很多团队在 Gemini 3.5 Flash 2026 年 5 月 19 日 GA 之后,默认就把所有 Gemini 流量迁过去,包括翻译、字幕生成、内容审核这类高频轻量任务。这其实是一个明显的误判。在翻译这类输入输出都不长、对单价极度敏感、对延迟极度敏感、不需要 Agent 工具编排的场景里,Gemini 3.1 Flash-Lite 才是真正的最优解,而不是更贵更"全能"的 Gemini 3.5 Flash。本文从 6 个维度系统对比这两款模型,数据全部来自 Google DeepMind 官方 model card、LLM-Stats、Artificial Analysis 等英文一手资料。

直接给结论:在翻译、字幕、批量分类、文本规范化这一类轻量级场景里,我推荐 Gemini 3.1 Flash-Lite 而不是 Gemini 3.5 Flash,核心原因有六点:输入便宜 6 倍、输出便宜 6 倍、首 token 延迟快 2.5 倍、MMMLU 多语言得分高达 88.9%、翻译被 Google 官方列为它的 sweet spot、3.5 Flash 的 Agent 强项在翻译里完全用不上。建议先通过 API易 apiyi.com 的 0.05 美金免费额度跑一组真实翻译任务做横评,实际成本与质量差距比基准数字更直观。
翻译场景下 Gemini 3.1 Flash-Lite 为什么更胜任 Gemini 3.5 Flash
翻译这类任务的特征非常清晰:输入是源语言短文本(几百到几千 token),输出是目标语言短文本,单次调用不需要思考链路、不需要工具调用、不需要多模态融合,但调用频次极高、对成本和延迟极度敏感。这正是 Flash-Lite 系列被 Google 设计出来的场景。
Gemini 3.1 Flash-Lite 在 2026 年 3 月 3 日 release,Google 官方博客原话是 "our most cost-effective AI model yet",并明确把"massive translation, content classification, moderation, structured data extraction, repetitive agentic tasks"列为它的 sweet spot。DeepMind 的 model card 进一步指出它具备"best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts",MMMLU 多语言基准得分 88.9%,在轻量段位里属于绝对头部。
Gemini 3.5 Flash 是 5 月 19 日 GA 的 Agentic Flash,定位是"Agent 工具编排 + 编码主力",在 Terminal-Bench 2.1、MCP Atlas、Finance Agent v2 上反超 Gemini 3.1 Pro。但这些 Agent 能力在翻译任务里完全用不上,你为这些能力付的溢价是纯浪费。这就是为什么"Flash 系列"内部要按任务类型再切一刀:Agent 走 3.5 Flash,翻译/分类/审核走 3.1 Flash-Lite。
🎯 选型核心建议:不要被"版本号大就更好"的直觉误导。Gemini 3.5 Flash(5 月发布)与 Gemini 3.1 Flash-Lite(3 月发布)是两条平行产品线,分别覆盖"Agent 主力"与"高吞吐轻量"两个段位。API易 apiyi.com 平台同时上线了两款模型,可以在同一个鉴权 key 下按任务类型自动路由,不需要二选一。
Gemini 3.5 Flash vs Gemini 3.1 Flash-Lite 规格对比
把两款模型放在同一张表里,产品线分工与能力差异一目了然。下表汇总两款模型的核心规格,所有数据均来自 Google DeepMind model card 与 LLM-Stats 公开页面。
| 对比维度 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 翻译场景胜出 |
|---|---|---|---|
| 发布日期 | 2026 年 5 月 19 日 | 2026 年 3 月 3 日 | — |
| 发布状态 | GA 正式版 | Preview 预览版 | — |
| 模型 ID | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| 定位 | Agentic Flash · 工具编排 | High-volume · 高吞吐轻量 | Flash-Lite |
| 上下文窗口 | 1M 输入 / 64K 输出 | 1M 输入 / 64K 输出 | 平手 |
| 输入模态 | 文本+图像+音频+视频 | 文本+图像+语音+视频 | 平手 |
| 思考模式 | 动态思考默认开启 | 思考级别可调 | Flash-Lite(可关) |
| 知识截止 | 2026 年 1 月 | 2025 年 1 月 | 3.5 Flash |
| MMMLU 多语言 | 未公布(预计 80+) | 88.9% | Flash-Lite |
| 输出速度 | 约 289 token/s | 比 2.5 Flash 快 45%,TTFT 快 2.5x | Flash-Lite |
| Agent 工具能力 | 反超 3.1 Pro 多项基准 | 标准 function calling | 翻译场景不需要 |
| API易 接入 | 已上线 | 已上线 | 平手 |
读这张表时要重点关注三个分歧点。第一是定位差异:Flash-Lite 主打"high-volume",这意味着 Google 在设计阶段就把"吞吐量优先于单点智能"写在了产品基因里,正好对应翻译/分类这类高频任务的需求。第二是 MMMLU 88.9% 这个数字,这是公开 Gemini 3.x 家族里多语言基准最高的轻量模型,直接体现翻译质量。第三是"思考级别可调",Flash-Lite 允许把 thinking 关掉,对翻译这类零思考链路任务可以再压低延迟。
翻译场景下的成本对比:Gemini 3.5 Flash vs 3.1 Flash-Lite 的 6 倍价差
成本是翻译场景选型最核心的指标。翻译任务的特征是"输入输出都不长但频次极高",一个常见的 SaaS 产品每天可能要跑几千万到几亿 token 的翻译,单价差 6 倍意味着每月账单差几千美金到几万美金。
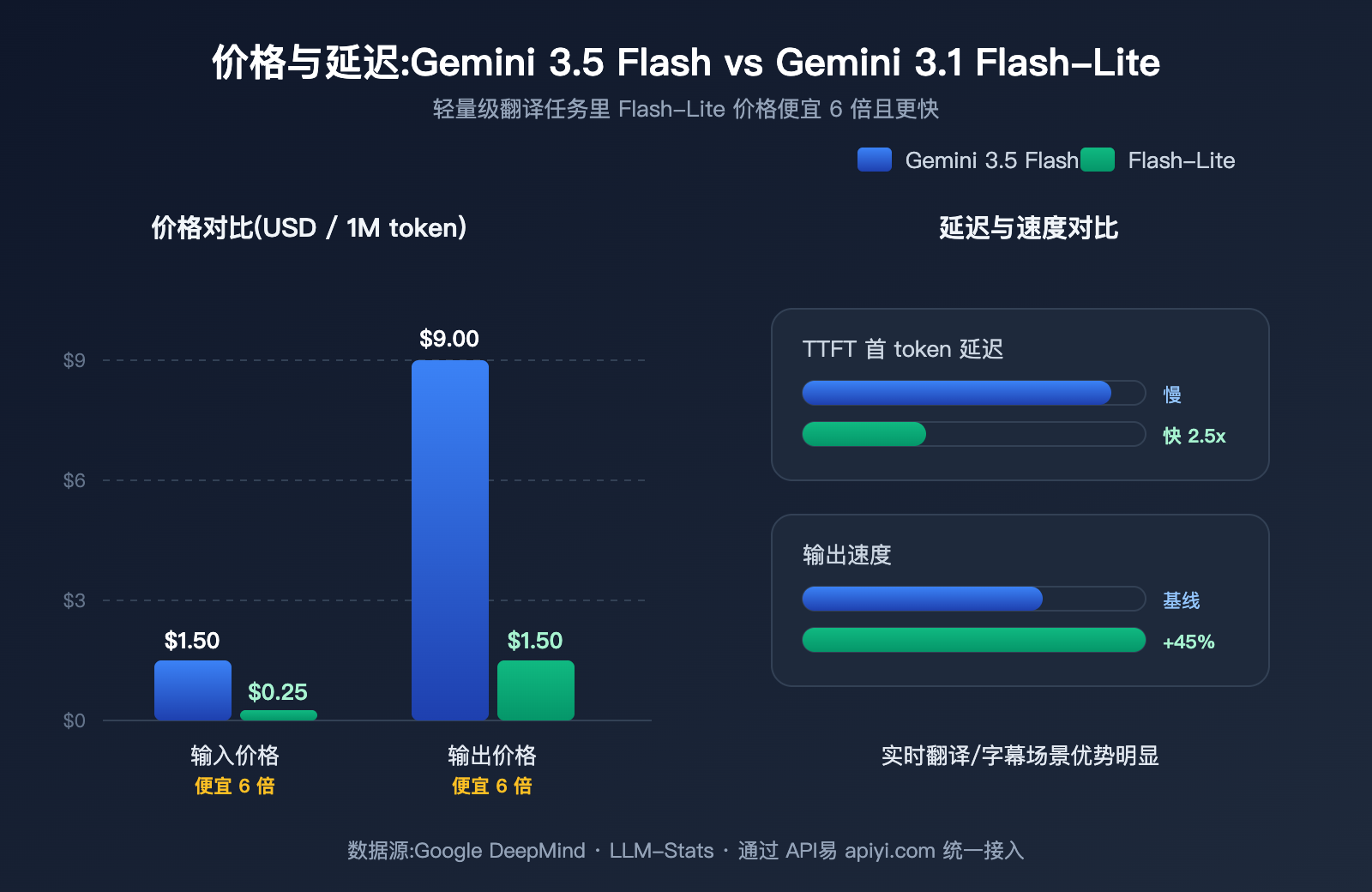
下表把两款模型在翻译场景里最关键的成本维度放在一起对比,所有价格为每 100 万 token 美金计价。
| 成本/性能维度 | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 差距 |
|---|---|---|---|
| 输入价格 | $1.50 | $0.25 | Flash-Lite 便宜 6 倍 |
| 输出价格 | $9.00 | $1.50 | Flash-Lite 便宜 6 倍 |
| 缓存命中输入 | $0.15 | $0.025(估算) | Flash-Lite 便宜 6 倍 |
| TTFT(首 token 延迟) | 较低 | 比 2.5 Flash 快 2.5x | Flash-Lite |
| 输出速度 | 约 289 token/s | 比 2.5 Flash 快 45% | 持平略胜 Flash-Lite |
| 思考模式默认 | 默认开启,有 thinking 开销 | 可关,零思考延迟 | Flash-Lite |
来做一个真实账单模拟。假设一个 SaaS 翻译产品每天处理 1000 万 token 输入和 500 万 token 输出(中等规模 B2C 应用),分别用两款模型跑一个月会是什么账单?
| 月度账单(每天 1000 万输入 / 500 万输出) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | 节省 |
|---|---|---|---|
| 每天输入成本 | $15.00 | $2.50 | $12.50 |
| 每天输出成本 | $45.00 | $7.50 | $37.50 |
| 每天合计 | $60.00 | $10.00 | $50 |
| 每月合计(30 天) | $1,800 | $300 | $1,500 / 月 |
| 每年合计 | $21,600 | $3,600 | $18,000 / 年 |
💡 成本测算建议:把这张表的数字带入你自己的真实流量,每月差距通常在四位数美金以上。建议先在 API易 apiyi.com 上注册账号拿到 0.05 美金免费额度,用同一组翻译样本分别调用
gemini-3.5-flash和gemini-3.1-flash-lite-preview,既能验证质量差距,也能直接拿到自己业务的真实价差。
Gemini 3.1 Flash-Lite 翻译质量与速度实测分析
价格便宜没意义,前提是翻译质量得过关。Gemini 3.1 Flash-Lite 在翻译这件事上的实测数据其实非常硬核,绝大多数场景下它的翻译质量不会让用户感到"明显比 Flash 差"。下面四组数据是核心证据。
第一是 MMMLU 多语言基准的 88.9% 得分。MMMLU(Multilingual MMLU)考察的是模型在 15+ 种语言上理解专业知识和推理的能力,Flash-Lite 在这项上达到 88.9%,在所有 Flash-Lite 级别的模型里属于绝对头部,意味着它在中文、日文、韩文、阿拉伯文等非拉丁语系上仍能保持高质量。
第二是 Google DeepMind 在 model card 里明确写的"best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts"。这是 Google 自己对 Flash-Lite 翻译能力的官方背书,特别强调"非拉丁文字"上的提升——对中文 SaaS 来说尤其关键。
第三是 Lara Translate 在 2026 年 2 月 Translation Model Benchmark 中的横评结论:Flash 系列变体被定位为"lower latency and higher throughput workflows"的首选,翻译任务的核心约束(低延迟 + 高吞吐 + 成本敏感)与 Flash-Lite 的设计目标高度匹配。
第四是 Time-to-First-Token(TTFT)与输出速度。Flash-Lite 的 TTFT 比 Gemini 2.5 Flash 快 2.5 倍,输出速度提升 45%,这两个指标在翻译这种"实时性敏感"的场景里直接决定用户体验。我们建议在 API易 apiyi.com 上测一次同一段 5000 字中文翻译为英文的耗时,差距非常直观。
场景推荐:什么时候选 Flash-Lite,什么时候要 3.5 Flash
把 6 个维度的对比换成具体的任务选型建议,可以归纳成下面这张推荐表。它解决的不是"哪个模型更强",而是"在每个具体任务上该用谁"。
| 任务类型 | 推荐模型 | 关键理由 |
|---|---|---|
| 通用文本翻译(中英/中日等) | Gemini 3.1 Flash-Lite | MMMLU 88.9% + 价格便宜 6x |
| 字幕翻译 / 实时翻译 | Gemini 3.1 Flash-Lite | TTFT 快 2.5x + 输出速度提升 45% |
| 内容审核 / 文本分类 | Gemini 3.1 Flash-Lite | Google 官方 sweet spot,批量任务最优 |
| 结构化数据提取 | Gemini 3.1 Flash-Lite | 适合大批量 JSON 抽取 |
| 多语言对话机器人 | Gemini 3.1 Flash-Lite | 多语言质量 + 低延迟 + 低成本 |
| 翻译 + 后处理 Agent | Gemini 3.5 Flash | 需要 function calling 串多个工具 |
| 翻译 + 工具调用 | Gemini 3.5 Flash | Agent 能力反超 3.1 Pro |
| 代码助手 / IDE 补全 | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76.2% |
| 长文档 RAG 问答 | Gemini 3.5 Flash | 缓存命中 + 1M 上下文 |
| 复杂 Agent 工作流 | Gemini 3.5 Flash | MCP Atlas 83.6% |
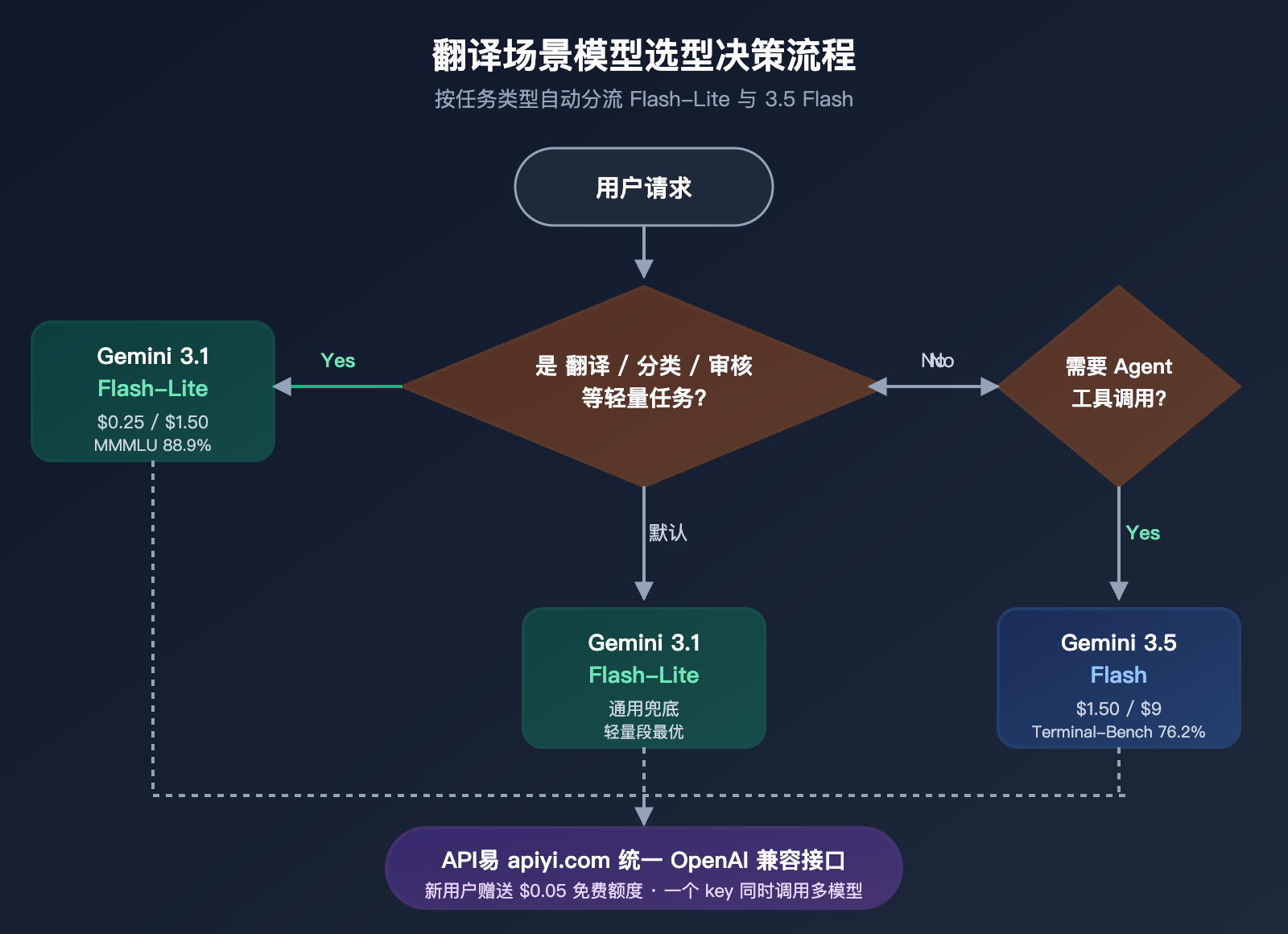
实践中最理想的策略仍然是"按任务路由":翻译/分类/审核走 gemini-3.1-flash-lite-preview,Agent / 编码 / 长文档 RAG 走 gemini-3.5-flash,两款模型挂在同一个 API易 apiyi.com 鉴权 key 下完成切换。这样既能拿到 Flash-Lite 在轻量任务上的 6 倍成本红利,又能保留 3.5 Flash 在重型 Agent 上的能力上限。
选择 Gemini 3.1 Flash-Lite 的典型场景
如果你的产品里有任何一项符合下列特征,Flash-Lite 几乎一定是更优解:每天调用次数超过 10 万次、单次输入输出在 5K token 以内、对 P95 延迟敏感、不需要工具调用、需要支持多种语言。典型场景包括跨境电商商品翻译、SaaS 多语言客服、内容审核流水线、字幕生成、批量 OCR 后规范化等。配合 API易 apiyi.com 的 OpenAI 兼容接口,迁移成本几乎为零。
仍然推荐 Gemini 3.5 Flash 的典型场景
如果你的任务里有"翻译后还要调工具"或者"翻译嵌入复杂 Agent 链"的需求,Gemini 3.5 Flash 才有意义。例如:翻译 + 知识库检索 + 调外部 API,或者用户提交一段外语 → 模型先翻译 → 再调 calculator/search/code execution 工具。这类任务用 Flash-Lite 会因为缺 Agent 能力反复出错,反而成本更高。
翻译场景下 Gemini 3.1 Flash-Lite 在 API易 的接入示例
下面给出一个针对翻译场景优化的最简 Python 接入示例,展示如何在 API易 apiyi.com 上调用 Gemini 3.1 Flash-Lite,完整保留 OpenAI 兼容写法。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Translate the user input to {target_lang}. Output the translation only, no explanation."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
查看带批量并发与回退路由的完整实现
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Translate to {target_lang}. Output translation only."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Translate to {target_lang}. Output translation only."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 批量翻译优化建议:翻译场景适合开高并发(
concurrency=20~50)+ 较低 temperature(0.1-0.3)+ 短 system prompt。API易 apiyi.com 平台已经为高吞吐场景做了路由优化,新用户注册赠送 0.05 美金免费额度,按 Flash-Lite 的 $0.25/$1.50 定价大约可以翻译 5 万-10 万 token 的真实内容,足够完整压测一个批量翻译 Pipeline。
Gemini 3.5 Flash vs 3.1 Flash-Lite 翻译常见问题 FAQ
Q1:Gemini 3.1 Flash-Lite 是 Preview 版本,生产环境能用吗?
可以用,但要做好两手准备。Flash-Lite 自 2026 年 3 月 3 日上线以来一直在 Preview 阶段,Google 官方没有给出明确的 GA 日期,但 API 接口与价格已经稳定。建议生产环境采用"主路由 Flash-Lite + 异常回退 3.5 Flash"的双模型策略,通过 API易 apiyi.com 的统一接口完成路由切换,避免单点依赖。当 Google 将其升级为 GA 或推出 3.5 Flash-Lite 时,只需要替换 model 字段即可平滑迁移。
Q2:翻译质量上 Flash-Lite 真的能追上 Flash 吗?
在 90% 以上的通用翻译任务上是的。Google DeepMind model card 明确写明 Flash-Lite 具备"best-in-class translation and multilingual understanding",MMMLU 多语言得分 88.9%。但在两类场景下 3.5 Flash 仍然有优势:一是涉及专业术语(医学、法律、金融)的长篇翻译;二是翻译 + 上下文推理(例如基于上下文判断代词指代)。建议通过 API易 apiyi.com 跑一组真实业务样本横评,而不是只看基准数。
Q3:用 Flash-Lite 替换 GPT-4o-mini 或 Claude Haiku 4.5 做翻译合适吗?
合适,且通常会更便宜更快。Gemini 3.1 Flash-Lite 的 $0.25/$1.50 定价低于 GPT-4o-mini($0.15/$0.60 看似更便宜但实测翻译质量不如 Flash-Lite),也低于 Claude Haiku 4.5。多语言基准上 Flash-Lite 的 88.9% MMMLU 高于同档竞品。建议在 API易 apiyi.com 上把三个候选模型挂在同一个 key 下做 A/B 对比,实测哪款最适合你的具体语言对。
Q4:Flash-Lite 的 1M 上下文真的能用于翻译吗?
可以,且是它最被低估的能力。1M token 大约相当于 70 万-80 万英文单词或 30 万-40 万中文字,足以一次性翻译整本中等长度的书或一整套企业文档。配合 thinking 关闭模式,1M 上下文的单次翻译成本约为 $0.25 输入 + $1.50 输出,远低于把同样内容拆给 3.5 Flash 或 GPT-5.5。API易 apiyi.com 已经完整开放 Flash-Lite 的 1M 上下文窗口,可以直接调用。
总结:翻译场景 Gemini 3.1 Flash-Lite 是 6 倍性价比的最优解
回到本文最核心的判断:翻译这类轻量级高频任务,Gemini 3.1 Flash-Lite 不是 Gemini 3.5 Flash 的"降级版",而是 Google 专门为这类场景设计的最优解。它的输入价格便宜 6 倍、输出价格便宜 6 倍、首 token 延迟快 2.5 倍、MMMLU 多语言得分高达 88.9%、Google 官方把翻译列为它的 sweet spot,这五个事实共同决定了它在翻译场景下的统治地位。Gemini 3.5 Flash 的 Agent / 编码强项在翻译里完全用不上,你为这些能力付的溢价是纯浪费。
最稳妥的策略是双模型路由:翻译/分类/审核走 gemini-3.1-flash-lite-preview,Agent / 编码 / 长文档 RAG 走 gemini-3.5-flash,通过 API易 apiyi.com 的统一 OpenAI 兼容接口在同一个鉴权 key 下完成切换。新用户注册赠送 0.05 美金免费额度,足够完整压测一个批量翻译 Pipeline,实测出哪款模型在你业务上的真实成本节省比例。
作者:API易 技术团队 · apiyi.com
发布时间:2026 年 5 月 20 日
参考资料:Google DeepMind Model Card、Google Blog、LLM-Stats、Artificial Analysis、DevTK、AIMLAPI、Lara Translate Benchmark、Emelia Hub