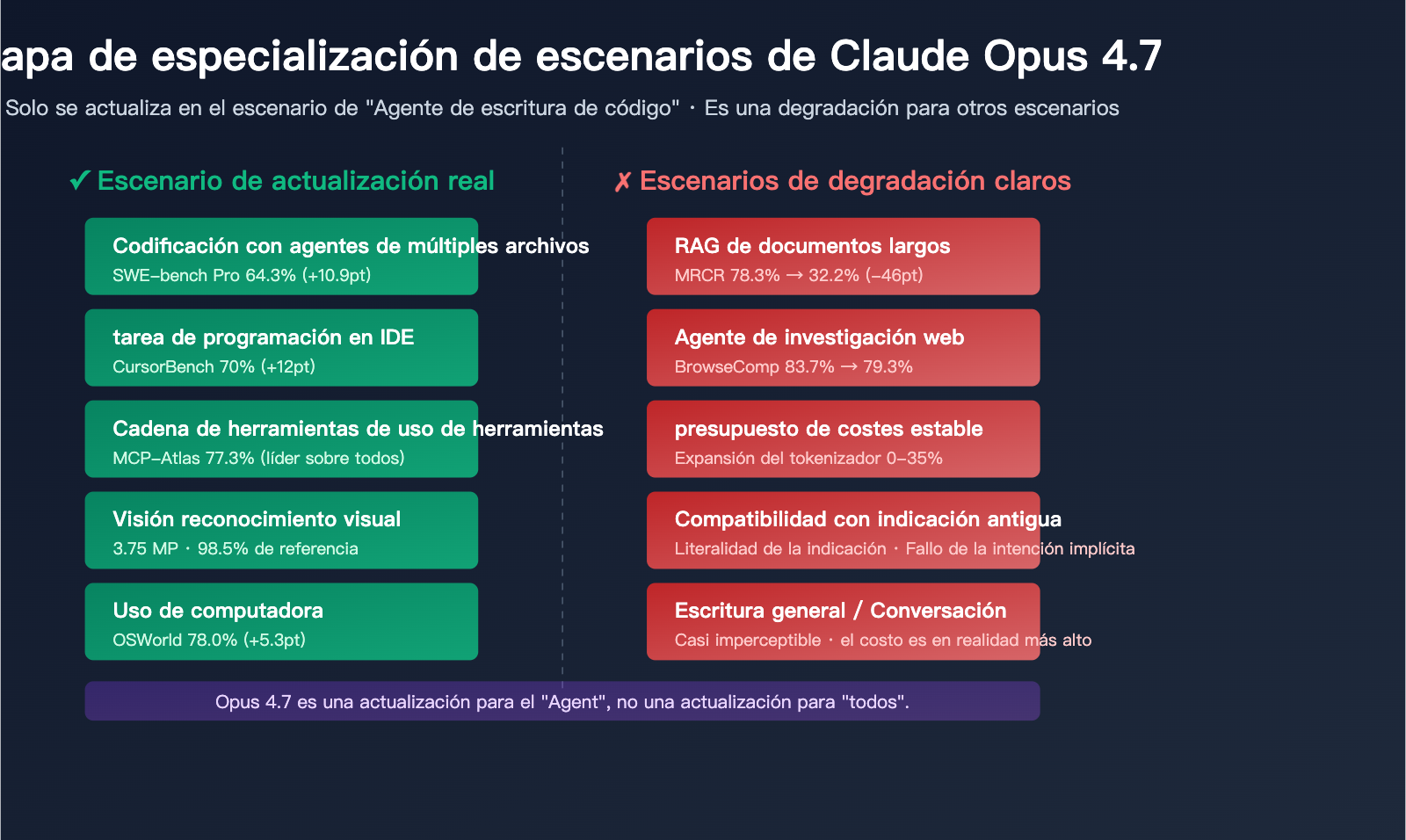
Claude Opus 4.7 se lanzó el 16 de abril de 2026 y, en menos de dos días, la percepción de la comunidad pasó de "actualización integral" a "actualización selectiva". El problema no reside en los benchmarks oficiales, sino en una conclusión que ha sido validada repetidamente: Opus 4.7 es una actualización diseñada exclusivamente para "Agentes de programación", siendo un retroceso para cualquier otro escenario.
Este artículo va directo al grano y responde a la verdadera razón por la que Claude Opus 4.7 no rinde: ¿Por qué la barra de cuota del Max Plan 20x se agota visiblemente más rápido que el día anterior? ¿Por qué los escenarios de RAG con documentos largos funcionan peor que en la 4.6? ¿Por qué las indicaciones (prompts) antiguas arrojan resultados cada vez más pobres?
Valor central: Al terminar de leer, sabrás exactamente en qué situaciones migrar de inmediato a la 4.7, en cuáles quedarte en la 4.6 y cómo usar tres configuraciones para recuperar tanto el control de costos como la calidad.
La razón principal por la que Claude Opus 4.7 no rinde
Para entender esta sensación de "falta de rendimiento", primero debemos distinguir dos cosas: cambios en las capacidades del modelo y cambios en la facturación/cuotas. Opus 4.7 ha ajustado ambos aspectos, y estos cambios solo benefician a un grupo reducido: solo los usuarios que realmente aprovechan las capacidades de los agentes obtienen un beneficio neto; la mayoría de los usuarios cotidianos terminan asumiendo mayores costos.
Los verdaderos beneficiarios de la actualización a Opus 4.7
Anthropic menciona explícitamente en su blog oficial que Opus 4.7 está diseñado para "escenarios donde Opus 4.6 necesitaba supervisión constante": flujos de trabajo de codificación agentica de larga duración, tareas de nivel de producción en bases de código con múltiples archivos y el uso de computadora (computer use), entre otros.
| Grupo beneficiario | Mejora en Opus 4.7 | Escenario típico |
|---|---|---|
| Desarrolladores de Claude Code | ⭐⭐⭐⭐⭐ | Refactorización multiactivo, bucles de agentes |
| Usuarios de Cursor | ⭐⭐⭐⭐⭐ | Tareas de codificación reales en el IDE |
| Desarrollo de herramientas Agentic | ⭐⭐⭐⭐ | MCP-Atlas supera a todos los modelos |
| Procesamiento de documentos visuales | ⭐⭐⭐⭐ | Resolución de 3.75 MP |
| Usuarios de redacción/copywriting | ⭐ | Mejora casi imperceptible |
| RAG con documentos largos | Retroceso | MRCR 78.3% → 32.2% |
| Investigación Web/BrowseComp | Retroceso | 83.7% → 79.3% |
| Ciberseguridad | Retroceso | CyberGym 73.8% → 73.1% |
| Producción sensible a costos | Retroceso | Inflación de Tokenizer 0-35% |
🎯 Recomendación de migración: Si no perteneces a los primeros cuatro grupos, pero tu negocio necesita invocar tanto la 4.6 como la 4.7, te sugerimos enrutar por escenario a través de la plataforma APIYI (apiyi.com). Esta plataforma permite utilizar una interfaz unificada para invocar toda la serie de modelos de Claude, evitando la degradación del rendimiento causada por una migración indiscriminada.
Las tres razones fundamentales por las que Claude Opus 4.7 "no rinde"
Razón 1: La reestructuración del Tokenizer provoca una inflación en el consumo de tokens
Opus 4.7 utiliza un nuevo Tokenizer. El mismo fragmento de texto de entrada se divide en 1.0 a 1.35 veces más tokens en la 4.7. Esta tasa varía significativamente según el tipo de contenido:
- Conversación en inglés puro: cerca de 1.0×
- Contenido en chino: 1.1–1.2×
- Fragmentos de código: 1.15–1.25×
- JSON/datos estructurados: 1.2–1.35×
- Escenarios multilingües mixtos: 1.25–1.35×
Razón 2: Claude Code activa por defecto el nivel de razonamiento xhigh
Al mismo tiempo que se lanzó la 4.7, Claude Code elevó el nivel de razonamiento predeterminado de todos los planes de "high" a "xhigh". El nivel xhigh, que se sitúa entre "high" y "max", consume más "tokens de pensamiento" (thinking tokens) en la misma tarea, y este consumo se refleja directamente en tu factura.
Razón 3: La cuota del Max Plan 20x se mide por tokens
Aunque el Max Plan 20x de Anthropic se denomina nominalmente como "20 veces la cuota Pro", la esencia de sus límites subyacentes son los tokens, no el número de solicitudes. Cuando la inflación del Tokenizer y el nivel xhigh predeterminado ocurren simultáneamente, la misma operación consumirá más tokens. Múltiples usuarios han reportado: al usar Opus 4.7 el 17 de abril, la barra de cuota del Max Plan se agotó notablemente más rápido que al usar la 4.6 el 15 de abril.
Panorama del rendimiento de Claude Opus 4.7 por escenarios
Para determinar si Opus 4.7 supone una mejora o un retroceso en tu caso de uso, no puedes limitarte a los puntos de referencia seleccionados por la marca. En esta sección, evaluamos cada aspecto a través de 7 escenarios de uso real.

Escenario 1: Agente de codificación (mejora notable)
Este es el terreno en el que destaca Opus 4.7. Múltiples datos confirman esto:
| Punto de referencia de código | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Mejora de Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | No público | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | No público | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
En los 9 puntos de referencia comparables directamente, Opus 4.7 obtuvo 6 victorias, 1 empate y 2 derrotas frente a GPT-5.4, recuperando por primera vez el título de campeón en codificación Agente de manos de GPT-5.4.
🚀 Recomendación para escenarios de Agentes: Si estás construyendo agentes a nivel de producción, te sugerimos realizar la invocación del modelo Claude Opus 4.7 directamente a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece interfaces totalmente compatibles con el oficial de Claude y admite funciones nuevas como niveles xhigh y presupuestos de tareas (Task Budgets).
Escenario 2: Visión y reconocimiento visual (mejora cualitativa)
La visión es otro escenario de mejora real:
- Resolución de imagen máxima: 1.15 MP → 3.75 MP (3x)
- Píxeles en el lado más largo: expansión desde la medida estándar a 2576px
- Puntos de referencia de reconocimiento visual: 54.5% → 98.5%
Para escenarios que requieren entender directamente diagramas de arquitectura, borradores de diseño, escaneos de PDF o capturas de pantalla de interfaces, se trata de una mejora perceptible.
Escenario 3: RAG con documentos largos (retroceso grave)
Esta es la queja más común en la comunidad. MRCR (Multi-Round Context Recall) es el estándar para medir la capacidad de recuperación en contextos largos:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- Brecha: -46.1pt
Esta cifra explica por qué varios desarrolladores han comentado: "Al darle a 4.7 un documento de flujo de trabajo de 800 líneas, dice que lo ha leído, pero el contenido que genera no tiene absolutamente nada que ver con el documento".
Si tu negocio principal es la consulta de documentos largos, el análisis de contratos o la revisión de bases de código grandes, Opus 4.7 supone un claro retroceso; se recomienda seguir con la versión 4.6.
Escenario 4: Investigación web y BrowseComp (ligero retroceso)
BrowseComp mide el desempeño en tareas de investigación web:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
En escenarios de Agentes de investigación que requieren navegación web profunda y síntesis de información, GPT-5.4 Pro sigue siendo la opción superior, mientras que Opus 4.7 rinde incluso peor que la 4.6.
Escenario 5: Escritura y conversación general (casi imperceptible)
Para tareas diarias de escritura, generación de textos y conversaciones, las diferencias subjetivas entre Opus 4.7 y 4.6 son muy limitadas. Sin embargo, debido a la expansión del Tokenizer, cada conversación consumirá un 10-20% más de tokens que en la era de la 4.6.
Conclusión: La versión 4.6 es más rentable para tareas de escritura; la mejora de capacidades de 4.7 es casi inexistente en este ámbito.
Escenario 6: Compatibilidad con indicadores antiguos (posible retroceso)
La guía de instrucciones de Opus 4.7 es más "literal" — ya no lee entre líneas de forma tan proactiva como la 4.6. Esto significa que:
- Las indicaciones que dependen de intenciones implícitas verán caer su calidad de salida.
- Con instrucciones vagas como "ayúdame a escribirlo un poco mejor", 4.7 tiende a ejecutarlo estrictamente al pie de la letra.
- Es necesario reformular las restricciones implícitas para hacerlas explícitas (p. ej., "límite de 500 palabras", "debe contener el elemento X").
Si tienes una gran biblioteca de indicadores heredada de la era 4.6, necesitarás realizar pruebas de regresión sistemáticas antes de migrar.
Escenario 7: Ciberseguridad (ligero retroceso)
CyberGym (punto de referencia de replicación de vulnerabilidades de ciberseguridad):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
Anthropic ha reconocido oficialmente que este es el precio a pagar por los nuevos mecanismos de protección de ciberseguridad añadidos. Para los equipos dedicados a la investigación "red team" y auditorías de seguridad, este es un retroceso pequeño pero real.
💡 Consejo de selección de escenario: Elegir entre Opus 4.7 y 4.6 depende principalmente de tus necesidades y estándares de calidad específicos. Te recomendamos realizar pruebas comparativas reales a través de la plataforma APIYI (apiyi.com), que admite una interfaz unificada para múltiples modelos principales, facilitando la conmutación y verificación rápidas.
Análisis del consumo de cuota del plan Max 4.7 de Claude Opus
Esta sección está dedicada a responder a la pregunta: "¿Por qué la barra de vida se agota más rápido?".
Mecanismo de consumo de cuota del plan Max 20x
El plan Max 20x de Claude se mide internamente por tokens y tiene dos límites principales:
- Límite de ventana deslizante de 5 horas: Para evitar un volumen masivo de invocaciones en poco tiempo.
- Límite superior de mensajes semanales: Protección general del uso.
Tras el lanzamiento de Opus 4.7, los valores absolutos de estos límites no cambiaron, pero debido al nuevo Tokenizer y a los ajustes predeterminados en el nivel "xhigh", el consumo promedio de tokens por mensaje ha aumentado significativamente.
Tres fuentes de inflación en el consumo de tokens
| Fuente de inflación | Alcance del impacto | Tasa de inflación estimada |
|---|---|---|
| Nuevo Tokenizer | Todas las entradas | 0% – 35% (según el tipo de contenido) |
| Nivel xhigh predeterminado | Salida en tareas de razonamiento | 20% – 60% (en comparación con high) |
| Resolución de problemas más rigurosa | Bucles de Agentes | 10% – 30% (aumento en los pasos) |
La sensación real tras combinar los tres factores: al completar el mismo trabajo en Claude Code, la versión 4.7 consume entre un 30% y un 80% más de cuota que la 4.6. Esta es la explicación matemática de por qué la "barra de vida" se agota visiblemente más rápido.
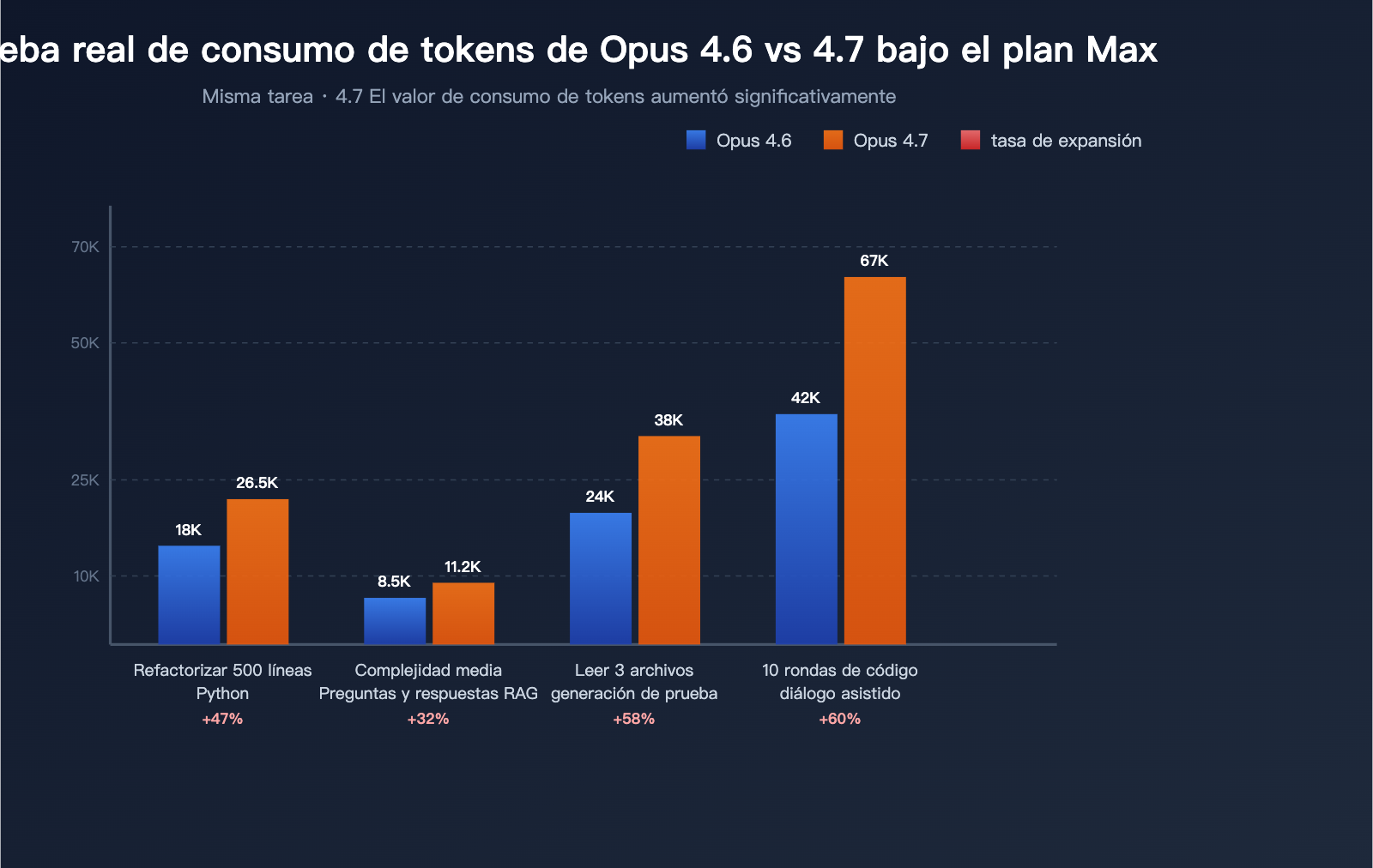
Datos de las pruebas (3 tareas típicas)
Recopilados a partir de los comentarios de la comunidad:
| Tarea de prueba | Consumo de Tokens (4.6) | Consumo de Tokens (4.7) | Tasa de inflación |
|---|---|---|---|
| Refactorización de módulo Python de 500 líneas | ~18,000 | ~26,500 | +47% |
| Responder a una pregunta RAG de complejidad media | ~8,500 | ~11,200 | +32% |
| Leer 3 archivos y generar pruebas | ~24,000 | ~38,000 | +58% |
| 10 rondas de asistencia de código en diálogo largo | ~42,000 | ~67,000 | +60% |
Estos datos demuestran que: que el Opus 4.7 sea "menos duradero" no es una ilusión, sino un cambio sistémico cuantificable y verificable.
¿Por qué Anthropic dice que "el precio no ha cambiado"?
En su comunicado, Anthropic aclaró:
- Precio de entrada: $5 / millón de tokens (sin cambios)
- Precio de salida: $25 / millón de tokens (sin cambios)
Esto es totalmente cierto en cuanto al precio unitario, pero es una táctica clásica de "discurso sobre el precio unitario": el precio por unidad se mantiene, pero la cantidad de tokens necesaria para realizar la misma tarea aumenta, lo que hace que la factura final inevitablemente suba. Plataformas de análisis de costes externas, como Finout, denominan a este fenómeno: "La historia del coste real detrás de un precio que no cambia".
💰 Sugerencia de control de costes: Para entornos de producción sensibles a los costes de tokens, recomiendo encarecidamente realizar una prueba de comparación de facturación con tráfico real a través de la plataforma APIYI (apiyi.com) antes de realizar la migración. Esta plataforma admite estadísticas detalladas de invocación y análisis de costes, lo que facilita cuantificar el impacto real de la migración en tu presupuesto.
title: "Tres acciones para resolver el consumo excesivo de Claude Opus 4.7"
description: "Optimiza tu uso de Claude Opus 4.7 con estas tres estrategias prácticas para controlar el consumo de tokens y mejorar la eficiencia de tus agentes."
Tres acciones para resolver el consumo excesivo de Claude Opus 4.7
Si ya has actualizado a la versión 4.7 o no puedes volver a una versión anterior por el momento, aquí tienes tres acciones que puedes ejecutar de inmediato para mantener el consumo de tu cuota bajo control.
Acción 1: Reducir manualmente el esfuerzo (effort) a medium o high
Claude Code establece xhigh como predeterminado para optimizar las "tareas de codificación más complejas", pero para la mayoría de las tareas cotidianas, medium o high son más que suficientes.
Puedes especificarlo explícitamente en la invocación del modelo:
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactoriza este código"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Ver comparativa de consumo de tokens según el nivel de esfuerzo
import time
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Por favor, analiza los problemas de rendimiento del siguiente código y ofrece sugerencias de optimización.
(Insertar aquí 200 líneas de código Python)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Sugerencia: Para asistencia diaria con código, usa high; para preguntas y respuestas simples, usa medium; reserva xhigh solo para refactorizaciones extremadamente complejas que involucren múltiples archivos.
Acción 2: Enrutar modelos según el escenario
No intentes actualizar todo a la versión 4.7 de forma indiscriminada. Una estrategia de enrutamiento razonable sería:
| Escenario de negocio | Modelo recomendado | Motivo |
|---|---|---|
| Codificación con agentes (múltiples archivos) | Opus 4.7 (xhigh) | Especialidad del agente |
| Generación de código (archivo único) | Opus 4.7 (high) | Mejora notable |
| Análisis de imágenes de alta resolución | Opus 4.7 (high) | Salto cualitativo en visión |
| RAG de documentos largos | Opus 4.6 | Evita el colapso de MRCR |
| Agente de investigación web | GPT-5.4 Pro | Líder en BrowseComp |
| Escritura / Redacción general | Opus 4.6 o Sonnet | Costo de tokenización menor |
| Conversación simple | Haiku / Sonnet | Mejor relación calidad-precio |
Acción 3: Habilitar presupuestos de tareas (Task Budgets) para limitar el consumo
Los nuevos presupuestos de tareas (en versión beta pública) de Opus 4.7 son una herramienta excelente para controlar el costo de los ciclos de los agentes:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Completa toda la tarea de refactorización"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
El modelo verá el presupuesto restante en cada ronda de respuesta y ajustará automáticamente su estrategia: priorizará las tareas principales cuando el presupuesto sea ajustado y profundizará en los detalles cuando sea suficiente.
🎯 Sugerencia integral: Para equipos sensibles al presupuesto de tokens, recomendamos gestionar las invocaciones de Claude Opus 4.7 a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece monitoreo de cuotas en tiempo real y capacidades de enrutamiento multimodelo, ayudándote a transformar la sensación de "consumo incontrolado" en una curva de costos predecible.
Comparativa lateral: Claude Opus 4.7 vs GPT-5.4 xhigh
En los comentarios de los usuarios se menciona: "En mis pruebas, Opus 4.7 parece seguir estando por debajo de GPT-5.4 xhigh". Este es un juicio que debe analizarse según el escenario.

9 puntos de referencia de comparación directa
| Benchmark | Opus 4.7 | GPT-5.4 | Ganador |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Conocimiento corporativo) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Reconocimiento visual | 98.5% | — | Opus 4.7 |
| BrowseComp (Investigación Web) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG de contexto largo | 32.2% | Sin colapso | GPT-5.4 |
| Costo de tokens | 1.0–1.35× | Estable | GPT-5.4 |
Opus 4.7 obtiene 6 victorias, 1 empate y 2 derrotas en 9 categorías, pero en los escenarios que más te interesan, la conclusión puede ser completamente opuesta:
- Si tu escenario de prueba depende fuertemente de la investigación web (por ejemplo, agentes de investigación, automatización de navegadores), GPT-5.4 xhigh realmente supera a Opus por 10 puntos porcentuales en BrowseComp.
- Si realizas RAG de documentos largos, GPT-5.4 no presenta el problema de colapso de MRCR.
- Si buscas una curva de costos de tokens estable, el tokenizador de GPT-5.4 no ha cambiado.
Por lo tanto, la percepción de que "Opus 4.7 no está a la altura de GPT-5.4 xhigh" es completamente razonable para flujos de trabajo específicos.
Matriz de decisión de selección de modelo
| Tu necesidad principal | Modelo preferido | Alternativa |
|---|---|---|
| Codificación con agentes (múltiples archivos) | Opus 4.7 xhigh | Opus 4.6 |
| Tareas de codificación real en el IDE | Opus 4.7 high | GPT-5.4 |
| Agente de investigación (Web) | GPT-5.4 Pro | Opus 4.7 |
| Preguntas y respuestas corporativas | Opus 4.7 | GPT-5.4 |
| Comprensión de documentos largos / RAG | Opus 4.6 | GPT-5.4 |
| Comprensión de imágenes de alta resolución | Opus 4.7 | Gemini 3.1 Pro |
| Sensibilidad extrema al costo | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Sugerencia de despliegue multimodelo: Es difícil que un solo modelo cubra todos los escenarios en las aplicaciones de IA modernas. Recomendamos acceder a toda la serie de modelos Claude, GPT y Gemini a través de la plataforma APIYI (apiyi.com) para enrutar de forma inteligente según el escenario. Esta plataforma ofrece la capacidad de invocar todos los modelos principales con una sola clave API, reduciendo drásticamente la complejidad del despliegue multimodelo.
Preguntas frecuentes sobre la menor eficiencia de Claude Opus 4.7
P1: ¿Es realmente Claude Opus 4.7 menos «eficiente» (más costoso/consumidor) que la versión 4.6?
Sí, pero esta "menor eficiencia" debe entenderse bajo dos dimensiones:
-
Nivel de cuota: Es claramente menos eficiente. La expansión del tokenizador entre un 0 y un 35% + el ajuste predeterminado
xhighde Claude Code provoca un aumento del 30-80% en el consumo de tokens. Los usuarios del plan Max 20x han reportado consistentemente que la barra de cuota se agota mucho más rápido. -
Nivel de capacidad: Depende del caso de uso. En tareas de agentes de programación, visión y uso de herramientas es claramente superior; sin embargo, en RAG de documentos largos, investigación web y escritura general, es más débil o mantiene un rendimiento similar.
Si no realizas este tipo de tareas de agentes, para ti, Opus 4.7 es simplemente "más caro".
P2: ¿Por qué Anthropic dice que «el precio no ha cambiado» pero mi factura es mayor?
Lo que el oficial ha declarado es que el precio unitario no ha cambiado: 5 $ por millón de tokens de entrada y 25 $ por millón de tokens de salida. Sin embargo, el nuevo tokenizador de Opus 4.7 hace que el mismo texto consuma entre 1,0 y 1,35 veces más tokens, lo cual, sumado a la expansión de tokens de salida por xhigh, hace que sea común ver facturas entre un 20 y un 50% más altas que en la era 4.6.
Para controlar los costos, puedes realizar pruebas de tráfico real a través de la plataforma APIYI (apiyi.com), la cual admite llamadas paralelas a toda la serie de Claude y ofrece estadísticas de facturación detalladas.
P3: El consumo de la cuota del plan Max 20x es más rápido, ¿qué medidas puedo tomar?
Tres acciones ejecutables de inmediato:
- Reducir el esfuerzo (effort) a 'high' o 'medium': Desactiva manualmente el valor predeterminado
xhighen la configuración de Claude Code; para tareas diarias, 'high' es suficiente. - Desactivar pasos de pensamiento innecesarios: En conversaciones largas, si te enfrentas a problemas simples, pide explícitamente al modelo que se salte el razonamiento profundo.
- Cambiar a Sonnet u Opus 4.6 para tareas que no sean de Agente: La escritura, las preguntas y respuestas sencillas y la traducción no requieren Opus 4.7.
Combinar estas tres acciones puede devolver el consumo de cuota del plan Max a los niveles de la era 4.6, o incluso menos.
P4: Ya migré a Opus 4.7, ¿vale la pena volver a la 4.6?
Depende de tu flujo de trabajo principal:
- Principalmente realizas programación con agentes multi-archivo: No vuelvas atrás, la versión 4.7 es realmente más potente.
- Principalmente haces RAG de documentos largos / análisis de contratos: Vuelve inmediatamente a la 4.6, ya que el colapso del MRCR es severo.
- Escenarios mixtos: No hace falta volver por completo, enruta según el escenario: tareas de agentes pesadas con 4.7, lo demás con 4.6 o Sonnet.
En la invocación del modelo vía API es muy sencillo: solo tienes que cambiar el parámetro model de claude-opus-4-7 a claude-opus-4-6.
P5: ¿Es Opus 4.7 siempre superior a GPT-5.4 xhigh en todos los escenarios?
No. Los datos oficiales muestran que Opus 4.7 obtuvo 6 victorias, 1 empate y 2 derrotas en 9 puntos de referencia comparables directamente, pero perdió en escenarios clave:
- BrowseComp (Investigación web): GPT-5.4 Pro 89,3% frente a Opus 4.7 79,3%.
- RAG de contexto largo: GPT-5.4 no presenta un colapso del MRCR similar.
Por lo tanto, es perfectamente posible que la percepción de los usuarios de que "en mis pruebas, Opus 4.7 sigue sin superar a GPT-5.4 xhigh" sea real, siempre y cuando tu escenario central sea la investigación web o los documentos extensos.
A través de la plataforma APIYI (apiyi.com), puedes invocar Claude y GPT simultáneamente en un mismo proyecto y enrutar según el escenario; es el enfoque más pragmático actualmente.
P6: La calidad de salida de mis indicaciones (prompts) antiguas ha bajado en Opus 4.7, ¿qué puedo hacer?
Este es un efecto secundario de que la 4.7 sea "más literal" al seguir instrucciones. Principios de reescritura:
- Convierte la intención implícita en restricción explícita: De "escribe de forma más profesional" a "debes utilizar terminología técnica del sector y evitar expresiones coloquiales".
- Convierte límites vagos en valores numéricos concretos: De "no seas demasiado largo" a "controla la extensión a menos de 300 palabras".
- Añade restricciones de contraejemplos: Indica al modelo qué tipo de salidas son inaceptables.
Esta carga de trabajo no es pequeña; para bibliotecas grandes de indicaciones, se recomienda realizar pruebas A/B primero para confirmar cuáles necesitan ser reescritas.
Resumen de ventajas y desventajas de Claude Opus 4.7
Ventajas reales (donde realmente destaca)
- Salto en la capacidad de agentes de programación: SWE-bench Pro 64,3%, CursorBench 70%, superando a GPT-5.4.
- Cambio cualitativo en Visión: Alta resolución de 3,75 MP, punto de referencia visual del 98,5%.
- La cadena de herramientas MCP-Atlas más potente: 77,3%, liderando sobre todos los modelos públicos.
- Seguimiento de instrucciones más preciso: Para indicaciones con restricciones completas, el resultado es más controlable.
- Los "Task Budgets" aportan capacidad de gobernanza de costos de agentes.
Limitaciones reales (donde es más débil)
- Expansión del tokenizador de 0-35%: El discurso sobre los precios ocultó el aumento real de los costos.
- El ajuste
xhighpredeterminado incrementa el consumo de tokens de salida: La cuota del plan Max 20x se vuelve significativamente más ajustada. - Colapso en contexto largo MRCR: 78,3% → 32,2%, inservible para RAG de documentos largos.
- Retroceso en BrowseComp: Pierde frente a GPT-5.4 Pro en escenarios de investigación web.
- Ligero retroceso en CyberGym: Rendimiento ligeramente inferior en tareas relacionadas con la seguridad.
- Problemas de compatibilidad con indicaciones antiguas: Las indicaciones que dependen de intenciones implícitas requieren reescritura.
Resumen
Claude Opus 4.7 es una actualización extremadamente típica de "especialización de escenario". Todas sus mejoras apuntan a un solo objetivo: permitir que Anthropic recupere el título de campeón en el ámbito de la codificación mediante agentes (Agentic coding). Ha logrado este objetivo, pero el precio a pagar es que los usuarios de "todos los demás escenarios" terminan asumiendo el costo de esta actualización.
Si eres un desarrollador de agentes, un usuario intensivo de Claude Code o un usuario avanzado de Cursor, vale la pena migrar a Opus 4.7 de inmediato. Sin embargo, si tus casos de uso principales son la escritura, RAG, investigación web o producción sensible a los costos, te sugiero lo siguiente:
- Mantén Opus 4.6 para tareas que no sean de agentes.
- Reduce el
effortpredeterminado de Claude Code dexhighahigh. - Enruta múltiples modelos según el escenario, no apliques una actualización generalizada.
"El precio no ha cambiado" nunca es la historia completa. El costo real se esconde en el tokenizador, los niveles predeterminados y la profundidad de razonamiento. Opus 4.7 no es malo, simplemente no es de propósito general; al entender esto, podrás aprovechar su verdadero valor.
Recomendamos utilizar la plataforma APIYI (apiyi.com) para gestionar de forma unificada todas las invocaciones del modelo Claude. Esta plataforma ofrece enrutamiento inteligente de múltiples modelos, monitoreo de cuotas en tiempo real y una interfaz de API totalmente compatible con la oficial, siendo la herramienta más práctica para abordar el problema de la "especialización de escenario" de Opus 4.7.
Referencias
-
Anuncio oficial de Anthropic: Presentación oficial de Claude Opus 4.7
- Enlace:
anthropic.com/news/claude-opus-4-7 - Descripción: Definición oficial de capacidades y escenarios de uso recomendados.
- Enlace:
-
Documentación oficial de Anthropic: Guía de migración a Opus 4.7
- Enlace:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Descripción: Cambios en el tokenizador y explicación del modo
xhigh.
- Enlace:
-
Análisis de costos de Finout: El costo real detrás de la etiqueta de precio sin cambios
- Enlace:
finout.io/blog/claude-opus-4-7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Descripción: Análisis de costos de terceros y desglose de facturación.
- Enlace:
-
Comparativa de Artificial Analysis: GPT-5.4 xhigh vs. Claude Opus
- Enlace:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Descripción: Datos de comparativa independiente de múltiples modelos.
- Enlace:
-
GitHub Issue #23706: Comentarios de usuarios del plan Max sobre el consumo de tokens
- Enlace:
github.com/anthropics/claude-code/issues/23706 - Descripción: Experiencia de primera mano de usuarios de Claude Code con el plan Max.
- Enlace:
Autor: Equipo técnico de APIYI
Fecha de publicación: 18 de abril de 2026
Modelos aplicables: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Intercambio técnico: Te invitamos a obtener cuotas de prueba para múltiples modelos a través de APIYI (apiyi.com) y comprobar por ti mismo las diferencias reales en distintos escenarios.