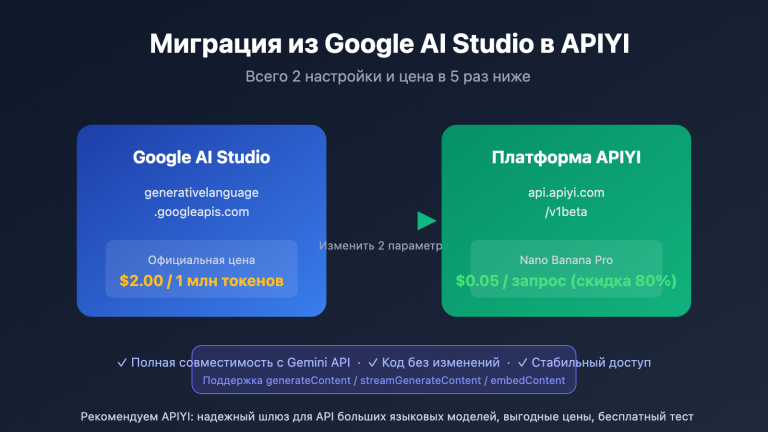
После того как 19 мая 2026 года модель Gemini 3.5 Flash стала общедоступной (GA), многие команды по умолчанию перевели на неё весь трафик, включая высокочастотные и легковесные задачи: перевод, генерацию субтитров и модерацию контента. Это явная ошибка в оценке. В сценариях, где входные и выходные данные короткие, критически важна стоимость за запрос, критически важна задержка (latency) и не требуется оркестрация через Agent-инструменты, Gemini 3.1 Flash-Lite является по-настоящему оптимальным решением, а не более дорогая и «универсальная» Gemini 3.5 Flash. В этой статье мы систематически сравним обе модели по 6 параметрам, используя данные из официальных карточек моделей Google DeepMind, LLM-Stats, Artificial Analysis и других первоисточников.

Короткий вывод: для таких легковесных задач, как перевод, субтитры, пакетная классификация и нормализация текста, я рекомендую Gemini 3.1 Flash-Lite, а не Gemini 3.5 Flash. Основных причин шесть: входные данные дешевле в 6 раз, выходные — в 6 раз, задержка до первого токена меньше в 2,5 раза, многоязычный балл MMMLU достигает 88,9%, Google официально называет перевод «золотой серединой» (sweet spot) для этой модели, а сильные стороны 3.5 Flash в работе с агентами в переводе совершенно не нужны. Рекомендую сначала запустить серию реальных задач по переводу, используя бесплатный лимит в 0,05$ на платформе APIYI (apiyi.com), чтобы наглядно увидеть разницу в стоимости и качестве по сравнению с бенчмарками.
Почему в задачах перевода Gemini 3.1 Flash-Lite справляется лучше, чем Gemini 3.5 Flash
Характеристики задач перевода предельно ясны: на входе — короткий текст на исходном языке (от нескольких сотен до нескольких тысяч токенов), на выходе — короткий текст на целевом языке. Одиночный вызов модели не требует цепочек рассуждений (chain-of-thought), вызова внешних инструментов или мультимодального синтеза, но при этом частота вызовов крайне высока, а требования к стоимости и задержке — экстремальны. Именно для таких сценариев Google и разработала серию Flash-Lite.
Gemini 3.1 Flash-Lite была выпущена 3 марта 2026 года. В официальном блоге Google её назвали «нашей самой экономически эффективной ИИ-моделью на текущий момент» и прямо указали, что её «золотая середина» — это «масштабный перевод, классификация контента, модерация, извлечение структурированных данных и повторяющиеся агентские задачи». В карточке модели от DeepMind дополнительно отмечается, что она обладает «лучшими в своем классе возможностями перевода и понимания языков, с заметными улучшениями для нелатинских алфавитов», а многоязычный балл MMMLU составляет 88,9%, что является абсолютным топом в сегменте легковесных моделей.
Gemini 3.5 Flash, вышедшая 19 мая, — это «агентская» модель (Agentic Flash), ориентированная на «оркестрацию инструментов + разработку кода». Она превосходит Gemini 3.1 Pro в тестах Terminal-Bench 2.1, MCP Atlas и Finance Agent v2. Однако эти агентские способности в задачах перевода абсолютно бесполезны, и вы просто переплачиваете за функции, которые не используете. Именно поэтому внутри серии Flash произошло разделение: для агентов — 3.5 Flash, для перевода/классификации/модерации — 3.1 Flash-Lite.
🎯 Ключевой совет по выбору: не поддавайтесь интуиции, что «чем выше версия, тем лучше». Gemini 3.5 Flash (майский релиз) и Gemini 3.1 Flash-Lite (мартовский релиз) — это две параллельные линейки продуктов, которые закрывают разные ниши: «основной агент» и «высокопроизводительная легковесная модель». Платформа APIYI (apiyi.com) поддерживает обе модели одновременно, позволяя автоматически маршрутизировать запросы в зависимости от типа задачи в рамках одного API-ключа, поэтому выбирать что-то одно не обязательно.
Сравнение характеристик Gemini 3.5 Flash и Gemini 3.1 Flash-Lite
Сравнение этих двух моделей в одной таблице наглядно показывает разницу в их позиционировании и возможностях. Ниже приведены ключевые характеристики, основанные на данных Google DeepMind и публичных метриках LLM-Stats.
| Параметр сравнения | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Лидер в переводе |
|---|---|---|---|
| Дата выпуска | 19 мая 2026 г. | 3 марта 2026 г. | — |
| Статус | GA (общедоступная) | Preview (предварительная) | — |
| ID модели | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Позиционирование | Agentic Flash (агенты) | High-volume (высокая нагрузка) | Flash-Lite |
| Контекстное окно | 1 млн вх. / 64 тыс. вых. | 1 млн вх. / 64 тыс. вых. | Ничья |
| Входные модальности | Текст, изображения, аудио, видео | Текст, изображения, голос, видео | Ничья |
| Режим мышления | Динамическое мышление (вкл. по умолч.) | Настраиваемый уровень мышления | Flash-Lite (можно откл.) |
| Актуальность знаний | Январь 2026 г. | Январь 2025 г. | 3.5 Flash |
| MMMLU (мультиязычность) | Не объявлено (ожидается 80+) | 88.9% | Flash-Lite |
| Скорость вывода | ~289 токенов/с | На 45% быстрее 2.5 Flash, TTFT в 2.5x быстрее | Flash-Lite |
| Агентные возможности | Превосходит 3.1 Pro в ряде тестов | Стандартный вызов функций | Не требуется для перевода |
| Доступ через APIYI | Доступно | Доступно | Ничья |
При анализе этой таблицы стоит обратить внимание на три момента. Во-первых, разница в позиционировании: Flash-Lite ориентирована на «высокую нагрузку» (high-volume). Google изначально заложила в нее приоритет пропускной способности над глубоким интеллектом, что идеально подходит для частотных задач вроде перевода или классификации. Во-вторых, показатель MMMLU 88.9% — это лучший результат среди всех легких моделей семейства Gemini 3.x, что напрямую влияет на качество перевода. В-третьих, «настраиваемый уровень мышления»: в Flash-Lite можно отключить функцию thinking, что позволяет еще сильнее снизить задержку для задач, не требующих глубоких размышлений.
Сравнение стоимости перевода: 6-кратная разница между Gemini 3.5 Flash и 3.1 Flash-Lite
Стоимость — главный критерий при выборе модели для перевода. Задачи перевода характеризуются «короткими входами/выходами, но огромной частотой». Типичный SaaS-продукт может обрабатывать от десятков миллионов до сотен миллионов токенов в день, поэтому разница в цене в 6 раз означает экономию от нескольких тысяч до десятков тысяч долларов в месяц.
