많은 팀이 2026년 5월 19일 Gemini 3.5 Flash가 정식 출시(GA)된 이후, 번역, 자막 생성, 콘텐츠 검토와 같은 고빈도 경량 작업까지 포함한 모든 Gemini 트래픽을 해당 모델로 이전했습니다. 하지만 이는 명백한 오판입니다. 입출력 길이가 짧고, 단가에 극도로 민감하며, 지연 시간(Latency)에 민감하고, 에이전트 도구 연동이 필요 없는 번역과 같은 시나리오에서는 더 비싸고 '범용적인' Gemini 3.5 Flash보다 Gemini 3.1 Flash-Lite가 진정한 최적의 솔루션이기 때문입니다. 본 글에서는 Google DeepMind 공식 모델 카드, LLM-Stats, Artificial Analysis 등 영문 1차 자료를 바탕으로 6가지 차원에서 두 모델을 체계적으로 비교합니다.

결론부터 말씀드리자면, 번역, 자막, 대량 분류, 텍스트 정규화와 같은 경량 작업에는 Gemini 3.5 Flash가 아닌 Gemini 3.1 Flash-Lite를 추천합니다. 그 핵심 이유는 6가지입니다: 입력 비용 6배 저렴, 출력 비용 6배 저렴, 첫 토큰 지연 시간 2.5배 빠름, MMMLU 다국어 점수 88.9% 기록, Google 공식 문서에서 번역 작업에 최적화된 모델로 명시, 3.5 Flash의 강점인 에이전트 기능이 번역에는 불필요하다는 점입니다. APIYI(apiyi.com)에서 제공하는 0.05달러 무료 크레딧으로 실제 번역 작업을 테스트해 보세요. 실제 비용과 품질 차이가 벤치마크 수치보다 훨씬 더 직관적으로 다가올 것입니다.
번역 시나리오에서 Gemini 3.1 Flash-Lite가 Gemini 3.5 Flash보다 뛰어난 이유
번역 작업의 특징은 매우 명확합니다. 입력은 소스 언어의 짧은 텍스트(수백에서 수천 토큰)이고, 출력은 타겟 언어의 짧은 텍스트입니다. 단일 호출에서 복잡한 사고 과정, 도구 호출, 멀티모달 융합은 필요하지 않지만, 호출 빈도가 매우 높고 비용과 지연 시간에 극도로 민감합니다. 바로 이 지점이 Google이 Flash-Lite 시리즈를 설계한 이유입니다.
Gemini 3.1 Flash-Lite는 2026년 3월 3일에 출시되었습니다. Google 공식 블로그는 이를 "가장 비용 효율적인 AI 모델"이라고 소개하며, "대규모 번역, 콘텐츠 분류, 검토, 구조화된 데이터 추출, 반복적인 에이전트 작업"을 핵심 활용 분야로 명시했습니다. DeepMind의 모델 카드는 이 모델이 "최고 수준의 번역 및 다국어 이해 능력을 갖췄으며, 특히 비라틴 문자 스크립트에서 개선되었다"고 강조합니다. MMMLU 다국어 벤치마크 점수 88.9%는 경량 모델군에서 최상위권에 해당합니다.
Gemini 3.5 Flash는 5월 19일에 출시된 에이전트 중심의 Flash 모델로, "에이전트 도구 연동 + 코딩 주력"을 목표로 합니다. Terminal-Bench 2.1, MCP Atlas, Finance Agent v2 등에서 Gemini 3.1 Pro를 앞서기도 했습니다. 하지만 이러한 에이전트 역량은 번역 작업에서 전혀 쓰이지 않으며, 이를 위해 지불하는 프리미엄 비용은 낭비에 가깝습니다. 이것이 바로 "Flash 시리즈" 내부에서도 작업 유형에 따라 모델을 구분해야 하는 이유입니다. 에이전트 작업은 3.5 Flash, 번역/분류/검토는 3.1 Flash-Lite를 선택하세요.
🎯 모델 선택 핵심 제언: "버전 숫자가 높을수록 무조건 좋다"는 직관에 속지 마세요. Gemini 3.5 Flash(5월 출시)와 Gemini 3.1 Flash-Lite(3월 출시)는 각각 "에이전트 주력"과 "고처리량 경량 작업"을 담당하는 별개의 제품 라인입니다. APIYI(apiyi.com) 플랫폼에서는 두 모델을 모두 지원하며, 동일한 API 키 내에서 작업 유형에 따라 자동으로 라우팅할 수 있으므로 굳이 하나만 선택할 필요가 없습니다.
Gemini 3.5 Flash vs Gemini 3.1 Flash-Lite 사양 비교
두 모델을 한 표에 정리해 보니 제품 라인업의 역할 분담과 성능 차이가 한눈에 들어옵니다. 아래 표는 Google DeepMind 모델 카드와 LLM-Stats 공개 페이지의 데이터를 바탕으로 두 모델의 핵심 사양을 요약한 것입니다.
| 비교 항목 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 번역 작업 유리 |
|---|---|---|---|
| 출시일 | 2026년 5월 19일 | 2026년 3월 3일 | — |
| 출시 상태 | GA 정식 버전 | Preview 프리뷰 버전 | — |
| 모델 ID | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| 포지셔닝 | Agentic Flash · 도구 오케스트레이션 | High-volume · 고처리량 경량 모델 | Flash-Lite |
| 컨텍스트 윈도우 | 1M 입력 / 64K 출력 | 1M 입력 / 64K 출력 | 동등 |
| 입력 모달리티 | 텍스트+이미지+오디오+비디오 | 텍스트+이미지+음성+비디오 | 동등 |
| 사고 모드 | 동적 사고 기본 활성화 | 사고 레벨 조절 가능 | Flash-Lite(끄기 가능) |
| 지식 컷오프 | 2026년 1월 | 2025년 1월 | 3.5 Flash |
| MMMLU 다국어 | 미공개 (예상 80+) | 88.9% | Flash-Lite |
| 출력 속도 | 약 289 token/s | 2.5 Flash 대비 45% 향상, TTFT 2.5배 빠름 | Flash-Lite |
| Agent 도구 능력 | 3.1 Pro 여러 벤치마크 상회 | 표준 function calling | 번역 작업 시 불필요 |
| APIYI 연동 | 지원 | 지원 | 동등 |
이 표를 보실 때는 세 가지 차이점에 주목해 주세요. 첫째는 포지셔닝입니다. Flash-Lite는 'high-volume'을 표방합니다. 이는 Google이 설계 단계부터 '지능보다 처리량 우선'을 제품 DNA에 심어두었음을 의미하며, 번역이나 분류 같은 고빈도 작업에 최적화되어 있습니다. 둘째는 MMMLU 88.9%라는 수치입니다. 이는 공개된 Gemini 3.x 제품군 중 다국어 벤치마크 점수가 가장 높은 경량 모델로, 번역 품질을 직접적으로 증명합니다. 셋째는 '사고 레벨 조절'입니다. Flash-Lite는 사고(thinking) 과정을 끌 수 있어, 별도의 추론이 필요 없는 번역 작업에서 지연 시간을 더욱 단축할 수 있습니다.
번역 작업의 비용 비교: Gemini 3.5 Flash vs 3.1 Flash-Lite 6배 가격 차이
비용은 번역 작업에서 모델을 선택할 때 가장 중요한 지표입니다. 번역은 "입출력 길이는 짧지만 빈도는 매우 높은" 특징을 가집니다. 일반적인 SaaS 제품은 하루에 수천만에서 수억 토큰의 번역을 처리하는데, 단가 6배 차이는 매달 수천 달러에서 수만 달러의 비용 차이로 이어집니다.
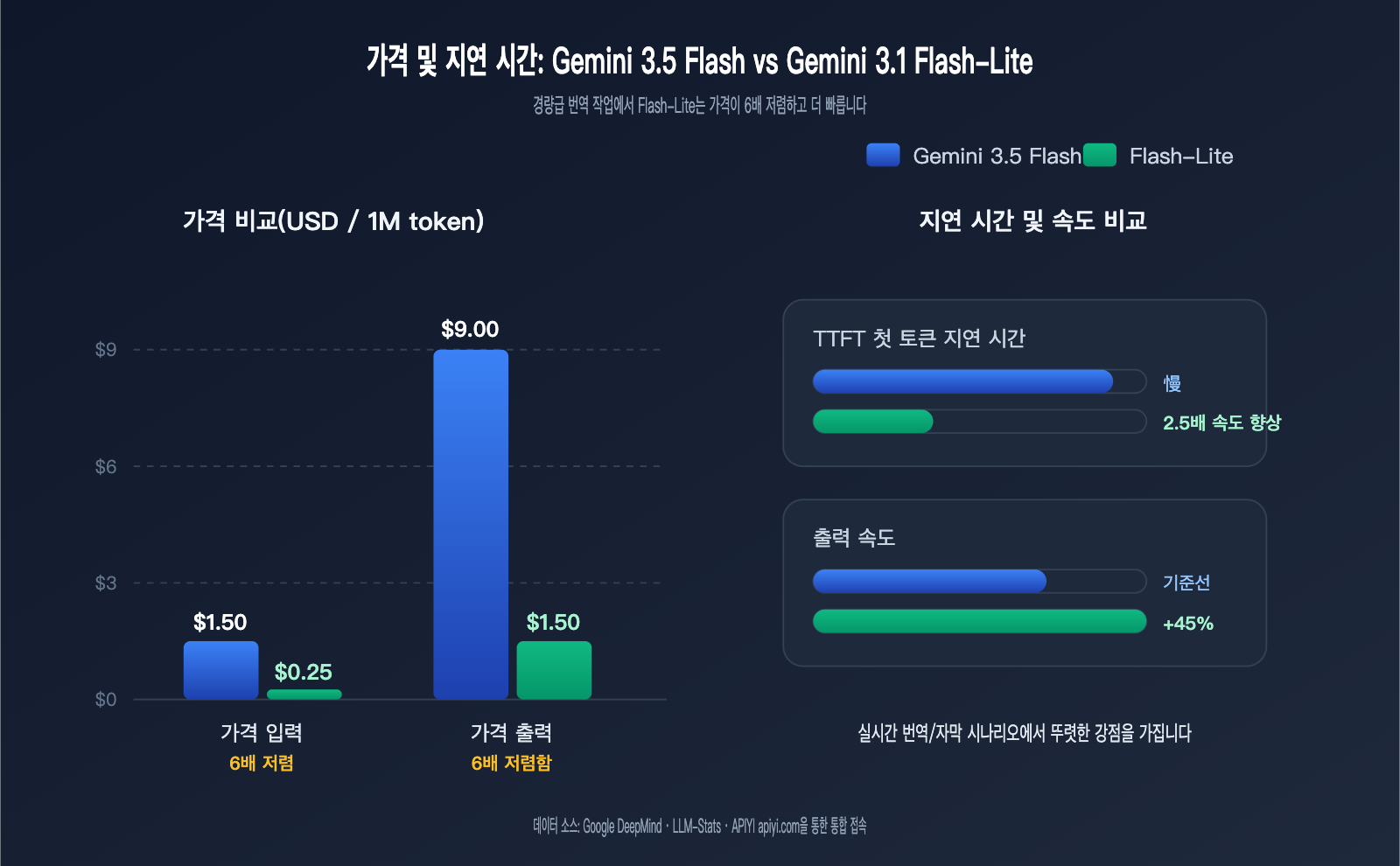
다음 표는 두 모델의 번역 작업 시 핵심 비용 항목을 비교한 것입니다. 모든 가격은 100만 토큰당 달러 기준입니다.
| 비용/성능 항목 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 차이 |
|---|---|---|---|
| 입력 가격 | $1.50 | $0.25 | Flash-Lite 6배 저렴 |
| 출력 가격 | $9.00 | $1.50 | Flash-Lite 6배 저렴 |
| 캐시 적중 입력 | $0.15 | $0.025 (추정) | Flash-Lite 6배 저렴 |
| TTFT (첫 토큰 지연) | 낮음 | 2.5 Flash 대비 2.5배 빠름 | Flash-Lite |
| 출력 속도 | 약 289 token/s | 2.5 Flash 대비 45% 향상 | 동등 또는 Flash-Lite 우세 |
| 사고 모드 기본값 | 기본 활성화, 사고 비용 발생 | 끄기 가능, 사고 지연 없음 | Flash-Lite |
실제 비용을 시뮬레이션해 보겠습니다. SaaS 번역 서비스가 하루에 1,000만 토큰 입력과 500만 토큰 출력을 처리한다고 가정할 때(중규모 B2C 앱), 한 달 비용은 얼마나 될까요?
| 월간 비용 (일 1,000만 입력 / 500만 출력) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 절감액 |
|---|---|---|---|
| 일일 입력 비용 | $15.00 | $2.50 | $12.50 |
| 일일 출력 비용 | $45.00 | $7.50 | $37.50 |
| 일일 합계 | $60.00 | $10.00 | $50 |
| 월간 합계 (30일) | $1,800 | $300 | $1,500 / 월 |
| 연간 합계 | $21,600 | $3,600 | $18,000 / 년 |
💡 비용 산정 제안: 위 표의 수치에 실제 트래픽을 대입해 보세요. 월간 차이가 보통 4자리 수 달러 이상 발생할 것입니다. APIYI apiyi.com에서 계정을 생성하고 무료 크레딧을 받아, 동일한 번역 샘플로
gemini-3.5-flash와gemini-3.1-flash-lite-preview를 각각 호출해 보세요. 품질 차이를 검증함과 동시에 실제 비즈니스에서의 비용 절감 효과를 바로 확인할 수 있습니다.
Gemini 3.1 Flash-Lite 번역 품질 및 속도 실측 분석
가격이 저렴한 것만으로는 부족하죠. 번역 품질이 뒷받침되어야 합니다. Gemini 3.1 Flash-Lite의 번역 성능에 대한 실측 데이터는 상당히 강력합니다. 대부분의 상황에서 사용자가 "Flash보다 확실히 떨어진다"고 느낄 일은 거의 없을 것입니다. 다음 네 가지 데이터가 그 핵심 근거입니다.
첫째, MMMLU 다국어 벤치마크에서 88.9%의 점수를 기록했습니다. MMMLU(Multilingual MMLU)는 모델이 15개 이상의 언어에서 전문 지식을 이해하고 추론하는 능력을 평가합니다. Flash-Lite는 이 부문에서 88.9%를 달성하며 Flash-Lite급 모델 중 최상위권에 속합니다. 이는 한국어, 중국어, 일본어, 아랍어 등 비라틴어권 언어에서도 여전히 고품질의 번역을 유지할 수 있음을 의미합니다.
둘째, Google DeepMind가 모델 카드에서 명시한 "비라틴 문자 체계에서 개선된, 동급 최고의 번역 및 다국어 이해 능력(best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts)"이라는 평가입니다. 이는 Google이 공식적으로 Flash-Lite의 번역 능력을 보증하는 것으로, 특히 한국어와 같은 비라틴어권에서의 향상은 SaaS 서비스에 매우 중요한 요소입니다.
셋째, Lara Translate가 2026년 2월에 발표한 '번역 모델 벤치마크'의 결론입니다. Flash 시리즈 변형 모델들은 "낮은 지연 시간과 높은 처리량 워크플로우(lower latency and higher throughput workflows)"를 위한 최우선 선택지로 꼽혔습니다. 번역 작업의 핵심 제약 사항인 '저지연 + 고처리량 + 비용 효율성'이 Flash-Lite의 설계 목표와 완벽하게 일치하기 때문입니다.
넷째, TTFT(Time-to-First-Token)와 출력 속도입니다. Flash-Lite의 TTFT는 Gemini 2.5 Flash보다 2.5배 빠르며, 출력 속도는 45% 향상되었습니다. 이 두 지표는 번역처럼 '실시간성'이 중요한 환경에서 사용자 경험을 결정짓는 핵심 요소입니다. APIYI(apiyi.com)에서 5,000자 분량의 중-영 번역을 직접 테스트해 보시면 그 차이를 직관적으로 체감하실 수 있을 것입니다.
시나리오별 추천: Flash-Lite를 쓸 때와 3.5 Flash를 쓸 때
6가지 차원의 비교를 실제 작업에 적용하기 쉽게 아래 추천 표로 정리했습니다. 이 표는 "어떤 모델이 더 강한가"가 아니라 "각 작업에 무엇을 써야 하는가"에 대한 가이드를 제공합니다.
| 작업 유형 | 추천 모델 | 핵심 이유 |
|---|---|---|
| 일반 텍스트 번역 (한영/한일 등) | Gemini 3.1 Flash-Lite | MMMLU 88.9% + 6배 저렴한 비용 |
| 자막 번역 / 실시간 번역 | Gemini 3.1 Flash-Lite | TTFT 2.5배 빠름 + 출력 속도 45% 향상 |
| 콘텐츠 검수 / 텍스트 분류 | Gemini 3.1 Flash-Lite | Google 공식 최적 모델, 대량 작업에 최적 |
| 구조화된 데이터 추출 | Gemini 3.1 Flash-Lite | 대량의 JSON 추출에 적합 |
| 다국어 챗봇 | Gemini 3.1 Flash-Lite | 다국어 품질 + 저지연 + 저비용 |
| 번역 + 후처리 Agent | Gemini 3.5 Flash | 여러 도구를 연결하는 function calling 필요 |
| 번역 + 도구 호출 | Gemini 3.5 Flash | 3.1 Pro를 능가하는 Agent 성능 |
| 코드 어시스턴트 / IDE 자동 완성 | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76.2% |
| 긴 문서 RAG 질의응답 | Gemini 3.5 Flash | 캐시 적중 + 1M 컨텍스트 윈도우 |
| 복잡한 Agent 워크플로우 | Gemini 3.5 Flash | MCP Atlas 83.6% |
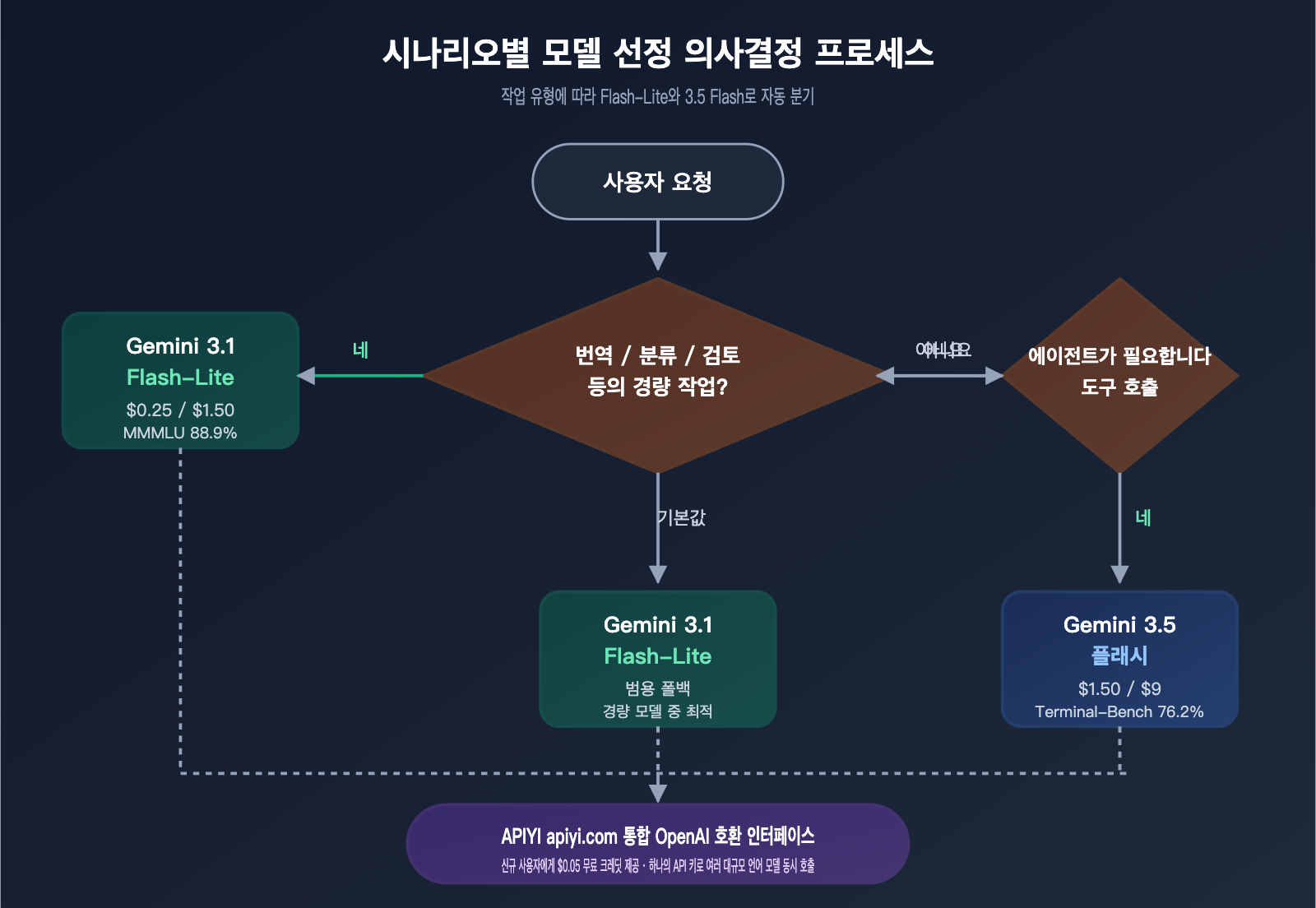
실무에서 가장 이상적인 전략은 여전히 '작업별 라우팅'입니다. 번역, 분류, 검수 작업은 gemini-3.1-flash-lite-preview를 사용하고, Agent, 코딩, 긴 문서 RAG는 gemini-3.5-flash를 사용하세요. 두 모델을 동일한 APIYI(apiyi.com) 인증 키 아래에서 전환하며 사용하면, Flash-Lite의 경량 작업 비용 절감 혜택을 누리면서도 3.5 Flash의 강력한 Agent 성능을 유지할 수 있습니다.
Gemini 3.1 Flash-Lite가 적합한 대표적인 시나리오
귀하의 서비스가 다음 특징 중 하나라도 해당한다면, Flash-Lite가 거의 확실히 더 나은 선택입니다: 일일 호출 횟수가 10만 회 이상, 단일 입력/출력이 5K 토큰 이내, P95 지연 시간에 민감, 도구 호출 불필요, 다국어 지원 필요. 대표적인 예로 해외 직구 상품 번역, SaaS 다국어 고객 응대, 콘텐츠 검수 파이프라인, 자막 생성, 대량 OCR 후 정규화 등이 있습니다. APIYI(apiyi.com)의 OpenAI 호환 인터페이스를 활용하면 마이그레이션 비용은 거의 제로에 가깝습니다.
여전히 Gemini 3.5 Flash를 추천하는 시나리오
작업 중에 "번역 후 도구 호출"이 필요하거나 "번역이 복잡한 Agent 체인에 포함"되어야 한다면 Gemini 3.5 Flash를 사용하는 것이 맞습니다. 예를 들어, 번역 + 지식베이스 검색 + 외부 API 호출, 혹은 사용자가 외국어를 제출하면 모델이 먼저 번역한 뒤 계산기/검색/코드 실행 도구를 사용하는 경우입니다. 이런 작업에 Flash-Lite를 쓰면 Agent 능력 부족으로 오류가 반복되어 결과적으로 비용이 더 많이 발생할 수 있습니다.
번역 시나리오에서 Gemini 3.1 Flash-Lite를 APIYI에 연동하는 예제
번역 시나리오에 최적화된 가장 간결한 Python 연동 예제를 소개합니다. APIYI(apiyi.com)에서 Gemini 3.1 Flash-Lite를 호출하는 방법이며, OpenAI 호환 방식을 그대로 유지했습니다.
from openai import OpenAI
# APIYI 클라이언트를 설정합니다
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"사용자 입력을 {target_lang}(으)로 번역하세요. 설명 없이 번역 결과만 출력하세요."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
대량 동시 처리 및 폴백(Fallback) 라우팅이 포함된 전체 구현 확인하기
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
# 기본 모델로 호출
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"{target_lang}(으)로 번역하세요. 번역 결과만 출력하세요."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
# 실패 시 폴백 모델로 호출
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"{target_lang}(으)로 번역하세요. 번역 결과만 출력하세요."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 대량 번역 최적화 팁: 번역 작업은 높은 동시성(
concurrency=20~50)과 낮은 temperature(0.1-0.3), 짧은 시스템 프롬프트를 사용하는 것이 좋습니다. APIYI(apiyi.com) 플랫폼은 이미 고처리량 시나리오를 위해 라우팅 최적화가 적용되어 있습니다. 신규 가입 시 0.05달러의 무료 크레딧을 제공하며, Flash-Lite의 가격($0.25/$1.50) 기준으로 약 5만~10만 토큰 분량의 실제 내용을 번역할 수 있어 대량 번역 파이프라인의 전체 부하 테스트를 진행하기에 충분합니다.
Gemini 3.5 Flash vs 3.1 Flash-Lite 번역 FAQ
Q1: Gemini 3.1 Flash-Lite는 프리뷰 버전인데, 운영 환경에서 사용해도 될까요?
사용 가능하지만, 대비책을 마련해 두는 것이 좋습니다. Flash-Lite는 2026년 3월 3일 출시 이후 계속 프리뷰 단계에 있으며, 구글 공식 GA 날짜는 미정입니다. 하지만 API 인터페이스와 가격은 안정적입니다. 운영 환경에서는 "메인 모델 Flash-Lite + 예외 발생 시 3.5 Flash 폴백" 전략을 권장합니다. APIYI(apiyi.com)의 통합 인터페이스를 통해 라우팅을 전환하면 단일 지점 장애를 피할 수 있습니다. 나중에 구글이 GA로 전환하거나 3.5 Flash-Lite를 출시하면 모델 필드만 교체하여 원활하게 마이그레이션할 수 있습니다.
Q2: 번역 품질 면에서 Flash-Lite가 정말 Flash를 따라잡을 수 있을까요?
일반적인 번역 작업의 90% 이상에서는 가능합니다. 구글 딥마인드 모델 카드에 따르면 Flash-Lite는 "동급 최고의 번역 및 다국어 이해 능력"을 갖췄으며, MMMLU 다국어 점수는 88.9%에 달합니다. 다만, 전문 용어(의학, 법률, 금융)가 포함된 장문 번역이나 번역과 문맥 추론이 동시에 필요한 경우(예: 문맥에 따른 대명사 지칭 판단)에는 3.5 Flash가 여전히 우위에 있습니다. 벤치마크 점수만 보기보다는 APIYI(apiyi.com)에서 실제 업무 샘플을 활용해 직접 비교 평가해 보시는 것을 추천합니다.
Q3: Flash-Lite로 GPT-4o-mini나 Claude Haiku 4.5를 대체해 번역하는 것이 적절할까요?
적절하며, 보통 더 저렴하고 빠릅니다. Gemini 3.1 Flash-Lite의 가격($0.25/$1.50)은 GPT-4o-mini보다 저렴하거나 비슷하며, Claude Haiku 4.5보다도 경제적입니다. 다국어 벤치마크에서 Flash-Lite의 88.9% MMMLU 점수는 동급 제품보다 높습니다. APIYI(apiyi.com)에서 동일한 API 키로 세 모델을 모두 호출해 A/B 테스트를 진행하여, 본인의 특정 언어 조합에 가장 적합한 모델을 찾아보세요.
Q4: Flash-Lite의 1M 컨텍스트 윈도우를 번역에 정말 활용할 수 있나요?
네, 가장 저평가된 능력 중 하나입니다. 1M 토큰은 약 70만80만 개의 영어 단어 또는 30만40만 개의 한글 글자 수에 해당하며, 중간 길이의 책 한 권이나 기업 문서 전체를 한 번에 번역하기에 충분합니다. Thinking 모드를 끄면 1M 컨텍스트의 단일 번역 비용은 약 $0.25(입력) + $1.50(출력)으로, 동일한 내용을 3.5 Flash나 GPT-5.5로 나누어 번역하는 것보다 훨씬 저렴합니다. APIYI(apiyi.com)는 Flash-Lite의 1M 컨텍스트 윈도우를 완전히 개방했으므로 바로 호출하여 사용할 수 있습니다.
요약: 번역 작업에서 Gemini 3.1 Flash-Lite가 6배 더 높은 가성비를 자랑하는 최적의 선택인 이유
본문의 핵심 결론으로 돌아가 보겠습니다. 번역과 같은 경량화된 고빈도 작업에서 Gemini 3.1 Flash-Lite는 Gemini 3.5 Flash의 '하위 버전'이 아니라, Google이 이러한 시나리오를 위해 특별히 설계한 최적의 솔루션입니다. 입력 비용 6배 저렴, 출력 비용 6배 저렴, 첫 토큰 지연 시간(TTFT) 2.5배 단축, MMMLU 다국어 점수 88.9% 기록, 그리고 Google이 공식적으로 번역 작업을 이 모델의 '스위트 스팟(Sweet Spot)'으로 지정했다는 다섯 가지 사실이 번역 분야에서의 압도적인 위상을 증명합니다. Gemini 3.5 Flash의 강점인 에이전트 및 코딩 능력은 번역 작업에서 전혀 활용되지 않으므로, 해당 기능을 위해 지불하는 추가 비용은 낭비일 뿐입니다.
가장 현명한 전략은 듀얼 모델 라우팅을 사용하는 것입니다. 번역/분류/검토 작업에는 gemini-3.1-flash-lite-preview를, 에이전트/코딩/긴 문서 RAG 작업에는 gemini-3.5-flash를 활용하세요. APIYI(apiyi.com)의 통합 OpenAI 호환 인터페이스를 사용하면 동일한 인증 키 하나로 간편하게 모델을 전환할 수 있습니다. 신규 사용자에게는 0.05달러의 무료 크레딧을 제공하고 있으니, 이를 활용해 대량 번역 파이프라인을 직접 테스트해 보고 실제 비즈니스 환경에서 얼마나 많은 비용을 절감할 수 있는지 확인해 보세요.
작성자: APIYI 기술팀 · apiyi.com
발행일: 2026년 5월 20일
참고 자료: Google DeepMind 모델 카드, Google 블로그, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub