Claude Opus 4.7 вышел 16 апреля 2026 года, и всего за пару дней мнение сообщества о нем сменилось с «полноценного апгрейда» на «выборочное обновление». Проблема не в официальных бенчмарках, а в выводе, который подтверждается повсеместно: Opus 4.7 — это обновление исключительно для «кодящих агентов», для всех остальных сценариев это даунгрейд.
В этой статье мы без лишней воды разберем реальные причины, почему Claude Opus 4.7 кажется «невыносливым»: почему лимиты Max Plan 20x тают на глазах по сравнению с предыдущими днями? Почему RAG с длинными документами работает хуже, чем на 4.6? И почему старые промпты выдают посредственные результаты?
Главная ценность: после прочтения вы будете точно знать, в каких сценариях стоит немедленно переходить на 4.7, в каких — остаться на 4.6, и как с помощью трех настроек вернуть баланс между стоимостью и качеством.

Основные причины «невыносливости» Claude Opus 4.7
Чтобы понять ощущение «невыносливости», нужно различать две вещи: изменение возможностей модели и изменение биллинга/лимитов. Opus 4.7 претерпел изменения в обоих аспектах, причем выгоду от них получили немногие — только те, кто действительно использует возможности агентов, в то время как большинство обычных пользователей столкнулись с ростом затрат.
Кто реально выиграл от обновления Opus 4.7?
В официальном блоге Anthropic прямо указано, что Opus 4.7 создан для сценариев, где «Opus 4.6 требовалась помощь (hand-holding)»: длительные агентные рабочие процессы в кодинге, производственные задачи с большими кодовыми базами из множества файлов, компьютерное использование (computer use) и так далее.
| Группа пользователей | Прирост от Opus 4.7 | Типичные сценарии |
|---|---|---|
| Разработчики Claude Code | ⭐⭐⭐⭐⭐ | Рефакторинг множества файлов, агентные циклы |
| Пользователи Cursor | ⭐⭐⭐⭐⭐ | Реальные задачи кодинга в IDE |
| Разработчики агентных цепочек | ⭐⭐⭐⭐ | MCP-Atlas опережает все модели |
| Обработка документов (Vision) | ⭐⭐⭐⭐ | Разрешение 3.75 MP |
| Копирайтинг/Тексты | ⭐ | Почти незаметно |
| RAG длинных документов | Даунгрейд | MRCR 78.3% → 32.2% |
| Web-исследования/BrowseComp | Даунгрейд | 83.7% → 79.3% |
| Кибербезопасность | Даунгрейд | CyberGym 73.8% → 73.1% |
| Производство (чувствительное к цене) | Даунгрейд | Рост токенизатора на 0-35% |
🎯 Совет по миграции: Если вы не относитесь к первым четырем категориям, но вашему бизнесу нужно использовать и 4.6, и 4.7, рекомендуем использовать платформу APIYI (apiyi.com) для маршрутизации по сценариям. Платформа поддерживает единый интерфейс для вызова всей линейки моделей Claude, что позволяет избежать падения производительности из-за «слепого» перехода.
Три фундаментальные причины «невыносливости» Claude Opus 4.7
Причина 1: Рефакторинг токенизатора привел к раздуванию потребления токенов
В Opus 4.7 используется совершенно новый токенизатор. Тот же самый текст на 4.7 будет разбит на количество токенов, превышающее прежнее в 1.0–1.35 раза. Этот коэффициент заметно варьируется в зависимости от типа контента:
- Чисто английский диалог: близко к 1.0×
- Китайский контент: 1.1–1.2×
- Фрагменты кода: 1.15–1.25×
- JSON/структурированные данные: 1.2–1.35×
- Смешанные языковые сценарии: 1.25–1.35×
Причина 2: Claude Code по умолчанию использует уровень рассуждений xhigh
Одновременно с запуском 4.7, Claude Code повысил уровень рассуждений по умолчанию для всех тарифов с high до xhigh. Уровень xhigh находится между high и max и потребляет больше «токенов размышления» (thinking tokens) для тех же задач, что напрямую отражается в вашем счете.
Причина 3: Лимиты Max Plan 20x рассчитываются по токенам
Хотя Max Plan 20x от Anthropic номинально является «20-кратным лимитом Pro», по сути, ограничение основано на токенах, а не на количестве запросов. Когда одновременно происходит раздувание токенизатора и включение xhigh по умолчанию, одни и те же операции съедают лимиты гораздо быстрее. Многие пользователи отмечают: 17 апреля при использовании Opus 4.7 шкала лимитов Max Plan таяла значительно быстрее, чем 15 апреля при использовании 4.6.
Панорама возможностей Claude Opus 4.7 по сценариям
Чтобы понять, является ли переход на Opus 4.7 апгрейдом или даунгрейдом именно для ваших задач, не стоит полагаться только на официальные бенчмарки. В этом разделе мы разберем 7 реальных сценариев использования.

Сценарий 1: Кодинг-агенты (явный апгрейд)
Это родная стихия Opus 4.7. Множество данных подтверждают это:
| Бенчмарк кодинга | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Прирост Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | не публ. | +6.8 п.п. |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9 п.п. |
| CursorBench | 58% | 70% | не публ. | +12 п.п. |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5 п.п. |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3 п.п. |
В 9 напрямую сравнимых бенчмарках Opus 4.7 одержал 6 побед, 1 ничью и 2 поражения против GPT-5.4, впервые вернув лидерство в области агентского кодинга.
🚀 Рекомендация для агентов: Если вы создаете продакшн-агентов, рекомендуем вызывать Claude Opus 4.7 через платформу APIYI (apiyi.com). Она предоставляет интерфейс, полностью совместимый с официальным API Claude, и поддерживает новые функции, такие как уровни xhigh и Task Budgets.
Сценарий 2: Компьютерное зрение (качественный скачок)
Vision — еще одна область, где произошел реальный апгрейд:
- Макс. разрешение изображений: 1.15 Мп → 3.75 Мп (в 3 раза)
- Длинная сторона: расширена до 2576 пикселей
- Бенчмарк распознавания: 54.5% → 98.5%
Для задач, требующих чтения архитектурных схем, макетов дизайна, сканов PDF или скриншотов UI, это ощутимый качественный сдвиг.
Сценарий 3: RAG по длинным документам (серьезный даунгрейд)
Это самая частая жалоба в сообществе. MRCR (Multi-Round Context Recall) — стандартный бенчмарк для оценки способности модели извлекать информацию из длинного контекста:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- Разрыв: -46.1 п.п.
Эти цифры объясняют, почему многие разработчики жалуются: «Скармливаешь 4.7 документ на 800 строк, она говорит, что прочитала, но генерирует ответ, который вообще не связан с документом».
Если ваш основной бизнес — это ответы по длинным документам, анализ контрактов или аудит огромных кодовых баз, Opus 4.7 — это явный даунгрейд, рекомендуем оставаться на 4.6.
Сценарий 4: Веб-исследования и BrowseComp (небольшой даунгрейд)
BrowseComp оценивает эффективность выполнения задач по поиску в сети:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
В сценариях Research Agent, требующих глубокого серфинга и синтеза информации, GPT-5.4 Pro остается более сильным выбором, а Opus 4.7 проигрывает даже версии 4.6.
Сценарий 5: Обычное письмо и диалоги (почти незаметно)
Для повседневных задач, написания текстов и общения субъективная разница между Opus 4.7 и 4.6 минимальна. Однако из-за расширения токенизатора каждое ваше сообщение будет потреблять на 10–20% больше токенов, чем в эпоху 4.6.
Вывод: для копирайтинга 4.6 выгоднее, так как в 4.7 здесь почти нет прироста возможностей.
Сценарий 6: Совместимость со старыми промптами (потенциальный откат)
Инструкции в Opus 4.7 стали более «буквальными» — модель больше не пытается «читать между строк», как это делала 4.6. Это значит, что:
- Промпты, опирающиеся на скрытые намерения, могут давать худший результат.
- На расплывчатые команды вроде «помоги написать получше» 4.7 реагирует строго буквально.
- Скрытые ограничения нужно переписывать в явные (например, «лимит 500 слов», «обязательно включить элемент X»).
Если у вас накоплена большая база промптов времен 4.6, перед миграцией обязательно проведите системное регрессионное тестирование.
Сценарий 7: Кибербезопасность (небольшой даунгрейд)
CyberGym (бенчмарк воспроизведения уязвимостей):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
Anthropic официально признала, что это цена внедрения новых механизмов защиты. Для команд, занимающихся ред-тимингом и аудитом безопасности, это небольшой, но реальный даунгрейд.
💡 Совет по выбору: Выбор между Opus 4.7 и 4.6 зависит от ваших задач. Рекомендуем провести тестирование через платформу APIYI (apiyi.com), которая поддерживает единый интерфейс для множества моделей, что упрощает быстрое переключение и проверку.
Практический анализ расхода лимитов Claude Opus 4.7 Max Plan
Этот раздел посвящен ответу на вопрос: «Почему полоска лимитов тает на глазах?»
Механизм расхода лимитов Max Plan 20x
Claude Max Plan 20x работает на основе учета токенов, где ключевыми являются два ограничения:
- Скользящее окно на 5 часов: защита от чрезмерного количества вызовов за короткий промежуток времени.
- Недельный лимит сообщений: общий контроль использования.
После запуска Opus 4.7 абсолютные значения этих лимитов не изменились, однако из-за нового токенизатора и настроек уровня xhigh средний расход токенов на каждое сообщение заметно вырос.
Три источника «раздувания» расхода токенов
| Источник | Область влияния | Оценочный рост |
|---|---|---|
| Новый токенизатор | Все входящие данные | 0% – 35% (зависит от типа контента) |
| Уровень xhigh по умолчанию | Вывод в задачах рассуждения | 20% – 60% (относительно high) |
| Более строгий подход к решению | Циклы агента | 10% – 30% (увеличение шагов) |
В совокупности это дает ощутимый результат: при выполнении одной и той же задачи в Claude Code, версия 4.7 потребляет на 30% – 80% больше лимитов, чем 4.6. Это математическое объяснение того, почему «полоска здоровья» тает на глазах.
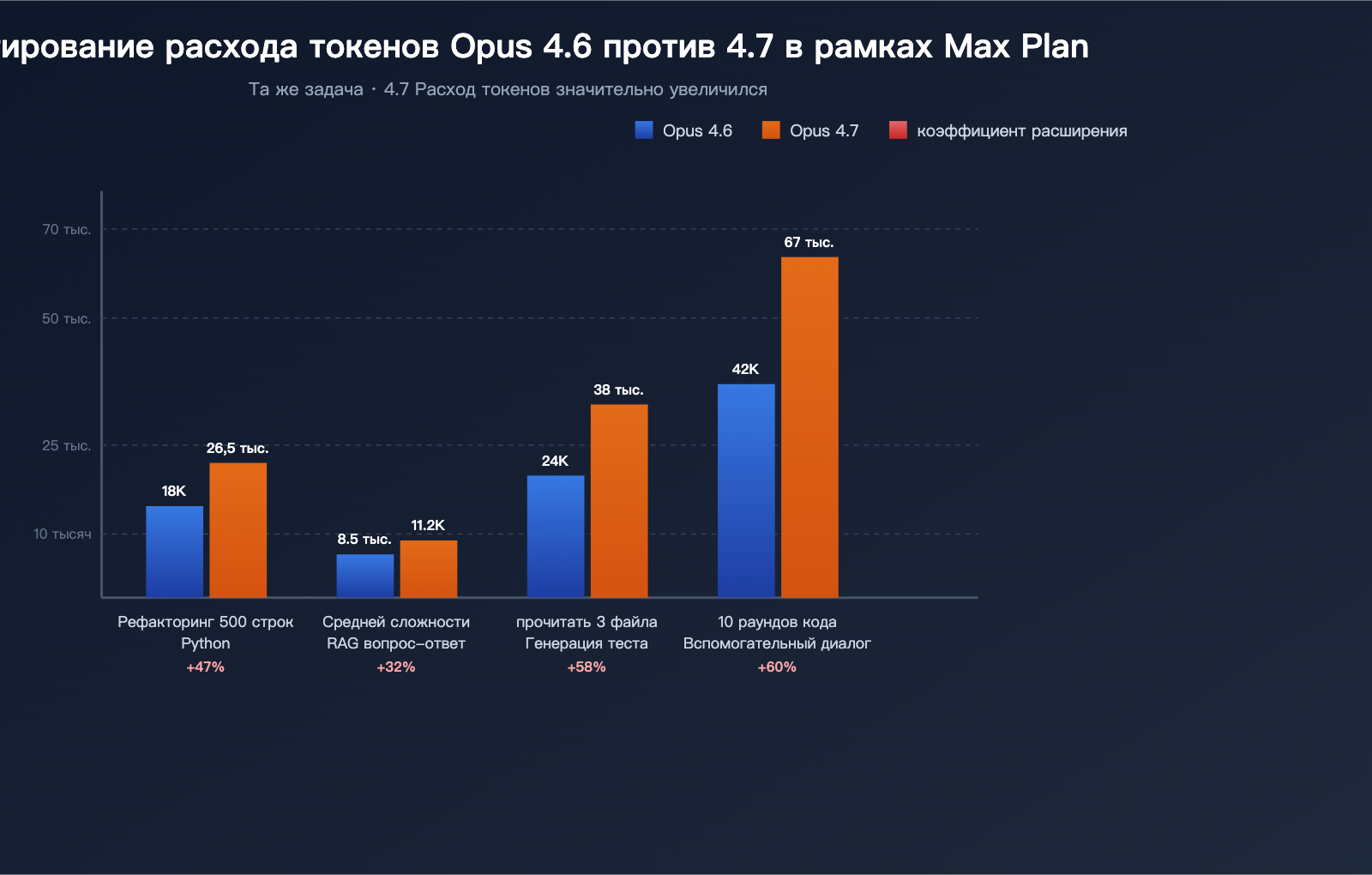
Результаты тестов (3 типичные задачи)
Данные на основе отзывов сообщества:
| Тестовая задача | Расход токенов 4.6 | Расход токенов 4.7 | Рост |
|---|---|---|---|
| Рефакторинг Python-модуля (500 строк) | ~18,000 | ~26,500 | +47% |
| Ответ на RAG-вопрос средней сложности | ~8,500 | ~11,200 | +32% |
| Анализ 3 файлов и генерация тестов | ~24,000 | ~38,000 | +58% |
| 10 раундов помощи с кодом в длинном диалоге | ~42,000 | ~67,000 | +60% |
Эти данные подтверждают: «недолговечность» Opus 4.7 — это не иллюзия, а системное изменение, которое можно измерить.
Почему Anthropic утверждает, что «цены не изменились»?
В официальном анонсе Anthropic четко указано:
- Цена на вход: $5 / млн токенов (без изменений)
- Цена на выход: $25 / млн токенов (без изменений)
На уровне единичных расценок это правда, но это классический «маркетинговый трюк»: цена за единицу осталась прежней, но количество токенов, необходимых для выполнения той же задачи, увеличилось, что неизбежно ведет к росту итогового счета. Сторонние платформы для анализа затрат, такие как Finout, называют это явление «Реальная история стоимости за неизменным ценником».
💰 Совет по оптимизации затрат: Если вы чувствительны к стоимости токенов в продакшене, настоятельно рекомендуем провести сравнительный тест на реальном трафике через платформу APIYI (apiyi.com) перед миграцией. Платформа поддерживает детальную статистику вызовов и анализ затрат, что позволяет количественно оценить реальное влияние миграции на ваш бюджет.
Три способа оптимизации расходов на Claude Opus 4.7
Если вы уже обновились до версии 4.7 или пока не можете откатиться назад, вот три способа, которые помогут вернуть потребление лимитов в разумные рамки.
Способ 1: Вручную снижаем effort до medium или high
Claude Code использует xhigh по умолчанию для «максимально сложных задач программирования», но для большинства повседневных дел режима medium или high вполне достаточно.
Явно укажите это при вызове API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Перепиши этот код"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Посмотрите реальное сравнение потребления токенов для разных уровней effort
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Проанализируй производительность приведенного ниже кода и дай рекомендации по оптимизации.
(Здесь вставлено 200 строк Python-кода)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Совет: для повседневной помощи с кодом используйте high; для простых вопросов — medium; xhigh включайте только при крайне сложной работе с множеством файлов.
Способ 2: Маршрутизация моделей по сценариям
Не пытайтесь «подсадить» все процессы на 4.7. Разумная стратегия выглядит так:
| Сценарий | Рекомендуемая модель | Причина |
|---|---|---|
| Агентная разработка (много файлов) | Opus 4.7 (xhigh) | Родная стихия агента |
| Генерация кода (один файл) | Opus 4.7 (high) | Ощутимый прирост качества |
| Анализ изображений высокого разрешения | Opus 4.7 (high) | Качественный скачок в зрении |
| RAG по длинным документам | Opus 4.6 | Избегаем «провалов» MRCR |
| Web-исследовательский агент | GPT-5.4 Pro | Лидерство в BrowseComp |
| Обычный текст / копирайтинг | Opus 4.6 или Sonnet | Выгоднее по токенам |
| Простые диалоги | Haiku / Sonnet | Лучшее соотношение цены и качества |
Способ 3: Настройка Task Budgets для ограничения расхода
Новая функция Task Budgets (бета-тест) в Opus 4.7 — отличный инструмент для контроля стоимости агентских циклов:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Выполни всю задачу рефакторинга"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
Модель видит остаток бюджета в каждом ответе и автоматически адаптирует стратегию: при нехватке токенов она сфокусируется на главном, при избытке — проработает детали.
🎯 Комплексный совет: Командам, чувствительным к бюджету токенов, рекомендуем централизованно управлять вызовами Claude Opus 4.7 через платформу APIYI apiyi.com. Она предоставляет мониторинг лимитов в реальном времени и интеллектуальную маршрутизацию, превращая «непредсказуемые траты» в прозрачную кривую расходов.
Claude Opus 4.7 против GPT-5.4 xhigh: сравнение
В отзывах пользователей часто звучит: «По моим тестам Opus 4.7 все еще уступает GPT-5.4 xhigh». Это суждение справедливо, но зависит от сценария.

Девять ключевых бенчмарков
| Бенчмарк | Opus 4.7 | GPT-5.4 | Лидер |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Корп. знания) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Распознавание изображений | 98.5% | — | Opus 4.7 |
| BrowseComp (Web-исследования) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG (длинный контекст) | 32.2% | без сбоев | GPT-5.4 |
| Стоимость токенов | 1.0–1.35× | стабильно | GPT-5.4 |
Opus 4.7 выигрывает в 6 из 9 категорий, но в конкретных задачах выводы могут быть иными:
- Если ваш сценарий завязан на web-исследования (например, Research Agent или автоматизация браузера), GPT-5.4 xhigh действительно обходит соперника на 10%.
- Если вы работаете с RAG длинных документов, у GPT-5.4 нет проблем с MRCR-провалами.
- Если вы ищете стабильность затрат, то Tokenizer в GPT-5.4 не менялся.
Поэтому ощущение «Opus 4.7 хуже, чем GPT-5.4» вполне оправдано для определенных рабочих процессов.
Матрица выбора модели
| Ваша задача | Лучший выбор | Альтернатива |
|---|---|---|
| Агентная разработка (много файлов) | Opus 4.7 xhigh | Opus 4.6 |
| Реальное кодирование в IDE | Opus 4.7 high | GPT-5.4 |
| Исследовательский агент (Web) | GPT-5.4 Pro | Opus 4.7 |
| Ответы по корпоративным знаниям | Opus 4.7 | GPT-5.4 |
| Понимание длинных документов / RAG | Opus 4.6 | GPT-5.4 |
| Анализ изображений высокого разрешения | Opus 4.7 | Gemini 3.1 Pro |
| Максимальная экономия | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Рекомендация по мультимодельному подходу: Современные AI-приложения требуют гибкости. Мы советуем использовать платформу APIYI apiyi.com для унифицированного доступа к Claude, GPT и Gemini. Один API-ключ для всех основных моделей значительно упрощает интеграцию и позволяет легко переключаться между ними в зависимости от задачи.
FAQ: Почему Claude Opus 4.7 кажется «недолговечным»?
Q1: Действительно ли Claude Opus 4.7 менее «вынослив», чем 4.6?
Да, но термин «недолговечность» стоит рассматривать в двух аспектах:
-
Лимиты: Да, это так. Токенизатор расширился на 0–35%, а использование режима
xhighпо умолчанию в Claude Code привело к росту потребления токенов на 30–80%. Пользователи с подпиской Max Plan 20x массово отмечают, что лимиты расходуются гораздо быстрее. -
Возможности: Зависит от сценария. В задачах с использованием кодинг-агентов, зрения (Vision) и инструментов (Tool Use) модель стала заметно сильнее. Однако в задачах RAG по длинным документам, веб-исследованиях и обычном написании текстов она либо слабее, либо на том же уровне.
Если вы не используете эти специфические агентские задачи, то для вас Opus 4.7 — это просто «дороже».
Q2: Почему Anthropic заявляет, что «цены не изменились», а мой счет вырос?
Официально заявлено, что цена за единицу осталась прежней: $5 за миллион входных токенов и $25 за миллион выходных. Но новый токенизатор Opus 4.7 заставляет тот же текст потреблять в 1.0–1.35 раза больше токенов, а с учетом роста выходных токенов в режиме xhigh, итоговый счет часто оказывается на 20–50% выше, чем во времена 4.6.
Чтобы контролировать расходы, вы можете провести реальное тестирование трафика через платформу APIYI (apiyi.com), которая поддерживает параллельные вызовы всей линейки Claude и предоставляет детальную статистику затрат.
Q3: Лимиты Max Plan 20x тают на глазах. Что можно сделать?
Три действия, которые можно предпринять прямо сейчас:
- Снизить effort до high или medium: В настройках Claude Code вручную отключите
xhighпо умолчанию — для повседневных задачhighвполне достаточно. - Отключить ненужные этапы размышлений: В длинных диалогах при решении простых задач явно просите модель пропускать глубокие рассуждения.
- Переключиться на Sonnet или Opus 4.6 для неагентских задач: Для написания текстов, простых ответов и переводов Opus 4.7 не нужен.
Эти три шага помогут вернуть расход лимитов Max Plan к уровню времен 4.6 или даже ниже.
Q4: Я уже перешел на Opus 4.7, стоит ли откатываться на 4.6?
Зависит от вашего основного рабочего процесса:
- Если вы в основном занимаетесь кодингом через мультифайловые агенты: Не откатывайтесь, 4.7 действительно сильнее.
- Если вы работаете с длинными документами (RAG) или анализом контрактов: Немедленно откатывайтесь на 4.6, так как показатель MRCR сильно просел.
- Смешанные сценарии: Не обязательно откатываться полностью — просто используйте маршрутизацию по задачам: для тяжелых агентских задач — 4.7, для остального — 4.6 или Sonnet.
В API-вызовах откат делается просто: достаточно изменить параметр model с claude-opus-4-7 на claude-opus-4-6.
Q5: Всегда ли Opus 4.7 сильнее, чем GPT-5.4 xhigh?
Нет. Официальные данные показывают, что в 9 прямых сравнительных тестах Opus 4.7 одержал 6 побед при 1 ничьей и 2 поражениях, но проиграл именно в критических сценариях:
- BrowseComp (веб-исследования): GPT-5.4 Pro 89.3% против Opus 4.7 79.3%.
- RAG с длинным контекстом: У GPT-5.4 не наблюдается такого же падения MRCR.
Поэтому слова пользователей о том, что «в моих тестах Opus 4.7 все еще уступает GPT-5.4 xhigh», вполне могут быть правдой, если ваша основная задача — веб-поиск или работа с длинными документами.
Использование платформы APIYI (apiyi.com) для одновременного вызова Claude и GPT в рамках одного проекта с маршрутизацией по сценариям — на данный момент самый прагматичный подход.
Q6: Старые промпты выдают худший результат на Opus 4.7. Что делать?
Это побочный эффект того, что 4.7 стал «буквальнее» следовать инструкциям. Принципы переработки:
- Превращайте скрытые намерения в явные ограничения: Вместо «пиши профессиональнее» — «обязательно используй отраслевую терминологию, избегай разговорных выражений».
- Заменяйте размытые ограничения на конкретные цифры: Вместо «не слишком длинно» — «не более 300 слов».
- Добавляйте ограничения через примеры того, что делать нельзя.
Работа предстоит немалая. Для больших библиотек промптов рекомендую сначала провести A/B тестирование, чтобы понять, какие именно промпты требуют правок.
Итоги: Плюсы и минусы Claude Opus 4.7
Реальные преимущества (в чем он силен)
- Скачок в способностях кодинг-агентов: SWE-bench Pro 64.3%, CursorBench 70% — превосходит GPT-5.4.
- Качественный сдвиг в Vision: разрешение 3.75 Мп, визуальные тесты на уровне 98.5%.
- Лучшая поддержка инструментов MCP-Atlas: 77.3%, лидер среди всех публичных моделей.
- Более точное следование инструкциям: для промптов с четкими ограничениями результат более предсказуем.
- Task Budgets: позволяют лучше управлять расходами агентов.
Реальные ограничения (в чем он слаб)
- Расширение токенизатора на 0–35%: маркетинговые заявления о ценах маскируют реальный рост затрат.
- Режим xhigh по умолчанию: увеличивает потребление выходных токенов, что делает лимиты Max Plan 20x значительно более «тесными».
- Провал в длинном контексте (MRCR): падение с 78.3% до 32.2%, RAG по длинным документам стал непригоден.
- Откат в BrowseComp: проигрывает GPT-5.4 Pro в веб-исследованиях.
- Небольшой регресс в CyberGym: задачи, связанные с безопасностью, стали чуть хуже.
- Проблемы совместимости со старыми промптами: промпты, полагающиеся на скрытые намерения, требуют переписывания.
Резюме
Claude Opus 4.7 — это классический пример обновления с «узкой специализацией». Все улучшения направлены на одну цель: вернуть Anthropic лидерство в области агентного программирования (Agentic coding). С этой задачей модель справилась, но ценой стало то, что пользователи «всех остальных сценариев» фактически оплачивают этот апгрейд из своего кармана.
Если вы занимаетесь разработкой агентов, активно используете Claude Code или глубоко интегрированы в экосистему Cursor, переход на Opus 4.7 оправдан. Однако, если ваши основные задачи — это написание текстов, RAG, веб-исследования или вы чувствительны к стоимости продакшена, рекомендуем следующее:
- Оставьте Opus 4.6 для задач, не связанных с агентами.
- Снизьте уровень
effortв Claude Code сxhighдоhigh. - Используйте маршрутизацию моделей в зависимости от задачи, не переходите на одну модель для всего.
Фраза «цена не изменилась» — это еще не вся история. Реальные расходы скрыты в токенизаторе, настройках по умолчанию и глубине рассуждений. Opus 4.7 не плоха, она просто не универсальна — осознав это, вы сможете использовать её максимально эффективно.
Рекомендуем использовать платформу APIYI (apiyi.com) для централизованного управления вызовами моделей Claude. Платформа предлагает интеллектуальную маршрутизацию, мониторинг лимитов в реальном времени и API, полностью совместимый с официальным. Это самое практичное решение для адаптации к «узкой специализации» Opus 4.7.
Справочные материалы
-
Официальный анонс Anthropic: Представление Claude Opus 4.7
- Ссылка:
anthropic.com/news/claude-opus-4-7 - Описание: Официальное определение возможностей и рекомендуемые сценарии использования.
- Ссылка:
-
Официальная документация Anthropic: Руководство по миграции на Opus 4.7
- Ссылка:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Описание: Изменения в токенизаторе и пояснения по режиму
xhigh.
- Ссылка:
-
Анализ затрат от Finout: Реальная стоимость за неизменным ценником
- Ссылка:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Описание: Сторонний анализ затрат и разбор счетов.
- Ссылка:
-
Сравнительный обзор от Artificial Analysis: GPT-5.4 xhigh против Claude Opus
- Ссылка:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Описание: Независимые данные сравнительного тестирования различных моделей.
- Ссылка:
-
GitHub Issue #23706: Отзывы пользователей Max Plan о расходе токенов
- Ссылка:
github.com/anthropics/claude-code/issues/23706 - Описание: Реальные отзывы пользователей Claude Code Max Plan.
- Ссылка:
Автор: Техническая команда APIYI
Дата публикации: 18.04.2026
Применимые модели: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Техническое сообщество: Приглашаем получить тестовые лимиты для разных моделей через APIYI (apiyi.com), чтобы лично оценить реальную разницу в различных сценариях.