Nota do autor: Uma comparação profunda entre os modelos de código aberto MiniMax-M2.5 e GLM-5, lançados simultaneamente em fevereiro de 2026, analisando suas especialidades em 6 dimensões: codificação, raciocínio, agentes, velocidade, preço e arquitetura.
Em 11 e 12 de fevereiro de 2026, duas grandes empresas chinesas de IA lançaram quase simultaneamente seus modelos principais: Zhipu GLM-5 (744B parâmetros) e MiniMax-M2.5 (230B parâmetros). Ambos utilizam a arquitetura MoE e a licença de código aberto MIT, mas apresentam posicionamentos bem distintos em termos de capacidades.
Valor central: Ao terminar este artigo, você entenderá claramente que o GLM-5 se destaca em raciocínio e confiabilidade de conhecimento, enquanto o MiniMax-M2.5 brilha em codificação e chamadas de ferramentas para agentes, permitindo que você faça a escolha ideal para cada cenário específico.

Visão Geral das Diferenças entre MiniMax-M2.5 e GLM-5
| Dimensão de Comparação | MiniMax-M2.5 | GLM-5 | Vantagem |
|---|---|---|---|
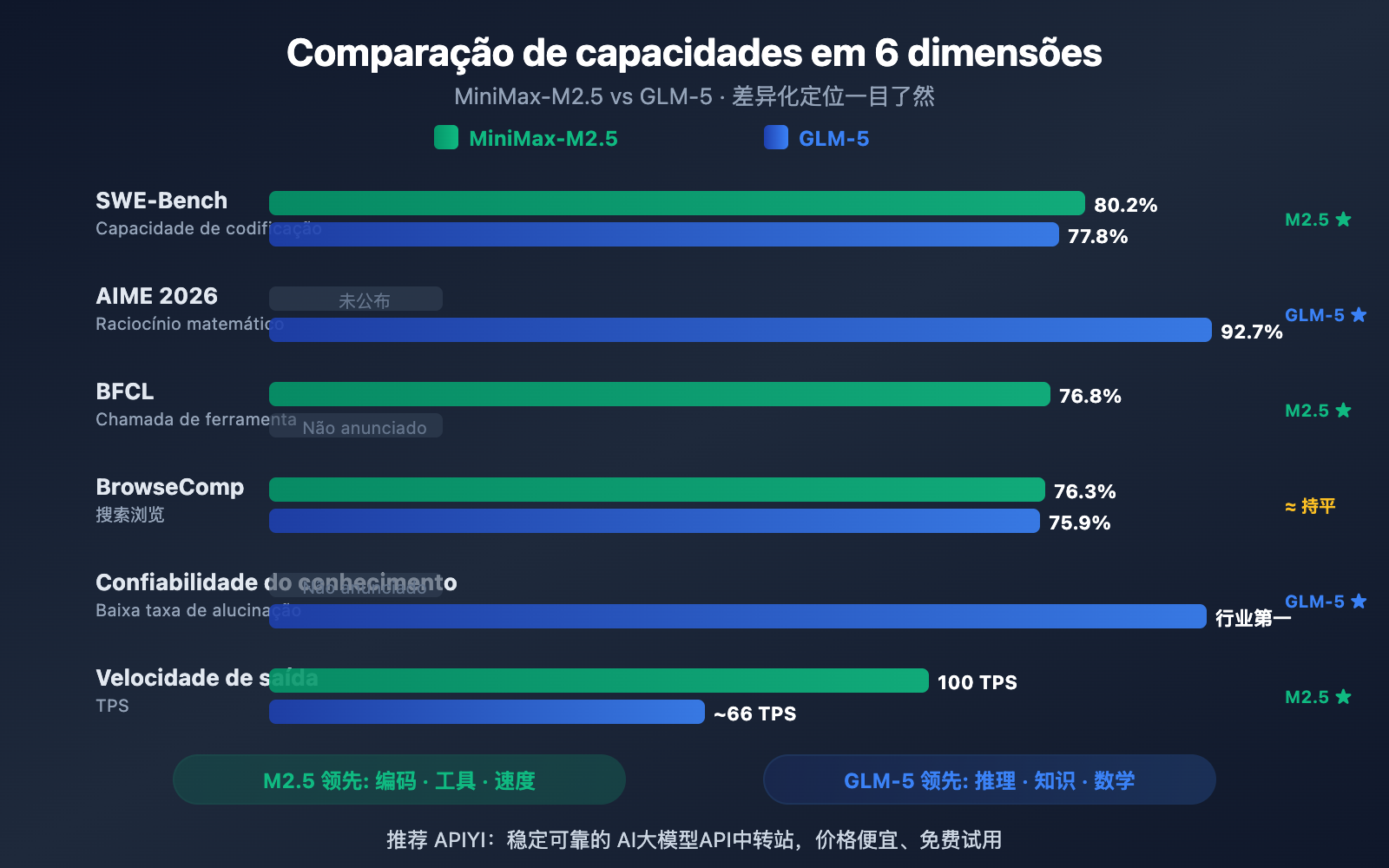
| Codificação SWE-Bench | 80.2% | 77.8% | M2.5 lidera por 2.4% |
| Raciocínio Matemático AIME | — | 92.7% | GLM-5 é excelente |
| Chamada de Ferramentas BFCL | 76.8% | — | M2.5 é excelente |
| Busca BrowseComp | 76.3% | 75.9% | Praticamente igual |
| Preço de Saída/M tokens | $1.20 | $3.20 | M2.5 é 2.7x mais barato |
| Velocidade de Saída | 50-100 TPS | ~66 TPS | M2.5 Lightning é mais rápido |
| Parâmetros Totais | 230B | 744B | GLM-5 é maior |
| Parâmetros Ativados | 10B | 40B | M2.5 é mais leve |
Vantagens Principais do MiniMax-M2.5: Codificação e Agentes
O MiniMax-M2.5 apresenta um desempenho de destaque em benchmarks de codificação. Sua pontuação de 80.2% no SWE-Bench Verified não apenas supera os 77.8% do GLM-5, mas também ultrapassa os 80.0% do GPT-5.2, ficando logo atrás dos 80.8% do Claude Opus 4.6. No Multi-SWE-Bench, que exige colaboração em múltiplos arquivos, ele atingiu 51.3%, e chegou a impressionantes 76.8% no BFCL Multi-Turn para chamadas de ferramentas.
A arquitetura MoE do M2.5 ativa apenas 10B de parâmetros (4.3% do total de 230B), o que o torna a opção "mais leve" entre os modelos de Tier 1, com uma eficiência de inferência altíssima. A versão Lightning pode alcançar 100 TPS, sendo um dos modelos de ponta mais rápidos da atualidade.
Vantagens Principais do GLM-5: Raciocínio e Confiabilidade de Conhecimento
O GLM-5 possui vantagens significativas em tarefas de raciocínio e conhecimento. No raciocínio matemático AIME 2026, ele obteve 92.7%; no raciocínio científico GPQA-Diamond, 86.0%; e no Humanity's Last Exam (com ferramentas), marcou 50.4 pontos, superando os 43.4 do Claude Opus 4.5.
A capacidade mais marcante do GLM-5 é a confiabilidade do conhecimento — ele atingiu um nível de liderança na indústria na avaliação de alucinação AA-Omniscience, uma melhoria de 35 pontos em relação à geração anterior. Para cenários que exigem saídas de fatos com alta precisão, como redação de documentos técnicos, auxílio em pesquisa acadêmica e construção de bases de conhecimento, o GLM-5 é a escolha mais confiável. Além disso, seus 744B de parâmetros e o treinamento em 28,5 trilhões de tokens conferem a ele uma reserva de conhecimento muito mais profunda.
Comparação detalhada da capacidade de codificação: MiniMax-M2.5 vs GLM-5
A capacidade de codificação é um dos critérios que os desenvolvedores mais levam em conta ao escolher um modelo de IA hoje em dia. E, nesse aspecto, a diferença entre os dois modelos é bem nítida.
| Benchmark de Codificação | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (Ref.) |
|---|---|---|---|
| SWE-Bench Verified | 80,2% | 77,8% | 80,8% |
| Multi-SWE-Bench | 51,3% | — | 50,3% |
| SWE-Bench Multilingual | — | 73,3% | 77,5% |
| Terminal-Bench 2.0 | — | 56,2% | 65,4% |
| BFCL Multi-Turn | 76,8% | — | 63,3% |
O MiniMax-M2.5 supera o GLM-5 no SWE-Bench Verified por 2,4 pontos percentuais (80,2% vs 77,8%). Em benchmarks de codificação, essa já é considerada uma diferença significativa — o desempenho do M2.5 está no nível do Opus 4.6, enquanto o GLM-5 se aproxima mais do nível do Gemini 3 Pro.
O GLM-5 apresenta dados interessantes em codificação multilíngue (SWE-Bench Multilingual 73,3%) e em ambientes de terminal (Terminal-Bench 56,2%), mostrando versatilidade. No entanto, no SWE-Bench Verified, que é o teste mais crucial, a vantagem do M2.5 é clara.
O M2.5 também se destaca na eficiência: ele resolve uma tarefa única no SWE-Bench em apenas 22,8 minutos, uma melhoria de 37% em relação à geração anterior (M2.1). Isso se deve ao seu estilo peculiar de codificação "Spec-writing" — o modelo primeiro decompõe a arquitetura para depois implementar de forma eficiente, reduzindo ciclos inúteis de tentativa e erro.
🎯 Dica para cenários de codificação: Se a sua necessidade principal é assistência de IA para programar (correção de bugs, code review, implementação de funcionalidades), o MiniMax-M2.5 é a melhor escolha. Através do APIYI (apiyi.com), você pode acessar ambos os modelos simultaneamente para realizar testes comparativos na prática.
Comparação detalhada da capacidade de raciocínio: MiniMax-M2.5 vs GLM-5
O raciocínio é onde o GLM-5 mostra sua maior força, especialmente nas áreas de matemática e ciências.
| Benchmark de Raciocínio | MiniMax-M2.5 | GLM-5 | Descrição |
|---|---|---|---|
| AIME 2026 | — | 92,7% | Raciocínio matemático de nível olímpico |
| GPQA-Diamond | — | 86,0% | Raciocínio científico de nível de doutorado |
| Humanity's Last Exam (c/ ferramentas) | — | 50,4 | Supera os 43,4 do Opus 4.5 |
| HMMT Nov. 2025 | — | 96,9% | Próximo aos 97,1% do GPT-5.2 |
| τ²-Bench | — | 89,7% | Raciocínio no setor de telecomunicações |
| Confiabilidade AA-Omniscience | — | Líder do setor | Menor taxa de alucinação |
O GLM-5 utiliza um novo método de treinamento chamado SLIME (Infraestrutura de Aprendizado por Reforço Assíncrono), que aumentou drasticamente a eficiência do pós-treinamento. Isso permitiu que o GLM-5 desse um salto qualitativo em tarefas de raciocínio:
- Pontuação de 92,7% no AIME 2026, chegando perto dos 93,3% do Claude Opus 4.5 e superando de longe o nível da era GLM-4.5.
- 86,0% no GPQA-Diamond, demonstrando uma capacidade de raciocínio científico de nível de doutorado, muito próxima dos 87,0% do Opus 4.5.
- 50,4 pontos no Humanity's Last Exam (com ferramentas), superando os 43,4 do Opus 4.5 e os 45,5 do GPT-5.2.
O diferencial mais marcante do GLM-5 é a confiabilidade do conhecimento. Na avaliação de alucinação AA-Omniscience, o GLM-5 melhorou 35 pontos em relação à versão anterior, atingindo a liderança do setor. Isso significa que ele "inventa" muito menos conteúdo ao responder perguntas factuais, o que é extremamente valioso para cenários que exigem alta precisão de informações.
Já o MiniMax-M2.5 possui menos dados públicos sobre raciocínio puro, pois seu treinamento de aprendizado por reforço (RL) é focado em codificação e cenários de agentes (agents). O framework Forge RL do M2.5 foca na decomposição de tarefas e na otimização de chamadas de ferramentas em mais de 200 mil ambientes reais, em vez de focar apenas em raciocínio abstrato.
Resumo da comparação: Se o seu foco é raciocínio matemático, análise científica ou se você precisa de um chatbot com alta confiabilidade de informações, o GLM-5 leva a vantagem. Recomendamos testar o desempenho de ambos em suas tarefas específicas de raciocínio através da plataforma APIYI (apiyi.com).
