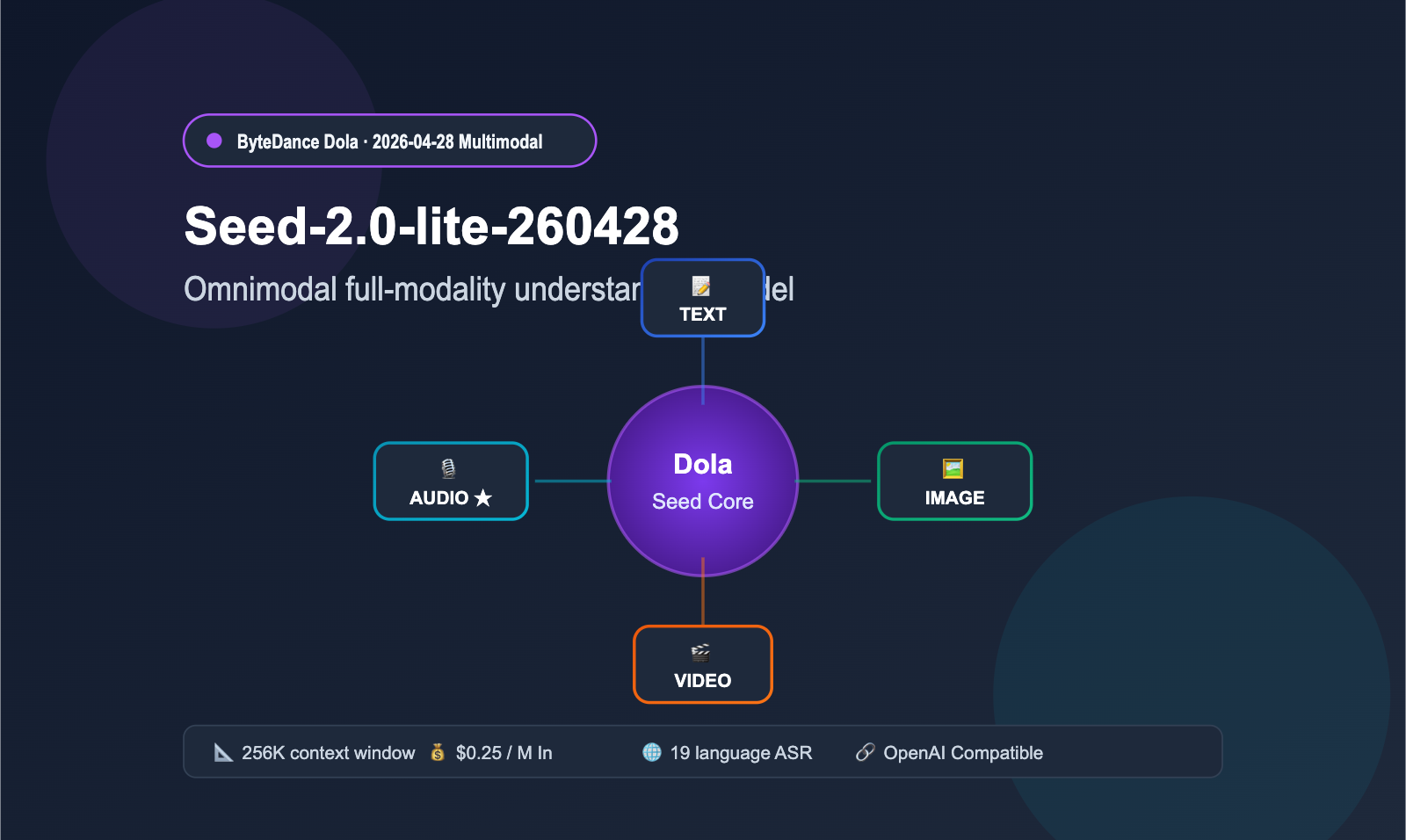
Here's an update that developers should definitely keep an eye on. On April 28, 2026, the ByteDance Dola foundation model family launched its first omnimodal understanding model, Seed-2.0-lite-260428. It natively supports four input modalities: video, image, audio, and text. This is the first model in the Dola Seed family that can "both see and hear," with simultaneous enhancements for tasks like Agents, Coding, and GUI interaction. This article breaks down the model's capabilities, audio understanding details, and typical use cases, based on official BytePlus ModelArk specifications, public ByteDance Seed benchmarks, and hands-on testing via APIYI (apiyi.com).
1. What is Seed-2.0-lite-260428: Core Positioning and Key Upgrades
Seed-2.0-lite-260428 is a significant iteration of the ByteDance Seed model released on April 28, 2026. While it builds upon the Seed-2.0-Lite foundation released in early March, it marks the first time "audio input" has been integrated as a native capability, pushing this product line into the realm of true "omnimodal" processing. The version number "260428" in the model name corresponds to its release date.
1.1 The First Omnimodal Model from the ByteDance Dola Family
In previous versions of the Dola Seed family, text and multimodal capabilities were housed in separate branches. Seed-2.0-lite-260428 unifies video, image, audio, and text inference within a single model. This means it can simultaneously "watch video footage" and "listen to audio content," performing joint reasoning and temporal retrieval based on both. This unified architecture is particularly critical for Agent-based applications, as many real-world tasks (such as video moderation, meeting summarization, and customer service quality assurance) naturally require cross-modal reasoning.
1.2 Quick Look at Core Model Specifications
The table below summarizes the core parameters of Seed-2.0-lite-260428 currently available on BytePlus ModelArk, helping you quickly determine if it fits your business needs.
| Specification | Parameter |
|---|---|
| API Model ID | seed-2-0-lite-260428 |
| Model Family | ByteDance Seed / Dola |
| Release Date | 2026-04-28 |
| Context Window | 262,144 tokens (~256K) |
| Max Output | 131,072 tokens (~128K) |
| Input Modalities | Text + Image + Video + Audio |
| Input Price | $0.25 / M tokens |
| Output Price | $2.00 / M tokens |
| API Compatibility | OpenAI Compatible API |
2. Four Key Capabilities of Seed-2.0-lite-260428's Full-Modal Understanding
The model's full-modal capability isn't just about "plugging in" various inputs; it's about performing joint reasoning through a unified representation. The official documentation summarizes its core capabilities into four key areas.
2.1 Joint Audio-Visual Reasoning and Temporal Retrieval
The model can analyze visual and audio information in a video simultaneously, accurately determining whether the "seen image" and "heard sound" are consistent. For example, it can judge whether a person's facial expressions in a video match their emotional tone, or if the actions on screen correspond to the correct sound effects. This audio-visual alignment capability is highly practical for scenarios like video moderation and deepfake detection.
2.2 Deep Video Decomposition and Long-Term Tracking
For long-form videos, Seed-2.0-lite-260428 supports extracting key clues across multiple time segments, continuously tracking characters and event progress, and performing multi-step reasoning across frames to reconstruct event relationships and behavioral context. Compared to traditional frame-by-frame description methods, its "long-term understanding" capability is better suited for tasks like surveillance video review and documentary editing assistance.
2.3 Enhanced Agent and Coding Capabilities
The model demonstrates stable and reliable execution capabilities for complex, long-sequence tasks and possesses deep full-stack development skills. This means developers can integrate it into an Agent framework to execute a complete closed loop—including planning, tool invocation, reviewing historical steps, and generating code—without needing to split tasks across multiple different models.
2.4 Unified Interface for GUI Understanding and Action Execution
GUI capabilities are integrated into a single interface, allowing the model to both understand screen captures (buttons, forms, menus) and output operation instructions (clicking coordinates, typing text). This is a direct upgrade for automated testing, desktop Agents, and RPA-style applications.
3. A Deep Dive into Seed-2.0-lite-260428's Audio Understanding
Audio is the most significant differentiator in this update, so let's break it down. The model has delivered impressive results across several mainstream audio benchmarks.
3.1 Performance on Mainstream Audio Benchmarks
The table below summarizes the benchmark scores officially released by ByteDance Seed, covering three dimensions: Automatic Speech Recognition (ASR), spoken language understanding, and wild speech scenarios.
| Benchmark | Task Type | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | English ASR (Clean) | 1.07 WER |
| LibriSpeech test-other | English ASR (Noise) | 2.17 WER |
| WenetSpeech test-net | Chinese ASR (Web) | 4.47 WER |
| WenetSpeech test-meeting | Chinese Meeting ASR | 5.31 WER |
| Fleurs (15 languages) | Multilingual ASR | 74.70 |
| MMSU | Spoken Language Understanding | 86.54 |
| WildSpeech | Wild Speech | 75.81 |
A WER of 1.07 on LibriSpeech test-clean is at the industry's top level, outperforming similar results from the public Whisper large-v3. The MMSU and WildSpeech scores are also slightly higher than the public data for Gemini 3.1 Pro, indicating that the model has reached a mainstream flagship level in terms of "understanding," not just "dictation."
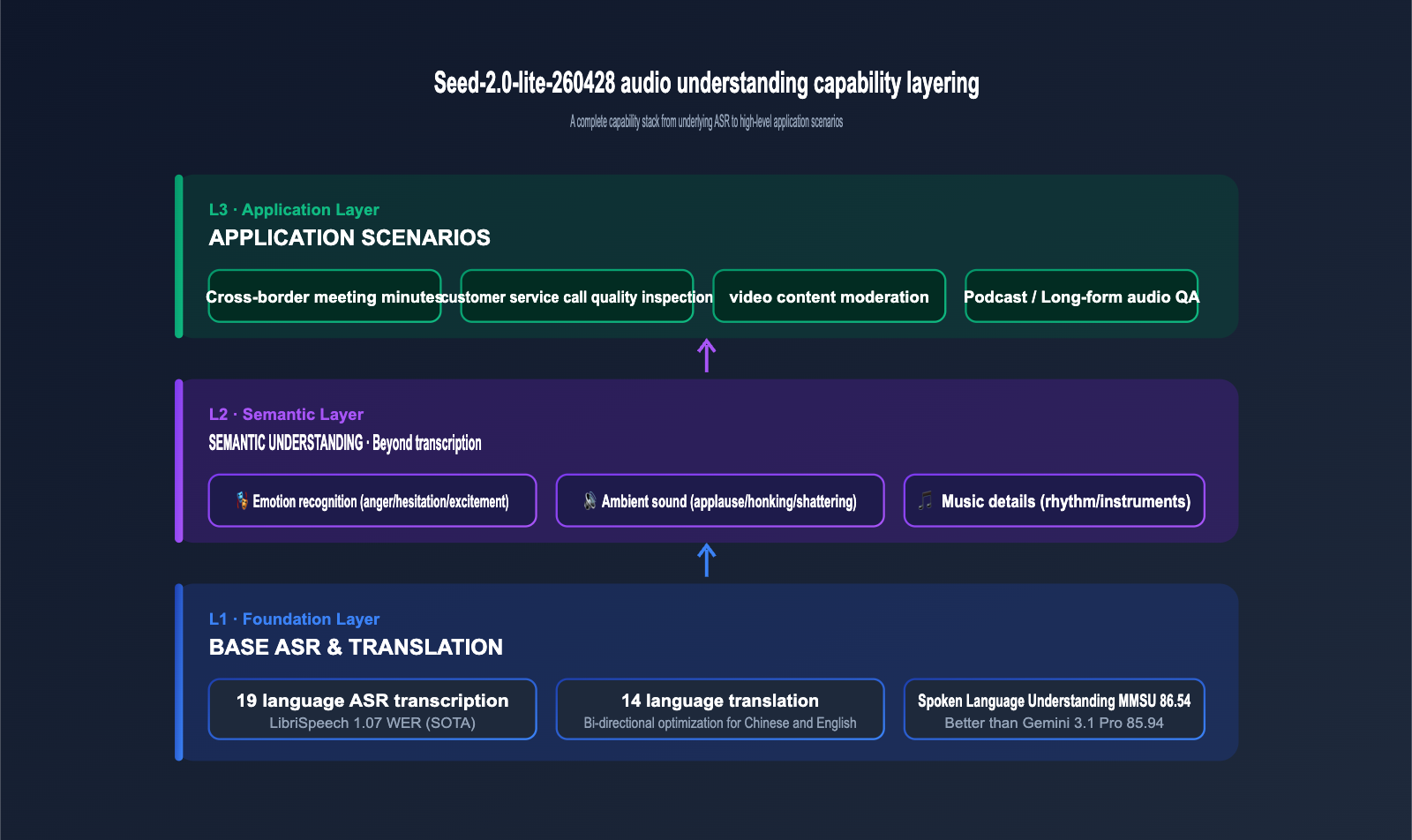
3.2 Transcription in 19 Languages and Translation Across 14 Languages
According to the official documentation, the model supports speech transcription in 19 languages and mutual translation between 14 languages, with bidirectional Chinese-English translation highlighted as a key optimization area. This means that for a single multilingual meeting recording, the model can output subtitles and translations in a unified language, making it ideal for cross-border teams and e-commerce customer service.
3.3 Beyond "Transcription": Emotion, Ambient Sound, and Musical Detail
The biggest difference from traditional ASR models is that Seed-2.0-lite-260428 can capture semantic information beyond just the "text content": speaker emotional fluctuations (anger, hesitation, excitement), background ambient sounds (breaking glass, applause, car horns), and musical details (rhythm, instruments, style). These dimensions have direct value for business applications like customer service quality inspection, content moderation, and music recommendation.
🎯 Integration Advice: For scenarios requiring "audio + text" synergy, such as cross-border meeting minutes, customer service quality inspection, and video content moderation, we recommend calling Seed-2.0-lite-260428 directly via APIYI (apiyi.com). A single base_url provides the dual benefits of multimodal reasoning and a 256K context window, eliminating the need to build your own voice pipeline.
4. Benchmarking Seed-2.0-lite-260428 Against Leading Multimodal Models
To gauge where this model stands in 2026, the best approach is to compare it directly with contemporary flagship multimodal models like GPT-4o and Gemini 3 Pro.
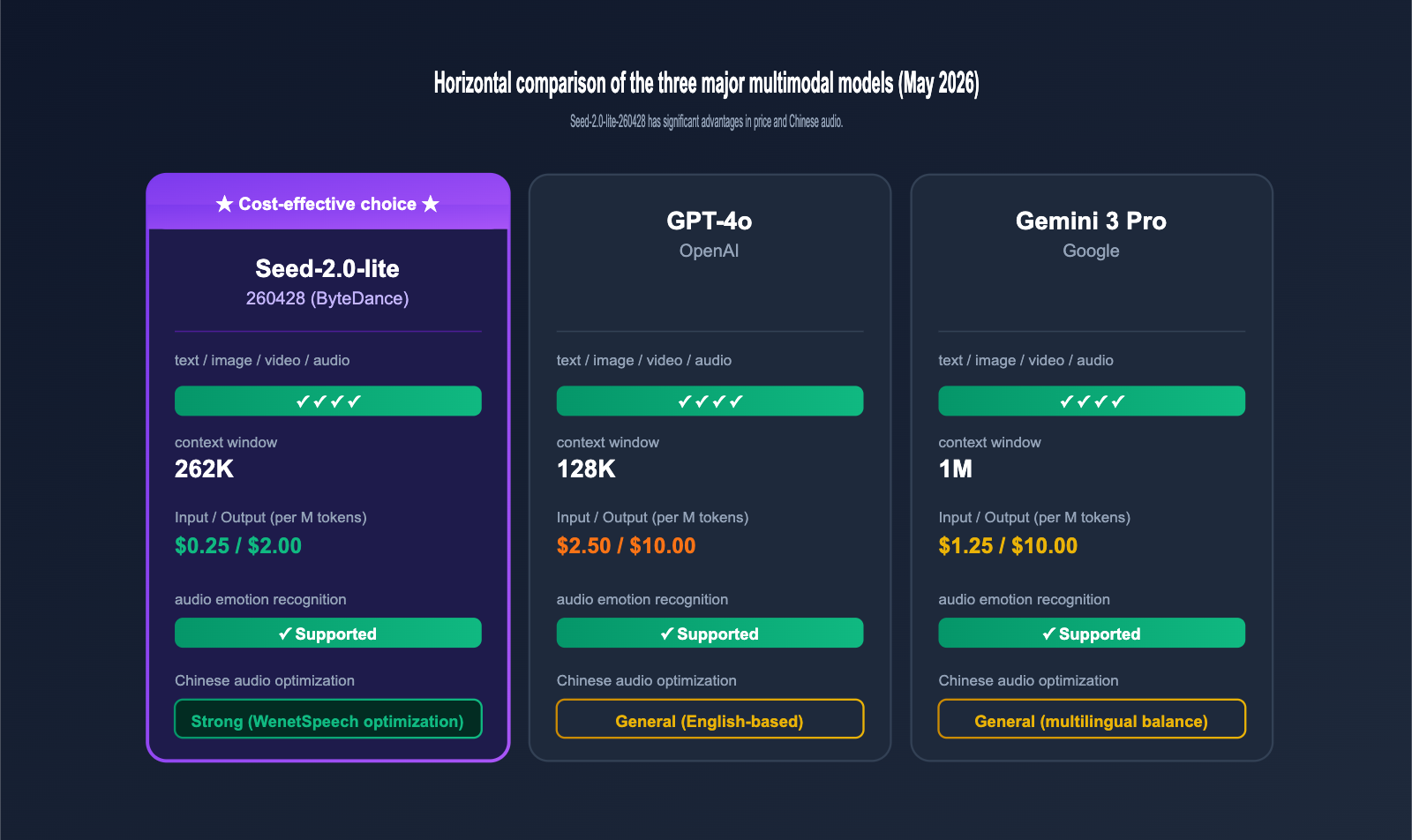
4.1 Capability Comparison of Leading Multimodal Models
| Dimension | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Text Input | ✓ | ✓ | ✓ |
| Image Input | ✓ | ✓ | ✓ |
| Video Input | ✓ | ✓ | ✓ |
| Audio Input | ✓ | ✓ | ✓ |
| Context Window | 262K | 128K | 1M |
| Input Price / M | $0.25 | $2.50 | $1.25 |
| Output Price / M | $2.00 | $10.00 | $10.00 |
| Audio Sentiment Analysis | ✓ | ✓ | ✓ |
| Chinese Audio Optimization | Strong (WenetSpeech) | Average | Average |
As you can see, the core advantage of Seed-2.0-lite-260428 lies in its "price + Chinese audio + 262K long context" combination, making it exceptionally cost-effective for tasks like multilingual audio/video processing and long meeting recaps. GPT-4o and Gemini 3 Pro still hold the edge in overall English proficiency and ecosystem breadth, making them better suited for general-purpose scenarios.
🎯 Selection Advice: If your business focuses primarily on Chinese audio/video processing and is cost-sensitive, Seed-2.0-lite-260428 is currently an extremely cost-effective choice. If your needs are English-centric or involve heavy multilingual creative generation, you can use the APIYI (apiyi.com) unified gateway to access all three flagship models and route requests based on the specific scenario.
5. Getting Started with Seed-2.0-lite-260428 via APIYI
The model is fully compatible with the OpenAI-style API, making migration incredibly easy. Below is a minimal example showing how to convert an image or audio file into a structured description.
5.1 Minimal Example for OpenAI-Compatible API
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Please describe the content, emotion, and background noise of this audio."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
By pointing the base_url to the unified APIYI (apiyi.com) endpoint and switching the model name, you can invoke Seed-2.0-lite-260428 alongside other multimodal models using the same SDK without needing to rewrite your code.
5.2 Typical Use Cases for Seed-2.0-lite-260428
The table below outlines several typical scenarios and how they benefit from the model's "unified audio + video + text inference" capabilities.
| Use Case | Key Capability | Business Value |
|---|---|---|
| Cross-border Meeting Minutes | 19-language ASR + 14-language translation + 256K context window | One-click bilingual minutes for multilingual meetings |
| Customer Service QA | Emotion recognition + ambient sound detection + long-form audio analysis | Automatic flagging of anger, interruptions, or overtime |
| Video Content Moderation | Joint audio-video inference + long-sequence tracking | Simultaneous detection of dangerous visuals and suspicious sounds |
| Podcast / Long-form Video QA | 256K long context window + audio transcription | Direct Q&A on hours of audio content |
| Desktop Agent Automation | GUI understanding + tool calling | Completing complex cross-application workflows |
6. Seed-2.0-lite-260428 FAQ
6.1 How should I fill in the model field for API calls?
Simply use seed-2-0-lite-260428. Note that it uses hyphens, not underscores. The suffix 260428 is the version number (April 28, 2026); do not omit it, or you might be routed to an older version. You can check the model list in the APIYI (apiyi.com) console to ensure you're using the latest release.
6.2 Which audio formats and durations are supported?
The model follows the OpenAI-style input_audio field convention and supports common formats like MP3, WAV, M4A, and FLAC. Please refer to the official ModelArk documentation for specific maximum durations and sample rates. We recommend keeping individual inputs under 30 minutes to ensure stable inference. For longer audio, you can segment it and merge the results.
6.3 What is the difference between this and the Seed-2.0-Lite version without the 260428 suffix?
The version without the suffix is the original Seed-2.0-Lite released on March 10, which only supports text, images, and video. The 260428 version is the full-modal upgrade released on April 28, which adds audio input and joint audio-video inference capabilities. If your business requires audio processing, you must use the version with the suffix.
6.4 Is billing based on tokens or audio duration?
The model is billed uniformly by tokens; audio is internally encoded into tokens for calculation. Current pricing is $0.25 / M input and $2.00 / M output. You can view the specific token count for an audio file in the "Billing Records" section of the APIYI (apiyi.com) console to help with cost estimation and optimization.
6.5 Does it support streaming output and Function Calling?
Yes, it's fully supported. Seed-2.0-lite-260428 is compatible with the stream=true and tools fields in the standard OpenAI Chat Completions protocol. You can integrate it directly into mainstream frameworks like LangChain, LangGraph, and the OpenAI Agents SDK without any special modifications.
VII. Summary: Omni-modal Models Usher in the Era of "Unified Inference" for Multimodal Applications
The value of Seed-2.0-lite-260428 goes beyond simply "adding audio capabilities." Its true significance lies in its ability to unify video, image, audio, and text within a single model for inference. For businesses that are inherently cross-modal—such as meeting analysis, customer service, content moderation, video analytics, and Agent automation—this "unified inference" represents a genuine architectural simplification. You no longer need to stitch together separate ASR, vision, and text models, nor do you have to worry about losing context between different models.
When it comes to cost and Chinese-language scenarios, this model offers a clear price-performance advantage among mainstream flagship models. At $0.25 per million input tokens, large-scale audio and video processing becomes engineeringly feasible, while the 256K context window is more than enough to cover hours of long-form audio and video.
If you need to unify the invocation of Seed-2.0-lite-260428 and other flagship multimodal models under a single base_url, you can visit the official APIYI documentation at apiyi.com to view complete integration examples and the full model list.
Author: APIYI Team — Continuously providing stable and efficient API proxy service and multi-model routing for global AI developers. For more details, visit apiyi.com.