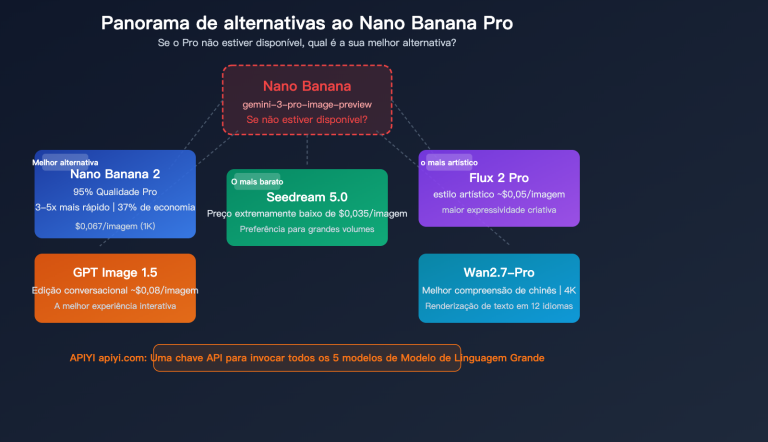
Muitas equipes, após a disponibilidade geral (GA) do Gemini 3.5 Flash em 19 de maio de 2026, migraram automaticamente todo o tráfego do Gemini para ele, incluindo tarefas leves e de alta frequência como tradução, geração de legendas e moderação de conteúdo. Na verdade, isso é um erro de julgamento claro. Em cenários como tradução — onde as entradas e saídas não são longas, o custo unitário é extremamente sensível, a latência é crítica e não há necessidade de orquestração de ferramentas (Agent) — o Gemini 3.1 Flash-Lite é a verdadeira solução ideal, e não o mais caro e "versátil" Gemini 3.5 Flash. Este artigo compara sistematicamente esses dois modelos em 6 dimensões, com dados provenientes de fontes primárias como o model card oficial do Google DeepMind, LLM-Stats e Artificial Analysis.

Direto ao ponto: em cenários leves como tradução, legendas, classificação em lote e normalização de texto, recomendo o Gemini 3.1 Flash-Lite em vez do Gemini 3.5 Flash. O motivo central reside em seis pontos: entrada 6 vezes mais barata, saída 6 vezes mais barata, latência do primeiro token 2,5 vezes mais rápida, pontuação multilingue MMMLU de 88,9%, tradução listada oficialmente pelo Google como seu ponto forte (sweet spot) e o fato de que os pontos fortes do 3.5 Flash em agentes são totalmente inúteis na tradução. Sugiro rodar um conjunto de tarefas de tradução reais via APIYI (apiyi.com) usando o crédito gratuito de 0,05 USD para uma comparação direta; a diferença real de custo e qualidade é muito mais intuitiva do que os números de referência.
Por que o Gemini 3.1 Flash-Lite é mais competente que o Gemini 3.5 Flash em cenários de tradução
As características de tarefas como tradução são muito claras: a entrada é um texto curto na língua de origem (centenas a milhares de tokens), a saída é um texto curto na língua de destino, e a chamada única não requer cadeia de pensamento, invocação de ferramentas ou fusão multimodal, mas a frequência de chamadas é extremamente alta e a sensibilidade a custo e latência é extrema. Este é exatamente o cenário para o qual a série Flash-Lite foi projetada pelo Google.
O Gemini 3.1 Flash-Lite foi lançado em 3 de março de 2026, e o blog oficial do Google descreveu-o como "nosso modelo de IA mais econômico até o momento", listando explicitamente "tradução em massa, classificação de conteúdo, moderação, extração de dados estruturados e tarefas repetitivas de agentes" como seu ponto forte. O model card do DeepMind aponta ainda que ele possui "a melhor tradução e compreensão multilingue da categoria, com melhorias notáveis em scripts não latinos", com uma pontuação de referência multilingue MMMLU de 88,9%, situando-se no topo absoluto entre os modelos leves.
O Gemini 3.5 Flash é o Flash "Agentic" lançado em 19 de maio, posicionado como "orquestração de ferramentas de agente +主力 em codificação", superando o Gemini 3.1 Pro no Terminal-Bench 2.1, MCP Atlas e Finance Agent v2. No entanto, essas capacidades de agente são totalmente inúteis em tarefas de tradução, e o ágio que você paga por essas capacidades é um desperdício puro. É por isso que a "série Flash" precisa ser segmentada por tipo de tarefa: agentes usam o 3.5 Flash, enquanto tradução/classificação/moderação usam o 3.1 Flash-Lite.
🎯 Sugestão principal de seleção: Não se deixe enganar pela intuição de que "número de versão maior é melhor". O Gemini 3.5 Flash (lançado em maio) e o Gemini 3.1 Flash-Lite (lançado em março) são duas linhas de produtos paralelas que cobrem, respectivamente, os segmentos de "agente principal" e "alta taxa de transferência/leve". A plataforma APIYI (apiyi.com) disponibiliza ambos os modelos, permitindo o roteamento automático por tipo de tarefa sob a mesma chave de autenticação, sem a necessidade de escolher apenas um.
Comparativo de especificações: Gemini 3.5 Flash vs. Gemini 3.1 Flash-Lite
Colocar ambos os modelos em uma única tabela torna a divisão de tarefas e as diferenças de capacidade entre as linhas de produtos muito claras. A tabela abaixo resume as especificações principais de ambos os modelos; todos os dados provêm do model card do Google DeepMind e da página pública LLM-Stats.
| Dimensão de comparação | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Vencedor no cenário de tradução |
|---|---|---|---|
| Data de lançamento | 19 de maio de 2026 | 3 de março de 2026 | — |
| Status de lançamento | GA (Geral) | Preview (Prévia) | — |
| ID do modelo | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Posicionamento | Agentic Flash · Orquestração de ferramentas | High-volume · Leve de alta vazão | Flash-Lite |
| Janela de contexto | 1M entrada / 64K saída | 1M entrada / 64K saída | Empate |
| Modalidades de entrada | Texto+Imagem+Áudio+Vídeo | Texto+Imagem+Voz+Vídeo | Empate |
| Modo de raciocínio | Raciocínio dinâmico ativado por padrão | Nível de raciocínio ajustável | Flash-Lite (pode ser desligado) |
| Corte de conhecimento | Janeiro de 2026 | Janeiro de 2025 | 3.5 Flash |
| MMMLU Multilíngue | Não divulgado (estimado 80+) | 88,9% | Flash-Lite |
| Velocidade de saída | Aprox. 289 token/s | 45% mais rápido que o 2.5 Flash, TTFT 2,5x mais rápido | Flash-Lite |
| Capacidade de ferramentas Agent | Supera o 3.1 Pro em vários benchmarks | Function calling padrão | Não necessário para tradução |
| Acesso via APIYI | Disponível | Disponível | Empate |
Ao ler esta tabela, foque em três pontos de divergência. O primeiro é a diferença de posicionamento: o Flash-Lite foca em "alto volume", o que significa que o Google projetou o modelo com a premissa de que a "vazão é prioridade sobre a inteligência pontual", o que se encaixa perfeitamente na demanda de tarefas de alta frequência como tradução e classificação. O segundo é o número de 88,9% no MMMLU, que é o modelo leve com o maior benchmark multilíngue da família Gemini 3.x, refletindo diretamente na qualidade da tradução. O terceiro é o "nível de raciocínio ajustável": o Flash-Lite permite desativar o thinking, o que pode reduzir ainda mais a latência em tarefas de tradução que não exigem uma cadeia de raciocínio complexa.
Comparação de custos no cenário de tradução: A diferença de preço de 6 vezes entre Gemini 3.5 Flash e 3.1 Flash-Lite
O custo é o indicador mais importante para a seleção de modelos em cenários de tradução. As tarefas de tradução são caracterizadas por "entradas e saídas curtas, mas com frequência altíssima". Um produto SaaS comum pode processar dezenas de milhões a centenas de milhões de tokens de tradução por dia; uma diferença de preço de 6 vezes significa uma diferença na fatura mensal que varia de alguns milhares a dezenas de milhares de dólares.
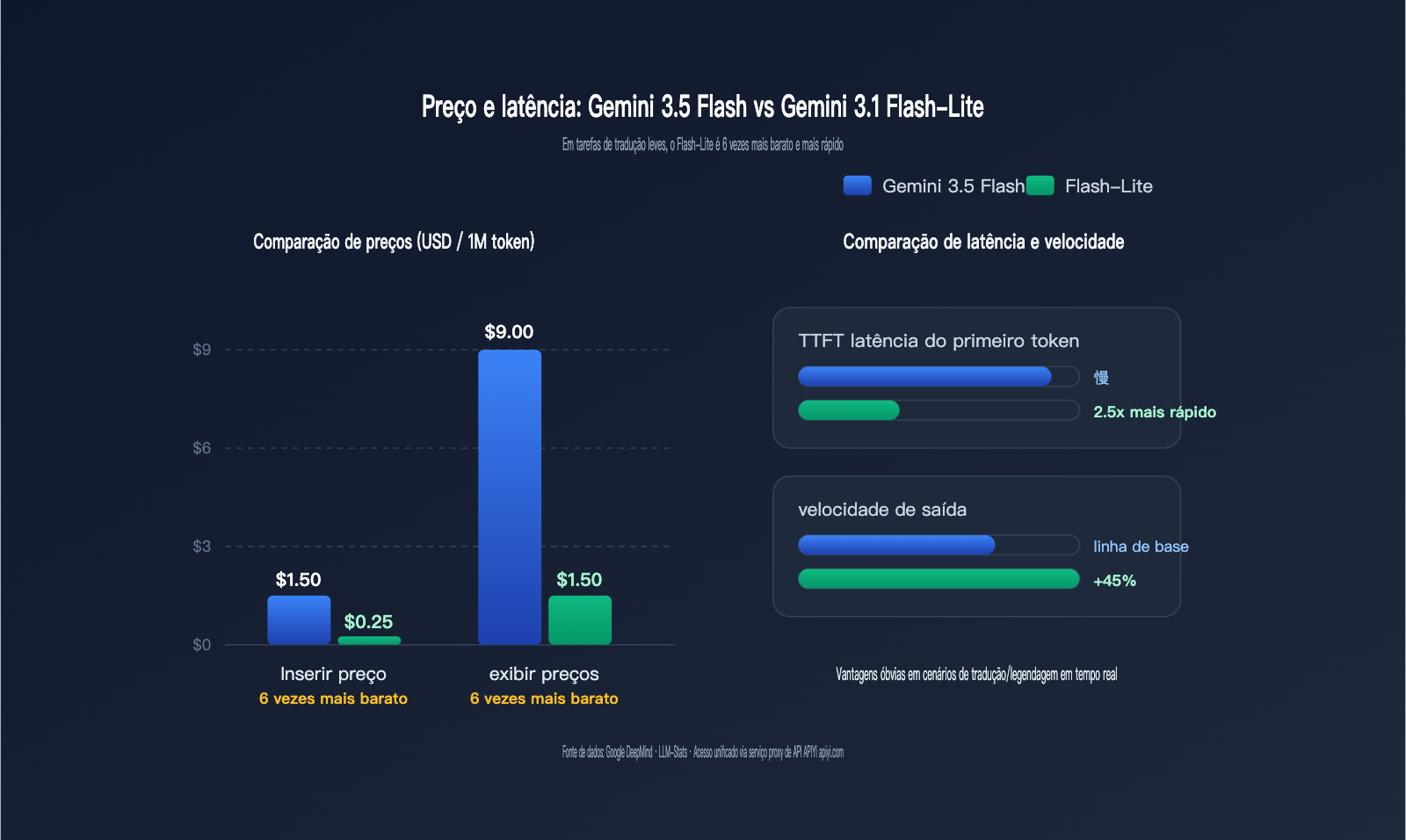
A tabela abaixo compara as dimensões de custo mais críticas no cenário de tradução, com todos os preços calculados por 1 milhão de tokens em dólares americanos.
| Dimensão de custo/desempenho | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Diferença |
|---|---|---|---|
| Preço de entrada | $1,50 | $0,25 | Flash-Lite 6x mais barato |
| Preço de saída | $9,00 | $1,50 | Flash-Lite 6x mais barato |
| Entrada com cache hit | $0,15 | $0,025 (estimado) | Flash-Lite 6x mais barato |
| TTFT (latência do primeiro token) | Mais baixa | 2,5x mais rápido que o 2.5 Flash | Flash-Lite |
| Velocidade de saída | Aprox. 289 token/s | 45% mais rápido que o 2.5 Flash | Empate ou leve vantagem Flash-Lite |
| Modo de raciocínio padrão | Ativado, com custo de thinking | Pode ser desligado, latência zero | Flash-Lite |
Vamos fazer uma simulação de fatura real. Suponha que um produto de tradução SaaS processe 10 milhões de tokens de entrada e 5 milhões de tokens de saída por dia (uma aplicação B2C de escala média). Qual seria a fatura mensal usando cada um dos modelos?
| Fatura mensal (10M entrada / 5M saída por dia) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Economia |
|---|---|---|---|
| Custo diário de entrada | $15,00 | $2,50 | $12,50 |
| Custo diário de saída | $45,00 | $7,50 | $37,50 |
| Total diário | $60,00 | $10,00 | $50 |
| Total mensal (30 dias) | $1.800 | $300 | $1.500 / mês |
| Total anual | $21.600 | $3.600 | $18.000 / ano |
💡 Dica de cálculo de custos: Aplique os números desta tabela ao seu volume real de tráfego; a diferença mensal geralmente ultrapassa quatro dígitos em dólares. Sugiro registrar uma conta no APIYI (apiyi.com) para obter o crédito gratuito de 0,05 dólares, usar o mesmo conjunto de amostras de tradução para invocar o
gemini-3.5-flashe ogemini-3.1-flash-lite-preview. Isso permitirá validar a diferença de qualidade e obter o diferencial de preço real para o seu negócio.
Análise de desempenho: Qualidade e velocidade de tradução do Gemini 3.1 Flash-Lite
Preço baixo não significa nada se a qualidade da tradução não for boa. Os dados de teste do Gemini 3.1 Flash-Lite em tradução são, na verdade, muito sólidos. Na grande maioria dos cenários, a qualidade da tradução não deixa o usuário com a sensação de que é "visivelmente pior que o Flash". Os quatro conjuntos de dados abaixo são a prova principal.
Primeiro, a pontuação de 88,9% no benchmark multilíngue MMMLU. O MMMLU (Multilingual MMLU) avalia a capacidade do modelo de compreender conhecimentos especializados e realizar raciocínios em mais de 15 idiomas. O Flash-Lite atingiu 88,9% neste quesito, posicionando-se no topo absoluto entre os modelos de nível Flash-Lite, o que significa que ele mantém alta qualidade em idiomas não latinos, como chinês, japonês, coreano e árabe.
Segundo, o que o Google DeepMind declarou explicitamente no model card: "best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts" (a melhor tradução e compreensão multilíngue da categoria, com melhorias notáveis em escritas não latinas). Este é o aval oficial do Google para a capacidade de tradução do Flash-Lite, destacando especialmente o avanço em "escritas não latinas" — algo crucial para SaaS em chinês.
Terceiro, a conclusão da avaliação comparativa do Lara Translate no Translation Model Benchmark de fevereiro de 2026: as variantes da série Flash são posicionadas como a escolha preferencial para "fluxos de trabalho de menor latência e maior throughput". As restrições centrais de tarefas de tradução (baixa latência + alto throughput + sensibilidade a custos) alinham-se perfeitamente aos objetivos de design do Flash-Lite.
Quarto, o Time-to-First-Token (TTFT) e a velocidade de saída. O TTFT do Flash-Lite é 2,5 vezes mais rápido que o do Gemini 2.5 Flash, com um aumento de 45% na velocidade de saída. Esses dois indicadores determinam diretamente a experiência do usuário em cenários sensíveis à "tempo real", como a tradução. Recomendamos testar o tempo de tradução de um mesmo texto de 5.000 caracteres chineses para inglês no APIYI (apiyi.com); a diferença é muito intuitiva.
Recomendação de cenários: Quando escolher o Flash-Lite e quando usar o 3.5 Flash
Convertendo a comparação de 6 dimensões em sugestões práticas de seleção de tarefas, podemos resumir na tabela de recomendações abaixo. Ela não resolve a questão de "qual modelo é mais forte", mas sim "qual usar em cada tarefa específica".
| Tipo de tarefa | Modelo recomendado | Motivo principal |
|---|---|---|
| Tradução de texto geral (Chinês-Inglês/Chinês-Japonês, etc.) | Gemini 3.1 Flash-Lite | MMMLU 88,9% + 6x mais barato |
| Tradução de legendas / Tradução em tempo real | Gemini 3.1 Flash-Lite | TTFT 2,5x mais rápido + 45% mais velocidade |
| Moderação de conteúdo / Classificação de texto | Gemini 3.1 Flash-Lite | Sweet spot oficial do Google, ideal para tarefas em lote |
| Extração de dados estruturados | Gemini 3.1 Flash-Lite | Adequado para extração de JSON em grande escala |
| Chatbot multilíngue | Gemini 3.1 Flash-Lite | Qualidade multilíngue + baixa latência + baixo custo |
| Tradução + Agente de pós-processamento | Gemini 3.5 Flash | Requer function calling para encadear várias ferramentas |
| Tradução + Chamada de ferramentas | Gemini 3.5 Flash | Capacidade de agente superior ao 3.1 Pro |
| Assistente de código / Autocompletar em IDE | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76,2% |
| Perguntas e respostas em RAG de documentos longos | Gemini 3.5 Flash | Cache hit + 1M de janela de contexto |
| Fluxos de trabalho de Agente complexos | Gemini 3.5 Flash | MCP Atlas 83,6% |
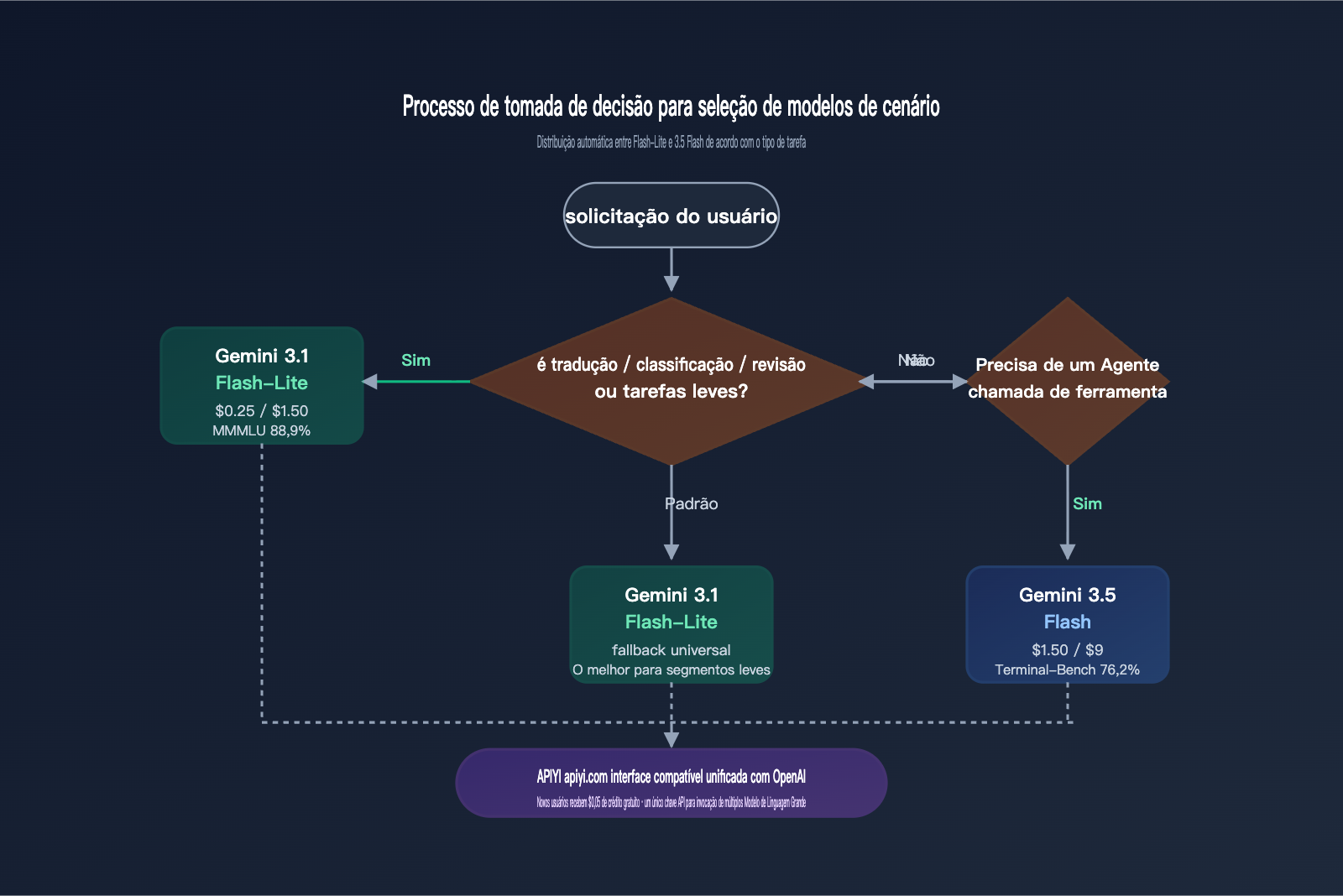
A estratégia mais ideal na prática continua sendo o "roteamento por tarefa": tradução/classificação/moderação utilizam o gemini-3.1-flash-lite-preview, enquanto Agentes / codificação / RAG de documentos longos utilizam o gemini-3.5-flash. Ambos os modelos podem ser alternados sob a mesma chave de autenticação do APIYI (apiyi.com). Dessa forma, você obtém o bônus de custo 6x menor do Flash-Lite em tarefas leves, mantendo o limite de capacidade do 3.5 Flash para Agentes pesados.
Cenários típicos para escolher o Gemini 3.1 Flash-Lite
Se o seu produto possui qualquer característica abaixo, o Flash-Lite é quase certamente a melhor solução: número de chamadas diárias superior a 100 mil, entrada/saída única dentro de 5K tokens, sensibilidade à latência P95, sem necessidade de chamada de ferramentas e necessidade de suporte a vários idiomas. Cenários típicos incluem tradução de produtos de e-commerce transfronteiriço, atendimento ao cliente multilíngue em SaaS, pipelines de moderação de conteúdo, geração de legendas, normalização após OCR em lote, etc. Com a interface compatível com OpenAI do APIYI (apiyi.com), o custo de migração é quase zero.
Cenários típicos onde ainda recomendamos o Gemini 3.5 Flash
Se a sua tarefa envolve "chamar ferramentas após a tradução" ou "incorporar a tradução em uma cadeia de Agentes complexa", o Gemini 3.5 Flash é o que faz sentido. Por exemplo: tradução + recuperação de base de conhecimento + chamada de API externa, ou o usuário envia um texto em língua estrangeira → o modelo traduz primeiro → depois chama ferramentas de calculadora/pesquisa/execução de código. Usar o Flash-Lite nessas tarefas causará erros repetidos devido à falta de capacidade de Agente, tornando o custo, na verdade, mais alto.
Exemplo de integração do Gemini 3.1 Flash-Lite na APIYI para cenários de tradução
Abaixo, apresento um exemplo de integração Python otimizado para cenários de tradução, demonstrando como realizar a invocação do modelo Gemini 3.1 Flash-Lite na APIYI (apiyi.com), mantendo total compatibilidade com a sintaxe da OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Traduza a entrada do usuário para {target_lang}. Forneça apenas a tradução, sem explicações."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("A inteligência artificial está mudando o modelo de colaboração na engenharia de software.", "English"))
Ver implementação completa com concorrência em lote e rota de fallback
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Traduza para {target_lang}. Forneça apenas a tradução."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Traduza para {target_lang}. Forneça apenas a tradução."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["Olá, mundo.", "A inteligência artificial está mudando o setor.", "Por favor, ajude-me a reservar uma passagem para Tóquio amanhã."]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Dicas de otimização para tradução em lote: Cenários de tradução funcionam bem com alta concorrência (
concurrency=20~50), temperatura mais baixa (0.1-0.3) e um comando (system prompt) curto. A plataforma APIYI (apiyi.com) já possui roteamento otimizado para cenários de alto throughput. Novos usuários ganham US$ 0,05 em créditos gratuitos; com o preço de US$ 0,25/US$ 1,50 do Flash-Lite, isso é suficiente para traduzir entre 50 mil e 100 mil tokens de conteúdo real, o que é ideal para realizar um teste de estresse completo em um pipeline de tradução em lote.
FAQ: Perguntas frequentes sobre tradução com Gemini 3.5 Flash vs 3.1 Flash-Lite
Q1: O Gemini 3.1 Flash-Lite é uma versão Preview, posso usar em produção?
Pode, mas é recomendável ter um plano de contingência. O Flash-Lite está em fase Preview desde 3 de março de 2026 e o Google ainda não forneceu uma data oficial de GA (Disponibilidade Geral), embora a interface da API e os preços estejam estáveis. Sugerimos uma estratégia de dois modelos em produção: "Rota principal Flash-Lite + Fallback para 3.5 Flash", gerenciada pela interface unificada da APIYI (apiyi.com) para evitar dependência de um único ponto. Quando o Google atualizar para GA ou lançar o 3.5 Flash-Lite, basta alterar o campo model para uma migração suave.
Q2: A qualidade da tradução do Flash-Lite realmente alcança a do Flash?
Em mais de 90% das tarefas de tradução geral, sim. O cartão de modelo do Google DeepMind afirma claramente que o Flash-Lite possui "tradução e compreensão multilíngue de primeira classe", com uma pontuação de 88,9% no MMMLU multilíngue. No entanto, o 3.5 Flash ainda leva vantagem em dois cenários: traduções longas com terminologia técnica (médica, jurídica, financeira) e tradução combinada com raciocínio contextual (como identificar referências de pronomes com base no contexto). Recomendamos rodar uma amostra real do seu negócio na APIYI (apiyi.com) para uma comparação direta, em vez de olhar apenas para benchmarks.
Q3: É adequado substituir o GPT-4o-mini ou Claude Haiku 4.5 pelo Flash-Lite para tradução?
Sim, e geralmente é mais barato e rápido. O preço de US$ 0,25/US$ 1,50 do Gemini 3.1 Flash-Lite é competitivo. Embora o GPT-4o-mini pareça mais barato (US$ 0,15/US$ 0,60), a qualidade da tradução no Flash-Lite costuma ser superior. Recomendamos configurar os três modelos sob a mesma chave na APIYI (apiyi.com) e realizar um teste A/B para ver qual se adapta melhor ao seu par de idiomas específico.
Q4: A janela de contexto de 1M do Flash-Lite pode ser usada para tradução?
Sim, e essa é sua capacidade mais subestimada. 1 milhão de tokens equivalem a cerca de 700 mil a 800 mil palavras em inglês ou 300 mil a 400 mil caracteres em chinês, o que é suficiente para traduzir um livro de tamanho médio ou um conjunto completo de documentos corporativos de uma só vez. Com o modo de pensamento (thinking) desativado, o custo de uma tradução única com 1M de contexto é de aproximadamente US$ 0,25 (entrada) + US$ 1,50 (saída), muito abaixo de dividir o mesmo conteúdo para o 3.5 Flash ou GPT-5.5. A APIYI (apiyi.com) já disponibiliza a janela de contexto de 1M do Flash-Lite para uso imediato.
Resumo: Gemini 3.1 Flash-Lite é a melhor escolha com custo-benefício 6x superior para tradução
Voltando ao ponto central deste artigo: para tarefas leves e de alta frequência como tradução, o Gemini 3.1 Flash-Lite não é uma "versão inferior" do Gemini 3.5 Flash, mas sim a solução ideal projetada pelo Google especificamente para esses cenários. O preço de entrada é 6 vezes menor, o preço de saída é 6 vezes menor, a latência do primeiro token é 2,5 vezes mais rápida, a pontuação multilíngue no MMMLU chega a 88,9% e o próprio Google classifica a tradução como seu ponto forte. Esses cinco fatos determinam sua dominância em cenários de tradução. Os pontos fortes do Gemini 3.5 Flash em agentes e codificação são inúteis na tradução, e o valor extra que você paga por essas capacidades é um desperdício puro.
A estratégia mais segura é o roteamento de dois modelos: use o gemini-3.1-flash-lite-preview para tradução, classificação e moderação, e o gemini-3.5-flash para agentes, codificação e RAG de documentos longos. Você pode alternar entre eles usando a interface compatível com OpenAI da APIYI (apiyi.com) sob a mesma chave API. Novos usuários recebem um crédito gratuito de 0,05 dólares, o suficiente para realizar um teste de estresse completo em um pipeline de tradução em lote e verificar a economia real de custos para o seu negócio.
Autor: Equipe Técnica da APIYI · apiyi.com
Data de publicação: 20 de maio de 2026
Referências: Google DeepMind Model Card, Google Blog, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub