Nota do autor: Análise profunda da capacidade de estruturação de texto do modelo de linguagem grande GLM-4.7, dominando técnicas práticas para extrair informações cruciais em formato JSON de documentos complexos como contratos e relatórios.
Extrair informações cruciais de grandes volumes de texto não estruturado de forma rápida é o principal desafio no processamento de dados corporativos. O modelo de linguagem grande GLM-4.7, lançado pela Zhipu AI em dezembro de 2025, trouxe uma solução inovadora para tarefas de estruturação de texto, graças ao seu suporte nativo a JSON Schema e uma janela de contexto ultralonga de 200K.
Valor Central: Ao ler este artigo, você aprenderá a usar o GLM-4.7 para extrair dados estruturados de documentos complexos, como contratos e relatórios, alcançando um aumento de ordem de magnitude na eficiência do processamento de documentos.

Principais Pontos da Estruturação de Texto no GLM-4.7
| Ponto Principal | Descrição | Valor |
|---|---|---|
| JSON Schema Nativo | Suporte integrado para saída estruturada, sem necessidade de engenharia de comandos complexa | Aumento de mais de 40% na precisão da extração |
| Janela de Contexto de 200K | Suporta entrada de documentos longos completos, sem necessidade de processamento por partes | Processa contratos/relatórios completos de uma só vez |
| Capacidade de Saída de 128K | Capaz de gerar resultados estruturados super longos | Ideal para extração de informações em lote |
| Suporte para Chamada de Função | Capacidade nativa de Tool Calling | Integração perfeita com sistemas de negócios |
| Vantagem de Custo | $0,10/M tokens, 4 a 7 vezes mais barato que modelos da mesma categoria | Custo controlado para implantação em larga escala |
Detalhes Principais da Estruturação de Texto no GLM-4.7
O GLM-4.7 é o Modelo de Linguagem Grande emblemático de nova geração lançado pela Zhipu AI em 22 de dezembro de 2025. Este modelo utiliza a arquitetura Mixture-of-Experts (MoE), com um total de aproximadamente 358B de parâmetros, alcançando uma inferência eficiente através de um mecanismo de ativação esparsa. No processamento de estruturação de texto, o GLM-4.7 deu um salto qualitativo em relação ao seu antecessor, o GLM-4.6, com um aumento de 38% no benchmark HLE, atingindo 42,8%, o que o coloca no mesmo nível do GPT-5.1 High.
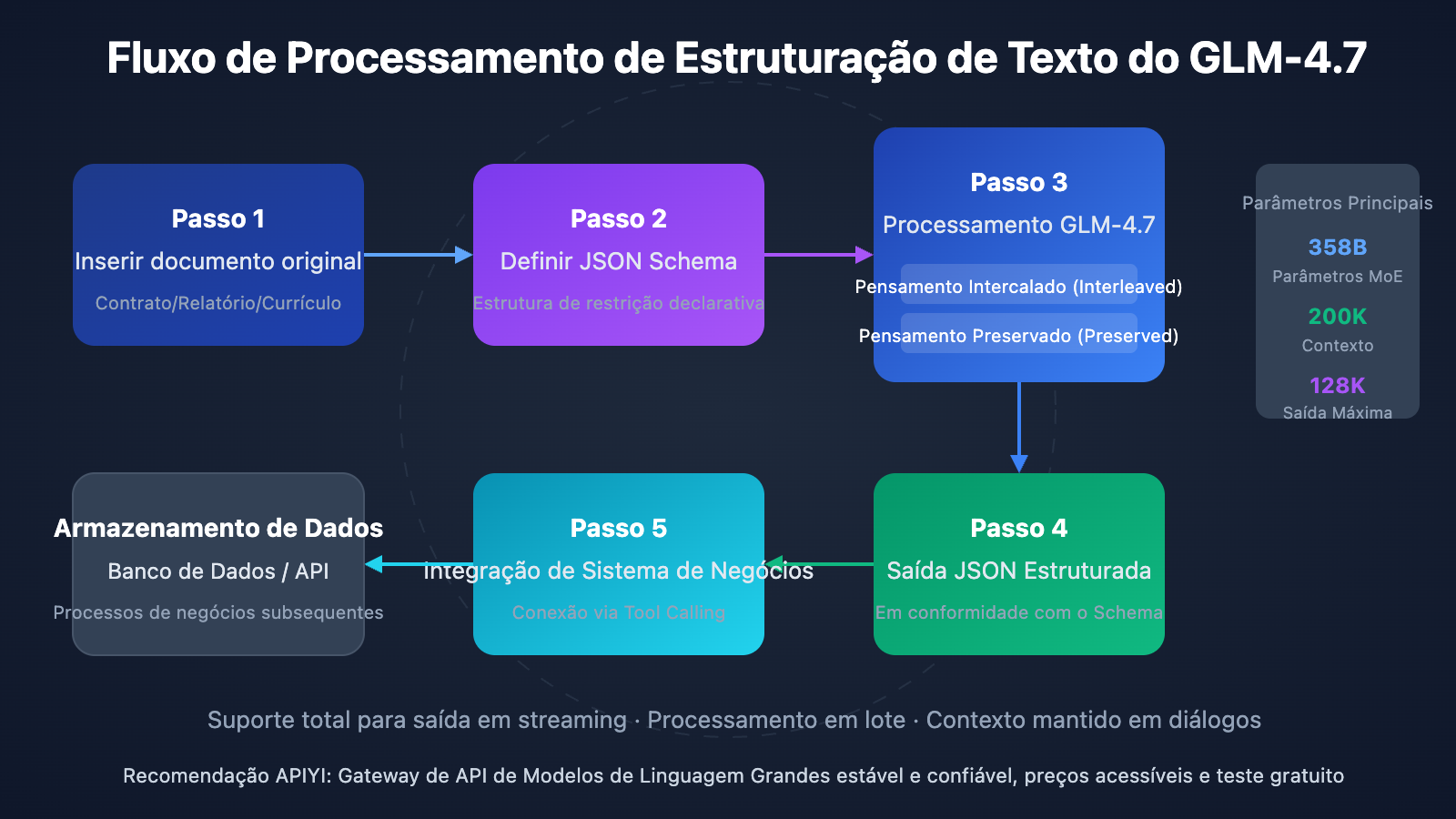
A capacidade de saída estruturada do GLM-4.7 se manifesta em três dimensões. Primeiro, o Pensamento Intercalado (Interleaved Thinking): o modelo planeja automaticamente o caminho de raciocínio antes de cada saída, garantindo a coerência da lógica de extração. Segundo, o Pensamento Preservado (Preserved Thinking): mantém o raciocínio de contexto em conversas de várias rodadas, sendo ideal para tarefas complexas de extração iterativa de informações. Por fim, o Controle em Nível de Turno (Turn-level Control): permite ajustar dinamicamente a profundidade do raciocínio em cada solicitação, equilibrando de forma flexível a velocidade e a precisão.
GLM-4.7 Estruturação de Texto: Guia Rápido
Exemplo minimalista
Aqui está a forma mais simples de usar: com apenas 10 linhas de código, você consegue realizar a extração estruturada de textos:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Ver código completo da implementação (com restrições JSON Schema)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
Sugestão: Obtenha créditos de teste gratuitos através do APIYI (apiyi.com) para validar rapidamente a eficácia da estruturação de texto do GLM-4.7. A plataforma suporta chamadas de interface unificada para vários modelos populares, facilitando a comparação da taxa de precisão de extração entre o GLM-4.7 e outros modelos.
Cenários de Aplicação da Estruturação de Texto com GLM-4.7
A capacidade de estruturação de texto do GLM-4.7 é aplicável a diversos cenários empresariais:
| Cenário | Dados de Entrada | Formato de Saída | Aumento Típico de Eficiência |
|---|---|---|---|
| Extração de informações de contratos | Contratos em PDF/Word | Dados estruturados em JSON | De horas para minutos |
| Análise de dados financeiros | Relatórios anuais/trimestrais | Tabelas de indicadores financeiros | Precisão de 95%+ |
| Triagem de currículos | Texto de currículos | Perfil do candidato em JSON | Eficiência de triagem 10x |
| Monitoramento de opinião pública | Conteúdo de notícias/redes sociais | Grafo de relação de entidades | Capacidade de processamento em tempo real |
| Interpretação de relatórios de pesquisa | Relatórios de pesquisa de mercado | Extração de pontos-chave | Aumento de 5x na cobertura |
Vantagens Técnicas da Estruturação de Texto do GLM-4.7
1. Suporte Nativo a JSON Schema
Assim como os modelos da série GPT, o GLM-4.7 suporta a especificação direta do JSON Schema no response_format. O modelo seguirá rigorosamente a estrutura definida para a saída. Isso significa que você não precisa escrever comandos complexos para "convencer" o modelo a gerar um formato específico; em vez disso, você restringe a estrutura de saída de forma declarativa.
2. Processamento de Contexto Extra Longo
Uma janela de contexto de 200K tokens significa que o GLM-4.7 pode processar cerca de 150 mil caracteres de uma só vez, o equivalente a um contrato completo ou um manual de especificações técnicas. Isso evita o processo complexo de dividir documentos longos em blocos e depois fundir os resultados, reduzindo o risco de perda de informações e quebra de contexto.
3. Pensamento Intercalado para Maior Precisão
Ao lidar com tarefas de extração complexas, o modo de pensamento intercalado do GLM-4.7 realiza automaticamente um raciocínio em várias etapas antes de gerar a resposta. Por exemplo, ao extrair valores de um contrato, o modelo identifica primeiro os parágrafos relacionados a valores, depois cruza os dados numéricos com os valores por extenso e, finalmente, entrega o resultado com o maior nível de confiança.
Sugestão Prática: Recomendamos realizar testes reais através da plataforma APIYI (apiyi.com) para avaliar o desempenho do GLM-4.7 no seu cenário de negócio específico. A plataforma oferece créditos gratuitos e logs de chamada detalhados, facilitando a depuração e otimização.

GLM-4.7 Estruturação de Texto: Comparação de Soluções
| Solução | Principais Características | Cenários de Uso | Desempenho |
|---|---|---|---|
| GLM-4.7 | JSON Schema nativo, 200K de contexto, baixo custo | Extração de documentos longos, processamento em larga escala, sensibilidade a custos | HLE 42,8%, SWE-bench 73,8% |
| GPT-5.1 | Saída estável, ecossistema maduro, resposta rápida | Requisitos de alta confiabilidade, cenários de entrega rápida | HLE 42,7%, tempo de resposta otimizado |
| Claude Sonnet 4.5 | Forte raciocínio lógico, compreensão profunda de contexto | Tarefas de análise complexas, raciocínio em múltiplas etapas | HLE 32,0%, excelente profundidade de raciocínio |
| DeepSeek-V3 | Código aberto e implantável, alta relação custo-benefício | Implantação privada, necessidades personalizadas | Desempenho excelente em benchmarks |
Diferenças cruciais entre o GLM-4.7 e concorrentes
| Dimensão de Comparação | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Status de Código Aberto | Aberto (Apache 2.0) | Fechado | Fechado |
| Preço (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| Janela de Contexto | 200K | 128K | 200K |
| Saída Máxima | 128K | 16K | 8K |
| Otimização para Chinês | Forte | Média | Média |
| Implantação Local | Suporta | Não suporta | Não suporta |
Sugestões de escolha:
- Se você precisa processar grandes volumes de documentos em chinês e possui sensibilidade a custos, o GLM-4.7 é a melhor escolha.
- Se você busca estabilidade de saída e facilidade de integração com o ecossistema, o GPT-5.1 é mais maduro.
- Se a tarefa envolve raciocínio complexo em múltiplas etapas, a capacidade lógica do Claude Sonnet 4.5 é superior.
Nota sobre a comparação: Os dados acima são provenientes de benchmarks públicos como HLE e SWE-bench, e podem ser validados na prática através da plataforma APIYI (apiyi.com). A plataforma suporta chamadas de interface unificada para todos os modelos mencionados acima.
GLM-4.7 Estruturação de Texto: Técnicas Avançadas
Processamento de Documentos em Lote
Para tarefas de estruturação de grandes volumes de documentos, você pode aproveitar a saída em streaming e a capacidade de concorrência do GLM-4.7:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""Extração assíncrona em lote de informações de documentos"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Integração com Chamada de Função (Tool Calling)
A capacidade de Tool Calling do GLM-4.7 permite conectar os resultados da extração diretamente aos seus sistemas de negócio:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "Salva as informações extraídas do contrato no banco de dados",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
Perguntas Frequentes
Q1: Qual é a precisão do GLM-4.7 na extração estruturada de texto?
