Viele Teams haben nach der allgemeinen Verfügbarkeit (GA) von Gemini 3.5 Flash am 19. Mai 2026 standardmäßig ihren gesamten Gemini-Traffic migriert – einschließlich hochfrequenter, leichtgewichtiger Aufgaben wie Übersetzungen, Untertitelgenerierung und Inhaltsmoderation. Das ist ein offensichtlicher Trugschluss. In Szenarien wie Übersetzungen, bei denen Input und Output kurz sind, eine extreme Sensibilität gegenüber Stückpreisen und Latenz besteht und keine Agent-Tool-Orchestrierung erforderlich ist, ist Gemini 3.1 Flash-Lite die wahre optimale Lösung und nicht das teurere und "allumfassendere" Gemini 3.5 Flash. Dieser Artikel vergleicht beide Modelle systematisch anhand von sechs Dimensionen, basierend auf Daten aus den offiziellen Model Cards von Google DeepMind, LLM-Stats, Artificial Analysis und weiteren englischsprachigen Primärquellen.

Hier ist das Fazit direkt vorab: Für leichtgewichtige Szenarien wie Übersetzungen, Untertitel, Batch-Klassifizierung und Textnormalisierung empfehle ich Gemini 3.1 Flash-Lite anstelle von Gemini 3.5 Flash. Die Hauptgründe sind: 6-mal günstigerer Input, 6-mal günstigerer Output, 2,5-mal schnellere Latenz bis zum ersten Token, ein MMMLU-Score für Mehrsprachigkeit von 88,9 %, die explizite Empfehlung von Google für Übersetzungen als "Sweet Spot" und die Tatsache, dass die Agent-Stärken von 3.5 Flash bei Übersetzungen völlig ungenutzt bleiben. Ich empfehle, zunächst über das kostenlose Guthaben von 0,05 USD bei APIYI (apiyi.com) eine Reihe echter Übersetzungsaufgaben für einen Vergleich durchzuführen; die tatsächlichen Kosten- und Qualitätsunterschiede sind anschaulicher als reine Benchmark-Zahlen.
Warum Gemini 3.1 Flash-Lite bei Übersetzungsaufgaben besser abschneidet als Gemini 3.5 Flash
Die Merkmale solcher Aufgaben sind klar definiert: Der Input besteht aus kurzen Texten in der Quellsprache (einige hundert bis tausend Token), der Output aus kurzen Texten in der Zielsprache. Ein einzelner Aufruf erfordert keine Denkprozesse, keine Tool-Nutzung und keine multimodale Fusion, aber die Aufrufhäufigkeit ist extrem hoch und die Sensibilität gegenüber Kosten und Latenz ist maximal. Genau das ist das Szenario, für das die Flash-Lite-Serie von Google entwickelt wurde.
Gemini 3.1 Flash-Lite wurde am 3. März 2026 veröffentlicht. Im offiziellen Google-Blog wird es als "unser bisher kosteneffizientestes KI-Modell" bezeichnet und "massive Übersetzung, Inhaltsklassifizierung, Moderation, strukturierte Datenextraktion und repetitive Agenten-Aufgaben" werden explizit als sein "Sweet Spot" genannt. Die Model Card von DeepMind hebt zudem die "erstklassige Übersetzungsleistung und das Verständnis für mehrere Sprachen mit bemerkenswerten Verbesserungen bei nicht-lateinischen Schriften" hervor. Mit einem MMMLU-Score von 88,9 % im Bereich der Mehrsprachigkeit gehört es zur absoluten Spitze bei den leichtgewichtigen Modellen.
Gemini 3.5 Flash ist das am 19. Mai veröffentlichte "Agentic Flash"-Modell, das auf "Agent-Tool-Orchestrierung + Coding-Power" ausgerichtet ist und bei Benchmarks wie Terminal-Bench 2.1, MCP Atlas und Finance Agent v2 das Gemini 3.1 Pro übertrifft. Diese Agenten-Fähigkeiten sind bei Übersetzungsaufgaben jedoch völlig überflüssig – der Aufpreis, den Sie für diese Funktionen zahlen, ist reine Verschwendung. Deshalb unterteilt Google die "Flash-Serie" nach Aufgabentyp: 3.5 Flash für Agenten-Aufgaben, 3.1 Flash-Lite für Übersetzungen, Klassifizierungen und Moderation.
🎯 Kernempfehlung zur Modellauswahl: Lassen Sie sich nicht von der Intuition leiten, dass eine höhere Versionsnummer automatisch besser ist. Gemini 3.5 Flash (Mai-Release) und Gemini 3.1 Flash-Lite (März-Release) sind zwei parallele Produktlinien, die jeweils die Bereiche "Agent-Power" und "High-Throughput-Leichtgewicht" abdecken. Die Plattform APIYI (apiyi.com) bietet beide Modelle an, sodass Sie unter demselben API-Schlüssel je nach Aufgabentyp automatisch routen können, anstatt sich für eines entscheiden zu müssen.
Spezifikationsvergleich: Gemini 3.5 Flash vs. Gemini 3.1 Flash-Lite
Wenn man beide Modelle in einer Tabelle gegenüberstellt, werden die Unterschiede in der Produktpositionierung und den Fähigkeiten sofort deutlich. Die folgende Tabelle fasst die Kernspezifikationen beider Modelle zusammen. Alle Daten stammen aus den offiziellen Model Cards von Google DeepMind sowie von der öffentlichen LLM-Stats-Seite.
| Vergleichsdimension | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Sieger im Übersetzungsszenario |
|---|---|---|---|
| Veröffentlichungsdatum | 19. Mai 2026 | 3. März 2026 | — |
| Status | GA (Allgemeine Verfügbarkeit) | Preview (Vorschau) | — |
| Modell-ID | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Positionierung | Agentic Flash · Tool-Orchestrierung | High-Volume · Leichtgewicht für hohen Durchsatz | Flash-Lite |
| Kontextfenster | 1M Input / 64K Output | 1M Input / 64K Output | Unentschieden |
| Eingabemodalitäten | Text+Bild+Audio+Video | Text+Bild+Sprache+Video | Unentschieden |
| Denkmodus | Dynamisches Denken standardmäßig aktiv | Denkstufe einstellbar | Flash-Lite (abschaltbar) |
| Wissensstand | Januar 2026 | Januar 2025 | 3.5 Flash |
| MMMLU Mehrsprachigkeit | Nicht veröffentlicht (erwartet 80+) | 88,9 % | Flash-Lite |
| Ausgabegeschwindigkeit | ca. 289 Token/s | 45 % schneller als 2.5 Flash, TTFT 2,5x schneller | Flash-Lite |
| Agent-Tool-Fähigkeiten | Übertrifft 3.1 Pro in mehreren Benchmarks | Standard-Funktionsaufruf | Für Übersetzung nicht relevant |
| APIYI-Anbindung | Verfügbar | Verfügbar | Unentschieden |
Beim Lesen dieser Tabelle sollten Sie sich auf drei Punkte konzentrieren. Erstens die Positionierung: Flash-Lite ist auf „High-Volume“ ausgelegt. Das bedeutet, dass Google bereits in der Designphase „Durchsatz vor Intelligenz“ in die Produkt-DNA geschrieben hat – ideal für hochfrequente Aufgaben wie Übersetzungen oder Klassifizierungen. Zweitens der MMMLU-Wert von 88,9 %: Dies ist das leistungsfähigste Leichtgewichtsmodell für Mehrsprachigkeit in der Gemini 3.x-Familie, was sich direkt in der Übersetzungsqualität widerspiegelt. Drittens die „einstellbare Denkstufe“: Flash-Lite erlaubt das Abschalten des Denkprozesses, was bei Übersetzungen, die keine komplexe Logik erfordern, die Latenz weiter senkt.
Kostenvergleich bei Übersetzungen: Der 6-fache Preisunterschied zwischen Gemini 3.5 Flash und 3.1 Flash-Lite
Die Kosten sind der wichtigste Indikator bei der Modellauswahl für Übersetzungen. Übersetzungsszenarien zeichnen sich durch „kurze Ein- und Ausgaben bei extrem hoher Frequenz“ aus. Ein typisches SaaS-Produkt verarbeitet täglich Millionen bis Milliarden von Token; ein Preisunterschied von Faktor 6 bedeutet monatliche Differenzen von mehreren tausend bis zehntausend Dollar.
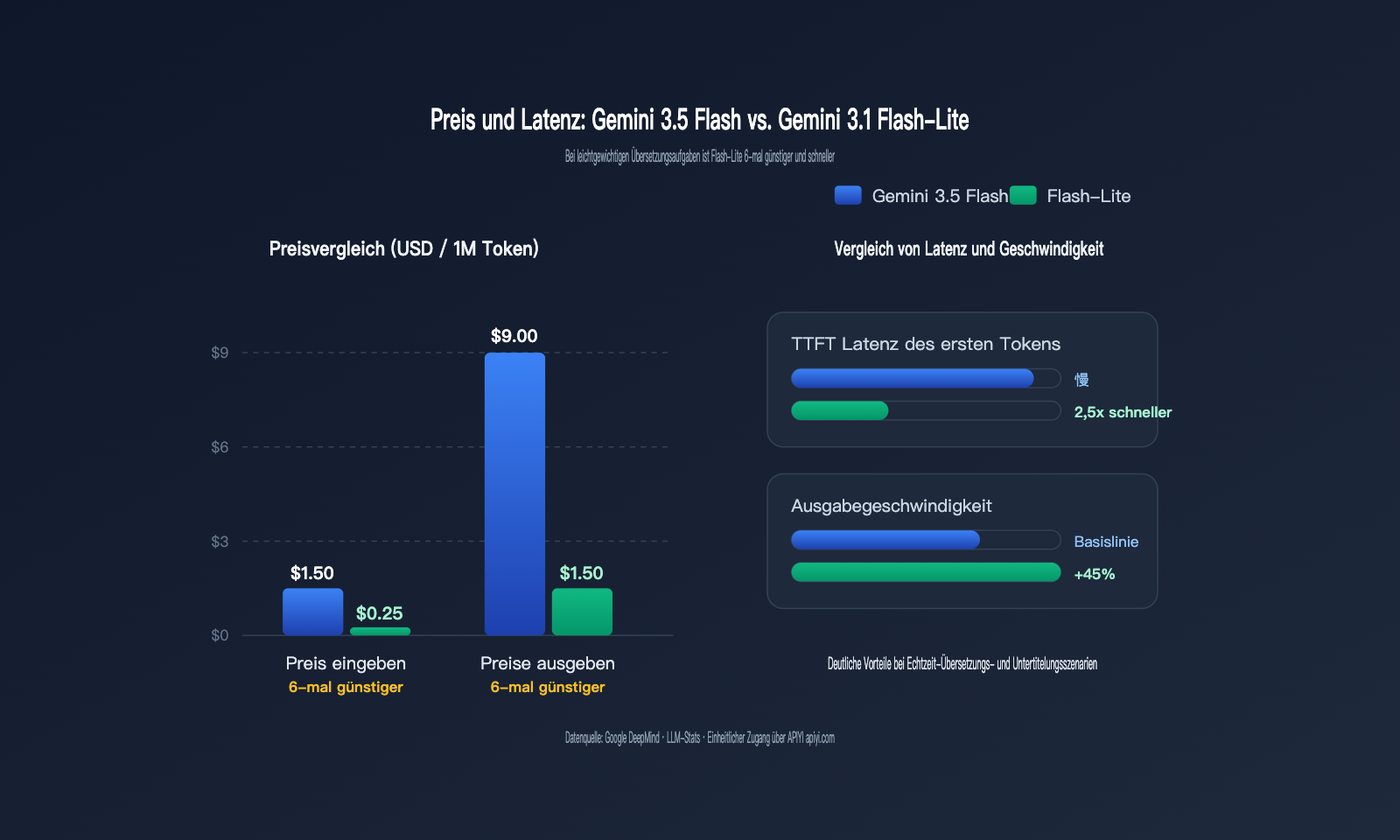
Die folgende Tabelle vergleicht die entscheidenden Kostendimensionen für Übersetzungsszenarien. Alle Preise beziehen sich auf 1 Million Token.
| Kosten/Leistungs-Dimension | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Differenz |
|---|---|---|---|
| Input-Preis | 1,50 $ | 0,25 $ | Flash-Lite 6x günstiger |
| Output-Preis | 9,00 $ | 1,50 $ | Flash-Lite 6x günstiger |
| Cache-Hit Input | 0,15 $ | 0,025 $ (geschätzt) | Flash-Lite 6x günstiger |
| TTFT (Latenz bis 1. Token) | Niedrig | 2,5x schneller als 2.5 Flash | Flash-Lite |
| Ausgabegeschwindigkeit | ca. 289 Token/s | 45 % schneller als 2.5 Flash | Gleichstand/leicht besser |
| Denkmodus | Standardmäßig aktiv (Kosten) | Abschaltbar (keine Denk-Latenz) | Flash-Lite |
Lassen Sie uns eine reale Kostenrechnung simulieren. Angenommen, ein SaaS-Übersetzungsprodukt verarbeitet täglich 10 Millionen Input-Token und 5 Millionen Output-Token (mittleres B2C-Volumen). Wie sieht die monatliche Rechnung aus?
| Monatsrechnung (tägl. 10 Mio. Input / 5 Mio. Output) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Ersparnis |
|---|---|---|---|
| Tägliche Input-Kosten | 15,00 $ | 2,50 $ | 12,50 $ |
| Tägliche Output-Kosten | 45,00 $ | 7,50 $ | 37,50 $ |
| Täglich gesamt | 60,00 $ | 10,00 $ | 50,00 $ |
| Monatlich gesamt (30 Tage) | 1.800 $ | 300 $ | 1.500 $ / Monat |
| Jährlich gesamt | 21.600 $ | 3.600 $ | 18.000 $ / Jahr |
💡 Tipp zur Kostenkalkulation: Übertragen Sie diese Zahlen auf Ihr tatsächliches Volumen; die monatliche Ersparnis liegt meist im vierstelligen Bereich. Wir empfehlen, sich bei APIYI (apiyi.com) zu registrieren, um ein Startguthaben zu erhalten. Testen Sie beide Modelle (
gemini-3.5-flashundgemini-3.1-flash-lite-preview) mit demselben Datensatz, um sowohl die Qualitätsunterschiede als auch die tatsächliche Kostenersparnis für Ihr Unternehmen zu validieren.
Analyse der Übersetzungsqualität und Geschwindigkeit von Gemini 3.1 Flash-Lite
Ein niedriger Preis ist wertlos, wenn die Übersetzungsqualität nicht stimmt. Die Messdaten von Gemini 3.1 Flash-Lite bei Übersetzungsaufgaben sind jedoch beeindruckend: In den meisten Szenarien werden Nutzer keinen „signifikanten Unterschied zu Flash“ feststellen. Die folgenden vier Datensätze liefern den Kernbeweis.
Erstens der Wert von 88,9 % im MMMLU-Benchmark (Multilingual MMLU). Dieser prüft das Verständnis von Fachwissen und die Schlussfolgerungsfähigkeit in über 15 Sprachen. Mit 88,9 % gehört Flash-Lite zur absoluten Spitze der Modelle seiner Klasse und beweist, dass es auch bei nicht-lateinischen Schriften wie Chinesisch, Japanisch, Koreanisch oder Arabisch eine hohe Qualität beibehält.
Zweitens die offizielle Bestätigung von Google DeepMind in der Model Card: „best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts“. Google hebt hier explizit die Verbesserungen bei nicht-lateinischen Schriften hervor – ein entscheidender Punkt für chinesische SaaS-Anwendungen.
Drittens das Fazit des „Translation Model Benchmark“ von Lara Translate vom Februar 2026: Die Flash-Varianten werden als erste Wahl für „Workflows mit geringer Latenz und hohem Durchsatz“ eingestuft. Die Kernanforderungen an Übersetzungsaufgaben (niedrige Latenz + hoher Durchsatz + Kostensensibilität) passen perfekt zum Designziel von Flash-Lite.
Viertens die Time-to-First-Token (TTFT) und die Ausgabegeschwindigkeit. Die TTFT von Flash-Lite ist 2,5-mal schneller als bei Gemini 2.5 Flash, die Ausgabegeschwindigkeit stieg um 45 %. Diese Kennzahlen bestimmen bei zeitkritischen Übersetzungen direkt das Nutzererlebnis. Wir empfehlen, auf APIYI (apiyi.com) die Zeit für die Übersetzung eines 5000 Zeichen langen chinesischen Textes ins Englische zu testen – der Unterschied ist sehr deutlich.
Szenario-Empfehlung: Wann Flash-Lite und wann 3.5 Flash wählen?
Die folgende Empfehlungstabelle fasst die Entscheidungskriterien für verschiedene Aufgaben zusammen. Es geht nicht darum, welches Modell „stärker“ ist, sondern welches für die jeweilige Aufgabe am besten geeignet ist.
| Aufgabentyp | Empfohlenes Modell | Hauptgrund |
|---|---|---|
| Allgemeine Textübersetzung (Ch-En/Ch-Jp etc.) | Gemini 3.1 Flash-Lite | MMMLU 88,9 % + 6x günstiger |
| Untertitel- / Echtzeitübersetzung | Gemini 3.1 Flash-Lite | 2,5x schnellere TTFT + 45 % mehr Speed |
| Content-Moderation / Textklassifizierung | Gemini 3.1 Flash-Lite | Googles „Sweet Spot“, optimal für Batch-Aufgaben |
| Strukturierte Datenextraktion | Gemini 3.1 Flash-Lite | Ideal für große Mengen an JSON-Extraktionen |
| Mehrsprachige Chatbots | Gemini 3.1 Flash-Lite | Sprachqualität + niedrige Latenz + geringe Kosten |
| Übersetzung + Nachbearbeitungs-Agent | Gemini 3.5 Flash | Erfordert Function Calling für mehrere Tools |
| Übersetzung + Tool-Aufruf | Gemini 3.5 Flash | Agent-Fähigkeiten übertreffen 3.1 Pro |
| Code-Assistent / IDE-Vervollständigung | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76,2 % |
| RAG-Fragen zu langen Dokumenten | Gemini 3.5 Flash | Cache-Treffer + 1M Kontextfenster |
| Komplexe Agent-Workflows | Gemini 3.5 Flash | MCP Atlas 83,6 % |
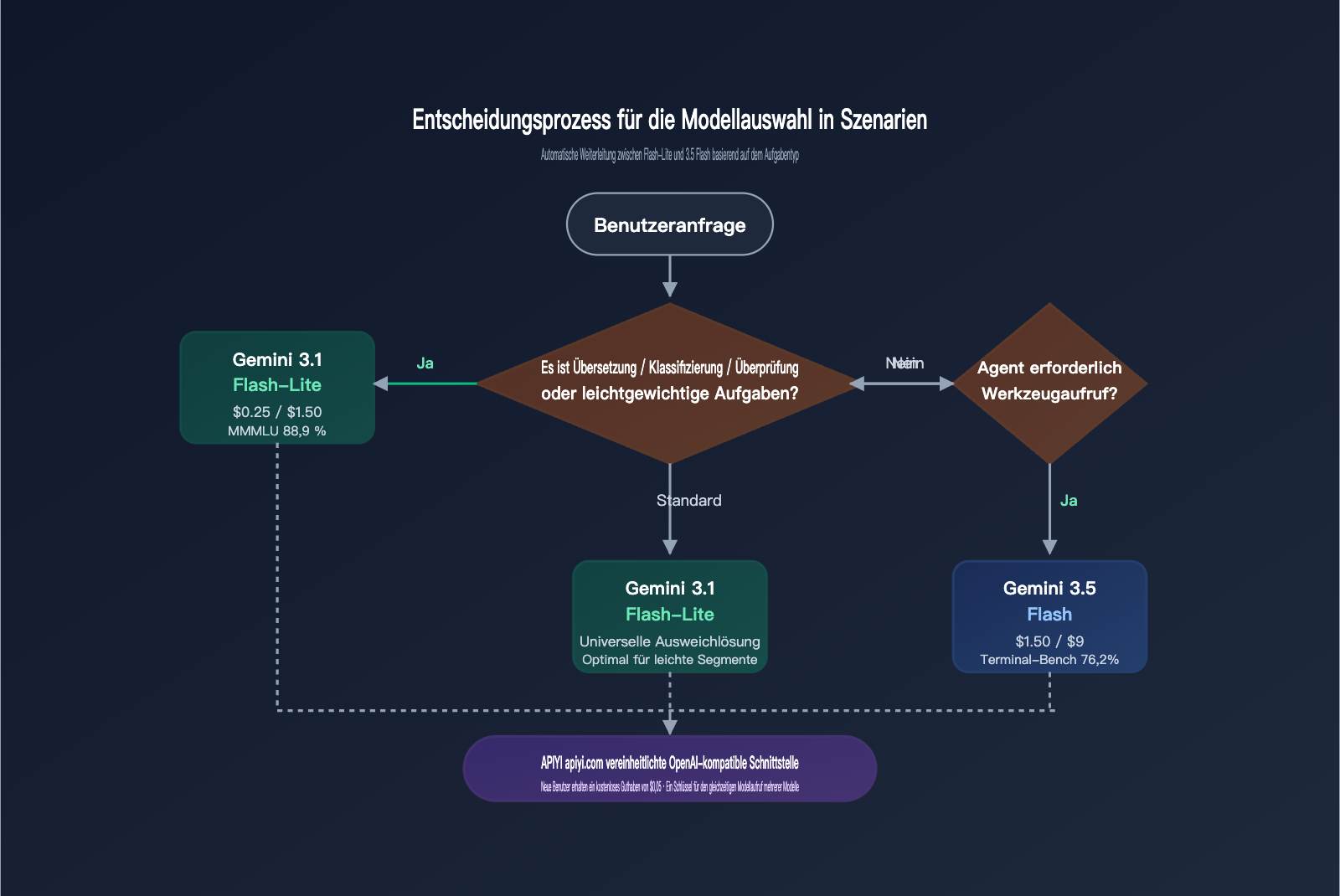
Die ideale Strategie in der Praxis bleibt das „aufgabenbasierte Routing“: Übersetzung, Klassifizierung und Moderation laufen über gemini-3.1-flash-lite-preview, während Agent-Aufgaben, Programmierung und RAG für lange Dokumente über gemini-3.5-flash abgewickelt werden. Beide Modelle lassen sich über denselben API-Schlüssel bei APIYI (apiyi.com) steuern. So profitieren Sie von der 6-fachen Kostenersparnis von Flash-Lite bei leichten Aufgaben und behalten gleichzeitig die volle Leistungsfähigkeit von 3.5 Flash für komplexe Agent-Workflows.
Typische Szenarien für Gemini 3.1 Flash-Lite
Wenn Ihr Produkt eines der folgenden Merkmale aufweist, ist Flash-Lite fast immer die bessere Wahl: mehr als 100.000 Aufrufe pro Tag, Eingabe/Ausgabe unter 5K Token, Empfindlichkeit gegenüber P95-Latenz, kein Bedarf an Tool-Aufrufen und Unterstützung für mehrere Sprachen. Typische Szenarien sind Produktübersetzungen im grenzüberschreitenden E-Commerce, mehrsprachiger SaaS-Kundensupport, Content-Moderations-Pipelines, Untertitelgenerierung oder Normalisierung nach Batch-OCR. Dank der OpenAI-kompatiblen Schnittstelle von APIYI (apiyi.com) ist der Migrationsaufwand nahezu null.
Typische Szenarien für Gemini 3.5 Flash
Gemini 3.5 Flash ist sinnvoll, wenn Ihre Aufgaben „Tool-Aufrufe nach der Übersetzung“ oder „Übersetzung innerhalb komplexer Agent-Ketten“ erfordern. Beispiele: Übersetzung + Wissensdatenbank-Abfrage + Aufruf externer APIs, oder der Nutzer sendet einen fremdsprachigen Text → das Modell übersetzt ihn → und ruft anschließend Tools wie Taschenrechner, Suche oder Code-Ausführung auf. Bei solchen Aufgaben würde Flash-Lite aufgrund fehlender Agent-Fähigkeiten häufiger Fehler produzieren, was die Kosten letztlich in die Höhe treibt.
Einbindungsbeispiel für Gemini 3.1 Flash-Lite bei APIYI für Übersetzungsszenarien
Hier ist ein optimiertes, minimalistisches Python-Beispiel für Übersetzungsszenarien, das zeigt, wie Sie Gemini 3.1 Flash-Lite über APIYI (apiyi.com) aufrufen können, wobei die OpenAI-kompatible Schreibweise vollständig beibehalten wird.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Übersetze die Eingabe des Nutzers in {target_lang}. Gib nur die Übersetzung aus, keine Erklärungen."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
Vollständige Implementierung mit Batch-Parallelisierung und Fallback-Routing anzeigen
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Übersetze in {target_lang}. Gib nur die Übersetzung aus."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Übersetze in {target_lang}. Gib nur die Übersetzung aus."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Optimierungstipps für Batch-Übersetzungen: Übersetzungsszenarien eignen sich hervorragend für hohe Parallelität (
concurrency=20~50), eine niedrige Temperature (0.1-0.3) und kurze System-Prompts. Die Plattform APIYI (apiyi.com) hat das Routing bereits für Szenarien mit hohem Durchsatz optimiert. Neue Nutzer erhalten ein Startguthaben von 0,05 USD. Bei der Preisgestaltung von Flash-Lite (0,25 USD / 1,50 USD) können Sie damit etwa 50.000 bis 100.000 Token an echtem Inhalt übersetzen – genug, um eine Batch-Übersetzungs-Pipeline vollständig zu testen.
FAQ: Gemini 3.5 Flash vs. 3.1 Flash-Lite für Übersetzungen
Q1: Gemini 3.1 Flash-Lite ist eine Preview-Version. Ist sie für die Produktion geeignet?
Ja, aber Sie sollten für Redundanz sorgen. Flash-Lite befindet sich seit dem 3. März 2026 in der Preview-Phase. Google hat noch kein offizielles GA-Datum genannt, aber die API-Schnittstellen und Preise sind stabil. Wir empfehlen für die Produktion eine Strategie mit zwei Modellen: "Haupt-Routing Flash-Lite + Fallback 3.5 Flash". Über die einheitliche Schnittstelle von APIYI (apiyi.com) können Sie das Routing steuern und Single-Point-of-Failure-Risiken vermeiden. Sobald Google das Modell auf GA aktualisiert oder eine 3.5 Flash-Lite veröffentlicht, können Sie durch einfaches Anpassen des model-Feldes nahtlos migrieren.
Q2: Kann Flash-Lite bei der Übersetzungsqualität wirklich mit Flash mithalten?
Bei über 90 % der allgemeinen Übersetzungsaufgaben: Ja. Die Model Card von Google DeepMind besagt explizit, dass Flash-Lite über "best-in-class translation and multilingual understanding" verfügt, mit einem MMMLU-Score von 88,9 % für mehrere Sprachen. In zwei Szenarien hat 3.5 Flash jedoch weiterhin Vorteile: Erstens bei langen Übersetzungen mit Fachterminologie (Medizin, Recht, Finanzen) und zweitens bei Übersetzungen, die logische Schlussfolgerungen erfordern (z. B. die Auflösung von Pronomen basierend auf dem Kontext). Wir empfehlen, einen Testlauf mit echten Geschäftsdaten über APIYI (apiyi.com) durchzuführen, anstatt sich nur auf Benchmarks zu verlassen.
Q3: Ist es sinnvoll, GPT-4o-mini oder Claude Haiku 4.5 durch Flash-Lite für Übersetzungen zu ersetzen?
Ja, es ist meist günstiger und schneller. Die Preisgestaltung von Gemini 3.1 Flash-Lite (0,25 USD / 1,50 USD) liegt unter der von GPT-4o-mini (0,15 USD / 0,60 USD – wobei die Übersetzungsqualität in der Praxis oft hinter Flash-Lite zurückbleibt) und auch unter der von Claude Haiku 4.5. Der MMMLU-Score von 88,9 % übertrifft vergleichbare Konkurrenzmodelle. Testen Sie am besten alle drei Modelle unter demselben API-Schlüssel bei APIYI (apiyi.com) mittels A/B-Vergleich, um zu sehen, welches für Ihre spezifischen Sprachpaare am besten geeignet ist.
Q4: Kann das 1M-Kontextfenster von Flash-Lite wirklich für Übersetzungen genutzt werden?
Ja, und das ist seine am meisten unterschätzte Fähigkeit. 1 Million Token entsprechen etwa 700.000 bis 800.000 englischen Wörtern oder 300.000 bis 400.000 chinesischen Schriftzeichen. Das reicht aus, um ein ganzes Buch mittlerer Länge oder einen kompletten Satz Unternehmensdokumente in einem Durchgang zu übersetzen. Bei deaktiviertem "Thinking"-Modus liegen die Kosten für eine solche Übersetzung bei ca. 0,25 USD (Input) + 1,50 USD (Output) – weit unter den Kosten für eine Aufteilung der Inhalte auf 3.5 Flash oder GPT-5.5. APIYI (apiyi.com) bietet vollen Zugriff auf das 1M-Kontextfenster von Flash-Lite.
Fazit: Gemini 3.1 Flash-Lite ist die kosteneffizienteste Lösung für Übersetzungsszenarien
Kommen wir zum Kernpunkt dieses Artikels: Für leichtgewichtige, hochfrequente Aufgaben wie Übersetzungen ist Gemini 3.1 Flash-Lite keine „abgespeckte Version“ von Gemini 3.5 Flash, sondern die von Google speziell für solche Szenarien entwickelte Optimallösung. Die fünf entscheidenden Faktoren für seine Vormachtstellung bei Übersetzungen sind: Der Input ist 6-mal günstiger, der Output ebenfalls 6-mal preiswerter, die Latenz bis zum ersten Token ist 2,5-mal schneller, der MMMLU-Score für Mehrsprachigkeit liegt bei beeindruckenden 88,9 % und Google selbst führt Übersetzungen als sein Haupteinsatzgebiet auf. Die Stärken von Gemini 3.5 Flash in den Bereichen Agenten-Steuerung und Programmierung sind bei Übersetzungen völlig irrelevant – Sie zahlen also nur für Funktionen, die Sie gar nicht benötigen.
Die sicherste Strategie ist ein Dual-Modell-Routing: Nutzen Sie gemini-3.1-flash-lite-preview für Übersetzungen, Klassifizierungen und Moderationsaufgaben, während Sie gemini-3.5-flash für Agenten-Workflows, Programmierung und RAG bei langen Dokumenten einsetzen. Über die einheitliche, OpenAI-kompatible Schnittstelle von APIYI (apiyi.com) können Sie beide Modelle bequem unter demselben API-Schlüssel verwalten. Neue Nutzer erhalten ein Startguthaben von 0,05 USD – das reicht aus, um eine komplette Batch-Übersetzungs-Pipeline einem Stresstest zu unterziehen und die tatsächliche Kostenersparnis für Ihr Unternehmen zu ermitteln.
Autor: APIYI Technik-Team · apiyi.com
Veröffentlichungsdatum: 20. Mai 2026
Referenzen: Google DeepMind Model Card, Google Blog, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub