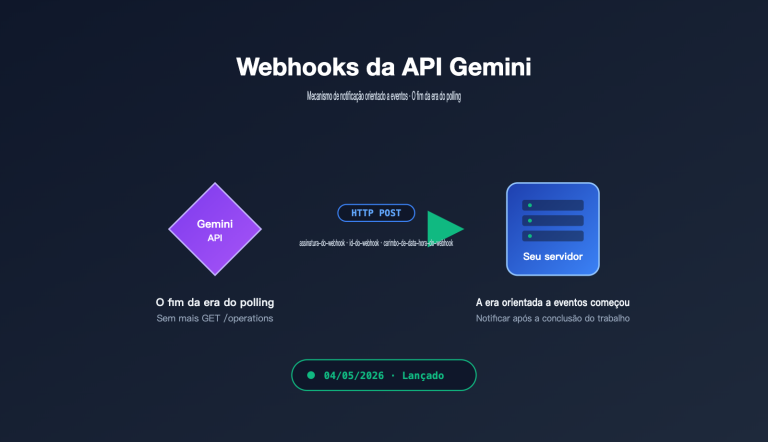
Os preços do Gemini 3.1 Pro Preview e do Gemini 3.0 Pro Preview são exatamente os mesmos — Input $2.00, Output $12.00 / milhão de tokens. Aí vem a pergunta: onde o 3.1 é realmente melhor que o 3.0? Vale a pena mudar?
A resposta é: vale muito a pena, e não há motivo algum para não mudar.
Este artigo comparará as diferenças entre as duas versões item por item usando dados de benchmark reais. Spoiler do veredito: a pontuação de raciocínio ARC-AGI-2 do 3.1 Pro saltou de 31,1% para 77,1%, um aumento de 2,5 vezes; a codificação no SWE-Bench subiu de 76,8% para 80,6%; e a pesquisa no BrowseComp saltou de 59,2% para 85,9%. Isso não é um ajuste fino, é um upgrade de geração.
Valor central: Ao terminar de ler, você entenderá claramente cada melhoria específica do 3.1 Pro em relação ao 3.0 Pro e como escolher entre eles em diferentes cenários.

Tabela Comparativa de Parâmetros: Gemini 3.1 Pro vs 3.0 Pro
Primeiro, vamos ver as diferenças nos parâmetros técnicos:
| Dimensão de Comparação | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | Mudança |
|---|---|---|---|
| ID do Modelo | gemini-3-pro-preview |
gemini-3.1-pro-preview |
Nova versão |
| Data de Lançamento | 18 de novembro de 2025 | 19 de fevereiro de 2026 | +3 meses |
| Preço Input (≤200K) | $2.00 / M tokens | $2.00 / M tokens | Inalterado |
| Preço Output (≤200K) | $12.00 / M tokens | $12.00 / M tokens | Inalterado |
| Preço Input (>200K) | $4.00 / M tokens | $4.00 / M tokens | Inalterado |
| Preço Output (>200K) | $18.00 / M tokens | $18.00 / M tokens | Inalterado |
| Janela de Contexto | 1M tokens | 1M tokens | Inalterado |
| Saída Máxima | — | 65K tokens | Melhoria clara |
| Limite de Upload | 20MB | 100MB | 5 vezes maior |
| Suporte a URL do YouTube | ❌ | ✅ | Novo |
| Níveis de Pensamento | 2 níveis (low/high) | 3 níveis (low/medium/high) | Novo nível medium |
| Endpoint customtools | ❌ | ✅ | Novo |
| Data de Corte de Conhecimento | Janeiro de 2025 | Janeiro de 2025 | Inalterado |
Preço, janela de contexto e data de corte do conhecimento permanecem exatamente os mesmos. Todas as mudanças são puros ganhos de capacidade.
🎯 Conclusão central: O preço não aumenta nem um centavo, mas as funcionalidades só aumentam. Do ponto de vista técnico, o 3.1 Pro é um substituto superior direto do 3.0 Pro. Ao usar via APIYI (apiyi.com), basta alterar o parâmetro
modeldegemini-3-pro-previewparagemini-3.1-pro-previewpara concluir o upgrade.
Diferença 1: Capacidade de Raciocínio — De "Excelente" a "Excepcional"
Esta é a maior melhoria da versão 3.0 para a 3.1, e também o ponto de atualização mais enfatizado oficialmente pelo Google.
| Benchmark de Raciocínio | 3.0 Pro | 3.1 Pro | Aumento | Descrição |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | Raciocínio em novos padrões lógicos |
| GPQA Diamond | — | 94.3% | — | Raciocínio científico de nível de pós-graduação |
| MMMLU | — | 92.6% | — | Compreensão multidisciplinar e multimodal |
| LiveCodeBench Pro | — | Elo 2887 | — | Competição de programação em tempo real |
O salto no ARC-AGI-2 é o mais impressionante: de 31,1% para 77,1%, não é apenas o dobro, mas sim 2,5 vezes mais. Este benchmark avalia a capacidade do modelo de resolver novos padrões lógicos — ou seja, tipos de problemas de raciocínio que o modelo nunca viu antes. A pontuação de 77,1% também supera os 68,8% do Claude Opus 4.6, estabelecendo uma posição de liderança na dimensão de raciocínio.
O motivo técnico por trás disso: O Google descreve oficialmente o 3.1 Pro como possuindo "unprecedented depth and nuance" (profundidade e nuances sem precedentes), enquanto a descrição do 3.0 Pro era "advanced intelligence" (inteligência avançada). Isso não é apenas uma mudança no marketing; os dados do ARC-AGI-2 provam que houve um salto qualitativo na profundidade do raciocínio.
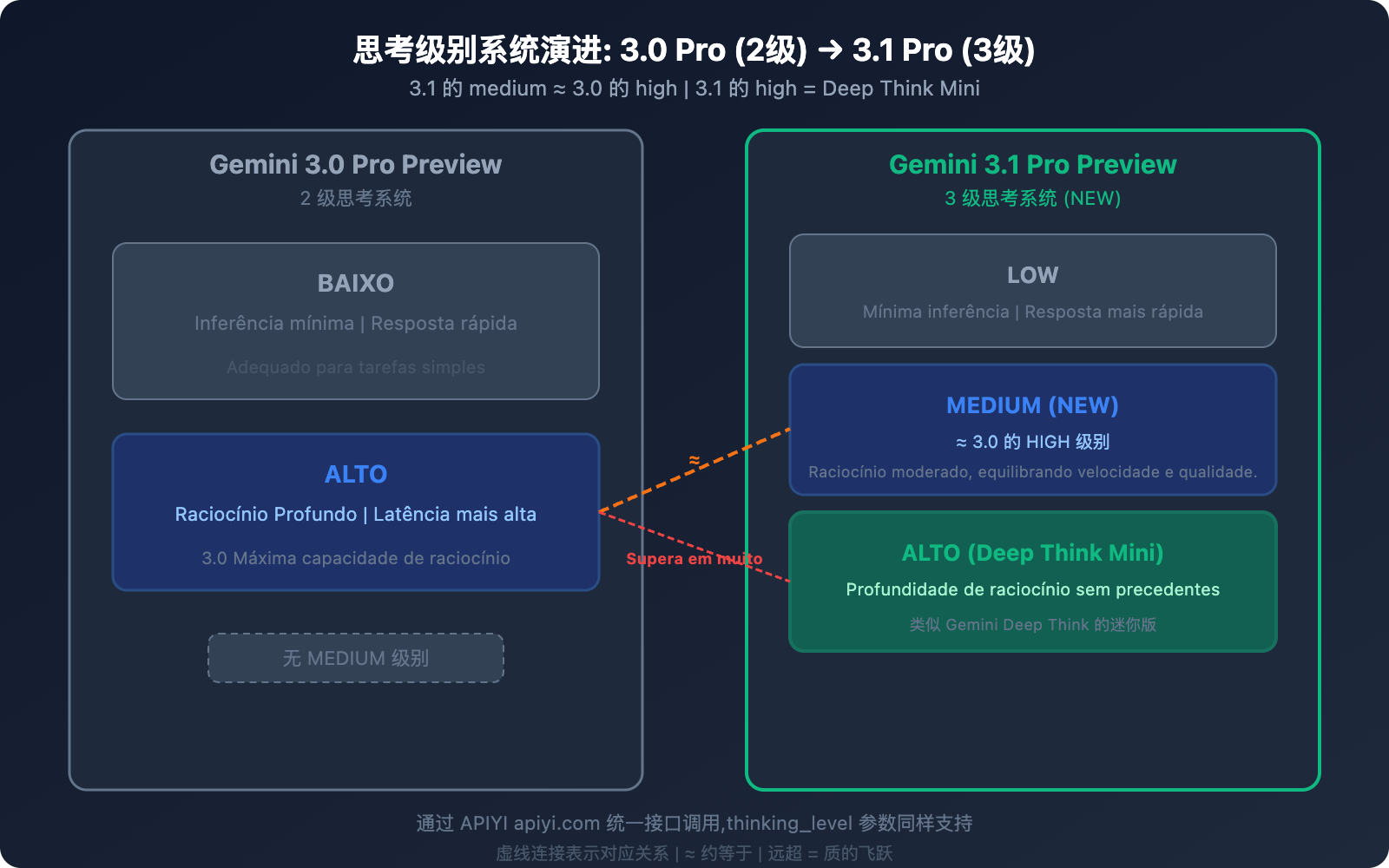
Diferença 2: Sistema de Níveis de Pensamento — De 2 para 3 níveis
Esta é uma das melhorias mais práticas do 3.1 Pro para o uso no dia a dia.
Sistema de Pensamento do 3.0 Pro (2 níveis)
| Nível | Comportamento |
|---|---|
| low | Raciocínio mínimo, resposta rápida |
| high | Raciocínio profundo, maior latência |
Sistema de Pensamento do 3.1 Pro (3 níveis)
| Nível | Comportamento | Relação de Equivalência |
|---|---|---|
| low | Raciocínio mínimo, resposta rápida | Semelhante ao "low" do 3.0 |
| medium (Novo) | Raciocínio moderado, equilíbrio entre velocidade e qualidade | ≈ "high" do 3.0 |
| high | Modo Deep Think Mini, raciocínio mais profundo | Muito superior ao "high" do 3.0 |
Informação crucial: O nível "medium" do 3.1 Pro ≈ "high" do 3.0 Pro. Isso significa que:
- Usando o "medium" do 3.1, você obtém a mesma qualidade de raciocínio do nível mais alto do 3.0.
- O "high" do 3.1 é um patamar totalmente novo — semelhante a uma versão "mini" do Gemini Deep Think.
- Para a mesma qualidade de raciocínio (medium), a latência é menor do que no "high" do 3.0.
💡 Dica Prática: Se você usava constantemente o modo "high" do 3.0 Pro, ao mudar para o 3.1 Pro, sugerimos começar pelo nível "medium" — a qualidade de raciocínio é equivalente, mas a latência é menor. Mude para o "high" (Deep Think Mini) apenas quando encontrar tarefas de raciocínio realmente complexas. Assim, você terá uma experiência geral melhor sem aumentar os custos. A plataforma APIYI (apiyi.com) suporta o envio do parâmetro
thinking_level.
Diferença 3: Capacidade de codificação — Entrando no primeiro escalão
| Benchmark de Codificação | 3.0 Pro | 3.1 Pro | Melhoria | Comparação com a Indústria |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | Codificação de terminal para Agent |
| LiveCodeBench Pro | — | Elo 2887 | — | Competição de programação em tempo real |
A melhoria no SWE-Bench Verified pode parecer de apenas 3,8 pontos percentuais (76,8% → 80,6%) à primeira vista, mas, nessa faixa de pontuação, cada 1% de evolução é extremamente difícil. O resultado de 80,6% faz com que a distância entre o Gemini 3.1 Pro e o Claude Opus 4.6 (80,9%) diminua para apenas 0,3% — passando de "líder do segundo escalão" para "lado a lado com o primeiro escalão".
A evolução no Terminal-Bench 2.0 é ainda mais notável: de 56,9% para 68,5%, um aumento de 20,4%. Este benchmark avalia especificamente a capacidade do Agent de executar tarefas de codificação em ambientes de terminal. Esse salto de 11,6 pontos percentuais significa que a confiabilidade do 3.1 Pro em cenários de programação automatizada foi drasticamente reforçada.
Diferença 4: Capacidades de Agent e busca — Um salto gigantesco
| Benchmark de Agent | 3.0 Pro | 3.1 Pro | Magnitude da melhoria |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
Estes dois itens representam os benchmarks com maior evolução na transição do 3.0 para o 3.1:
BrowseComp avalia a capacidade de busca na web do Agent — saltou de 59,2% para 85,9%, um aumento de 26,7 pontos percentuais. Isso tem um significado enorme para quem está construindo assistentes de pesquisa, ferramentas de análise competitiva ou Agents de recuperação de informações em tempo real.
MCP Atlas mede a capacidade de fluxos de trabalho multietapas usando o Model Context Protocol — subiu de 54,1% para 69,2%. O MCP é o padrão de protocolo para Agents impulsionado pelo Google, e essa melhoria mostra que a capacidade de coordenação e execução do 3.1 Pro em fluxos de trabalho complexos de Agents foi significativamente aprimorada.
Endpoint dedicado customtools: O 3.1 Pro também introduziu o endpoint dedicado gemini-3.1-pro-preview-customtools, otimizado especificamente para cenários de chamadas mistas entre comandos bash e funções personalizadas. Esse endpoint ajustou a prioridade de chamada para ferramentas comuns entre desenvolvedores, como view_file e search_code, sendo mais estável e confiável do que o endpoint geral em cenários de Agents como operações automatizadas (AIOps) e assistentes de programação de IA.
🎯 Atenção, desenvolvedores de Agents: Se você está construindo bots de revisão de código, Agents de implantação automatizada ou ferramentas semelhantes, recomendamos fortemente o uso do endpoint customtools. Você pode chamar este endpoint diretamente através do APIYI (apiyi.com), basta preencher o parâmetro
modelcomogemini-3.1-pro-preview-customtools.
Diferença 5: Capacidade de Saída e Recursos de API
| Característica | 3.0 Pro | 3.1 Pro | Mudança |
|---|---|---|---|
| Tokens máximos de saída | Não especificado | 65.000 | Claramente marcado como 65K |
| Limite de upload de arquivos | 20MB | 100MB | Aumento de 5 vezes |
| URL do YouTube | ❌ Não suportado | ✅ Envio direto | Novo |
| Endpoint customtools | ❌ | ✅ | Novo |
| Eficiência de saída | Base | +15% | Menos tokens, melhores resultados |
Limite de saída de 65K: Permite gerar documentos longos, grandes blocos de código ou relatórios de análise detalhados de uma só vez, sem a necessidade de dividir em várias requisições e depois juntar as partes.
Upload de arquivos de 100MB: A expansão de 20MB para 100MB significa que você pode fazer upload direto de repositórios de código maiores, conjuntos de documentos PDF ou arquivos de mídia para análise.
Envio direto de URL do YouTube: Ao inserir um link do YouTube diretamente no prompt, o modelo analisa automaticamente o conteúdo do vídeo — sem que você precise baixar, converter ou fazer o upload manualmente.
Aumento de 15% na eficiência de saída: Feedback real do Diretor de IA da JetBrains — o 3.1 Pro entrega resultados mais confiáveis usando menos tokens. Isso significa que, para a mesma tarefa, o consumo real de tokens é menor, resultando em um custo-benefício melhor.
Valor de cada recurso para diferentes usuários
| Recurso | Valor para Desenvolvedores | Valor para Equipes Corporativas |
|---|---|---|
| Saída de 65K | Gera arquivos de código completos de uma vez | Geração em massa de documentos técnicos e relatórios |
| Upload de 100MB | Upload de projetos inteiros para análise | Auditoria de grandes repositórios de código |
| URL do YouTube | Análise rápida de vídeos de tutoriais | Análise de demonstrações de produtos concorrentes |
| customtools | Desenvolvimento de assistentes de programação com IA | Agentes de automação de operações (Ops) |
| Eficiência +15% | Redução nos custos de chamadas individuais | Otimização significativa de custos em cenários de larga escala |
💰 Teste de custo: Em tarefas idênticas, o consumo real de tokens de saída do 3.1 Pro é, em média, 10-15% menor que o do 3.0 Pro. Para aplicações corporativas com milhões de tokens diários, a mudança pode economizar centenas de dólares por mês. Você pode comparar isso com precisão através das estatísticas de uso do APIYI (apiyi.com).
Diferença 6: Eficiência de Saída — Melhores resultados com menos tokens
Esta é uma melhoria que costuma passar despercebida, mas que tem um grande impacto prático. Segundo Vladislav Tankov, Diretor de IA da JetBrains: o 3.1 Pro apresenta uma melhoria de 15% na qualidade, consumindo menos tokens de saída em comparação ao 3.0 Pro.
O que isso significa na prática?
Custo de uso real menor: Embora o preço unitário seja o mesmo, o 3.1 Pro gasta menos tokens para concluir a mesma tarefa, o que reduz o valor final da fatura. Imagine uma aplicação que consome 1 milhão de tokens de saída por dia; um aumento de 15% na eficiência economiza cerca de US$ 1,80 por dia em taxas de saída.
Velocidade de resposta mais rápida: Menos tokens de saída significam um tempo de geração menor. Em aplicações em tempo real sensíveis à latência, esse ganho é valioso.
Qualidade de saída mais refinada: O 3.1 Pro não está simplesmente "falando menos", mas sim "sendo mais preciso" — transmitindo a mesma quantidade de informação (ou até mais) com uma linguagem mais compacta, reduzindo redundâncias e "enchente de linguiça".
Diferença 7: Segurança e Confiabilidade
| Dimensão de Segurança | 3.0 Pro | 3.1 Pro | Mudança |
|---|---|---|---|
| Segurança de texto | Referência | +0.10% | Pequena melhoria |
| Segurança multilíngue | Referência | +0.11% | Pequena melhoria |
| Taxa de recusa indevida | Referência | Mantém nível baixo | Inalterado |
| Estabilidade em tarefas longas | Referência | Melhoria | Mais confiável |
Embora o aumento na segurança não seja numericamente expressivo, a direção está correta — as capacidades foram aprimoradas sem sacrificar a segurança. A melhoria na estabilidade de tarefas longas é especialmente importante para aplicações de Agentes, o que significa que, em fluxos de trabalho de várias etapas, o 3.1 Pro tem menos chances de "se perder" ou gerar saídas não confiáveis.
Diferença 8: Mudanças na Descrição do Posicionamento Oficial
| Dimensão | Descrição do 3.0 Pro | Descrição do 3.1 Pro |
|---|---|---|
| Posicionamento central | advanced intelligence | unprecedented depth and nuance |
| Características de raciocínio | advanced reasoning | SOTA reasoning |
| Características de codificação | agentic and vibe coding | powerful coding |
| Multimodalidade | multimodal understanding | powerful multimodal understanding |
De "advanced" para "unprecedented", de "agentic and vibe coding" para "powerful coding" — a mudança no vocabulário reflete o upgrade no posicionamento. O 3.0 Pro enfatizava o "avançado" e a "inovação" (vibe coding), enquanto o 3.1 Pro foca na "profundidade" e no "poder".
Diferença 9: Sugestões de uso — quando usar cada um

Exemplo de código de migração
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
# 3.0 Pro → 3.1 Pro: mude apenas um parâmetro
# Versão antiga: model="gemini-3-pro-preview"
# Versão nova: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Único lugar que precisa ser alterado
messages=[{"role": "user", "content": "Analise os gargalos de desempenho deste código"}]
)
Ver código de teste comparativo A/B
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
test_prompt = "Dado o array [3,1,4,1,5,9,2,6], use merge sort e analise a complexidade de tempo"
# Testando 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# Testando 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\nResposta 3.0:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\nResposta 3.1:\n{resp_31.choices[0].message.content[:300]}...")
Notas de migração e melhores práticas
Passo 1: Testar cenários principais
Compare a saída do 3.0 e do 3.1 nos seus 3 a 5 comandos mais usados. Foque na qualidade do raciocínio, precisão do código e formato de saída.
Passo 2: Ajustar o nível de pensamento
Se você usava o modo high no 3.0, ao mudar para o 3.1, sugerimos começar com o medium (qualidade de raciocínio equivalente, mas mais rápido). Use o high (Deep Think Mini) apenas quando realmente precisar de raciocínio profundo.
Passo 3: Explorar novas capacidades
Experimente funções exclusivas do 3.1, como upload de arquivos de 100MB, análise de URLs do YouTube e saídas longas de 65K, para descobrir novos cenários de aplicação.
Passo 4: Migração total
Após confirmar os resultados, altere todas as chamadas de gemini-3-pro-preview para gemini-3.1-pro-preview. Recomendamos manter o 3.0 como fallback até que o 3.1 esteja rodando de forma estável no seu cenário por pelo menos uma semana.
🚀 Migração Rápida: Através da plataforma APIYI (apiyi.com), a migração do 3.0 para o 3.1 requer apenas a mudança de um parâmetro. Sugerimos rodar alguns testes A/B em cenários críticos para confirmar o efeito antes de fazer a troca total.
Perguntas Frequentes (FAQ)
Q1: O 3.1 Pro e o 3.0 Pro são totalmente compatíveis? Preciso mudar o comando após a troca?
A interface da API é totalmente compatível, basta alterar o parâmetro model. No entanto, como o método de raciocínio do 3.1 Pro foi aprimorado, alguns comandos cuidadosamente ajustados podem se comportar de forma ligeiramente diferente no 3.1 — geralmente melhor, mas recomendamos fazer testes de regressão em cenários principais. Através do APIYI (apiyi.com), você pode chamar as duas versões simultaneamente para comparação.
Q2: O 3.0 Pro continuará sendo mantido? Quando será desativado?
Como um modelo Preview, o Google costuma avisar sobre a desativação com pelo menos 2 semanas de antecedência. Atualmente, o 3.0 Pro ainda está disponível, mas considerando que o 3.1 Pro é um substituto superior em todas as dimensões, recomendamos migrar o quanto antes. As chamadas via APIYI (apiyi.com) não são afetadas por ajustes de versão do lado do Google, pois a plataforma gerencia o roteamento do modelo automaticamente.
Q3: O consumo de tokens do modo de pensamento “high” do 3.1 Pro é alto?
O modo high (Deep Think Mini) de fato consome mais tokens de saída, pois o modelo realiza uma cadeia de raciocínio interna mais profunda. Sugerimos usar o medium (equivalente à qualidade high do 3.0) para tarefas diárias e reservar o high para cenários como raciocínio matemático e depuração complexa. Assim, você mantém ou até reduz os custos na maioria das tarefas.
Q4: Ambas as versões podem ser usadas no APIYI?
Sim. O APIYI (apiyi.com) suporta tanto o gemini-3-pro-preview quanto o gemini-3.1-pro-preview, usando a mesma API Key e base_url, facilitando testes comparativos A/B e trocas flexíveis.
Sugestões de upgrade do Gemini 3.1 Pro para diferentes perfis de usuário
Diferentes tipos de desenvolvedores obtêm benefícios variados no upgrade da versão 3.0 para a 3.1. Confira as recomendações específicas:
| Tipo de Usuário | Diferencial mais benéfico | Prioridade de upgrade | Ação recomendada |
|---|---|---|---|
| Desenvolvedores de AI Agents | Agent/Busca +45%, MCP Atlas +28% | ⭐⭐⭐⭐⭐ | Troque agora, a melhoria é muito nítida |
| Ferramentas de auxílio de código | SWE-Bench +5%, Terminal-Bench +20% | ⭐⭐⭐⭐ | Recomendado, basta usar o modo medium |
| Analistas de dados | Raciocínio ARC-AGI-2 +148%, upload de 100MB | ⭐⭐⭐⭐⭐ | Prioridade total, capacidade de análise de arquivos grandes muito superior |
| Criadores de conteúdo | Saída longa de 65K, análise de URL do YouTube | ⭐⭐⭐⭐ | Recomendado, novas funcionalidades úteis |
| Usuários de API leve | Eficiência de saída +15%, custo inalterado | ⭐⭐⭐ | Troque quando puder, melhor desempenho pelo mesmo preço |
| Aplicações sensíveis à segurança | Melhoria na segurança e confiabilidade, estabilidade em tarefas longas | ⭐⭐⭐⭐ | Faça testes de regressão antes de migrar |
💡 Sugestão geral: Independentemente do seu perfil, você pode usar a APIYI (apiyi.com) para manter as versões 3.0 e 3.1 simultaneamente. Faça testes A/B para confirmar os resultados antes da migração total. Custo zero de migração, risco zero.
Fluxo de decisão para migração do Gemini 3.1 Pro
Siga estes passos para decidir se deve migrar:
- Sua aplicação depende da precisão do raciocínio? → Sim → Troque agora (melhoria de 148% no ARC-AGI-2)
- Sua aplicação envolve Agents ou busca? → Sim → Altamente recomendado (BrowseComp +45%)
- Seus comandos (prompts) são altamente personalizados? → Sim → Teste primeiro no modo medium, confirme a consistência e depois migre
- Você faz apenas perguntas e respostas simples ou tradução? → Sim → Pode trocar a qualquer momento, o resultado será no mínimo igual, mas com mais eficiência
- Não tem certeza? → Faça um teste A/B com seus 5 principais comandos na APIYI (apiyi.com). Você terá a resposta em 10 minutos.
Resumo: 9 Diferenças Principais
| # | Dimensão da Diferença | 3.0 Pro → 3.1 Pro | Valor da Migração |
|---|---|---|---|
| 1 | Capacidade de raciocínio | ARC-AGI-2: 31.1% → 77.1% | Altíssimo |
| 2 | Sistema de pensamento | Nível 2 → Nível 3 (incluindo Deep Think Mini) | Alto |
| 3 | Capacidade de codificação | SWE-Bench: 76.8% → 80.6% | Alto |
| 4 | Agent/Busca | BrowseComp: 59.2% → 85.9% | Altíssimo |
| 5 | Recursos de Saída/API | Saída de 65K, upload de 100MB, URL do YouTube | Alto |
| 6 | Eficiência de saída | Melhores resultados com menos tokens (+15%) | Alto |
| 7 | Segurança e Confiabilidade | Pequena melhoria na segurança, maior estabilidade em tarefas longas | Médio |
| 8 | Posicionamento oficial | advanced → unprecedented depth | Sinal de mercado |
| 9 | Cenários aplicáveis | Quase todos os cenários devem migrar | Claro |
Resumo em uma frase: Mesmo preço, API compatível e melhor em todos os indicadores — o Gemini 3.1 Pro Preview é um upgrade gratuito de geração em relação ao 3.0 Pro Preview. Não há motivo para não migrar.
Recomendamos realizar a migração rapidamente via APIYI (apiyi.com), basta alterar o parâmetro do modelo.
Referências
-
Blog Oficial do Google: Anúncio de lançamento do Gemini 3.1 Pro
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descrição: Resultados oficiais de benchmarks e apresentação de funcionalidades
- Link:
-
Model Card do Google DeepMind: Detalhes técnicos e avaliação de segurança do 3.1 Pro
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Descrição: Dados de segurança e parâmetros detalhados
- Link:
-
Primeiros testes da VentureBeat: Experiência aprofundada com os recursos do Deep Think Mini
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descrição: Relatório de experiência prática sobre o sistema de pensamento de três níveis
- Link:
-
Artificial Analysis: Dados comparativos entre 3.1 Pro e 3.0 Pro
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - Descrição: Comparação de benchmarks de terceiros e análise de desempenho
- Link:
📝 Autor: Equipe APIYI | Para troca de conhecimentos técnicos, visite APIYI apiyi.com
📅 Data de atualização: 20 de fevereiro de 2026
🏷️ Palavras-chave: Gemini 3.1 Pro vs 3.0 Pro, comparação de modelos, raciocínio dobrado, SWE-Bench, ARC-AGI-2, Deep Think Mini