Claude Opus 4.7 dirilis pada 16 April 2026. Dalam dua hari, sentimen komunitas berubah drastis dari "peningkatan menyeluruh" menjadi "peningkatan selektif". Masalahnya bukan pada skor benchmark resmi, melainkan pada kesimpulan yang telah berulang kali divalidasi: Opus 4.7 hanyalah peningkatan yang disiapkan untuk "Agent pembuat kode", dan merupakan penurunan kualitas untuk semua skenario lainnya.
Artikel ini akan langsung menjawab alasan mengapa Claude Opus 4.7 terasa tidak awet: Mengapa kuota Max Plan 20x Anda habis jauh lebih cepat dibandingkan hari sebelumnya? Mengapa skenario RAG dokumen panjang justru terasa lebih buruk daripada 4.6? Mengapa petunjuk lama yang digunakan justru menghasilkan output yang semakin menurun kualitasnya?
Nilai Inti: Setelah membaca artikel ini, Anda akan tahu dengan pasti—skenario mana yang harus segera beralih ke 4.7, skenario mana yang harus tetap di 4.6, serta cara menggunakan tiga langkah konfigurasi untuk menyeimbangkan biaya dan kualitas.

Alasan Utama Mengapa Claude Opus 4.7 Tidak Awet
Untuk memahami sensasi "tidak awet" ini, kita perlu membedakan dua hal: perubahan kemampuan model dan perubahan penagihan/kuota. Opus 4.7 melakukan penyesuaian pada kedua dimensi tersebut, dan penerima manfaat dari penyesuaian ini sangat terbatas—hanya pengguna yang benar-benar memanfaatkan kemampuan Agent yang mendapatkan keuntungan, sementara sebagian besar pengguna harian justru menanggung biaya lebih.
Kelompok yang Benar-benar Diuntungkan oleh Pembaruan Opus 4.7
Dalam blog resminya, Anthropic menyatakan dengan jelas bahwa Opus 4.7 dirancang untuk "skenario di mana Opus 4.6 membutuhkan bantuan (hand-holding)": alur kerja pengkodean Agentic yang berjalan lama, tugas tingkat produksi pada basis kode multi-file yang besar, penggunaan komputer (computer use), dan skenario lainnya.
| Kelompok Penerima Manfaat | Peningkatan Opus 4.7 | Skenario Tipikal |
|---|---|---|
| Pengembang Claude Code | ⭐⭐⭐⭐⭐ | Refactoring multi-file, loop Agent |
| Pengguna Cursor | ⭐⭐⭐⭐⭐ | Tugas pengkodean nyata di IDE |
| Pengembangan Rantai Alat Agentic | ⭐⭐⭐⭐ | MCP-Atlas mengungguli semua model |
| Pemrosesan Dokumen Visual | ⭐⭐⭐⭐ | Resolusi tinggi 3,75 MP |
| Pengguna Penulisan/Copywriting | ⭐ | Hampir tidak terasa peningkatannya |
| RAG Dokumen Panjang | Penurunan | MRCR 78,3% → 32,2% |
| Riset Web/BrowseComp | Penurunan | 83,7% → 79,3% |
| Terkait Keamanan Siber | Penurunan | CyberGym 73,8% → 73,1% |
| Produksi Sensitif Biaya | Penurunan | Ekspansi Tokenizer 0-35% |
🎯 Saran Migrasi: Jika Anda bukan termasuk empat kategori pengguna di atas, tetapi bisnis Anda perlu memanggil 4.6 dan 4.7 secara bersamaan, disarankan untuk melakukan routing berdasarkan skenario melalui platform APIYI (apiyi.com). Platform ini mendukung antarmuka terpadu untuk memanggil seluruh seri model Claude secara bersamaan, guna menghindari penurunan performa akibat migrasi yang "dipukul rata".
Tiga Alasan Mendasar Mengapa Claude Opus 4.7 "Tidak Awet"
Alasan 1: Rekonstruksi Tokenizer menyebabkan pembengkakan konsumsi Token
Opus 4.7 menggunakan Tokenizer yang benar-benar baru. Potongan teks input yang sama akan dipecah menjadi 1,0 hingga 1,35 kali lipat jumlah Token pada 4.7. Rasio ini menunjukkan perbedaan yang jelas pada berbagai jenis konten:
- Percakapan bahasa Inggris murni: mendekati 1,0×
- Konten bahasa Indonesia: 1,1–1,2×
- Potongan kode: 1,15–1,25×
- JSON/data terstruktur: 1,2–1,35×
- Skenario campuran multibahasa: 1,25–1,35×
Alasan 2: Claude Code mengaktifkan tingkat penalaran xhigh secara default
Bersamaan dengan peluncuran 4.7, Claude Code meningkatkan tingkat penalaran default untuk semua paket dari high ke xhigh. xhigh berada di antara high dan max, yang akan mengonsumsi lebih banyak "Token pemikiran" (thinking tokens) pada tugas yang sama, dan konsumsi bagian ini langsung masuk ke dalam tagihan Anda.
Alasan 3: Kuota Max Plan 20x dihitung berdasarkan Token
Meskipun Max Plan 20x dari Anthropic secara nominal adalah "kuota 20 kali Pro", esensi dari batas bawahnya adalah Token, bukan jumlah permintaan. Ketika pembengkakan Tokenizer + default xhigh terjadi secara bersamaan, operasi yang sama akan mengonsumsi kuota Token jauh lebih cepat. Banyak pengguna melaporkan: saat menggunakan Opus 4.7 pada 17 April, bar kuota Max Plan habis jauh lebih cepat dibandingkan saat menggunakan 4.6 pada 15 April.
Panorama Performa Skenario Claude Opus 4.7
Untuk menilai apakah Opus 4.7 merupakan peningkatan atau penurunan bagi skenario penggunaan Anda, jangan hanya melihat tolok ukur yang dipilih oleh pihak resmi. Bagian ini akan mengevaluasi satu per satu berdasarkan 7 skenario penggunaan nyata.

Skenario 1: Agent Pengodean (Peningkatan Signifikan)
Ini adalah kandang dari Opus 4.7. Banyak data memvalidasi hal ini:
| Tolok Ukur Pengodean | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Peningkatan Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | Tidak diungkap | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | Tidak diungkap | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Dalam 9 tolok ukur yang bisa dibandingkan secara langsung, Opus 4.7 mencetak skor 6 menang, 1 seri, dan 2 kalah melawan GPT-5.4, untuk pertama kalinya merebut kembali gelar juara pengodean Agentic dari GPT-5.4.
🚀 Rekomendasi Skenario Agent: Jika Anda sedang membangun Agent kelas produksi, disarankan untuk melakukan pemanggilan model Claude Opus 4.7 secara langsung melalui platform APIYI apiyi.com. Platform ini menyediakan antarmuka yang sepenuhnya kompatibel dengan standar Claude, mendukung fitur baru seperti tingkatan xhigh dan Task Budgets.
Skenario 2: Identifikasi Visual Vision (Peningkatan Kualitatif)
Vision adalah skenario lain yang mengalami peningkatan nyata:
- Resolusi gambar maksimum: 1.15 MP → 3.75 MP (3×)
- Piksel sisi panjang: Dari standar hingga 2576px
- Tolok ukur identifikasi visual: 54.5% → 98.5%
Bagi skenario yang membutuhkan kemampuan membaca bagan arsitektur, draf desain, dokumen PDF pindaian, dan tangkapan layar UI secara langsung, ini adalah peningkatan yang terasa secara kualitatif.
Skenario 3: RAG Dokumen Panjang (Penurunan Serius)
Ini adalah keluhan yang paling banyak muncul di komunitas. MRCR (Multi-Round Context Recall) adalah tolok ukur standar untuk mengukur kemampuan pemanggilan kembali (recall) konteks panjang:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- Selisih: -46.1pt
Angka ini menjelaskan mengapa banyak pengembang melaporkan: "Memberikan dokumen alur kerja 800 baris ke 4.7, ia mengaku telah membacanya, tetapi konten yang dihasilkan justru sama sekali tidak berhubungan dengan dokumen tersebut."
Jika bisnis inti Anda adalah tanya jawab dokumen panjang, analisis kontrak, atau pemeriksaan basis kode besar, Opus 4.7 adalah penurunan yang jelas, disarankan untuk tetap menggunakan 4.6.
Skenario 4: Riset Web dan BrowseComp (Penurunan Ringan)
BrowseComp mengukur kinerja tugas riset Web:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
Dalam skenario Research Agent yang membutuhkan penjelajahan Web secara mendalam dan sintesis informasi, GPT-5.4 Pro tetap menjadi pilihan yang lebih kuat, sementara Opus 4.7 bahkan tidak lebih baik dari 4.6.
Skenario 5: Penulisan Umum dan Percakapan (Hampir Tidak Terasa)
Untuk penulisan sehari-hari, pembuatan konten, dan tugas percakapan, perbedaan subjektif antara Opus 4.7 dan 4.6 sangat terbatas. Namun, karena adanya ekspansi Tokenizer, setiap percakapan Anda akan mengonsumsi Token 10-20% lebih tinggi dibandingkan era 4.6.
Kesimpulan: Skenario penulisan lebih hemat menggunakan 4.6, peningkatan kemampuan 4.7 di sini hampir tidak terlihat.
Skenario 6: Kompatibilitas Petunjuk Lama (Potensi Penurunan)
Instruksi Opus 4.7 menjadi lebih "literal" — ia tidak lagi proaktif dalam "membaca makna di balik kata-kata" seperti 4.6. Ini berarti:
- Petunjuk yang mengandalkan niat tersirat akan menghasilkan kualitas yang menurun
- Menggunakan instruksi samar seperti "tolong buat lebih baik", 4.7 cenderung mengeksekusi sesuai makna harfiahnya
- Perlu mengubah batasan tersirat menjadi batasan eksplisit (seperti "batas 500 kata", "harus menyertakan elemen X")
Jika Anda memiliki banyak koleksi pustaka petunjuk dari era 4.6, Anda perlu melakukan pengujian regresi sistematis sebelum bermigrasi.
Skenario 7: Keamanan Siber (Penurunan Kecil)
CyberGym (tolok ukur reproduksi kerentanan keamanan siber):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
Pihak Anthropic mengakui ini adalah konsekuensi dari mekanisme perlindungan keamanan siber yang baru ditambahkan. Bagi tim yang melakukan riset red team atau audit keamanan, ini adalah penurunan kecil namun nyata.
💡 Saran Pemilihan Skenario: Memilih Opus 4.7 atau 4.6 sangat bergantung pada skenario aplikasi dan kebutuhan kualitas Anda. Kami menyarankan untuk melakukan perbandingan pengujian secara nyata melalui platform APIYI apiyi.com yang mendukung antarmuka terpadu untuk berbagai model utama, sehingga memudahkan peralihan dan verifikasi yang cepat.
Uji Coba Konsumsi Kuota Claude Opus 4.7 Max Plan
Bagian ini khusus menjawab pertanyaan "mengapa kuota habis lebih cepat".
Mekanisme Konsumsi Kuota Claude Max Plan 20x
Claude Max Plan 20x diukur berdasarkan Token, dengan dua batasan inti:
- Batas Jendela Geser 5 Jam: Mencegah pemanggilan dalam jumlah sangat besar dalam waktu singkat.
- Batas Pesan Mingguan: Perlindungan penggunaan secara keseluruhan.
Setelah Opus 4.7 dirilis, nilai absolut dari kedua batasan tersebut tidak berubah, namun karena Tokenizer baru dan pengaturan default xhigh, konsumsi Token rata-rata per pesan meningkat secara signifikan.
Tiga Sumber Lonjakan Konsumsi Token
| Sumber Lonjakan | Ruang Lingkup | Estimasi Laju Lonjakan |
|---|---|---|
| Tokenizer Baru | Semua input | 0% – 35% (tergantung jenis konten) |
| Default xhigh | Output tugas penalaran | 20% – 60% (relatif terhadap high) |
| Penyelesaian Lebih Ketat | Loop Agen | 10% – 30% (peningkatan jumlah langkah) |
Hasil nyata setelah menggabungkan ketiga faktor tersebut: pekerjaan yang sama diselesaikan di Claude Code menggunakan 4.7 menghabiskan kuota 30% – 80% lebih banyak daripada 4.6. Inilah penjelasan matematis mengapa "bar kuota habis lebih cepat dari yang terlihat".
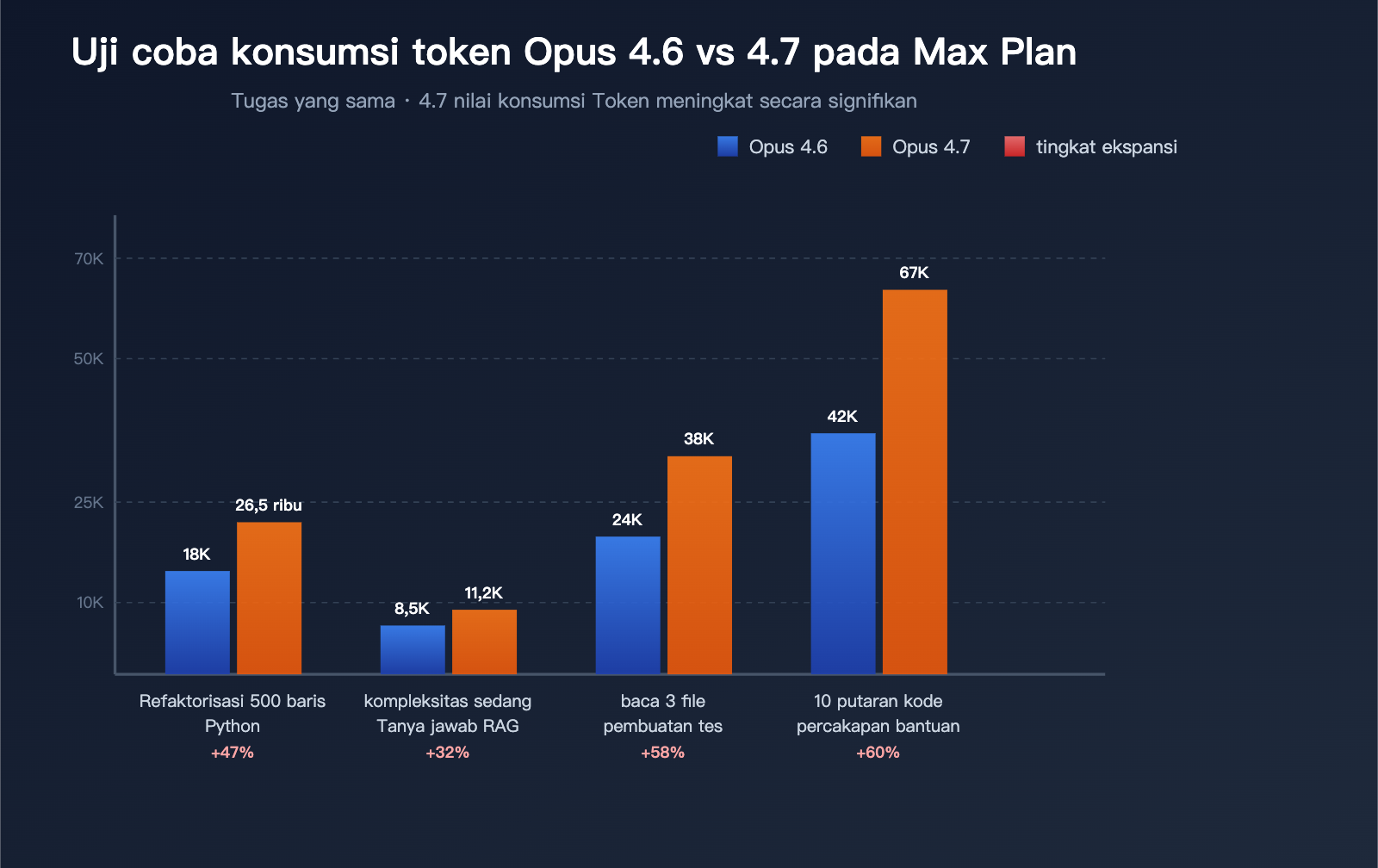
Data Uji Coba (3 Tugas Tipikal)
Dirangkum berdasarkan umpan balik komunitas:
| Tugas Uji Coba | Konsumsi Token 4.6 | Konsumsi Token 4.7 | Laju Lonjakan |
|---|---|---|---|
| Refaktor modul Python 500 baris | ~18.000 | ~26.500 | +47% |
| Menjawab pertanyaan RAG yang cukup kompleks | ~8.500 | ~11.200 | +32% |
| Membaca 3 file dan membuat pengujian | ~24.000 | ~38.000 | +58% |
| 10 putaran bantuan kode dalam obrolan panjang | ~42.000 | ~67.000 | +60% |
Data ini menjelaskan: Opus 4.7 yang "tidak awet" bukanlah sekadar perasaan, melainkan perubahan sistemik yang dapat diverifikasi dan diukur.
Mengapa Anthropic Mengatakan "Harga Tidak Berubah"?
Anthropic menyatakan dalam pengumuman resminya:
- Harga input: $5 / juta Token (tidak berubah)
- Harga output: $25 / juta Token (tidak berubah)
Hal ini memang benar di tingkat harga satuan, namun ini adalah "retorika harga satuan" yang klasik—harga satuan tidak berubah, tetapi jumlah Token yang dikonsumsi untuk tugas yang sama meningkat, sehingga tagihan akhir secara alami naik. Platform analisis biaya pihak ketiga seperti Finout menyebut fenomena ini sebagai "Kisah Biaya Nyata di Balik Label Harga yang Tidak Berubah".
💰 Saran Kontrol Biaya: Untuk lingkungan produksi yang sensitif terhadap biaya Token, sangat disarankan untuk melakukan uji perbandingan tagihan dengan lalu lintas nyata melalui platform APIYI (apiyi.com) sebelum bermigrasi. Platform ini mendukung statistik pemanggilan dan analisis biaya yang detail, sehingga memudahkan untuk mengukur dampak nyata migrasi terhadap anggaran Anda.
Tiga Tindakan Solutif untuk Claude Opus 4.7 yang Tidak Awet
Jika Anda sudah meningkatkan ke versi 4.7 atau belum bisa melakukan rollback, berikut tiga tindakan yang bisa segera dilakukan agar konsumsi kuota tetap dalam batas yang terkendali.
Tindakan 1: Secara manual turunkan effort ke medium atau high
Claude Code menetapkan xhigh sebagai standar karena optimasi untuk "tugas pengkodean paling kompleks", namun untuk sebagian besar tugas harian, medium atau high sudah cukup memadai.
Tentukan secara eksplisit dalam pemanggilan API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refaktor kode ini"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Lihat perbandingan konsumsi Token untuk setiap tingkat effort
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Tolong analisis masalah performa kode di bawah ini dan berikan saran optimasi.
(Sisipkan 200 baris kode Python di sini)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Saran: Untuk bantuan kode harian, gunakan high; untuk tanya jawab sederhana, gunakan medium; aktifkan xhigh hanya saat menangani refaktor multi-file yang sangat kompleks.
Tindakan 2: Gunakan perutean model yang berbeda berdasarkan skenario
Jangan "menyamaratakan" semuanya ke 4.7. Strategi perutean yang masuk akal:
| Skenario Bisnis | Model Rekomendasi | Alasan |
|---|---|---|
| Pengkodean Agen multi-file | Opus 4.7 (xhigh) | Keunggulan Agen |
| Pembuatan kode file tunggal | Opus 4.7 (high) | Manfaat peningkatan terlihat jelas |
| Analisis gambar resolusi tinggi | Opus 4.7 (high) | Peningkatan kualitas visual |
| RAG dokumen panjang | Opus 4.6 | Menghindari keruntuhan MRCR |
| Agen Riset Web | GPT-5.4 Pro | Unggul di BrowseComp |
| Penulisan biasa / Copywriting | Opus 4.6 atau Sonnet | Biaya Token lebih murah |
| Obrolan sederhana | Haiku / Sonnet | Paling hemat biaya |
Tindakan 3: Aktifkan Task Budgets untuk membatasi konsumsi per tugas
Task Budgets (beta) yang baru ditambahkan di Opus 4.7 adalah alat ampuh untuk mengendalikan biaya loop Agen:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Selesaikan seluruh tugas refaktor"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
Model akan melihat sisa anggaran di setiap putaran respons dan secara otomatis menyesuaikan strategi berdasarkan anggaran—memprioritaskan tugas inti saat anggaran terbatas, dan menggali detail saat anggaran mencukupi.
🎯 Saran Komprehensif: Untuk tim yang sensitif terhadap anggaran Token, disarankan untuk mengelola pemanggilan Claude Opus 4.7 melalui platform APIYI (apiyi.com). Platform ini menyediakan pemantauan kuota real-time dan kemampuan perutean multi-model, yang membantu Anda mengubah kesan "tidak awet" menjadi kurva biaya yang terkendali.
Perbandingan Horizontal Claude Opus 4.7 vs GPT-5.4 xhigh
Dalam umpan balik pengguna disebutkan: "Dalam pengujian saya, Opus 4.7 tampaknya masih belum bisa menandingi GPT-5.4 xhigh." Ini adalah penilaian yang perlu dibahas berdasarkan skenario penggunaan.

9 Tolok Ukur Perbandingan Langsung
| Tolok Ukur | Opus 4.7 | GPT-5.4 | Pemenang |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (Pengetahuan Perusahaan) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Pengenalan Visual | 98.5% | — | Opus 4.7 |
| BrowseComp (Riset Web) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG Konteks Panjang | 32.2% | Tidak runtuh | GPT-5.4 |
| Biaya Token | 1.0–1.35× | Stabil | GPT-5.4 |
Opus 4.7 meraih 6 kemenangan, 1 seri, dan 2 kekalahan dari 9 tolok ukur, namun dalam skenario yang paling Anda perhatikan, kesimpulannya bisa jadi sebaliknya:
- Jika skenario pengujian Anda sangat bergantung pada riset web (misalnya Research Agent, otomatisasi browser), GPT-5.4 xhigh memang unggul 10 poin persentase di BrowseComp.
- Jika Anda melakukan RAG dokumen panjang, GPT-5.4 tidak mengalami masalah keruntuhan MRCR.
- Jika Anda mengejar kurva biaya token yang stabil, Tokenizer GPT-5.4 tidak mengalami perubahan.
Jadi, perasaan bahwa "Opus 4.7 tidak bisa menandingi GPT-5.4 xhigh" sangat masuk akal untuk alur kerja tertentu.
Matriks Keputusan Pemilihan Model
| Kebutuhan Utama Anda | Model Pilihan Utama | Alternatif |
|---|---|---|
| Pengodean Agentik multi-file | Opus 4.7 xhigh | Opus 4.6 |
| Tugas pengodean nyata di IDE | Opus 4.7 high | GPT-5.4 |
| Research Agent (Riset Web) | GPT-5.4 Pro | Opus 4.7 |
| Tanya jawab pengetahuan perusahaan | Opus 4.7 | GPT-5.4 |
| Pemahaman dokumen panjang / RAG | Opus 4.6 | GPT-5.4 |
| Pemahaman gambar resolusi tinggi | Opus 4.7 | Gemini 3.1 Pro |
| Sangat sensitif terhadap biaya | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Saran penerapan multi-model: Aplikasi AI modern sulit mencakup semua skenario dengan satu model saja. Disarankan untuk menggunakan platform APIYI (apiyi.com) untuk mengakses model Claude, GPT, dan Gemini secara terpadu, serta melakukan perutean cerdas berdasarkan skenario. Platform ini menyediakan kemampuan untuk memanggil semua model utama dengan satu kunci API, yang secara signifikan mengurangi kompleksitas penerapan multi-model.
FAQ Ketahanan Claude Opus 4.7
Q1: Apakah Claude Opus 4.7 benar-benar kurang tahan lama dibandingkan 4.6?
Ya, tetapi "kurang tahan lama" harus dipahami dalam dua dimensi:
-
Tingkat kuota: Jelas lebih cepat habis. Ekspansi Tokenizer sebesar 0-35% + Claude Code yang menggunakan xhigh secara default menyebabkan konsumsi token meningkat 30-80%. Pengguna paket Max 20x secara umum melaporkan kuota mereka habis lebih cepat.
-
Tingkat kemampuan: Tergantung skenario. Jelas lebih kuat dalam skenario pengodean Agent, Visi, dan Penggunaan Alat; namun lebih lemah atau setara dalam skenario RAG dokumen panjang, riset web, dan penulisan umum.
Jika Anda tidak melakukan tugas-tugas Agent tersebut, maka Opus 4.7 bagi Anda hanyalah "lebih mahal".
Q2: Mengapa Anthropic mengatakan “harga tidak berubah” tetapi tagihan saya menjadi lebih mahal?
Pernyataan resmi merujuk pada harga satuan yang tidak berubah: $5 / juta token input, $25 / juta token output. Namun, Tokenizer baru pada Opus 4.7 membuat teks yang sama mengonsumsi 1.0–1.35× lebih banyak token, ditambah dengan ekspansi token output xhigh, sehingga tagihan akhir yang naik 20-50% dibandingkan era 4.6 adalah hasil yang umum.
Untuk mengontrol biaya, Anda dapat melakukan pengujian perbandingan lalu lintas nyata melalui platform APIYI (apiyi.com), yang mendukung pemanggilan paralel seluruh seri Claude dan statistik penagihan yang terperinci.
Q3: Kuota Max Plan 20x habis lebih cepat, apa yang bisa dilakukan?
Tiga tindakan yang bisa segera dilakukan:
- Turunkan effort ke high atau medium: Matikan default xhigh di pengaturan Claude Code; untuk tugas sehari-hari, level high sudah cukup.
- Matikan langkah berpikir yang tidak perlu: Jika menemui pertanyaan sederhana dalam percakapan panjang, secara eksplisit minta model untuk melewati penalaran mendalam.
- Beralih ke Sonnet atau Opus 4.6 untuk tugas non-Agent: Penulisan, tanya jawab sederhana, dan penerjemahan tidak memerlukan Opus 4.7.
Ketiga tindakan ini digabungkan dapat membuat konsumsi kuota Max Plan kembali ke level era 4.6, atau bahkan lebih rendah.
Q4: Saya sudah bermigrasi ke Opus 4.7, apakah layak kembali ke 4.6?
Tergantung pada alur kerja utama Anda:
- Utamanya melakukan pengodean Agent multi-file: Jangan kembali, 4.7 benar-benar lebih kuat.
- Utamanya melakukan RAG dokumen panjang / analisis kontrak: Segera kembali ke 4.6, karena keruntuhan MRCR cukup parah.
- Skenario campuran: Tidak perlu kembali sepenuhnya, cukup lakukan perutean berdasarkan skenario—tugas Agent berat gunakan 4.7, sisanya gunakan 4.6 atau Sonnet.
Dalam pemanggilan API, proses kembali sangat mudah, cukup ubah parameter model dari claude-opus-4-7 kembali ke claude-opus-4-6.
Q5: Apakah Opus 4.7 lebih kuat dari GPT-5.4 xhigh di semua skenario?
Tidak. Data resmi menunjukkan Opus 4.7 memenangkan 6 dari 9 tolok ukur yang dapat dibandingkan secara langsung, namun kalah di dua skenario kunci:
- BrowseComp (Riset Web): GPT-5.4 Pro 89.3% vs Opus 4.7 79.3%.
- RAG konteks panjang: GPT-5.4 tidak menunjukkan keruntuhan serupa MRCR.
Jadi, pernyataan pengguna bahwa "dalam pengujian saya, Opus 4.7 masih belum bisa menandingi GPT-5.4 xhigh" bisa jadi benar—dengan catatan skenario utama Anda adalah riset web atau dokumen panjang.
Melalui platform APIYI (apiyi.com), Anda dapat memanggil Claude dan GPT secara bersamaan dalam satu proyek dan melakukan perutean berdasarkan skenario, yang saat ini merupakan pendekatan paling pragmatis.
Q6: Prompt lama menghasilkan kualitas output yang menurun di Opus 4.7, apa solusinya?
Ini adalah efek samping dari kepatuhan instruksi Opus 4.7 yang "lebih literal". Prinsip penulisan ulang:
- Ubah niat implisit menjadi batasan eksplisit: Awalnya "tulis dengan lebih profesional" → Ubah menjadi "wajib menggunakan istilah industri, hindari ekspresi bahasa lisan".
- Ubah batasan samar menjadi nilai numerik yang kaku: Awalnya "jangan terlalu panjang" → Ubah menjadi "batasi dalam 300 kata".
- Tambahkan batasan kontra-contoh: Beri tahu model output mana yang tidak dapat diterima.
Beban kerja ini cukup besar. Untuk pustaka Prompt yang besar, disarankan untuk melakukan pengujian A/B terlebih dahulu guna memastikan Prompt mana yang perlu ditulis ulang.
Ringkasan Kelebihan dan Kekurangan Claude Opus 4.7
Keunggulan Nyata (Mengakui kekuatannya)
- Peningkatan Kemampuan Agent Coding: SWE-bench Pro 64,3%, CursorBench 70%, melampaui GPT-5.4.
- Perubahan Kualitas Vision: Resolusi tinggi 3,75 MP, benchmark visual 98,5%.
- Toolchain MCP-Atlas Terkuat: 77,3%, memimpin di antara semua model publik.
- Kepatuhan Instruksi Lebih Akurat: Untuk petunjuk dengan batasan lengkap, output lebih terkontrol.
- Task Budgets Memberikan Kemampuan Tata Kelola Biaya Agent.
Keterbatasan Nyata (Mengakui kelemahannya)
- Inflasi Tokenizer 0-35%: Narasi harga menutupi kenaikan biaya yang sebenarnya.
- xhigh Meningkatkan Konsumsi Token Output Secara Default: Kuota Max Plan 20x menjadi jauh lebih ketat.
- Penurunan MRCR Konteks Panjang: 78,3% → 32,2%, RAG dokumen panjang tidak dapat digunakan.
- Kemunduran BrowseComp: Kalah dari GPT-5.4 Pro dalam skenario riset web.
- Sedikit Penurunan CyberGym: Sedikit mengalami kemunduran pada tugas terkait keamanan.
- Masalah Kompatibilitas Petunjuk Lama: Petunjuk yang bergantung pada maksud tersirat perlu ditulis ulang.
Kesimpulan
Claude Opus 4.7 adalah pembaruan yang sangat tipikal dengan "spesialisasi skenario". Semua peningkatannya mengarah pada satu tujuan—membuat Anthropic merebut kembali gelar juara dalam bidang coding berbasis Agent. Tujuan ini berhasil dicapai, namun dengan harga: pengguna di "semua skenario lain" harus ikut menanggung biaya pembaruan ini.
Jika Anda adalah pengembang Agent, pengguna berat Claude Code, atau pengguna setia Cursor, Opus 4.7 layak untuk segera diadopsi. Namun, jika skenario utama Anda adalah penulisan, RAG, riset web, atau produksi yang sensitif terhadap biaya, disarankan untuk:
- Mempertahankan Opus 4.6 untuk tugas non-Agent.
- Menurunkan effort default Claude Code dari xhigh ke high.
- Melakukan perutean beberapa model berdasarkan skenario, jangan gunakan satu model untuk semua kebutuhan.
"Harga tidak berubah" tidak pernah menjadi cerita yang utuh. Biaya sebenarnya tersembunyi dalam Tokenizer, pengaturan default, dan kedalaman inferensi. Opus 4.7 tidak buruk, hanya saja tidak bersifat generalis—memahami hal ini akan membantu Anda memanfaatkannya dengan nilai yang tepat.
Direkomendasikan untuk mengelola pemanggilan model Claude secara terpadu melalui platform APIYI apiyi.com. Platform ini menyediakan perutean cerdas multi-model, pemantauan kuota real-time, dan antarmuka API yang sepenuhnya kompatibel dengan versi resmi, menjadikannya alat paling praktis untuk mengatasi masalah "spesialisasi skenario" pada Opus 4.7.
Referensi
-
Pengumuman Resmi Anthropic: Pengenalan resmi Claude Opus 4.7
- Tautan:
anthropic.com/news/claude-opus-4-7 - Keterangan: Definisi kemampuan resmi dan skenario penggunaan yang direkomendasikan.
- Tautan:
-
Dokumentasi Resmi Anthropic: Panduan Migrasi Opus 4.7
- Tautan:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Keterangan: Perubahan pada Tokenizer dan penjelasan mengenai xhigh.
- Tautan:
-
Analisis Biaya Finout: Biaya sebenarnya di balik label harga yang tetap
- Tautan:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Keterangan: Analisis biaya pihak ketiga dan rincian tagihan.
- Tautan:
-
Uji Perbandingan Artificial Analysis: Perbandingan GPT-5.4 xhigh vs Claude Opus
- Tautan:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Keterangan: Data uji perbandingan independen pihak ketiga untuk berbagai model.
- Tautan:
-
GitHub Issue #23706: Umpan balik konsumsi Token pengguna Max Plan
- Tautan:
github.com/anthropics/claude-code/issues/23706 - Keterangan: Umpan balik langsung dari pengguna Max Plan Claude Code.
- Tautan:
Penulis: Tim Teknis APIYI
Tanggal Rilis: 18 April 2026
Model yang Berlaku: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Diskusi Teknis: Jangan ragu untuk mendapatkan kuota uji coba multi-model melalui APIYI di apiyi.com, dan rasakan sendiri perbedaan nyata dalam berbagai skenario.