Many teams automatically migrated all their Gemini traffic to Gemini 3.5 Flash after its GA release on May 19, 2026, including high-frequency, lightweight tasks like translation, subtitle generation, and content moderation. This is a clear misjudgment. For scenarios where inputs and outputs are short, price-sensitive, latency-sensitive, and don't require agentic tool orchestration, Gemini 3.1 Flash-Lite is the true optimal solution—not the more expensive and "all-purpose" Gemini 3.5 Flash. This article systematically compares these two models across six dimensions, using data sourced from official Google DeepMind model cards, LLM-Stats, and Artificial Analysis.

To give you the conclusion upfront: for lightweight scenarios like translation, subtitles, batch classification, and text normalization, I recommend Gemini 3.1 Flash-Lite over Gemini 3.5 Flash. There are six core reasons: it's 6x cheaper for input, 6x cheaper for output, has 2.5x faster time-to-first-token latency, boasts an MMMLU multilingual score of 88.9%, is explicitly positioned by Google for translation, and the agentic strengths of 3.5 Flash are completely unused in translation tasks. I suggest using the $0.05 free credit on APIYI (apiyi.com) to run a set of real translation tasks for a side-by-side comparison; the actual cost and quality differences will be much more intuitive than the benchmark numbers.
Why Gemini 3.1 Flash-Lite is better suited for translation than Gemini 3.5 Flash
The characteristics of translation tasks are very clear: the input is a short source-language text (a few hundred to a few thousand tokens), the output is a short target-language text, and a single invocation doesn't require complex reasoning chains, tool calls, or multimodal fusion. However, they are extremely high-frequency and highly sensitive to cost and latency. This is exactly the scenario for which the Flash-Lite series was designed by Google.
Gemini 3.1 Flash-Lite was released on March 3, 2026. In the official Google blog, it was described as "our most cost-effective AI model yet," and they explicitly listed "massive translation, content classification, moderation, structured data extraction, repetitive agentic tasks" as its sweet spot. DeepMind's model card further notes that it possesses "best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts," with an MMMLU multilingual benchmark score of 88.9%, placing it at the top of the lightweight tier.
Gemini 3.5 Flash, which reached GA on May 19, is the "Agentic Flash." It's positioned as a "tool orchestration + coding powerhouse," outperforming Gemini 3.1 Pro on Terminal-Bench 2.1, MCP Atlas, and Finance Agent v2. But these agentic capabilities are completely useless for translation tasks, and the premium you pay for them is pure waste. This is why the "Flash series" is split by task type: use 3.5 Flash for agents, and 3.1 Flash-Lite for translation, classification, and moderation.
🎯 Core Selection Advice: Don't be misled by the intuition that "a higher version number is always better." Gemini 3.5 Flash (released in May) and Gemini 3.1 Flash-Lite (released in March) are two parallel product lines covering "agentic heavy lifting" and "high-throughput lightweight tasks," respectively. The APIYI (apiyi.com) platform offers both models, allowing you to automatically route requests based on task type under the same API key, so you don't have to choose just one.
Gemini 3.5 Flash vs. Gemini 3.1 Flash-Lite Specification Comparison
By placing both models in a single table, the division of labor within the product line and the differences in capabilities become clear at a glance. The table below summarizes the core specifications of both models, with all data sourced from the Google DeepMind model card and public LLM-Stats pages.
| Comparison Dimension | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Translation Scenario Winner |
|---|---|---|---|
| Release Date | May 19, 2026 | March 3, 2026 | — |
| Release Status | GA (General Availability) | Preview | — |
| Model ID | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Positioning | Agentic Flash · Tool Orchestration | High-volume · Lightweight | Flash-Lite |
| Context Window | 1M Input / 64K Output | 1M Input / 64K Output | Tie |
| Input Modalities | Text+Image+Audio+Video | Text+Image+Voice+Video | Tie |
| Thinking Mode | Dynamic thinking enabled by default | Adjustable thinking levels | Flash-Lite (can be disabled) |
| Knowledge Cutoff | January 2026 | January 2025 | 3.5 Flash |
| MMMLU Multilingual | Not announced (est. 80+) | 88.9% | Flash-Lite |
| Output Speed | ~289 tokens/s | 45% faster than 2.5 Flash, 2.5x faster TTFT | Flash-Lite |
| Agent Tool Capability | Outperforms 3.1 Pro on multiple benchmarks | Standard function calling | Not needed for translation |
| APIYI Integration | Available | Available | Tie |
When reading this table, focus on three key points of divergence. First, the positioning difference: Flash-Lite is designed for "high-volume," meaning Google baked "throughput over individual intelligence" into the product's DNA during the design phase, which perfectly matches the needs of high-frequency tasks like translation and classification. Second, the 88.9% MMMLU score is the highest multilingual benchmark for a lightweight model in the Gemini 3.x family, which directly reflects translation quality. Third, the "adjustable thinking level" allows you to disable thinking in Flash-Lite, further reducing latency for zero-thought tasks like translation.
Cost Comparison in Translation Scenarios: The 6x Price Gap Between Gemini 3.5 Flash and 3.1 Flash-Lite
Cost is the most critical metric for selecting a model for translation. Translation tasks are characterized by "short inputs/outputs but extremely high frequency." A typical SaaS product might process tens to hundreds of millions of tokens per day; a 6x price difference translates to a monthly bill difference of thousands to tens of thousands of dollars.
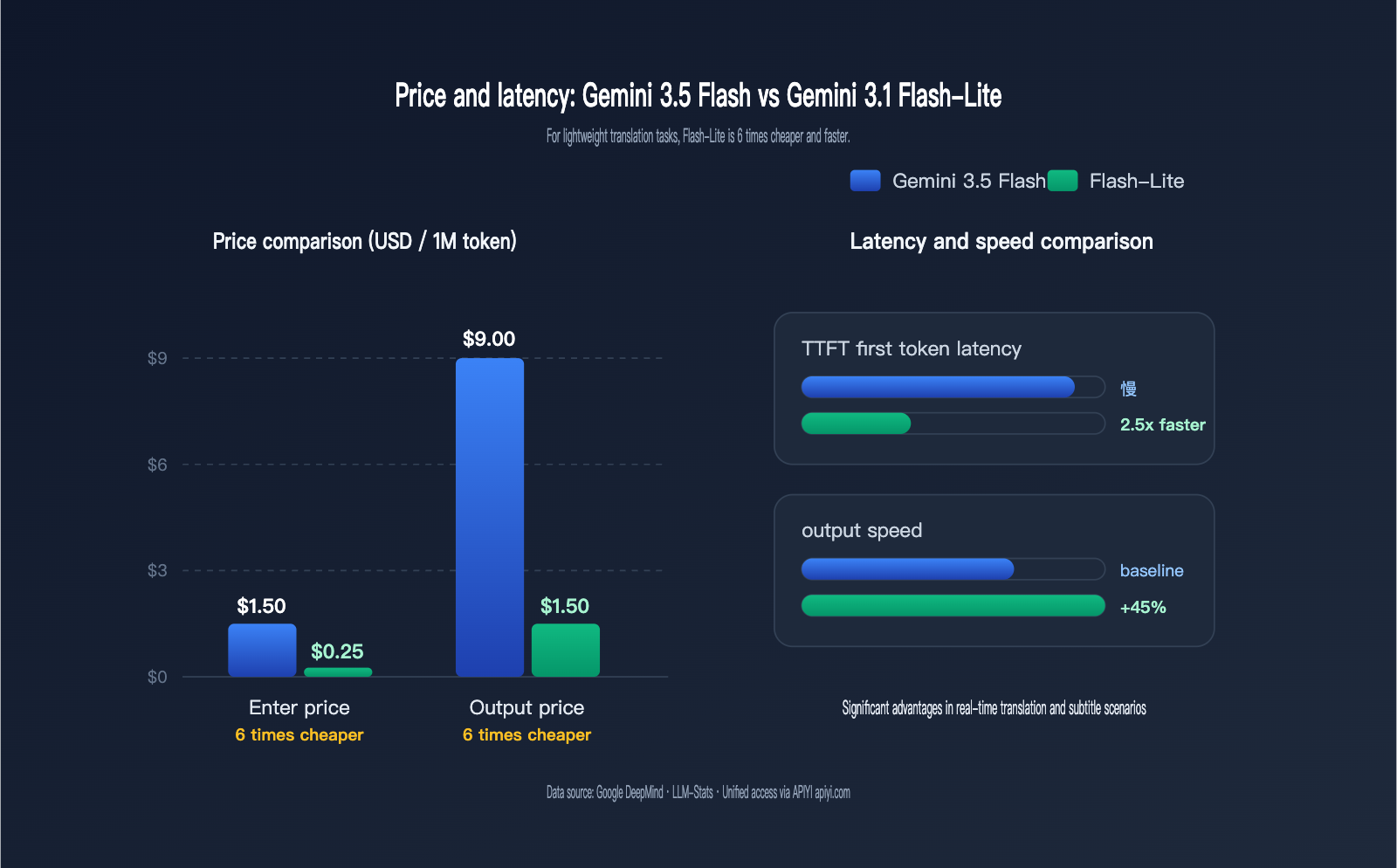
The table below compares the key cost dimensions for both models in translation scenarios. All prices are in USD per 1 million tokens.
| Cost/Performance Dimension | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Gap |
|---|---|---|---|
| Input Price | $1.50 | $0.25 | Flash-Lite is 6x cheaper |
| Output Price | $9.00 | $1.50 | Flash-Lite is 6x cheaper |
| Cached Input | $0.15 | $0.025 (est.) | Flash-Lite is 6x cheaper |
| TTFT (First Token Latency) | Lower | 2.5x faster than 2.5 Flash | Flash-Lite |
| Output Speed | ~289 tokens/s | 45% faster than 2.5 Flash | Tie/Slightly better Flash-Lite |
| Default Thinking Mode | Enabled, has thinking overhead | Can be disabled, zero thinking latency | Flash-Lite |
Let's run a real-world billing simulation. Suppose a SaaS translation product processes 10 million input tokens and 5 million output tokens daily (a medium-sized B2C application). What would the monthly bill look like for each model?
| Monthly Bill (10M input / 5M output per day) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Savings |
|---|---|---|---|
| Daily Input Cost | $15.00 | $2.50 | $12.50 |
| Daily Output Cost | $45.00 | $7.50 | $37.50 |
| Daily Total | $60.00 | $10.00 | $50 |
| Monthly Total (30 days) | $1,800 | $300 | $1,500 / month |
| Annual Total | $21,600 | $3,600 | $18,000 / year |
💡 Cost Estimation Tip: Plug your own actual traffic numbers into this table; the monthly difference is usually in the thousands of dollars. We recommend registering an account on APIYI (apiyi.com) to get the $0.05 free credit, then use the same set of translation samples to call
gemini-3.5-flashandgemini-3.1-flash-lite-preview. This allows you to verify quality differences while getting real-world cost data for your specific business.
Gemini 3.1 Flash-Lite Translation Quality and Speed Analysis
Low prices don't mean much if the translation quality isn't up to par. The real-world data for Gemini 3.1 Flash-Lite in translation tasks is actually quite impressive; in the vast majority of scenarios, users won't feel that its translation quality is "significantly worse than Flash." The following four sets of data serve as core evidence.
First is its 88.9% score on the MMMLU multilingual benchmark. MMMLU (Multilingual MMLU) evaluates a model's ability to understand professional knowledge and reason across 15+ languages. Flash-Lite reaching 88.9% in this metric places it firmly in the top tier among all Flash-Lite class models, meaning it maintains high quality in non-Latin scripts such as Chinese, Japanese, Korean, and Arabic.
Second is the official statement from Google DeepMind in the model card: "best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts." This is Google's official endorsement of Flash-Lite's translation capabilities, specifically highlighting improvements in "non-Latin scripts"—which is particularly critical for Chinese SaaS applications.
Third is the conclusion from the Lara Translate Translation Model Benchmark in February 2026: Flash series variants are positioned as the top choice for "lower latency and higher throughput workflows." The core constraints of translation tasks (low latency + high throughput + cost sensitivity) align perfectly with Flash-Lite's design goals.
Fourth is the Time-to-First-Token (TTFT) and output speed. Flash-Lite's TTFT is 2.5x faster than Gemini 2.5 Flash, with a 45% increase in output speed. In "real-time sensitive" scenarios like translation, these two metrics directly determine the user experience. We recommend testing the time it takes to translate a 5,000-character Chinese text into English on APIYI (apiyi.com); the difference is quite intuitive.
Scenario Recommendations: When to choose Flash-Lite vs. 3.5 Flash
We can condense the comparison across six dimensions into specific task selection recommendations, summarized in the table below. This doesn't solve "which model is stronger," but rather "which one to use for each specific task."
| Task Type | Recommended Model | Key Reason |
|---|---|---|
| General Text Translation (CN-EN/CN-JP, etc.) | Gemini 3.1 Flash-Lite | MMMLU 88.9% + 6x cheaper |
| Subtitle Translation / Real-time Translation | Gemini 3.1 Flash-Lite | 2.5x faster TTFT + 45% faster output |
| Content Moderation / Text Classification | Gemini 3.1 Flash-Lite | Google's official sweet spot, best for batch tasks |
| Structured Data Extraction | Gemini 3.1 Flash-Lite | Ideal for large-scale JSON extraction |
| Multilingual Chatbot | Gemini 3.1 Flash-Lite | Multilingual quality + low latency + low cost |
| Translation + Post-processing Agent | Gemini 3.5 Flash | Requires function calling to chain multiple tools |
| Translation + Tool Invocation | Gemini 3.5 Flash | Agent capabilities surpass 3.1 Pro |
| Code Assistant / IDE Completion | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76.2% |
| Long-document RAG Q&A | Gemini 3.5 Flash | Cache hit + 1M context window |
| Complex Agent Workflows | Gemini 3.5 Flash | MCP Atlas 83.6% |
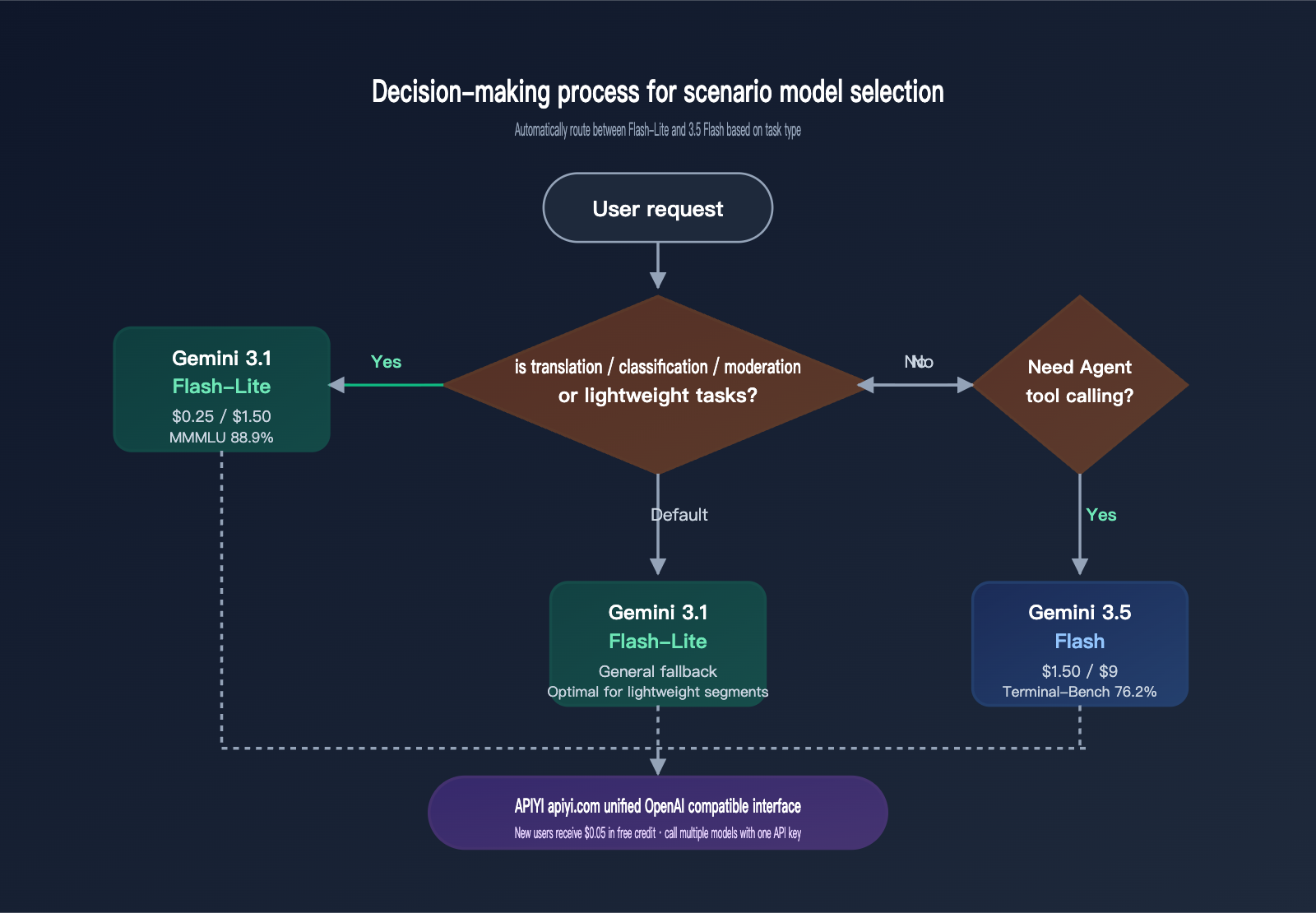
The most ideal strategy in practice remains "task-based routing": use gemini-3.1-flash-lite-preview for translation/classification/moderation, and gemini-3.5-flash for Agents/coding/long-document RAG. Both models can be switched using the same APIYI (apiyi.com) authentication key. This allows you to capture the 6x cost benefit of Flash-Lite for lightweight tasks while retaining the capability ceiling of 3.5 Flash for heavy-duty Agent work.
Typical Scenarios for Choosing Gemini 3.1 Flash-Lite
If any aspect of your product meets the following characteristics, Flash-Lite is almost certainly the better choice: daily calls exceeding 100,000, single input/output within 5K tokens, sensitivity to P95 latency, no need for tool invocation, and a requirement for multilingual support. Typical scenarios include cross-border e-commerce product translation, SaaS multilingual customer service, content moderation pipelines, subtitle generation, and batch OCR normalization. With APIYI's OpenAI-compatible interface, migration costs are virtually zero.
Typical Scenarios for Recommending Gemini 3.5 Flash
If your task involves "translating and then calling a tool" or "embedding translation into a complex Agent chain," Gemini 3.5 Flash is the way to go. For example: translation + knowledge base retrieval + calling an external API, or when a user submits foreign language text → the model translates it first → then calls a calculator/search/code execution tool. Using Flash-Lite for these tasks will lead to frequent errors due to the lack of Agent capabilities, ultimately resulting in higher costs.
Integrating Gemini 3.1 Flash-Lite for Translation Tasks via APIYI
Here is a streamlined Python integration example optimized for translation tasks. It shows you how to perform a model invocation for Gemini 3.1 Flash-Lite on APIYI (apiyi.com) while maintaining full compatibility with the OpenAI SDK.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Translate the user input to {target_lang}. Output the translation only, no explanation."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
View full implementation with batch concurrency and fallback routing
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Translate to {target_lang}. Output translation only."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Translate to {target_lang}. Output translation only."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Batch Translation Optimization Tips: Translation tasks perform best with high concurrency (
concurrency=20~50), a lower temperature (0.1-0.3), and a concise system prompt. The APIYI platform has optimized routing for high-throughput scenarios. New users receive $0.05 in free credits upon registration; at Flash-Lite's $0.25/$1.50 pricing, this is enough to translate roughly 50k-100k tokens of real content, which is plenty for a full stress test of your batch translation pipeline.
Gemini 3.5 Flash vs. 3.1 Flash-Lite Translation FAQ
Q1: Gemini 3.1 Flash-Lite is a Preview version; can I use it in production?
Yes, but it's best to have a backup plan. Flash-Lite has been in the Preview stage since March 3, 2026. While Google hasn't announced a specific GA date, the API interface and pricing are stable. For production, I recommend a dual-model strategy: use Flash-Lite as your primary route with a fallback to 3.5 Flash. You can handle this routing seamlessly via the unified APIYI interface to avoid single-point dependencies. When Google promotes it to GA or releases a 3.5 Flash-Lite, you'll only need to update the model field to migrate smoothly.
Q2: Can Flash-Lite really match Flash in translation quality?
For over 90% of general translation tasks, yes. The Google DeepMind model card explicitly states that Flash-Lite features "best-in-class translation and multilingual understanding," with an MMMLU multilingual score of 88.9%. However, 3.5 Flash still holds an edge in two scenarios: long-form translations involving highly technical terminology (medical, legal, financial) and tasks requiring translation combined with complex contextual reasoning (e.g., resolving pronoun references based on context). I suggest running a set of real business samples on APIYI for an A/B test rather than relying solely on benchmarks.
Q3: Is it appropriate to replace GPT-4o-mini or Claude Haiku 4.5 with Flash-Lite for translation?
Absolutely. It's usually faster and more cost-effective. Gemini 3.1 Flash-Lite's $0.25/$1.50 pricing is competitive, and its 88.9% MMMLU multilingual benchmark outperforms many peers in its class. I recommend using APIYI to test all three candidate models under the same API key to see which one works best for your specific language pairs.
Q4: Can Flash-Lite’s 1M context window really be used for translation?
Yes, and it's arguably its most underrated capability. A 1M token context window is equivalent to roughly 700k-800k English words or 300k-400k Chinese characters—enough to translate an entire medium-length book or a comprehensive set of corporate documents in one go. With "thinking" mode disabled, the cost for a single 1M-token translation is approximately $0.25 for input and $1.50 for output, which is significantly cheaper than splitting the same content across multiple 3.5 Flash or GPT-5.5 calls. APIYI has fully enabled the 1M context window for Flash-Lite, ready for you to use.
Summary: Gemini 3.1 Flash-Lite is the 6x Cost-Effective Winner for Translation Tasks
Let's get straight to the core takeaway: For lightweight, high-frequency tasks like translation, Gemini 3.1 Flash-Lite isn't just a "downgraded" version of Gemini 3.5 Flash—it's the optimal solution Google specifically designed for these scenarios. Five key facts cement its dominance in translation: it's 6x cheaper for both input and output, delivers a 2.5x faster time-to-first-token, boasts an impressive 88.9% score on the MMMLU multilingual benchmark, and Google explicitly highlights translation as its "sweet spot." The strengths of Gemini 3.5 Flash in agentic workflows and coding are completely irrelevant here; paying the premium for those capabilities is simply a waste.
The most sensible strategy is a dual-model routing approach: use gemini-3.1-flash-lite-preview for translation, classification, and moderation tasks, while reserving gemini-3.5-flash for agents, coding, and long-document RAG. You can easily switch between them using the unified, OpenAI-compatible interface provided by APIYI (apiyi.com) under a single API key. New users receive a $0.05 free credit upon registration—plenty to stress-test a full batch translation pipeline and calculate the actual cost savings for your specific business use case.
Author: APIYI Technical Team · apiyi.com
Published: May 20, 2026
References: Google DeepMind Model Card, Google Blog, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub