2026年5月19日にGemini 3.5 Flashが一般公開(GA)されて以来、多くのチームが翻訳、字幕生成、コンテンツモデレーションといった高頻度かつ軽量なタスクを含む、すべてのGeminiトラフィックをデフォルトで移行させています。しかし、これは明らかに誤った判断です。入出力が短く、単価に極めて敏感で、遅延を嫌い、Agentツールによる編排を必要としない翻訳のようなシナリオでは、高価で「万能」なGemini 3.5 Flashよりも、Gemini 3.1 Flash-Liteこそが真の最適解だからです。本記事では、Google DeepMindの公式モデルカード、LLM-Stats、Artificial Analysisなどの一次情報を基に、これら2つのモデルを6つの側面から体系的に比較します。

結論を申し上げます。翻訳、字幕生成、バッチ分類、テキスト正規化といった軽量なシナリオでは、Gemini 3.5 FlashではなくGemini 3.1 Flash-Liteを推奨します。その理由は主に6点あります。入力コストが6倍安く、出力コストも6倍安いこと、最初のトークン生成までの遅延が2.5倍速いこと、MMMLU多言語スコアが88.9%と高いこと、Google公式が翻訳を「スイートスポット(最適領域)」として挙げていること、そして3.5 Flashの強みであるAgent機能が翻訳では全く不要であることです。まずはAPIYI(apiyi.com)の0.05ドルの無料枠を利用して、実際の翻訳タスクで比較テストを行うことをお勧めします。実際のコストと品質の差は、ベンチマーク数値よりも直感的に理解できるはずです。
翻訳シナリオにおいてGemini 3.1 Flash-LiteがGemini 3.5 Flashより優れている理由
翻訳タスクの特性は非常に明確です。入力はソース言語の短いテキスト(数百から数千トークン)、出力はターゲット言語の短いテキストであり、単一の呼び出しにおいて思考プロセスやツール呼び出し、マルチモーダル融合は必要ありません。しかし、呼び出し頻度が極めて高く、コストと遅延に非常に敏感です。これこそが、Flash-LiteシリーズがGoogleによって設計されたシナリオです。
Gemini 3.1 Flash-Liteは2026年3月3日にリリースされました。Google公式ブログでは「これまでで最もコスト効率の高いAIモデル」と謳われており、「大規模な翻訳、コンテンツ分類、モデレーション、構造化データ抽出、反復的なエージェントタスク」がそのスイートスポットであると明記されています。DeepMindのモデルカードでは、さらに「クラス最高の翻訳と多言語理解能力を持ち、特に非ラテン文字において顕著な改善が見られる」と指摘されており、MMMLU多言語ベンチマークスコアは88.9%と、軽量モデルの中ではトップクラスです。
一方、Gemini 3.5 Flashは5月19日に一般公開された「Agentic Flash」であり、「Agentツール編排+コーディングの主力」として位置づけられています。Terminal-Bench 2.1、MCP Atlas、Finance Agent v2ではGemini 3.1 Proを上回る性能を見せました。しかし、これらのAgent能力は翻訳タスクでは全く活用されず、そのために支払うプレミアムは完全に無駄になります。これが「Flashシリーズ」内でタスクタイプに応じて使い分けるべき理由です。Agentタスクには3.5 Flashを、翻訳・分類・モデレーションには3.1 Flash-Liteを使いましょう。
🎯 モデル選定の核心アドバイス:「バージョン番号が大きい方が良い」という直感に惑わされないでください。Gemini 3.5 Flash(5月リリース)とGemini 3.1 Flash-Lite(3月リリース)は、それぞれ「Agentの主力」と「高スループット・軽量」という2つの異なる領域をカバーする並行製品ラインです。APIYI(apiyi.com)プラットフォームでは両方のモデルが利用可能であり、同じ認証キーの下でタスクタイプに応じて自動ルーティングを行うことができるため、どちらか一方を選ぶ必要はありません。
Gemini 3.5 Flash vs Gemini 3.1 Flash-Lite スペック比較
2つのモデルを1つの表にまとめることで、製品ラインナップの役割分担と能力の違いが一目瞭然になります。以下の表は、両モデルの主要スペックをまとめたものです。すべてのデータは、Google DeepMindのモデルカードおよびLLM-Statsの公開ページに基づいています。
| 比較項目 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 翻訳用途での優位性 |
|---|---|---|---|
| リリース日 | 2026年5月19日 | 2026年3月3日 | — |
| リリース状況 | GA(正式版) | Preview(プレビュー版) | — |
| モデルID | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| 位置付け | Agentic Flash(ツール連携) | High-volume(高スループット) | Flash-Lite |
| コンテキストウィンドウ | 1M 入力 / 64K 出力 | 1M 入力 / 64K 出力 | 引き分け |
| 入力モダリティ | テキスト+画像+音声+動画 | テキスト+画像+音声+動画 | 引き分け |
| 思考モード | 動的思考がデフォルトで有効 | 思考レベル調整可能 | Flash-Lite(オフ可) |
| 知識のカットオフ | 2026年1月 | 2025年1月 | 3.5 Flash |
| MMMLU 多言語 | 未公開(予想 80+) | 88.9% | Flash-Lite |
| 出力速度 | 約 289 token/s | 2.5 Flash比で45%高速、TTFTは2.5倍高速 | Flash-Lite |
| エージェントツール能力 | 3.1 Proの複数ベンチマークを上回る | 標準的な関数呼び出し | 翻訳用途では不要 |
| APIYI 接続 | 対応済み | 対応済み | 引き分け |
この表を読む際は、3つの分岐点に注目してください。1つ目は「位置付けの違い」です。Flash-Liteは「high-volume(大量処理)」を掲げており、Googleが設計段階から「単一の知能よりもスループットを優先する」という製品思想を持っていることがわかります。これは翻訳や分類といった高頻度タスクのニーズに合致しています。2つ目は「MMMLU 88.9%」という数値です。これは公開されているGemini 3.xファミリーの中で多言語ベンチマークが最も高い軽量モデルであり、翻訳品質を直接的に示しています。3つ目は「思考レベルの調整」です。Flash-Liteは「思考(thinking)」プロセスをオフにできるため、翻訳のような思考を必要としないタスクにおいて、レイテンシをさらに低減できます。
翻訳シーンにおけるコスト比較:Gemini 3.5 Flash vs 3.1 Flash-Lite の6倍の価格差
コストは翻訳シーンにおける選定の最も重要な指標です。翻訳タスクは「入出力は長くないが頻度が極めて高い」という特徴があります。一般的なSaaS製品では、1日に数千万から数億トークンの翻訳を処理することも珍しくなく、単価が6倍違えば、月々の請求額に数千ドルから数万ドルの差が生じます。
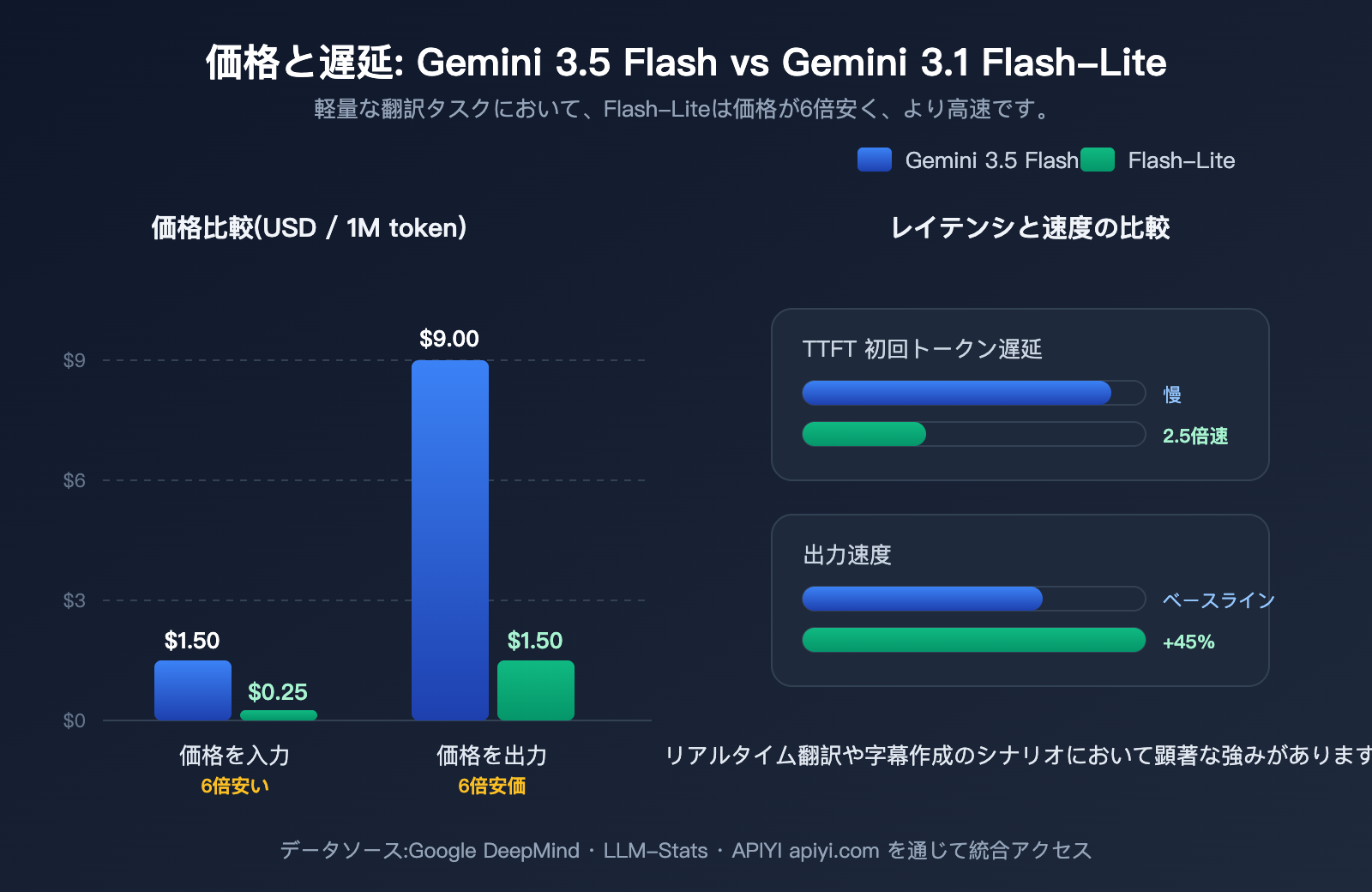
以下の表は、翻訳シーンにおける重要なコスト項目を比較したものです。すべての価格は100万トークンあたりの米ドル単価です。
| コスト/性能項目 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 差分 |
|---|---|---|---|
| 入力価格 | $1.50 | $0.25 | Flash-Liteが6倍安い |
| 出力価格 | $9.00 | $1.50 | Flash-Liteが6倍安い |
| キャッシュヒット入力 | $0.15 | $0.025(推定) | Flash-Liteが6倍安い |
| TTFT(初トークン遅延) | 低い | 2.5 Flash比で2.5倍高速 | Flash-Lite |
| 出力速度 | 約 289 token/s | 2.5 Flash比で45%高速 | 同等〜Flash-Liteがやや優勢 |
| 思考モードデフォルト | 有効(思考コストあり) | オフ可(思考遅延ゼロ) | Flash-Lite |
実際の請求額をシミュレーションしてみましょう。あるSaaS翻訳製品が毎日1,000万トークンの入力と500万トークンの出力を処理する場合(中規模B2Cアプリ)、両モデルで1ヶ月運用した際のコストは以下のようになります。
| 月間コスト(毎日 1000万入力 / 500万出力) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 節約額 |
|---|---|---|---|
| 1日の入力コスト | $15.00 | $2.50 | $12.50 |
| 1日の出力コスト | $45.00 | $7.50 | $37.50 |
| 1日の合計 | $60.00 | $10.00 | $50 |
| 月間合計(30日) | $1,800 | $300 | $1,500 / 月 |
| 年間合計 | $21,600 | $3,600 | $18,000 / 年 |
💡 コスト試算のアドバイス:この表の数値を貴社の実際のトラフィックに当てはめてみてください。月間の差額は通常4桁ドル以上になります。まずは APIYI (apiyi.com) でアカウントを作成し、0.05ドルの無料枠を利用して、同一の翻訳サンプルで
gemini-3.5-flashとgemini-3.1-flash-lite-previewをそれぞれ呼び出してみてください。品質の差を検証できるだけでなく、自社ビジネスにおける実際の価格差を直接確認できます。
Gemini 3.1 Flash-Lite の翻訳品質と速度に関する実測分析
価格が安いことは重要ですが、前提条件は「翻訳品質が十分であること」です。Gemini 3.1 Flash-Lite の翻訳に関する実測データは非常に説得力があり、ほとんどのシナリオにおいて、ユーザーが「明らかに Flash より劣る」と感じることはありません。以下の4つのデータがその核心的な根拠です。
1つ目は、MMMLU 多言語ベンチマークでの 88.9% というスコアです。MMMLU(Multilingual MMLU)は、15以上の言語における専門知識の理解と推論能力を評価するもので、Flash-Lite がこのスコアを達成したことは、Flash-Lite クラスのモデルの中ではトップレベルです。これは、中国語、日本語、韓国語、アラビア語などの非ラテン系言語においても、高い品質を維持できることを意味します。
2つ目は、Google DeepMind がモデルカードで明記している「best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts(クラス最高の翻訳と多言語理解、特に非ラテン文字での改善)」という評価です。これは Google による公式のお墨付きであり、特に中国語の SaaS にとって極めて重要な「非ラテン文字」への対応強化が強調されています。
3つ目は、2026年2月の Lara Translate による「Translation Model Benchmark」での結論です。Flash シリーズの派生モデルは「低レイテンシかつ高スループットなワークフロー」の第一候補として位置付けられており、翻訳タスクの制約(低レイテンシ、高スループット、コスト意識)と Flash-Lite の設計目標が高度に合致しています。
4つ目は、Time-to-First-Token(TTFT)と出力速度です。Flash-Lite の TTFT は Gemini 2.5 Flash よりも 2.5 倍速く、出力速度は 45% 向上しています。これらの指標は、翻訳のような「リアルタイム性が求められる」シナリオにおいて、ユーザー体験を直接左右します。APIYI (apiyi.com) にて、5000文字の中国語を英語に翻訳する際の所要時間を測定してみることをお勧めします。その差は一目瞭然です。
シナリオ別推奨:Flash-Lite を選ぶべきか、3.5 Flash を選ぶべきか
6つの次元での比較を具体的なタスク選定の提案に落とし込むと、以下の推奨表にまとめられます。これは「どちらのモデルが優れているか」ではなく、「どのタスクにどちらを使うべきか」を解決するものです。
| タスクタイプ | 推奨モデル | 主な理由 |
|---|---|---|
| 一般的なテキスト翻訳(中英/中日など) | Gemini 3.1 Flash-Lite | MMMLU 88.9% + コストが 6 分の 1 |
| 字幕翻訳 / リアルタイム翻訳 | Gemini 3.1 Flash-Lite | TTFT 2.5 倍高速 + 出力速度 45% 向上 |
| コンテンツ審査 / テキスト分類 | Gemini 3.1 Flash-Lite | Google 公式の最適解、バッチ処理に最適 |
| 構造化データ抽出 | Gemini 3.1 Flash-Lite | 大量の JSON 抽出に適している |
| 多言語チャットボット | Gemini 3.1 Flash-Lite | 多言語品質 + 低レイテンシ + 低コスト |
| 翻訳 + 後処理 Agent | Gemini 3.5 Flash | 複数のツールを繋ぐ関数呼び出しが必要 |
| 翻訳 + ツール呼び出し | Gemini 3.5 Flash | Agent 能力が 3.1 Pro を上回る |
| コードアシスタント / IDE 補完 | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76.2% |
| 長文ドキュメント RAG 応答 | Gemini 3.5 Flash | キャッシュヒット + 1M コンテキスト |
| 複雑な Agent ワークフロー | Gemini 3.5 Flash | MCP Atlas 83.6% |
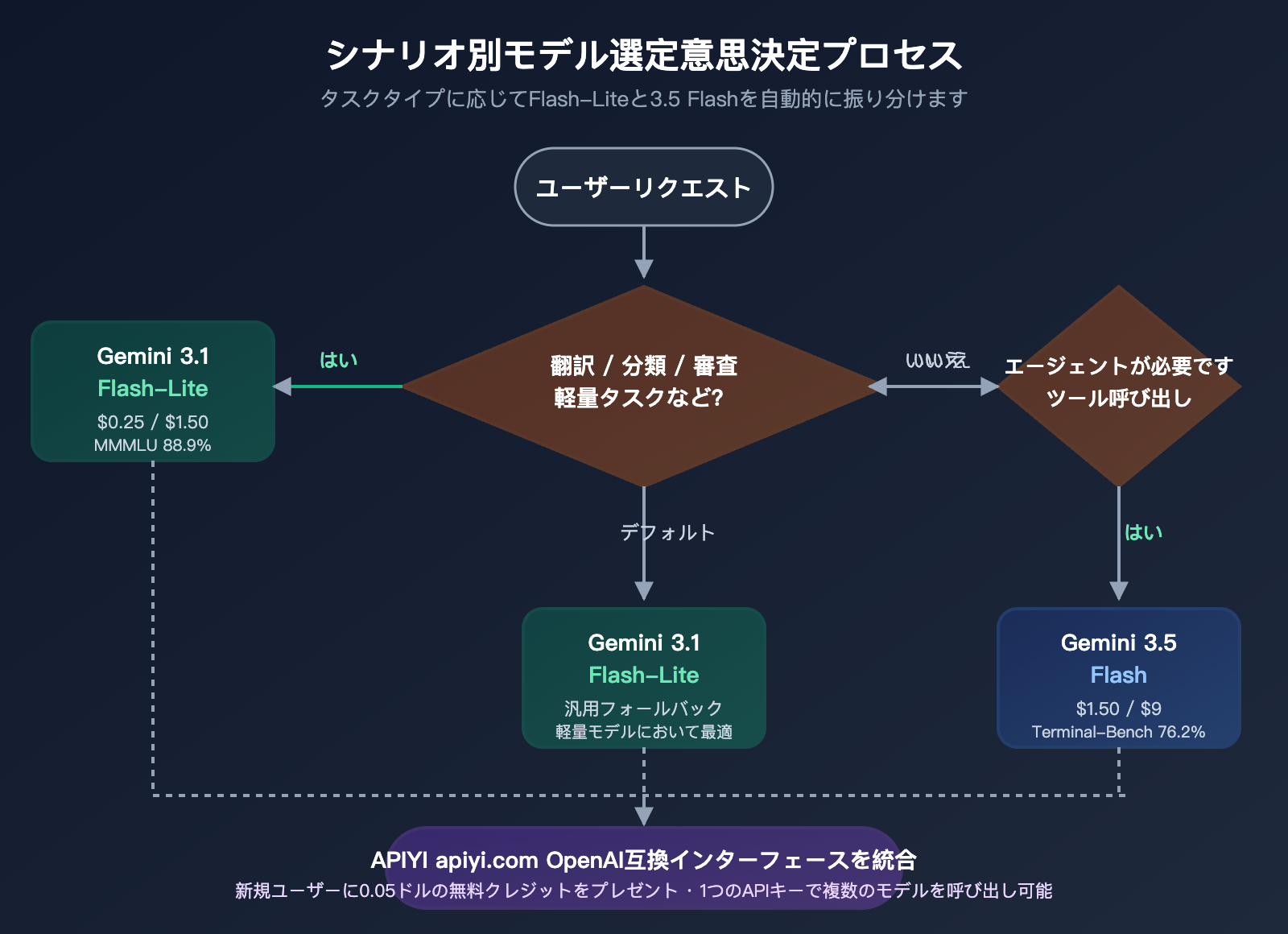
実践において最も理想的な戦略は依然として「タスクに応じたルーティング」です。翻訳、分類、審査には gemini-3.1-flash-lite-preview を使い、Agent、コーディング、長文ドキュメント RAG には gemini-3.5-flash を使用します。これら2つのモデルを同一の APIYI (apiyi.com) の APIキーで管理し、切り替えることで、Flash-Lite の軽量タスクにおける 6 倍のコストメリットを享受しつつ、3.5 Flash の高度な Agent 能力を維持することができます。
Gemini 3.1 Flash-Lite を選ぶべき典型的なシナリオ
製品が以下の特徴のいずれかに当てはまる場合、Flash-Lite がより良い選択肢となる可能性が高いです:1日の呼び出し回数が 10 万回を超える、1回の入力・出力が 5K トークン以内、P95 レイテンシに敏感、ツール呼び出しが不要、多言語対応が必要。典型的なシナリオには、越境 EC の商品翻訳、SaaS の多言語カスタマーサポート、コンテンツ審査パイプライン、字幕生成、バッチ OCR 後の正規化などが含まれます。APIYI (apiyi.com) の OpenAI 互換インターフェースを活用すれば、移行コストはほぼゼロです。
それでも Gemini 3.5 Flash を推奨する典型的なシナリオ
タスクに「翻訳後にツールを呼び出す必要がある」あるいは「翻訳を複雑な Agent チェーンに組み込む」といった要件がある場合は、Gemini 3.5 Flash を選ぶ意味があります。例えば、翻訳+ナレッジベース検索+外部 API 呼び出し、あるいはユーザーが送信した外国語をモデルが翻訳し、さらに計算機、検索、コード実行ツールを呼び出すといったケースです。このようなタスクで Flash-Lite を使用すると、Agent 能力の不足によりエラーが頻発し、結果としてコストがかさんでしまう可能性があります。
翻訳シナリオにおける Gemini 3.1 Flash-Lite の APIYI 接続例
翻訳タスクに最適化された、最もシンプルな Python 接続例を紹介します。APIYI(apiyi.com)上で Gemini 3.1 Flash-Lite を呼び出す方法で、OpenAI 互換の記述をそのまま利用可能です。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"ユーザーの入力を {target_lang} に翻訳してください。翻訳結果のみを出力し、説明は不要です。"},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
バッチ並列処理とフォールバックルーティングを含む完全な実装を見る
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"{target_lang} に翻訳してください。翻訳結果のみを出力してください。"},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"{target_lang} に翻訳してください。翻訳結果のみを出力してください。"},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 バッチ翻訳の最適化アドバイス:翻訳タスクは、高い並列数(
concurrency=20~50)、低めの temperature(0.1-0.3)、短いシステムプロンプトの組み合わせが適しています。APIYI(apiyi.com)プラットフォームは、高スループットのシナリオ向けにルーティングが最適化されています。新規登録で 0.05 ドル分の無料クレジットが付与されます。Flash-Lite の $0.25/$1.50 という価格設定であれば、約 5 万〜10 万トークンの翻訳が可能で、バッチ翻訳パイプラインの負荷テストには十分な量です。
Gemini 3.5 Flash vs 3.1 Flash-Lite 翻訳に関する FAQ
Q1: Gemini 3.1 Flash-Lite はプレビュー版ですが、本番環境で使えますか?
使用可能ですが、万全を期すことをお勧めします。Flash-Lite は 2026 年 3 月 3 日のリリース以来プレビュー段階にありますが、API インターフェースと価格は安定しています。本番環境では「メインルーティングに Flash-Lite、異常時のフォールバックに 3.5 Flash」というデュアルモデル戦略を推奨します。APIYI(apiyi.com)の統一インターフェースを通じてルーティングを切り替えることで、単一障害点を回避できます。Google が GA 版へ昇格させたり、3.5 Flash-Lite をリリースしたりした際は、モデルフィールドを書き換えるだけでスムーズに移行可能です。
Q2:翻訳品質において、Flash-Lite は本当に Flash に追いつけますか?
一般的な翻訳タスクの 90% 以上において、はい、追いついています。Google DeepMind のモデルカードには、Flash-Lite が「クラス最高レベルの翻訳と多言語理解」を備えており、MMMLU 多言語スコアが 88.9% であることが明記されています。ただし、3.5 Flash が優位なケースも 2 つあります。1 つ目は専門用語(医療、法律、金融)を含む長文翻訳、2 つ目は翻訳とコンテキスト推論(文脈に基づいた代名詞の指し示しの判断など)を組み合わせる場合です。ベンチマークスコアだけでなく、APIYI(apiyi.com)を通じて実際の業務サンプルで比較評価することをお勧めします。
Q3:GPT-4o-mini や Claude Haiku 4.5 の代わりに Flash-Lite を使うのは適切ですか?
適切であり、多くの場合、より安価で高速です。Gemini 3.1 Flash-Lite の $0.25/$1.50 という価格設定は GPT-4o-mini($0.15/$0.60 と一見安価ですが、実測の翻訳品質は Flash-Lite に劣ります)や Claude Haiku 4.5 よりも低コストです。多言語ベンチマークにおいても、Flash-Lite の 88.9% という MMMLU スコアは同クラスの競合製品を上回っています。APIYI(apiyi.com)上で 3 つの候補モデルを同じキーで A/B 比較し、特定の言語ペアに最適なモデルを実測することをお勧めします。
Q4: Flash-Lite の 1M コンテキストウィンドウは本当に翻訳に使えますか?
はい、使えます。そして、これこそが最も過小評価されている能力です。1M トークンは約 70 万〜80 万語の英語、または 30 万〜40 万文字の中国語に相当し、中程度の長さの書籍や企業文書一式を一度に翻訳するのに十分です。Thinking モードをオフにすれば、1M コンテキストの翻訳コストは入力 $0.25 + 出力 $1.50 程度となり、同じ内容を 3.5 Flash や GPT-5.5 に分割して処理させるよりも遥かに低コストです。APIYI(apiyi.com)では Flash-Lite の 1M コンテキストウィンドウを完全に開放しており、直接呼び出すことが可能です。
まとめ:翻訳タスクにおいて Gemini 3.1 Flash-Lite がコストパフォーマンス 6 倍の最適解である理由
本稿の核心となる結論をお伝えします。翻訳のような軽量かつ高頻度なタスクにおいて、Gemini 3.1 Flash-Lite は Gemini 3.5 Flash の「廉価版」ではなく、Google がまさにこのようなユースケースのために設計した最適解です。入力コストは 6 倍安く、出力コストも 6 倍安く、最初のトークンの遅延は 2.5 倍高速です。さらに、MMMLU の多言語スコアは 88.9% に達しており、Google 公式も翻訳をこのモデルの「スイートスポット(最も得意とする領域)」として挙げています。これら 5 つの事実が、翻訳タスクにおける圧倒的な優位性を裏付けています。Gemini 3.5 Flash が持つエージェント機能やコーディング能力は翻訳には不要であり、それらの機能に対して支払うコストは無駄になってしまいます。
最も賢明な戦略は、デュアルモデルルーティングを採用することです。翻訳・分類・審査には gemini-3.1-flash-lite-preview を使用し、エージェント・コーディング・長文ドキュメントの RAG には gemini-3.5-flash を使用します。APIYI (apiyi.com) の OpenAI 互換インターフェースを利用すれば、単一の API キーでこれらをシームレスに切り替えることが可能です。新規ユーザーには 0.05 ドル分の無料クレジットを贈呈しており、バッチ翻訳パイプラインの負荷テストを十分に行い、実際の業務でどれほどのコスト削減が可能か検証いただけます。
著者: APIYI 技術チーム · apiyi.com
公開日: 2026 年 5 月 20 日
参考資料: Google DeepMind Model Card、Google Blog、LLM-Stats、Artificial Analysis、DevTK、AIMLAPI、Lara Translate Benchmark、Emelia Hub