嚴謹推理的學術場景
- 需要多角度深度分析: 4 Agents 的內部討論機制適合複雜決策和戰略規劃
- 預算敏感場景: 參考 Grok 4.1 定價,API 成本可能遠低於 Claude Opus 4.6
Claude Opus 4.6 vs Grok 4.20 Beta 決策矩陣
| 你的需求 | 推薦選擇 | 原因 |
|---|---|---|
| 寫代碼、做項目 | Claude Opus 4.6 | Agent Teams + Terminal-Bench 最高分 |
| 實時市場分析 | Grok 4.20 Beta | X Firehose 獨家數據源 |
| 數學/科學推理 | Grok 4.20 Beta | Bellman 函數級別的驗證 |
| 企業知識工作 | Claude Opus 4.6 | GDPval-AA 行業領先 |
| 立即需要 API | Claude Opus 4.6 | 已全面開放,API易已上線 |
| 控制 API 成本 | Grok 4.20 Beta | 參考定價顯著更低 |
| 前端開發 | Claude Opus 4.6 | "Tasteful coder" 評價 |
| 複雜戰略決策 | Grok 4.20 Beta | 4 Agents 多角度分析 |
🚀 快速體驗: 想要對比兩款模型的實際表現?推薦通過 API易 apiyi.com 獲取 Claude Opus 4.6 的 API Key,先行體驗編碼和推理能力。Grok 4.20 API 上線後,也可在同一平臺快速切換對比。
常見問題
Q1: Claude Opus 4.6 的 Agent Teams 和 Grok 4.20 的 4 Agents 哪個更強?
兩者不是同類技術,無法直接比較"強弱"。Claude Agent Teams 是並行編碼工具,讓多個 AI 實例同時寫不同模塊的代碼,適合軟件開發場景。Grok 4 Agents 是推理增強機制,讓四個專業代理從不同角度分析同一問題,適合複雜決策場景。選擇取決於你的使用場景,而非絕對性能。
Q2: 現在能用 API 調用這兩個模型嗎?
Claude Opus 4.6 的 API 已全面開放,可通過 API易 apiyi.com 獲取 API Key 直接調用,支持標準 OpenAI 兼容接口。Grok 4.20 Beta 的 API 尚未開放,目前只能通過 SuperGrok 訂閱($30/月)在 grok.com 對話界面使用。API易平臺將在 Grok 4.20 API 開放後第一時間接入。
Q3: 這兩個模型的 API 成本差距大嗎?
差距非常顯著。Claude Opus 4.6 標準定價爲 $5/$25 per MTok(輸入/輸出),而 Grok 4.1 的參考定價爲 $0.20/$0.50 per MTok,Grok 的 API 成本約爲 Claude 的 2%-4%。不過,Claude 提供 Prompt Caching(最高節省 90%)和 Batch 處理(節省 50%)等降本方案,實際使用成本可以大幅降低。通過 API易 apiyi.com 平臺調用還可以獲得更靈活的計費方式。
Q4: 如果預算有限,應該優先選哪個?
如果你的核心需求是編碼開發,Claude Opus 4.6 儘管單價更高,但編碼質量和 Agent Teams 帶來的效率提升可以彌補成本差距。如果你的需求側重信息分析和推理,可以先使用 SuperGrok 訂閱($30/月不限量對話)體驗 Grok 4.20 Beta,等 API 上線後再評估切換。兩款模型最終通過 API易 apiyi.com 都可以在同一平臺管理和調用。
總結
Claude Opus 4.6 vs Grok 4.20 Beta 的核心結論:
- 多代理架構路線不同: Claude Agent Teams 做"並行開發團隊",Grok 4 Agents 做"專家討論小組"——兩者互補而非替代
- 編碼選 Claude,推理選 Grok: Claude Opus 4.6 在 Terminal-Bench 和 ARC AGI 2 上領先,Grok 4.20 在數學研究和實時分析上有獨家優勢
- API 成熟度差距明顯: Claude Opus 4.6 已全面可用,Grok 4.20 仍在 Beta,API 尚未開放
- 成本考量: Grok API 參考價格遠低於 Claude,但 Claude 的 Prompt Caching 可縮小差距
- 實時數據是 Grok 獨家護城河: X Firehose 數據在金融交易和輿情分析場景中不可替代
對於大多數開發者,建議先用 Claude Opus 4.6 滿足編碼和日常需求,同時關注 Grok 4.20 API 的上線進展,在特定場景(實時分析、數學推理)中補充使用。
推薦通過 API易 apiyi.com 統一管理 API 調用,平臺已支持 Claude Opus 4.6,Grok 4.20 上線後也將第一時間接入,方便在同一接口下快速切換和成本對比。
📚 參考資料
-
Anthropic 官方 – Claude Opus 4.6 發佈公告: 模型功能和基準測試詳情
- 鏈接:
anthropic.com/news/claude-opus-4-6 - 說明: Claude Opus 4.6 的官方發佈信息和技術細節
- 鏈接:
-
Claude API 定價文檔: 完整的 API 定價和計費規則
- 鏈接:
platform.claude.com/docs/en/about-claude/pricing - 說明: 包含標準定價、長上下文溢價、Prompt Caching 等詳細信息
- 鏈接:
-
xAI 官方發佈記錄: Grok 系列版本更新
- 鏈接:
docs.x.ai/developers/release-notes - 說明: xAI 官方的模型更新和 API 發佈記錄
- 鏈接:
-
xAI 模型定價: Grok API 官方定價
- 鏈接:
docs.x.ai/developers/models - 說明: Grok 各版本 API 的詳細定價信息
- 鏈接:
作者: APIYI Team
技術交流: 歡迎在評論區分享你對 Claude Opus 4.6 和 Grok 4.20 Beta 的使用體驗,更多模型對比和 API 接入方案可訪問 API易 apiyi.com 技術社區