저자 주: Nano Banana Pro API의 빈번한 과부하 현상의 근본 원인을 파헤칩니다. 구글 TPU 자체 칩 아키텍처부터 AI Studio와 Vertex AI의 차이점까지, 공급 부족 뒤에 숨겨진 기술적 진실을 알아봅니다.
Nano Banana Pro가 2025년 11월에 출시된 이후, 개발자들 사이에서 한 가지 당혹스러운 현상이 발견되고 있습니다. 구글이 자체 개발한 TPU 칩을 보유하고 있음에도 불구하고, 이 이미지 생성 API에서 "모델 과부하(Model Overloaded)" 오류가 빈번하게 발생한다는 점이죠. 왜 자체 칩으로도 컴퓨팅 파워 문제를 해결하지 못하는 걸까요? AI Studio와 Vertex AI라는 두 플랫폼 사이에는 어떤 본질적인 차이가 있을까요? 이번 글에서는 구글 컴퓨팅 파워 아키텍처의 기저 로직을 바탕으로 이러한 문제 뒤에 숨겨진 기술적 진실을 깊이 있게 파헤쳐 보겠습니다.
핵심 가치: 실제 데이터와 아키텍처 분석을 통해 Nano Banana Pro 안정성 문제의 근본 원인을 이해하고, 더 신뢰할 수 있는 API 연동 방안을 선택하는 데 도움을 드립니다.
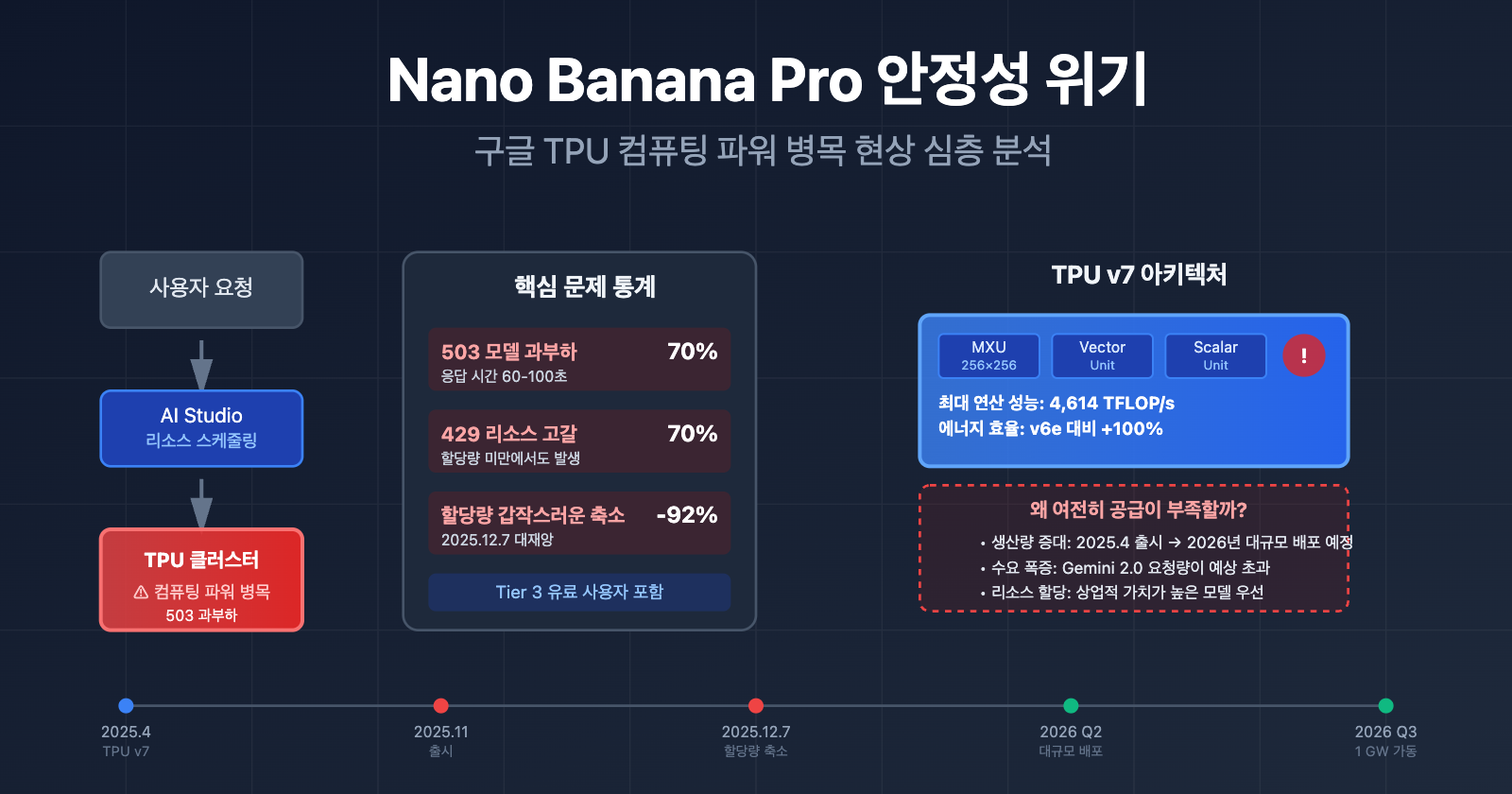
Nano Banana Pro API 안정성 핵심 문제
2025년 11월 출시 이후 지금까지, Nano Banana Pro (gemini-2.0-flash-preview-image-generation)는 지속적인 안정성 위기를 겪고 있습니다. 다음은 개발자 커뮤니티에서 보고된 핵심 문제 데이터입니다.
| 문제 유형 | 발생 빈도 | 전형적인 증상 | 영향 범위 |
|---|---|---|---|
| 503 모델 과부하 | 높은 빈도(오류의 70% 이상 차지) | 응답 시간이 30초에서 60~100초로 급증 | 모든 등급 사용자 (Tier 3 유료 사용자 포함) |
| 429 리소스 고갈 | API 오류의 약 70% | 할당량 제한보다 훨씬 낮은 수준에서도 발생 | 무료 티어 및 Tier 1 유료 사용자 |
| 할당량 갑작스러운 축소 | 2025년 12월 7일 | 무료 티어 1일 3장에서 2장으로 감소, 2.5 Pro 무료 티어 제외 | 전 세계 무료 티어 사용자 |
| 서비스 사용 불가 | 간헐적 | 전날까지는 빠르게 생성되다가 다음 날 갑자기 완전히 사용 불가 | 무료 티어에 의존하는 앱 개발자 |
Nano Banana Pro 안정성 문제의 근본 원인
이러한 문제들의 핵심은 코드 결함이 아니라, 바로 구글 서버 측의 연산 리소스 용량 병목 현상입니다. 심지어 가장 높은 할당량 등급인 Tier 3 유료 사용자조차 요청 빈도가 공식 제한보다 훨씬 낮은 상황에서 과부하 오류를 겪고 있는데요. 이는 문제가 사용자 할당량 관리가 아닌 인프라 수준에서 발생하고 있음을 보여줍니다.
구글 공식 개발자 포럼의 답변에 따르면, 연산 리소스가 Gemini 2.0 시리즈의 신규 모델들로 재배정되면서 Nano Banana Pro와 같은 이미지 생성 모델의 가용 용량이 제한되고 있다고 합니다. 이러한 리소스 스케줄링 전략이 서비스 불안정의 직접적인 원인이 된 것이죠.
🎯 기술 제언: 프로덕션 환경에서 Nano Banana Pro를 사용할 때는 APIYI(apiyi.com) 플랫폼을 통해 접속하는 것을 추천합니다. 이 플랫폼은 지능형 부하 분산과 자동 장애 조치(페일오버) 메커니즘을 제공하여 API 호출 성공률과 안정성을 획기적으로 높여줍니다.
구글 TPU 자체 개발 칩 아키텍처의 진실
많은 분이 구글이 자체 개발한 TPU(Tensor Processing Unit) 칩을 보유하고 있으니 AI 모델의 연산 수요를 거뜬히 감당할 수 있을 거라 생각합니다. 하지만 현실은 생각보다 훨씬 복잡합니다.
TPU v7 (Ironwood)의 최신 아키텍처
2025년 4월, 구글은 Cloud Next 컨퍼런스에서 7세대 TPU인 '아이언우드(Ironwood)'를 발표했습니다. 이는 지금까지 출시된 버전 중 가장 강력한 성능을 자랑합니다.
| 아키텍처 파라미터 | TPU v7 (Ironwood) | TPU v6e (Trillium) | 향상 폭 |
|---|---|---|---|
| 최대 연산 성능 | 4,614 TFLOP/s | 약 2,300 TFLOP/s | ~100% |
| 에너지 효율 | 기준 | 참조 | 와트당 성능 100% 향상 |
| 클러스터 구성 | 256 칩 / 9,216 칩 두 종류 | 단일 구성 | 유연한 확장 능력 |
| 매트릭스 유닛 | 256×256 MXU (시스톨릭 어레이) | 128×128 MXU | 연산 밀도 4배 |
| 응용 시나리오 | 추론 우선 (Inference-first) | 훈련+추론 혼합 | 추론 성능 특화 최적화 |
TPU의 핵심 아키텍처 구성 요소
각 TPU 칩은 하나 이상의 TensorCore를 포함하며, 각 TensorCore는 다음과 같은 부분으로 구성됩니다.
- 매트릭스 곱셈 유닛 (MXU): TPU v6e 및 v7x는 256×256 곱셈 누산기 어레이를 채택했으며, 이전 버전은 128×128이었습니다.
- 벡터 유닛: 매트릭스 연산 이외의 처리를 담당합니다.
- 스칼라 유닛: 제어 로직을 실행합니다.
이러한 시스톨릭 어레이(systolic array) 아키텍처는 신경망 추론에 특히 적합하지만, 나름의 한계도 존재합니다.
왜 자체 개발 칩으로도 연산 자원 부족을 해결하지 못할까요?
TPU v7의 강력한 성능에도 불구하고 Nano Banana Pro의 안정성 문제가 여전한 데에는 세 가지 이유가 있습니다.
1. 생산량 확대(Ramp-up) 주기
TPU v7은 2025년 4월에 발표되었지만, 대규모 배포까지는 시간이 걸립니다. 구글은 2025년 말 앤스로픽(Anthropic)과 100억 달러 규모의 협력을 발표하며 2026년에 1GW 이상의 AI 연산 자원을 가동할 계획이라고 밝혔습니다. 즉, 2025년 11월부터 2026년 초까지는 신구 아키텍처가 교체되는 과도기이며, 이로 인해 가용 리소스가 부족해지는 현상이 발생합니다.
2. 폭발적인 수요 증가
Gemini 2.0 시리즈 모델이 2025년 말 출시된 후, API 요청량이 구글의 초기 예측치를 훨씬 초과했습니다. 특히 Nano Banana Pro의 이미지 생성 수요를 포함한 무료 티어 사용자의 유입은 유료 사용자의 리소스 풀을 직접적으로 압박하고 있습니다.
3. 리소스 할당 우선순위
구글은 Gemini 2.5 Pro(텍스트), Gemini 2.0 Flash(멀티모달), Nano Banana Pro(이미지 생성) 등 여러 AI 제품 라인의 연산 수요를 조율해야 합니다. 연산 자원이 한정적일 때는 상업적 가치가 더 높은 모델에 우선적으로 할당되므로, 결과적으로 Nano Banana Pro의 용량 제한으로 이어지게 됩니다.
🎯 아키텍처 인사이트: TPU 칩을 직접 만든다고 해서 연산 자원이 무한한 것은 아닙니다. 칩 생산 능력, 데이터 센터 구축, 에너지 공급 등이 모두 제약 요인이 됩니다. 기업 사용자의 경우, 단일 공급업체의 용량 리스크를 피하기 위해 APIYI(apiyi.com) 플랫폼을 통해 멀티 클라우드 연산 스케줄링 능력을 확보하는 것을 추천해 드립니다.
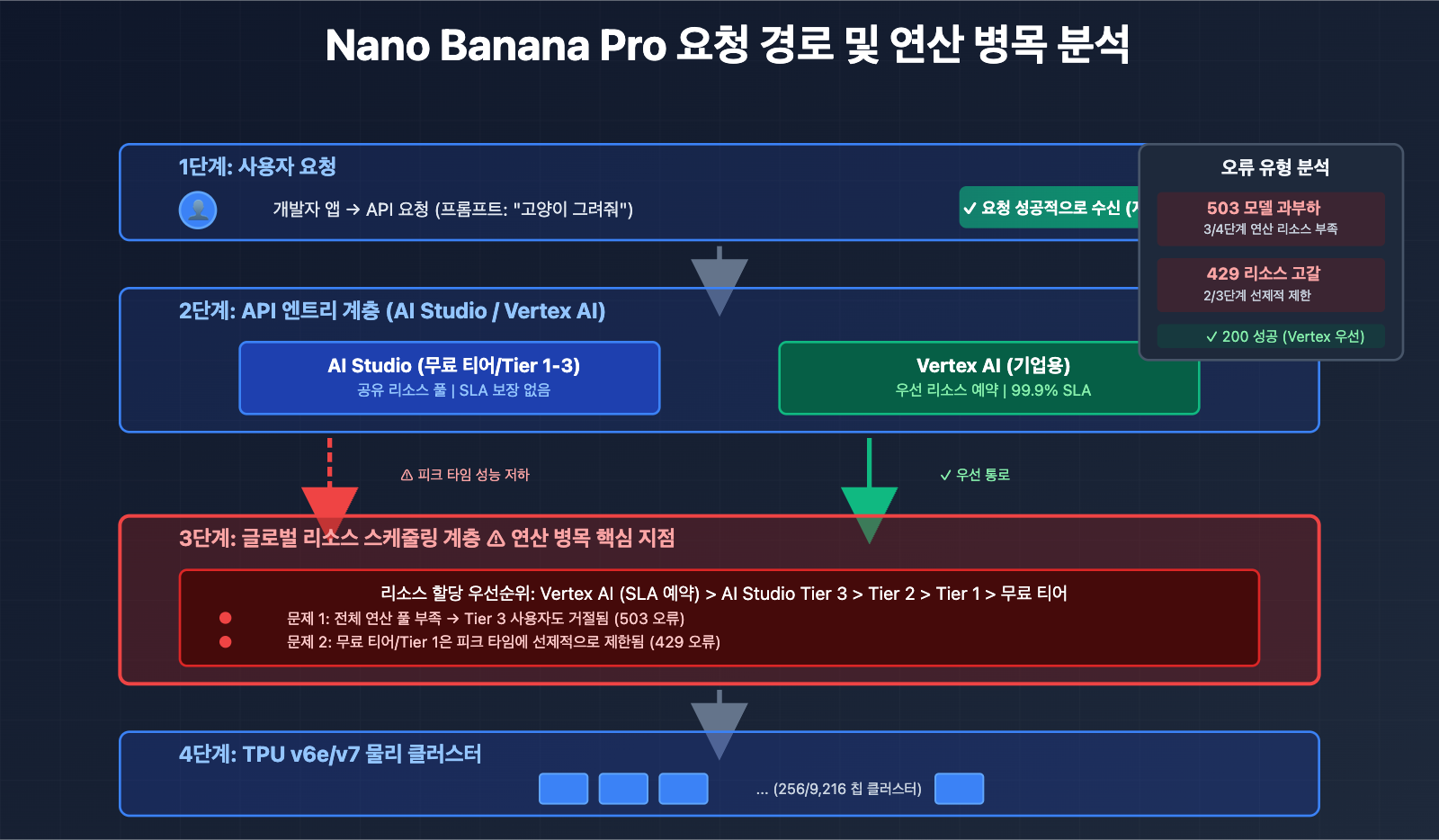
AI Studio vs Vertex AI: 두 플랫폼의 본질적인 차이
많은 개발자분이 혼란스러워하시는 부분인데요. Gemini AI Studio와 Vertex AI 모두 Gemini 모델을 호출할 수 있는데, 왜 안정성과 할당량(Quota) 차이가 이렇게 큰 걸까요? 답은 두 플랫폼의 아키텍처 지향점이 완전히 다르다는 데 있습니다.
플랫폼 포지셔닝 비교
| 비교 항목 | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API on GCP) |
|---|---|---|
| 타겟 사용자 | 개인 개발자, 학생, 스타트업 | 기업급 팀, 프로덕션 환경 애플리케이션 |
| 진입 장벽 | API Key만 받으면 몇 분 만에 프로토타입 개발 가능 | Google Cloud 계정 및 결제 설정 필요 |
| 가격 모델 | 무료 티어 (할당량 제한) + Tier 1/2/3 유료 | 사용량 기반 과금 (무료 티어 없음), GCP 결제 시스템 통합 |
| SLA 보장 | SLA(서비스 수준 합의서) 없음 | 기업급 SLA 제공, 99.9% 가용성 보장 |
| 기능 범위 | 모델 호출 API + 시각화 프로토타이핑 도구 | 전체 ML 워크플로우 (데이터 라벨링, 훈련, 미세 조정, 배포, 모니터링) |
| 할당량 안정성 | 글로벌 리소스 스케줄링의 영향으로 동적 조정 가능 | 기업용 할당량 예약, 리소스 우선 할당 |
AI Studio의 핵심 장점과 한계
장점:
- 빠른 시작: 가입 즉시 API 키를 받을 수 있어 클라우드 서비스 설정이 필요 없습니다.
- 시각화 프로토타이핑 도구: 프롬프트 테스트 인터페이스가 내장되어 있어 빠른 반복 개발이 가능합니다.
- 친숙한 무료 티어: 학습, 실험 및 소규모 프로젝트에 적합합니다.
한계:
- SLA 보장 없음: 서비스 가용성이 계약으로 보호받지 못합니다.
- 불안정한 할당량: 2025년 12월 7일의 갑작스러운 할당량 삭감 사건처럼, Gemini 2.5 Pro가 무료 티어에서 제외되거나 2.5 Flash의 일일 한도가 250회에서 20회로(92% 삭감) 급감할 수 있습니다.
- 기업용 기능 부족: BigQuery, Dataflow 등 GCP 데이터 서비스와 통합할 수 없습니다.
Vertex AI의 기업급 역량
핵심 장점:
- 리소스 우선순위: 유료 사용자의 요청은 구글 내부 스케줄링 시스템에서 더 높은 우선순위를 갖습니다.
- MLOps 통합: 모델 훈련, 버전 관리, A/B 테스트, 모니터링 및 알림 등 전체 라이프사이클을 지원합니다.
- 데이터 주권: 데이터 저장 지역을 지정할 수 있어 GDPR, CCPA 등 규제 준수에 유리합니다.
- 기업 지원: 전담 기술 지원 팀과 아키텍처 컨설팅 서비스를 이용할 수 있습니다.
적용 시나리오:
- 일일 요청량이 10,000회를 초과하는 프로덕션 애플리케이션
- 모델 미세 조정(Fine-tuning) 및 맞춤형 훈련이 필요한 경우
- 가용성과 응답 시간에 엄격한 SLA 요구사항이 있는 기업
🎯 선택 가이드: 프로토타입 단계를 지나 일평균 호출량이 5,000회를 넘는다면 Vertex AI로 이전하거나 APIYI(apiyi.com)와 같은 통합 플랫폼을 이용하는 것이 좋습니다. 이러한 플랫폼은 여러 클라우드 제공업체의 연산 자원을 통합하여 하나의 인터페이스에서 플랫폼 간 스케줄링을 구현하므로, AI Studio의 편의성을 유지하면서도 Vertex AI 수준의 안정성을 확보할 수 있습니다.
<!-- 定位 -->
<g transform="translate(0, 80)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">🎯 포지셔닝</text>
<text x="15" y="38" font-family="Arial, sans-serif" font-size="14" fill="#e2e8f0">
개인 개발자, 학생, 프로토타입 개발
</text>
</g>
<!-- 资源调度 -->
<g transform="translate(0, 145)">
<rect x="0" y="0" width="480" height="120" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">⚙️ 리소스 스케줄링</text>
<!-- 共享资源池 -->
<g transform="translate(15, 35)">
<rect x="0" y="0" width="450" height="30" rx="4" fill="#1e40af" fill-opacity="0.3" stroke="#3b82f6" stroke-width="1.5"/>
<text x="225" y="20" font-family="Arial, sans-serif" font-size="13" fill="#93c5fd" text-anchor="middle">
전역 공유 리소스 풀 (동적 할당, 예약 없음)
</text>
</g>
<!-- 优先级层级 -->
<g transform="translate(15, 70)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="12" fill="#cbd5e1">우선순위: Tier 3 (유료 최고) > Tier 2 > Tier 1 > 무료 티어</text>
<text x="0" y="18" font-family="Arial, sans-serif" font-size="12" fill="#fca5a5">
⚠️ 피크 시간대에는 모든 티어에서 서비스 수준이 저하될 수 있음
</text>
</g>
</g>
<!-- 稳定性 -->
<g transform="translate(0, 280)">
<rect x="0" y="0" width="480" height="90" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">📊 안정성</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• SLA 보장 없음 (서비스 가용성이 계약으로 보호되지 않음)
</text>
<text x="0" y="22" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 할당량이 동적으로 조정될 수 있음 (예: 2025.12.7 92% 삭감)
</text>
<text x="0" y="44" font-family="Arial, sans-serif" font-size="13" fill="#fca5a5">
• 503/429 에러율: 70% (피크 시간대)
</text>
</g>
</g>
<!-- 定价 -->
<g transform="translate(0, 385)">
<rect x="0" y="0" width="480" height="70" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">💰 가격 정책</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 무료 티어: 2-5 RPM (한도 제한)
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• Tier 1-3: 이미지당 $0.05-0.08
</text>
</g>
</g>
<!-- 适用场景 -->
<g transform="translate(0, 470)">
<rect x="0" y="0" width="480" height="110" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">✅ 권장 사용 시나리오</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 빠른 프로토타입 개발 및 기술 검증
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 학습 및 실험 (신용카드 등록 불필요)
</text>
<text x="0" y="40" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 일일 호출량 1,000회 미만의 소규모 앱
</text>
<text x="0" y="60" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 지연 시간 및 가용성에 대한 허용치가 높은 경우
</text>
</g>
</g>
<!-- 风险标注 -->
<g transform="translate(0, 595)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#7f1d1d" fill-opacity="0.3" stroke="#ef4444" stroke-width="2"/>
<text x="240" y="30" font-family="Arial, sans-serif" font-size="14" fill="#fca5a5" text-anchor="middle" font-weight="bold">
⚠️ 리스크: 불안정한 할당량 + 서비스 보장 없음
</text>
</g>
<!-- 定位 -->
<g transform="translate(0, 80)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">🎯 포지셔닝</text>
<text x="15" y="38" font-family="Arial, sans-serif" font-size="14" fill="#e2e8f0">
기업급 팀, 프로덕션 환경 애플리케이션
</text>
</g>
<!-- 资源调度 -->
<g transform="translate(0, 145)">
<rect x="0" y="0" width="480" height="120" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">⚙️ 리소스 스케줄링</text>
<!-- 企业级资源池 -->
<g transform="translate(15, 35)">
<rect x="0" y="0" width="450" height="30" rx="4" fill="#065f46" fill-opacity="0.4" stroke="#10b981" stroke-width="1.5"/>
<text x="225" y="20" font-family="Arial, sans-serif" font-size="13" fill="#86efac" text-anchor="middle">
기업용 연산 풀 (SLA 예약 리소스, 우선 스케줄링)
</text>
</g>
<!-- 优先级说明 -->
<g transform="translate(15, 70)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="12" fill="#cbd5e1">우선순위: 모든 AI Studio 티어보다 높음</text>
<text x="0" y="18" font-family="Arial, sans-serif" font-size="12" fill="#86efac">
✓ 리소스 예약 메커니즘으로 피크 시간대에도 가용성 보장
</text>
</g>
</g>
<!-- 稳定性 -->
<g transform="translate(0, 280)">
<rect x="0" y="0" width="480" height="90" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">📊 안정성</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 99.9% 가용성 SLA (서비스 수준 보장)
</text>
<text x="0" y="22" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 할당량 안정성 (계약 기반, 갑작스러운 삭감 없음)
</text>
<text x="0" y="44" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 503/429 에러율: 5% 미만 (낮음)
</text>
</g>
</g>
<!-- 定价 -->
<g transform="translate(0, 385)">
<rect x="0" y="0" width="480" height="70" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">💰 가격 정책</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#fca5a5">
✗ 무료 티어 없음
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 사용량 기반 과금: 이미지당 $0.08-0.12
</text>
</g>
</g>
<!-- 适用场景 -->
<g transform="translate(0, 470)">
<rect x="0" y="0" width="480" height="110" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">✅ 권장 사용 시나리오</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 일일 호출량 5,000회 이상의 프로덕션 앱
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• SLA 보장이 필요한 기업급 서비스
</text>
<text x="0" y="40" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• GCP 데이터 서비스(BigQuery/Dataflow) 연동 필요 시
</text>
<text x="0" y="60" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 모델 미세 조정 및 MLOps 역량 필요 시
</text>
</g>
</g>
<!-- 优势标注 -->
<g transform="translate(0, 595)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#065f46" fill-opacity="0.3" stroke="#10b981" stroke-width="2"/>
<text x="240" y="30" font-family="Arial, sans-serif" font-size="14" fill="#86efac" text-anchor="middle" font-weight="bold">
✓ 장점: 기업용 SLA + 리소스 예약 + 안정성
</text>
</g>
<text x="520" y="25" font-family="Arial, sans-serif" font-size="18" fill="#f1f5f9" text-anchor="middle" font-weight="bold">
핵심 차이: 리소스 스케줄링 우선순위 및 서비스 보장
</text>
<g transform="translate(30, 40)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="14" fill="#cbd5e1">
• <tspan fill="#93c5fd" font-weight="bold">AI Studio</tspan>: 공유 리소스 풀, SLA 없음, 할당량 동적 조정, 프로토타입에 적합 | 비용은 낮지만 불안정함
</text>
<text x="0" y="24" font-family="Arial, sans-serif" font-size="14" fill="#cbd5e1">
• <tspan fill="#86efac" font-weight="bold">Vertex AI</tspan>: 기업용 리소스 예약, 99.9% SLA, 할당량 안정, 프로덕션 환경에 적합 | 비용은 높지만 신뢰할 수 있음
</text>
<text x="0" y="48" font-family="Arial, sans-serif" font-size="14" fill="#fbbf24">
• <tspan font-weight="bold">추천</tspan>: APIYI(apiyi.com) 통합 플랫폼을 통해 비용과 안정성을 모두 잡는 멀티 클라우드 스케줄링 활용
</text>
</g>
Nano Banana Pro 공급 부족의 심층적인 원인
이전의 분석을 종합해 볼 때, Nano Banana Pro가 지속적으로 공급 부족 현상을 겪는 이유는 크게 다음 세 가지 측면으로 요약할 수 있습니다.
1. 기술적 측면: 칩 생산 능력과 수요의 불균형
- TPU v7 생산량 확대 중: 2025년 4월에 출시되었으나, 대규모 배포는 2026년이 되어야 완료될 예정입니다.
- 추론보다 학습 우선: Gemini 3.0 시리즈의 학습 작업이 방대한 TPU v6e 및 v7 리소스를 점유하고 있습니다.
- 이미지 생성의 연산 집약성: Nano Banana Pro의 확산 모델(Diffusion Model) 추론에 필요한 연산량은 텍스트 모델의 5~10배에 달합니다.
2. 비즈니스 측면: 무료 티어 전략 수정
| 시점 | 정책 변화 | 배경 원인 |
|---|---|---|
| 2025년 11월 | Nano Banana Pro 출시, 무료 티어 일일 3장 | 빠른 사용자 피드백 확보 및 시장 입지 구축 |
| 2025년 12월 7일 | 무료 티어 일일 2장으로 축소, Gemini 2.5 Pro 무료 티어 삭제 | 연산 비용 예산 초과, 무료 사용자 증가 억제 필요 |
| 2026년 1월 | 무료 티어 RPM 10에서 5로 하향 | Gemini 2.0 Flash 기업 고객을 위한 리소스 예약 |
구글은 공식 포럼을 통해 이러한 조정이 **"지속 가능한 서비스 품질 보장"**을 위한 것이라고 명확히 밝혔습니다. 실제로 무료 티어 사용자의 급증(특히 자동화 도구 및 배치 호출)으로 인해 비용 관리가 불가능해지자 구글이 정책을 강화하게 된 것입니다.
3. 아키텍처 측면: AI Studio와 Vertex AI의 리소스 격리
두 플랫폼 모두 동일한 하부 모델을 호출하지만, 구글 내부의 리소스 스케줄링 우선순위가 다릅니다.
- Vertex AI: GCP의 기업급 연산 풀에 직접 연결되어 있으며, SLA가 보장된 리소스 예약을 제공받습니다.
- AI Studio: 글로벌 리소스 풀을 공유하며, 피크 시간대에는 성능이 저하되거나 제한될 수 있습니다.
이러한 아키텍처 설계로 인해 AI Studio의 무료 티어 및 Tier 1 사용자는 429/503 오류를 더 자주 겪게 되며, Vertex AI 유료 사용자는 상대적으로 영향을 덜 받습니다.
4. 제품 전략: '시장 점유'에서 '수익 최적화'로
Nano Banana Pro 출시 초기, 구글은 DALL-E 3, Midjourney 등 경쟁사에 대항하기 위해 공격적인 무료 전략을 취했습니다. 하지만 사용자 수가 폭발적으로 증가하면서 무료 티어 비즈니스 모델의 지속 불가능성을 깨닫고, '고가치 유료 사용자'에게 리소스를 집중하기 시작했습니다.
이러한 전환의 상징적인 사건이 바로 2025년 12월의 쿼터 삭감과 2.5 Pro 무료 티어 제거이며, 개발자 커뮤니티에서는 이를 "Free Tier Fiasco(무료 티어 대참사)"라고 부르기도 합니다.
🎯 대응 전략: Nano Banana Pro에 의존하는 프로덕션 환경의 앱이라면 멀티 클라우드 백업 전략을 도입하는 것을 추천합니다. APIYI(apiyi.com) 플랫폼을 사용하면 단일 인터페이스 환경에서 Nano Banana Pro, DALL-E 3, Stable Diffusion 등 여러 모델의 자동 전환 규칙을 설정할 수 있습니다. 특정 서비스에 과부하가 발생하면 자동으로 예비 플랜으로 전환하여 비즈니스 연속성을 보장할 수 있습니다.
개발자가 Nano Banana Pro의 불안정성에 대응하는 방법
앞선 분석을 바탕으로, 검증된 네 가지 기술적 방안을 제안합니다.
방안 1: 지수 백오프(Exponential Backoff) 재시도 메커니즘 구현
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""지수 백오프 전략을 사용하여 Nano Banana Pro API 호출"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # 실제 API 호출 함수
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"과부하 오류 발생, {wait_time:.2f}초 후 재시도 중...")
time.sleep(wait_time)
else:
raise e
raise Exception("최대 재시도 횟수 도달")
핵심 아이디어: 503/429 오류가 발생하면 대기 시간을 지수적으로 늘려(1초 → 2초 → 4초 → 8초) 연쇄적인 오류 발생(Cascading failure)을 방지합니다.
완성형 프로덕션급 구현 코드 (클릭하여 펼치기)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""완전한 오류 처리 및 모니터링을 포함한 프로덕션급 이미지 생성 메서드"""
for attempt in range(self.max_retries):
try:
# 실제 API 호출 로직
response = self._call_api(prompt, **kwargs)
logger.info(f"요청 성공 (시도 {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"오류 {error_code}: {str(e)[:100]} | "
f"{wait_time:.2f}초 대기 (시도 {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"최대 재시도 횟수 도달, 최종 실패: {str(e)}")
raise
else:
logger.error(f"재시도 불가능한 오류: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""지수 백오프 시간을 계산하며, 동기적 재시도를 피하기 위해 지터(jitter)를 추가"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # 최대 대기 시간 60초
def _parse_error_code(self, error: Exception) -> int:
"""예외에서 HTTP 상태 코드를 추출"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""실제 API 호출 로직 (실제 구현체로 교체 필요)"""
# 여기에 실제 API 호출 코드를 작성하세요.
pass
# 사용 예시
client = NanoBananaClient(api_key="your_api_key")
result = client.generate_image("피아노를 치는 귀여운 고양이")
방안 2: 요청 간격 제어
개발자 커뮤니티의 피드백에 따르면, 요청 사이에 5~10초의 고정 지연 시간을 추가하는 것만으로도 503 오류 발생률을 현저히 낮출 수 있습니다.
import time
def batch_generate_images(prompts):
"""이미지를 대량으로 생성하며 요청 빈도를 엄격히 제어"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # 마지막 요청 후에는 대기 불필요
time.sleep(7) # 7초 고정 간격
return results
적용 시나리오: 배치 콘텐츠 생성, 오프라인 데이터 처리 등 실시간성이 중요하지 않은 애플리케이션.
방안 3: 멀티 클라우드 백업 전략
통합 API 플랫폼을 통해 자동 장애 조치(Failover)를 구현합니다.
| 단계 | 기술적 구현 | 기대 효과 |
|---|---|---|
| 1. 주/부 모델 설정 | Nano Banana Pro (주) + DALL-E 3 (부) | 단일 장애점(SPOF) 극복 |
| 2. 전환 규칙 설정 | 503 오류 3회 연속 발생 시 → 자동으로 부 모델로 전환 | 사용자 체감 지연 시간 단축 |
| 3. 복구 상태 모니터링 | 5분마다 주 서비스 상태 체크 | 주 서비스 정상화 시 자동 복구 |
🎯 추천 구현 방식: APIYI(apiyi.com) 플랫폼은 이러한 멀티 클라우드 스케줄링 전략을 기본적으로 지원합니다. 콘솔에서 전환 규칙만 설정하면 시스템이 장애 감지, 트래픽 전환, 비용 최적화를 자동으로 처리하므로 비즈니스 코드를 수정할 필요가 없습니다.
방안 4: Vertex AI 또는 기업용 플랫폼으로 업그레이드
애플리케이션이 다음 조건 중 하나라도 해당된다면 업그레이드를 고려하는 것이 좋습니다.
- 일일 API 호출량이 5,000회 이상인 경우
- 응답 시간에 엄격한 SLA 요구 사항이 있는 경우 (예: 95th 백분위수 < 10초)
- 서비스 중단을 수용할 수 없는 경우 (예: 이커머스 이미지 생성, 실시간 콘텐츠 검수)
비용 비교:
AI Studio Tier 1: 장당 $0.05 (잦은 과부하 발생)
Vertex AI: 장당 $0.08 (안정적, SLA 보장)
APIYI 플랫폼: 장당 $0.06 (멀티 클라우드 스케줄링, 자동 장애 대응)
Vertex AI의 단가가 더 높지만, 재시도 비용, 개발 시간 및 비즈니스 손실을 고려하면 실제 TCO(총 소유 비용)는 더 낮을 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: 유료 사용자인데 왜 "모델 과부하(Model Overloaded)" 오류가 발생하나요?
A: Nano Banana Pro의 용량 병목 현상은 사용자 할당량(Quota) 층이 아니라 구글의 전역 컴퓨팅 자원 스케줄링 층에서 발생합니다. Tier 3 유료 사용자라 하더라도 전체 컴퓨팅 자원 풀이 가득 차면 503 오류를 받게 됩니다. 이는 일반적인 429 할당량 초과 오류와는 성격이 다릅니다.
그 차이점은 다음과 같습니다:
- 429 오류: 개인 할당량 소진 (예: RPM 제한)
- 503 오류: 구글 서버 측의 컴퓨팅 자원 부족 (사용자의 할당량과는 무관)
Q2: AI Studio와 Vertex AI는 동일한 모델을 호출하나요?
A: 네, 두 서비스 모두 호출하는 기저의 Nano Banana Pro 모델(gemini-2.0-flash-preview-image-generation)은 완전히 동일합니다. 하지만 자원 스케줄링 우선순위에서 차이가 납니다.
- Vertex AI: 기업용 SLA(서비스 수준 합의)가 보장되며, 컴퓨팅 자원이 우선적으로 배정됩니다.
- AI Studio: 공유 자원 풀을 사용하므로, 사용량이 몰리는 피크 시간대에 서비스가 제한될 수 있습니다.
이는 클라우드 서버의 '종량제 플랜'과 '예약 인스턴스'의 차이와 비슷하다고 이해하시면 됩니다.
Q3: 구글이 무료 티어 할당량을 계속 줄일까요?
A: 과거 사례로 볼 때, 구글은 무료 티어 정책을 지속적으로 조정할 가능성이 큽니다.
- 2025년 11월: 무료 티어 일일 3장으로 제한
- 2025년 12월 7일: 일일 2장으로 축소, 2.5 Pro 모델 제거
- 2026년 1월: RPM(분당 요청 수) 10에서 5로 하향
구글의 공식적인 입장은 "지속 가능한 서비스 품질 확보"이지만, 실제로는 비용 관리와 사용자 확보 사이에서 균형을 맞추려는 전략입니다. 따라서 실제 서비스 중인 앱이라면 무료 티어에만 의존하기보다 유료 플랜이나 멀티 클라우드 백업 방안을 미리 마련해두는 것이 좋습니다.
Q4: Nano Banana Pro의 안정성은 언제쯤 개선될까요?
A: 구글의 공개 정보에 따르면, 핵심적인 전환점은 2026년 중반이 될 것으로 보입니다.
- 2026년 2분기: TPU v7(Ironwood) 대규모 배포 완료
- 2026년 3분기: Anthropic과 협력한 1GW 규모의 컴퓨팅 자원 가동
이 시점에는 자원 공급이 크게 늘어나겠지만, 수요 역시 동시에 증가할 수 있습니다. 보수적으로 예측하자면, 2026년 하반기쯤 되어야 실질적인 안정성 개선을 체감할 수 있을 것입니다.
Q5: Nano Banana Pro를 어떻게 도입하는 것이 좋을까요?
A: 현재 개발 중인 애플리케이션의 단계에 따라 추천하는 방안이 다릅니다.
| 단계 | 추천 방안 | 이유 |
|---|---|---|
| 프로토타입 개발 | AI Studio 무료 티어 | 최저 비용으로 아이디어 빠르게 검증 |
| 소규모 런칭 | AI Studio Tier 1 + 재시도 로직 | 비용과 안정성의 균형 |
| 운영 환경 | Vertex AI 또는 APIYI 플랫폼 | SLA 보장 및 기업급 기술 지원 |
| 핵심 비즈니스 | 멀티 클라우드 백업 전략 (예: APIYI 플랫폼) | 최고 수준의 가용성, 자동 장애 조치(Failover) |
🎯 의사결정 팁: 어떤 선택이 최선일지 고민된다면, APIYI(apiyi.com) 플랫폼을 통해 A/B 테스트를 진행해 보시는 걸 추천드려요. 동일한 요청에 대해 Nano Banana Pro(AI Studio), Nano Banana Pro(Vertex AI), DALL-E 3 등 다양한 모델의 실제 퍼포먼스를 비교해 보고, 실제 데이터를 기반으로 결정할 수 있습니다.
요약: Nano Banana Pro의 자원 과제를 이성적으로 바라보기
Nano Banana Pro의 안정성 문제는 단발적인 사건이 아닙니다. 이는 AI 업계 전체가 직면한 컴퓨팅 자원 수급 불균형의 축약판이라 할 수 있습니다.
핵심 모순:
- 수요 측면: 생성형 AI 애플리케이션의 폭발적 증가 (특히 이미지 생성 분야)
- 공급 측면: 칩 생산 능력 확대의 지연, 데이터 센터 구축 주기(12~18개월)의 한계
- 경제 모델: 무료 티어 전략의 지속 불가능성과 낮은 유료 전환율
세 가지 기술적 진실:
-
자체 TPU 보유 ≠ 무한한 자원: 구글이 TPU v7과 같은 첨단 칩을 보유하고 있더라도, 생산 수율 확보, 에너지 공급, 데이터 센터 건설에는 물리적인 시간이 필요합니다. 2026년이 중요한 변곡점이 될 것입니다.
-
AI Studio vs Vertex AI의 본질: 단순히 '무료 버전'과 '유료 버전'의 차이가 아니라, 자원 스케줄링 우선순위의 차이입니다. Vertex AI의 기업용 SLA 뒤에는 독립적인 자원 예약 메커니즘이 존재합니다.
-
공급 부족의 장기화: Gemini 3.0, GPT-5 등 차세대 모델이 출시됨에 따라 컴퓨팅 자원 수요는 계속 늘어날 것입니다. 단기적으로(2026~2027년) 자원 부족 상태가 근본적으로 해결되기는 어렵습니다.
실질적인 제언:
- 단기: 재시도(Retry) 메커니즘, 요청 간격 제어 등 엔지니어링 기법으로 문제를 완화하세요.
- 중기: Vertex AI로의 업그레이드나 멀티 클라우드 플랫폼 도입의 ROI를 검토하세요.
- 장기: 2026년 중반 구글의 자원 확충 진전 상황을 주시하며 전략을 유연하게 조정하세요.
기업용 애플리케이션의 경우, 단일 공급업체의 용량 리스크를 피하기 위해 멀티 클라우드 백업 전략을 채택할 것을 강력히 권장합니다. APIYI(apiyi.com)와 같은 통합 플랫폼을 사용하면 코드 복잡도를 높이지 않고도 클라우드 간 스케줄링, 자동 장애 조치 및 비용 최적화 기능을 활용할 수 있습니다.
마지막 생각: Nano Banana Pro가 직면한 도전 과제는 AI 애플리케이션의 안정성이 모델의 성능뿐만 아니라 기반 인프라의 성숙도에 달려 있다는 점을 일깨워 줍니다. 컴퓨팅 자원이 곧 경쟁력인 시대에, 견고한 아키텍처 설계와 공급원 다변화는 제품 경쟁력의 핵심 요소가 될 것입니다.
함께 읽어볼 만한 글:
- Nano Banana Pro API 사용 가이드
- Google TPU v7 아키텍처 심층 분석
- AI 이미지 생성 API 선택 가이드: Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 운영 환경에서의 AI API 호출 베스트 프랙티스 10가지