MiniMax-M2.5 vs GLM-5: Comparativo de Capacidades de Agente e Busca
| Benchmark de Agente | MiniMax-M2.5 | GLM-5 | Vantagem |
|---|---|---|---|
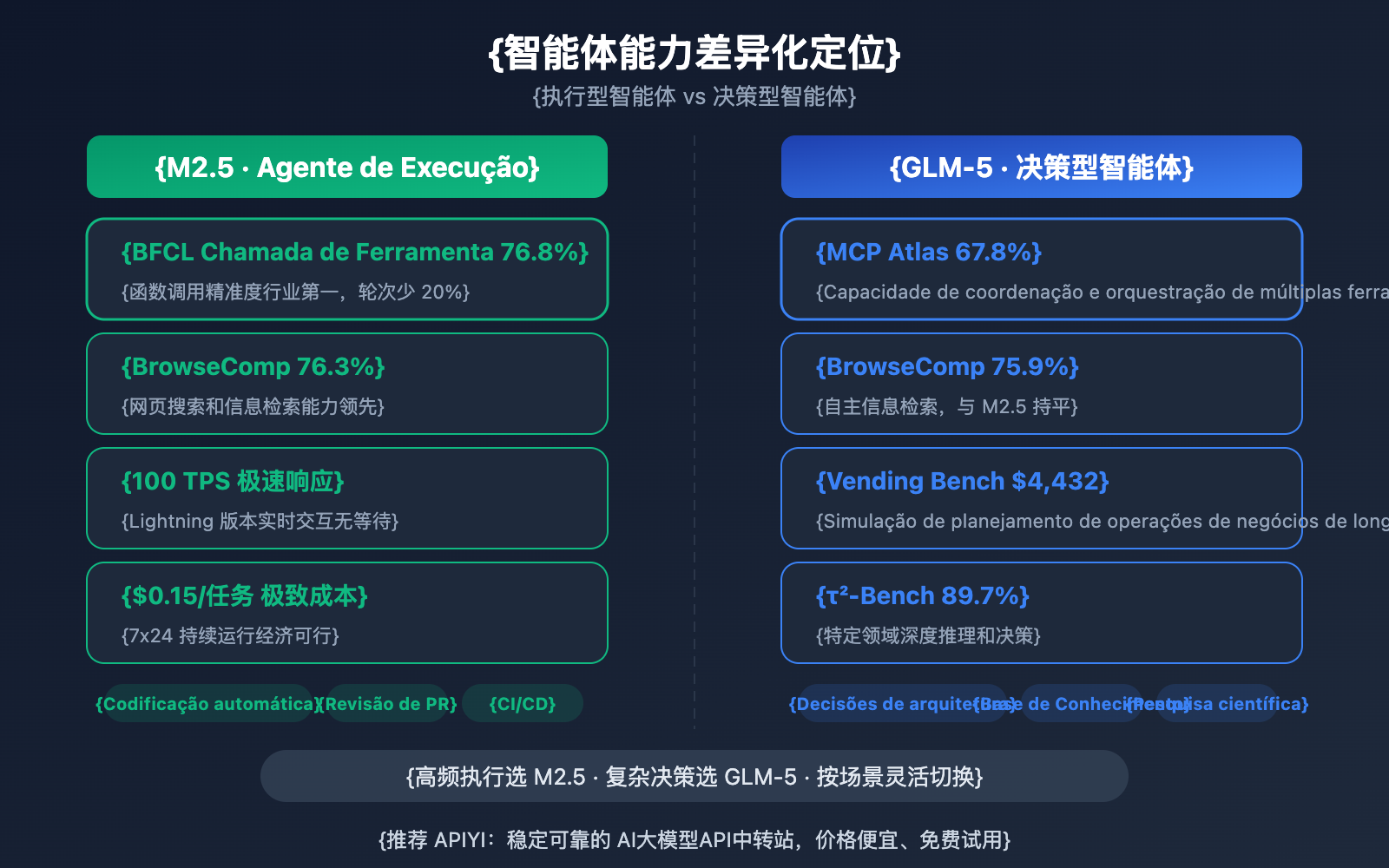
| BFCL Multi-Turn | 76,8% | — | M2.5 lidera em chamadas de ferramentas |
| BrowseComp (com contexto) | 76,3% | 75,9% | Praticamente empatados |
| MCP Atlas | — | 67,8% | GLM-5 em coordenação multi-ferramentas |
| Vending Bench 2 | — | $4.432 | GLM-5 em planejamento de longo prazo |
| τ²-Bench | — | 89,7% | GLM-5 em raciocínio de domínio |
Os dois modelos apresentam uma diferenciação clara em suas capacidades de agente:
O MiniMax-M2.5 se destaca como um agente "executor": ele brilha em cenários que exigem chamadas frequentes de ferramentas, iteração rápida e execução eficiente. O score de 76,8% no BFCL significa que o M2.5 é capaz de realizar chamadas de função, operações de arquivos e interações de API com precisão, sendo que o número de turnos de chamada de ferramentas foi reduzido em 20% em comparação com a geração anterior. Internamente na MiniMax, 80% do novo código já é gerado por ele, e 30% das tarefas diárias são concluídas pelo modelo.
O GLM-5 brilha como um agente "decisor": ele leva vantagem em cenários que exigem raciocínio profundo, planejamento de longo prazo e tomadas de decisão complexas. O score de 67,8% no MCP Atlas demonstra sua capacidade de coordenação de ferramentas em larga escala; os $4.432 de receita simulada no Vending Bench 2 mostram sua habilidade de planejamento de negócios em períodos extensos; e os 89,7% no τ²-Bench evidenciam seu raciocínio profundo em domínios específicos.
Ambos estão praticamente empatados em termos de navegação e busca na web — 76,3% vs 75,9% no BrowseComp — consolidando-se como líderes nessa área.
🎯 Sugestão de cenário para agentes: Escolha o M2.5 para chamadas de ferramentas de alta frequência e codificação automática; prefira o GLM-5 para decisões complexas e planejamento de longo prazo. A plataforma APIYI (apiyi.com) suporta ambos os modelos simultaneamente, permitindo alternar de forma flexível conforme a necessidade.
MiniMax-M2.5 对比 GLM-5 架构与成本对比
| 架构与成本 | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| 总参数量 | 230B | 744B |
| 激活参数量 | 10B | 40B |
| 激活比例 | 4.3% | 5.4% |
| 训练数据 | — | 28.5 万亿 Token |
| 上下文窗口 | 205K | 200K |
| 最大输出 | — | 131K |
| 输入价格 | $0.15/M (标准版) | $1.00/M |
| 输出价格 | $1.20/M (标准版) | $3.20/M |
| 输出速度 | 50-100 TPS | ~66 TPS |
| 训练芯片 | — | 华为昇腾 910 |
| 训练框架 | Forge RL | SLIME 异步 RL |
| 注意力机制 | — | DeepSeek Sparse Attention |
| 开源协议 | MIT | MIT |
MiniMax-M2.5 架构优势分析
M2.5 的核心架构优势在于"极致轻量"——仅激活 10B 参数就实现了接近 Opus 4.6 的编码能力。这使得:
- 推理成本极低: 输出价格 $1.20/M,仅为 GLM-5 的 37%
- 推理速度极快: Lightning 版本 100 TPS,比 GLM-5 的 ~66 TPS 快 52%
- 部署门槛更低: 10B 激活参数在消费级 GPU 上也有部署可能性
GLM-5 架构优势分析
GLM-5 的 744B 总参数和 40B 激活参数赋予了它更强的知识容量和推理深度:
- 更大的知识储备: 28.5 万亿 Token 训练数据,远超前代
- 更深的推理能力: 40B 激活参数支持更复杂的推理链
- 国产算力自主: 全程使用华为昇腾芯片训练,实现算力独立
- DeepSeek Sparse Attention: 高效处理 200K 长上下文
建议: 对于成本敏感的高频调用场景,M2.5 的价格优势明显(输出价格仅为 GLM-5 的 37%)。建议通过 APIYI apiyi.com 平台实际测试两者在你的任务上的性价比。
MiniMax-M2.5 对比 GLM-5 API 快速接入
通过 APIYI平台可以统一接口同时调用两个模型,方便快速对比:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 编码任务测试 - M2.5 更擅长
code_task = "用 Rust 实现一个无锁并发队列"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 推理任务测试 - GLM-5 更擅长
reason_task = "证明所有大于 2 的偶数都可以表示为两个素数之和(哥德巴赫猜想的验证思路)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
建议: 通过 APIYI apiyi.com 获取免费测试额度,针对你的具体场景分别测试两个模型。编码任务试 M2.5,推理任务试 GLM-5,找到最适合你的方案。
Perguntas Frequentes
Q1: No que o MiniMax-M2.5 e o GLM-5 são melhores, respectivamente?
O MiniMax-M2.5 é excelente em codificação (coding) e chamadas de ferramentas de agentes — com 80,2% no SWE-Bench, ele chega perto dos 4,6% do Opus, e seu BFCL de 76,8% é o primeiro do setor. Já o GLM-5 brilha em raciocínio e confiabilidade de conhecimento — atingindo 92,7% no AIME, 86,0% no GPQA e a menor taxa de alucinação do mercado. Dica rápida: quer escrever código? Vá de M2.5. Precisa de raciocínio lógico? Escolha o GLM-5.
Q2: Qual é a diferença de preço entre os dois modelos?
O preço de saída da versão padrão do MiniMax-M2.5 é de $1,20/M tokens, enquanto o GLM-5 custa $3,20/M tokens, tornando o M2.5 cerca de 2,7 vezes mais barato. Se você optar pela versão de alta velocidade M2.5 Lightning ($2,40/M), o preço se aproxima do GLM-5, mas com uma velocidade superior. Ao acessar através da plataforma APIYI (apiyi.com), você ainda pode aproveitar descontos em recargas.
Q3: Como posso comparar rapidamente o desempenho real dos dois modelos?
Recomendamos usar a plataforma APIYI (apiyi.com) para uma integração unificada:
- Crie uma conta para obter sua API Key e créditos gratuitos.
- Prepare dois tipos de tarefas de teste: uma de codificação e outra de raciocínio.
- Chame o MiniMax-M2.5 e o GLM-5 para a mesma tarefa.
- Compare a qualidade da resposta, a velocidade de reação e o consumo de tokens.
- Como a interface é compatível com OpenAI, basta alterar o parâmetro
modelpara trocar de modelo.
Resumo
Conclusões principais da comparação entre MiniMax-M2.5 e GLM-5:
- Codificação: M2.5 é a primeira escolha: 80,2% no SWE-Bench vs 77,8% do concorrente (uma liderança de 2,4%), além do BFCL de 76,8% em chamadas de ferramentas, sendo o melhor da indústria.
- Raciocínio: GLM-5 é a primeira escolha: Com 92,7% no AIME, 86,0% no GPQA e 50,4 pontos no Humanity's Last Exam, ele supera até o Opus 4.5.
- Confiabilidade de Conhecimento: GLM-5 lidera: Primeiro lugar na avaliação de alucinação AA-Omniscience, entregando fatos muito mais confiáveis.
- Custo-benefício: M2.5 é superior: O preço de saída é apenas 37% do valor do GLM-5, e a versão Lightning é ainda mais rápida.
Ambos os modelos possuem licença MIT e arquitetura MoE, mas com focos bem distintos: o M2.5 é o "rei da codificação e dos agentes de execução", enquanto o GLM-5 é o "pioneiro em raciocínio e confiabilidade de conhecimento". A sugestão é alternar entre eles na plataforma APIYI (apiyi.com) conforme sua necessidade real e aproveitar as promoções de recarga para garantir o melhor preço.
📚 Referências
-
Comunicado Oficial do MiniMax M2.5: Capacidades principais de codificação do M2.5 e detalhes do treinamento Forge RL
- Link:
minimax.io/news/minimax-m25 - Descrição: Dados completos de benchmark, incluindo SWE-Bench 80,2%, BFCL 76,8%, etc.
- Link:
-
Lançamento Oficial do GLM-5: Arquitetura MoE de 744B e tecnologia de treinamento SLIME do GLM-5 da Zhipu
- Link:
docs.z.ai/guides/llm/glm-5 - Descrição: Inclui dados de benchmark de raciocínio como AIME 92,7%, GPQA 86,0%, etc.
- Link:
-
Avaliação Independente da Artificial Analysis: Benchmarks padronizados e rankings para ambos os modelos
- Link:
artificialanalysis.ai/models/glm-5 - Descrição: Dados independentes sobre o Intelligence Index, testes de velocidade real, comparação de preços, etc.
- Link:
-
Análise Aprofundada da BuildFastWithAI: Benchmarks abrangentes do GLM-5 e comparação com a concorrência
- Link:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - Descrição: Tabela comparativa detalhada com Opus 4.5 e GPT-5.2.
- Link:
-
MiniMax no HuggingFace: Pesos do modelo open-source M2.5
- Link:
huggingface.co/MiniMaxAI - Descrição: Licença MIT, suporte para implantação via vLLM/SGLang.
- Link:
Autor: Equipe APIYI
Troca de Conhecimento: Sinta-se à vontade para compartilhar os resultados dos seus testes comparativos de modelos na seção de comentários. Para mais tutoriais de integração de APIs de modelos de IA, visite a comunidade técnica APIYI em apiyi.com.