Nota del autor: OpenAI lanzó oficialmente gpt-image-2 (ChatGPT Images 2.0) el 21 de abril de 2026. En este artículo te presento sus capacidades principales, resolución 2K, soporte multilingüe, razonamiento tipo agente, precios oficiales (8 $/30 $ por millón de tokens) y cómo integrarlo vía API.
OpenAI lanzó oficialmente gpt-image-2 (ChatGPT Images 2.0) el 21 de abril de 2026. Se trata de la tercera generación de su modelo insignia de imágenes, tras el gpt-image-1 de abril de 2025 y el gpt-image-1.5 de diciembre de 2025. Desde el 22 de abril, todos los usuarios de ChatGPT y Codex ya pueden utilizarlo, y la API estará disponible para desarrolladores a principios de mayo.
Esto no es una actualización convencional, sino el primer intento de OpenAI de integrar las "capacidades de razonamiento de la serie O" en un modelo de imagen. Antes de empezar a dibujar, gpt-image-2 investiga, planifica y razona activamente sobre la estructura de la imagen, convirtiéndose en el primer modelo de generación de imágenes con capacidades de agente (Agentic) en la industria.
Valor principal: Al terminar de leer este artículo, entenderás claramente las capacidades principales de gpt-image-2, su estructura de precios, sus casos de uso y dominarás la ruta de acceso más rápida a su API.

Puntos clave de gpt-image-2
| Característica | Descripción | Valor para principiantes |
|---|---|---|
| Disponibilidad oficial | Abierto a todos los usuarios de ChatGPT/Codex desde el 22/04/2026 | Sin listas de espera |
| Resolución 2K | Salida nativa de 2048 niveles | Material de calidad de impresión |
| Razonamiento Agéntico | Planificación de la estructura antes de dibujar | Resultados precisos en escenas complejas |
| Texto multilingüe | Claridad en caracteres japoneses, coreanos, chinos, indios y bengalíes | Ideal para creatividad localizada |
| Integración web | Búsqueda en tiempo real para verificar hechos | Infografías precisas |
| API disponible en mayo | Precios basados en tokens | Costos predecibles |
El significado del lanzamiento de gpt-image-2
El primer modelo de imagen con capacidad de razonamiento. gpt-image-2 introduce las "Capacidades de Pensamiento" (Thinking Capabilities) de la serie O de OpenAI: antes de generar el primer píxel, el modelo estudia el significado de la indicación, planifica la estructura de la composición y razona sobre las restricciones de detalle antes de comenzar el renderizado. TechCrunch señala que este enfoque agéntico aumenta drásticamente la tasa de éxito en escenas complejas (diseños de revistas, cómics de varios paneles, infografías).
El texto y los detalles son su mayor avance. OpenAI destaca que gpt-image-2 puede renderizar con precisión texto pequeño, iconos, elementos de interfaz, composiciones densas y restricciones de estilo sutiles, lo cual ha sido el punto débil de todos los modelos de imagen anteriores. VentureBeat lo calificó como un modelo que "parece completar a la perfección textos multilingües, infografías completas, diapositivas, mapas e incluso cómics".

Análisis detallado de las 5 capacidades principales de gpt-image-2
Capacidad 1: Resolución nativa 2K
gpt-image-2 admite de forma nativa una resolución máxima de 2K (2048 píxeles), suficiente para satisfacer las necesidades de maquetación de revistas, impresión comercial y contenido para pantallas de alta definición. Aunque algunas filtraciones tempranas mencionaban 4K, la cifra oficial confirmada es 2K, lo cual es más que suficiente para la gran mayoría de los escenarios comerciales.
Capacidad 2: Renderizado preciso de texto multilingüe
Esta es la mejora central destacada por el equipo oficial. Admite la generación de texto de alta fidelidad en los siguientes idiomas:
| Categoría de idioma | Idiomas representativos | Aplicación típica |
|---|---|---|
| CJK | Chino, japonés, coreano | Publicidad localizada |
| Lenguas del sur de Asia | Hindi, bengalí | Contenido para el mercado del sur de Asia |
| Lenguas latinas | Inglés, español, francés | Mercado global principal |
| Caracteres complejos | Árabe, hebreo | Mercado de Oriente Medio |
Los casos de prueba de VentureBeat incluyen: portadas de revistas con Key Visual completo, menús de restaurantes multilingües, etiquetas en mapas de metro y globos de diálogo para manga japonés; todo el texto se ve "perfectamente integrado".
Capacidad 3: Razonamiento "Agentic" ("Thinking")
Esta es la verdadera innovación a nivel de arquitectura de gpt-image-2. A diferencia del flujo anterior de "indicación → renderizado directo", ahora el modelo realiza lo siguiente:
- Investigación (Research): Comprende las entidades, relaciones y restricciones contenidas en la indicación.
- Planificación (Plan): Concibe el diseño de la imagen, la posición de los elementos y la jerarquía visual.
- Razonamiento (Reason): Verifica de forma cruzada las restricciones de detalle (fuentes, proporciones, lógica de color).
- Autoverificación previa a la entrega (Double-check): Una vez generada, vuelve a validar si cumple con los requisitos.
Este enfoque "Agentic" le permite lograr una tasa de éxito significativamente mayor que la generación anterior en infografías, composiciones de múltiples elementos y escenarios con restricciones estrictas.
Capacidad 4: Integración de búsqueda web
gpt-image-2 incorpora capacidad de búsqueda web, lo que le permite consultar en tiempo real hechos recientes, logotipos de empresas, apariencia de productos, etc., antes de generar la imagen. Esto resuelve el problema de la desviación de la realidad causada por la "fecha de corte de los datos de entrenamiento" (la fecha de corte oficial de conocimiento es diciembre de 2025).
Por ejemplo, al generar un "póster para el recinto de la Semana de la Moda de París 2026", el modelo se conectará primero a internet para confirmar el nombre del recinto, las fechas y las marcas patrocinadoras antes de iniciar el proceso creativo.
Capacidad 5: Salida multiformato en una sola ejecución
gpt-image-2 puede generar combinaciones de materiales de marketing en diferentes tamaños o mangas de varios paneles basándose en una sola indicación. En las pruebas de TechCrunch, al introducir "diseña 4 materiales de redes sociales para una nueva marca de café", el modelo devolvió cuatro imágenes coordinadas en formatos 1:1, 9:16, 16:9 y 3:4 de una sola vez.
Análisis de la estructura de precios oficial de gpt-image-2
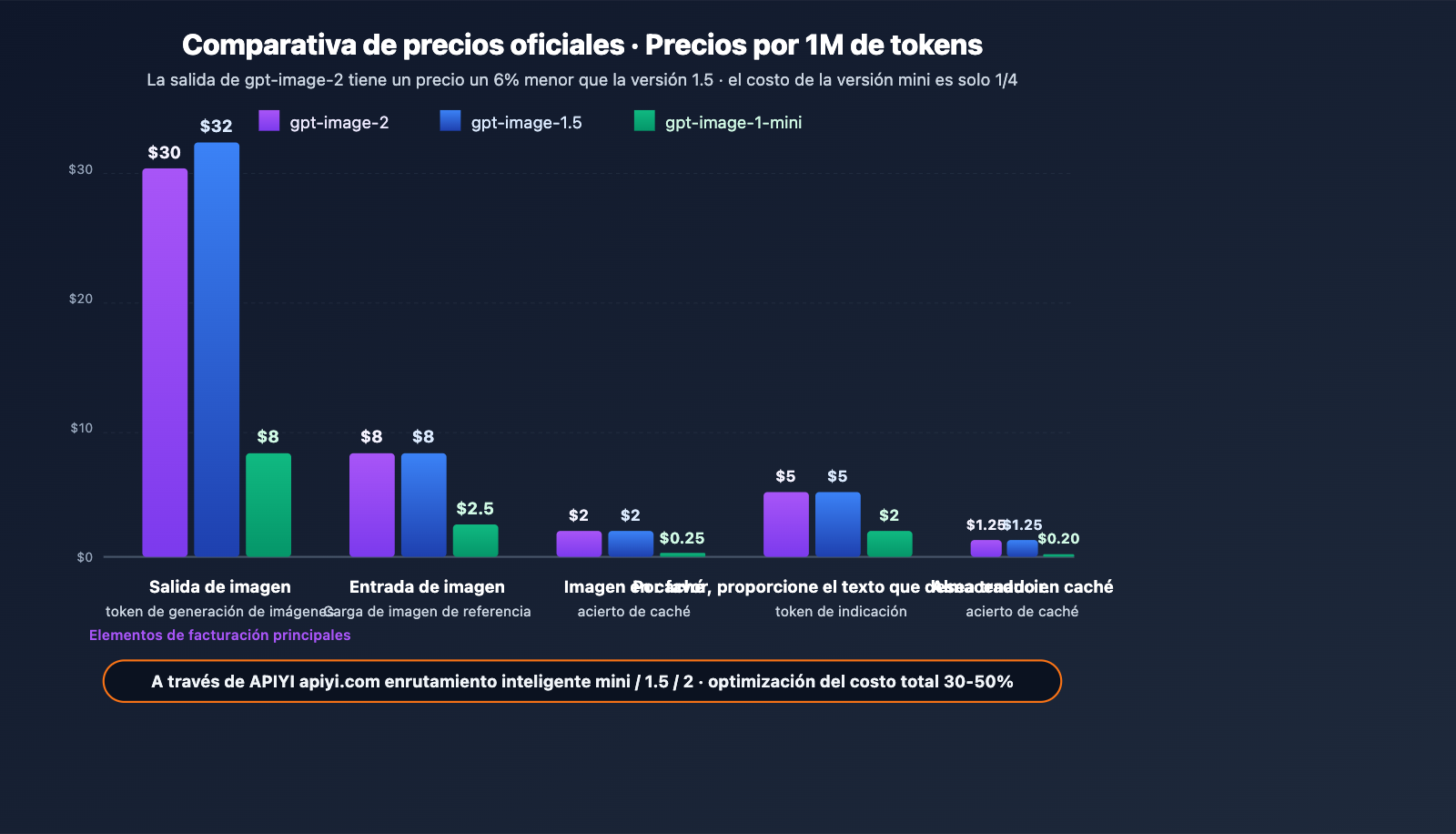
Tabla oficial de precios (por millón de tokens)
| Modelo | Image Input | Image Cached | Image Output | Text Input | Text Cached | Text Output |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
Interpretación clave
Lógica de precios: Se factura según el número de tokens de entrada y salida, no por cantidad de imágenes. Esto significa que el costo unitario de una resolución alta o una indicación compleja será mayor, mientras que las tareas de baja complejidad resultan más económicas; es un modelo mucho más flexible que el "cobro fijo por imagen".
Comparativa con gpt-image-1.5:
- Image Output ha bajado de $32 a $30 (reducción del 6%).
- Image Input/Cached se mantienen sin cambios.
- Text Input/Cached se mantienen igual, pero se ha eliminado el ítem de facturación Text Output (gpt-image-2 se centra en la generación de imágenes y ya no genera texto como salida).
- Conclusión: El costo integral de gpt-image-2 es ligeramente menor, pero sus capacidades han mejorado drásticamente, ofreciendo una relación costo-beneficio significativamente superior.
El significado de la versión mini: Para escenarios que no requieren una calidad extrema (miniaturas por lotes, borradores, vistas previas), gpt-image-1-mini ofrece capacidades básicas a aproximadamente 1/4 del precio, ideal para escenarios a gran escala sensibles a los costos.
Estimación de costos para escenarios típicos
| Escenario | Estimación por imagen | Explicación |
|---|---|---|
| Imagen estándar con indicación simple | $0.04-$0.08 | Bajo consumo de tokens |
| Imagen publicitaria de complejidad media | $0.10-$0.15 | Consumo medio de tokens |
| Infografía de alta complejidad | $0.20-$0.35 | Múltiples elementos + indicación larga |
| Edición de fusión de varias imágenes | $0.15-$0.30 | Uso de imagen de referencia (image input) |
Consejo de optimización de costos: A través de la gestión unificada de cuentas en APIYI (apiyi.com), puedes enrutar automáticamente las tareas según el tipo: usa
gpt-image-1-mini($8 por salida) para vistas previas sencillas ygpt-image-2($30 por salida) para entregas de alta calidad, optimizando el costo total entre un 30% y un 50%.
Guía de inicio rápido para gpt-image-2
Ejemplo de invocación minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="Portada de revista 2K, marca de café 'Moonlight Baking', estilo visual principal en tonos marrón oscuro,"
"título principal en chino 'Slow-cooked Time', subtítulo 'Issue 042 · 2026 Spring Edition'",
size="2048x2048"
)
print(response.data[0].url)
Ver código de implementación completo (incluye multilingüe, fusión de múltiples imágenes y degradación inteligente)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
Enrutamiento inteligente: selecciona el modelo óptimo según el nivel de calidad
Args:
prompt: descripción de la imagen
quality_tier:
- mini: vista previa por lotes / borrador (gpt-image-1-mini, 4 veces más barato)
- standard: entrega estándar (gpt-image-1.5)
- premium: alta calidad + Agentic (gpt-image-2)
size: tamaño de salida
Returns:
URL de la imagen generada
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"La generación falló: {e}")
return None
multilingual_examples = {
"japonés": "Portada de manga japonés, título '月の向こうへ', subtítulo '第1話'",
"coreano": "Portada de álbum de K-pop, título grande '봄이 올 때' ",
"hindi": "Póster de película de Bollywood, título 'मानसून की रात'",
"árabe": "Póster de caligrafía árabe, contenido 'مرحبا بالعالم'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
Sugerencia de la plataforma: A través de APIYI (apiyi.com) puedes invocar simultáneamente los tres niveles: gpt-image-2, gpt-image-1.5 y gpt-image-1-mini, utilizando una sola clave API para realizar un enrutamiento inteligente, usando "mini para borradores y premium para entregas finales".
Comparativa de gpt-image-2 frente a la competencia
| Modelo | Posicionamiento | Ventaja principal | Precio oficial |
|---|---|---|---|
| gpt-image-2 | Nuevo buque insignia de OpenAI | Razonamiento Agentic + texto multilingüe | Salida $30/M token |
| gpt-image-1.5 | Insignia de la generación anterior | Maduro y estable + ecosistema API completo | Salida $32/M token |
| gpt-image-1-mini | Entrada ligera | Costo 1/4 · alta velocidad | Salida $8/M token |
| Nano Banana Pro | Insignia de Google | 14 imágenes de referencia + SynthID | Por imagen $0.045-$0.151 |
| Midjourney v7 | Preferido por estilo artístico | Estética artística líder | Modelo de suscripción |
Análisis comparativo de gpt-image-2
Nano Banana Pro: Banana Pro mantiene el liderazgo en consistencia de múltiples imágenes de referencia (14 imágenes), madurez de edición y marcas de agua de cumplimiento. Sin embargo, gpt-image-2 ofrece ventajas diferenciadas en tres dimensiones: precisión de texto multilingüe, capacidades de razonamiento Agentic e integración con búsqueda web.
gpt-image-1.5: La generación anterior sigue siendo una opción estable y confiable, con el ecosistema de API más maduro, ideal para escenarios convencionales que no requieren capacidades Agentic avanzadas. Para proyectos nuevos, recomendamos usar gpt-image-2 directamente; los proyectos antiguos pueden migrarse gradualmente según el caso de uso.
Midjourney: En el campo del estilo artístico, Midjourney sigue siendo el más fuerte. gpt-image-2 es más adecuado para escenarios donde la viabilidad comercial es la prioridad: imágenes de productos, interfaz de usuario (UI), infografías y materiales de localización.
Nota sobre la selección: La elección del modelo depende principalmente de tus escenarios de aplicación específicos y requisitos de calidad. Recomendamos realizar pruebas reales a través de la plataforma APIYI (apiyi.com), donde una sola integración te permite comparar múltiples modelos líderes.
Escenarios de aplicación típicos de gpt-image-2
Seis escenarios ideales para que los principiantes comiencen rápidamente:
- Escenario 1 · Material de marketing – El razonamiento agente permite que los títulos, el enfoque del producto y la jerarquía visual queden perfectos a la primera.
- Escenario 2 · Infografías/Educación – Búsqueda web + texto multilingüe + etiquetas de datos precisas.
- Escenario 3 · Cómics multipanel – Generación de varias viñetas a la vez + texto claro en los globos de diálogo.
- Escenario 4 · Maquetación de revistas – Resolución 2K + soporte para diseños complejos aptos para impresión comercial.
- Escenario 5 · Publicidad localizada – Precisión a nivel de carácter en CJK, hindi, bengalí y árabe.
- Escenario 6 · Mockups de UI – Reproducción precisa de texto pequeño, iconos y diseños densos.
Sugerencia de escenario: Recomendamos a los principiantes empezar por "Material de marketing" e "Infografías"; son los escenarios donde mejor se aprecia el salto de capacidad de gpt-image-2 frente a la generación anterior. Puedes obtener saldo de prueba gratuito en APIYI (apiyi.com) para probarlo rápidamente.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es gpt-image-2?
gpt-image-2 es el modelo de generación de imágenes de próxima generación lanzado oficialmente por OpenAI el 21-04-2026, también conocido como "ChatGPT Images 2.0". Es el primer modelo de imagen que introduce capacidades de razonamiento de la serie O, soportando resolución 2K, texto multilingüe, planificación agente e integración con búsqueda web. Disponible para todos los usuarios de ChatGPT/Codex desde el 22 de abril, con la API disponible a principios de mayo.
Q2: ¿Cuál es la mayor mejora de gpt-image-2 frente a gpt-image-1.5?
Tres mejoras clave: (1) Razonamiento agente: investiga, planifica y razona la estructura de la imagen antes de generarla, aumentando drásticamente la tasa de éxito en escenas complejas; (2) Texto multilingüe: precisión a nivel de carácter en idiomas no latinos como japonés, coreano, chino, hindi y bengalí; (3) Integración con búsqueda web: consulta hechos en tiempo real para resolver el problema del corte de conocimiento. Además, el precio de salida de imagen ha bajado de $32/M tokens a $30, ofreciendo una mejor relación calidad-precio.
Q3: ¿Cuándo estará disponible la API oficial de gpt-image-2?
Según el anuncio oficial de OpenAI, los usuarios de ChatGPT/Codex pueden usarlo directamente en la web desde el 22-04-2026, y la API de gpt-image-2 estará abierta para desarrolladores a principios de mayo de 2026. Antes de la apertura oficial, puedes acceder a las últimas capacidades de generación a través de la solución de APIYI (apiyi.com) con gpt-image-2-all ($0.03/uso), permitiendo una transición fluida cuando se abra la API oficial.
Q4: ¿Cómo entender el precio de $8/$30 por token?
Es el precio unitario por millón de tokens, siguiendo la misma lógica de facturación que los modelos de texto como GPT-4o:
- Entrada de imagen $8: Costo de tokens de entrada cuando el usuario sube una imagen de referencia.
- Imagen en caché $2: Costo de tokens de entrada cuando se alcanza la caché (reducción significativa para imágenes repetidas).
- Salida de imagen $30: Costo de tokens de salida al generar la imagen.
- Entrada de texto $5: Costo de entrada para el prompt de texto.
El costo por imagen suele oscilar entre $0.04 y $0.35, dependiendo de la complejidad del prompt y la resolución de salida.
Q5: ¿Cómo acceder a gpt-image-2 a través de la API?
La forma más rápida es a través de APIYI (apiyi.com):
- Visita apiyi.com, registra una cuenta y obtén tu clave API.
- Configura la
base_urlcomohttps://vip.apiyi.com/v1. - Usa el SDK oficial de OpenAI y llama al modelo con
model="gpt-image-2".
APIYI lanza los nuevos modelos en sincronía con OpenAI; tus claves, saldo y facturación actuales se mantienen, y una sola cuenta soporta todos los modelos principales como gpt-image-2, gpt-image-1.5, gpt-image-1-mini y Nano Banana Pro.
Q6: ¿Cómo elegir entre gpt-image-2 y gpt-image-1-mini?
Elige según la sensibilidad a la calidad:
- gpt-image-2: Salida de imagen a $30/M tokens, ideal para entregables finales (visuales publicitarios, materiales de impresión, propuestas a clientes).
- gpt-image-1-mini: Salida de imagen a $8/M tokens (aprox. 1/4 del precio), ideal para previsualizaciones por lotes, iteración de borradores, miniaturas y exploración experimental.
Un flujo de trabajo común es usarlos en combinación: utiliza el modelo mini para iterar rápidamente 10-20 borradores y, una vez definida la dirección, usa gpt-image-2 para obtener la versión final de alta calidad.
Q7: ¿En qué ayuda realmente la capacidad de «pensamiento» agente a un principiante?
La mayor ayuda es reducir la barrera de la ingeniería de prompts. Antes, era necesario ajustar meticulosamente el prompt para evitar que la IA "dibujara mal"; ahora, el modelo razona activamente sobre lo que quieres:
- Si dices "portada de revista" → planificará la jerarquía de fuentes, espacios en blanco y la posición de la imagen principal.
- Si dices "infografía" → razonará sobre la precisión de los datos, la posición de la leyenda y la semántica del color.
- Si dices "cómic multipanel" → planificará el ritmo de las viñetas, la posición de los globos de texto y la consistencia de los personajes.
Resultado: Los principiantes pueden obtener resultados de nivel profesional con prompts sencillos.
Q8: ¿Qué limitaciones conocidas tiene gpt-image-2?
Tres tipos de limitaciones objetivas:
- Corte de conocimiento 2025-12: El contenido relacionado con eventos o productos de 2026 puede no ser preciso, dependiendo de la capacidad de búsqueda web para complementar.
- Máximo 2K por vez: Los tamaños superiores a 2048 requieren un procesamiento posterior de superresolución.
- Latencia de API: El razonamiento agente consume más tiempo que el renderizado directo; las aplicaciones interactivas deben diseñar indicadores de carga adecuados.
- Consideraciones de cumplimiento: La marca de agua SynthID de Nano Banana Pro y la compensación por derechos de autor siguen siendo la opción preferida para escenarios sensibles al cumplimiento.
Puntos clave de gpt-image-2
- Lanzamiento oficial el 21-04-2026: Disponible en la web de ChatGPT/Codex el 22-04, y para desarrolladores vía API a principios de mayo.
- Primer modelo de imagen con capacidades de agente: Realiza investigación previa, planificación, razonamiento y autoverificación, mejorando drásticamente la tasa de éxito en un solo intento para escenas complejas.
- El texto multilingüe es el avance principal: Precisión a nivel de carácter en escrituras no latinas como CJK, hindi, bengalí y árabe.
- Precios oficiales de $8/$30 (por millón de tokens): La salida de imagen es un 6% más barata que gpt-image-1.5, con una mejora sustancial en las capacidades.
- Cómo empezar: Utiliza una sola clave API de APIYI (apiyi.com) para invocar gpt-image-2 / 1.5 / mini mediante enrutamiento inteligente.
Resumen
Los puntos clave de gpt-image-2 son:
- Salto generacional en capacidades: La introducción del razonamiento de la serie O permite que el modelo de imagen "piense" por primera vez, logrando una mejora cualitativa en la tasa de éxito en escenas complejas.
- Prioridad en la viabilidad comercial: Resolución 2K, soporte para texto multilingüe e integración con búsqueda web apuntan a un objetivo claro: listo para producción, no solo para entretenimiento.
- Precios transparentes y predecibles: La facturación por token es más flexible que las tarifas fijas por uso. Combinado con el nivel "mini", permite construir flujos de generación con costes optimizados.
Para la toma de decisiones en tu equipo, recomendamos empezar a probar gpt-image-2 inmediatamente a través de APIYI (apiyi.com). APIYI ofrece crédito gratuito y permite la integración simplemente cambiando la base_url en el SDK oficial de OpenAI. Además, soporta enrutamiento inteligente entre los modelos mini, 1.5 y 2, ayudándote a validar la mejor solución para cada escenario al menor coste posible.
Lecturas recomendadas
Si te interesa gpt-image-2, te recomiendo seguir explorando estos temas:
- 📘 gpt-image-2 vs gpt-image-1.5: Análisis completo de las 8 mejoras clave – Descubre las razones técnicas detrás de este salto en sus capacidades.
- 📊 gpt-image-2: Análisis de 6 escenarios de aplicación – Domina las rutas de implementación para casos de negocio reales.
- 🚀 gpt-image-2 vs Nano Banana Pro: Comparativa profunda – Elige de forma racional el modelo que mejor se adapte a tus necesidades.
- ⚡ gpt-image-2-all: Solución alternativa por $0.03/invocación – Un canal de invocación estable disponible antes del lanzamiento oficial de la API.
📚 Referencias
-
Anuncio oficial de OpenAI: Lanzamiento de ChatGPT Images 2.0
- Enlace:
openai.com/index/new-chatgpt-images-is-here - Descripción: Especificaciones técnicas y posicionamiento de producto de gpt-image-2.
- Enlace:
-
Evaluación de VentureBeat: Pruebas en texto multilingüe, infografías, mapas y cómics
- Enlace:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - Descripción: Verificación independiente de las capacidades multilingües y de diseño complejo.
- Enlace:
-
Reporte de TechCrunch: Análisis profundo de la capacidad de renderizado de texto
- Enlace:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - Descripción: Comparativa detallada con modelos anteriores como DALL-E 3.
- Enlace:
-
Análisis de PetaPixel: Interpretación de la capacidad de "razonamiento" (Agentic Thinking)
- Enlace:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - Descripción: Cómo el razonamiento de la serie O se integra en el proceso de generación de imágenes.
- Enlace:
-
Precios oficiales de OpenAI: Tabla de precios por millón de tokens
- Enlace:
openai.com/api/pricing - Descripción: Información completa sobre los precios de gpt-image-2 / 1.5 / mini.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.