بعد إطلاق نموذج Gemini 3.5 Flash في 19 مايو 2026، قامت العديد من الفرق بنقل جميع حركة مرور البيانات (Traffic) الخاصة بها إليه بشكل افتراضي، بما في ذلك المهام الخفيفة وعالية التكرار مثل الترجمة، وتوليد العناوين الفرعية، ومراجعة المحتوى. في الواقع، يُعد هذا تقديراً خاطئاً. ففي سيناريوهات مثل الترجمة، حيث تكون مدخلات ومخرجات النص قصيرة، والحساسية تجاه التكلفة والزمن (Latency) فائقة، ولا توجد حاجة لتنظيم أدوات الوكيل (Agent)، يظل نموذج Gemini 3.1 Flash-Lite هو الحل الأمثل، وليس Gemini 3.5 Flash الأكثر تكلفة و"شمولية". يقدم هذا المقال مقارنة منهجية بين النموذجين من 6 أبعاد، بناءً على بيانات رسمية من Google DeepMind، وLLM-Stats، وArtificial Analysis.

الخلاصة المباشرة: في سيناريوهات المهام الخفيفة مثل الترجمة، والعناوين الفرعية، والتصنيف الجماعي، وتنسيق النصوص، أوصي باستخدام Gemini 3.1 Flash-Lite بدلاً من Gemini 3.5 Flash، وذلك لستة أسباب جوهرية: تكلفة المدخلات أقل بـ 6 مرات، وتكلفة المخرجات أقل بـ 6 مرات، وزمن استجابة الرمز الأول (First Token Latency) أسرع بـ 2.5 مرة، ودرجة اختبار MMMLU للغات المتعددة تصل إلى 88.9%، كما صنفت Google الترجمة رسمياً كأحد مجالات تميزه (Sweet Spot)، بالإضافة إلى أن قدرات الوكيل (Agent) القوية في 3.5 Flash لا فائدة منها في مهام الترجمة. يُنصح بتجربة مجموعة من مهام الترجمة الفعلية عبر رصيد مجاني بقيمة 0.05 دولار من منصة APIYI (apiyi.com) لإجراء مقارنة، حيث ستكون الفجوة في التكلفة والجودة أكثر وضوحاً من الأرقام القياسية.
لماذا يتفوق Gemini 3.1 Flash-Lite على Gemini 3.5 Flash في مهام الترجمة؟
تتميز مهام الترجمة بوضوح شديد: المدخلات هي نصوص قصيرة باللغة المصدر (من بضع مئات إلى بضعة آلاف من الرموز)، والمخرجات هي نصوص قصيرة باللغة المستهدفة، ولا يتطلب الاستدعاء الواحد سلسلة تفكير معقدة، أو استدعاء أدوات، أو دمجاً متعدد الوسائط، ولكن تكرار الاستدعاء مرتفع جداً، والحساسية تجاه التكلفة وزمن الاستجابة فائقة. وهذا هو بالضبط السيناريو الذي صُممت من أجله سلسلة Flash-Lite من Google.
تم إطلاق Gemini 3.1 Flash-Lite في 3 مارس 2026، وذكرت مدونة Google الرسمية أنه "نموذج الذكاء الاصطناعي الأكثر فعالية من حيث التكلفة لدينا حتى الآن"، وحددت بوضوح "الترجمة الضخمة، وتصنيف المحتوى، والمراجعة، واستخراج البيانات المهيكلة، ومهام الوكيل المتكررة" كمجالات تميزه. وأشارت بطاقة نموذج DeepMind إلى أنه يتمتع بـ "أفضل قدرات ترجمة وفهم للغات متعددة في فئته، مع تحسينات ملحوظة في النصوص غير اللاتينية"، حيث سجل 88.9% في معيار MMMLU للغات المتعددة، مما يجعله في صدارة النماذج الخفيفة.
أما Gemini 3.5 Flash، الذي تم إطلاقه في 19 مايو، فهو نموذج "Flash الموجه للوكلاء" (Agentic Flash)، ويتمحور حول "تنظيم أدوات الوكيل + البرمجة الأساسية"، حيث تفوق على Gemini 3.1 Pro في اختبارات Terminal-Bench 2.1 وMCP Atlas وFinance Agent v2. لكن هذه القدرات الخاصة بالوكلاء لا تُستخدم إطلاقاً في مهام الترجمة، وما تدفعه من تكلفة إضافية مقابل هذه القدرات هو هدر خالص. ولهذا السبب قامت Google بتقسيم "سلسلة Flash" حسب نوع المهمة: مهام الوكلاء تستخدم 3.5 Flash، بينما الترجمة/التصنيف/المراجعة تستخدم 3.1 Flash-Lite.
🎯 نصيحة أساسية للاختيار: لا تنخدع بالاعتقاد بأن "رقم الإصدار الأكبر يعني دائماً أداءً أفضل". إن Gemini 3.5 Flash (إصدار مايو) وGemini 3.1 Flash-Lite (إصدار مارس) هما خطان إنتاج متوازيان، يغطي كل منهما فئة مختلفة: "الوكلاء الأساسيون" و"المهام الخفيفة عالية الإنتاجية". توفر منصة APIYI (apiyi.com) كلا النموذجين، ويمكنك التوجيه التلقائي للمهام حسب نوعها تحت مفتاح API واحد، دون الحاجة للاختيار بينهما.
مقارنة مواصفات Gemini 3.5 Flash و Gemini 3.1 Flash-Lite
عند وضع النموذجين في جدول واحد، تتضح الفروقات في تقسيم خط الإنتاج والقدرات بشكل جلي. يلخص الجدول أدناه المواصفات الأساسية للنموذجين، حيث تم استقاء جميع البيانات من بطاقة نموذج Google DeepMind وصفحات LLM-Stats العامة.
| بُعد المقارنة | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | الأفضل في الترجمة |
|---|---|---|---|
| تاريخ الإصدار | 19 مايو 2026 | 3 مارس 2026 | — |
| حالة الإصدار | GA (إصدار رسمي) | Preview (إصدار معاينة) | — |
| معرف النموذج | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| التموضع | Agentic Flash (وكيل ذكي) | High-volume (كفاءة عالية) | Flash-Lite |
| نافذة السياق | 1 مليون إدخال / 64 ألف إخراج | 1 مليون إدخال / 64 ألف إخراج | تعادل |
| أنماط الإدخال | نص+صورة+صوت+فيديو | نص+صورة+صوت+فيديو | تعادل |
| نمط التفكير | تفكير ديناميكي مفعل افتراضياً | مستوى تفكير قابل للتعديل | Flash-Lite (يمكن إيقافه) |
| تاريخ توقف المعرفة | يناير 2026 | يناير 2025 | 3.5 Flash |
| MMMLU متعدد اللغات | لم يُعلن (المتوقع 80+) | 88.9% | Flash-Lite |
| سرعة الإخراج | حوالي 289 رمز/ثانية | أسرع من 2.5 Flash بـ 45%، TTFT أسرع بـ 2.5x | Flash-Lite |
| قدرات أدوات الوكيل | تتفوق على 3.1 Pro في معايير عدة | استدعاء وظائف قياسي | غير ضروري للترجمة |
| الربط عبر APIYI | متاح | متاح | تعادل |
عند قراءة هذا الجدول، يجب التركيز على ثلاث نقاط اختلاف جوهرية. الأولى هي اختلاف التموضع: حيث يركز Flash-Lite على "حجم العمل العالي" (high-volume)، مما يعني أن جوجل صممته ليكون "الإنتاجية فوق الذكاء الفردي"، وهو ما يتناسب تماماً مع احتياجات مهام الترجمة والتصنيف عالية التكرار. الثانية هي رقم 88.9% في اختبار MMMLU، وهو أعلى معيار متعدد اللغات لنماذج الفئة الخفيفة في عائلة Gemini 3.x، مما يعكس جودة الترجمة مباشرة. الثالثة هي "مستوى التفكير القابل للتعديل"، حيث يسمح Flash-Lite بإيقاف خاصية التفكير، مما يقلل زمن الاستجابة (Latency) في مهام الترجمة التي لا تتطلب تفكيراً معقداً.
مقارنة التكلفة في مهام الترجمة: فارق السعر 6 أضعاف بين Gemini 3.5 Flash و 3.1 Flash-Lite
تعد التكلفة المؤشر الأهم عند اختيار النموذج لمهام الترجمة. تتميز مهام الترجمة بأنها "ذات إدخال وإخراج قصير ولكن بتكرار عالٍ جداً". قد يحتاج منتج SaaS شائع إلى معالجة عشرات الملايين من الرموز (tokens) يومياً، لذا فإن فارق السعر بمقدار 6 أضعاف يعني فرقاً في الفاتورة الشهرية يتراوح بين آلاف وعشرات آلاف الدولارات.
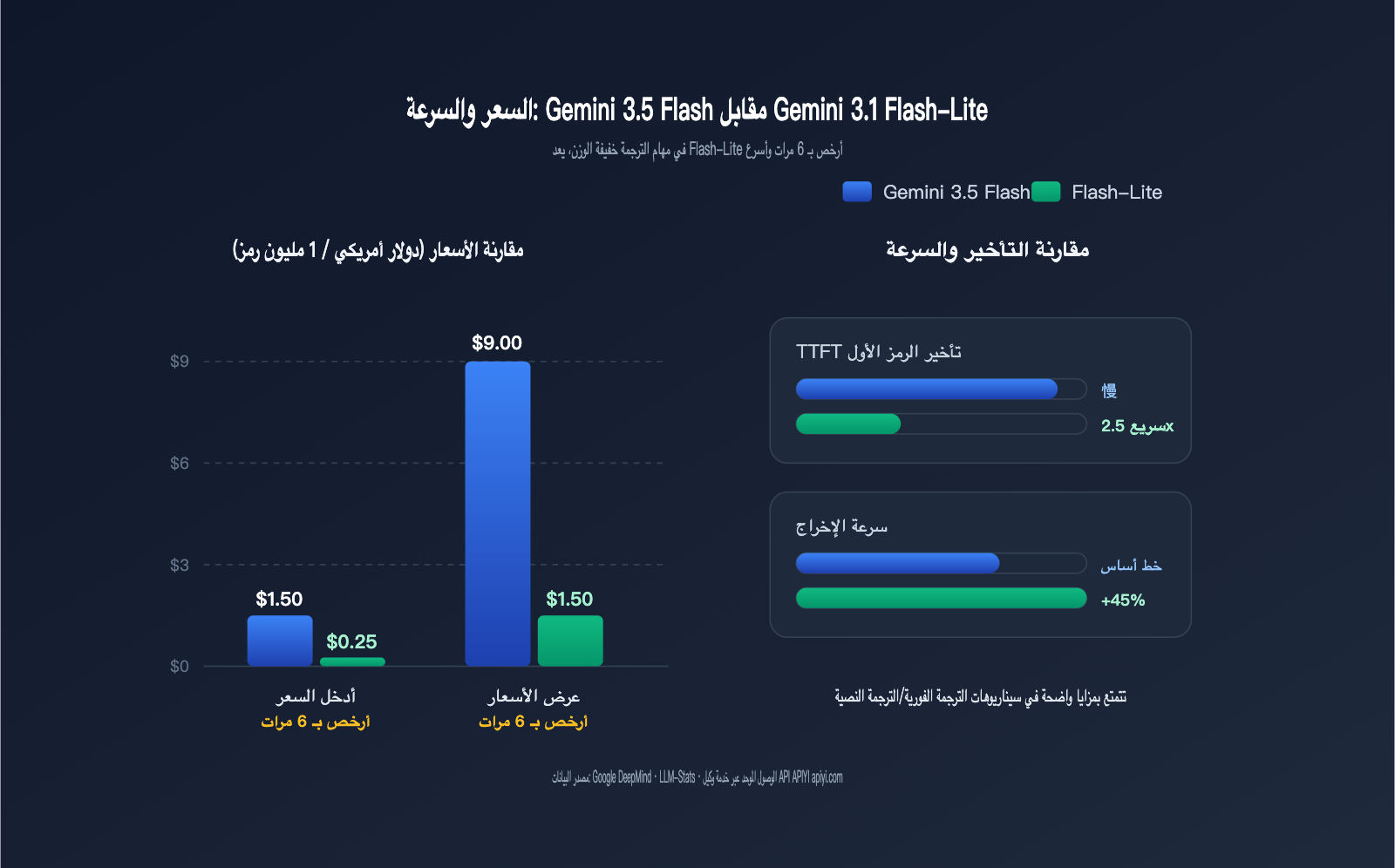
يوضح الجدول التالي أهم أبعاد التكلفة للنموذجين في سياق الترجمة، حيث يتم حساب جميع الأسعار لكل مليون رمز (token).
| بُعد التكلفة/الأداء | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | الفارق |
|---|---|---|---|
| سعر الإدخال | $1.50 | $0.25 | Flash-Lite أرخص بـ 6 أضعاف |
| سعر الإخراج | $9.00 | $1.50 | Flash-Lite أرخص بـ 6 أضعاف |
| إدخال مع ذاكرة مؤقتة | $0.15 | $0.025 (تقديري) | Flash-Lite أرخص بـ 6 أضعاف |
| TTFT (زمن أول رمز) | أبطأ | أسرع من 2.5 Flash بـ 2.5x | Flash-Lite |
| سرعة الإخراج | ~289 رمز/ثانية | أسرع من 2.5 Flash بـ 45% | تعادل/أفضل قليلاً لـ Flash-Lite |
| نمط التفكير | مفعل افتراضياً (تكلفة إضافية) | قابل للإيقاف (بدون تأخير تفكير) | Flash-Lite |
لنقم بمحاكاة فاتورة حقيقية. لنفترض أن منتج ترجمة SaaS يعالج يومياً 10 ملايين رمز إدخال و5 ملايين رمز إخراج (تطبيق B2C متوسط الحجم)، كيف ستكون الفاتورة الشهرية عند استخدام النموذجين؟
| الفاتورة الشهرية (10 مليون إدخال / 5 مليون إخراج يومياً) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | التوفير |
|---|---|---|---|
| تكلفة الإدخال اليومية | $15.00 | $2.50 | $12.50 |
| تكلفة الإخراج اليومية | $45.00 | $7.50 | $37.50 |
| الإجمالي اليومي | $60.00 | $10.00 | $50 |
| الإجمالي الشهري (30 يوماً) | $1,800 | $300 | $1,500 / شهرياً |
| الإجمالي السنوي | $21,600 | $3,600 | $18,000 / سنوياً |
💡 نصيحة لحساب التكلفة: قم بإسقاط أرقام هذا الجدول على حجم حركة البيانات الحقيقية لديك؛ عادة ما يكون الفارق الشهري بأربعة أرقام بالدولار. يُنصح بالتسجيل في APIYI (apiyi.com) للحصول على رصيد مجاني بقيمة 0.05 دولار، ثم تجربة نفس مجموعة نصوص الترجمة باستخدام
gemini-3.5-flashوgemini-3.1-flash-lite-preview؛ فهذا لا يساعدك فقط في التحقق من فارق الجودة، بل يمنحك أيضاً التكلفة الفعلية الدقيقة لأعمالك.
تحليل أداء Gemini 3.1 Flash-Lite: الجودة والسرعة
لا جدوى من السعر الرخيص إذا لم تكن جودة الترجمة مقبولة. في الواقع، البيانات العملية لنموذج Gemini 3.1 Flash-Lite في مهام الترجمة قوية للغاية، وفي معظم السيناريوهات لن يشعر المستخدم بأن جودته "أقل بشكل ملحوظ" من نموذج Flash. إليك أربع مجموعات من البيانات كأدلة جوهرية:
أولاً، درجة 88.9% في معيار MMMLU متعدد اللغات. يقيس معيار MMMLU (Multilingual MMLU) قدرة النموذج على فهم المعرفة المتخصصة والاستنتاج عبر أكثر من 15 لغة. وصول Flash-Lite إلى 88.9% يضعه في صدارة النماذج من فئته، مما يعني أنه يحافظ على جودة عالية في اللغات غير اللاتينية مثل الصينية، اليابانية، الكورية، والعربية.
ثانياً، ما ذكره فريق Google DeepMind بوضوح في بطاقة النموذج (model card): "أفضل ترجمة وفهم متعدد اللغات في فئته، مع تحسينات ملحوظة في النصوص غير اللاتينية". هذا دعم رسمي من جوجل لقدرات Flash-Lite في الترجمة، مع التركيز بشكل خاص على التحسينات في "النصوص غير اللاتينية"، وهو أمر بالغ الأهمية لخدمات SaaS التي تستهدف لغات متعددة.
ثالثاً، استنتاج اختبار Lara Translate في فبراير 2026 ضمن "معيار نماذج الترجمة": تم تصنيف متغيرات سلسلة Flash كخيار أول لـ "سير العمل الذي يتطلب زمن انتقال منخفض وإنتاجية عالية"، حيث تتطابق القيود الأساسية لمهام الترجمة (زمن انتقال منخفض + إنتاجية عالية + حساسية للتكلفة) تماماً مع أهداف تصميم Flash-Lite.
رابعاً، زمن الوصول للرمز الأول (TTFT) وسرعة الإخراج. زمن TTFT لنموذج Flash-Lite أسرع بـ 2.5 مرة من Gemini 2.5 Flash، مع زيادة في سرعة الإخراج بنسبة 45%. هذان المؤشران يحددان تجربة المستخدم مباشرة في سيناريوهات "حساسة للوقت" مثل الترجمة. ننصح بتجربة قياس وقت ترجمة 5000 كلمة من الصينية إلى الإنجليزية على منصة APIYI (apiyi.com)، حيث ستكون الفجوة واضحة جداً.
توصيات السيناريوهات: متى تختار Flash-Lite ومتى تختار 3.5 Flash؟
بدلاً من المقارنة عبر 6 أبعاد، يمكننا تلخيص ذلك في جدول التوصيات التالي. هذا الجدول لا يحدد "أي نموذج أقوى"، بل يحدد "أي نموذج يجب استخدامه لكل مهمة محددة".
| نوع المهمة | النموذج الموصى به | السبب الرئيسي |
|---|---|---|
| الترجمة النصية العامة (صيني-إنجليزي/صيني-ياباني إلخ) | Gemini 3.1 Flash-Lite | درجة MMMLU 88.9% + سعر أرخص بـ 6 مرات |
| ترجمة الترجمة المرئية / الترجمة الفورية | Gemini 3.1 Flash-Lite | TTFT أسرع بـ 2.5 مرة + سرعة إخراج أعلى بـ 45% |
| مراجعة المحتوى / تصنيف النصوص | Gemini 3.1 Flash-Lite | النقطة المثالية حسب جوجل، الأفضل للمهام الجماعية |
| استخراج البيانات المهيكلة | Gemini 3.1 Flash-Lite | مناسب لاستخراج كميات كبيرة من JSON |
| روبوتات المحادثة متعددة اللغات | Gemini 3.1 Flash-Lite | جودة متعددة اللغات + زمن انتقال منخفض + تكلفة منخفضة |
| ترجمة + وكيل معالجة لاحقة | Gemini 3.5 Flash | يتطلب استدعاء وظائف (function calling) لربط أدوات متعددة |
| ترجمة + استدعاء أدوات | Gemini 3.5 Flash | قدرات الوكيل تتفوق على 3.1 Pro |
| مساعد البرمجة / الإكمال التلقائي في IDE | Gemini 3.5 Flash | درجة Terminal-Bench 2.1 = 76.2% |
| الإجابة على الأسئلة عبر RAG للمستندات الطويلة | Gemini 3.5 Flash | توافق التخزين المؤقت + نافذة سياق 1M |
| سير عمل الوكيل المعقد | Gemini 3.5 Flash | درجة MCP Atlas 83.6% |
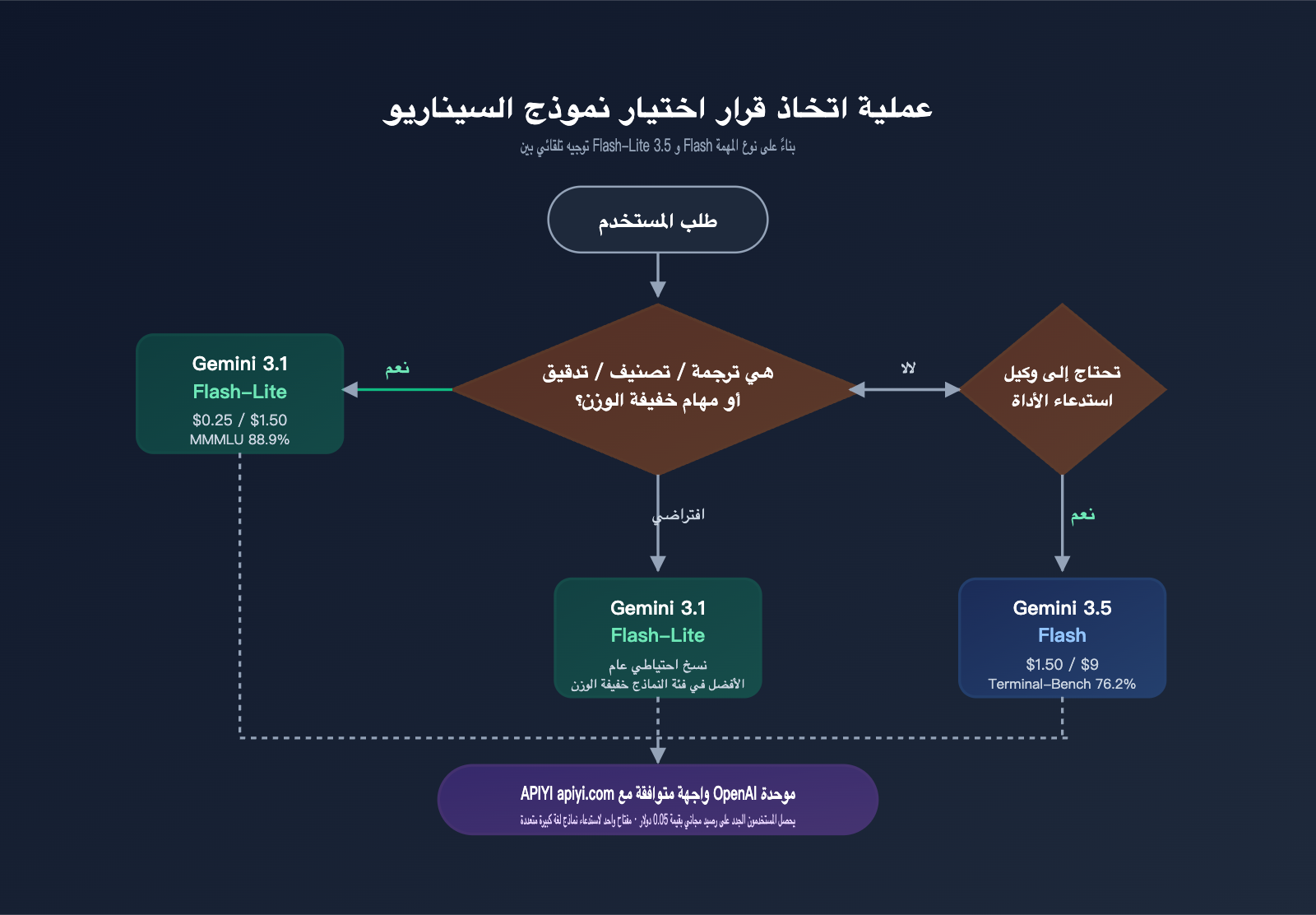
تظل الاستراتيجية المثالية في الممارسة العملية هي "التوجيه حسب المهمة": مهام الترجمة/التصنيف/المراجعة توجه إلى gemini-3.1-flash-lite-preview، بينما توجه مهام الوكيل (Agent) / البرمجة / RAG للمستندات الطويلة إلى gemini-3.5-flash، مع ربط كلا النموذجين تحت مفتاح API واحد على منصة APIYI (apiyi.com) للتبديل بينهما. بهذه الطريقة، يمكنك الاستفادة من ميزة التكلفة المنخفضة لـ Flash-Lite في المهام الخفيفة، مع الحفاظ على سقف قدرات 3.5 Flash في مهام الوكيل الثقيلة.
سيناريوهات نموذجية لاختيار Gemini 3.1 Flash-Lite
إذا كان منتجك يحتوي على أي من الخصائص التالية، فمن المرجح أن يكون Flash-Lite هو الحل الأمثل: عدد مرات الاستدعاء اليومي يتجاوز 100 ألف مرة، حجم المدخلات والمخرجات في المرة الواحدة ضمن 5 آلاف رمز (token)، الحساسية لزمن انتقال P95، عدم الحاجة لاستدعاء أدوات، والحاجة لدعم لغات متعددة. تشمل السيناريوهات النموذجية ترجمة منتجات التجارة الإلكترونية العابرة للحدود، خدمة عملاء SaaS متعددة اللغات، خطوط أنابيب مراجعة المحتوى، توليد الترجمة المرئية، وتطبيع البيانات بعد التعرف الضوئي على الحروف (OCR) بكميات كبيرة. وبالتعاون مع واجهة APIYI (apiyi.com) المتوافقة مع OpenAI، فإن تكلفة الترحيل تكاد تكون صفراً.
سيناريوهات نموذجية لاختيار Gemini 3.5 Flash
إذا كانت مهامك تتضمن "استدعاء أدوات بعد الترجمة" أو "دمج الترجمة في سلسلة وكيل معقدة"، فإن Gemini 3.5 Flash هو الخيار المنطقي. على سبيل المثال: الترجمة + استرجاع قاعدة المعرفة + استدعاء API خارجي، أو عندما يقدم المستخدم نصاً بلغة أجنبية → يقوم النموذج بالترجمة أولاً → ثم استدعاء أدوات مثل الحاسبة/البحث/تنفيذ الكود. استخدام Flash-Lite في هذه المهام سيؤدي إلى أخطاء متكررة بسبب نقص قدرات الوكيل، مما يجعل التكلفة أعلى في النهاية.
مثال على دمج Gemini 3.1 Flash-Lite في خدمة APIYI لسيناريوهات الترجمة
فيما يلي مثال برمجي بسيط بلغة Python مُحسّن لسيناريوهات الترجمة، يوضح كيفية استدعاء نموذج Gemini 3.1 Flash-Lite عبر منصة APIYI (apiyi.com)، مع الحفاظ الكامل على التوافق مع مكتبة OpenAI.
from openai import OpenAI
# إعداد العميل باستخدام مفتاح API الخاص بك
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"ترجم مدخلات المستخدم إلى {target_lang}. أخرج الترجمة فقط، بدون أي شرح."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("الذكاء الاصطناعي يغير أنماط التعاون في هندسة البرمجيات.", "English"))
عرض التنفيذ الكامل مع التزامن الجماعي (Batch) ومسار الرجوع (Fallback)
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"ترجم إلى {target_lang}. أخرج الترجمة فقط."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
# في حال حدوث خطأ، يتم الرجوع للنموذج البديل
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"ترجم إلى {target_lang}. أخرج الترجمة فقط."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["مرحباً بالعالم.", "الذكاء الاصطناعي يغير الصناعة.", "ساعدني في حجز تذكرة طيران إلى طوكيو غداً."]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 نصائح لتحسين الترجمة الجماعية: سيناريوهات الترجمة مناسبة جداً لاستخدام التزامن العالي (
concurrency=20~50) مع درجة حرارة (temperature) منخفضة (0.1-0.3) وموجه (system prompt) قصير. منصة APIYI (apiyi.com) قامت بتحسين التوجيه لسيناريوهات الإنتاجية العالية. يحصل المستخدمون الجدد على رصيد مجاني بقيمة 0.05 دولار، وهو ما يكفي لترجمة 50 ألف إلى 100 ألف توكن، مما يتيح لك اختبار خط أنابيب الترجمة بالكامل.
الأسئلة الشائعة حول الترجمة باستخدام Gemini 3.5 Flash مقابل 3.1 Flash-Lite
س1: Gemini 3.1 Flash-Lite هو إصدار تجريبي (Preview)، هل يمكن استخدامه في بيئة الإنتاج؟
نعم، ولكن يجب أن تكون مستعداً. منذ إطلاقه في 3 مارس 2026، لا يزال Flash-Lite في مرحلة المعاينة، ولم تحدد جوجل تاريخاً رسمياً للإطلاق العام (GA)، لكن واجهات البرمجة (API) والأسعار أصبحت مستقرة. نوصي باستخدام استراتيجية "النموذج المزدوج" في بيئة الإنتاج: المسار الرئيسي Flash-Lite مع مسار رجوع (Fallback) لنموذج 3.5 Flash، وذلك عبر واجهة APIYI الموحدة لتجنب الاعتماد على نقطة فشل واحدة.
س2: هل يمكن لـ Flash-Lite حقاً مجاراة Flash في جودة الترجمة؟
في أكثر من 90% من مهام الترجمة العامة، نعم. تشير بطاقة نموذج Google DeepMind إلى أن Flash-Lite يتمتع بـ "أفضل ترجمة وفهم متعدد اللغات في فئته"، مع درجة 88.9% في اختبار MMMLU. ومع ذلك، يتفوق 3.5 Flash في حالتين: الترجمة الطويلة التي تتضمن مصطلحات تقنية (طبية، قانونية، مالية)، والترجمة التي تتطلب استنتاجاً سياقياً (مثل تحديد الضمائر بناءً على السياق).
س3: هل من المناسب استبدال GPT-4o-mini أو Claude Haiku 4.5 بـ Flash-Lite للترجمة؟
نعم، وغالباً ما يكون أرخص وأسرع. تسعير Gemini 3.1 Flash-Lite التنافسي يجعله خياراً ممتازاً. نوصي باستخدام منصة APIYI لإجراء اختبار A/B بين النماذج الثلاثة باستخدام نفس المفتاح، لتحديد الأنسب لزوج اللغات الخاص بك.
س4: هل يمكن حقاً استخدام نافذة سياق 1M الخاصة بـ Flash-Lite للترجمة؟
نعم، وهي قدرته الأكثر استهانة بها. 1 مليون توكن تعادل تقريباً 300 ألف إلى 400 ألف كلمة عربية، وهو ما يكفي لترجمة كتاب متوسط الطول أو مجموعة كاملة من وثائق الشركات دفعة واحدة. منصة APIYI تدعم نافذة السياق الكاملة لـ Flash-Lite، مما يتيح لك استدعاءها مباشرة.
الخلاصة: نموذج Gemini 3.1 Flash-Lite هو الخيار الأمثل لمهام الترجمة بتكلفة أقل بـ 6 مرات
بالعودة إلى جوهر هذا المقال: في مهام الترجمة ذات الطابع الخفيف والمتكرر، لا يُعد Gemini 3.1 Flash-Lite مجرد "نسخة مخففة" من Gemini 3.5 Flash، بل هو الحل الأمثل الذي صممته جوجل خصيصاً لهذه السيناريوهات. إن انخفاض تكلفة المدخلات والمخرجات بمقدار 6 مرات، وسرعة استجابة الرمز الأول (First Token) الأسرع بـ 2.5 مرة، بالإضافة إلى حصوله على 88.9 نقطة في اختبار MMMLU للغات المتعددة، وتصنيف جوجل الرسمي للترجمة كأحد نقاط قوته الأساسية؛ هي خمس حقائق تؤكد هيمنته المطلقة في مجال الترجمة. فالميزات التي يتفوق بها Gemini 3.5 Flash في مجالات الوكلاء (Agents) والبرمجة لا قيمة لها في مهام الترجمة، وأي تكلفة إضافية تدفعها مقابل تلك القدرات تعتبر هدراً للموارد.
الاستراتيجية الأكثر حكمة هي استخدام نظام توجيه ثنائي للنماذج: اعتمد gemini-3.1-flash-lite-preview لمهام الترجمة، التصنيف، والمراجعة، بينما استخدم gemini-3.5-flash لمهام الوكلاء (Agents)، البرمجة، واسترجاع المعلومات (RAG) من المستندات الطويلة. يمكنك التبديل بينهما بسهولة عبر واجهة برمجة التطبيقات المتوافقة مع OpenAI التي يوفرها موقع APIYI (apiyi.com) تحت مفتاح API واحد. يحصل المستخدمون الجدد على رصيد مجاني بقيمة 0.05 دولار عند التسجيل، وهو ما يكفي لاختبار خط إنتاج ترجمة كامل وقياس نسبة التوفير الحقيقية في تكاليف أعمالك.
الكاتب: الفريق التقني لـ APIYI · apiyi.com
تاريخ النشر: 20 مايو 2026
المراجع: بطاقة نموذج Google DeepMind، مدونة جوجل، LLM-Stats، Artificial Analysis، DevTK، AIMLAPI، معيار Lara للترجمة، Emelia Hub