Claude Opus 4.7 was released on April 16, 2026. Within just two days, community sentiment shifted rapidly from "comprehensive upgrade" to "selective upgrade." The issue isn't with the official benchmarks, but with a conclusion that has been repeatedly verified: Opus 4.7 is an upgrade specifically for "coding Agents," and for all other scenarios, it's a downgrade.
This article cuts straight to the point, answering the real reason why Claude Opus 4.7 isn't durable: Why does the Max Plan 20x quota bar visibly drop faster than it did the day before? Why is long-document RAG performance worse than it was on 4.6? Why do old prompts yield increasingly poor results?
Core Value: After reading this, you'll know exactly which scenarios require an immediate migration to 4.7, which ones should stay on 4.6, and how to use three configuration tweaks to balance cost and quality.

The Core Reason Why Claude Opus 4.7 Isn't Durable
To understand this "lack of durability," we need to distinguish between two things: model capability changes and billing/quota changes. Opus 4.7 has made adjustments in both dimensions, and these adjustments benefit a narrow group—only users who truly leverage Agent capabilities see a net gain, while most daily users end up bearing the costs.
The Real Beneficiaries of the Opus 4.7 Upgrade
Anthropic explicitly stated in their official blog that Opus 4.7 is designed for "scenarios where Opus 4.6 needed hand-holding": long-running Agentic coding workflows, production-level tasks for large multi-file codebases, and computer use.
| Real Beneficiaries | Upgrade Magnitude | Typical Scenarios |
|---|---|---|
| Claude Code Developers | ⭐⭐⭐⭐⭐ | Multi-file refactoring, Agent loops |
| Cursor Users | ⭐⭐⭐⭐⭐ | Real coding tasks within IDE |
| Agentic Toolchain Devs | ⭐⭐⭐⭐ | MCP-Atlas leads all models |
| Visual Document Processing | ⭐⭐⭐⭐ | 3.75 MP high-res parsing |
| Writing/Copywriting Users | ⭐ | Barely noticeable upgrade |
| RAG Long Documents | Downgrade | MRCR 78.3% → 32.2% |
| Web Research/BrowseComp | Downgrade | 83.7% → 79.3% |
| Cybersecurity Related | Downgrade | CyberGym 73.8% → 73.1% |
| Cost-Sensitive Production | Downgrade | Tokenizer expansion 0-35% |
🎯 Migration Advice: If you don't fall into the first four categories but your business requires calling both 4.6 and 4.7, we recommend routing by scenario via the APIYI (apiyi.com) platform. The platform supports a unified interface to call the entire Claude model series, preventing performance regressions caused by a "one-size-fits-all" migration.
Three Fundamental Reasons Why Claude Opus 4.7 "Isn't Durable"
Reason 1: Tokenizer refactoring leads to Token consumption inflation
Opus 4.7 uses a brand-new Tokenizer. The same piece of input text will be split into 1.0 to 1.35 times as many Tokens on 4.7. This multiplier varies significantly depending on the content type:
- Pure English conversation: Close to 1.0×
- Chinese content: 1.1–1.2×
- Code snippets: 1.15–1.25×
- JSON/Structured data: 1.2–1.35×
- Mixed-language scenarios: 1.25–1.35×
Reason 2: Claude Code defaults to the xhigh reasoning tier
With the launch of 4.7, Claude Code raised the default reasoning tier for all plans from "high" to "xhigh." xhigh sits between "high" and "max," consuming more "thinking tokens" for the same task, and this portion of consumption is added directly to your bill.
Reason 3: Max Plan 20x quota is measured by Tokens
Although the Max Plan 20x is nominally "20 times the Pro quota," the underlying limit is essentially based on Tokens rather than the number of requests. When Tokenizer inflation and the default xhigh setting occur simultaneously, the same operations consume your Token balance much faster. Multiple users have reported: when using Opus 4.7 on April 17, the Max Plan quota bar dropped significantly faster than it did when using 4.6 on April 15.
Claude Opus 4.7 Scenario Performance Overview
To determine whether Opus 4.7 is an upgrade or a downgrade for your specific use case, you shouldn't rely solely on the benchmarks cherry-picked by the vendor. This section evaluates the model across seven real-world usage scenarios.

Scenario 1: Coding Agent (Significant Upgrade)
This is where Opus 4.7 truly shines. Multiple data points confirm this:
| Coding Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Opus 4.7 Improvement |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | N/A | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | N/A | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Opus 4.7 achieved 6 wins, 1 draw, and 2 losses against GPT-5.4 across 9 directly comparable benchmarks, reclaiming the title of "Agentic coding champion" from GPT-5.4 for the first time.
🚀 Agent Scenario Recommendation: If you're building production-grade agents, we recommend calling Claude Opus 4.7 directly via the APIYI (apiyi.com) platform. The platform provides an interface fully compatible with the official Claude API, supporting new features like the xhigh tier and Task Budgets.
Scenario 2: Vision Recognition (Transformative Upgrade)
Vision is another area where the upgrade is tangible:
- Max image resolution: 1.15 MP → 3.75 MP (3×)
- Long edge pixels: Expanded from standard to 2576px
- Vision recognition benchmark: 54.5% → 98.5%
For tasks requiring direct interpretation of architectural diagrams, design drafts, PDF scans, or UI screenshots, this is a noticeable leap forward.
Scenario 3: Long-Document RAG (Severe Downgrade)
This is the most common complaint from the community. MRCR (Multi-Round Context Recall) is the standard benchmark for measuring long-context retrieval capabilities:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- Gap: -46.1pt
This figure explains why many developers have reported: "I fed 4.7 an 800-line workflow document; it claimed to have read it, but the generated content had absolutely nothing to do with the document."
If your core business involves long-document Q&A, contract analysis, or large code repository reviews, Opus 4.7 is a clear downgrade. We recommend sticking with 4.6.
Scenario 4: Web Research and BrowseComp (Slight Downgrade)
BrowseComp measures performance in web research tasks:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
For Research Agent scenarios requiring deep web browsing and information synthesis, GPT-5.4 Pro remains the stronger choice, while Opus 4.7 actually underperforms compared to 4.6.
Scenario 5: General Writing and Conversation (Hardly Noticeable)
For daily writing, copywriting, and conversational tasks, the subjective difference between Opus 4.7 and 4.6 is very limited. However, due to tokenizer expansion, your actual token consumption per conversation will be 10-20% higher than in the 4.6 era.
Conclusion: 4.6 is more cost-effective for writing tasks, as the capability upgrades in 4.7 are barely visible here.
Scenario 6: Legacy Prompt Compatibility (Potential Regression)
Opus 4.7's instruction following is more "literal"—it no longer proactively "reads between the lines" as effectively as 4.6. This means:
- Prompts relying on implicit intent may see a drop in output quality.
- With vague instructions like "please help me write it better," 4.7 tends to execute strictly according to the literal meaning.
- You'll need to rewrite implicit constraints into explicit ones (e.g., "limit to 500 words," "must include X element").
If you have a large library of legacy 4.6-era prompts, you'll need to perform systematic regression testing before migrating.
Scenario 7: Cybersecurity (Minor Downgrade)
CyberGym (cybersecurity vulnerability reproduction benchmark):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
Anthropic has acknowledged that this is a trade-off resulting from newly added cybersecurity protection mechanisms. For teams involved in red-teaming or security audits, this is a small but real downgrade.
💡 Scenario Selection Advice: Choosing between Opus 4.7 and 4.6 depends primarily on your specific application scenario and quality requirements. We recommend conducting actual test comparisons via the APIYI (apiyi.com) platform, which supports unified interface calls for various mainstream models, making it easy to switch and verify quickly.
Claude Opus 4.7 Max Plan Usage Breakdown
This section is dedicated to answering the question: "Why is my usage bar draining so much faster?"
Max Plan 20x Usage Mechanism
The Claude Max Plan 20x operates on a token-based measurement system with two core restrictions:
- 5-hour rolling window limit: Prevents excessive usage in short bursts.
- Weekly message cap: Protects overall platform capacity.
Since the launch of Opus 4.7, while the absolute values for these limits haven't changed, the average token consumption per message has risen significantly due to the new Tokenizer and the default xhigh reasoning tier.
Three Sources of Token Inflation
| Inflation Source | Scope of Impact | Estimated Inflation |
|---|---|---|
| New Tokenizer | All inputs | 0% – 35% (varies by content type) |
xhigh default tier |
Reasoning task outputs | 20% – 60% (relative to high) |
| Rigor in problem solving | Agent loops | 10% – 30% (increased step count) |
The real-world experience: when completing the same task in Claude Code, 4.7 consumes 30% – 80% more of your quota than 4.6 did. That’s the mathematical explanation for why your "usage bar" is dropping so quickly.
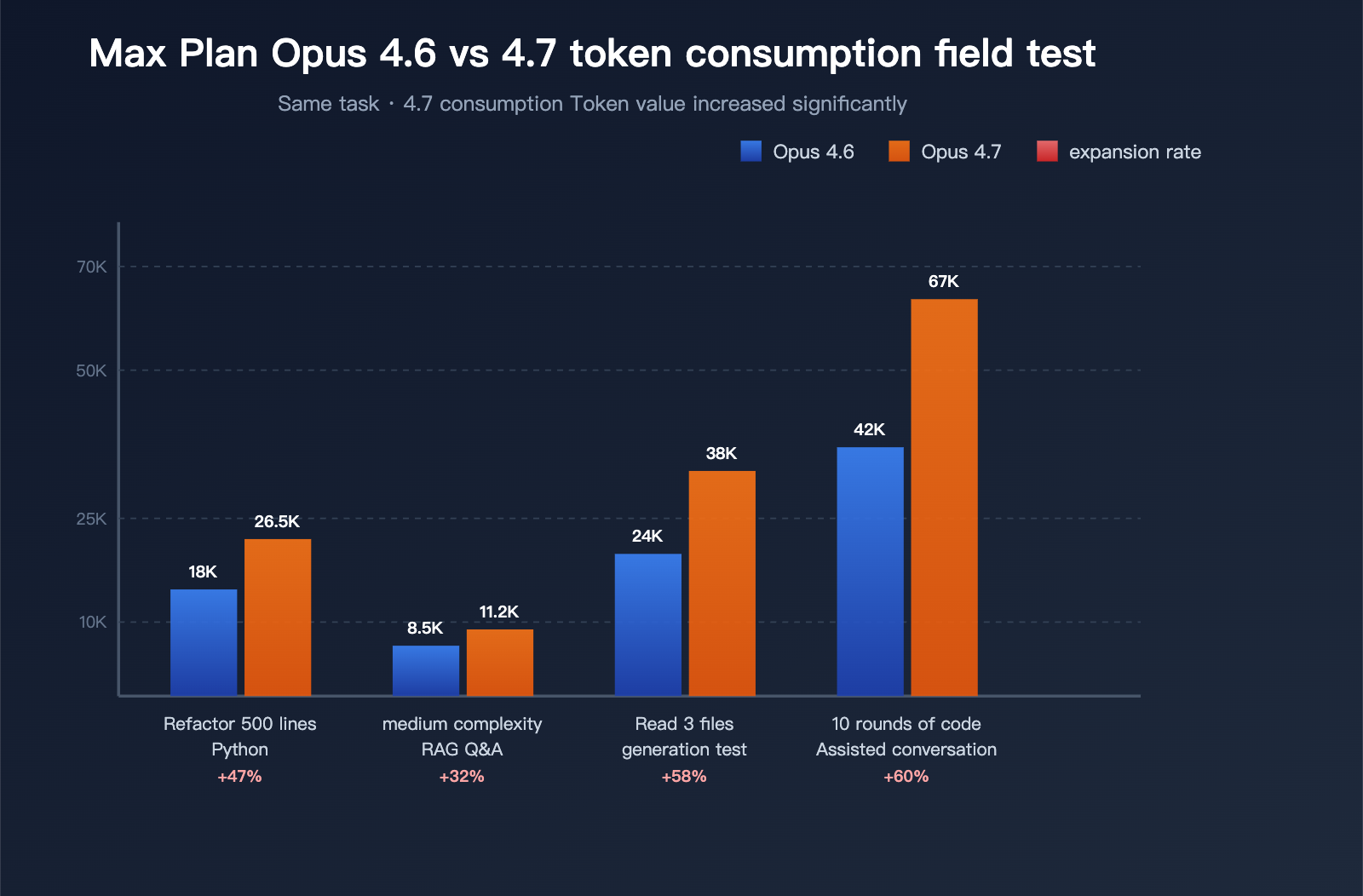
Performance Data (3 Typical Tasks)
Data aggregated from community feedback:
| Test Task | 4.6 Token Usage | 4.7 Token Usage | Inflation |
|---|---|---|---|
| Refactoring a 500-line Python module | ~18,000 | ~26,500 | +47% |
| Answering a moderately complex RAG question | ~8,500 | ~11,200 | +32% |
| Reading 3 files and generating tests | ~24,000 | ~38,000 | +58% |
| 10 rounds of code assistance in a long chat | ~42,000 | ~67,000 | +60% |
This data confirms: Opus 4.7 "burning through quotas" isn't just an illusion; it's a verifiable, systemic shift.
Why does Anthropic say the "price hasn't changed"?
In their release announcement, Anthropic confirmed:
- Input price: $5 / million tokens (unchanged)
- Output price: $25 / million tokens (unchanged)
This is technically true regarding unit prices, but it’s a classic case of "unit price framing" — the price per unit is the same, but the number of tokens required to complete the same task has increased, naturally driving up your final bill. Third-party cost analysis platforms like Finout call this phenomenon the "Real Cost Story Behind the Unchanged Price Tag."
💰 Cost Control Recommendation: For production environments sensitive to token costs, we strongly suggest running a real-traffic billing comparison test via the APIYI (apiyi.com) platform before migrating. The platform offers granular usage analytics and cost reporting, making it easy to quantify how this migration will affect your budget.
Three Ways to Improve Claude Opus 4.7 Efficiency
If you've already upgraded to 4.7 and can't roll back, here are three actionable steps to keep your usage within a manageable range.
Action 1: Manually lower effort to medium or high
Claude Code defaults to xhigh for "most complex coding tasks," but for most daily work, medium or high is more than enough.
Explicitly set this in your API calls:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactor this code"}],
extra_headers={
"reasoning-effort": "medium"
}
)
See token usage comparison by effort level
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Please analyze the performance issues in the following code and provide optimization suggestions.
(Insert 200 lines of Python code here)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Recommendation: Use high for daily coding assistance, medium for simple Q&A, and save xhigh only for extremely complex multi-file refactoring tasks.
Action 2: Route by scenario
Don't use a "one-size-fits-all" approach for upgrading to 4.7. Use a logical routing strategy:
| Business Scenario | Recommended Model | Reason |
|---|---|---|
| Multi-file Agentic coding | Opus 4.7 (xhigh) | Where Agents shine |
| Single-file code generation | Opus 4.7 (high) | Clear upgrade benefits |
| High-res image parsing | Opus 4.7 (high) | Visual quality leap |
| Long-document RAG | Opus 4.6 | Avoids MRCR collapse |
| Web research Agent | GPT-5.4 Pro | Leading BrowseComp performance |
| General writing / Copy | Opus 4.6 or Sonnet | Lower Tokenizer costs |
| Simple chat | Haiku / Sonnet | Best price-performance |
Action 3: Enable Task Budgets to limit single-task consumption
The new Task Budgets (in public beta) for Opus 4.7 are a great tool for controlling Agent loop costs:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Complete the entire refactoring task"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
The model sees the remaining budget in every response and automatically adjusts its strategy—prioritizing core tasks when the budget is tight and delving into details when the budget allows.
🎯 Final Recommendation: For teams sensitive to token budgets, we recommend managing your Claude Opus 4.7 usage via the APIYI (apiyi.com) platform. It provides real-time quota monitoring and multi-model routing capabilities to help you turn the feeling of "draining credits" into a predictable, controllable cost curve.
Claude Opus 4.7 vs. GPT-5.4 xhigh: A Head-to-Head Comparison
A user recently noted: "In my own testing, Opus 4.7 still doesn't seem to measure up to GPT-5.4 xhigh." This is a fair assessment, but it really depends on the specific use case.

9 Direct Benchmarks
| Benchmark | Opus 4.7 | GPT-5.4 | Winner |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Enterprise Knowledge) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Visual Recognition | 98.5% | — | Opus 4.7 |
| BrowseComp (Web Research) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| Long-context RAG | 32.2% | No collapse | GPT-5.4 |
| Token Cost | 1.0–1.35× | Stable | GPT-5.4 |
Opus 4.7 takes 6 wins, 1 draw, and 2 losses out of 9, but for your specific needs, the conclusion might be the exact opposite:
- If your workflow relies heavily on web research (e.g., Research Agents, browser automation), GPT-5.4 xhigh leads by 10 percentage points on BrowseComp.
- If you're doing long-document RAG, GPT-5.4 doesn't suffer from the MRCR collapse issue.
- If you need a stable token cost curve, GPT-5.4's tokenizer remains unchanged.
So, the feeling that "Opus 4.7 doesn't measure up to GPT-5.4 xhigh" is perfectly valid for certain workflows.
Selection Decision Matrix
| Your Core Need | Preferred Model | Alternative |
|---|---|---|
| Multi-file Agentic Coding | Opus 4.7 xhigh | Opus 4.6 |
| Real-world IDE Coding | Opus 4.7 high | GPT-5.4 |
| Research Agent (Web Research) | GPT-5.4 Pro | Opus 4.7 |
| Enterprise Knowledge Q&A | Opus 4.7 | GPT-5.4 |
| Long-document Understanding / RAG | Opus 4.6 | GPT-5.4 |
| High-res Image Understanding | Opus 4.7 | Gemini 3.1 Pro |
| Highly Cost-Sensitive | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Multi-model Deployment Tip: Modern AI applications rarely rely on a single model for everything. We recommend using the APIYI (apiyi.com) platform to integrate Claude, GPT, and Gemini models, allowing you to route requests intelligently based on the scenario. This platform lets you access all major models with a single API key, significantly simplifying your deployment.
Claude Opus 4.7 Durability FAQ
Q1: Is Claude Opus 4.7 really less “durable” than 4.6?
Yes, but you have to look at it from two angles:
-
Quota: It's definitely less durable. The tokenizer expansion (0-35%) plus the default "xhigh" setting in Claude Code leads to a 30-80% increase in token consumption. Users on the Max Plan 20x have reported their quota bars depleting much faster.
-
Capability: It depends on the task. It's clearly stronger for coding agents, vision, and tool use, but weaker or on par for long-document RAG, web research, and general writing.
If you aren't doing those specific agent tasks, Opus 4.7 is essentially just "more expensive" for you.
Q2: Why did Anthropic say “prices haven’t changed” but my bill went up?
They stated that the unit price hasn't changed ($5/million input tokens, $25/million output tokens). However, the new Opus 4.7 tokenizer means the same text consumes 1.0–1.35× more tokens. Combined with the "xhigh" output token inflation, it's common to see bills rise by 20-50% compared to the 4.6 era.
To control costs, use the APIYI (apiyi.com) platform to run real-traffic comparison tests; it supports parallel calls across the entire Claude series and provides detailed billing analytics.
Q3: My Max Plan 20x quota is draining fast. What can I do?
Three immediate actions:
- Lower effort to "high" or "medium": Manually disable the default "xhigh" in your Claude Code settings; "high" is plenty for daily tasks.
- Disable unnecessary thinking steps: For simple questions in long conversations, explicitly tell the model to skip deep reasoning.
- Switch to Sonnet or Opus 4.6 for non-agent tasks: You don't need Opus 4.7 for writing, simple Q&A, or translation.
These three steps can bring your Max Plan consumption back to 4.6-era levels or even lower.
Q4: I’ve already migrated to Opus 4.7. Is it worth rolling back to 4.6?
It depends on your core workflow:
- Mainly doing multi-file agent coding: Don't roll back; 4.7 is genuinely stronger.
- Mainly doing long-document RAG / contract analysis: Roll back to 4.6 immediately to avoid MRCR collapse.
- Mixed scenarios: No need for a full rollback; just route by scenario—use 4.7 for heavy agent tasks and 4.6 or Sonnet for everything else.
Rolling back via API is simple: just change the model parameter from claude-opus-4-7 back to claude-opus-4-6.
Q5: Is Opus 4.7 stronger than GPT-5.4 xhigh in every scenario?
No. Official data shows Opus 4.7 winning 6 out of 9 benchmarks, but the two losses are in critical areas:
- BrowseComp (Web Research): GPT-5.4 Pro 89.3% vs. Opus 4.7 79.3%.
- Long-context RAG: GPT-5.4 doesn't show the same MRCR collapse.
So, if a user says "Opus 4.7 doesn't measure up to GPT-5.4 xhigh," they're likely right—provided their core work is web research or long-document analysis.
Using the APIYI (apiyi.com) platform allows you to call both Claude and GPT in the same project and route based on the scenario, which is the most pragmatic approach right now.
Q6: My old prompts are performing worse on Opus 4.7. What should I do?
This is a side effect of 4.7's more "literal" instruction following. Here are some rewriting tips:
- Turn implicit intent into explicit constraints: Change "Write more professionally" to "Must use industry terminology and avoid colloquialisms."
- Turn vague limits into hard numbers: Change "Don't make it too long" to "Keep it under 300 words."
- Add negative constraints: Tell the model exactly what kind of output is unacceptable.
This takes some effort, so for large prompt libraries, we recommend running A/B tests to identify which prompts actually need rewriting.
Summary of Claude Opus 4.7 Pros and Cons
Real Strengths (Where it truly shines)
- Leap in Coding Agent Capabilities: Hits 64.3% on SWE-bench Pro and 70% on CursorBench, surpassing GPT-5.4.
- Qualitative Shift in Vision: Features 3.75 MP high-resolution input, reaching 98.5% on vision benchmarks.
- Superior MCP-Atlas Toolchain: Achieves 77.3%, leading all other publicly available models.
- More Precise Instruction Following: Outputs are more controllable when using prompts with strict constraints.
- Task Budgets: Enables better cost management for agentic tasks.
Real Limitations (Where it falls short)
- Tokenizer Inflation (0-35%): The "same price" marketing hides the reality of increased actual costs.
- xhigh Default Increases Token Consumption: With the Max Plan, your 20x quota gets eaten up much faster.
- MRCR Long-Context Cliff: Performance drops from 78.3% to 32.2%, making it unreliable for long-document RAG.
- BrowseComp Regression: Loses out to GPT-5.4 Pro in web research scenarios.
- CyberGym Minor Regression: Shows a slight dip in security-related tasks.
- Legacy Prompt Compatibility Issues: Prompts that rely on implicit intent often need a rewrite.
Conclusion
Claude Opus 4.7 is a classic case of a "specialized" upgrade. Every improvement is laser-focused on one goal: reclaiming the crown for Anthropic in the agentic coding arena. It succeeds there, but the trade-off is that users across "all other scenarios" are essentially footing the bill for this upgrade.
If you're building agents, a heavy Claude Code user, or a power user of Cursor, Opus 4.7 is worth migrating to immediately. But if your core workflows involve creative writing, RAG, web research, or cost-sensitive production, here’s our advice:
- Keep using Opus 4.6 for non-agent tasks.
- Lower the default effort in Claude Code from
xhightohigh. - Route tasks across multiple models based on the scenario rather than going all-in on one.
"No price change" is never the whole story. The real cost is hidden in the tokenizer, default settings, and inference depth. Opus 4.7 isn't "bad"—it's just not a general-purpose model. Understanding this distinction is how you'll get the most value out of it.
We recommend using the APIYI (apiyi.com) platform to centrally manage all your Claude model invocations. It offers intelligent multi-model routing, real-time quota monitoring, and a fully official-compatible API, making it the most practical tool for navigating the "specialized" nature of Opus 4.7.
References
-
Anthropic Official Announcement: Official introduction to Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Description: Official capability definitions and recommended use cases.
- Link:
-
Anthropic Official Documentation: Opus 4.7 Migration Guide
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Description: Details on Tokenizer changes and xhigh specifications.
- Link:
-
Finout Cost Analysis: The real cost behind the "Unchanged Price Tag"
- Link:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Description: Third-party cost analysis and bill breakdown.
- Link:
-
Artificial Analysis Benchmark: GPT-5.4 xhigh vs. Claude Opus comparison
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Description: Independent third-party cross-model benchmark data.
- Link:
-
GitHub Issue #23706: Token consumption feedback from Max Plan users
- Link:
github.com/anthropics/claude-code/issues/23706 - Description: First-hand user experience feedback from Claude Code Max Plan users.
- Link:
Author: APIYI Technical Team
Release Date: 2026-04-18
Applicable Models: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Technical Discussion: Feel free to visit APIYI at apiyi.com to get testing credits for various models and experience the real-world differences across different scenarios yourself.