Em cenários como contratos padrão, currículos e relatórios financeiros, a precisão da extração do GLM-4.7, quando combinada com restrições de JSON Schema, pode ultrapassar 95%. Para documentos complexos, recomendamos a implementação de um mecanismo de verificação humana. O modo de pensamento intercalado do modelo realiza automaticamente verificações em várias etapas, o que aumenta ainda mais a acurácia.
Q2: Quais são as limitações do GLM-4.7 ao lidar com documentos longos?
O GLM-4.7 suporta uma janela de contexto de 200K tokens, o que equivale a cerca de 150 mil caracteres chineses. Para documentos extremamente longos, sugerimos processar por divisões lógicas de capítulos ou utilizar as ferramentas de fragmentação de documentos longos oferecidas pela plataforma APIYI. A saída máxima de uma única chamada é de 128K tokens, o que é suficiente para cobrir a grande maioria das demandas de extração estruturada.
Q3: Como começar a testar rapidamente a capacidade de estruturação de texto do GLM-4.7?
Recomendamos utilizar uma plataforma de agregação de APIs que suporte múltiplos modelos para realizar seus testes:
- Acesse o site da APIYI (apiyi.com) e registre uma conta.
- Obtenha sua API Key e utilize o saldo gratuito disponível.
- Use os exemplos de código apresentados neste artigo para uma validação rápida.
- Compare o desempenho de diferentes modelos no seu cenário de negócio específico.
Resumo
Pontos-chave da estruturação de texto com o GLM-4.7:
- Suporte nativo à estruturação: Saída restrita por JSON Schema, eliminando a necessidade de engenharia de comando complexa.
- Capacidade de contexto ultra-longo: Janela de 200K tokens, permitindo processar documentos longos e completos de uma só vez.
- Excelente custo-benefício: O preço é apenas 1/4 a 1/7 de modelos da mesma categoria, sendo ideal para implementações em larga escala.
- Otimização para cenários específicos: Como um modelo de origem chinesa, ele apresenta uma compreensão mais precisa de contratos e relatórios nesse idioma.
Como o modelo topo de linha da Zhipu AI, o GLM-4.7 demonstra no campo da estruturação de texto uma capacidade comparável ao GPT-5.1, contando ainda com as vantagens de ser código aberto, ter baixo custo e ser otimizado para o idioma chinês. Para empresas que possuem uma grande demanda de processamento de documentos, o GLM-4.7 é uma escolha que merece ser avaliada seriamente.
Recomendamos validar os resultados rapidamente através da APIYI (apiyi.com). A plataforma oferece saldo gratuito e uma interface unificada para múltiplos modelos, facilitando a realização de testes em cenários reais.
Materiais de Referência
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome do material: dominio.com. Isso facilita a cópia, mas os links não são clicáveis para evitar a perda de autoridade de SEO.
-
Documentação Oficial do GLM-4.7: Documentação para desenvolvedores da Zhipu AI
- Link:
docs.z.ai/guides/llm/glm-4.7 - Descrição: Contém a explicação completa dos parâmetros da API e as melhores práticas.
- Link:
-
Análise Técnica do GLM-4.7: Análise profunda da arquitetura e capacidades do modelo
- Link:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Descrição: Avaliação técnica de terceiros, incluindo comparação de dados de benchmark.
- Link:
-
Página do Modelo no Hugging Face: Download de pesos open-source
- Link:
huggingface.co/zai-org/GLM-4.7 - Descrição: Fornece os arquivos do modelo e o guia de implementação necessários para o deploy local.
- Link:
-
OpenRouter GLM-4.7: Acesso à API por múltiplos canais
- Link:
openrouter.ai/z-ai/glm-4.7 - Descrição: Oferece opções de acesso de vários fornecedores e comparação de preços.
- Link:
Autor: Equipe Técnica
Troca de Conhecimento: Sinta-se à vontade para discutir suas experiências no uso da estruturação de texto com GLM-4.7 na seção de comentários. Para mais materiais, visite a comunidade técnica APIYI em apiyi.com.