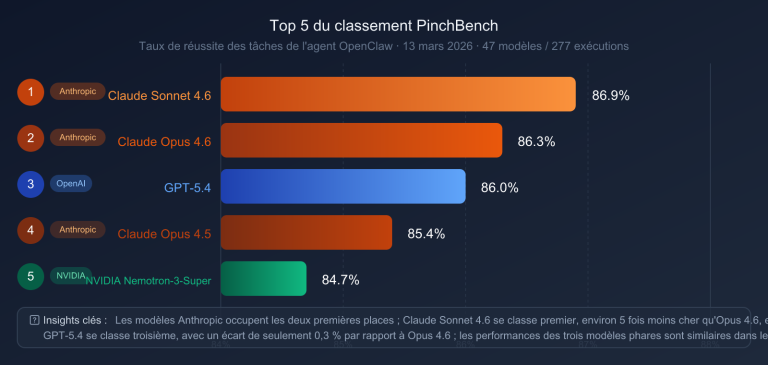
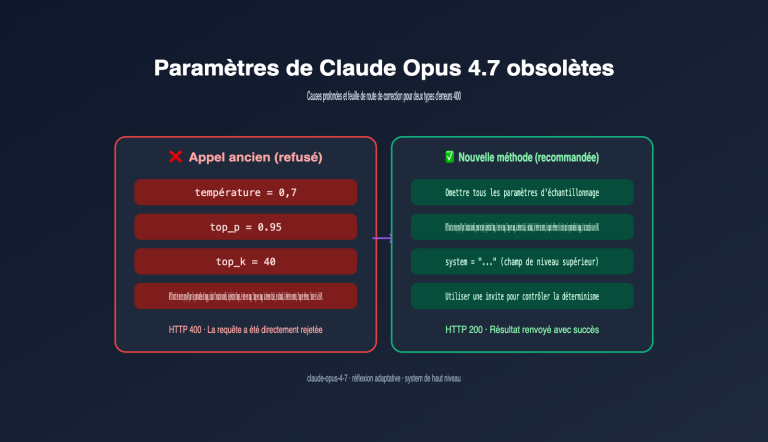
Claude Opus 4.7 a été lancé le 16 avril 2026. En moins de deux jours, l'avis de la communauté est passé d'une « mise à jour complète » à une « mise à jour sélective ». Le problème ne vient pas des benchmarks officiels, mais d'une conclusion vérifiée à maintes reprises : l'Opus 4.7 est une mise à jour pensée uniquement pour les "Agents de codage", s'avérant être une régression pour tous les autres scénarios.
Cet article va droit au but et répond aux raisons réelles du manque de durabilité de Claude Opus 4.7 : pourquoi la jauge de quota Max Plan 20x fond-elle visiblement plus vite qu'auparavant ? Pourquoi le RAG sur documents longs est-il moins performant qu'avec la 4.6 ? Pourquoi vos anciens prompts donnent-ils des résultats de plus en plus médiocres ?
Valeur ajoutée : Après avoir lu cet article, vous saurez exactement dans quels scénarios migrer immédiatement vers la 4.7, quand rester sur la 4.6, et comment utiliser trois ajustements de configuration pour retrouver un équilibre entre coût et qualité.
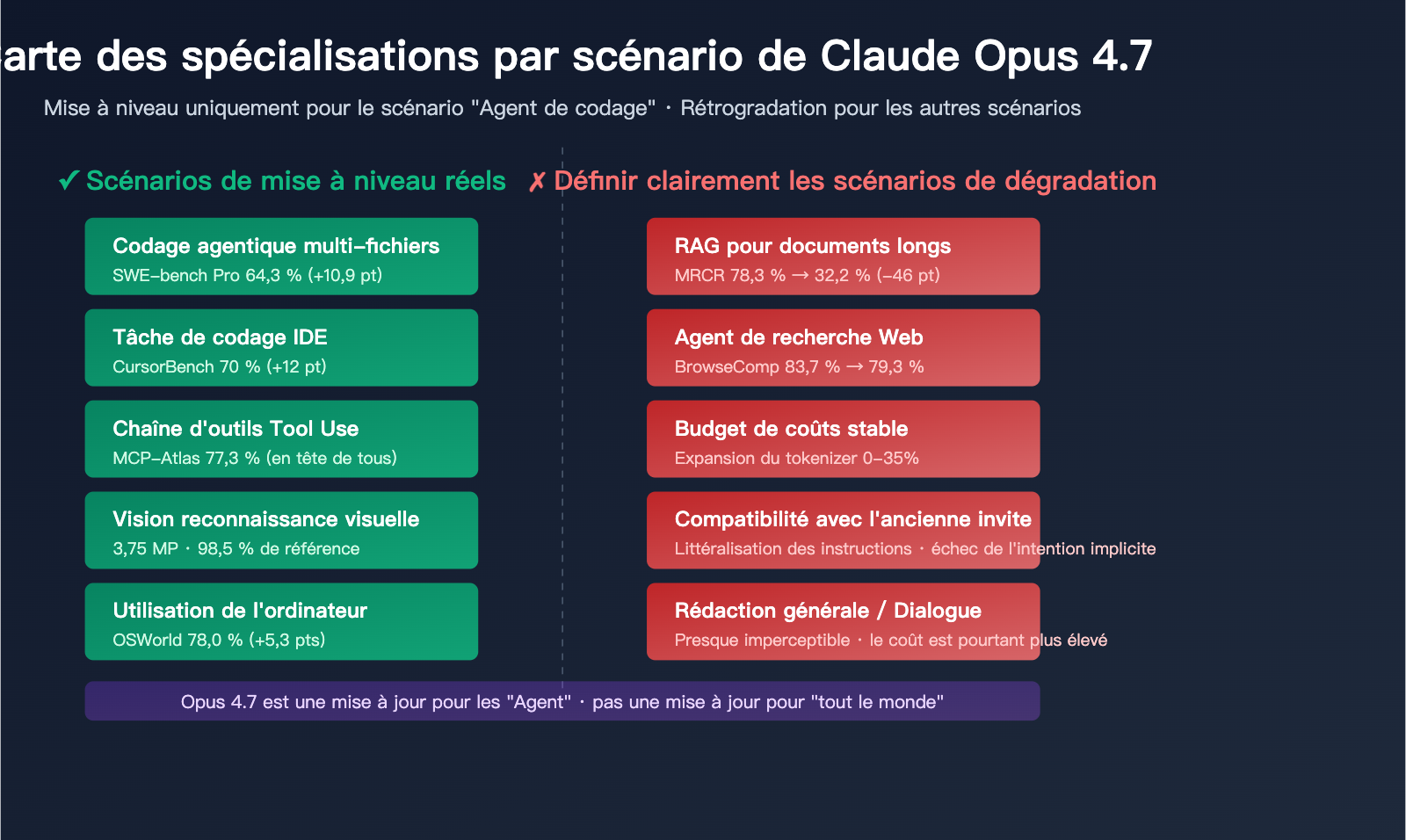
Les raisons fondamentales du manque de durabilité de Claude Opus 4.7
Pour comprendre cette sensation de "manque de durabilité", il faut distinguer deux choses : l'évolution des capacités du modèle et l'évolution de la facturation/des quotas. Opus 4.7 a ajusté ces deux dimensions, mais ces changements ne profitent qu'à un cercle restreint : seuls les utilisateurs tirant réellement parti des capacités d'Agent en tirent profit, tandis que la plupart des utilisateurs quotidiens subissent une hausse des coûts.
Les réels bénéficiaires de la mise à jour Opus 4.7
Anthropic indique clairement dans son blog officiel que l'Opus 4.7 est conçu pour les scénarios où « l'Opus 4.6 avait besoin d'être assisté » : flux de travail de codage agentique longue durée, tâches de production sur des bases de code multi-fichiers, utilisation de l'ordinateur (computer use), etc.
| Public bénéficiaire | Ampleur de la mise à jour Opus 4.7 | Scénarios types |
|---|---|---|
| Développeurs Claude Code | ⭐⭐⭐⭐⭐ | Refactorisation multi-fichiers, boucles d'Agent |
| Utilisateurs de Cursor | ⭐⭐⭐⭐⭐ | Tâches de codage réelles dans l'IDE |
| Développement d'outils Agentiques | ⭐⭐⭐⭐ | MCP-Atlas dépasse tous les modèles |
| Traitement de documents visuels | ⭐⭐⭐⭐ | Analyse haute résolution 3,75 MP |
| Utilisateurs rédaction/copywriting | ⭐ | Mise à jour presque imperceptible |
| RAG documents longs | Régression | MRCR 78,3% → 32,2% |
| Recherche Web/BrowseComp | Régression | 83,7% → 79,3% |
| Cybersécurité | Régression | CyberGym 73,8% → 73,1% |
| Production sensible aux coûts | Régression | Gonflement des jetons de 0-35% |
🎯 Conseil de migration : Si vous n'appartenez pas aux quatre premières catégories, mais que votre activité nécessite d'appeler à la fois la 4.6 et la 4.7, nous vous recommandons d'utiliser le routage par scénario via la plateforme APIYI (apiyi.com). Cette plateforme permet d'utiliser une interface unifiée pour invoquer toute la gamme de modèles Claude, évitant ainsi la baisse de performance liée à une migration "généralisée".
Les trois raisons fondamentales du manque de durabilité de Claude Opus 4.7
Raison 1 : La refonte du Tokenizer entraîne une explosion de la consommation de jetons
Opus 4.7 utilise un tout nouveau Tokenizer. Un même texte d'entrée sera divisé en 1,0 à 1,35 fois plus de jetons sur la 4.7. Ce multiplicateur varie nettement selon le type de contenu :
- Conversation en anglais pur : proche de 1,0×
- Contenu en chinois : 1,1–1,2×
- Fragments de code : 1,15–1,25×
- JSON/données structurées : 1,2–1,35×
- Scénarios multilingues mixtes : 1,25–1,35×
Raison 2 : Claude Code active par défaut le palier d'inférence xhigh
En même temps que le lancement de la 4.7, Claude Code a fait passer le palier d'inférence par défaut de tous les forfaits de "high" à "xhigh". Le niveau xhigh se situe entre "high" et "max" et consomme plus de "jetons de réflexion" (thinking tokens) pour les mêmes tâches ; cette consommation est directement comptabilisée dans votre facture.
Raison 3 : Le quota du Max Plan 20x est calculé par jetons
Bien que le Max Plan 20x d'Anthropic soit nominalement un "quota 20 fois supérieur au Pro", la limite fondamentale repose sur les jetons (tokens) et non sur le nombre de requêtes. Lorsque le gonflement du Tokenizer et l'activation par défaut du xhigh surviennent simultanément, une même opération consommera plus rapidement votre quota de jetons. De nombreux utilisateurs ont rapporté : le 17 avril, lors de l'utilisation d'Opus 4.7, la jauge de quota du Max Plan diminuait nettement plus vite que le 15 avril avec la 4.6.
Panorama des performances de Claude Opus 4.7 par scénario
Pour déterminer si Opus 4.7 représente une mise à niveau ou une régression pour vos besoins, ne vous fiez pas uniquement aux benchmarks officiels. Cette section évalue le modèle à travers 7 scénarios d'utilisation réels.

Scénario 1 : Agent de codage (Mise à niveau évidente)
C'est le terrain de prédilection d'Opus 4.7. Plusieurs données confirment cette tendance :
| Benchmark de codage | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Amélioration Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80,8 % | 87,6 % | Non public | +6,8 pt |
| SWE-bench Pro | 53,4 % | 64,3 % | 57,7 % | +10,9 pt |
| CursorBench | 58 % | 70 % | Non public | +12 pt |
| MCP-Atlas | 75,8 % | 77,3 % | 68,1 % | +1,5 pt |
| OSWorld-Verified | 72,7 % | 78,0 % | 75,0 % | +5,3 pt |
Sur 9 benchmarks comparables, Opus 4.7 affiche un score de 6 victoires, 1 nul et 2 défaites face à GPT-5.4, reprenant pour la première fois le titre de champion du codage agentique.
🚀 Recommandation pour les Agents : Si vous développez des agents en production, nous vous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour invoquer directement Claude Opus 4.7. Cette plateforme propose une interface entièrement compatible avec l'API officielle de Claude, tout en prenant en charge les nouvelles fonctionnalités comme le niveau xhigh et les budgets de tâches.
Scénario 2 : Vision et reconnaissance visuelle (Mise à niveau majeure)
La vision est un autre domaine où l'amélioration est réelle :
- Résolution d'image maximale : 1,15 MP → 3,75 MP (×3)
- Pixels sur le côté long : extension jusqu'à 2576 px
- Benchmark de reconnaissance visuelle : 54,5 % → 98,5 %
Pour les besoins nécessitant de lire directement des schémas d'architecture, des maquettes de design, des scans PDF ou des captures d'écran d'interface, il s'agit d'un changement qualitatif perceptible.
Scénario 3 : RAG sur documents longs (Régression sévère)
C'est le point de frustration majeur au sein de la communauté. Le MRCR (Multi-Round Context Recall) est le benchmark standard pour mesurer la capacité de rappel dans un contexte étendu :
- Opus 4.6 : 78,3 %
- Opus 4.7 : 32,2 %
- Écart : -46,1 pt
Ce chiffre explique les retours de nombreux développeurs : "J'ai fourni à la version 4.7 un document de travail de 800 lignes ; il prétend l'avoir lu, mais le contenu généré n'a aucun rapport avec le document."
Si votre activité principale repose sur le question-réponse sur documents longs, l'analyse de contrats ou l'examen de vastes bases de code, Opus 4.7 est une régression claire ; nous vous conseillons de rester sur la version 4.6.
Scénario 4 : Recherche Web et BrowseComp (Légère régression)
BrowseComp mesure les performances sur les tâches de recherche Web :
- Opus 4.6 : 83,7 %
- Opus 4.7 : 79,3 %
- GPT-5.4 Pro : 89,3 %
Pour les agents de recherche nécessitant une navigation Web approfondie et une synthèse d'informations, GPT-5.4 Pro reste un choix plus robuste, tandis qu'Opus 4.7 se montre même moins performant que la version 4.6.
Scénario 5 : Rédaction et conversation courante (Presque imperceptible)
Pour la rédaction quotidienne, la génération de contenu marketing ou les tâches conversationnelles, les différences subjectives entre Opus 4.7 et 4.6 sont très limitées. Cependant, en raison de l'expansion du tokenizer, la consommation réelle de jetons par échange sera 10 à 20 % plus élevée qu'à l'époque de la 4.6.
Conclusion : La version 4.6 est plus rentable pour la rédaction, car les améliorations de la 4.7 sont quasi invisibles ici.
Scénario 6 : Compatibilité des anciennes invites (Rétrogradation potentielle)
Le suivi des instructions par Opus 4.7 est devenu plus "littéral" — il ne cherche plus autant à "lire entre les lignes" que la 4.6. Cela signifie que :
- Les invites dépendant d'intentions implicites voient leur qualité diminuer.
- Avec des instructions vagues comme "Aide-moi à rendre cela meilleur", la 4.7 a tendance à exécuter la demande au pied de la lettre.
- Il est nécessaire de transformer les contraintes implicites en contraintes explicites (ex: "limite de 500 mots", "doit inclure l'élément X").
Si vous disposez d'une vaste bibliothèque d'invites conçues pour la 4.6, une série de tests de régression est nécessaire avant toute migration.
Scénario 7 : Cybersécurité (Légère régression)
CyberGym (benchmark de reproduction de vulnérabilités en cybersécurité) :
- Opus 4.6 : 73,8 %
- Opus 4.7 : 73,1 %
Anthropic a admis que cela est le prix à payer pour les nouveaux mécanismes de protection cyber. Pour les équipes travaillant sur le Red Teaming ou l'audit de sécurité, il s'agit d'une régression légère mais réelle.
💡 Conseil de sélection : Le choix entre Opus 4.7 et 4.6 dépend principalement de votre cas d'usage et de vos exigences de qualité. Nous vous recommandons d'effectuer des tests comparatifs via la plateforme APIYI (apiyi.com), qui prend en charge une interface unifiée pour plusieurs modèles majeurs, facilitant ainsi les changements et les validations rapides.
Analyse de la consommation du plan Claude Opus 4.7 Max
Cette section répond spécifiquement à la question : « Pourquoi ma barre de progression descend-elle plus vite ? »
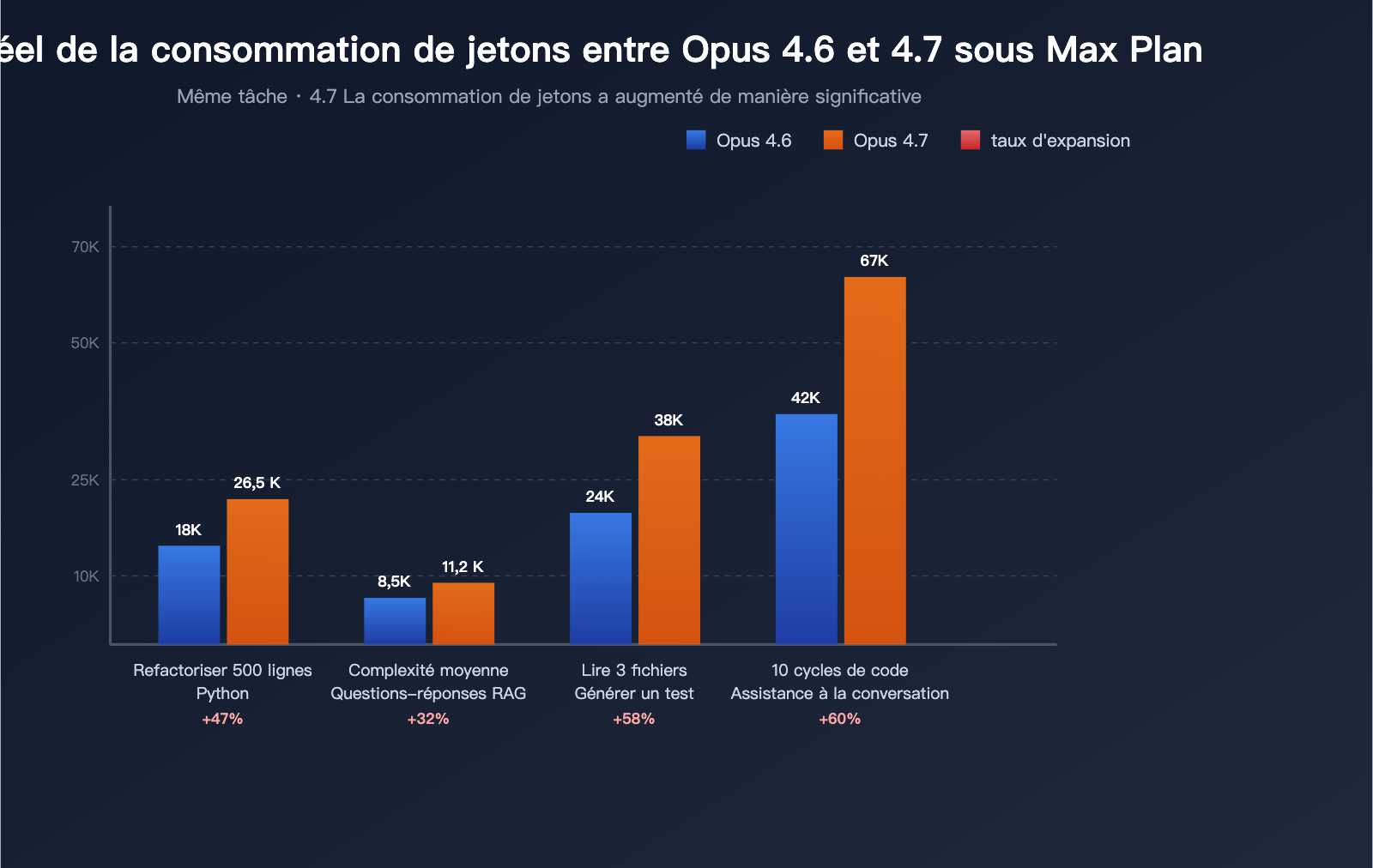
Mécanisme de consommation du plan Claude Max 20x
Le plan Claude Max 20x est basé sur une mesure par jetons (tokens), avec deux limites principales :
- Fenêtre glissante de 5 heures : pour éviter les appels massifs sur une courte période.
- Limite hebdomadaire de messages : pour protéger l'utilisation globale.
Depuis le lancement d'Opus 4.7, les valeurs absolues de ces limites n'ont pas changé, mais en raison du nouveau Tokenizer et du niveau par défaut « xhigh », la consommation moyenne de jetons par message a considérablement augmenté.
Trois sources de gonflement de la consommation de jetons
| Source de gonflement | Portée | Taux de gonflement estimé |
|---|---|---|
| Nouveau Tokenizer | Toutes les entrées | 0 % – 35 % (selon le type de contenu) |
| Niveau par défaut xhigh | Sorties de raisonnement | 20 % – 60 % (par rapport à « high ») |
| Résolution plus rigoureuse | Boucles d'agents | 10 % – 30 % (augmentation du nombre d'étapes) |
Résultat concret : pour une même tâche effectuée sur Claude Code, la version 4.7 consomme entre 30 % et 80 % de quota en plus par rapport à la 4.6. C'est l'explication mathématique derrière cette impression que la « barre de vie » fond à vue d'œil.
Données de test (3 tâches typiques)
Basé sur les retours de la communauté :
| Tâche de test | Consommation 4.6 | Consommation 4.7 | Taux de gonflement |
|---|---|---|---|
| Refactorisation d'un module Python de 500 lignes | ~18 000 | ~26 500 | +47 % |
| Réponse à une question RAG moyennement complexe | ~8 500 | ~11 200 | +32 % |
| Lecture de 3 fichiers et génération de tests | ~24 000 | ~38 000 | +58 % |
| 10 tours d'assistance au code dans une longue conversation | ~42 000 | ~67 000 | +60 % |
Ces données confirment que le manque d'endurance d'Opus 4.7 n'est pas une illusion, mais un changement systémique quantifiable.
Pourquoi Anthropic affirme-t-il que « les prix n'ont pas changé » ?
Dans son annonce, Anthropic précise :
- Prix d'entrée : 5 $ / million de jetons (inchangé)
- Prix de sortie : 25 $ / million de jetons (inchangé)
C'est techniquement vrai au niveau du prix unitaire, mais il s'agit d'un « argument marketing sur le prix unitaire » classique : le prix par jeton reste le même, mais comme la quantité de jetons nécessaire pour une même tâche augmente, la facture finale grimpe mécaniquement. Des plateformes d'analyse de coûts comme Finout appellent ce phénomène : « La réalité des coûts derrière une étiquette de prix inchangée ».
💰 Conseil de contrôle des coûts : Pour les environnements de production sensibles aux coûts des jetons, nous recommandons vivement d'effectuer un test de comparaison de facturation en conditions réelles via la plateforme APIYI (apiyi.com) avant toute migration. Cette plateforme permet des statistiques d'invocation précises et une analyse des coûts, facilitant la quantification de l'impact réel de la migration sur votre budget.
Voici trois solutions pour gérer la consommation excessive de Claude Opus 4.7 si vous l'avez déjà adopté ou si vous ne pouvez pas revenir en arrière.
Action 1 : Réduire manuellement l'effort à « medium » ou « high »
Claude Code utilise par défaut xhigh pour optimiser les « tâches de codage les plus complexes », mais pour la plupart des tâches quotidiennes, medium ou high suffisent largement.
Spécifiez-le explicitement lors de l'invocation du modèle :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactorise ce code"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Voir la comparaison réelle de la consommation de jetons selon l’effort
import time
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Analyse les problèmes de performance du code ci-dessous et propose des optimisations.
(Insérer ici 200 lignes de code Python)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Conseil : Utilisez high pour l'assistance au code quotidienne, medium pour les questions-réponses simples, et réservez xhigh uniquement pour les refactorisations multi-fichiers extrêmement complexes.
Action 2 : Router les modèles selon le scénario
Ne passez pas tout à la version 4.7 par défaut. Voici une stratégie de routage raisonnable :
| Scénario métier | Modèle recommandé | Raison |
|---|---|---|
| Codage Agentique multi-fichiers | Opus 4.7 (xhigh) | Terrain de jeu des agents |
| Génération de code mono-fichier | Opus 4.7 (high) | Avantage net de la mise à jour |
| Analyse d'images haute résolution | Opus 4.7 (high) | Gain qualitatif visuel |
| RAG sur documents longs | Opus 4.6 | Évite l'effondrement MRCR |
| Agent de recherche Web | GPT-5.4 Pro | Leader sur BrowseComp |
| Rédaction / Copywriting | Opus 4.6 ou Sonnet | Coût de tokenisation moindre |
| Conversation simple | Haiku / Sonnet | Meilleur rapport qualité-prix |
Action 3 : Activer les « Task Budgets » pour limiter la consommation par tâche
La nouvelle fonctionnalité Task Budgets (en bêta publique) d'Opus 4.7 est un outil puissant pour contrôler les coûts des boucles d'agents :
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Termine toute la tâche de refactorisation"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
Le modèle voit le budget restant à chaque étape de réponse et ajuste automatiquement sa stratégie : il privilégie les tâches essentielles si le budget est serré, ou approfondit les détails s'il est confortable.
🎯 Conseil global : Pour les équipes sensibles au budget de jetons, nous recommandons de gérer les invocations de Claude Opus 4.7 via la plateforme APIYI (apiyi.com). Elle offre un suivi des quotas en temps réel et des capacités de routage multi-modèles, transformant cette impression de « manque de durabilité » en une courbe de coûts maîtrisée.
Comparaison transversale : Claude Opus 4.7 vs GPT-5.4 xhigh
Certains utilisateurs rapportent : « Dans mes tests, Opus 4.7 semble toujours inférieur à GPT-5.4 xhigh. » C'est un jugement qui doit être nuancé selon le contexte.

9 points de référence pour une comparaison directe
| Référence | Opus 4.7 | GPT-5.4 | Vainqueur |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Connaissances entreprise) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Reconnaissance visuelle | 98.5% | — | Opus 4.7 |
| BrowseComp (Recherche Web) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG sur contexte long | 32.2% | Stable | GPT-5.4 |
| Coût en jetons | 1.0–1.35× | Stable | GPT-5.4 |
Opus 4.7 remporte 6 victoires, 1 nul et 2 défaites sur 9 points, mais selon vos priorités, la conclusion peut s'inverser :
- Si votre flux de travail dépend fortement de la recherche Web (ex: Agent de recherche, automatisation de navigateur), GPT-5.4 xhigh mène effectivement de 10 points sur BrowseComp.
- Si vous faites du RAG sur documents longs, GPT-5.4 ne souffre pas du problème d'effondrement MRCR.
- Si vous recherchez une courbe de coûts stable, le tokenizer de GPT-5.4 n'a pas changé.
Matrice de décision pour la sélection
| Votre besoin principal | Modèle prioritaire | Alternative |
|---|---|---|
| Codage Agentique multi-fichiers | Opus 4.7 xhigh | Opus 4.6 |
| Codage réel dans l'IDE | Opus 4.7 high | GPT-5.4 |
| Agent de recherche (Web) | GPT-5.4 Pro | Opus 4.7 |
| Q&R sur connaissances entreprise | Opus 4.7 | GPT-5.4 |
| Compréhension de documents longs / RAG | Opus 4.6 | GPT-5.4 |
| Compréhension d'images HD | Opus 4.7 | Gemini 3.1 Pro |
| Sensibilité extrême aux coûts | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Conseil de déploiement multi-modèles : Il est difficile pour une application IA moderne de couvrir tous les scénarios avec un seul modèle. Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour accéder de manière unifiée à l'ensemble des modèles Claude, GPT et Gemini, et de router intelligemment selon le scénario. Cette plateforme permet d'appeler tous les modèles principaux avec une seule clé API, simplifiant considérablement la complexité du déploiement.
FAQ sur la "durabilité" de Claude Opus 4.7
Q1 : Claude Opus 4.7 est-il vraiment moins « durable » que la version 4.6 ?
Oui, mais le terme "durabilité" doit être compris sous deux angles :
-
Niveau des quotas : Il est clairement moins durable. L'expansion du tokenizer de 0 à 35 % + le mode
xhighpar défaut de Claude Code entraînent une augmentation de la consommation de jetons de 30 à 80 %. Les utilisateurs du plan Max 20x rapportent massivement que leur barre de quota s'épuise beaucoup plus rapidement. -
Niveau des capacités : Cela dépend du scénario. Il est nettement plus performant pour les agents de codage, la vision et l'utilisation d'outils ; en revanche, il est plus faible ou équivalent pour le RAG sur documents longs, la recherche web et la rédaction classique.
Si vous n'utilisez pas ces types de tâches d'agent, alors Opus 4.7 est simplement "plus cher" pour vous.
Q2 : Pourquoi Anthropic affirme que le « prix n’a pas changé » alors que ma facture a augmenté ?
L'annonce officielle concerne le prix unitaire qui reste inchangé : 5 $ par million de jetons en entrée, 25 $ par million de jetons en sortie. Cependant, le nouveau tokenizer d'Opus 4.7 consomme 1,0 à 1,35 fois plus de jetons pour le même texte, et avec l'expansion des jetons de sortie en mode xhigh, une augmentation finale de la facture de 20 à 50 % par rapport à l'ère 4.6 est un résultat courant.
Pour contrôler vos coûts, vous pouvez effectuer des tests de trafic réels via la plateforme APIYI (apiyi.com), qui prend en charge l'invocation du modèle en parallèle pour toute la gamme Claude et propose des statistiques de facturation détaillées.
Q3 : La consommation des quotas du plan Max 20x s’accélère, quelles mesures prendre ?
Trois actions immédiatement applicables :
- Réduire l'effort à
highoumedium: Désactivez manuellement lexhighpar défaut dans les paramètres de Claude Code ; le modehighsuffit pour les tâches quotidiennes. - Désactiver les étapes de réflexion inutiles : Pour les questions simples dans les longues conversations, demandez explicitement au modèle de sauter le raisonnement approfondi.
- Passer à Sonnet ou Opus 4.6 pour les tâches non liées aux agents : La rédaction, les questions-réponses simples et la traduction ne nécessitent pas Opus 4.7.
Ces trois actions combinées peuvent ramener la consommation de votre quota Max Plan au niveau de l'ère 4.6, voire en dessous.
Q4 : J’ai déjà migré vers Opus 4.7, est-il judicieux de revenir à la 4.6 ?
Tout dépend de votre flux de travail principal :
- Principalement du codage d'agent multi-fichiers : Ne revenez pas en arrière, la 4.7 est vraiment plus performante.
- Principalement du RAG sur documents longs / analyse de contrats : Revenez immédiatement à la 4.6, car le MRCR s'effondre sérieusement.
- Scénarios mixtes : Pas besoin de tout basculer, utilisez le routage par scénario — utilisez la 4.7 pour les tâches d'agent lourdes, et la 4.6 ou Sonnet pour le reste.
Le retour en arrière lors de l'invocation du modèle est simple : il suffit de remplacer le paramètre model de claude-opus-4-7 par claude-opus-4-6.
Q5 : Opus 4.7 est-il plus performant que GPT-5.4 xhigh dans tous les scénarios ?
Non. Les données officielles montrent qu'Opus 4.7 remporte 6 victoires, 1 nul et 2 défaites sur 9 benchmarks comparables, mais les deux défaites concernent des scénarios clés :
- BrowseComp (Recherche Web) : GPT-5.4 Pro 89,3 % contre Opus 4.7 79,3 %.
- RAG sur contexte long : GPT-5.4 ne présente pas d'effondrement similaire au MRCR.
Par conséquent, les utilisateurs qui disent "dans mes tests, Opus 4.7 n'est toujours pas à la hauteur de GPT-5.4 xhigh" peuvent tout à fait avoir raison, à condition que votre cœur de métier soit la recherche web ou les documents longs.
Utiliser la plateforme APIYI (apiyi.com) pour appeler simultanément Claude et GPT dans le même projet et router selon le scénario est actuellement l'approche la plus pragmatique.
Q6 : La qualité de sortie de mes anciennes invites baisse avec Opus 4.7, que faire ?
C'est un effet secondaire de la "littéralité" accrue dans le suivi des instructions de la version 4.7. Principes de réécriture :
- Transformez les intentions implicites en contraintes explicites : Au lieu de "écris de manière plus professionnelle", utilisez "tu dois utiliser le jargon du secteur et éviter les expressions familières".
- Transformez les limites floues en valeurs numériques strictes : Au lieu de "ne fais pas trop long", utilisez "limite à 300 mots".
- Ajoutez des contraintes par contre-exemples : Indiquez au modèle quels types de sorties sont inacceptables.
La charge de travail est importante ; pour les grandes bibliothèques d'invites, il est conseillé de commencer par des tests A/B pour confirmer quelles invites nécessitent une réécriture.
Résumé des avantages et inconvénients de Claude Opus 4.7
Avantages réels (reconnaître ses points forts)
- Bond en avant des capacités d'agent de codage : SWE-bench Pro 64,3 %, CursorBench 70 %, surpassant GPT-5.4.
- Changement qualitatif de la vision : Haute résolution 3,75 MP, benchmark visuel à 98,5 %.
- Chaîne d'outils MCP-Atlas la plus puissante : 77,3 %, en tête de tous les modèles publics.
- Suivi des instructions plus précis : Pour les invites avec des contraintes complètes, la sortie est plus contrôlable.
- Capacité de gestion des coûts des agents grâce aux Task Budgets.
Limites réelles (reconnaître ses points faibles)
- Expansion du tokenizer de 0 à 35 % : Le discours marketing sur les prix masque une réelle augmentation des coûts.
- Le mode
xhighaugmente par défaut la consommation de jetons de sortie : Le quota du plan Max 20x devient nettement plus serré. - Effondrement du contexte long MRCR : Passage de 78,3 % à 32,2 %, rendant le RAG sur documents longs inutilisable.
- Recul sur BrowseComp : Perd face à GPT-5.4 Pro dans les scénarios de recherche web.
- Léger recul sur CyberGym : Légère baisse sur les tâches liées à la sécurité.
- Problèmes de compatibilité avec les anciennes invites : Les invites dépendant d'intentions implicites doivent être réécrites.
Résumé
Claude Opus 4.7 est une mise à jour « ultra-spécialisée » par excellence. Toutes ses améliorations convergent vers un seul objectif : permettre à Anthropic de reprendre le titre de champion dans le domaine du codage par agents (Agentic coding). C'est un pari réussi, mais au prix d'un compromis : les utilisateurs de « tous les autres scénarios » paient la note de cette mise à jour.
Si vous développez des agents, ou si vous êtes un utilisateur intensif de Claude Code ou de Cursor, le passage à Opus 4.7 est vivement recommandé. En revanche, si vos usages principaux sont la rédaction, le RAG, la recherche web ou la production sensible aux coûts, voici nos conseils :
- Gardez Opus 4.6 pour les tâches non liées aux agents.
- Réduisez l'effort par défaut de Claude Code de
xhighàhigh. - Utilisez le routage par scénario pour vos modèles, ne passez pas tout aveuglément à la nouvelle version.
« Prix inchangé » n'est jamais toute l'histoire. Le coût réel se cache dans le tokenizer, les niveaux par défaut et la profondeur d'inférence. Opus 4.7 n'est pas un mauvais modèle, il n'est simplement pas polyvalent — une fois que vous aurez compris cela, vous pourrez en tirer le meilleur parti.
Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour gérer de manière centralisée toutes vos invocations de modèles Claude. La plateforme propose un routage intelligent multi-modèles, un suivi des quotas en temps réel et une interface API entièrement compatible avec l'officielle, ce qui en fait l'outil le plus pragmatique pour gérer les spécificités d'Opus 4.7.
Références
-
Annonce officielle d'Anthropic : Présentation officielle de Claude Opus 4.7
- Lien :
anthropic.com/news/claude-opus-4-7 - Description : Définition officielle des capacités et cas d'usage recommandés.
- Lien :
-
Documentation officielle d'Anthropic : Guide de migration vers Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Description : Changements liés au tokenizer et explications sur le mode
xhigh.
- Lien :
-
Analyse des coûts par Finout : Le coût réel derrière l'étiquette de prix inchangée
- Lien :
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Description : Analyse des coûts par un tiers et décomposition de la facturation.
- Lien :
-
Comparatif Artificial Analysis : GPT-5.4 xhigh vs Claude Opus
- Lien :
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Description : Données comparatives indépendantes sur plusieurs modèles.
- Lien :
-
GitHub Issue #23706 : Retours des utilisateurs du plan Max sur la consommation de jetons
- Lien :
github.com/anthropics/claude-code/issues/23706 - Description : Retours d'expérience directs des utilisateurs de Claude Code Max Plan.
- Lien :
Auteur : Équipe technique APIYI
Date de publication : 18/04/2026
Modèles concernés : Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Échanges techniques : N'hésitez pas à obtenir des crédits de test multi-modèles via APIYI (apiyi.com) pour constater par vous-même les écarts réels selon les scénarios.