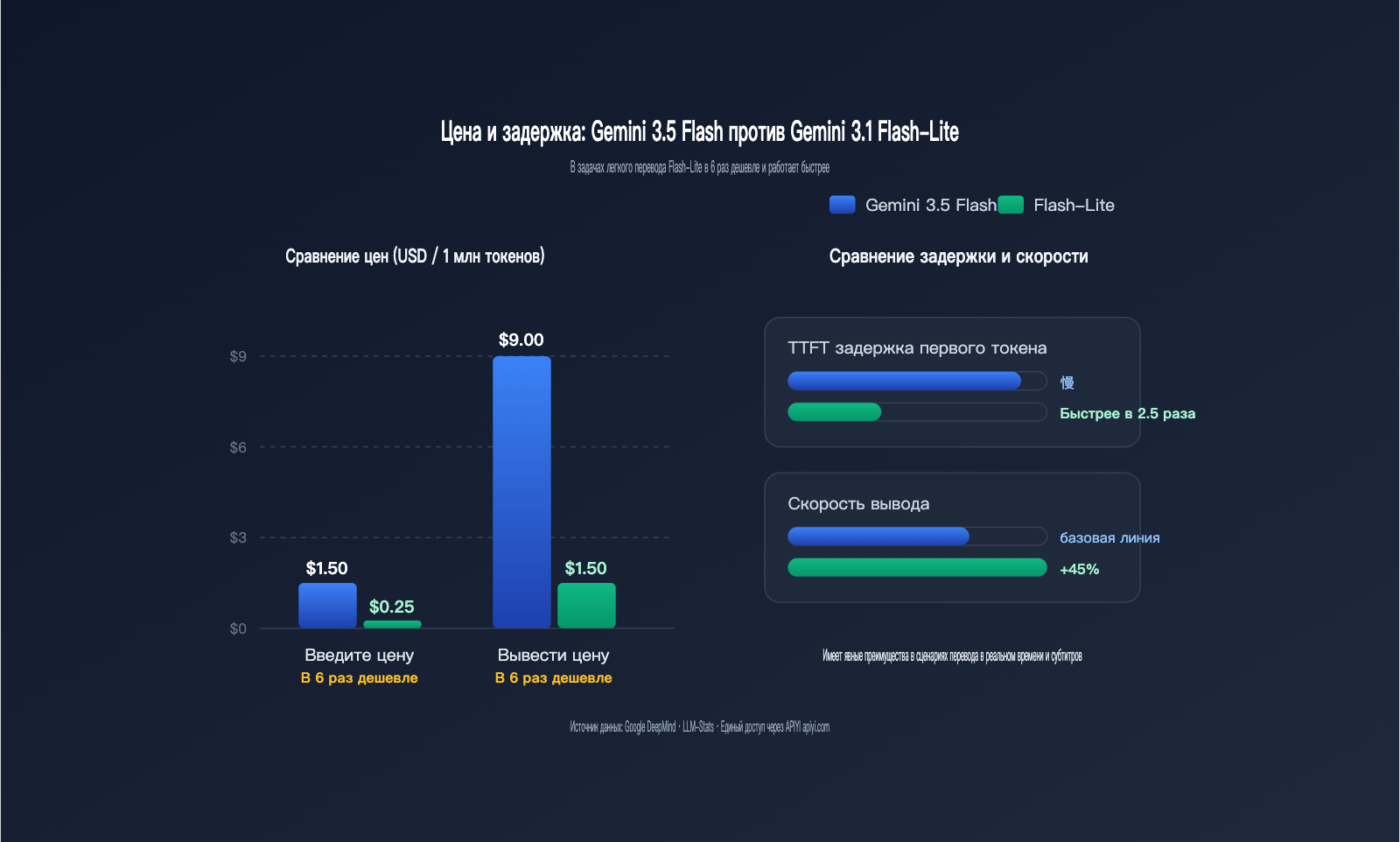
В таблице ниже приведены ключевые показатели стоимости для сценария перевода (цены указаны за 1 млн токенов).
| Параметр стоимости/производительности | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Разница |
|---|---|---|---|
| Цена за вход | $1.50 | $0.25 | Flash-Lite дешевле в 6 раз |
| Цена за выход | $9.00 | $1.50 | Flash-Lite дешевле в 6 раз |
| Вход с кэшированием | $0.15 | $0.025 (оценка) | Flash-Lite дешевле в 6 раз |
| TTFT (задержка первого токена) | Ниже | В 2.5x быстрее 2.5 Flash | Flash-Lite |
| Скорость вывода | ~289 токенов/с | На 45% быстрее 2.5 Flash | Паритет / чуть лучше Flash-Lite |
| Режим мышления по умолч. | Вкл., есть расходы на thinking | Можно откл., нулевая задержка | Flash-Lite |
Давайте проведем симуляцию реальных счетов. Допустим, SaaS-сервис перевода обрабатывает 10 млн токенов на входе и 5 млн токенов на выходе ежедневно (средний B2C-продукт). Сколько это будет стоить за месяц?
| Ежемесячный счет (10 млн вх. / 5 млн вых. в день) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Экономия |
|---|---|---|---|
| Стоимость входа в день | $15.00 | $2.50 | $12.50 |
| Стоимость выхода в день | $45.00 | $7.50 | $37.50 |
| Итого в день | $60.00 | $10.00 | $50 |
| Итого в месяц (30 дней) | $1,800 | $300 | $1,500 / мес. |
| Итого в год | $21,600 | $3,600 | $18,000 / год |
💡 Совет по расчету затрат: подставьте свои реальные объемы трафика в эту таблицу. Обычно разница составляет четырехзначные суммы в долларах. Рекомендуем зарегистрироваться на APIYI (apiyi.com), получить бесплатный кредит 0.05$ и протестировать обе модели на своих данных — это позволит не только проверить качество, но и увидеть реальную разницу в затратах для вашего бизнеса.
Анализ качества и скорости перевода Gemini 3.1 Flash-Lite
Низкая цена не имеет смысла, если страдает качество перевода. Однако реальные показатели Gemini 3.1 Flash-Lite в задачах перевода впечатляют: в большинстве сценариев пользователи даже не замечают «заметной разницы» по сравнению с моделью Flash. Вот четыре ключевых аргумента в пользу этой модели.
Во-первых, результат 88,9% в многоязычном бенчмарке MMMLU. MMMLU (Multilingual MMLU) проверяет способность модели понимать профессиональные знания и рассуждать на более чем 15 языках. Показатель 88,9% выводит Flash-Lite в абсолютные лидеры среди моделей своего класса, что гарантирует высокое качество работы с китайским, японским, корейским, арабским и другими нелатинскими языками.
Во-вторых, Google DeepMind прямо заявляет в карточке модели о «лучшем в своем классе переводе и понимании языков, с заметными улучшениями в работе с нелатинскими шрифтами». Это официальное подтверждение от Google, что особенно важно для китайских SaaS-решений.
В-третьих, выводы из отчета Lara Translate «Translation Model Benchmark» за февраль 2026 года: варианты серии Flash признаны лучшим выбором для «рабочих процессов с низкой задержкой и высокой пропускной способностью». Ключевые требования к задачам перевода (низкая задержка + высокая пропускная способность + чувствительность к стоимости) идеально соответствуют целям разработки Flash-Lite.
В-четвертых, показатели Time-to-First-Token (TTFT) и скорость вывода. TTFT у Flash-Lite в 2,5 раза быстрее, чем у Gemini 2.5 Flash, а скорость вывода выше на 45%. В задачах, где важна «реальность времени», эти показатели напрямую определяют пользовательский опыт. Рекомендуем протестировать время перевода 5000 иероглифов с китайского на английский через APIYI apiyi.com — разница будет очевидна.
Рекомендации по сценариям: когда выбирать Flash-Lite, а когда — 3.5 Flash
Мы свели сравнение по 6 параметрам в удобную таблицу рекомендаций. Она отвечает не на вопрос «какая модель сильнее», а на вопрос «какую модель использовать для конкретной задачи».
| Тип задачи | Рекомендуемая модель | Ключевое обоснование |
|---|---|---|
| Общий перевод текста (кит-англ/кит-яп и т.д.) | Gemini 3.1 Flash-Lite | MMMLU 88,9% + цена ниже в 6 раз |
| Перевод субтитров / синхронный перевод | Gemini 3.1 Flash-Lite | TTFT быстрее в 2,5 раза + скорость вывода +45% |
| Модерация контента / классификация текста | Gemini 3.1 Flash-Lite | Оптимально для пакетных задач |
| Извлечение структурированных данных | Gemini 3.1 Flash-Lite | Идеально для массового извлечения JSON |
| Многоязычные чат-боты | Gemini 3.1 Flash-Lite | Качество языков + низкая задержка + низкая стоимость |
| Перевод + агент постобработки | Gemini 3.5 Flash | Требуется вызов функций (function calling) |
| Перевод + вызов инструментов | Gemini 3.5 Flash | Возможности агента превосходят 3.1 Pro |
| Помощник по коду / автодополнение в IDE | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76,2% |
| RAG по длинным документам | Gemini 3.5 Flash | Кэширование + контекстное окно 1M |
| Сложные агентские рабочие процессы | Gemini 3.5 Flash | MCP Atlas 83,6% |
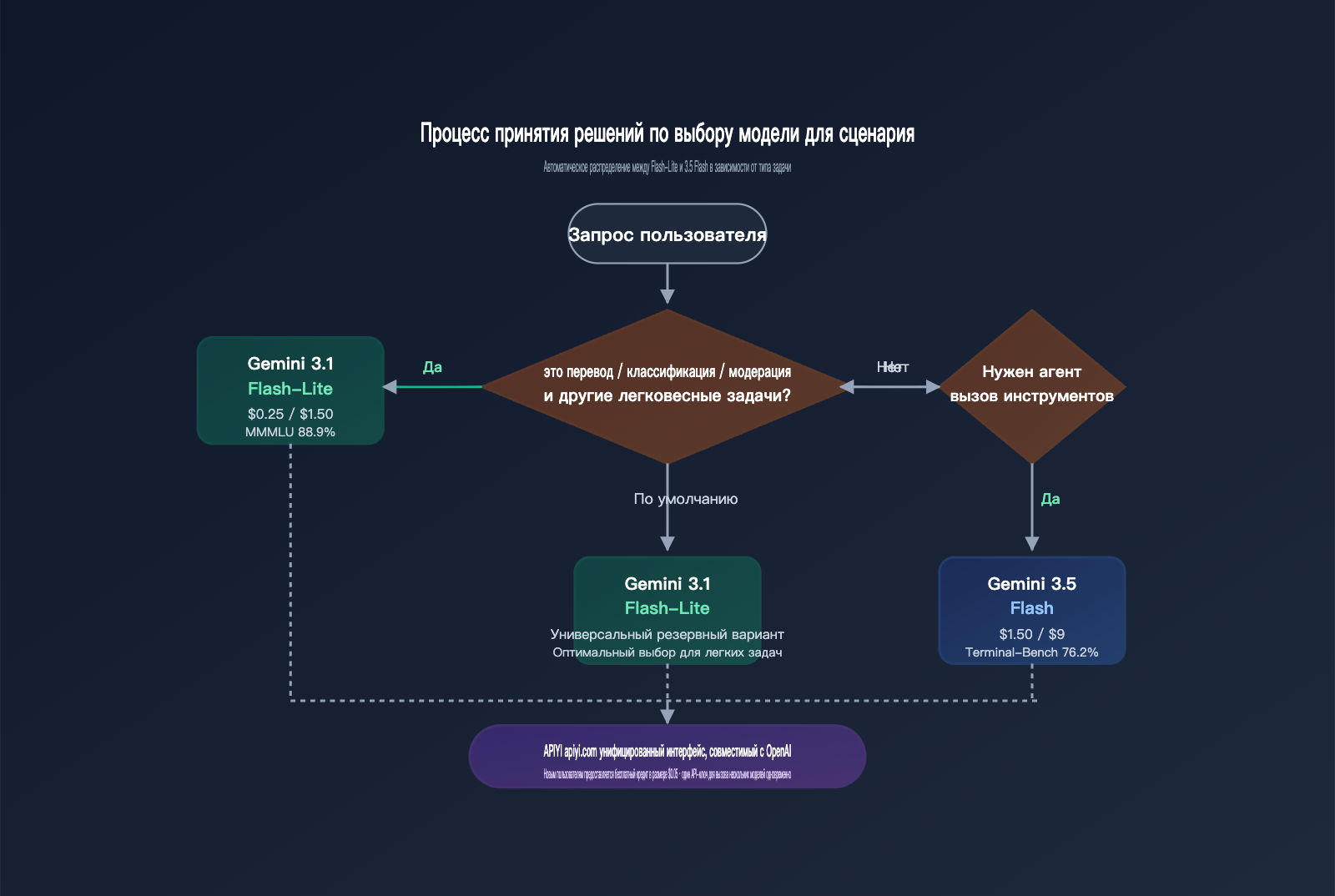
В практической работе идеальная стратегия — это «маршрутизация по задачам»: перевод, классификацию и модерацию направляем на gemini-3.1-flash-lite-preview, а работу агентов, написание кода и RAG по длинным документам — на gemini-3.5-flash. Обе модели можно переключать в рамках одного API-ключа на APIYI apiyi.com. Это позволяет получить 6-кратную экономию на легких задачах, сохраняя при этом мощь 3.5 Flash для сложных агентских сценариев.
Типичные сценарии для выбора Gemini 3.1 Flash-Lite
Если ваш продукт соответствует хотя бы одному из следующих критериев, Flash-Lite почти наверняка будет лучшим решением: более 100 000 вызовов в день, объем входных/выходных данных до 5 тыс. токенов, чувствительность к задержке P95, отсутствие необходимости в вызове инструментов, поддержка нескольких языков. Типичные примеры: перевод товаров для трансграничной электронной коммерции, многоязычная поддержка SaaS, конвейеры модерации контента, генерация субтитров, нормализация данных после OCR. Благодаря совместимости с API OpenAI на платформе APIYI apiyi.com, стоимость миграции практически нулевая.
Типичные сценарии для выбора Gemini 3.5 Flash
Если ваша задача включает «перевод с последующим вызовом инструментов» или «встраивание перевода в сложную агентскую цепочку», Gemini 3.5 Flash незаменима. Например: перевод + поиск по базе знаний + вызов внешнего API, или когда пользователь отправляет текст на иностранном языке, а модель должна сначала перевести его, а затем вызвать калькулятор, поиск или выполнить код. В таких задачах Flash-Lite будет часто ошибаться из-за нехватки агентских возможностей, что в итоге приведет к большим затратам.
Пример интеграции Gemini 3.1 Flash-Lite для задач перевода через APIYI
Ниже представлен минималистичный пример на Python, оптимизированный для задач перевода. Он показывает, как вызывать Gemini 3.1 Flash-Lite через сервис-прокси API APIYI (apiyi.com), сохраняя полную совместимость с библиотекой OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Переведи ввод пользователя на {target_lang}. Выведи только перевод, без пояснений."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
Посмотреть полную реализацию с пакетной обработкой и резервным маршрутом
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Переведи на {target_lang}. Выведи только перевод."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
# Резервный вызов при ошибке
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Переведи на {target_lang}. Выведи только перевод."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Советы по оптимизации пакетного перевода: Для перевода лучше всего подходят высокая параллельность (
concurrency=20~50), низкаяtemperature(0.1-0.3) и короткий системный промпт. Платформа APIYI (apiyi.com) уже оптимизировала маршрутизацию для сценариев с высокой пропускной способностью. Новым пользователям при регистрации начисляется бонус в $0.05, чего при тарифах Flash-Lite ($0.25/$1.50) хватит на перевод 50-100 тыс. токенов реального контента — этого достаточно для полноценного нагрузочного тестирования вашего конвейера перевода.
FAQ: Gemini 3.5 Flash против 3.1 Flash-Lite в задачах перевода
Q1: Gemini 3.1 Flash-Lite — это Preview-версия, можно ли использовать её в продакшене?
Можно, но лучше подстраховаться. Flash-Lite находится в стадии Preview с 3 марта 2026 года, и Google пока не объявила точную дату GA, однако API и цены уже стабильны. Для продакшена рекомендуем стратегию с двумя моделями: «основной маршрут Flash-Lite + резервный 3.5 Flash». Это легко реализуется через единый интерфейс APIYI (apiyi.com), чтобы избежать зависимости от одной точки отказа. Когда Google переведет модель в GA или выпустит 3.5 Flash-Lite, вам нужно будет лишь изменить поле model для плавного перехода.
Q2: Действительно ли Flash-Lite догоняет Flash по качеству перевода?
В 90% стандартных задач перевода — да. В карточке модели Google DeepMind указано, что Flash-Lite обладает «лучшим в своем классе переводом и пониманием мультиязычности» с результатом 88.9% в тесте MMMLU. Однако 3.5 Flash всё ещё выигрывает в двух случаях: при переводе длинных текстов со сложной терминологией (медицина, право, финансы) и при переводе с необходимостью логического вывода (например, определение того, к чему относится местоимение в контексте). Советуем прогнать реальные бизнес-образцы через APIYI (apiyi.com) для сравнения, а не полагаться только на бенчмарки.
Q3: Стоит ли заменять GPT-4o-mini или Claude Haiku 4.5 на Flash-Lite для перевода?
Стоит, так как это обычно дешевле и быстрее. Тарифы Gemini 3.1 Flash-Lite ($0.25/$1.50) конкурентоспособны, а качество перевода часто превосходит аналоги. Рекомендуем добавить все три модели в один API-ключ на APIYI (apiyi.com) и провести A/B-тестирование, чтобы понять, какая из них лучше всего подходит для вашей конкретной языковой пары.
Q4: Можно ли реально использовать 1 млн токенов контекстного окна Flash-Lite для перевода?
Да, и это её самая недооцененная возможность. 1 млн токенов — это примерно 300-400 тысяч иероглифов или 700-800 тысяч английских слов. Этого достаточно, чтобы перевести целую книгу среднего размера или пакет корпоративной документации за один раз. При отключенном режиме рассуждений (thinking) стоимость перевода составит около $0.25 за вход и $1.50 за выход, что намного дешевле, чем разбивать контент для 3.5 Flash или GPT-5.5. APIYI (apiyi.com) уже полностью открыл доступ к окну в 1 млн токенов для Flash-Lite.
Итог: Gemini 3.1 Flash-Lite — оптимальное решение для перевода с 6-кратной выгодой
Возвращаясь к главному выводу статьи: для таких легковесных и высокочастотных задач, как перевод, Gemini 3.1 Flash-Lite — это не «урезанная версия» Gemini 3.5 Flash, а специализированное решение от Google, идеально подходящее для подобных сценариев. Пять фактов подтверждают его доминирование в задачах перевода: стоимость входных токенов ниже в 6 раз, стоимость выходных — в 6 раз, задержка до первого токена (TTFT) меньше в 2,5 раза, показатель MMMLU для мультиязычных задач достигает 88,9%, а сама Google официально называет перевод его «золотой серединой». Сильные стороны Gemini 3.5 Flash в работе с агентами и кодом в переводе просто не востребованы, поэтому переплата за эти возможности — пустая трата ресурсов.
Самая надежная стратегия — использование маршрутизации между двумя моделями: перевод, классификацию и модерацию направляйте на gemini-3.1-flash-lite-preview, а задачи для агентов, написание кода и RAG по длинным документам — на gemini-3.5-flash. Переключаться между ними можно через единый API-интерфейс, совместимый с OpenAI, от APIYI (apiyi.com) под одним API-ключом. Новым пользователям при регистрации начисляется бонус в размере 0,05 USD — этого достаточно, чтобы провести полноценное нагрузочное тестирование вашего конвейера перевода и на практике увидеть, сколько именно удастся сэкономить в вашем бизнесе.
Автор: Техническая команда APIYI · apiyi.com
Дата публикации: 20 мая 2026 г.
Источники: Google DeepMind Model Card, блог Google, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub