O Claude Opus 4.7 foi lançado em 16 de abril de 2026 e, em apenas dois dias, a percepção da comunidade mudou drasticamente de "atualização completa" para "atualização seletiva". O problema não está nos benchmarks oficiais, mas em uma conclusão validada repetidamente: o Opus 4.7 é uma atualização feita apenas para "Agentes de codificação", sendo um retrocesso para todos os outros cenários.
Este artigo vai direto ao ponto e responde à verdadeira razão pela qual o Claude Opus 4.7 não é durável: por que a barra de limite do Max Plan 20x cai visivelmente mais rápido do que no dia anterior? Por que cenários de RAG com documentos longos estão, na verdade, piores do que no 4.6? Por que comandos antigos (prompts) trazem resultados cada vez piores?
Valor central: Ao terminar este artigo, você saberá exatamente em quais cenários deve migrar imediatamente para o 4.7, em quais deve permanecer no 4.6 e como usar três ações de configuração para equilibrar custo e qualidade.
O motivo central do Claude Opus 4.7 não ser durável
Para entender essa sensação de "falta de durabilidade", precisamos distinguir duas coisas: mudança na capacidade do modelo e mudança na cobrança/limites. O Opus 4.7 fez ajustes em ambos os eixos, e esses ajustes beneficiam um grupo restrito — apenas os usuários que realmente utilizam a capacidade de "Agente" obtiveram um ganho positivo, enquanto a maioria dos usuários cotidianos acabou arcando com o custo.
O verdadeiro grupo beneficiado pela atualização do Opus 4.7
A Anthropic deixou claro em seu blog oficial que o Opus 4.7 foi projetado para "cenários onde o Opus 4.6 precisava de ajuda (hand-holding)": fluxos de trabalho de codificação agentica de longa duração, tarefas de nível de produção em bases de código com múltiplos arquivos, uso de computador (computer use), entre outros.
| Grupo realmente beneficiado | Nível de atualização do Opus 4.7 | Cenário típico |
|---|---|---|
| Desenvolvedores Claude Code | ⭐⭐⭐⭐⭐ | Refatoração de múltiplos arquivos, loops de Agente |
| Usuários do Cursor | ⭐⭐⭐⭐⭐ | Tarefas reais de codificação dentro da IDE |
| Desenvolvimento de cadeia de ferramentas Agentic | ⭐⭐⭐⭐ | MCP-Atlas supera todos os modelos |
| Processamento de documentos visuais | ⭐⭐⭐⭐ | Resolução de 3.75 MP de alta definição |
| Usuários de escrita/copywriting | ⭐ | Atualização quase imperceptível |
| RAG de documentos longos | Retrocesso | MRCR 78.3% → 32.2% |
| Pesquisa Web/BrowseComp | Retrocesso | 83.7% → 79.3% |
| Relacionado à cibersegurança | Retrocesso | CyberGym 73.8% → 73.1% |
| Produção sensível a custos | Retrocesso | Expansão do Tokenizer 0-35% |
🎯 Sugestão de migração: Se você não pertence aos quatro primeiros grupos, mas seu negócio precisa invocar o 4.6 e o 4.7 simultaneamente, recomendamos o roteamento por cenário através da plataforma APIYI (apiyi.com). A plataforma suporta uma interface unificada para invocar toda a série de modelos Claude, evitando a queda de desempenho causada por uma migração "única para todos".
Três razões fundamentais para o Claude Opus 4.7 "não ser durável"
Razão 1: A refatoração do Tokenizer leva à expansão do consumo de tokens
O Opus 4.7 usa um Tokenizer totalmente novo. O mesmo trecho de texto de entrada será segmentado em 1,0 a 1,35 vezes mais tokens no 4.7. Essa taxa varia significativamente dependendo do tipo de conteúdo:
- Conversa puramente em inglês: próximo de 1,0×
- Conteúdo em chinês: 1,1–1,2×
- Trechos de código: 1,15–1,25×
- JSON/Dados estruturados: 1,2–1,35×
- Cenários multilingues mistos: 1,25–1,35×
Razão 2: Claude Code ativa o nível de raciocínio xhigh por padrão
Ao mesmo tempo em que lançou o 4.7, o Claude Code elevou o nível de raciocínio padrão de todos os planos de "high" para "xhigh". O xhigh fica entre o "high" e o "max", consumindo mais "tokens de pensamento" (thinking tokens) na mesma tarefa, e essa parte do consumo é contabilizada diretamente na sua fatura.
Razão 3: O limite do Max Plan 20x é medido por tokens
Embora o Max Plan 20x da Anthropic seja nominalmente um "limite 20 vezes maior que o Pro", a essência do limite subjacente é baseada em tokens, não em número de solicitações. Quando a expansão do Tokenizer e o padrão xhigh ocorrem simultaneamente, a mesma operação consome a conta de tokens muito mais rápido. Vários usuários relataram: ao usar o Opus 4.7 em 17 de abril, a barra de limites do Max Plan caiu visivelmente mais rápido do que ao usar o 4.6 em 15 de abril.
Panorama do desempenho do Claude Opus 4.7 por cenário
Para decidir se o Opus 4.7 é um upgrade ou um downgrade para o seu caso de uso, não basta olhar apenas para os benchmarks escolhidos pela fabricante. Esta seção avalia o modelo um a um, com base em 7 cenários de uso real.

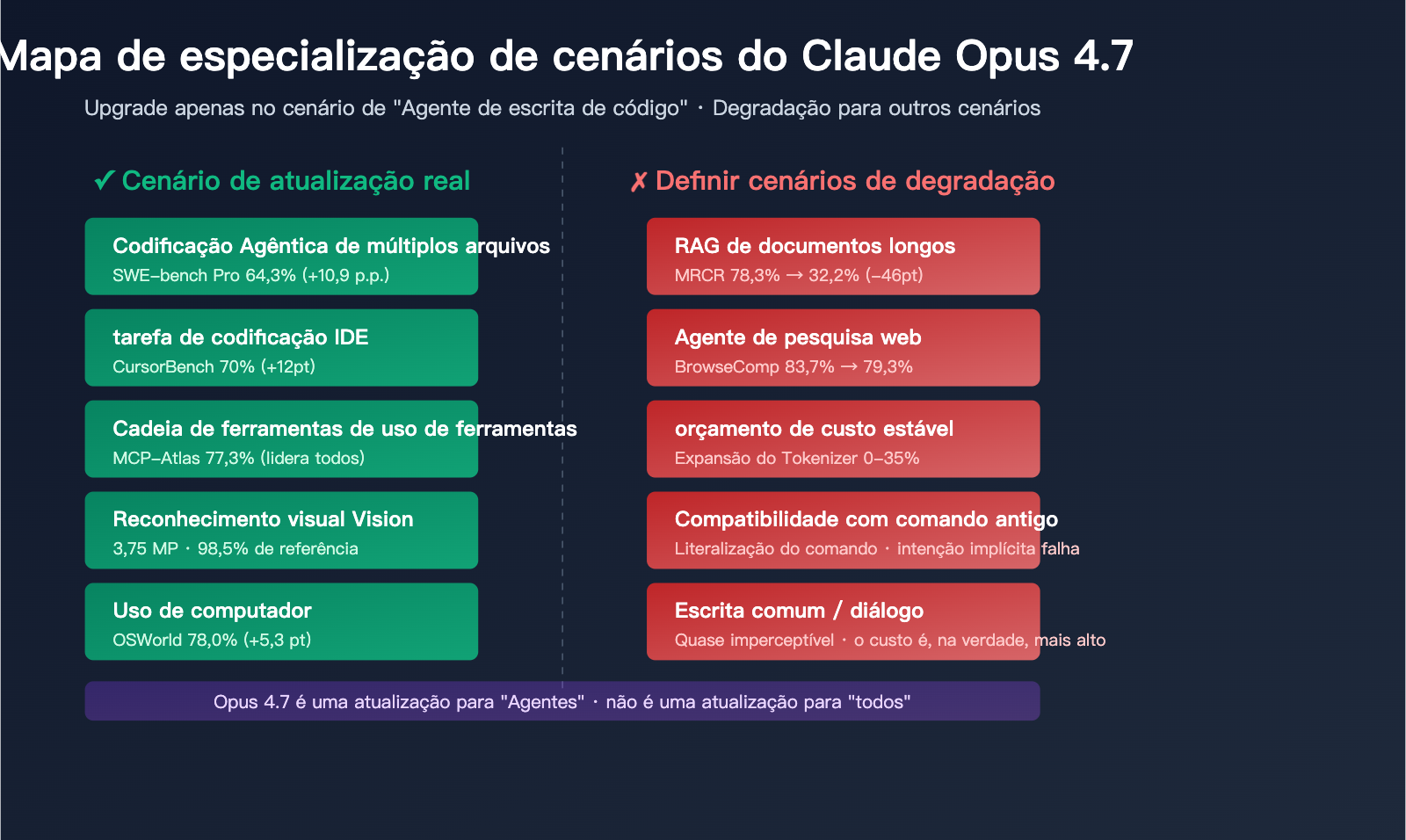
Cenário 1: Agente de codificação (Upgrade claro)
Este é o terreno onde o Opus 4.7 brilha. Vários dados confirmam isso:
| Benchmark de Código | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Melhoria Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | Não divulgado | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | Não divulgado | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Em 9 benchmarks comparáveis diretamente, o Opus 4.7 obteve 6 vitórias, 1 empate e 2 derrotas contra o GPT-5.4, retomando pela primeira vez o título de campeão em codificação com agentes.
🚀 Recomendação para Agentes: Se você está construindo agentes de nível de produção, recomendo realizar a invocação do modelo Claude Opus 4.7 diretamente pela plataforma APIYI (apiyi.com). A plataforma oferece interfaces totalmente compatíveis com o Claude oficial, suportando novos recursos como o nível xhigh e orçamentos de tarefa (Task Budgets).
Cenário 2: Visão e reconhecimento visual (Upgrade qualitativo)
A visão é outro cenário de upgrade real:
- Resolução máxima de imagem: 1.15 MP → 3.75 MP (3×)
- Pixels no lado mais longo: de uma extensão comum para 2576px
- Benchmark de reconhecimento visual: 54.5% → 98.5%
Para cenários que exigem a leitura direta de diagramas de arquitetura, rascunhos de design, PDFs digitalizados e capturas de tela de UI, esta é uma mudança perceptível.
Cenário 3: RAG de documentos longos (Downgrade severo)
Esta é a reclamação mais comum da comunidade. O MRCR (Multi-Round Context Recall) é o benchmark padrão para medir a capacidade de recuperação em contextos longos:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- Diferença: -46.1pt
Este número explica por que vários desenvolvedores relataram: "Forneci ao 4.7 um documento de fluxo de trabalho de 800 linhas; ele disse que leu, mas o conteúdo gerado não tinha absolutamente nada a ver com o documento."
Se o seu negócio principal envolve perguntas e respostas sobre documentos longos, análise de contratos ou revisão de grandes bases de código, o Opus 4.7 é claramente um downgrade; recomendo manter o 4.6.
Cenário 4: Pesquisa Web e BrowseComp (Downgrade leve)
O BrowseComp mede o desempenho em tarefas de pesquisa na Web:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
Em cenários de Agentes de Pesquisa que exigem navegação profunda na Web e síntese de informações, o GPT-5.4 Pro continua sendo a escolha mais forte, enquanto o Opus 4.7 acaba sendo inferior até mesmo ao 4.6.
Cenário 5: Escrita comum e conversação (Quase imperceptível)
Para tarefas diárias de escrita, geração de textos e conversação, as diferenças subjetivas entre o Opus 4.7 e o 4.6 são muito limitadas. No entanto, devido à expansão do tokenizador, cada conversa sua consumirá, na prática, de 10% a 20% mais tokens do que na era do 4.6.
Conclusão: O 4.6 é mais econômico para cenários de escrita, já que o upgrade de capacidade do 4.7 quase não é visto aqui.
Cenário 6: Compatibilidade com comandos antigos (Potencial retrocesso)
A obediência a comandos (instruções) do Opus 4.7 é mais "literal" — ele não tenta mais "ler nas entrelinhas" como o 4.6. Isso significa que:
- Comandos que dependem de intenções implícitas terão uma queda na qualidade da saída.
- Com comandos vagos, como "por favor, ajude-me a escrever melhor", o 4.7 tende a executar estritamente o que foi pedido ao pé da letra.
- É necessário reescrever restrições implícitas em restrições explícitas (como "limite de 500 palavras", "deve conter o elemento X").
Se você possui uma vasta biblioteca de comandos da era 4.6, precisará realizar testes de regressão sistemáticos antes de migrar.
Cenário 7: Segurança cibernética (Downgrade leve)
CyberGym (benchmark de reprodução de vulnerabilidades de segurança cibernética):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
A Anthropic admitiu oficialmente que este é o custo dos novos mecanismos de proteção de segurança cibernética adicionados. Para equipes que trabalham com Red Teaming e auditorias de segurança, este é um downgrade pequeno, porém real.
💡 Sugestão de seleção de cenário: Escolher entre o Opus 4.7 ou 4.6 depende principalmente do seu caso de uso específico e dos requisitos de qualidade. Recomendamos realizar testes comparativos práticos através da plataforma APIYI (apiyi.com), que suporta a invocação unificada de vários modelos principais, facilitando a troca e a validação rápida.
Análise prática do consumo de cota do Claude Opus 4.7 Max Plan
Esta seção responde especificamente à pergunta: "Por que a barra de vida está diminuindo mais rápido?"
Mecanismo de consumo de cota do Max Plan 20x
O Max Plan do Claude é medido internamente por tokens, com dois limites principais:
- Limite de janela deslizante de 5 horas: para evitar chamadas excessivas em curtos períodos.
- Limite semanal de mensagens: proteção geral de uso.
Após o lançamento do Opus 4.7, os valores absolutos desses limites permaneceram os mesmos, mas devido ao novo Tokenizer e ao nível padrão "xhigh", o consumo médio de tokens por mensagem aumentou significativamente.
Três fontes de inflação no consumo de tokens
| Fonte de inflação | Escopo de impacto | Taxa de inflação estimada |
|---|---|---|
| Novo Tokenizer | Todas as entradas | 0% – 35% (depende do tipo de conteúdo) |
| Nível padrão xhigh | Saída de tarefas de raciocínio | 20% – 60% (em relação ao high) |
| Resolução de problemas mais rigorosa | Ciclos de Agente | 10% – 30% (aumento no número de passos) |
A sensação real após a combinação desses três fatores: ao concluir o mesmo trabalho no Claude Code, a versão 4.7 consome de 30% a 80% a mais de cota do que a 4.6. Essa é a explicação matemática para a "barra de vida diminuindo visivelmente mais rápido".
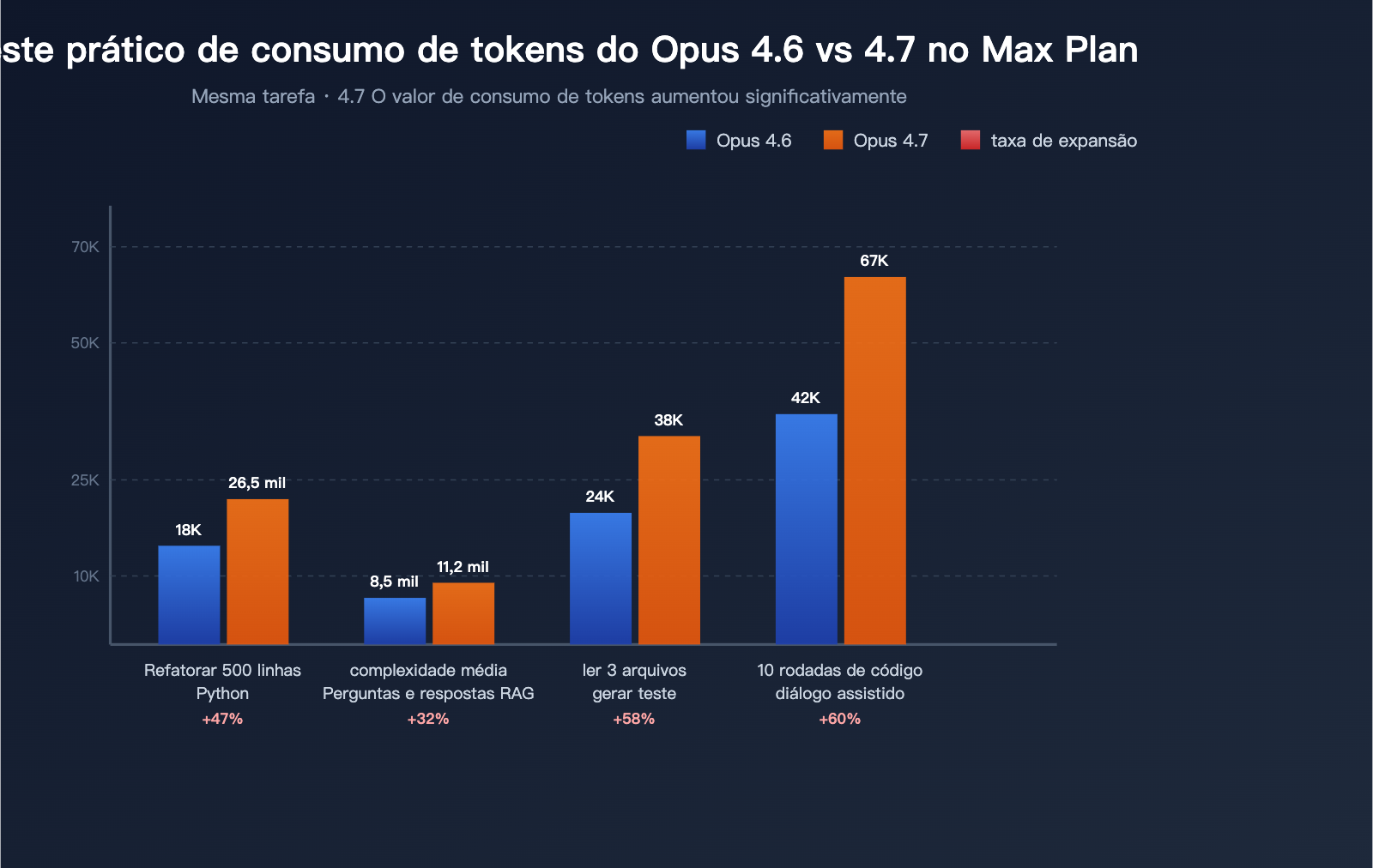
Dados de testes práticos (3 tarefas típicas)
Organizado com base no feedback da comunidade:
| Tarefa de teste | Consumo de tokens 4.6 | Consumo de tokens 4.7 | Taxa de inflação |
|---|---|---|---|
| Refatorar módulo Python de 500 linhas | ~18.000 | ~26.500 | +47% |
| Responder a uma pergunta RAG de complexidade média | ~8.500 | ~11.200 | +32% |
| Ler 3 arquivos e gerar testes | ~24.000 | ~38.000 | +58% |
| 10 rodadas de assistência de código em diálogo longo | ~42.000 | ~67.000 | +60% |
Estes dados mostram que: a "falta de durabilidade" do Opus 4.7 não é uma ilusão, mas uma mudança sistêmica que pode ser quantificada e verificada.
Por que a Anthropic diz que "o preço não mudou"?
A Anthropic deixou claro em seu anúncio:
- Preço de entrada: $5 / milhão de tokens (inalterado)
- Preço de saída: $25 / milhão de tokens (inalterado)
Isso é tecnicamente verdade no nível de preço unitário, mas é um exemplo clássico de "retórica de preço unitário" — o preço por unidade não mudou, mas a quantidade de tokens consumida para a mesma tarefa aumentou, fazendo com que a conta final suba naturalmente. Plataformas de análise de custos de terceiros, como a Finout, chamam esse fenômeno de "A verdadeira história de custo por trás da etiqueta de preço inalterada".
💰 Dica de controle de custos: Para ambientes de produção sensíveis ao custo de tokens, recomendamos fortemente realizar um teste de comparação de faturas com tráfego real através da plataforma APIYI (apiyi.com) antes de migrar. A plataforma oferece estatísticas detalhadas de chamadas e análise de custos, facilitando a quantificação do impacto real da migração no seu orçamento.
Três ações para resolver o consumo excessivo do Claude Opus 4.7
Se você já atualizou para a versão 4.7, ou se não consegue fazer o downgrade no momento, aqui estão três ações imediatas para trazer o consumo de créditos de volta a um nível controlável.
Ação 1: Reduza manualmente o esforço para "medium" ou "high"
O Claude Code define o xhigh como padrão para otimizar "tarefas de codificação extremamente complexas", mas, para a maioria das tarefas cotidianas, o medium ou o high são perfeitamente suficientes.
Especifique isso explicitamente na invocação do modelo:
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refatore este código"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Veja a comparação real do consumo de Tokens por nível de esforço
import time
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Analise os problemas de desempenho do código abaixo e forneça sugestões de otimização.
(Insira aqui 200 linhas de código Python)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Dica: Para auxílio de código no dia a dia, use high; para perguntas e respostas simples, use medium; reserve o xhigh apenas para refatorações complexas envolvendo vários arquivos.
Ação 2: Roteamento de modelos por cenário
Não "padronize" tudo para a versão 4.7. Uma estratégia de roteamento inteligente seria:
| Cenário de Negócio | Modelo Recomendado | Motivo |
|---|---|---|
| Codificação Agentic multi-arquivos | Opus 4.7 (xhigh) | Especialidade do agente |
| Geração de código single-file | Opus 4.7 (high) | Benefício claro na atualização |
| Análise de imagens em alta definição | Opus 4.7 (high) | Salto de qualidade visual |
| RAG de documentos longos | Opus 4.6 | Evita o colapso MRCR |
| Agente de pesquisa Web | GPT-5.4 Pro | Liderança no BrowseComp |
| Escrita comum / Copywriting | Opus 4.6 ou Sonnet | Custo de Token mais baixo |
| Conversação simples | Haiku / Sonnet | Melhor custo-benefício |
Ação 3: Ative o "Task Budgets" para limitar o consumo por tarefa
O novo Task Budgets do Opus 4.7 (em versão beta pública) é uma ferramenta poderosa para controlar o custo dos loops do agente:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Conclua a tarefa de refatoração completa"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
O modelo visualiza o orçamento restante a cada rodada de resposta e ajusta sua estratégia automaticamente — priorizando tarefas essenciais quando o orçamento está apertado, ou aprofundando detalhes quando há orçamento disponível.
🎯 Recomendação geral: Para equipes sensíveis ao orçamento de tokens, recomendamos gerenciar as invocações do Claude Opus 4.7 através da plataforma APIYI (apiyi.com). A plataforma oferece monitoramento de cotas em tempo real e capacidades de roteamento multi-modelo, ajudando você a transformar essa sensação de "consumo excessivo" em uma curva de custos previsível.
Comparação lateral: Claude Opus 4.7 vs GPT-5.4 xhigh
Alguns usuários relataram: "Nos meus testes, o Opus 4.7 parece ainda estar atrás do GPT-5.4 xhigh." Este é um julgamento que precisa ser discutido dependendo do cenário.

9 benchmarks de comparação direta
| Benchmark | Opus 4.7 | GPT-5.4 | Vencedor |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Conhecimento Corp.) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Reconhecimento Visual | 98.5% | — | Opus 4.7 |
| BrowseComp (Pesquisa Web) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG de longo contexto | 32.2% | Sem colapso | GPT-5.4 |
| Custo de Token | 1.0–1.35x | Estável | GPT-5.4 |
O Opus 4.7 venceu 6 das 9 categorias com 1 empate e 2 derrotas, mas no seu cenário de uso principal, a conclusão pode ser oposta:
- Se o seu caso de uso depende pesadamente de pesquisa Web (ex: Research Agent, automação de navegador), o GPT-5.4 xhigh de fato lidera o BrowseComp por 10 pontos percentuais.
- Se você faz RAG de documentos longos, o GPT-5.4 não possui o problema de colapso MRCR.
- Se você busca uma curva de custos estável, o Tokenizer do GPT-5.4 não sofreu alterações.
Portanto, a percepção de que "o Opus 4.7 não é tão bom quanto o GPT-5.4 xhigh" é perfeitamente justificável para certos fluxos de trabalho.
Matriz de decisão de seleção
| Sua necessidade principal | Modelo preferencial | Opção secundária |
|---|---|---|
| Codificação Agentic multi-arquivos | Opus 4.7 xhigh | Opus 4.6 |
| Tarefas de codificação reais no IDE | Opus 4.7 high | GPT-5.4 |
| Research Agent (Pesquisa Web) | GPT-5.4 Pro | Opus 4.7 |
| Perguntas e respostas corporativas | Opus 4.7 | GPT-5.4 |
| Compreensão de documentos longos / RAG | Opus 4.6 | GPT-5.4 |
| Compreensão de imagens em alta definição | Opus 4.7 | Gemini 3.1 Pro |
| Extrema sensibilidade a custos | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Sugestão de implementação multi-modelo: É difícil cobrir todos os cenários de aplicações de IA modernas com um único modelo. Recomendamos integrar toda a linha de modelos Claude, GPT e Gemini através da plataforma APIYI (apiyi.com) para roteamento inteligente conforme o caso. A plataforma oferece a capacidade de chamar todos os principais modelos com uma única chave de API, reduzindo drasticamente a complexidade da implantação multi-modelo.
Perguntas Frequentes sobre a "Menor Durabilidade" do Claude Opus 4.7
Q1: O Claude Opus 4.7 é realmente menos “durável” (consome mais créditos) que o 4.6?
Sim, mas essa "falta de durabilidade" deve ser entendida sob duas dimensões:
-
Nível de cota: Definitivamente consome mais. A expansão do Tokenizer em 0-35% + o padrão xhigh do Claude Code resulta em um aumento de 30-80% no consumo de tokens. Usuários do plano Max 20x relataram que a barra de cota esgota muito mais rápido na prática.
-
Nível de capacidade: Depende do cenário. É claramente mais forte em tarefas de Agent de codificação, visão e uso de ferramentas; porém, é mais fraco ou equivalente em cenários de RAG de documentos longos, pesquisas na Web e escrita geral.
Se você não realiza esses tipos de tarefas de Agent, o Opus 4.7 será simplesmente "mais caro" para você.
Q2: Por que a Anthropic diz que o “preço não mudou”, mas minha fatura subiu?
O que a declaração oficial diz é que o preço unitário permanece o mesmo: US$ 5 por milhão de tokens de entrada, US$ 25 por milhão de tokens de saída. No entanto, o novo Tokenizer do Opus 4.7 faz com que o mesmo texto consuma 1,0–1,35x mais tokens, e com a expansão de tokens de saída do xhigh, é comum que a fatura final suba entre 20% e 50% em relação à era do 4.6.
Para controlar os custos, você pode usar a plataforma APIYI (apiyi.com) para realizar testes de comparação de tráfego real. A plataforma oferece suporte à invocação paralela de toda a série Claude e estatísticas de cobrança detalhadas.
Q3: O consumo de cotas do Max Plan 20x está muito rápido. O que posso fazer para economizar?
Três ações práticas imediatas:
- Reduza o esforço (effort) para high ou medium: Desative manualmente o padrão xhigh nas configurações do Claude Code; o nível high é suficiente para tarefas do dia a dia.
- Desative etapas de pensamento desnecessárias: Em conversas longas, se encontrar perguntas simples, peça explicitamente ao modelo para pular o raciocínio profundo.
- Mude para o Sonnet ou Opus 4.6 em tarefas que não sejam de Agent: Escrita, perguntas e respostas simples e traduções não exigem o Opus 4.7.
Combinadas, essas três ações podem reduzir o consumo de cota do Max Plan ao nível da era 4.6, ou até menos.
Q4: Já migrei para o Opus 4.7, vale a pena voltar para o 4.6?
Depende do seu fluxo de trabalho principal:
- Se você foca em codificação de Agent com múltiplos arquivos: Não volte, o 4.7 é realmente mais forte.
- Se você foca em RAG de documentos longos / análise de contratos: Volte imediatamente para o 4.6, a queda no desempenho de MRCR é severa.
- Cenários mistos: Não precisa voltar tudo, basta rotear conforme o cenário — use o 4.7 para tarefas pesadas de Agent e o 4.6 ou Sonnet para o restante.
Na invocação de API, o rollback é simples: basta alterar o parâmetro model de claude-opus-4-7 de volta para claude-opus-4-6.
Q5: O Opus 4.7 é superior ao GPT-5.4 xhigh em todos os cenários?
Não. Dados oficiais mostram que o Opus 4.7 obteve 6 vitórias, 1 empate e 2 derrotas em 9 benchmarks comparáveis, mas as duas derrotas ocorreram em cenários críticos:
- BrowseComp (Pesquisa Web): GPT-5.4 Pro 89,3% vs Opus 4.7 79,3%
- RAG de contexto longo: O GPT-5.4 não apresentou uma queda de desempenho do tipo MRCR.
Portanto, os relatos de usuários dizendo que "nos meus testes, o Opus 4.7 ainda perde para o GPT-5.4 xhigh" podem ser perfeitamente verdadeiros — desde que o seu cenário principal seja pesquisa na Web ou documentos longos.
Através da plataforma APIYI (apiyi.com), é possível invocar tanto o Claude quanto o GPT no mesmo projeto e rotear as chamadas por cenário, o que é a abordagem mais prática no momento.
Q6: Meus comandos (prompts) antigos apresentam qualidade de saída inferior no Opus 4.7, o que fazer?
Este é um efeito colateral da adesão a instruções "mais literais" do 4.7. Princípios de reescrita:
- Transforme intenções implícitas em restrições explícitas: O que era "escreva de forma mais profissional" → mude para "deve usar termos técnicos do setor, evitando linguagem coloquial".
- Transforme limites vagos em valores numéricos rígidos: O que era "não escreva muito longo" → mude para "limite a 300 palavras".
- Adicione restrições de contraexemplo: Diga ao modelo quais tipos de saída são inaceitáveis.
O trabalho não é pequeno, mas para bibliotecas grandes de comandos, recomendo realizar testes A/B para confirmar quais precisam ser reescritos.
Resumo de Prós e Contras do Claude Opus 4.7
Vantagens reais (onde ele brilha)
- Salto na capacidade de Agent de codificação: 64,3% no SWE-bench Pro, 70% no CursorBench, superando o GPT-5.4.
- Mudança na visão: Alta resolução de 3,75 MP, 98,5% em benchmarks visuais.
- Cadeia de ferramentas MCP-Atlas mais forte: 77,3%, superando todos os modelos públicos.
- Adesão a instruções mais precisa: Para comandos com restrições completas, a saída é mais controlável.
- Task Budgets trazem governança de custos de Agent.
Limitações reais (onde ele é fraco)
- Expansão do Tokenizer de 0-35%: O discurso sobre preços mascarou o aumento real dos custos.
- Padrão xhigh aumenta o consumo de tokens de saída: A cota do Max Plan 20x ficou visivelmente mais restrita.
- Colapso de contexto longo MRCR: De 78,3% para 32,2%; inutilizável para RAG de documentos longos.
- Regressão no BrowseComp: Perde para o GPT-5.4 Pro em cenários de pesquisa na Web.
- Pequena regressão no CyberGym: Ligeiro declínio em tarefas relacionadas à segurança.
- Problemas de compatibilidade com comandos antigos: Comandos que dependem de intenções implícitas precisam ser reescritos.
Resumo
O Claude Opus 4.7 é uma atualização "especializada em cenários" por excelência. Todas as suas melhorias apontam para um único objetivo: permitir que a Anthropic recupere o título de campeã na área de codificação com agentes (Agentic coding). Ela conseguiu atingir esse objetivo, mas o preço é que os usuários de "todos os outros cenários" acabam pagando a conta por essa atualização.
Se você constrói agentes, é um usuário intensivo do Claude Code ou utiliza o Cursor profundamente, o Opus 4.7 vale a migração imediata. Mas, se o seu cenário principal envolve escrita, RAG, pesquisa na web ou produção sensível a custos, minha recomendação é:
- Mantenha o Opus 4.6 para tarefas que não sejam de agentes.
- Reduza o esforço (effort) padrão do Claude Code de xhigh para high.
- Roteie múltiplos modelos de acordo com o cenário, não adote uma atualização única para tudo.
"O preço não mudou" nunca é a história completa. O custo real está escondido no Tokenizer, nos níveis padrão e na profundidade de inferência. O Opus 4.7 não é ruim, ele apenas não é generalista — ao entender isso, você conseguirá extrair o valor correto dele.
Recomendamos gerenciar a invocação do modelo de toda a linha Claude através da plataforma APIYI (apiyi.com). A plataforma oferece roteamento inteligente de múltiplos modelos, monitoramento de cotas em tempo real e uma interface de API totalmente compatível com a oficial, sendo a ferramenta mais prática para lidar com o problema de "especialização de cenário" do Opus 4.7.
Referências
-
Anúncio oficial da Anthropic: Apresentação oficial do Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Descrição: Definição oficial de capacidades e cenários de uso recomendados.
- Link:
-
Documentação oficial da Anthropic: Guia de migração do Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Descrição: Mudanças no Tokenizer e explicações sobre o modo xhigh.
- Link:
-
Análise de custos da Finout: O custo real por trás da etiqueta de preço inalterada
- Link:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Descrição: Análise de custos de terceiros e detalhamento de faturas.
- Link:
-
Avaliação comparativa da Artificial Analysis: GPT-5.4 xhigh vs Claude Opus
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Descrição: Dados de avaliação comparativa independente de múltiplos modelos.
- Link:
-
GitHub Issue #23706: Feedback de consumo de tokens de usuários do plano Max
- Link:
github.com/anthropics/claude-code/issues/23706 - Descrição: Feedback direto de usuários do Claude Code no plano Max.
- Link:
Autor: Equipe Técnica APIYI
Data de publicação: 18/04/2026
Modelos aplicáveis: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Troca técnica: Convidamos você a obter cotas de teste de múltiplos modelos através da APIYI (apiyi.com) para verificar pessoalmente as diferenças reais em diferentes cenários.