Claude Opus 4.7이 2026년 4월 16일에 출시되었습니다. 출시 이틀 만에 커뮤니티의 반응은 "전면적인 업그레이드"에서 "선택적 업그레이드"로 급변했죠. 문제는 공식 벤치마크 점수가 아니라, 이미 반복적으로 검증된 결론에 있습니다. 바로 "Opus 4.7은 오직 '코딩 에이전트'만을 위한 업그레이드이며, 그 외 모든 시나리오에서는 사실상 다운그레이드"라는 점입니다.
이 글에서는 빙빙 돌리지 않고 **Claude Opus 4.7의 낮은 가성비(不耐用)**에 대한 진짜 이유를 바로 짚어보겠습니다. 왜 Max Plan 20x의 할당량이 전날보다 눈에 띄게 빨리 소진되는지, 왜 긴 문서 RAG 작업은 오히려 4.6보다 못한지, 그리고 왜 예전 프롬프트를 그대로 가져와도 결과물이 더 나빠지는지 명확히 설명해 드립니다.
핵심 가치: 이 글을 다 읽고 나면 어떤 상황에서 즉시 4.7로 전환해야 하고, 또 어떤 상황에서는 4.6을 유지해야 하는지, 그리고 세 가지 설정 조작으로 비용과 품질을 모두 잡는 방법을 확실히 알게 되실 겁니다.

Claude Opus 4.7의 낮은 가성비, 핵심 원인
"가성비가 낮다"는 체감을 이해하려면 두 가지를 구분해야 합니다. 바로 모델 능력의 변화와 요금/할당량의 변화입니다. Opus 4.7은 이 두 가지 측면에서 동시에 조정을 가했는데, 그 혜택을 보는 범위는 매우 좁습니다. 실제로 "에이전트 기능"을 적극적으로 활용하는 사용자들만 혜택을 보고, 일반적인 사용자들은 오히려 비용 부담만 늘어난 셈입니다.
Opus 4.7 업그레이드의 진짜 수혜 계층
Anthropic은 공식 블로그에서 Opus 4.7이 "Opus 4.6으로는 충분하지 않았던(hand-holding이 필요했던) 시나리오"를 위해 설계되었다고 명시했습니다. 즉, 장시간 실행되는 에이전트 기반 코딩 워크플로우, 대규모 다중 파일 코드베이스의 생산 작업, 컴퓨터 사용(computer use) 등이 여기에 해당합니다.
| 수혜 계층 | Opus 4.7 업그레이드 폭 | 대표 시나리오 |
|---|---|---|
| Claude Code 개발자 | ⭐⭐⭐⭐⭐ | 다중 파일 리팩토링, 에이전트 루프 |
| Cursor 사용자 | ⭐⭐⭐⭐⭐ | IDE 내 실제 코딩 작업 |
| 에이전트 툴체인 개발 | ⭐⭐⭐⭐ | MCP-Atlas 모든 모델 중 선두 |
| 시각적 문서 처리 | ⭐⭐⭐⭐ | 3.75 MP 고해상도 해석 |
| 글쓰기/카피라이팅 | ⭐ | 체감 변화 거의 없음 |
| RAG 긴 문서 | 다운그레이드 | MRCR 78.3% → 32.2% |
| 웹 리서치/BrowseComp | 다운그레이드 | 83.7% → 79.3% |
| 네트워크 보안 | 다운그레이드 | CyberGym 73.8% → 73.1% |
| 비용 민감형 생산 | 다운그레이드 | 토크나이저 팽창 0-35% |
🎯 전환 가이드: 앞의 네 가지 유형에 해당하지 않지만, 비즈니스상 4.6과 4.7을 모두 사용해야 한다면 APIYI(apiyi.com) 플랫폼을 통해 시나리오별로 라우팅하는 것을 권장합니다. 해당 플랫폼은 Claude 전체 모델을 통합 인터페이스로 동시에 호출할 수 있어, 무작정 전체 전환을 감행하다 발생하는 성능 저하를 방지할 수 있습니다.
Claude Opus 4.7의 가성비가 떨어지는 세 가지 근본 이유
이유 1: 토크나이저(Tokenizer) 재구조화로 인한 토큰 소모 팽창
Opus 4.7은 완전히 새로운 토크나이저를 사용합니다. 같은 입력 텍스트라도 4.7에서는 이전보다 1.0배에서 최대 1.35배까지 토큰이 더 많이 나뉩니다. 콘텐츠 유형별로 차이가 큽니다.
- 순수 영어 대화: 약 1.0배
- 한국어 콘텐츠: 1.1–1.2배
- 코드 조각: 1.15–1.25배
- JSON/구조화 데이터: 1.2–1.35배
- 다국어 혼합 시나리오: 1.25–1.35배
이유 2: Claude Code 기본 설정으로 xhigh 추론 단계 도입
Claude Code는 4.7 출시와 동시에 모든 플랜의 기본 추론 단계를 high에서 xhigh로 격상했습니다. xhigh는 high와 max 사이의 단계로, 동일한 작업에서도 더 많은 "생각 토큰(thinking tokens)"을 소모하며, 이 부분이 그대로 비용에 반영됩니다.
이유 3: Max Plan 20x 할당량의 토큰 기반 계측
Anthropic의 Max Plan 20x는 명목상 "Pro 할당량의 20배"라고 하지만, 실제 제한의 본질은 요청 수가 아닌 토큰량입니다. 토크나이저 팽창과 xhigh 기본 설정이 동시에 적용되면서 같은 작업을 해도 토큰 잔액이 훨씬 빨리 소진됩니다. 많은 사용자가 "4월 17일에 Opus 4.7을 사용해보니 4월 15일 4.6을 쓸 때보다 Max Plan 할당량 바가 훨씬 빠르게 줄어든다"고 지적하고 있습니다.
Claude Opus 4.7 시나리오별 성능 파노라마
Opus 4.7이 여러분의 작업 환경에서 업그레이드인지, 아니면 오히려 퇴보인지 판단하려면 공식 벤치마크만 봐서는 안 됩니다. 이번 섹션에서는 7가지 실제 사용 시나리오를 통해 하나씩 꼼꼼하게 평가해 보겠습니다.

시나리오 1: 코딩 Agent (확실한 업그레이드)
Opus 4.7의 주 무대입니다. 여러 데이터가 이를 뒷받침합니다.
| 코딩 벤치마크 | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Opus 4.7 향상 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | 미공개 | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | 미공개 | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Opus 4.7은 직접 비교 가능한 9개 벤치마크 중 GPT-5.4를 상대로 6승 1무 2패를 기록하며, Agentic 코딩 분야의 왕좌를 다시 탈환했습니다.
🚀 Agent 시나리오 추천: 프로덕션급 Agent를 구축 중이라면 APIYI(apiyi.com) 플랫폼을 통해 Claude Opus 4.7을 직접 호출해 보세요. Claude 공식 API와 완벽하게 호환되며, xhigh 등급 및 Task Budgets 같은 최신 기능도 지원합니다.
시나리오 2: Vision 시각 인식 (질적인 도약)
Vision은 확실하게 업그레이드된 또 다른 분야입니다.
- 최대 이미지 해상도: 1.15 MP → 3.75 MP (3배)
- 긴 변 픽셀: 기존 대비 2576px까지 확장
- 시각 인식 벤치마크: 54.5% → 98.5%
설계도, 디자인 시안, PDF 스캔본, UI 스크린샷 등을 직접 해석해야 하는 작업에서 체감할 수 있는 큰 변화입니다.
시나리오 3: 긴 문서 RAG (심각한 퇴보)
커뮤니티에서 가장 불만이 많은 부분입니다. MRCR(Multi-Round Context Recall)은 긴 컨텍스트의 호출 능력을 측정하는 표준 벤치마크입니다.
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- 격차: -46.1pt
많은 개발자가 "4.7에 800줄짜리 워크플로우 문서를 줬더니 읽었다고는 하는데, 생성된 내용은 문서와 전혀 상관없다"고 토로하는 이유가 바로 이 수치에 있습니다.
핵심 업무가 긴 문서 질의응답, 계약서 분석, 대규모 코드베이스 검토라면 Opus 4.7은 확실한 퇴보입니다. 4.6 버전을 유지하는 것을 추천합니다.
시나리오 4: 웹 리서치 및 BrowseComp (미세한 퇴보)
BrowseComp는 웹 리서치 작업의 성능을 측정합니다.
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
심층적인 웹 브라우징과 정보 종합이 필요한 Research Agent 시나리오에서는 GPT-5.4 Pro가 여전히 더 강력한 선택지이며, Opus 4.7은 4.6보다도 성능이 떨어집니다.
시나리오 5: 일반적인 글쓰기 및 대화 (체감 거의 없음)
일상적인 글쓰기, 카피라이팅, 대화형 작업에서 Opus 4.7과 4.6의 주관적인 차이는 매우 적습니다. 하지만 토크나이저(Tokenizer) 확장으로 인해 대화당 실제 소모되는 토큰은 4.6 시절보다 10~20% 더 많습니다.
결론: 글쓰기 작업에는 4.6이 더 경제적입니다. 4.7의 성능 향상을 여기서는 거의 느낄 수 없습니다.
시나리오 6: 기존 프롬프트 호환성 (잠재적 퇴보)
Opus 4.7은 지시사항을 훨씬 "문자 그대로" 따릅니다. 4.6처럼 행간의 의미를 스스로 파악하는 능력이 줄어들었습니다. 즉:
- 암시적 의도에 의존하던 프롬프트의 품질이 떨어질 수 있습니다.
- "좀 더 잘 써줘" 같은 모호한 지시를 하면 4.7은 문자 그대로만 수행하려는 경향이 있습니다.
- 암시적인 제약 조건을 "500자 제한", "X 요소 필수 포함"과 같이 명시적인 제약으로 바꿔야 합니다.
4.6 시절에 쌓아둔 프롬프트 라이브러리가 많다면, 마이그레이션 전 시스템적인 회귀 테스트가 필수입니다.
시나리오 7: 사이버 보안 관련 (미세한 퇴보)
CyberGym(사이버 보안 취약점 재현 벤치마크):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
Anthropic 측에서도 이는 새로 추가된 사이버 보안 보호 메커니즘으로 인한 대가임을 인정했습니다. 레드팀 연구나 보안 감사를 수행하는 팀에게는 작지만 분명한 퇴보입니다.
💡 시나리오별 선택 가이드: Opus 4.7과 4.6 중 무엇을 선택할지는 구체적인 애플리케이션 시나리오와 품질 요구사항에 달려 있습니다. 다양한 주류 모델의 통합 인터페이스를 제공하는 APIYI(apiyi.com) 플랫폼을 통해 실제 테스트를 진행하고 빠르게 전환 및 검증해 보시길 권장합니다.
Claude Opus 4.7 Max Plan 할당량 소모 실전 테스트
이 섹션에서는 "왜 체력바(할당량)가 더 빨리 줄어드는가"라는 질문에 대해 집중적으로 답변해 드립니다.
Max Plan 20x 할당량 소모 메커니즘
Claude Max Plan 20x는 기본적으로 토큰 단위로 측정되며, 크게 두 가지 제한이 있습니다.
- 5시간 슬라이딩 윈도우 제한: 단시간 내 과도한 호출 방지
- 주간 메시지 수 상한: 전체 사용량 보호
Opus 4.7 출시 이후 위 두 가지 제한의 절대값은 변하지 않았지만, 토크나이저(Tokenizer)와 xhigh 기본 설정으로 인해 메시지당 평균 토큰 소모량이 눈에 띄게 증가했습니다.
토큰 소모량 팽창의 3가지 원인
| 팽창 원인 | 영향 범위 | 예상 팽창률 |
|---|---|---|
| 새로운 토크나이저 | 모든 입력 | 0% – 35% (콘텐츠 유형에 따라 상이) |
| xhigh 기본 설정 | 추론 작업 출력 | 20% – 60% (high 대비) |
| 더 정교한 문제 해결 | 에이전트 루프 | 10% – 30% (단계 수 증가) |
이 세 가지가 합쳐지면 실제 체감상 Claude Code에서 동일한 작업을 완료했을 때, 4.7은 4.6보다 30% – 80% 더 많은 할당량을 소모하게 됩니다. 이것이 바로 "체력바가 눈에 띄게 빨리 줄어드는" 현상에 대한 수학적 설명입니다.
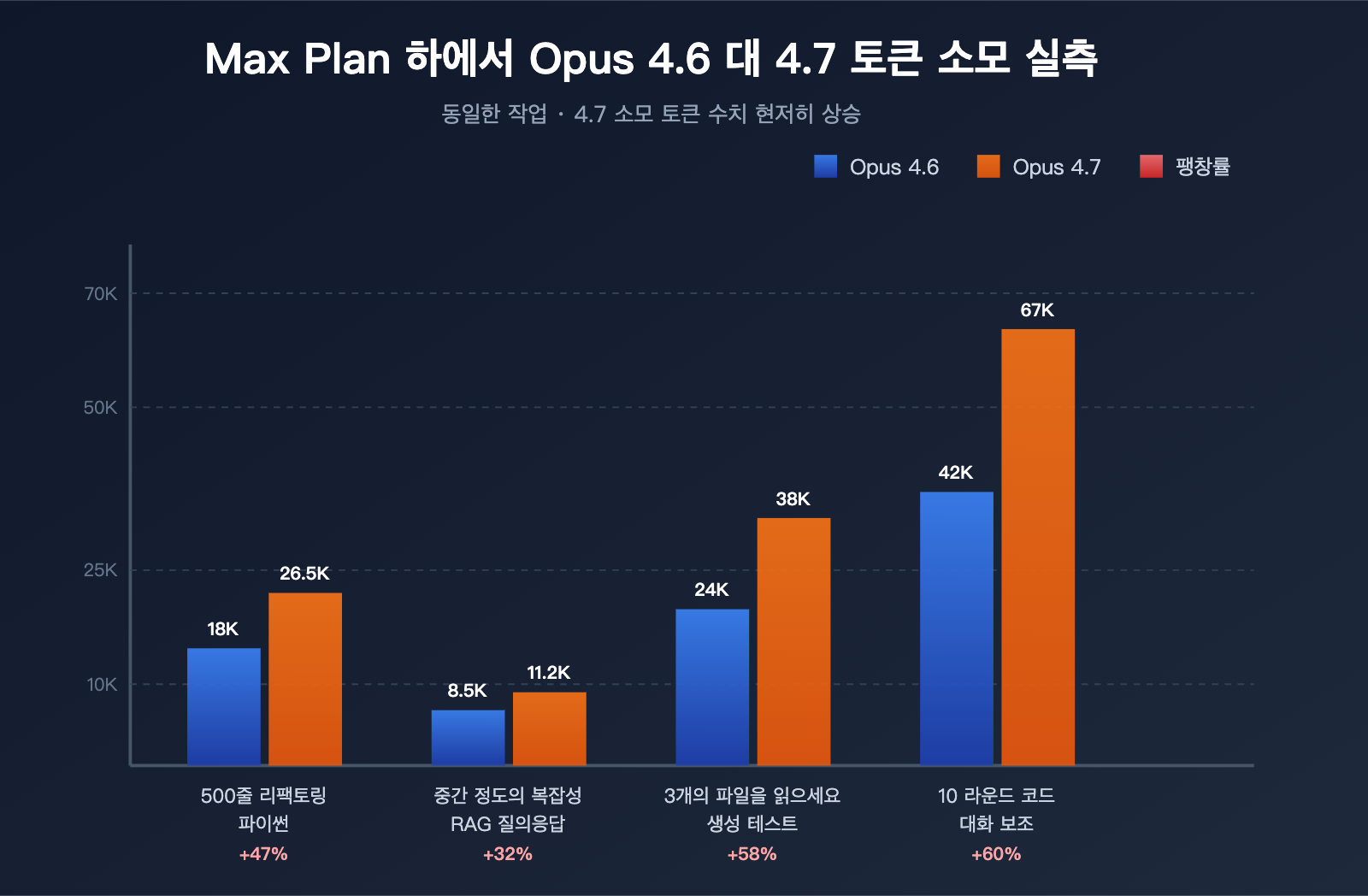
실전 테스트 데이터 (3가지 대표 작업)
커뮤니티의 실전 피드백을 바탕으로 정리한 데이터입니다.
| 테스트 작업 | 4.6 소모 토큰 | 4.7 소모 토큰 | 팽창률 |
|---|---|---|---|
| 500줄 Python 모듈 리팩토링 | ~18,000 | ~26,500 | +47% |
| 중간 난이도 RAG 질문 답변 | ~8,500 | ~11,200 | +32% |
| 파일 3개 읽기 및 테스트 생성 | ~24,000 | ~38,000 | +58% |
| 긴 대화 중 10회 코드 보조 | ~42,000 | ~67,000 | +60% |
이 데이터는 Opus 4.7이 "금방 소모된다"는 것이 착각이 아니라, 정량적으로 검증 가능한 시스템적 변화임을 보여줍니다.
Anthropic은 왜 "가격은 그대로"라고 할까?
Anthropic은 공지사항에서 다음과 같이 명시했습니다.
- 입력 가격: $5 / 100만 토큰 (변동 없음)
- 출력 가격: $25 / 100만 토큰 (변동 없음)
단가 측면에서는 사실이지만, 이는 전형적인 **"단가 마케팅"**입니다. 단가는 그대로지만 동일한 작업에 소모되는 토큰 양이 늘어났으니, 최종 청구 금액은 자연스럽게 오르게 됩니다. Finout과 같은 제3자 비용 분석 플랫폼에서는 이러한 현상을 **"변하지 않은 가격표 뒤에 숨겨진 실제 비용 이야기(Real Cost Story Behind the Unchanged Price Tag)"**라고 부릅니다.
💰 비용 절감 제안: 토큰 비용에 민감한 프로덕션 환경이라면, 마이그레이션 전 APIYI(apiyi.com) 플랫폼을 통해 실제 트래픽으로 비용 비교 테스트를 진행해 보시길 강력히 권장합니다. 해당 플랫폼은 상세한 호출 통계와 비용 분석을 지원하여 마이그레이션이 예산에 미치는 실제 영향을 정량화할 수 있습니다.
Claude Opus 4.7의 빠른 소모를 해결하는 3가지 방법
이미 4.7로 업그레이드했거나 당장 버전을 낮출 수 없는 상황이라면, 할당량 소모를 제어 가능한 범위로 되돌릴 수 있는 3가지 즉각적인 대응책이 있습니다.
방법 1: 수동으로 effort를 medium 또는 high로 낮추기
Claude Code가 xhigh를 기본값으로 설정한 것은 "가장 복잡한 코딩 작업"에 최적화하기 위함이지만, 대부분의 일상적인 작업은 medium이나 high로도 충분합니다.
API 호출 시 명시적으로 설정하세요:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "이 코드를 리팩토링해줘"}],
extra_headers={
"reasoning-effort": "medium"
}
)
effort 단계별 실전 토큰 소모량 비교 확인하기
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
아래 코드의 성능 문제를 분석하고 최적화 제안을 해주세요.
(여기에 200줄 Python 코드 삽입)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
제안: 일상적인 코드 보조에는 high를, 간단한 질문 답변에는 medium을 사용하세요. xhigh는 극도로 복잡한 다중 파일 리팩토링 시에만 사용하는 것이 좋습니다.
방법 2: 작업별로 모델 라우팅하기
모든 작업을 4.7로 일괄 업그레이드하지 마세요. 합리적인 라우팅 전략은 다음과 같습니다.
| 업무 시나리오 | 추천 모델 | 이유 |
|---|---|---|
| 다중 파일 에이전트 코딩 | Opus 4.7 (xhigh) | 에이전트 최적화 |
| 단일 파일 코드 생성 | Opus 4.7 (high) | 업그레이드 효과 확실 |
| 고해상도 이미지 분석 | Opus 4.7 (high) | 시각적 성능 향상 |
| 긴 문서 RAG | Opus 4.6 | MRCR 붕괴 방지 |
| 웹 리서치 에이전트 | GPT-5.4 Pro | BrowseComp 성능 우위 |
| 일반 글쓰기 / 문안 | Opus 4.6 또는 Sonnet | 토크나이저 비용 효율적 |
| 간단한 대화 | Haiku / Sonnet | 가성비 최고 |
방법 3: Task Budgets로 단일 작업 소모량 제한하기
Opus 4.7에 새로 추가된 Task Budgets(공개 베타)는 에이전트 루프 비용을 제어하는 강력한 도구입니다.
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "전체 리팩토링 작업을 완료해줘"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
모델은 매 응답마다 남은 예산을 확인하고, 예산에 맞춰 전략을 자동으로 조정합니다. 예산이 부족하면 핵심 작업부터 우선 처리하고, 충분하면 세부적인 부분까지 깊이 있게 파고듭니다.
🎯 종합 제안: 토큰 예산에 민감한 팀이라면 APIYI(apiyi.com) 플랫폼을 통해 Claude Opus 4.7 호출을 통합 관리하는 것을 추천합니다. 실시간 할당량 모니터링과 다중 모델 라우팅 기능을 통해 "금방 소모된다"는 느낌을 제어 가능한 비용 곡선으로 바꿀 수 있습니다.
Claude Opus 4.7 vs GPT-5.4 xhigh 횡단 비교
사용자 피드백 중 "실제로 테스트해보니 Opus 4.7이 여전히 GPT-5.4 xhigh보다 못한 것 같다"는 의견이 있었습니다. 이는 상황에 따라 다르게 판단해야 할 문제입니다.

9가지 직접 비교 벤치마크
| 벤치마크 | Opus 4.7 | GPT-5.4 | 승자 |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (기업 지식) | Elo 1753 | Elo 1674 | Opus 4.7 |
| 시각 인식 | 98.5% | — | Opus 4.7 |
| BrowseComp (웹 리서치) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| 긴 컨텍스트 RAG | 32.2% | 붕괴 없음 | GPT-5.4 |
| 토큰 비용 | 1.0–1.35배 | 안정적 | GPT-5.4 |
Opus 4.7이 9개 항목 중 6승 1무 2패를 기록했지만, 여러분이 가장 중요하게 생각하는 작업에 따라 결론은 완전히 달라질 수 있습니다.
- 웹 리서치(Research Agent, 브라우저 자동화 등)를 많이 사용하신다면: GPT-5.4 xhigh가 BrowseComp에서 10%p 앞서 있습니다.
- 긴 문서 RAG 작업을 하신다면: GPT-5.4는 MRCR 붕괴 문제가 없습니다.
- 안정적인 토큰 비용을 원하신다면: GPT-5.4는 토크나이저 변화가 없습니다.
따라서 "Opus 4.7이 GPT-5.4 xhigh보다 못하다"는 체감은 특정 워크플로우에서는 충분히 타당한 평가입니다.
모델 선택 매트릭스
| 핵심 요구사항 | 추천 모델 | 차선책 |
|---|---|---|
| 다중 파일 에이전트 코딩 | Opus 4.7 xhigh | Opus 4.6 |
| IDE 내 실전 코딩 | Opus 4.7 high | GPT-5.4 |
| 리서치 에이전트 (웹 리서치) | GPT-5.4 Pro | Opus 4.7 |
| 기업 지식 질의응답 | Opus 4.7 | GPT-5.4 |
| 긴 문서 이해 / RAG | Opus 4.6 | GPT-5.4 |
| 고해상도 이미지 이해 | Opus 4.7 | Gemini 3.1 Pro |
| 비용 민감도가 매우 높음 | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 멀티 모델 배포 제안: 현대 AI 애플리케이션은 단일 모델로 모든 상황을 커버하기 어렵습니다. APIYI(apiyi.com) 플랫폼을 통해 Claude, GPT, Gemini 전 라인업을 통합하여 상황에 맞게 스마트하게 라우팅하는 것을 추천합니다. 하나의 API 키로 모든 주요 모델을 호출할 수 있어 배포 복잡성을 획기적으로 줄여줍니다.
Claude Opus 4.7 내구성 관련 FAQ
Q1: Claude Opus 4.7이 정말 4.6보다 내구성이 떨어지나요?
네, 하지만 '내구성'은 두 가지 측면에서 이해해야 합니다.
-
할당량(Quota) 측면: 확실히 더 빨리 소모됩니다. 토크나이저가 0
35% 팽창했고, Claude Code의 기본 설정이 xhigh라 토큰 소비가 3080% 증가했습니다. Max Plan 20x 사용자들은 할당량 바가 훨씬 빨리 줄어든다고 입을 모읍니다. -
능력 측면: 상황에 따라 다릅니다. 코딩 에이전트, 비전, 툴 사용 작업에서는 확실히 강력하지만, 긴 문서 RAG, 웹 리서치, 일반적인 글쓰기 작업에서는 더 약하거나 비슷합니다.
이러한 에이전트 작업을 하지 않는다면, Opus 4.7은 단순히 '더 비싼 모델'일 뿐입니다.
Q2: Anthropic은 “가격은 그대로”라고 했는데 왜 청구 금액이 늘었나요?
공식적으로 밝힌 단가는 동일합니다(입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $25). 하지만 Opus 4.7의 새로운 토크나이저 때문에 같은 텍스트라도 1.01.35배 더 많은 토큰이 소모되며, xhigh 출력 토큰 팽창까지 더해져 4.6 시절보다 청구 금액이 2050% 상승하는 경우가 많습니다.
비용을 제어하고 싶다면 APIYI(apiyi.com) 플랫폼에서 실제 트래픽 비교 테스트를 해보세요. Claude 전 라인업의 병렬 호출과 상세한 비용 통계를 지원합니다.
Q3: Max Plan 20x 할당량이 너무 빨리 소모되는데, 해결책이 있을까요?
즉시 실행 가능한 세 가지 방법입니다:
- Effort를 high 또는 medium으로 낮추기: Claude Code 설정에서 xhigh 기본값을 끄고, 일상적인 작업에는 high를 사용하세요.
- 불필요한 사고 단계 끄기: 긴 대화 중 간단한 질문은 모델이 깊은 추론을 건너뛰도록 명시하세요.
- 에이전트 작업이 아니면 Sonnet이나 Opus 4.6으로 전환: 글쓰기, 간단한 질의응답, 번역에는 Opus 4.7이 필요 없습니다.
이 세 가지만 실천해도 Max Plan 할당량 소모를 4.6 시절 수준 혹은 그 이하로 되돌릴 수 있습니다.
Q4: 이미 Opus 4.7로 마이그레이션했는데, 4.6으로 돌아가는 게 좋을까요?
핵심 워크플로우에 따라 다릅니다.
- 다중 파일 에이전트 코딩 위주: 돌아가지 마세요. 4.7이 확실히 더 강력합니다.
- 긴 문서 RAG / 계약서 분석 위주: 즉시 4.6으로 돌아가세요. MRCR 붕괴가 심각합니다.
- 혼합 작업: 전부 돌아갈 필요 없이 상황에 맞춰 라우팅하세요. 에이전트 작업은 4.7, 나머지는 4.6이나 Sonnet을 사용하세요.
API 호출 시 model 파라미터를 claude-opus-4-7에서 claude-opus-4-6으로 바꾸기만 하면 됩니다.
Q5: Opus 4.7이 모든 상황에서 GPT-5.4 xhigh보다 강력한가요?
아닙니다. 공식 데이터상 Opus 4.7이 9개 벤치마크 중 6승 1무 2패를 기록했지만, 패배한 두 분야가 핵심적입니다.
- BrowseComp(웹 리서치): GPT-5.4 Pro 89.3% vs Opus 4.7 79.3%
- 긴 컨텍스트 RAG: GPT-5.4는 MRCR 붕괴 현상이 없음
따라서 "실제 테스트해보니 Opus 4.7이 GPT-5.4 xhigh보다 못하다"는 사용자 의견은, 웹 리서치나 긴 문서 작업이 핵심인 경우 충분히 사실일 수 있습니다.
APIYI(apiyi.com) 플랫폼을 사용하면 동일한 프로젝트 내에서 Claude와 GPT를 동시에 호출하여 상황별로 라우팅할 수 있으니, 현재로서는 가장 실용적인 방법입니다.
Q6: 기존 프롬프트가 Opus 4.7에서 출력 품질이 떨어졌는데 어떻게 하죠?
4.7이 지시사항을 더 '문자 그대로' 받아들이면서 생기는 부작용입니다. 수정 원칙은 다음과 같습니다.
- 암시적 의도를 명시적 제약으로: "더 전문적으로 써줘" → "업계 용어를 사용하고 구어체 표현을 피할 것"
- 모호한 제한을 수치화: "너무 길지 않게" → "300자 이내로 작성할 것"
- 반례 제약 추가: 모델에게 허용되지 않는 출력 형식을 알려주세요.
작업량이 많을 수 있으므로, 대규모 프롬프트 라이브러리의 경우 A/B 테스트를 통해 수정이 필요한 프롬프트를 먼저 선별하는 것을 추천합니다.
Claude Opus 4.7 장단점 요약
확실한 강점 (인정할 수밖에 없는 부분)
- 코딩 에이전트 능력 비약적 상승: SWE-bench Pro 64.3%, CursorBench 70% 기록, GPT-5.4 능가
- 비전(Vision) 기능의 질적 변화: 3.75 MP 고해상도 지원, 시각적 벤치마크 98.5% 달성
- 최강의 MCP-Atlas 툴체인: 77.3%로 공개된 모든 모델 중 선두
- 더 정교해진 프롬프트 준수: 제약 조건이 명확한 프롬프트에서 훨씬 더 통제된 결과물 출력
- Task Budgets를 통한 에이전트 비용 관리 능력 확보
현실적인 한계 (부족한 부분)
- 토크나이저(Tokenizer) 팽창 0-35%: 가격은 그대로인 척하지만 실제 비용 상승 발생
- xhigh 기본 설정으로 인한 출력 토큰 소모 증가: Max Plan의 20배 할당량이 눈에 띄게 부족해짐
- MRCR 긴 컨텍스트 성능 급락: 78.3% → 32.2%로 하락, 긴 문서 RAG 작업 시 사용 불가
- BrowseComp 성능 퇴보: 웹 리서치 시나리오에서 GPT-5.4 Pro에 밀림
- CyberGym 소폭 퇴보: 보안 관련 작업에서 성능이 다소 저하됨
- 기존 프롬프트 호환성 문제: 암묵적인 의도에 의존하는 프롬프트는 재작성 필요
요약
Claude Opus 4.7은 매우 전형적인 '특정 분야 편중형' 업그레이드입니다. 모든 개선 사항은 Anthropic이 에이전트 기반 코딩 분야에서 다시 왕좌를 차지하겠다는 하나의 목표를 향해 있습니다. 목표는 달성했지만, 그 대가로 '다른 모든 시나리오'의 사용자들이 이번 업그레이드의 비용을 함께 치르게 되었습니다.
만약 에이전트를 구축하거나 Claude Code, Cursor를 헤비하게 사용하신다면 Opus 4.7로 즉시 전환할 가치가 있습니다. 하지만 핵심 작업이 글쓰기, RAG, 웹 리서치, 비용 효율적인 생산이라면 다음을 권장합니다.
- 비 에이전트 작업용으로 Opus 4.6 유지
- Claude Code의 기본 effort 설정을 xhigh에서 high로 하향 조정
- 상황에 맞춰 여러 모델을 라우팅하여 사용, 무조건적인 업그레이드는 지양
"가격은 그대로"라는 말은 결코 전체 이야기가 아닙니다. 실제 비용은 토크나이저, 기본 설정값, 추론 깊이 속에 숨어 있습니다. Opus 4.7은 나쁜 모델이 아니라, 범용적이지 않은 모델입니다. 이 점을 이해한다면 Opus 4.7의 가치를 제대로 활용하실 수 있을 겁니다.
Claude 전 시리즈의 모델 호출을 통합 관리하려면 APIYI(apiyi.com) 플랫폼을 추천합니다. 이 플랫폼은 멀티 모델 지능형 라우팅, 실시간 할당량 모니터링, 공식 API와 완벽하게 호환되는 인터페이스를 제공하여 Opus 4.7의 '편중된 성능' 문제를 해결할 가장 실용적인 도구가 될 것입니다.
참고 자료
-
Anthropic 공식 발표: Claude Opus 4.7 정식 소개
- 링크:
anthropic.com/news/claude-opus-4-7 - 설명: 공식적인 모델 기능 정의 및 추천 사용 사례
- 링크:
-
Anthropic 공식 문서: Opus 4.7 마이그레이션 가이드
- 링크:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 설명: 토크나이저 변화 및 xhigh 모드에 대한 상세 설명
- 링크:
-
Finout 비용 분석: 가격표 그 이면의 실제 비용
- 링크:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - 설명: 제3자 관점에서의 비용 분석 및 청구서 내역 상세 분석
- 링크:
-
Artificial Analysis 비교 평가: GPT-5.4 xhigh vs Claude Opus 비교
- 링크:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - 설명: 독립적인 제3자 기관의 다중 모델 비교 데이터
- 링크:
-
GitHub Issue #23706: Max Plan 사용자 토큰 소모 관련 피드백
- 링크:
github.com/anthropics/claude-code/issues/23706 - 설명: Claude Code Max Plan 사용자의 실제 체감 경험 피드백
- 링크:
작성자: APIYI 기술팀
발행일: 2026-04-18
적용 모델: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
기술 교류: APIYI(apiyi.com)를 통해 다양한 모델의 테스트 크레딧을 제공받아, 여러 시나리오에서 모델 간의 실제 차이를 직접 경험해 보세요.