De nombreuses équipes, après la disponibilité générale (GA) de Gemini 3.5 Flash le 19 mai 2026, ont migré par défaut tout leur trafic vers ce modèle, y compris pour des tâches légères et à haute fréquence comme la traduction, la génération de sous-titres ou la modération de contenu. C'est en réalité une erreur de jugement manifeste. Pour des scénarios où les entrées et sorties sont courtes, extrêmement sensibles au prix unitaire, très sensibles à la latence et ne nécessitant pas d'orchestration d'outils (Agent), Gemini 3.1 Flash-Lite est la véritable solution optimale, et non le Gemini 3.5 Flash, plus coûteux et plus "polyvalent". Cet article compare systématiquement ces deux modèles selon 6 dimensions, en s'appuyant sur des données provenant des fiches techniques officielles de Google DeepMind, de LLM-Stats et d'Artificial Analysis.

Pour aller droit au but : dans les scénarios légers comme la traduction, les sous-titres, la classification par lots ou la normalisation de texte, je recommande Gemini 3.1 Flash-Lite plutôt que Gemini 3.5 Flash. Les raisons principales sont au nombre de six : une entrée 6 fois moins chère, une sortie 6 fois moins chère, une latence du premier jeton 2,5 fois plus rapide, un score multilingue MMMLU atteignant 88,9 %, une spécialisation officielle de Google pour la traduction, et le fait que les capacités d'agent du 3.5 Flash sont totalement inutiles pour la traduction. Je vous suggère d'utiliser le crédit gratuit de 0,05 $ d'APIYI (apiyi.com) pour effectuer une série de tests de traduction réels ; les écarts de coût et de qualité seront bien plus parlants que les chiffres théoriques.
Pourquoi Gemini 3.1 Flash-Lite est plus compétent que Gemini 3.5 Flash pour la traduction
Les caractéristiques des tâches de traduction sont très claires : l'entrée est un texte court en langue source (quelques centaines à quelques milliers de jetons), la sortie est un texte court en langue cible. L'invocation unique ne nécessite pas de chaîne de réflexion, pas d'appel d'outils, pas de fusion multimodale, mais la fréquence d'appel est extrêmement élevée et la sensibilité au coût et à la latence est critique. C'est précisément le scénario pour lequel la série Flash-Lite a été conçue par Google.
Gemini 3.1 Flash-Lite est sorti le 3 mars 2026. Le blog officiel de Google le qualifie de "notre modèle d'IA le plus rentable à ce jour" et place explicitement la "traduction massive, la classification de contenu, la modération, l'extraction de données structurées et les tâches répétitives d'agent" comme son domaine de prédilection. La fiche technique de DeepMind précise en outre qu'il possède une "traduction et une compréhension multilingue de premier ordre, avec des améliorations notables pour les écritures non latines", avec un score de référence multilingue MMMLU de 88,9 %, ce qui le place au sommet de sa catégorie.
Gemini 3.5 Flash, sorti le 19 mai, est le modèle "Agentic Flash". Il est positionné comme un outil d'orchestration d'agents et un moteur de codage, surpassant Gemini 3.1 Pro sur Terminal-Bench 2.1, MCP Atlas et Finance Agent v2. Cependant, ces capacités d'agent sont totalement inutiles pour la traduction, et la prime que vous payez pour ces fonctionnalités est un pur gaspillage. C'est pourquoi la série "Flash" est segmentée par type de tâche : le 3.5 Flash pour les agents, et le 3.1 Flash-Lite pour la traduction, la classification et la modération.
🎯 Conseil de sélection : ne vous laissez pas induire en erreur par l'intuition selon laquelle "un numéro de version plus élevé est forcément meilleur". Gemini 3.5 Flash (publié en mai) et Gemini 3.1 Flash-Lite (publié en mars) sont deux gammes de produits parallèles, couvrant respectivement les besoins en "agents" et en "tâches légères à haut débit". La plateforme APIYI (apiyi.com) propose les deux modèles, permettant un routage automatique selon le type de tâche sous une même clé API, sans avoir à choisir entre les deux.
Comparaison des spécifications : Gemini 3.5 Flash vs Gemini 3.1 Flash-Lite
En comparant ces deux modèles, la répartition des rôles et les différences de capacités deviennent évidentes. Le tableau ci-dessous résume les spécifications clés des deux modèles, basées sur les fiches techniques de Google DeepMind et les données publiques de LLM-Stats.
| Dimension de comparaison | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Avantage traduction |
|---|---|---|---|
| Date de sortie | 19 mai 2026 | 3 mars 2026 | — |
| État de publication | GA (Disponibilité générale) | Preview (Aperçu) | — |
| ID du modèle | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Positionnement | Agentic Flash · Orchestration d'outils | High-volume · Léger à haut débit | Flash-Lite |
| Fenêtre de contexte | 1M entrée / 64K sortie | 1M entrée / 64K sortie | Égalité |
| Modalités d'entrée | Texte+Image+Audio+Vidéo | Texte+Image+Voix+Vidéo | Égalité |
| Mode de réflexion | Réflexion dynamique activée par défaut | Niveau de réflexion ajustable | Flash-Lite (désactivable) |
| Date limite de connaissances | Janvier 2026 | Janvier 2025 | 3.5 Flash |
| MMMLU multilingue | Non publié (estimé à 80+) | 88,9 % | Flash-Lite |
| Vitesse de sortie | Env. 289 jetons/s | 45 % plus rapide que 2.5 Flash, TTFT 2,5x plus rapide | Flash-Lite |
| Capacité d'outils Agent | Surpasse 3.1 Pro sur plusieurs benchmarks | Appel de fonction standard | Non requis pour la traduction |
| Intégration APIYI | Disponible | Disponible | Égalité |
Lors de la lecture de ce tableau, trois points de divergence méritent votre attention. Premièrement, la différence de positionnement : le Flash-Lite est axé sur le "haut volume", ce qui signifie que Google a intégré la priorité au débit sur l'intelligence brute dès la conception, ce qui correspond parfaitement aux besoins des tâches à haute fréquence comme la traduction ou la classification. Deuxièmement, le score MMMLU de 88,9 % représente le modèle léger le plus performant en multilingue de la famille Gemini 3.x, ce qui se traduit directement par une meilleure qualité de traduction. Troisièmement, le "niveau de réflexion ajustable" permet de désactiver le mode réflexion sur le Flash-Lite, réduisant ainsi la latence pour des tâches de traduction qui ne nécessitent pas de raisonnement complexe.
Comparaison des coûts en traduction : l'écart de prix de 6x entre Gemini 3.5 Flash et 3.1 Flash-Lite
Le coût est l'indicateur le plus critique pour le choix d'un modèle dans un scénario de traduction. Les tâches de traduction se caractérisent par des entrées et sorties courtes, mais une fréquence extrêmement élevée. Un produit SaaS courant peut traiter des dizaines, voire des centaines de millions de jetons par jour ; un écart de prix de 6x signifie une différence de facture mensuelle allant de quelques milliers à plusieurs dizaines de milliers de dollars.
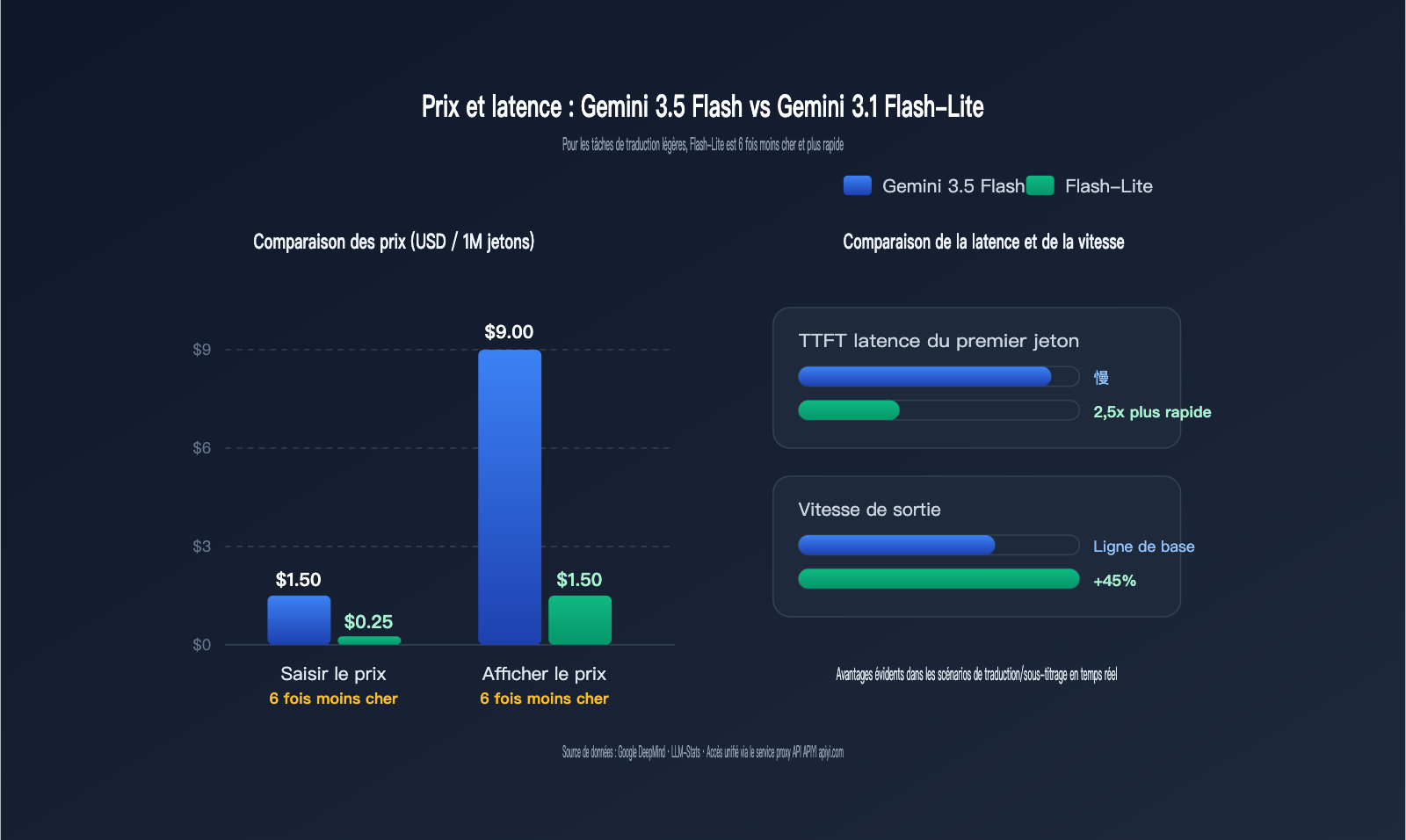
Le tableau suivant compare les dimensions de coût les plus critiques pour la traduction, avec des prix par million de jetons en dollars.
| Dimension coût/performance | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Écart |
|---|---|---|---|
| Prix entrée | 1,50 $ | 0,25 $ | Flash-Lite 6x moins cher |
| Prix sortie | 9,00 $ | 1,50 $ | Flash-Lite 6x moins cher |
| Entrée cache hit | 0,15 $ | 0,025 $ (est.) | Flash-Lite 6x moins cher |
| TTFT (latence premier jeton) | Plus élevée | 2,5x plus rapide que 2.5 Flash | Flash-Lite |
| Vitesse de sortie | Env. 289 jetons/s | 45 % plus rapide que 2.5 Flash | Égalité/Léger avantage Flash-Lite |
| Mode réflexion par défaut | Activé, avec coût de réflexion | Désactivable, latence zéro | Flash-Lite |
Simulons une facture réelle. Supposons qu'un produit de traduction SaaS traite 10 millions de jetons en entrée et 5 millions en sortie par jour (échelle B2C moyenne). À quoi ressemblerait la facture mensuelle pour chaque modèle ?
| Facture mensuelle (10M entrée / 5M sortie par jour) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Économies |
|---|---|---|---|
| Coût entrée quotidien | 15,00 $ | 2,50 $ | 12,50 $ |
| Coût sortie quotidien | 45,00 $ | 7,50 $ | 37,50 $ |
| Total quotidien | 60,00 $ | 10,00 $ | 50,00 $ |
| Total mensuel (30 jours) | 1 800 $ | 300 $ | 1 500 $ / mois |
| Total annuel | 21 600 $ | 3 600 $ | 18 000 $ / an |
💡 Conseil d'estimation des coûts : Appliquez ces chiffres à votre propre volume de trafic réel ; l'écart mensuel dépasse généralement les quatre chiffres en dollars. Nous vous suggérons de créer un compte sur APIYI (apiyi.com) pour obtenir un crédit gratuit de 0,05 $, puis d'utiliser le même échantillon de traduction pour appeler
gemini-3.5-flashetgemini-3.1-flash-lite-preview. Cela vous permettra non seulement de vérifier la différence de qualité, mais aussi d'obtenir les coûts réels pour votre propre activité.
Analyse des performances : qualité et vitesse de traduction de Gemini 3.1 Flash-Lite
Un prix bas ne signifie rien si la qualité de traduction n'est pas au rendez-vous. Pourtant, les données réelles sur Gemini 3.1 Flash-Lite sont très convaincantes : dans la grande majorité des cas, les utilisateurs ne remarqueront aucune "différence significative par rapport à Flash". Voici quatre points clés qui le prouvent.
Premièrement, son score de 88,9 % au benchmark multilingue MMMLU. Le MMMLU (Multilingual MMLU) évalue la capacité d'un modèle à comprendre des connaissances spécialisées et à raisonner dans plus de 15 langues. Avec 88,9 %, Flash-Lite se place en tête de sa catégorie, ce qui garantit une traduction de haute qualité pour le chinois, le japonais, le coréen, l'arabe et d'autres langues non latines.
Deuxièmement, Google DeepMind précise explicitement dans sa fiche technique qu'il s'agit d'un modèle "best-in-class pour la traduction et la compréhension multilingue, avec des améliorations notables sur les écritures non latines". C'est une validation officielle de Google, particulièrement cruciale pour les SaaS opérant sur le marché chinois.
Troisièmement, le benchmark de modèles de traduction de Lara Translate (février 2026) conclut que les variantes de la série Flash sont le choix privilégié pour les "flux de travail à faible latence et haut débit". Les contraintes majeures de la traduction (faible latence, haut débit, sensibilité aux coûts) correspondent parfaitement à la conception de Flash-Lite.
Quatrièmement, le Time-to-First-Token (TTFT) et la vitesse de sortie. Le TTFT de Flash-Lite est 2,5 fois plus rapide que celui de Gemini 2.5 Flash, avec une vitesse de sortie augmentée de 45 %. Dans des scénarios où la réactivité est primordiale, ces indicateurs déterminent directement l'expérience utilisateur. Nous vous suggérons de tester le temps nécessaire pour traduire 5 000 caractères chinois vers l'anglais sur APIYI (apiyi.com) : la différence est flagrante.
Recommandations : quand choisir Flash-Lite ou 3.5 Flash ?
Pour passer d'une comparaison théorique à une mise en pratique, voici un tableau récapitulatif. Il ne s'agit pas de déterminer "quel modèle est le plus puissant", mais "lequel utiliser pour chaque tâche spécifique".
| Type de tâche | Modèle recommandé | Raison principale |
|---|---|---|
| Traduction de texte général (Chinois-Anglais/Japonais, etc.) | Gemini 3.1 Flash-Lite | MMMLU 88,9 % + coût divisé par 6 |
| Traduction de sous-titres / Temps réel | Gemini 3.1 Flash-Lite | TTFT 2,5x plus rapide + vitesse +45 % |
| Modération de contenu / Classification | Gemini 3.1 Flash-Lite | Le "sweet spot" officiel de Google, idéal pour le traitement par lots |
| Extraction de données structurées | Gemini 3.1 Flash-Lite | Parfait pour l'extraction JSON à grande échelle |
| Chatbot multilingue | Gemini 3.1 Flash-Lite | Qualité multilingue + faible latence + faible coût |
| Traduction + Agent de post-traitement | Gemini 3.5 Flash | Nécessite l'appel de fonctions (function calling) |
| Traduction + Appel d'outils | Gemini 3.5 Flash | Capacités d'agent supérieures au 3.1 Pro |
| Assistant de code / Complétion IDE | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76,2 % |
| RAG sur longs documents | Gemini 3.5 Flash | Mise en cache + fenêtre de contexte de 1M |
| Flux de travail d'agent complexe | Gemini 3.5 Flash | MCP Atlas 83,6 % |
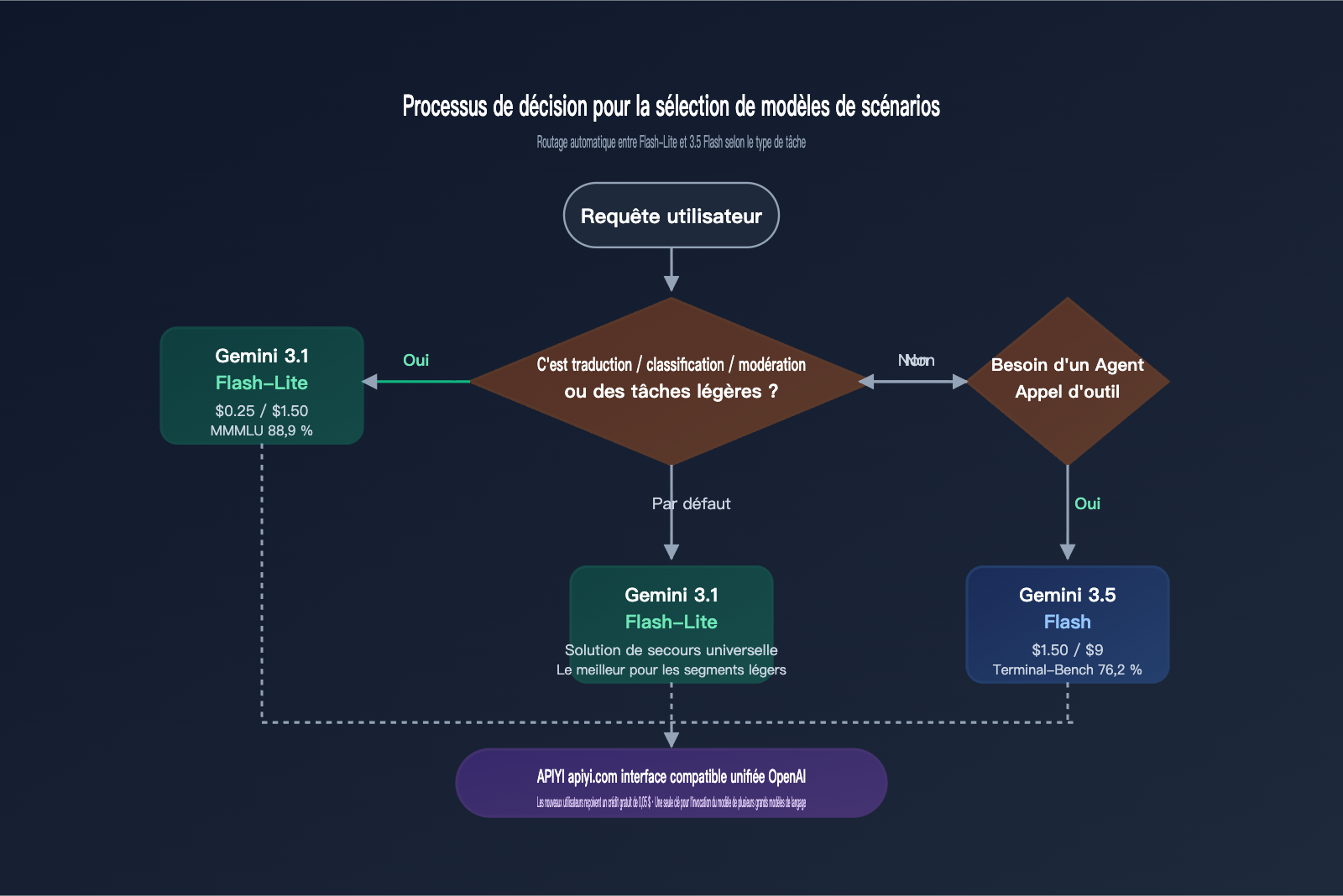
La stratégie idéale reste le routage par tâche : utilisez gemini-3.1-flash-lite-preview pour la traduction, la classification et la modération, et gemini-3.5-flash pour les agents, le codage et le RAG sur longs documents. En utilisant les deux modèles sous une même clé API sur APIYI (apiyi.com), vous profitez des économies de Flash-Lite tout en conservant la puissance de 3.5 Flash pour les tâches complexes.
Scénarios typiques pour Gemini 3.1 Flash-Lite
Si votre produit présente l'une des caractéristiques suivantes, Flash-Lite est presque toujours le meilleur choix : plus de 100 000 appels par jour, entrées/sorties inférieures à 5K tokens, sensibilité à la latence P95, pas besoin d'appel d'outils, besoin de support multilingue. Cela inclut la traduction de produits e-commerce, le support client multilingue, les pipelines de modération, la génération de sous-titres, etc. Grâce à l'interface compatible OpenAI d'APIYI (apiyi.com), le coût de migration est quasi nul.
Scénarios recommandés pour Gemini 3.5 Flash
Si votre tâche nécessite d'appeler des outils après la traduction ou d'intégrer la traduction dans une chaîne d'agents complexe, Gemini 3.5 Flash est indispensable. Par exemple : traduction + recherche dans une base de connaissances + appel d'API externe. Pour ces tâches, Flash-Lite risque d'échouer par manque de capacités d'agent, ce qui rendrait le processus plus coûteux au final.
Exemple d'intégration de Gemini 3.1 Flash-Lite sur APIYI pour la traduction
Voici un exemple d'intégration Python minimaliste optimisé pour la traduction, montrant comment appeler Gemini 3.1 Flash-Lite sur APIYI (apiyi.com) tout en conservant une compatibilité totale avec l'API OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Traduisez l'entrée utilisateur en {target_lang}. Ne renvoyez que la traduction, sans explication."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
Voir l’implémentation complète avec gestion de la concurrence et routage de secours
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Traduisez en {target_lang}. Ne renvoyez que la traduction."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Traduisez en {target_lang}. Ne renvoyez que la traduction."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Conseils d'optimisation pour la traduction par lots : Les scénarios de traduction se prêtent bien à une forte concurrence (
concurrency=20~50), unetemperaturebasse (0.1-0.3) et une invite système courte. La plateforme APIYI (apiyi.com) a optimisé le routage pour les scénarios à haut débit. Les nouveaux utilisateurs reçoivent un crédit gratuit de 0,05 $. Avec la tarification de Flash-Lite à 0,25 $/1,50 $, cela permet de traduire environ 50 000 à 100 000 jetons de contenu réel, ce qui est suffisant pour effectuer un test de charge complet sur un pipeline de traduction par lots.
FAQ : Gemini 3.5 Flash vs 3.1 Flash-Lite pour la traduction
Q1 : Gemini 3.1 Flash-Lite est en version Preview, est-ce utilisable en production ?
Oui, mais prévoyez un plan de secours. Flash-Lite est en phase Preview depuis le 3 mars 2026 et Google n'a pas encore annoncé de date de disponibilité générale (GA), bien que l'interface API et les tarifs soient stables. Pour la production, nous recommandons une stratégie à deux modèles : "modèle principal Flash-Lite + secours 3.5 Flash" via l'interface unifiée d'APIYI (apiyi.com) pour éviter toute dépendance à un point unique. Lorsque Google passera à la version GA ou lancera une version 3.5 Flash-Lite, il suffira de mettre à jour le champ model pour une migration en douceur.
Q2 : La qualité de traduction de Flash-Lite peut-elle vraiment rivaliser avec Flash ?
Dans 90 % des tâches de traduction courantes, oui. La fiche technique de Google DeepMind indique clairement que Flash-Lite possède une "traduction et une compréhension multilingue de premier ordre", avec un score MMMLU multilingue de 88,9 %. Cependant, le 3.5 Flash reste supérieur dans deux cas : les traductions longues impliquant des termes techniques (médical, juridique, financier) et les traductions nécessitant un raisonnement contextuel (par exemple, identifier des références de pronoms). Nous vous conseillons d'effectuer un test comparatif sur vos propres échantillons métier via APIYI (apiyi.com) plutôt que de vous fier uniquement aux benchmarks.
Q3 : Est-il judicieux de remplacer GPT-4o-mini ou Claude Haiku 4.5 par Flash-Lite pour la traduction ?
Oui, c'est souvent plus économique et plus rapide. La tarification de Gemini 3.1 Flash-Lite (0,25 $/1,50 $) est inférieure à celle de GPT-4o-mini (0,15 $/0,60 $, mais avec une qualité de traduction souvent jugée inférieure en pratique) et de Claude Haiku 4.5. Sur les benchmarks multilingues, le score MMMLU de 88,9 % de Flash-Lite surpasse ses concurrents directs. Vous pouvez tester les trois modèles avec la même clé sur APIYI (apiyi.com) pour voir lequel est le plus adapté à vos paires de langues spécifiques.
Q4 : La fenêtre de contexte de 1M de Flash-Lite est-elle vraiment utilisable pour la traduction ?
Absolument, et c'est sans doute sa capacité la plus sous-estimée. 1 million de jetons correspondent à environ 700 000 – 800 000 mots anglais ou 300 000 – 400 000 caractères chinois, ce qui suffit pour traduire d'un seul bloc un livre de taille moyenne ou un ensemble complet de documents d'entreprise. Avec le mode "thinking" désactivé, le coût de traduction pour 1M de jetons est d'environ 0,25 $ en entrée + 1,50 $ en sortie, bien moins cher que de découper le contenu pour 3.5 Flash ou GPT-5.5. APIYI (apiyi.com) a déjà ouvert l'accès à la fenêtre de contexte de 1M de Flash-Lite, prête à l'emploi.
Résumé : Gemini 3.1 Flash-Lite, le choix optimal avec un rapport coût-efficacité multiplié par 6 pour la traduction
Revenons au point central de cet article : pour les tâches légères et répétitives comme la traduction, Gemini 3.1 Flash-Lite n'est pas une version "au rabais" de Gemini 3.5 Flash, mais bien la solution optimale conçue par Google spécifiquement pour ce type de scénario. Voici les cinq faits qui confirment sa domination dans le domaine de la traduction : un coût d'entrée 6 fois moins élevé, un coût de sortie 6 fois moins élevé, une latence du premier jeton 2,5 fois plus rapide, un score multilingue MMMLU atteignant 88,9 %, et le fait que Google lui-même désigne la traduction comme son domaine de prédilection. Les points forts de Gemini 3.5 Flash en matière d'agents et de codage sont totalement inutiles pour la traduction ; payer le surcoût lié à ces capacités serait un pur gaspillage.
La stratégie la plus prudente consiste à utiliser un routage à double modèle : privilégiez gemini-3.1-flash-lite-preview pour la traduction, la classification et la modération, et réservez gemini-3.5-flash pour les agents, le codage et le RAG sur documents longs. Vous pouvez basculer entre les deux via l'interface compatible OpenAI unifiée d'APIYI (apiyi.com) avec une seule clé API. Les nouveaux utilisateurs reçoivent un crédit gratuit de 0,05 $, suffisant pour effectuer un test de charge complet sur un pipeline de traduction par lots et mesurer précisément les économies réelles que ce modèle peut apporter à votre activité.
Auteur : Équipe technique APIYI · apiyi.com
Date de publication : 20 mai 2026
Références : Fiche technique Google DeepMind, Blog Google, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub