Author's Note: OpenAI officially released gpt-image-2 (ChatGPT Images 2.0) on April 21, 2026. This article provides a comprehensive overview of its core capabilities, 2K resolution, multilingual text rendering, Agentic reasoning, official pricing ($8/$30 per million tokens), and API integration paths.
On April 21, 2026, OpenAI officially launched gpt-image-2 (ChatGPT Images 2.0), the third-generation flagship image model following the April 2025 gpt-image-1 and December 2025 gpt-image-1.5 releases. All ChatGPT and Codex users have had access since April 22, and the API will open to developers in early May.
This isn't just another routine update. It marks OpenAI's first attempt to integrate "O-series reasoning capabilities" into an image model. Before generating an image, gpt-image-2 proactively researches, plans, and reasons about the image structure, making it the industry's first true Agentic image generation model.
Core Value: By the end of this article, you'll have a clear understanding of gpt-image-2's core capabilities, pricing structure, use cases, and the fastest way to integrate it via API.

Key Highlights of gpt-image-2
| Feature | Description | Value for Beginners |
|---|---|---|
| Generally Available | Open to all ChatGPT/Codex users starting 2026-04-22 | No waitlist required |
| 2K Resolution | Native 2048-level output | Print-quality assets |
| Agentic Reasoning | Plans structure before drawing | Complex scenes done right the first time |
| Multilingual Text | Clear text in Japanese, Korean, Chinese, Hindi, and Bengali | Friendly for localized creative work |
| Web Search Integration | Real-time online fact-checking | Accurate infographics |
| API Launch Early May | Token-based pricing | Predictable costs |
The Significance of the gpt-image-2 Release
The first image model with reasoning capabilities. gpt-image-2 introduces the "Thinking Capabilities" from OpenAI's O-series. Before rendering a single pixel, the model analyzes the prompt's meaning, plans the composition, and reasons through detailed constraints. As TechCrunch noted, this agentic approach significantly boosts the success rate for complex scenes like magazine layouts, multi-panel comics, and infographics.
Text and detail are the biggest breakthroughs. OpenAI emphasizes that gpt-image-2 can accurately render small text, icons, UI elements, dense compositions, and subtle style constraints—areas that have historically been the Achilles' heel for all image models. VentureBeat's review described it as "seamlessly handling multilingual text, complete infographics, slide decks, maps, and even comics."

A Deep Dive into the 5 Core Capabilities of gpt-image-2
Capability 1: Native 2K Resolution
gpt-image-2 natively supports up to 2K resolution (2048 pixels), which is more than enough for magazine-grade layouts, commercial printing, and high-definition display content. While some early leaks mentioned 4K, the official confirmation is 2K—a resolution that is perfectly adequate for the vast majority of commercial scenarios.
Capability 2: Precise Multilingual Text Rendering
This is a core upgrade highlighted by the official team. It supports high-fidelity text generation in the following languages:
| Language Category | Representative Languages | Typical Applications |
|---|---|---|
| CJK | Chinese, Japanese, Korean | Localized advertising |
| South Asian | Hindi, Bengali | South Asian market content |
| Latin | English, Spanish, French | Global mainstream markets |
| Complex Scripts | Arabic, Hebrew | Middle Eastern markets |
VentureBeat’s test cases included full Key Visual magazine covers, multilingual restaurant menus, subway map labels, and Japanese manga speech bubbles—all of which featured text that looked "seamless."
Capability 3: Agentic Reasoning ("Thinking")
This is the true architectural innovation of gpt-image-2. Unlike the previous "prompt → direct rendering" pipeline, it now performs the following steps:
- Research: Understands the entities, relationships, and constraints within the prompt.
- Plan: Conceives the image layout, element placement, and visual hierarchy.
- Reason: Cross-verifies detail constraints (fonts, proportions, color logic).
- Double-check: Re-verifies the output against requirements after generation.
This agentic approach significantly improves the success rate for infographics, multi-element compositions, and strictly constrained scenarios compared to the previous generation.
Capability 4: Web Search Integration
gpt-image-2 features built-in web search capabilities, allowing it to query the latest facts, company logos, and product appearances in real-time before generating an image. This solves the "knowledge cutoff" issue (officially confirmed as December 2025).
For example, when generating a "2026 Paris Fashion Week venue poster," the model will first go online to confirm the venue name, date, and host brand before starting the creative process.
Capability 5: Multi-Format Output in One Go
gpt-image-2 can generate combinations of marketing assets in different sizes or multi-panel comics based on a single prompt. In TechCrunch's tests, inputting "design 4 social media assets for a new coffee brand" returned four coordinated visuals in 1:1, 9:16, 16:9, and 3:4 aspect ratios simultaneously.
Understanding Official Pricing for gpt-image-2
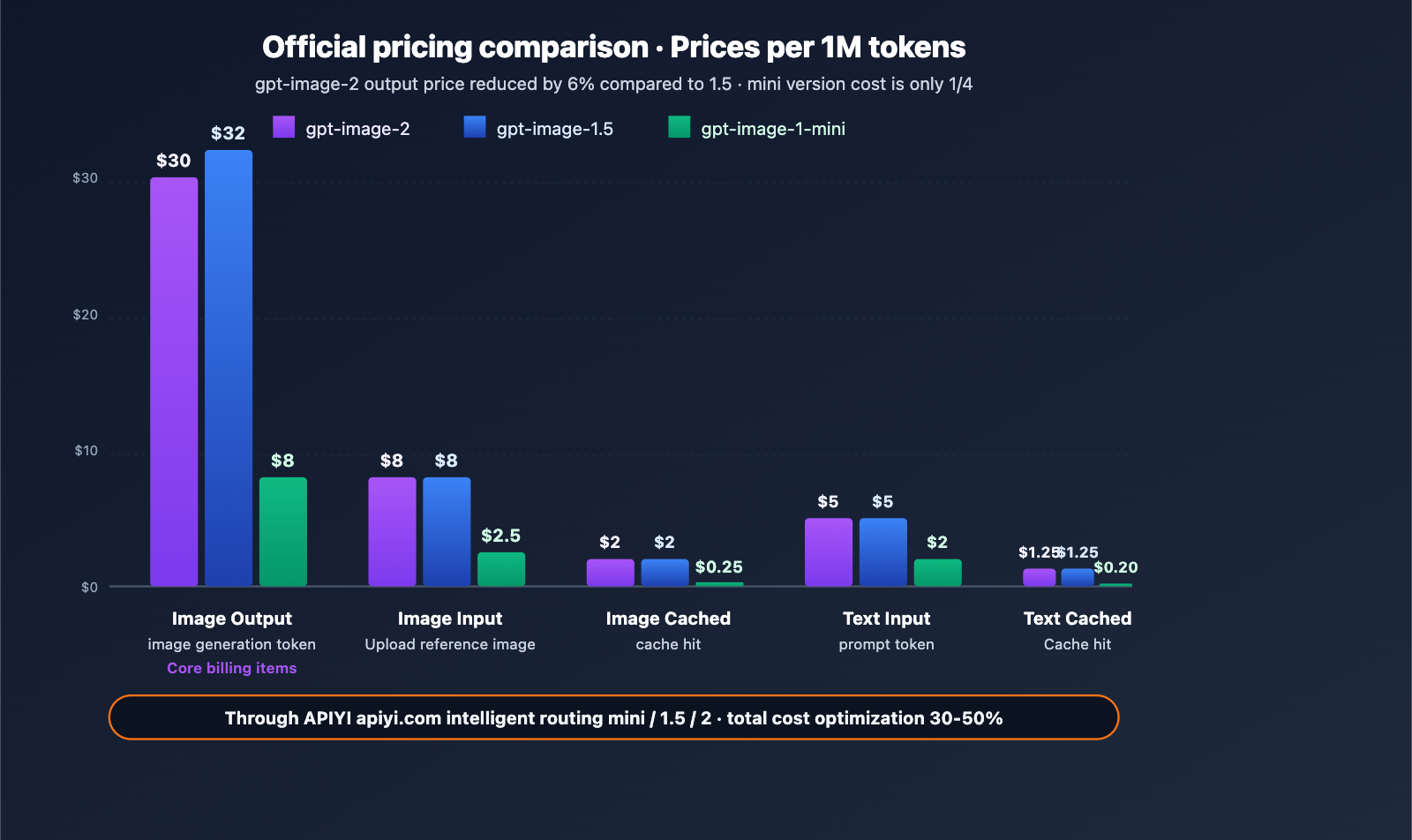
Official Pricing Table (per million tokens)
| Model | Image Input | Image Cached | Image Output | Text Input | Text Cached | Text Output |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
Key Takeaways
Pricing Logic: Billing is based on input and output token counts rather than the number of images. This means that higher resolution and more complex prompts will cost more per generation, while low-complexity tasks are cheaper—offering more flexibility than a "fixed price per image" model.
Comparison with gpt-image-1.5:
- Image Output price dropped from $32 to $30 (-6%).
- Image Input/Cached prices remain unchanged.
- Text Input/Cached prices remain unchanged, but the Text Output charge has been removed (gpt-image-2 focuses on image generation and no longer outputs text).
- Conclusion: The overall cost of gpt-image-2 is slightly lower, but its capabilities are significantly enhanced, offering better value for money.
The Role of the Mini Version: For scenarios that don't require extreme quality (such as batch thumbnails, drafts, or previews), gpt-image-1-mini provides basic capabilities at about 1/4 of the price, making it ideal for large-scale, cost-sensitive projects.
Typical Scenario Cost Estimates
| Scenario | Estimated Cost per Image | Explanation |
|---|---|---|
| Simple prompt standard image | $0.04-$0.08 | Low token consumption |
| Medium complexity ad image | $0.10-$0.15 | Moderate token consumption |
| High complexity infographic | $0.20-$0.35 | Multi-element + long prompt |
| Multi-image fusion/editing | $0.15-$0.30 | Includes reference image input |
Cost Optimization Tip: By using the APIYI (apiyi.com) unified account, you can automatically route tasks based on their type—use
gpt-image-1-mini($8 output) for simple previews andgpt-image-2($30 output) for high-quality deliverables, optimizing overall costs by 30-50%.
Getting Started with gpt-image-2
Minimal Invocation Example
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="2K magazine cover, coffee brand 'Moonlight Roasting', main visual in deep brown tones, "
"Chinese main title 'Slow-Cooked Time', subtitle 'Issue 042 · Spring 2026'",
size="2048x2048"
)
print(response.data[0].url)
View Full Implementation (Including Multilingual, Multi-image Fusion, and Smart Fallback)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
Smart routing: Select the optimal model based on quality tier.
Args:
prompt: Image description
quality_tier:
- mini: Batch previews / drafts (gpt-image-1-mini, 4x cheaper)
- standard: Standard delivery (gpt-image-1.5)
- premium: High quality + Agentic (gpt-image-2)
size: Output dimensions
Returns:
Generated image URL
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"Generation failed: {e}")
return None
multilingual_examples = {
"japanese": "Japanese manga cover, title '月の向こうへ', subtitle '第1話'",
"korean": "K-pop album cover, large title '봄이 올 때'",
"hindi": "Bollywood movie poster, title 'मानसून की रात'",
"arabic": "Arabic calligraphy poster, content 'مرحبا بالعالم'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
Platform Tip: Through APIYI (apiyi.com), you can access gpt-image-2, gpt-image-1.5, and gpt-image-1-mini simultaneously. Use a single API key to implement smart routing—using "mini" for drafts and "premium" for final production.
gpt-image-2 vs. Competitors
| Model | Positioning | Core Advantage | Official Pricing |
|---|---|---|---|
| gpt-image-2 | OpenAI's latest flagship | Agentic reasoning + multilingual text | Output $30/M token |
| gpt-image-1.5 | Previous flagship | Mature and stable + complete API ecosystem | Output $32/M token |
| gpt-image-1-mini | Lightweight entry | 1/4 cost · High speed | Output $8/M token |
| Nano Banana Pro | Google flagship | 14 reference images + SynthID | $0.045-$0.151 per image |
| Midjourney v7 | Art style leader | Superior aesthetics | Subscription-based |
gpt-image-2 Analysis
Nano Banana Pro: Banana Pro maintains a lead in multi-reference image consistency (14 images), editing maturity, and compliance watermarking. However, gpt-image-2 offers differentiated advantages in three dimensions: multilingual text accuracy, Agentic reasoning capabilities, and Web search integration.
gpt-image-1.5: The previous generation remains a stable and reliable choice with the most mature API ecosystem, making it suitable for standard scenarios where advanced Agentic capabilities aren't required. We recommend using gpt-image-2 for new projects, while older projects can be migrated gradually based on specific needs.
Midjourney: Midjourney remains the strongest in the realm of artistic style. gpt-image-2 is better suited for scenarios where commercial viability is the priority—such as product photography, UI design, infographics, and localized assets.
Selection Guide: Choosing the right model depends on your specific application scenario and quality requirements. We recommend performing real-world tests via the APIYI (apiyi.com) platform, which allows you to compare multiple mainstream models with a single integration.
gpt-image-2 Typical Use Cases
Here are six scenarios perfect for beginners to get started quickly:
- Scenario 1 · Marketing Materials – Agentic reasoning ensures headlines, product highlights, and visual hierarchy are spot-on in one go.
- Scenario 2 · Infographics/Education – Web search + multilingual text + precise data labeling.
- Scenario 3 · Multi-panel Comics – Generate multiple comic panels at once with clear, readable speech bubbles.
- Scenario 4 · Magazine Layouts – 2K resolution + complex layout support for professional printing.
- Scenario 5 · Localized Advertising – Character-level accuracy for CJK, Hindi, Bengali, Arabic, and more.
- Scenario 6 · UI Mockups – Accurate rendering of small text, icons, and dense layouts.
Pro Tip: For beginners, we recommend starting with "Marketing Materials" and "Infographics"—these two scenarios best showcase the leap in capabilities of gpt-image-2 compared to its predecessor. You can get free testing credits at APIYI (apiyi.com) to try it out right away.
FAQ
Q1: What is gpt-image-2?
gpt-image-2 is the next-generation image generation model officially released by OpenAI on April 21, 2026, also known as "ChatGPT Images 2.0." It is the first image model to introduce O-series reasoning capabilities, supporting 2K resolution, multilingual text, Agentic planning, and Web search integration. It has been available to all ChatGPT/Codex users since April 22, with the API launching in early May.
Q2: What are the biggest upgrades in gpt-image-2 compared to gpt-image-1.5?
Three core upgrades: (1) Agentic reasoning—the model researches, plans, and reasons about image structure before generating, significantly increasing success rates for complex scenes; (2) Multilingual text—character-level accuracy for non-Latin scripts like Japanese, Korean, Chinese, Hindi, and Bengali; (3) Web search integration—real-time fact-checking to overcome knowledge cutoff limitations. Additionally, the Image Output price has dropped from $32/M tokens to $30, offering better value.
Q3: When will the official gpt-image-2 API be available?
According to the official OpenAI announcement, ChatGPT/Codex users can use it directly on the web starting April 22, 2026, and the gpt-image-2 API will be open to developers in early May 2026. Before the official API opens, you can access the latest image generation capabilities early via the gpt-image-2-all reverse proxy solution on APIYI (apiyi.com) at $0.03/request, with a seamless transition once the official API launches.
Q4: How should I understand the $8/$30 token pricing?
This is the unit price per million tokens, following the same billing logic as text models like GPT-4o:
- Image Input $8: Input token cost when uploading a reference image.
- Image Cached $2: Input token cost for cache hits (significantly cheaper for repeated images).
- Image Output $30: Output token cost for generating images.
- Text Input $5: Input cost for text prompts.
The cost per image typically ranges from $0.04 to $0.35, depending on prompt complexity and output resolution.
Q5: How do I integrate gpt-image-2 via API?
The fastest way is through APIYI (apiyi.com):
- Visit apiyi.com to register an account and get your API key.
- Set the
base_urltohttps://vip.apiyi.com/v1. - Use the official OpenAI SDK and set
model="gpt-image-2"to start your model invocation.
APIYI launches new models in sync with OpenAI. Your existing keys, balance, and billing remain unchanged, and a single account supports all mainstream models including gpt-image-2, gpt-image-1.5, gpt-image-1-mini, and Nano Banana Pro.
Q6: How should I choose between gpt-image-2 and gpt-image-1-mini?
Choose based on quality sensitivity:
- gpt-image-2: Image Output $30/M tokens, suitable for final deliverables (advertising visuals, print materials, client proposals).
- gpt-image-1-mini: Image Output $8/M tokens (approx. 1/4 the cost), suitable for batch previews, draft iterations, thumbnails, and experimental exploration.
A common workflow is to use them in combination: iterate quickly with 10-20 drafts using the mini model, then use gpt-image-2 to output the final high-quality version once the direction is set.
Q7: How does the Agentic “Thinking” capability help beginners?
The biggest help for beginners is lowering the barrier to prompt engineering. Previously, you needed to carefully tune prompts to prevent the AI from "hallucinating," but now the model actively reasons about what you want:
- You say "magazine cover" → It plans font hierarchy, whitespace, and the placement of the main image.
- You say "infographic" → It reasons about data accuracy, legend placement, and color semantics.
- You say "multi-panel comic" → It plans the pacing, speech bubble placement, and character consistency.
Result: Beginners can get professional-grade output even with simple prompts.
Q8: What are the known limitations of gpt-image-2?
Here are three categories of limitations:
- Knowledge cutoff December 2025: Content involving events or products from 2026 may be inaccurate, relying on Web search capabilities for supplementation.
- 2K maximum per generation: Sizes exceeding 2048 require post-processing upscaling.
- API latency: Agentic reasoning takes longer than direct rendering; interactive applications should be designed with appropriate loading indicators.
- Compliance considerations: Nano Banana Pro's SynthID watermark + copyright indemnification remains the preferred choice for compliance-sensitive scenarios.
gpt-image-2 Key Takeaways
- Official Release on 2026-04-21: Available on the ChatGPT/Codex web interface on 4-22, with API access for developers opening in early May.
- The First Agentic Image Model: Features pre-generation research, planning, reasoning, and self-correction, significantly boosting success rates for complex scenes on the first attempt.
- Multilingual Text is the Core Breakthrough: Character-level accuracy for non-Latin scripts, including CJK, Hindi, Bengali, and Arabic.
- Official Pricing at $8/$30 (per million tokens): Image output costs are 6% lower than gpt-image-1.5, despite a massive leap in capabilities.
- Getting Started: Use a single API key from APIYI (apiyi.com) to access gpt-image-2, 1.5, and mini via intelligent routing.
Summary
Here are the key takeaways for gpt-image-2:
- Generational Leap in Capability: By introducing O-series reasoning, this is the first image model with "thinking" capabilities, leading to a qualitative improvement in first-try success rates for complex scenarios.
- Commercial Usability First: With 2K resolution, multilingual text support, and integrated web search, the model is clearly designed for production use rather than just entertainment.
- Transparent and Predictable Pricing: Token-based billing is more flexible than fixed per-request pricing. Combined with the mini tier, you can build cost-optimized generation pipelines.
For team decision-making, we recommend starting your trial of gpt-image-2 via APIYI (apiyi.com) immediately. APIYI offers free credits and allows you to connect using the official OpenAI SDK by simply switching the base_url. Plus, with support for intelligent routing across the mini, 1.5, and 2 tiers, it’s the easiest way to verify the best solution for your specific use cases at the lowest possible cost.
Related Articles
If you're interested in gpt-image-2, we recommend checking out these articles:
- 📘 gpt-image-2 vs gpt-image-1.5: A Deep Dive into 8 Major Upgrades – Understand the underlying reasons for this leap in capability.
- 📊 6 Key Use Cases for gpt-image-2 – Master the path to practical business implementation.
- 🚀 gpt-image-2 vs Nano Banana Pro: An In-depth Comparison – Make an informed choice to select the best model.
- ⚡ gpt-image-2-all Official Proxy Solution at $0.03/call – A stable channel for model invocation before the official API release.
📚 References
-
Official OpenAI Announcement: ChatGPT Images 2.0 Release
- Link:
openai.com/index/new-chatgpt-images-is-here - Note: Official gpt-image-2 capability specifications and product positioning.
- Link:
-
VentureBeat Review: Real-world testing of multilingual text, infographics, maps, and comics
- Link:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - Note: Independent verification of multilingual and complex layout capabilities.
- Link:
-
TechCrunch Report: In-depth review of text rendering capabilities
- Link:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - Note: Specific comparisons with previous models like DALL-E 3.
- Link:
-
PetaPixel Analysis: Decoding the Agentic "Thinking" capability
- Link:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - Note: How O-series reasoning is integrated into the image generation process.
- Link:
-
Official OpenAI Pricing: Pricing table per million tokens
- Link:
openai.com/api/pricing - Note: Complete pricing information for gpt-image-2 / 1.5 / mini.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to join the conversation in the comments section. For more resources, visit the APIYI documentation center at docs.apiyi.com.