Tras el lanzamiento general (GA) de Gemini 3.5 Flash el 19 de mayo de 2026, muchos equipos migraron automáticamente todo su tráfico de Gemini a este modelo, incluyendo tareas ligeras de alta frecuencia como traducción, generación de subtítulos y moderación de contenido. Esto es, en realidad, un error de juicio evidente. En escenarios donde las entradas y salidas son cortas, la sensibilidad al precio y a la latencia es extrema, y no se requiere la orquestación de herramientas de agentes, Gemini 3.1 Flash-Lite es la verdadera solución óptima, no el más caro y "todoterreno" Gemini 3.5 Flash. Este artículo compara sistemáticamente ambos modelos bajo 6 dimensiones, utilizando datos provenientes de fuentes oficiales de Google DeepMind, LLM-Stats y Artificial Analysis.

Conclusión directa: en escenarios ligeros como traducción, subtítulos, clasificación por lotes y normalización de texto, recomiendo Gemini 3.1 Flash-Lite en lugar de Gemini 3.5 Flash. La razón principal se basa en seis puntos: una entrada 6 veces más barata, una salida 6 veces más barata, una latencia del primer token 2.5 veces más rápida, una puntuación multilingüe MMMLU de hasta 88.9%, el hecho de que Google clasifica oficialmente la traducción como su punto fuerte (sweet spot), y que las capacidades de agente de 3.5 Flash son totalmente innecesarias en tareas de traducción. Sugiero ejecutar un conjunto de tareas de traducción reales a través del crédito gratuito de 0.05 USD de APIYI (apiyi.com) para realizar una comparativa; la diferencia real en costo y calidad será mucho más intuitiva que los números de referencia.
¿Por qué Gemini 3.1 Flash-Lite es más competente que Gemini 3.5 Flash en tareas de traducción?
Las características de tareas como la traducción son muy claras: la entrada es un texto corto en el idioma de origen (de cientos a miles de tokens), la salida es un texto corto en el idioma de destino, y la invocación única no requiere cadenas de razonamiento, llamadas a herramientas ni fusión multimodal; sin embargo, la frecuencia de invocación es extremadamente alta y existe una sensibilidad extrema a los costos y la latencia. Este es precisamente el escenario para el que Google diseñó la serie Flash-Lite.
Gemini 3.1 Flash-Lite fue lanzado el 3 de marzo de 2026. En el blog oficial de Google se describió como "nuestro modelo de IA más rentable hasta la fecha", y se enumeraron explícitamente la "traducción masiva, clasificación de contenido, moderación, extracción de datos estructurados y tareas repetitivas de agentes" como su punto fuerte. La tarjeta del modelo de DeepMind señala además que posee una "traducción y comprensión multilingüe de primera clase, con mejoras notables en escrituras no latinas", con una puntuación de referencia multilingüe MMMLU de 88.9%, situándose en la cima absoluta dentro de la categoría ligera.
Gemini 3.5 Flash es el Flash con capacidades de agente lanzado el 19 de mayo, posicionado como el "orquestador de herramientas de agente + motor de codificación", superando a Gemini 3.1 Pro en Terminal-Bench 2.1, MCP Atlas y Finance Agent v2. Pero estas capacidades de agente son totalmente inútiles en tareas de traducción; el sobreprecio que pagas por estas funciones es un desperdicio. Es por eso que la "serie Flash" debe dividirse según el tipo de tarea: los agentes utilizan 3.5 Flash, mientras que la traducción/clasificación/moderación utilizan 3.1 Flash-Lite.
🎯 Recomendación clave de selección: No te dejes engañar por la intuición de que "un número de versión mayor es mejor". Gemini 3.5 Flash (lanzado en mayo) y Gemini 3.1 Flash-Lite (lanzado en marzo) son dos líneas de productos paralelas que cubren, respectivamente, los segmentos de "motor de agentes" y "carga ligera de alto rendimiento". La plataforma APIYI (apiyi.com) tiene ambos modelos disponibles, lo que permite enrutar automáticamente según el tipo de tarea bajo la misma clave de autenticación, sin necesidad de elegir uno sobre el otro.
Comparativa de especificaciones: Gemini 3.5 Flash vs. Gemini 3.1 Flash-Lite
Al colocar ambos modelos en una misma tabla, la división de funciones y las diferencias de capacidad en la línea de productos quedan claras. La siguiente tabla resume las especificaciones clave de ambos modelos; todos los datos provienen de la tarjeta de modelo de Google DeepMind y de la página pública LLM-Stats.
| Dimensión de comparación | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Ganador en traducción |
|---|---|---|---|
| Fecha de lanzamiento | 19 de mayo de 2026 | 3 de marzo de 2026 | — |
| Estado de lanzamiento | GA (Disponibilidad general) | Preview (Vista previa) | — |
| ID del modelo | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Posicionamiento | Flash agente · Orquestación de herramientas | Alto volumen · Ligero de alto rendimiento | Flash-Lite |
| Ventana de contexto | 1M entrada / 64K salida | 1M entrada / 64K salida | Empate |
| Modalidades de entrada | Texto+Imagen+Audio+Video | Texto+Imagen+Voz+Video | Empate |
| Modo de razonamiento | Razonamiento dinámico activado por defecto | Nivel de razonamiento ajustable | Flash-Lite (se puede apagar) |
| Corte de conocimiento | Enero de 2026 | Enero de 2025 | 3.5 Flash |
| MMMLU multilingüe | No publicado (estimado 80+) | 88.9% | Flash-Lite |
| Velocidad de salida | Aprox. 289 token/s | 45% más rápido que 2.5 Flash, TTFT 2.5x más rápido | Flash-Lite |
| Capacidad de herramientas (Agente) | Supera a 3.1 Pro en varios benchmarks | Llamada a funciones estándar | No necesario en traducción |
| Acceso vía APIYI | Disponible | Disponible | Empate |
Al leer esta tabla, hay que prestar atención a tres puntos de divergencia. Primero, la diferencia de posicionamiento: Flash-Lite apuesta por el "alto volumen", lo que significa que Google diseñó el modelo priorizando el rendimiento sobre la inteligencia puntual, lo cual encaja perfectamente con las necesidades de tareas de alta frecuencia como la traducción o clasificación. Segundo, la cifra de 88.9% en MMMLU, que es el modelo ligero con el benchmark multilingüe más alto de la familia Gemini 3.x, lo que se traduce directamente en la calidad de la traducción. Tercero, el "nivel de razonamiento ajustable": Flash-Lite permite desactivar el thinking, lo que reduce aún más la latencia en tareas de traducción que no requieren razonamiento complejo.
Comparativa de costos en escenarios de traducción: La diferencia de precio de 6 veces entre Gemini 3.5 Flash y 3.1 Flash-Lite
El costo es el indicador más importante al elegir un modelo para traducción. Las tareas de traducción se caracterizan por tener "entradas y salidas cortas pero de frecuencia extremadamente alta". Un producto SaaS común puede procesar decenas o cientos de millones de tokens de traducción al día; una diferencia de precio de 6 veces significa una diferencia de miles a decenas de miles de dólares en la factura mensual.
