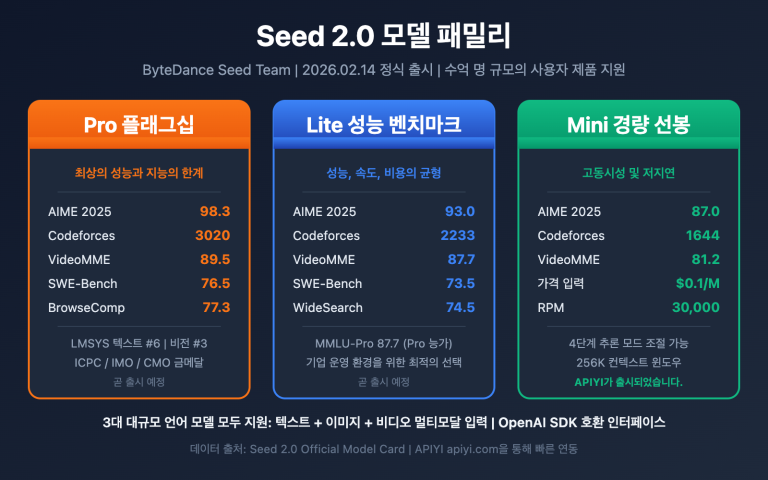
저자 주: Qwen-Image-2.0 통합 이미지 생성 및 편집 모델의 5대 핵심 돌파구를 심층 분석합니다. 7B 경량화 아키텍처, 원생 2K 해상도, 1000 토큰 장문 프롬프트 등 기술적 하이라이트와 함께 API 연동 및 실제 사용 가이드를 소개합니다.
알리바바 통의(通义) 팀이 2026년 2월 10일, 이미지 생성과 이미지 편집을 단일 모델로 통합한 중대 업데이트 버전인 Qwen-Image-2.0을 발표했습니다. 놀라운 점은 파라미터 수를 전작의 20B에서 7B로 대폭 줄였음에도 불구하고 성능은 전방위적으로 향상되었다는 것입니다. APIYI는 현재 Alibaba Cloud의 공식 파트너로서 연동 작업을 진행 중이며, 조만간 더욱 빠른 서비스 출시와 가격 경쟁력을 갖춘 서비스를 제공해 드릴 예정입니다.
핵심 가치: 이번 심층 분석을 통해 Qwen-Image-2.0의 5대 핵심 돌파구, 경쟁 모델과의 실제 차이점, 그리고 API를 통해 빠르게 연동하여 사용하는 방법을 알아보세요.
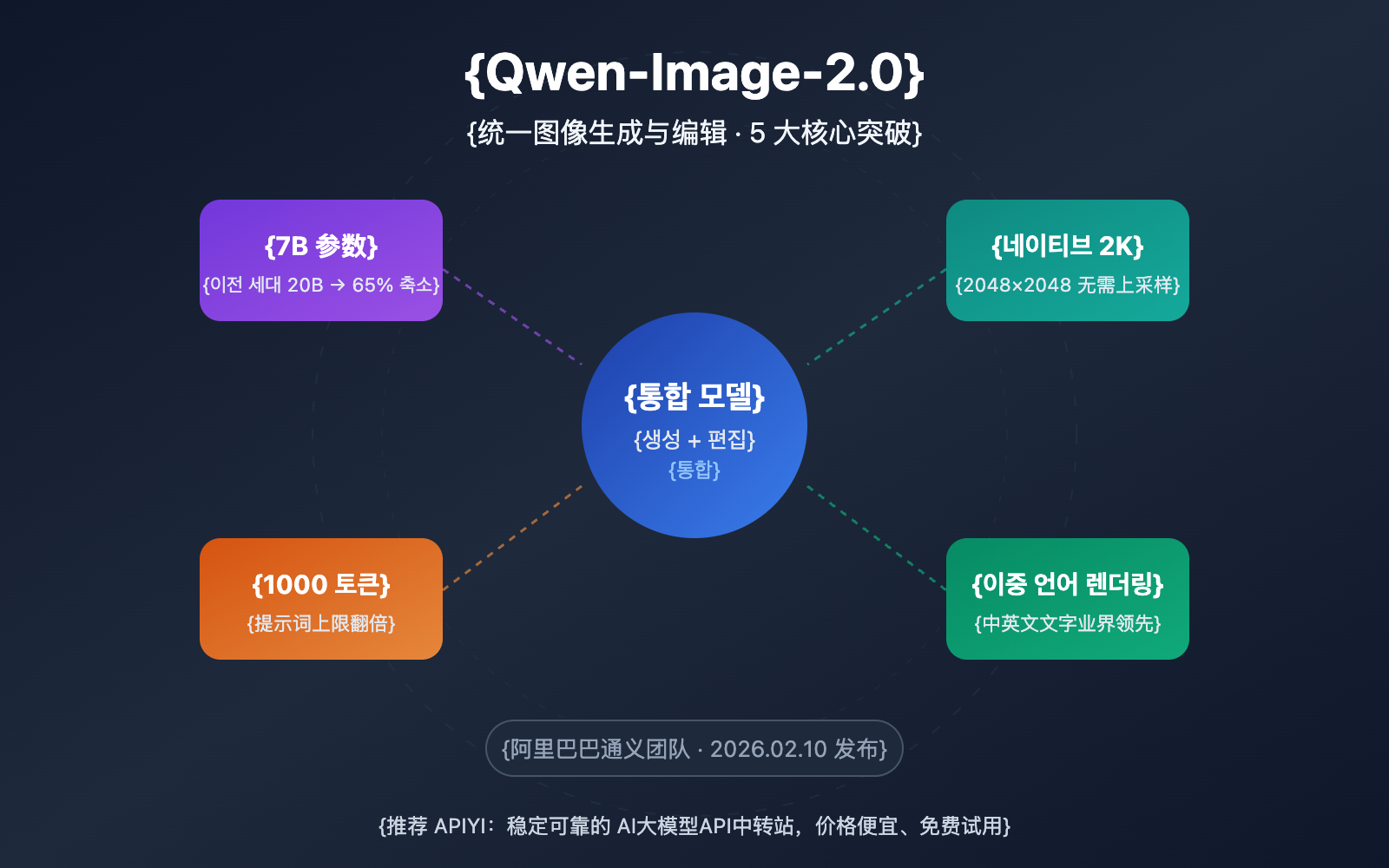
Qwen-Image-2.0 핵심 요점 요약
| 요점 | 설명 | 가치 |
|---|---|---|
| 통합 생성+편집 | 텍스트 투 이미지와 이미지 편집을 단일 7B 모델로 통합 | 두 모델을 각각 로드할 필요가 없어 배포 비용 대폭 절감 |
| 파라미터 수 65% 감소 | 전작 20B에서 7B(확산 디코더)로 정밀화 | 추론 속도 향상 및 그래픽 메모리 요구 사양 현저히 감소 |
| 원생 2K 해상도 | 최대 2048×2048 원생 출력 지원 | 업샘플링 없이도 디테일이 살아있는 고화질 구현 |
| 1000 토큰 프롬프트 | 프롬프트 상한선 2배 확대 (전작 약 500 토큰) | 더욱 복잡한 장면 묘사와 정밀한 제어 가능 |
| 이중 언어 텍스트 렌더링 | 중문 및 영문 텍스트 생성 업계 최고 수준 | 포스터, 인포그래픽 등 텍스트 포함 장면에서 탁월한 효과 |
Qwen-Image-2.0 핵심 기술 분석
Qwen-Image-2.0은 완전히 새로운 듀얼 컴포넌트 아키텍처 설계를 채택했습니다. 8B 파라미터의 Qwen3-VL 시각 언어 모델이 조건 인코더 역할을 수행하고, 7B 파라미터의 MMDiT(다중 모드 확산 트랜스포머)가 확산 디코더 역할을 합니다. 이러한 설계를 통해 모델은 텍스트와 이미지라는 두 가지 모달리티의 시맨틱 정보를 깊이 있게 이해하고, 확산 과정을 거쳐 고품질 이미지를 생성해냅니다.
전작인 Qwen-Image-2512와 가장 큰 차이점은 통합 훈련 전략에 있습니다. 텍스트 투 이미지(T2I)와 이미지 편집(I2I/TI2I)이 하나의 순전파(Forward Propagation) 과정으로 통합되었습니다. 이는 기존에 Qwen-Image(생성)와 Qwen-Image-Edit(편집)라는 두 개의 독립된 모델이 필요했던 작업을 이제 단 하나의 모델로 수행할 수 있음을 의미하며, 배포 비용과 복잡성을 획기적으로 낮췄습니다.
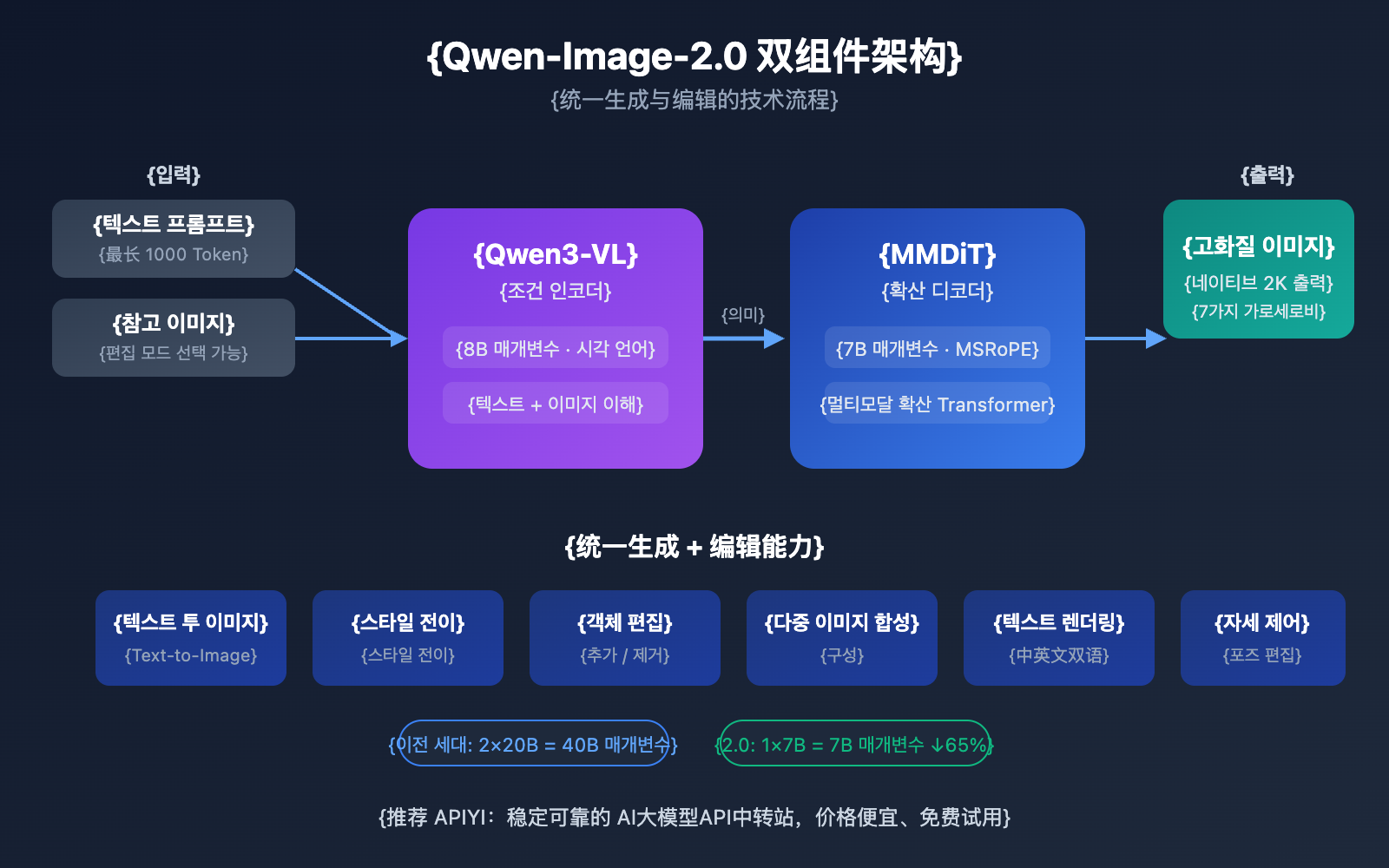
Qwen-Image-2.0의 5가지 핵심 혁신 상세 분석
혁신 1: 통합 생성 및 편집 아키텍처
이것은 Qwen-Image-2.0의 가장 상징적인 혁신입니다. 이전 세대에서는 텍스트 투 이미지(Text-to-Image) 모델과 이미지 편집 모델을 각각 별도로 유지해야 했지만, 2.0 버전에서는 이 둘을 하나로 합쳤습니다.
| 기능 | 이전 세대 솔루션 | Qwen-Image-2.0 |
|---|---|---|
| 텍스트 투 이미지 | Qwen-Image-2512 (20B) | 통합 모델 (7B) |
| 이미지 편집 | Qwen-Image-Edit-2511 (20B) | 통합 모델 (7B) |
| 스타일 전송 | 편집 모델에서 별도 처리 | 통합 모델에서 직접 지원 |
| 다중 이미지 합성 | 편집 모델에서 별도 처리 | 통합 모델에서 직접 지원 |
| 모델 총 VRAM | 20B 모델 2개 로드 필요 | 7B 모델 1개만 필요 |
실제 사용 시, 먼저 텍스트로 이미지를 생성한 다음, 모델 교체 없이 즉시 해당 이미지에 대해 스타일 전송, 객체 추가/삭제, 포즈 조정 등의 편집 작업을 수행할 수 있습니다. 전체 과정에서 모델을 전환할 필요가 없다는 것이 큰 장점이죠.
혁신 2: 7B 파라미터로 성능 역전 실현
파라미터 수를 20B에서 7B(확산 디코더 기준)로 줄여 규모를 65%나 축소했음에도 불구하고, 이미지 품질은 오히려 향상되었습니다. 그 비결은 바로 Qwen3-VL 인코더의 깊이 있는 시맨틱 이해 능력에 있습니다. 8B 파라미터의 시각 언어 모델이 '요구 사항 이해' 단계에서 더 많은 역할을 수행함으로써, 확산 디코더가 '이미지 생성'에만 더욱 효율적으로 집중할 수 있게 된 것입니다.
개발자들에게 이는 다음과 같은 의미를 갖습니다:
- 추론 속도 향상: API 호출 시 이미지당 약 5~8초 소요
- VRAM 요구 사양 감소: 약 24GB VRAM으로 실행 가능할 것으로 예상 (이전 세대는 48GB 이상 필요)
- 배포 비용 절감: 단일 소비자용 GPU에서도 실행 가능할 전망
혁신 3: 네이티브 2K 고해상도 지원
Qwen-Image-2.0은 별도의 초해상도(Super-Resolution) 업샘플링 단계 없이도 2048×2048 해상도 출력을 네이티브로 지원합니다. 또한 7가지 표준 화면 비율을 지원합니다:
| 화면 비율 | 해상도 | 추천 시나리오 |
|---|---|---|
| 16:9 | 1664×928 | 영상 커버, 블로그 삽입 이미지 (기본값) |
| 1:1 | 1328×1328 | 소셜 미디어 프로필, 제품 메인 이미지 |
| 9:16 | 928×1664 | 핸드폰 배경화면, 숏폼 영상 커버 |
| 4:3 | 1472×1104 | 전통적인 가로형 디스플레이 |
| 3:4 | 1104×1472 | 전통적인 세로형 디스플레이 |
| 3:2 | 1584×1056 | 사진 스타일 가로 이미지 |
| 2:3 | 1056×1584 | 사진 스타일 세로 이미지 |
혁신 4: 1000 토큰의 긴 프롬프트 지원
프롬프트 제한이 이전 세대의 약 500 토큰에서 1000 토큰으로 늘어났습니다. 두 배로 늘어난 공간 덕분에 훨씬 더 복잡한 장면을 묘사할 수 있게 되었죠. 실제 테스트 결과, 다음과 같은 상황에서 특히 유용했습니다:
- 전문 인포그래픽: 레이아웃 위치, 텍스트 내용, 색상 조합의 정밀한 제어
- 다중 객체 시나리오: 여러 객체 간의 위치 관계와 상호작용 디테일 묘사
- 스타일 융합: 원하는 예술적 스타일과 질감 요구 사항의 세밀한 설명
혁신 5: 독보적인 이국어 텍스트 렌더링
Qwen-Image-2.0은 이미지 내 텍스트 생성 능력이 업계 최고 수준입니다. 특히 중국어 렌더링의 경우 해서(楷书), 수금체(瘦金体), 소전체(小篆) 등 다양한 서체 스타일을 지원합니다. 덕분에 다음과 같은 작업에서 뚜렷한 강점을 보입니다:
- 마케팅 포스터 및 홍보 이미지 디자인
- 중국어 주석이 포함된 기술 도표
- 소셜 미디어용 카드 뉴스 콘텐츠
- 브랜드 비주얼 작업물 생성
🎯 실제 팁: Qwen-Image-2.0은 현재 API 초청 테스트 단계에 있습니다. APIYI(apiyi.com)에서 현재 연동 작업을 진행 중이며, 연동이 완료되면 공식 홈페이지보다 20% 저렴한 가격으로 OpenAI 호환 형식을 통해 통합 호출 서비스를 제공할 예정입니다. 조금만 기다려 주세요!
Qwen-Image-2.0 빠르게 시작하기
초간단 예제
다음은 DashScope API 형식을 기반으로 API를 호출하여 Qwen-Image-2.0으로 이미지를 생성하는 기본 방법입니다:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "一只戴墨镜的柴犬在沙滩冲浪,阳光明媚,高清摄影风格"
}]
)
print(response.choices[0].message.content)
DashScope 네이티브 API 호출 예제 보기
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "现代简约办公桌,桌上有笔记本和绿植,柔和自然光"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"图像URL: {image_url}")
# 주의: URL은 24시간 동안 유효하므로 즉시 다운로드하여 저장하세요.
권장 사항: APIYI(apiyi.com)가 Qwen-Image-2.0을 연동 중입니다. 연동이 완료되면 OpenAI 호환 형식으로 호출할 수 있어, 하나의 API Key로 GPT Image 1.5, Gemini 3 Pro Image, FLUX.2 등 여러 이미지 생성 모델을 간편하게 비교 테스트할 수 있습니다.
Qwen-Image-2.0와 경쟁 모델 비교
| 비교 항목 | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| 개발사 | 알리바바 | OpenAI | Black Forest Labs | |
| 통합 생성+편집 | ✅ | ✅ | ✅ | ❌ |
| 최대 해상도 | 2K | 2K+ | 2K | 2K |
| 중국어 텍스트 렌더링 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 추론 속도 | 5-8 초 | 10-15 초 | 5-10 초 | 10-20 초 |
| 오픈 소스 생태계 | 이전 버전 오픈 소스 | 폐쇄형 | 폐쇄형 | 부분 오픈 소스 |
| API 가격 참고 | 공식가 대비 20% 이상 저렴 (APIYI) | $0.04-0.08/장 | 토큰 기준 과금 | $0.04/장 |
Qwen-Image-2.0의 차별화된 강점:
- 중국어 환경 최강: 업계 최고 수준의 이중 언어 텍스트 렌더링 능력을 갖추고 있어, 중국어 포스터나 인포그래픽 제작 시 경쟁 모델보다 월등한 결과물을 보여줍니다.
- 가장 가벼운 아키텍처: 7B 파라미터만으로 GPT Image 1.5급의 품질을 구현하여 추론 비용이 훨씬 저렴합니다.
- 오픈 소스 잠재력: 이전 세대 전 시리즈가 Apache-2.0 라이선스로 오픈 소스화되었던 만큼, 2.0 버전의 오픈 소스화도 기대해 볼 만합니다.
- 풍부한 생태계: HuggingFace 좋아요 2,380개 이상, LoRA 어댑터 484개 이상 등 커뮤니티 활동이 매우 활발합니다.
비교 설명: 위 데이터는 공개된 기술 문서와 AI Arena 랭킹을 기반으로 작성되었습니다. 여러분의 구체적인 사용 환경에서 각 모델이 어떤 성능을 내는지 APIYI(apiyi.com) 플랫폼을 통해 직접 테스트하고 비교해 보시는 것을 추천드려요.
Qwen-Image-2.0 추천 활용 시나리오
다음과 같은 상황에서 사용하기 좋습니다:
- 이커머스 제품 이미지: 제품 이미지 생성과 배경 교체를 하나의 모델로 해결하여 워크플로우를 대폭 간소화할 수 있습니다. 이커머스 운영 및 디자인 팀에 적합합니다.
- 마케팅 소재 디자인: 포스터, 소셜 미디어 이미지, 광고 소재 제작 시 강력한 중국어 텍스트 렌더링 능력이 핵심 경쟁력입니다. 마케팅 팀에 추천합니다.
- 크리에이티브 디자인: 실사, 애니메이션, 수채화, 손그림 등 다양한 예술 스타일을 지원하며, 1,000 토큰의 긴 프롬프트를 통해 창의적인 방향을 정밀하게 제어할 수 있습니다. 디자이너와 콘텐츠 크리에이터에게 적합합니다.
- 기술 도표 생성: PPT 페이지, 인포그래픽, 플로우차트 등 전문적인 콘텐츠를 픽셀 단위의 정밀한 레이아웃으로 생성합니다. 기술 문서 작성 팀에 유용합니다.
🎯 시나리오 제안: 비즈니스에서 중국어 텍스트가 포함된 이미지 생성이 많다면, Qwen-Image-2.0은 현재 가장 주목해야 할 선택지입니다. APIYI (apiyi.com) 플랫폼을 통해 실제 비교 테스트를 진행하여 비즈니스 시나리오에 가장 적합한 솔루션을 찾아보시길 권장합니다.
Qwen-Image-2.0 버전 진화 및 가격 안내
버전 진화 타임라인
Qwen-Image 시리즈는 2025년 8월 첫 버전을 발표한 이후 빠른 속도로 업데이트를 이어오고 있습니다.
| 버전 | 시기 | 핵심 업데이트 |
|---|---|---|
| Qwen-Image v1 | 2025.08 | 최초 20B MMDiT 출시, Apache-2.0 오픈 소스 |
| Qwen-Image-Edit | 2025.08 | 전용 편집 모델 추가 |
| Qwen-Image-2512 | 2025.12 | 실사 질감 및 텍스트 렌더링 강화 |
| Qwen-Image-2.0 | 2026.02 | 통합 아키텍처, 7B 경량화, 네이티브 2K 지원 |
가격 참고
| 채널 | 모델 | 참고 가격 |
|---|---|---|
| 알리바바 클라우드 DashScope | qwen-image-max | ¥0.50/장 |
| 알리바바 클라우드 DashScope | qwen-image-plus | ¥0.20/장 |
| Replicate | Qwen Image | $0.030/장 |
| Fal.ai | Qwen Image Edit | $0.021/장 |
| APIYI (출시 예정) | Qwen-Image-2.0 | 공식 홈페이지 대비 20% 이상 저렴 |
💡 Qwen-Image-2.0 정식 버전의 가격은 아직 발표되지 않았습니다. **APIYI (apiyi.com)**는 현재 연동 작업을 진행 중이며, 공식 홈페이지보다 20% 이상 저렴한 혜택가를 제공할 예정입니다. 회원가입 시 무료 테스트 크레딧을 받을 수 있으니 많은 기대 부탁드립니다.
자주 묻는 질문(FAQ)
Q1: Qwen-Image-2.0와 Qwen-Image-2512의 차이점은 무엇인가요?
가장 큰 차이점은 2.0 버전이 생성과 편집 기능을 하나의 7B 파라미터 모델로 통합했다는 점이에요. 이전 세대인 2512는 텍스트-이미지 생성 전용 20B 모델이었고, 이미지 편집을 위해서는 Qwen-Image-Edit을 별도로 불러와야 했죠. 또한 2.0 버전은 네이티브 2K 해상도와 1000 토큰의 긴 프롬프트를 지원하며, 이미지 품질과 텍스트 렌더링 측면에서도 눈에 띄게 향상되었습니다.
Q2: Qwen-Image-2.0를 지금 API로 사용할 수 있나요?
현재 API 초청 테스트 단계이며, chat.qwen.ai에서 무료로 온라인 체험이 가능해요. APIYI(apiyi.com)에서도 현재 연동 작업을 진행 중인데요, 정식 출시되면 공식 홈페이지보다 20% 이상 저렴한 가격으로 제공될 예정입니다. OpenAI 호환 형식을 지원하므로, 키 하나만 있으면 여러 이미지 생성 모델을 간편하게 비교해 볼 수 있습니다.
Q3: Qwen-Image-2.0는 로컬 배포에 적합한가요?
Qwen-Image-2.0의 가중치는 아직 오픈 소스로 공개되지 않았어요. 하지만 이전 세대 전 모델이 Apache-2.0 라이선스로 공개되었던 전례를 볼 때, 커뮤니티에서는 2.0 버전도 곧 오픈 소스화될 것으로 기대하고 있습니다. 7B라는 파라미터 규모는 소비자용 GPU(24GB VRAM)에서도 구동 가능할 것으로 보여요. 오픈 소스 공개를 기다리는 동안에는 APIYI(apiyi.com)를 통해 API 방식으로 성능을 먼저 확인해 보시는 것을 추천드려요.
요약
Qwen-Image-2.0의 핵심 포인트:
- 통합 아키텍처가 가장 큰 특징: 하나의 7B 모델로 생성과 편집을 모두 수행하며, 이전 세대에서 두 개의 20B 모델이 필요했던 작업을 대체합니다.
- 품질 저하 없는 경량화: 파라미터는 65% 줄었지만, 이미지 품질과 기능 범위는 오히려 전반적으로 향상되었습니다.
- 중국어 환경에서의 독보적 성능: 이중 언어 텍스트 렌더링, 다양한 폰트 지원 등 중국어 텍스트가 포함된 이미지 생성에 최적화되어 있습니다.
- API 연동 예정: 현재 테스트 중이며, 곧 정식 버전을 만나보실 수 있습니다.
Qwen-Image-2.0는 중국산 AI 이미지 생성 모델의 중요한 돌파구를 마련했습니다. 고품질의 중국어 텍스트가 포함된 콘텐츠를 제작해야 하는 팀에게는 현재 가장 주목해야 할 모델 중 하나예요.
최신 연동 소식과 공식 홈페이지 대비 20% 이상 저렴한 혜택을 받으시려면 APIYI(apiyi.com)를 확인해 보세요. 플랫폼에서 제공하는 무료 크레딧과 통합 인터페이스를 통해 여러 모델을 빠르게 비교 검증할 수 있습니다.
📚 참고 자료
-
Qwen 공식 블로그: Qwen-Image-2.0 출시 공지
- 링크:
qwen.ai/blog?id=qwen-image-2.0 - 설명: 공식 기술 분석 및 기능 소개
- 링크:
-
GitHub 저장소: Qwen-Image 프로젝트 메인 페이지
- 링크:
github.com/QwenLM/Qwen-Image - 설명: 오픈 소스 코드, 기술 문서 및 사용 가이드
- 링크:
-
AI Arena 랭킹: 텍스트 투 이미지 및 이미지 편집 순위
- 링크:
arena.ai/leaderboard/text-to-image - 설명: 제3자 독립 평가 순위, 실시간 데이터 업데이트
- 링크:
-
알리바바 클라우드 API 문서: DashScope 이미지 생성 API
- 링크:
help.aliyun.com/zh/model-studio/qwen-image-api - 설명: 공식 API 연동 문서 및 파라미터 설명
- 링크:
작성자: 기술 팀
기술 교류: 댓글을 통해 자유롭게 의견을 나눠주세요. 더 많은 자료는 APIYI apiyi.com 기술 커뮤니티에서 확인하실 수 있습니다.