title: "Claude Opus 4.7 はなぜ「長持ちしない」のか?:実務で損をしないための移行ガイド"
description: "Claude Opus 4.7の登場で「コストが急増した」「性能が落ちた」と感じていませんか?本記事では、Opus 4.7がコード生成に特化している理由と、日常業務で損をしないための賢い使い分け術を徹底解説します。"
Claude Opus 4.7 は 2026 年 4 月 16 日にリリースされましたが、わずか 2 日でコミュニティの評価は「全面的なアップグレード」から「選択的なアップグレード」へと急変しました。問題は公式のベンチマークスコアではなく、繰り返し検証されたある結論にあります。それは、「Opus 4.7 は『コーディングエージェント』のためのアップデートであり、それ以外のあらゆるシナリオではダウングレードである」という事実です。
この記事では、遠回しな表現は抜きにして、なぜ Claude Opus 4.7 は「長持ちしない(コストパフォーマンスが悪い)」のか、その真の理由を明らかにします。なぜ Max Plan 20x の利用枠が前日よりも目に見えて早く減るのか?なぜ長文 RAG シナリオでは 4.6 よりも劣るのか?なぜ古いプロンプトをそのまま使っても結果が悪化するのか?
核心的な価値: この記事を読めば、どのシナリオで即座に 4.7 へ移行すべきか、どのシナリオで 4.6 に留まるべきか、そして 3 つの設定変更でコストと品質を最適化する方法が明確になります。

Claude Opus 4.7 が「長持ちしない」核心的な理由
「長持ちしない」という体感を理解するには、モデル能力の変化と課金/利用枠の変化という 2 つの側面を分けて考える必要があります。Opus 4.7 はこの両方で調整を行いましたが、その恩恵を受けるのはごく一部です。真に「エージェント能力」を必要とするユーザーだけがプラスの利益を得ており、一般的な日常ユーザーはコスト増という負担を強いられています。
Opus 4.7 アップグレードの真の恩恵を受ける層
Anthropic の公式ブログによると、Opus 4.7 は「Opus 4.6 では手助け(hand-holding)が必要だったシナリオ」のために設計されています。長時間実行されるエージェント型のコーディングワークフロー、大規模な複数ファイルにわたるコードベースのプロダクションレベルのタスク、コンピュータ使用(computer use)などがこれに該当します。
| 真の恩恵を受ける層 | Opus 4.7 アップグレード幅 | 代表的なシナリオ |
|---|---|---|
| Claude Code 開発者 | ⭐⭐⭐⭐⭐ | 複数ファイルのリファクタリング、エージェントループ |
| Cursor ユーザー | ⭐⭐⭐⭐⭐ | IDE 内でのリアルなコーディングタスク |
| エージェント型ツールチェーン開発 | ⭐⭐⭐⭐ | MCP-Atlas が全モデルをリード |
| 視覚ドキュメント処理 | ⭐⭐⭐⭐ | 3.75 MP 高解像度解析 |
| 執筆/ライティングユーザー | ⭐ | ほぼ進化を感じない |
| RAG 長文ドキュメント | ダウングレード | MRCR 78.3% → 32.2% |
| Web リサーチ/BrowseComp | ダウングレード | 83.7% → 79.3% |
| サイバーセキュリティ関連 | ダウングレード | CyberGym 73.8% → 73.1% |
| コスト重視のプロダクション | ダウングレード | トークナイザー膨張 0-35% |
🎯 移行のアドバイス: 上記の最初の 4 つに該当しない場合で、かつ業務で 4.6 と 4.7 を使い分ける必要がある場合は、APIYI (apiiyi.com) プラットフォームを通じてシナリオごとにルーティングすることをお勧めします。このプラットフォームは、統一インターフェースで Claude 全シリーズのモデルを呼び出せるため、「一律移行」によるパフォーマンス低下を回避できます。
Claude Opus 4.7 が「長持ちしない」3 つの根本原因
原因 1:トークナイザーの再構築によるトークン消費の膨張
Opus 4.7 は全く新しいトークナイザーを採用しています。同じ入力テキストでも、4.7 では 1.0 倍から 1.35 倍のトークンに分割されます。この倍率はコンテンツの種類によって顕著に異なります。
- 純粋な英語の会話:約 1.0 倍
- 中国語コンテンツ:1.1–1.2 倍
- コードスニペット:1.15–1.25 倍
- JSON/構造化データ:1.2–1.35 倍
- 多言語混在シナリオ:1.25–1.35 倍
原因 2:Claude Code でデフォルトの推論レベル「xhigh」が有効化
Claude Code は 4.7 のリリースと同時に、すべてのプランでデフォルトの推論レベルを「high」から「xhigh」に引き上げました。「xhigh」は「high」と「max」の中間に位置し、同じタスクでもより多くの「思考トークン(thinking tokens)」を消費します。この消費分はそのまま請求額に加算されます。
原因 3:Max Plan 20x の利用枠はトークン単位で計測
Anthropic の Max Plan 20x は名目上は「Pro 枠の 20 倍」ですが、利用制限の本質はリクエスト数ではなくトークン数です。トークナイザーの膨張とデフォルトの「xhigh」が同時に発生することで、同じ操作でもトークン消費が早くなります。多くのユーザーから「4 月 17 日に Opus 4.7 を使用した際、Max Plan の枠が 4 月 15 日に 4.6 を使用した時よりも明らかに早く減った」との報告が上がっています。
Claude Opus 4.7 シーン別パフォーマンスの全貌
Opus 4.7 があなたの利用シーンにおいて「アップグレード」なのか「ダウングレード」なのかを判断するには、公式が選定したベンチマークだけを見ていては不十分です。本セクションでは、7つの実利用シーンから一つずつ評価していきます。

シーン1:コーディング Agent(明確なアップグレード)
ここは Opus 4.7 の独壇場です。複数のデータがこれを裏付けています:
| コーディングベンチマーク | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Opus 4.7 向上幅 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | 未公開 | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | 未公開 | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Opus 4.7 は直接比較可能な9つのベンチマークのうち6勝1分2敗で GPT-5.4 を上回り、Agentic コーディングにおける王座を GPT-5.4 から初めて奪還しました。
🚀 Agent シーンでの推奨: 本番環境レベルの Agent を構築している場合、APIYI (apiyi.com) プラットフォームを通じて Claude Opus 4.7 を直接呼び出すことをお勧めします。このプラットフォームは Claude 公式と完全に互換性のあるインターフェースを提供しており、xhigh クラスや Task Budgets などの新機能もサポートしています。
シーン2:Vision 視覚認識(質的なアップグレード)
Vision は、真にアップグレードを実感できるもう一つのシーンです:
- 最大画像解像度:1.15 MP → 3.75 MP(3倍)
- 長辺ピクセル:通常サイズから 2576px まで拡張
- 視覚認識ベンチマーク:54.5% → 98.5%
アーキテクチャ図、設計図、PDF スキャン、UI スクリーンショットを直接読み取る必要があるシーンにおいて、これは体感できるレベルの質的な変化です。
シーン3:長文ドキュメント RAG(深刻なダウングレード)
これはコミュニティから最も多くの不満が寄せられている点です。MRCR(Multi-Round Context Recall)は、長文コンテキストの想起能力を測定する標準ベンチマークです:
- Opus 4.6:78.3%
- Opus 4.7:32.2%
- 差分:-46.1pt
この数値は、多くの開発者が「4.7 に800行のワークフロー文書を読み込ませたところ、読んだとは言うものの、生成された内容は文書と全く関係がなかった」と報告している理由を説明しています。
もしあなたの主要業務が長文ドキュメントの質疑応答、契約書解析、大規模コードベースのレビューであるなら、Opus 4.7 は明確なダウングレードです。4.6 を使い続けることを推奨します。
シーン4:Web リサーチと BrowseComp(軽微なダウングレード)
BrowseComp は Web リサーチタスクのパフォーマンスを測定します:
- Opus 4.6:83.7%
- Opus 4.7:79.3%
- GPT-5.4 Pro:89.3%
高度な Web ブラウジングと情報の統合を必要とする Research Agent シーンでは、GPT-5.4 Pro が依然として強力な選択肢であり、Opus 4.7 は 4.6 にすら及びません。
シーン5:一般的なライティングと対話(ほぼ変化なし)
日常的なライティング、コピーライティング、対話型タスクにおいて、Opus 4.7 と 4.6 の主観的な差は非常に限定的です。ただし、Tokenizer の肥大化により、対話ごとの実際のトークン消費量は 4.6 時代より 10〜20% 増加します。
結論: ライティングシーンでは 4.6 の方がコストパフォーマンスが高く、4.7 による能力向上はここではほとんど感じられません。
シーン6:旧プロンプトの互換性(潜在的な後退)
Opus 4.7 の指示追従はより「逐語的(リテラル)」になっています。つまり、4.6 のように「行間を読む」ような能動的な動きは減りました。これは以下を意味します:
- 暗黙の意図に依存するプロンプトでは、出力品質が低下する
- 「もう少しうまく書いて」といった曖昧な指示に対し、4.7 は文字通りに実行しようとする傾向がある
- 暗黙の制約を明示的な制約(例:「500文字以内」「Xという要素を必ず含める」など)に書き換える必要がある
4.6 時代のプロンプトライブラリを大量に蓄積している場合、移行前にシステム的な回帰テストが必要です。
シーン7:ネットワークセキュリティ関連(わずかなダウングレード)
CyberGym(サイバーセキュリティ脆弱性再現ベンチマーク):
- Opus 4.6:73.8%
- Opus 4.7:73.1%
Anthropic 公式も、これは新たに追加されたサイバーセキュリティ保護メカニズムによる代償であることを認めています。レッドチーム調査やセキュリティ監査を行うチームにとっては、わずかですが確実なダウングレードとなります。
💡 シーン別の選定アドバイス: Opus 4.7 を選ぶか 4.6 を選ぶかは、あなたの具体的なアプリケーションシーンと品質要件に依存します。APIYI (apiyi.com) プラットフォームを通じて実際のテスト比較を行うことをお勧めします。同プラットフォームは複数の主要モデルの統一インターフェース呼び出しをサポートしており、迅速な切り替えと検証が可能です。
Claude Opus 4.7 Max Plan の利用枠消費に関する実測
このセクションでは、「なぜ利用枠(HP)の減りがこれほど早いのか」という疑問にお答えします。
Max Plan 20x の利用枠消費メカニズム
Claude Max Plan 20x はトークン単位で計測されており、主に2つの制限があります。
- 5時間スライディングウィンドウ制限:短時間での過剰な呼び出しを防止
- 週次メッセージ上限:全体的な利用量を保護
Opus 4.7 のリリース後、これら2つの制限の絶対値は変わっていませんが、新しいトークナイザー(Tokenizer)と「xhigh」のデフォルト設定により、メッセージあたりの平均トークン消費量が大幅に増加しました。
トークン消費量が増加した3つの要因
| 増加要因 | 影響範囲 | 推定増加率 |
|---|---|---|
| 新しいトークナイザー | すべての入力 | 0% – 35%(コンテンツタイプによる) |
| xhigh デフォルト設定 | 推論タスクの出力 | 20% – 60%(highと比較) |
| より厳密な問題解決 | エージェントループ | 10% – 30%(ステップ数の増加) |
これら3つが重なった結果、Claude Code で同じ作業を行った場合、4.7 は 4.6 よりも 30% – 80% 多く利用枠を消費します。これが「HPの減りが目に見えて早い」という現象の数学的な根拠です。
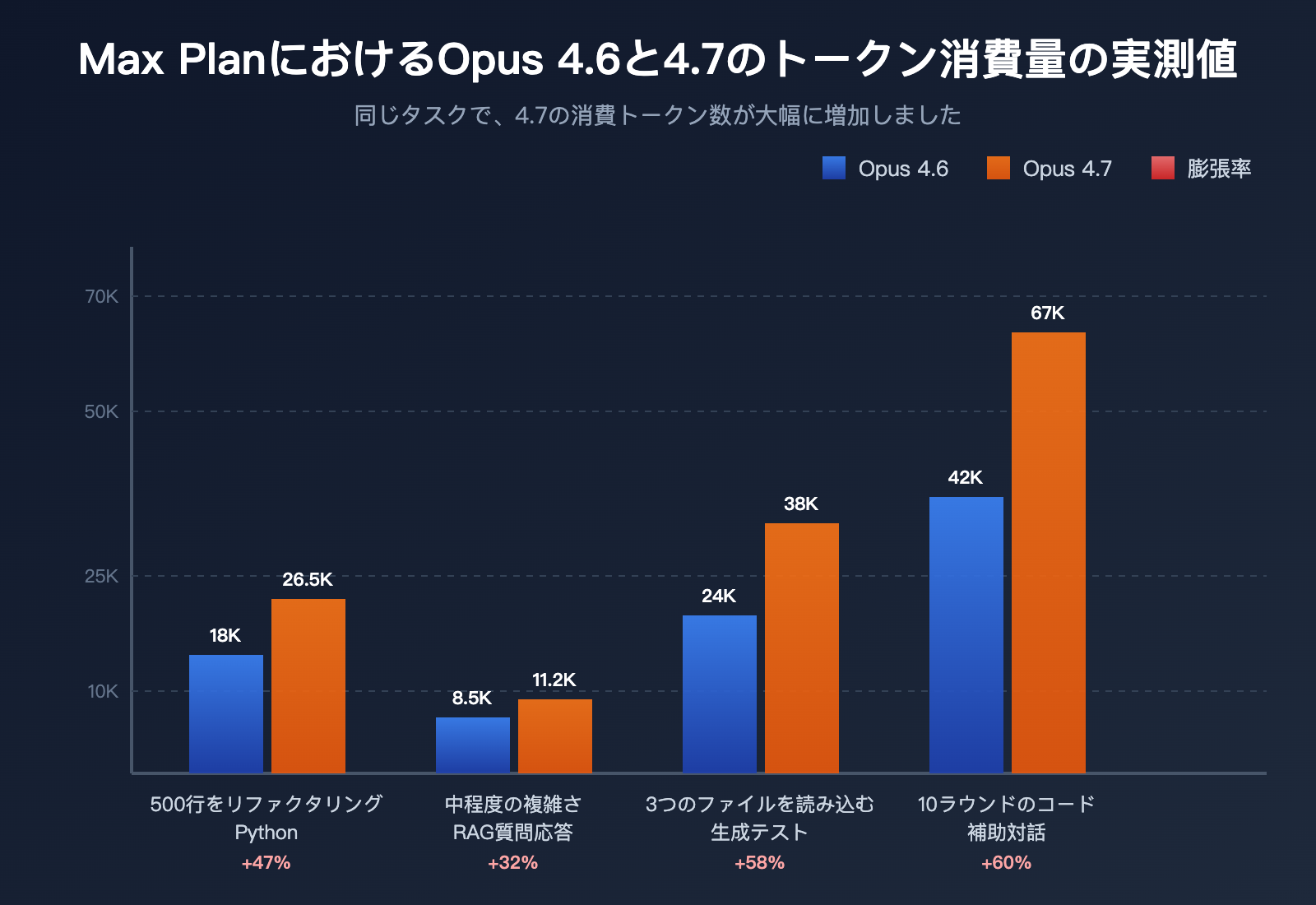
実測データ(3つの典型的なタスク)
コミュニティからの実測フィードバックをまとめました:
| テストタスク | 4.6 消費トークン | 4.7 消費トークン | 増加率 |
|---|---|---|---|
| 500行のPythonモジュールをリファクタリング | ~18,000 | ~26,500 | +47% |
| 中程度の複雑さのRAG質問への回答 | ~8,500 | ~11,200 | +32% |
| 3つのファイルを読み込みテストを生成 | ~24,000 | ~38,000 | +58% |
| 長い対話での10ターンのコード支援 | ~42,000 | ~67,000 | +60% |
このデータからも分かる通り、Opus 4.7 の「持ちが悪い」のは錯覚ではなく、数値で検証可能なシステム上の変化です。
なぜ Anthropic は「価格は変わっていない」と言うのか?
Anthropic は発表の中で以下のように明記しています:
- 入力価格:$5 / 100万トークン(変更なし)
- 出力価格:$25 / 100万トークン(変更なし)
単価レベルでは確かにその通りですが、これは典型的な 「単価のレトリック」 です。単価は変わらなくても、同じタスクで消費されるトークン数が増えれば、最終的な請求額は当然上がります。Finout などのサードパーティのコスト分析プラットフォームでは、この現象を 「変わらない値札の裏にある真のコストストーリー」 と呼んでいます。
💰 コスト管理のアドバイス: トークンコストに敏感な本番環境では、移行前に APIYI (apiyi.com) プラットフォームを使用して、実際のトラフィックでコスト比較テストを行うことを強く推奨します。同プラットフォームは詳細な呼び出し統計とコスト分析をサポートしており、移行が予算に与える影響を定量化するのに役立ちます。
Claude Opus 4.7 の「持ちが悪い」を解決する3つのアクション
すでに 4.7 にアップグレード済み、あるいはダウングレードが難しい場合、以下の3つのアクションを実行することで、利用枠の消費を制御可能な範囲に抑えることができます。
アクション 1:effort を手動で medium または high に下げる
Claude Code が「xhigh」をデフォルトにしているのは「最も複雑なコーディングタスク」向けの最適化ですが、日常的なタスクのほとんどは「medium」や「high」で十分です。
API 呼び出し時に明示的に指定します:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "このコードをリファクタリングして"}],
extra_headers={
"reasoning-effort": "medium"
}
)
effort 設定ごとの実測トークン消費量比較を見る
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
以下のコードのパフォーマンス上の問題を分析し、最適化の提案をしてください。
(ここに 200 行の Python コードを挿入)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
アドバイス:日常的なコード支援には「high」、単純な質問には「medium」を使用し、極めて複雑な複数ファイルのリファクタリングを行う場合にのみ「xhigh」を有効にしてください。
アクション 2:シナリオに応じてモデルを使い分ける
すべてを 4.7 にアップグレードするのではなく、合理的なルーティング戦略を立てましょう。
| ビジネスシナリオ | 推奨モデル | 理由 |
|---|---|---|
| 複数ファイルの Agentic コーディング | Opus 4.7 (xhigh) | エージェントの主戦場 |
| 単一ファイルのコード生成 | Opus 4.7 (high) | アップグレードの恩恵が大きい |
| 高解像度画像の解析 | Opus 4.7 (high) | 視覚的な質が向上 |
| 長文ドキュメントの RAG | Opus 4.6 | MRCR の崩壊を回避 |
| Web リサーチエージェント | GPT-5.4 Pro | BrowseComp がリード |
| 一般的な執筆 / ライティング | Opus 4.6 または Sonnet | トークナイザーのコストが低い |
| 単純な対話 | Haiku / Sonnet | コスパが最高 |
アクション 3:Task Budgets を有効にして単一タスクの消費を制限する
Opus 4.7 で新たに追加された Task Budgets(パブリックベータ)は、エージェントループのコストを制御するための強力なツールです:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "リファクタリングタスク全体を完了して"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
モデルは各応答で残りの予算を確認し、予算に合わせて戦略を自動調整します。予算が厳しいときは核心的なタスクを優先し、余裕があるときは詳細まで掘り下げます。
🎯 総合的なアドバイス: トークン予算に敏感なチームは、APIYI (apiyi.com) プラットフォームを通じて Claude Opus 4.7 の呼び出しを一元管理することをお勧めします。リアルタイムの利用枠監視やマルチモデルルーティング機能により、「持ちが悪い」という感覚を制御可能なコスト曲線へと変えることができます。
title: Claude Opus 4.7 と GPT-5.4 xhigh の横断比較
description: Claude Opus 4.7 と GPT-5.4 xhigh の性能比較、コスト分析、および最適なモデル選定基準を解説。開発者やAIユーザー向けに、効率的なモデル運用とAPI活用術を紹介します。
Claude Opus 4.7 vs GPT-5.4 xhigh 横断比較
ユーザーからのフィードバックに「実測したところ、Opus 4.7 は依然として GPT-5.4 xhigh に及ばない」という意見がありました。これは利用シーンによって評価が分かれる判断です。

直接比較:9 つのベンチマーク
| ベンチマーク | Opus 4.7 | GPT-5.4 | 勝者 |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (企業知識) | Elo 1753 | Elo 1674 | Opus 4.7 |
| 視覚認識 | 98.5% | — | Opus 4.7 |
| BrowseComp (Webリサーチ) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| 長文コンテキスト RAG | 32.2% | 崩壊なし | GPT-5.4 |
| トークンコスト | 1.0–1.35倍 | 安定 | GPT-5.4 |
Opus 4.7 は 9 項目中 6 勝 1 分 2 敗という結果ですが、あなたが最も重要視するシーンでは評価が逆転する可能性があります。
- Web リサーチ(Research Agent やブラウザ自動化など)を多用する場合:GPT-5.4 xhigh は BrowseComp で 10 ポイントのアドバンテージがあります。
- 長文ドキュメントの RAG を行う場合:GPT-5.4 には MRCR の崩壊問題がありません。
- 安定したトークンコストを求める場合:GPT-5.4 は Tokenizer の変更がないためコストが安定しています。
したがって、「Opus 4.7 は GPT-5.4 xhigh に及ばない」という体感は、特定のワークフローにおいては完全に理にかなっています。
モデル選定マトリクス
| 核心的なニーズ | 推奨モデル | 次点 |
|---|---|---|
| マルチファイル Agent コーディング | Opus 4.7 xhigh | Opus 4.6 |
| IDE でのリアルなコーディング | Opus 4.7 high | GPT-5.4 |
| Research Agent(Web リサーチ) | GPT-5.4 Pro | Opus 4.7 |
| 企業知識の Q&A | Opus 4.7 | GPT-5.4 |
| 長文理解 / RAG | Opus 4.6 | GPT-5.4 |
| 高精細な画像理解 | Opus 4.7 | Gemini 3.1 Pro |
| コスト重視 | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 マルチモデル運用のヒント: 現代のAIアプリケーションを単一のモデルでカバーするのは困難です。APIYI (apiyi.com) プラットフォームを活用し、Claude、GPT、Gemini の全モデルを統一的に接続して、シーンごとにスマートにルーティングすることをお勧めします。1 つの APIキーですべての主要モデルを呼び出せるため、モデルデプロイの複雑さを大幅に軽減できます。
Claude Opus 4.7 に関する FAQ
Q1: Claude Opus 4.7 は本当に 4.6 よりも「長持ち」しないのか?
はい、その通りです。ただし「長持ちしない」には 2 つの側面があります。
-
枠(クォータ)レベル:間違いなく消耗が早いです。Tokenizer の 0~35% の膨張に加え、Claude Code がデフォルトで xhigh を使用するため、トークン消費量が 30~80% 増加します。Max Plan を利用しているユーザーからは、枠の減りが早いという声が共通しています。
-
能力レベル:シーンによります。コーディング Agent、Vision、ツール使用などのタスクでは明らかに優れていますが、長文 RAG、Web リサーチ、一般的な執筆作業では性能が落ちるか同等です。
これら特定の Agent タスクを行わないのであれば、Opus 4.7 は単に「高価なモデル」となります。
Q2: Anthropic は「価格は変わっていない」と言っているのに、なぜ請求額が高くなるのか?
公式が言及しているのは「単価」です(入力 100 万トークンあたり $5、出力 100 万トークンあたり $25)。しかし、Opus 4.7 の新しい Tokenizer は同じテキストでも 1.0~1.35 倍のトークンを消費し、さらに xhigh による出力トークンの増加が重なるため、請求額が 4.6 時代から 20~50% 増えるのは珍しくありません。
コストをコントロールしたい場合は、APIYI (apiyi.com) プラットフォームで実トラフィックの比較テストを行うのが有効です。このプラットフォームでは Claude 全シリーズの並列呼び出しと詳細な料金統計が可能です。
Q3: Max Plan の枠の減りが早い場合、どのような対策があるか?
すぐに実行できる 3 つの対策があります。
- effort を high または medium に下げる:Claude Code 設定で xhigh のデフォルトをオフにし、日常タスクには high を使用する。
- 不要な思考ステップをオフにする:簡単な質問に対しては、モデルに深い推論をスキップするよう明示的に指示する。
- Agent 以外のタスクは Sonnet または Opus 4.6 に切り替える:執筆、簡単な質問、翻訳には Opus 4.7 は不要です。
これらを組み合わせることで、Max Plan の消耗を 4.6 時代の水準、あるいはそれ以下に戻すことができます。
Q4: Opus 4.7 に移行したが、4.6 に戻す価値はあるか?
あなたの主要なワークフローによります。
- マルチファイル Agent コーディングが中心:戻さないでください。4.7 は間違いなく強力です。
- 長文 RAG や契約書の分析が中心:すぐに 4.6 に戻してください。MRCR の崩壊が顕著です。
- 混在する場合:すべて戻す必要はありません。シーンごとに使い分けてください。重い Agent タスクには 4.7、それ以外には 4.6 か Sonnet を使いましょう。
API 利用の場合は、model パラメータを claude-opus-4-7 から claude-opus-4-6 に変えるだけで簡単です。
Q5: Opus 4.7 は GPT-5.4 xhigh にすべての面で勝っているのか?
いいえ。公式データでも、Opus 4.7 は 9 つの直接比較で 6 勝 1 分 2 敗ですが、敗北した 2 項目は重要なシーンです。
- BrowseComp(Web リサーチ):GPT-5.4 Pro 89.3% vs Opus 4.7 79.3%
- 長文コンテキスト RAG:GPT-5.4 には MRCR 崩壊のような問題は発生していない
したがって、「Opus 4.7 は GPT-5.4 xhigh に及ばない」というユーザーの指摘は、Web リサーチや長文が核心タスクである場合、完全に正しいと言えます。
APIYI (apiyi.com) プラットフォームを活用し、同一プロジェクト内で Claude と GPT を呼び分け、シーンごとにルーティングするのが最も現実的です。
Q6: 古いプロンプトを Opus 4.7 で使うと出力品質が落ちる。どうすればいいか?
これは 4.7 が「より字面通り」に命令に従うようになったことの副作用です。以下の原則で書き直してみてください。
- 暗示的な意図を明示的な制約にする:例:「もっとプロらしく」→「業界用語を使い、口語的な表現を避けること」へ変更。
- 曖昧な制限を具体的な数値にする:例:「長すぎないように」→「300文字以内に抑えること」へ変更。
- 反例の制約を追加する:受け入れられない出力形式を明示する。
修正の手間はかかりますが、大規模なプロンプトライブラリがある場合は、A/B テストを実施してどのプロンプトを修正すべきか確認することをお勧めします。
Claude Opus 4.7 のメリット・デメリットまとめ
確かな強み(優れた点)
- コーディングエージェント能力の飛躍:SWE-bench Proで64.3%、CursorBenchで70%を記録し、GPT-5.4を上回る性能。
- Vision機能の質的変化:3.75 MPの高解像度に対応し、視覚タスクのベンチマークで98.5%を達成。
- 最強のMCP-Atlasツールチェーン:77.3%のスコアを記録し、公開されている全モデルの中でトップ。
- 指示追従性の向上:厳格な制約があるプロンプトに対して、より制御しやすい出力を実現。
- タスク予算(Task Budgets)によるエージェントのコスト管理能力の向上。
確かな限界(弱い点)
- トークナイザーの膨張(0〜35%):価格据え置きという宣伝文句の裏で、実質的なコスト上昇が発生。
- xhigh設定でのトークン消費量増加:Maxプランの20倍の割当枠が以前より厳しくなっている。
- MRCR(長文脈検索)の大幅低下:78.3%から32.2%へ急落しており、長文ドキュメントを用いたRAGには不向き。
- BrowseCompの退化:Webリサーチのシナリオでは、GPT-5.4 Proに遅れをとる。
- CyberGymのわずかな低下:セキュリティ関連のタスクで若干の性能低下が見られる。
- 古いプロンプトの互換性問題:暗黙的な意図に依存するプロンプトは、書き直しが必要。
まとめ
Claude Opus 4.7 は、非常に典型的な「シナリオ特化型」のアップデートと言えます。その進化のすべては、「Anthropicがエージェントによるコーディングという分野で再び王座を奪還する」という一つの目標に向かっています。この目標は達成されましたが、その代償として「他のすべてのシナリオ」のユーザーが今回のアップグレードのコストを負担する形となっています。
もしあなたがエージェント構築、Claude Codeのヘビーユーザー、あるいはCursorのパワーユーザーであれば、Opus 4.7への即時移行は価値があります。しかし、執筆、RAG、Webリサーチ、あるいはコスト重視の業務がメインであれば、以下の対策をおすすめします。
- 非エージェントタスクのためにOpus 4.6を使い続ける。
- Claude Codeのデフォルトのeffort設定を「xhigh」から「high」に下げる。
- シナリオに合わせて複数のモデルをルーティングする(一律のアップグレードは避ける)。
「価格据え置き」がすべてを物語っているわけではありません。真のコストは、トークナイザー、デフォルトの計算負荷設定、そして推論の深さの中に隠れています。Opus 4.7は「悪い」のではなく、「汎用的ではない」のです。 この点を理解すれば、正しい用途で最大限の価値を引き出すことができるはずです。
Claudeシリーズのモデル呼び出しを統合管理するには、APIYI(apiyi.com)プラットフォームの利用を推奨します。このプラットフォームは、マルチモデルのインテリジェントルーティング、リアルタイムの予算監視、公式と完全互換のAPIを提供しており、Opus 4.7の「シナリオ特化」という課題に対処するための最も実用的なツールです。
参考文献
-
Anthropic 公式発表: Claude Opus 4.7 正式紹介
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: 公式による能力定義と推奨される使用シナリオ
- リンク:
-
Anthropic 公式ドキュメント: Opus 4.7 移行ガイド
- リンク:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 説明: トークナイザーの変更点と xhigh に関する解説
- リンク:
-
Finout コスト分析: 変わらない価格設定の裏にある真のコスト
- リンク:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - 説明: サードパーティによるコスト分析と請求内訳の分解
- リンク:
-
Artificial Analysis 横断比較: GPT-5.4 xhigh vs Claude Opus 比較
- リンク:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - 説明: 独立したサードパーティによるマルチモデル横断比較データ
- リンク:
-
GitHub Issue #23706: Max Plan ユーザーによるトークン消費に関するフィードバック
- リンク:
github.com/anthropics/claude-code/issues/23706 - 説明: Claude Code Max Plan ユーザーによるリアルな使用感のフィードバック
- リンク:
著者: APIYI 技術チーム
公開日: 2026年4月18日
対象モデル: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
技術交流: APIYI (apiyi.com) にてマルチモデルのテスト枠を提供しています。ぜひ実際のシナリオで、モデル間の違いを体感してみてください。