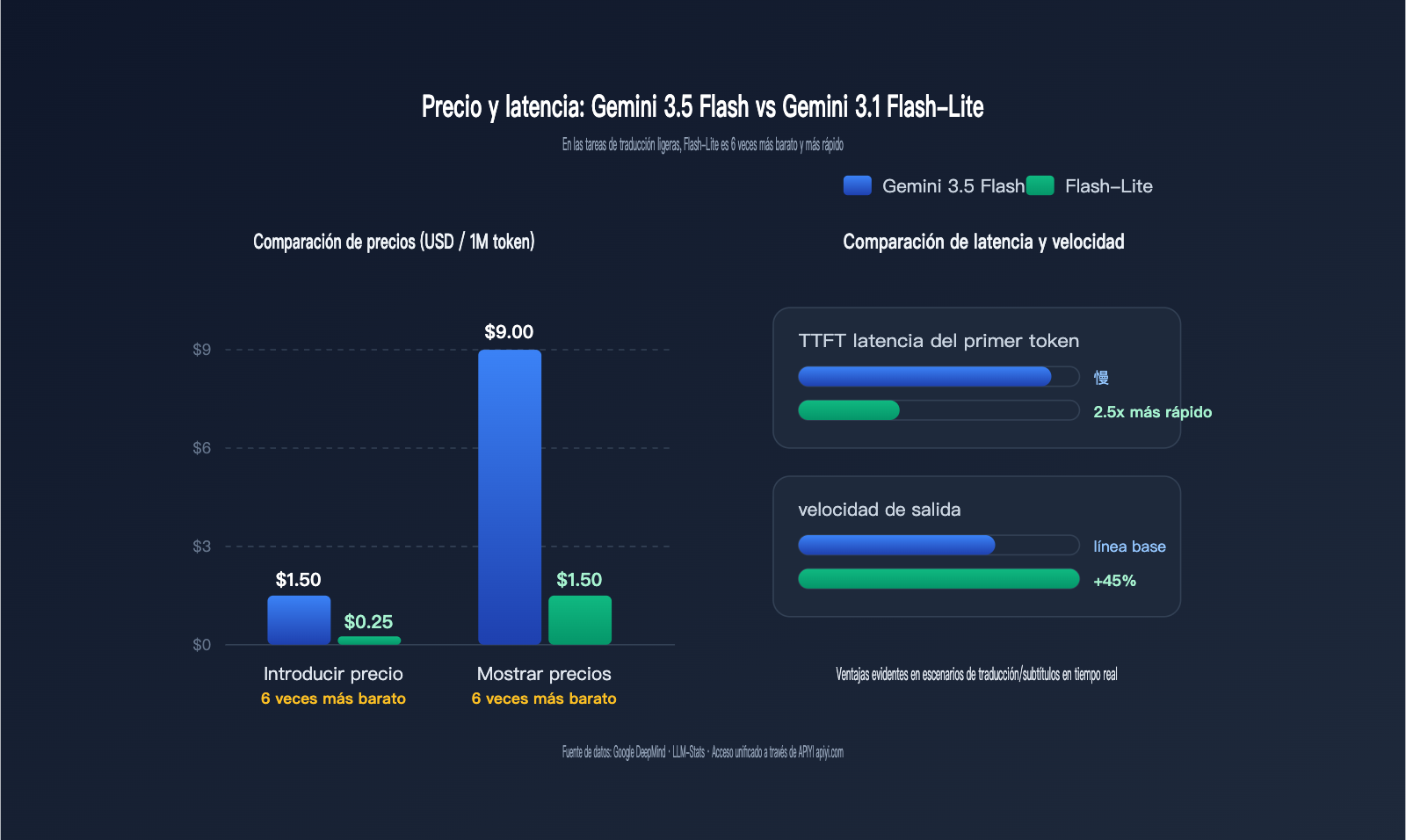
La siguiente tabla compara las dimensiones de costo más críticas en escenarios de traducción, con precios expresados en dólares por cada millón de tokens.
| Dimensión de costo/rendimiento | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Diferencia |
|---|---|---|---|
| Precio de entrada | $1.50 | $0.25 | Flash-Lite 6 veces más barato |
| Precio de salida | $9.00 | $1.50 | Flash-Lite 6 veces más barato |
| Entrada con caché | $0.15 | $0.025 (estimado) | Flash-Lite 6 veces más barato |
| TTFT (latencia primer token) | Más alta | 2.5x más rápido que 2.5 Flash | Flash-Lite |
| Velocidad de salida | Aprox. 289 token/s | 45% más rápido que 2.5 Flash | Empate/Ligeramente mejor Flash-Lite |
| Modo razonamiento por defecto | Activado, con costo de thinking | Se puede apagar, latencia cero | Flash-Lite |
Hagamos una simulación de factura real. Supongamos que un producto de traducción SaaS procesa 10 millones de tokens de entrada y 5 millones de tokens de salida al día (una aplicación B2C de escala media). ¿Cómo sería la factura mensual usando cada modelo?
| Factura mensual (10M entrada / 5M salida diarios) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Ahorro |
|---|---|---|---|
| Costo entrada diario | $15.00 | $2.50 | $12.50 |
| Costo salida diario | $45.00 | $7.50 | $37.50 |
| Total diario | $60.00 | $10.00 | $50 |
| Total mensual (30 días) | $1,800 | $300 | $1,500 / mes |
| Total anual | $21,600 | $3,600 | $18,000 / año |
💡 Consejo de cálculo de costos: Aplica los números de esta tabla a tu tráfico real; la diferencia mensual suele ser de cuatro cifras en dólares. Te sugiero registrarte en APIYI (apiyi.com) para obtener el crédito gratuito de 0.05 USD, usar el mismo conjunto de muestras de traducción para invocar
gemini-3.5-flashygemini-3.1-flash-lite-preview. Esto te permitirá verificar la diferencia de calidad y obtener el diferencial de precio real para tu negocio.
Análisis de rendimiento y velocidad de Gemini 3.1 Flash-Lite en traducción
Que un modelo sea barato no sirve de nada si la calidad de la traducción no está a la altura. Los datos reales de Gemini 3.1 Flash-Lite en tareas de traducción son bastante sólidos; en la gran mayoría de los casos, los usuarios no notarán una "diferencia significativa respecto a Flash". Los siguientes cuatro puntos son la evidencia clave:
Primero, su puntuación del 88.9% en el benchmark multilingüe MMMLU. El MMMLU (Multilingual MMLU) evalúa la capacidad del modelo para comprender conocimientos especializados y razonar en más de 15 idiomas. Alcanzar un 88.9% sitúa a Flash-Lite en la cima de los modelos de su categoría, lo que garantiza una alta calidad en idiomas no latinos como chino, japonés, coreano o árabe.
Segundo, Google DeepMind especifica en su ficha técnica que ofrece una "traducción y comprensión multilingüe de primera clase, con mejoras notables en escrituras no latinas". Este es el respaldo oficial de Google sobre la capacidad de traducción de Flash-Lite, destacando especialmente su mejora en "caracteres no latinos", algo fundamental para el SaaS en chino.
Tercero, la conclusión de la comparativa de Lara Translate en el Translation Model Benchmark de febrero de 2026: las variantes de la serie Flash se posicionan como la opción preferida para "flujos de trabajo de baja latencia y alto rendimiento". Las restricciones críticas de las tareas de traducción (baja latencia + alto rendimiento + sensibilidad al costo) encajan perfectamente con el diseño de Flash-Lite.
Cuarto, el tiempo hasta el primer token (TTFT) y la velocidad de salida. El TTFT de Flash-Lite es 2.5 veces más rápido que el de Gemini 2.5 Flash, con una mejora del 45% en la velocidad de salida. Estos indicadores determinan directamente la experiencia del usuario en escenarios donde la "inmediatez" es clave. Recomendamos realizar una prueba en APIYI (apiyi.com) comparando el tiempo que toma traducir 5000 caracteres de chino a inglés; la diferencia es muy evidente.
Recomendaciones de uso: ¿Cuándo elegir Flash-Lite y cuándo 3.5 Flash?
Podemos resumir la comparativa de 6 dimensiones en sugerencias concretas para tus tareas en la siguiente tabla. El objetivo no es determinar "qué modelo es más potente", sino "cuál usar para cada tarea específica".
| Tipo de tarea | Modelo recomendado | Razón clave |
|---|---|---|
| Traducción general (chino-inglés/chino-japonés, etc.) | Gemini 3.1 Flash-Lite | MMMLU 88.9% + 6x más barato |
| Traducción de subtítulos / Traducción en tiempo real | Gemini 3.1 Flash-Lite | TTFT 2.5x más rápido + 45% más velocidad |
| Moderación de contenido / Clasificación de texto | Gemini 3.1 Flash-Lite | Punto óptimo oficial de Google, ideal para tareas masivas |
| Extracción de datos estructurados | Gemini 3.1 Flash-Lite | Ideal para extracción masiva de JSON |
| Chatbots multilingües | Gemini 3.1 Flash-Lite | Calidad multilingüe + baja latencia + bajo costo |
| Traducción + Agente de post-procesamiento | Gemini 3.5 Flash | Requiere llamada a funciones (function calling) |
| Traducción + Llamada a herramientas | Gemini 3.5 Flash | Capacidad de agente superior a 3.1 Pro |
| Asistente de código / Autocompletado en IDE | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76.2% |
| Preguntas y respuestas RAG sobre documentos largos | Gemini 3.5 Flash | Acierto en caché + 1M de ventana de contexto |
| Flujos de trabajo de agentes complejos | Gemini 3.5 Flash | MCP Atlas 83.6% |
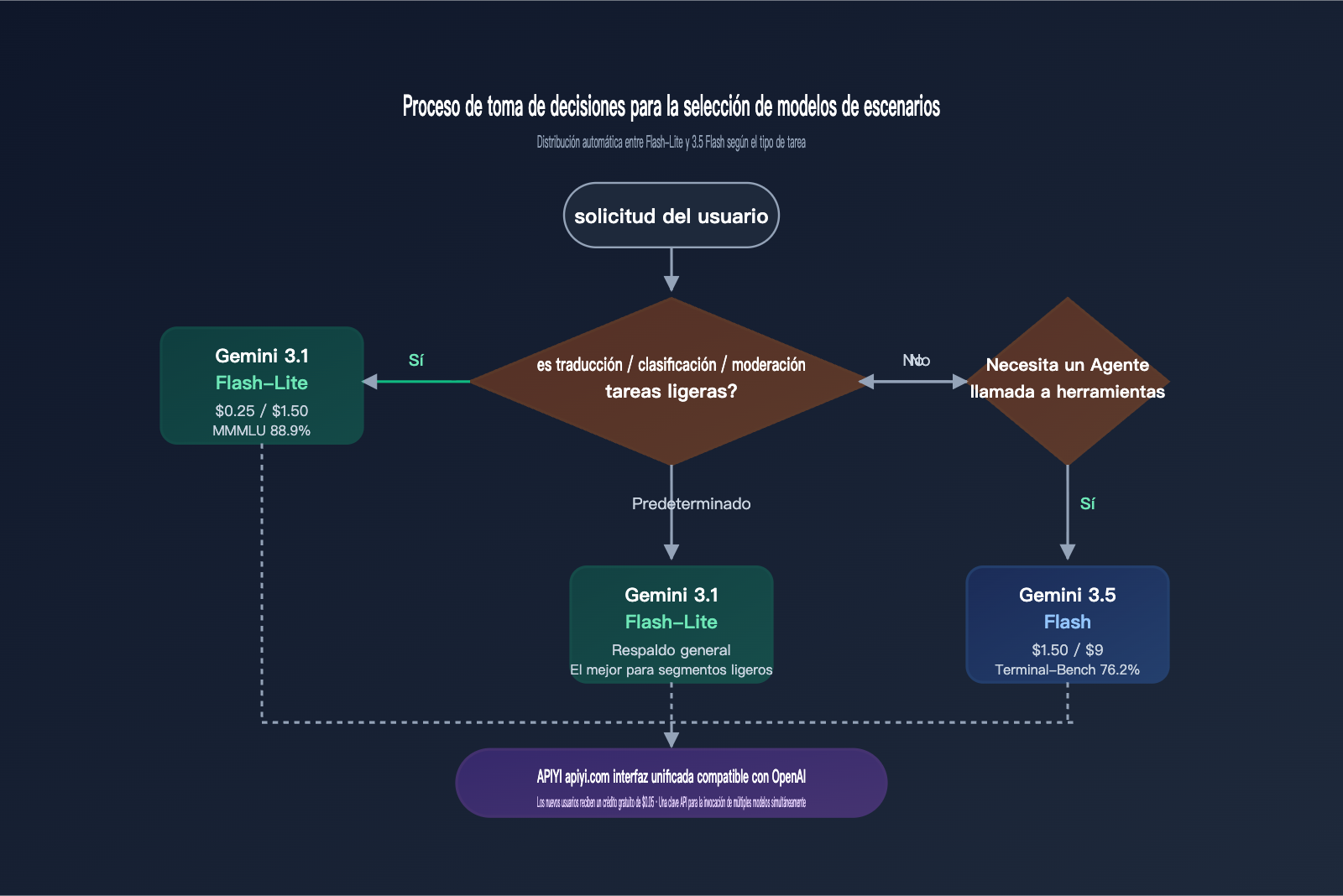
La estrategia más ideal en la práctica sigue siendo el "enrutamiento por tarea": traducción/clasificación/moderación a través de gemini-3.1-flash-lite-preview, y agentes/codificación/RAG de documentos largos a través de gemini-3.5-flash. Ambos modelos se pueden gestionar bajo la misma clave API de APIYI (apiyi.com). De esta forma, obtienes el beneficio de costo 6 veces menor de Flash-Lite en tareas ligeras, manteniendo el límite de capacidad de 3.5 Flash para agentes pesados.
Escenarios típicos para elegir Gemini 3.1 Flash-Lite
Si tu producto cumple con alguna de estas características, Flash-Lite es casi siempre la mejor opción: más de 100,000 llamadas diarias, entrada/salida única dentro de los 5K tokens, sensibilidad a la latencia P95, sin necesidad de llamadas a herramientas y soporte para múltiples idiomas. Los escenarios típicos incluyen traducción de productos de comercio electrónico transfronterizo, atención al cliente multilingüe SaaS, tuberías de moderación de contenido, generación de subtítulos y normalización tras OCR masivo. Gracias a la interfaz compatible con OpenAI de APIYI (apiyi.com), el costo de migración es prácticamente nulo.
Escenarios típicos donde se sigue recomendando Gemini 3.5 Flash
Si tu tarea requiere "llamar a herramientas después de traducir" o "integrar la traducción en una cadena de agentes compleja", Gemini 3.5 Flash cobra sentido. Por ejemplo: traducción + recuperación de base de conocimientos + llamada a API externa, o cuando el usuario envía un texto en idioma extranjero → el modelo traduce → y luego llama a herramientas de calculadora/búsqueda/ejecución de código. En este tipo de tareas, usar Flash-Lite provocará errores constantes debido a la falta de capacidad de agente, lo que resultará en un costo mayor.
Ejemplo de integración de Gemini 3.1 Flash-Lite en APIYI para escenarios de traducción
A continuación, presento un ejemplo de integración mínima en Python optimizado para tareas de traducción, que muestra cómo invocar Gemini 3.1 Flash-Lite en APIYI (apiyi.com) manteniendo la compatibilidad total con OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Traduce la entrada del usuario a {target_lang}. Devuelve solo la traducción, sin explicaciones."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
Ver implementación completa con concurrencia por lotes y rutas de respaldo
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Traduce a {target_lang}. Devuelve solo la traducción."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Traduce a {target_lang}. Devuelve solo la traducción."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Sugerencia para traducción por lotes: Los escenarios de traducción funcionan mejor con alta concurrencia (
concurrency=20~50), unatemperaturebaja (0.1-0.3) y una indicación del sistema corta. La plataforma APIYI (apiyi.com) ya ha optimizado el enrutamiento para escenarios de alto rendimiento. Los nuevos usuarios reciben un crédito gratuito de 0.05 USD, lo que, según el precio de $0.25/$1.50 de Flash-Lite, permite traducir entre 50,000 y 100,000 tokens de contenido real, suficiente para realizar una prueba de carga completa de un pipeline de traducción por lotes.
Preguntas frecuentes sobre la traducción: Gemini 3.5 Flash vs 3.1 Flash-Lite
Q1: Gemini 3.1 Flash-Lite es una versión Preview, ¿se puede usar en entornos de producción?
Se puede, pero es recomendable tomar precauciones. Flash-Lite ha estado en fase Preview desde su lanzamiento el 3 de marzo de 2026 y, aunque Google no ha dado una fecha oficial de disponibilidad general (GA), la interfaz de la API y los precios son estables. Sugerimos una estrategia de doble modelo para producción: "modelo principal Flash-Lite + respaldo 3.5 Flash", gestionando el cambio de ruta a través de la interfaz unificada de APIYI (apiyi.com) para evitar puntos únicos de fallo. Cuando Google lo actualice a GA o lance 3.5 Flash-Lite, solo tendrás que cambiar el campo model para una migración fluida.
Q2: ¿Realmente Flash-Lite alcanza a Flash en calidad de traducción?
En más del 90% de las tareas de traducción general, sí. La ficha técnica de Google DeepMind indica que Flash-Lite posee una "traducción y comprensión multilingüe de primera clase", con una puntuación MMMLU multilingüe de 88.9%. Sin embargo, 3.5 Flash sigue teniendo ventaja en dos escenarios: traducciones extensas con terminología técnica (medicina, derecho, finanzas) y traducción combinada con razonamiento contextual (por ejemplo, determinar a qué se refiere un pronombre según el contexto). Recomendamos ejecutar una prueba comparativa con muestras de tu negocio real en APIYI (apiyi.com) en lugar de basarte solo en los benchmarks.
Q3: ¿Es adecuado reemplazar GPT-4o-mini o Claude Haiku 4.5 por Flash-Lite para traducir?
Es adecuado y, por lo general, más barato y rápido. El precio de $0.25/$1.50 de Gemini 3.1 Flash-Lite es competitivo frente a GPT-4o-mini y Claude Haiku 4.5. En los benchmarks multilingües, el 88.9% de MMMLU de Flash-Lite supera a competidores de su misma categoría. Te sugerimos configurar los tres modelos bajo una misma clave en APIYI (apiyi.com) y realizar una prueba A/B para determinar cuál se adapta mejor a tus pares de idiomas específicos.
Q4: ¿Realmente se puede usar la ventana de contexto de 1M de Flash-Lite para traducir?
Sí, y es su capacidad más subestimada. 1M de tokens equivalen a unas 700,000-800,000 palabras en inglés o 300,000-400,000 caracteres chinos, suficiente para traducir de una sola vez un libro de longitud media o un conjunto completo de documentos corporativos. Con el modo de pensamiento desactivado, el costo de una traducción única con 1M de contexto es de aproximadamente $0.25 (entrada) + $1.50 (salida), mucho menor que dividir el contenido para 3.5 Flash o GPT-5.5. APIYI (apiyi.com) ya tiene habilitada la ventana de contexto de 1M para Flash-Lite, lista para usar.
Resumen: Gemini 3.1 Flash-Lite es la opción con mejor relación calidad-precio (6 veces superior) para tareas de traducción
Volviendo al punto central de este artículo: para tareas ligeras y de alta frecuencia como la traducción, Gemini 3.1 Flash-Lite no es una "versión recortada" de Gemini 3.5 Flash, sino la solución óptima diseñada específicamente por Google para este tipo de escenarios. Su precio de entrada es 6 veces más barato, el de salida también es 6 veces menor, la latencia del primer token es 2,5 veces más rápida, su puntuación multilingüe MMMLU alcanza un impresionante 88,9 % y Google ha catalogado oficialmente la traducción como su punto fuerte (sweet spot). Estos cinco hechos consolidan su posición dominante en el ámbito de la traducción. Las capacidades de agente y codificación de Gemini 3.5 Flash son innecesarias en este contexto, por lo que pagar un sobreprecio por ellas sería un desperdicio.
La estrategia más sensata es utilizar un enrutamiento de doble modelo: para traducción, clasificación y moderación, utiliza gemini-3.1-flash-lite-preview; para agentes, codificación y RAG con documentos extensos, opta por gemini-3.5-flash. Puedes alternar entre ambos bajo la misma clave API mediante la interfaz compatible con OpenAI de APIYI (apiyi.com). Los nuevos usuarios reciben un crédito gratuito de 0,05 USD al registrarse, suficiente para realizar una prueba de estrés completa en tu flujo de trabajo de traducción por lotes y verificar cuánto puedes ahorrar realmente en los costes de tu negocio.
Autor: Equipo técnico de APIYI · apiyi.com
Fecha de publicación: 20 de mayo de 2026
Referencias: Ficha técnica de Google DeepMind, Blog de Google, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub