ملاحظة المؤلف: أطلقت OpenAI رسميًا في 21 أبريل 2026 نموذج gpt-image-2 (ChatGPT Images 2.0). يستعرض هذا المقال بالتفصيل قدراته الأساسية، دقة 2K، دعم النصوص متعددة اللغات، استدلال الوكيل (Agentic)، التسعير الرسمي (8 دولارات / 30 دولارًا لكل مليون رمز)، ومسار الوصول عبر API.
أطلقت OpenAI في 21 أبريل 2026 رسميًا نموذج gpt-image-2 (ChatGPT Images 2.0)، وهو الجيل الثالث من نماذج الصور الرائدة بعد gpt-image-1 في أبريل 2025 وgpt-image-1.5 في ديسمبر 2025. أصبح النموذج متاحًا لجميع مستخدمي ChatGPT وCodex اعتبارًا من 22 أبريل، وسيتم فتح الوصول عبر API للمطورين في أوائل مايو.
هذا ليس مجرد تحديث روتيني، بل هو المحاولة الأولى من OpenAI لدمج "قدرات الاستدلال من سلسلة O" في نموذج صور؛ حيث يقوم gpt-image-2 بالبحث والتخطيط والاستدلال على هيكل الصورة بشكل استباقي قبل البدء في الرسم، مما يجعله أول نموذج لتوليد الصور في الصناعة يتمتع بقدرات وكيل (Agentic) حقيقية.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم بوضوح القدرات الأساسية لنموذج gpt-image-2، وهيكل التسعير، وسيناريوهات الاستخدام، وستتقن أسرع مسار للوصول عبر API.
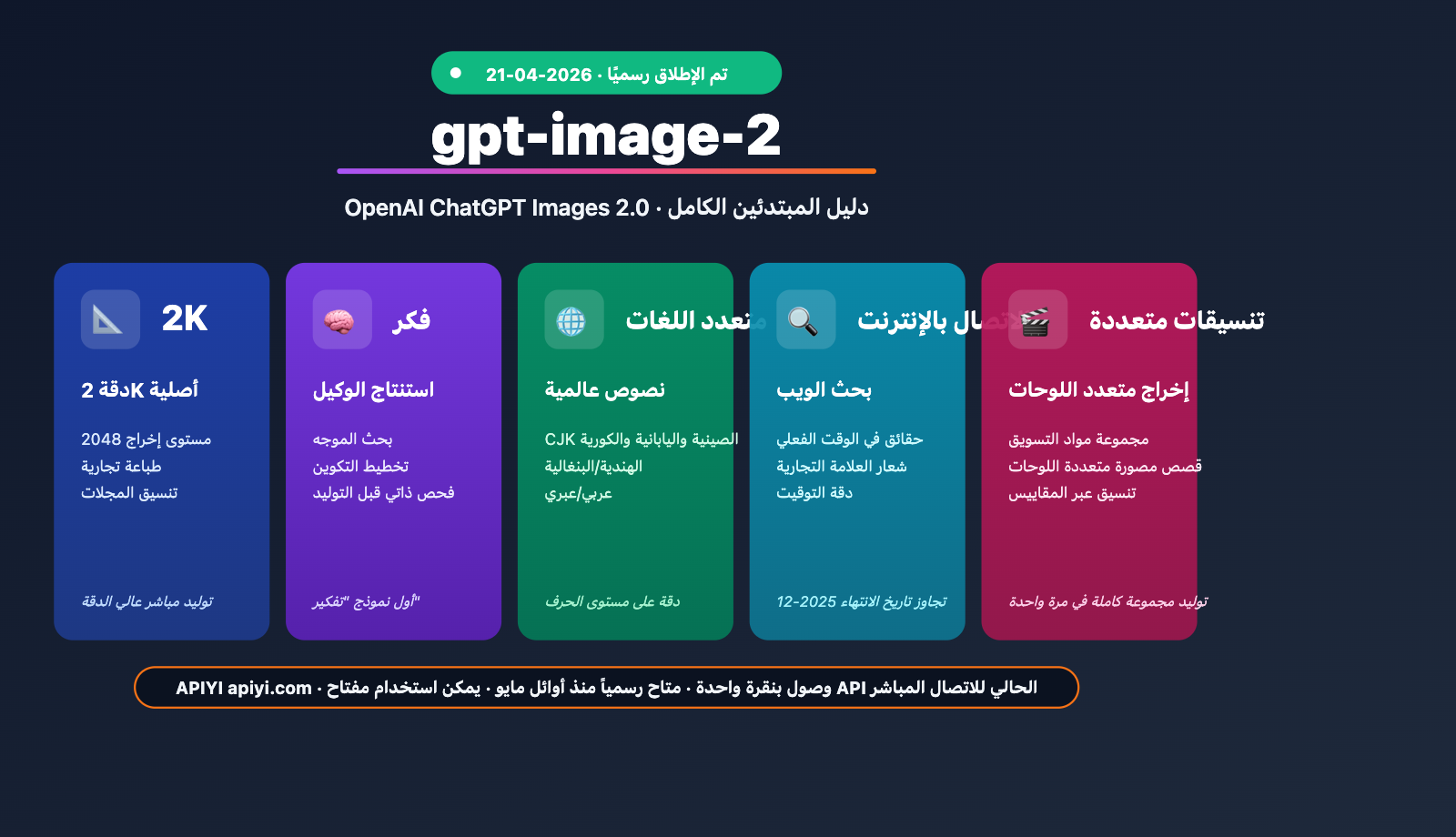
النقاط الجوهرية لـ gpt-image-2
| الميزة | الوصف | القيمة للمبتدئين |
|---|---|---|
| متاح رسمياً | متاح لجميع مستخدمي ChatGPT/Codex منذ 22 أبريل 2026 | لا حاجة لقوائم الانتظار |
| دقة 2K | مخرجات بدقة 2048 أصلية | مواد بجودة الطباعة |
| الاستدلال الوكيل | تخطيط الهيكل قبل البدء بالرسم | دقة عالية في المشاهد المعقدة |
| نصوص متعددة اللغات | وضوح في النصوص العربية، اليابانية، الكورية، الهندية والبنغالية | مثالي للإبداع المحلي |
| تكامل بحث الويب | بحث فوري عبر الإنترنت للتحقق من الحقائق | دقة عالية في الرسوم البيانية |
| فتح API في أوائل مايو | التسعير حسب الـ token | تكاليف يمكن التنبؤ بها |
أهمية إطلاق gpt-image-2
أول نموذج صور يتمتع بقدرات استدلالية. يقدم gpt-image-2 "قدرات التفكير" (Thinking Capabilities) من سلسلة نماذج OpenAI O؛ فقبل توليد البكسل الأول، يقوم النموذج بتحليل معنى الموجه، وتخطيط هيكل التكوين، واستنتاج قيود التفاصيل، ثم يبدأ في العرض. تشير تقارير TechCrunch إلى أن هذا النهج الوكيل (Agentic) يرفع بشكل كبير من معدل النجاح من المحاولة الأولى في المشاهد المعقدة (مثل تنسيق المجلات، القصص المصورة متعددة اللوحات، والرسوم البيانية).
النصوص والتفاصيل هي الاختراق الأكبر. تؤكد OpenAI أن gpt-image-2 يمكنه عرض النصوص الصغيرة، الأيقونات، عناصر واجهة المستخدم، التكوينات الكثيفة، وقيود الأسلوب الدقيقة بدقة عالية—وهي نقاط الضعف التي عانت منها جميع نماذج الصور السابقة. وقد وصفت مراجعة VentureBeat النموذج بأنه "ينجز النصوص متعددة اللغات، والرسوم البيانية الكاملة، والشرائح التقديمية، والخرائط، وحتى القصص المصورة بسلاسة تامة".

شرح القدرات الخمس الجوهرية لـ gpt-image-2
القدرة الأولى: دقة أصلية تصل إلى 2K
يدعم gpt-image-2 أصلياً دقة تصل إلى 2K (مستوى 2048)، وهي كافية لتلبية احتياجات التنسيق المكتبي، والطباعة التجارية، ومحتوى الشاشات عالية الدقة. وعلى الرغم من أن بعض التسريبات المبكرة أشارت إلى دقة 4K، إلا أن المصادر الرسمية أكدت أنها 2K، وهو ما يعد كافياً تماماً للغالبية العظمى من السيناريوهات التجارية.
القدرة الثانية: عرض دقيق للنصوص متعددة اللغات
هذا هو التحديث الجوهري الذي أكدت عليه الشركة. يدعم النموذج توليد نصوص عالية الدقة باللغات التالية:
| فئة اللغة | اللغات الممثلة | التطبيقات النموذجية |
|---|---|---|
| CJK | الصينية، اليابانية، الكورية | الإعلانات المحلية |
| لغات جنوب آسيا | الهندية، البنغالية | محتوى أسواق جنوب آسيا |
| اللغات اللاتينية | الإنجليزية، الإسبانية، الفرنسية | الأسواق العالمية الرئيسية |
| الحروف المعقدة | العربية، العبرية | أسواق الشرق الأوسط |
تضمنت حالات الاختبار التي أجرتها VentureBeat: أغلفة مجلات كاملة، قوائم طعام بلغات متعددة، خرائط مترو، وفقاعات حوار في المانجا اليابانية—حيث بدت جميع النصوص "متناغمة تماماً".
القدرة الثالثة: الاستنتاج الوكيل (Agentic "Thinking")
هذا هو الابتكار المعماري الحقيقي في gpt-image-2. على عكس خط العمل السابق "موجه ← توليد مباشر"، يقوم النموذج الآن بـ:
- البحث (Research): فهم الكيانات والعلاقات والقيود الموجودة في الموجه.
- التخطيط (Plan): تصور تخطيط المشهد، ومواقع العناصر، والتسلسل الهرمي البصري.
- الاستنتاج (Reason): التحقق المتبادل من قيود التفاصيل (الخط، النسبة، منطق الألوان).
- الفحص الذاتي قبل التسليم (Double-check): التحقق مرة أخرى بعد اكتمال التوليد للتأكد من مطابقة المتطلبات.
هذا النهج الوكيل يجعله يتفوق بشكل كبير على الجيل السابق في الرسوم البيانية، تركيب العناصر المتعددة، وسيناريوهات القيود الصارمة.
القدرة الرابعة: تكامل البحث عبر الويب
يحتوي gpt-image-2 على قدرة بحث مدمجة عبر الويب، مما يسمح له بالاستعلام عن أحدث الحقائق، وشعارات الشركات، ومظاهر المنتجات في الوقت الفعلي قبل التوليد. هذا يحل مشكلة الانحراف عن الواقع الناتجة عن "تاريخ انتهاء بيانات التدريب" (أكدت الشركة أن تاريخ انتهاء المعرفة هو ديسمبر 2025).
على سبيل المثال، عند توليد "ملصق لمكان إقامة أسبوع الموضة في باريس لعام 2026"، سيقوم النموذج بالاتصال بالإنترنت أولاً للتأكد من اسم المكان، والتاريخ، والعلامة التجارية الراعية، قبل البدء في عملية الإبداع.
القدرة الخامسة: مخرجات متعددة التنسيقات في وقت واحد
يمكن لـ gpt-image-2 توليد مجموعة من المواد التسويقية بأحجام مختلفة أو صفحات مانجا متعددة بناءً على موجه واحد. في اختبارات TechCrunch، أدى إدخال "تصميم 4 مواد لوسائل التواصل الاجتماعي لعلامة تجارية جديدة للقهوة" إلى الحصول على أربعة تصاميم متناسقة بأبعاد 1:1، 9:16، 16:9، و3:4 في وقت واحد.
قراءة في التسعير الرسمي لـ gpt-image-2
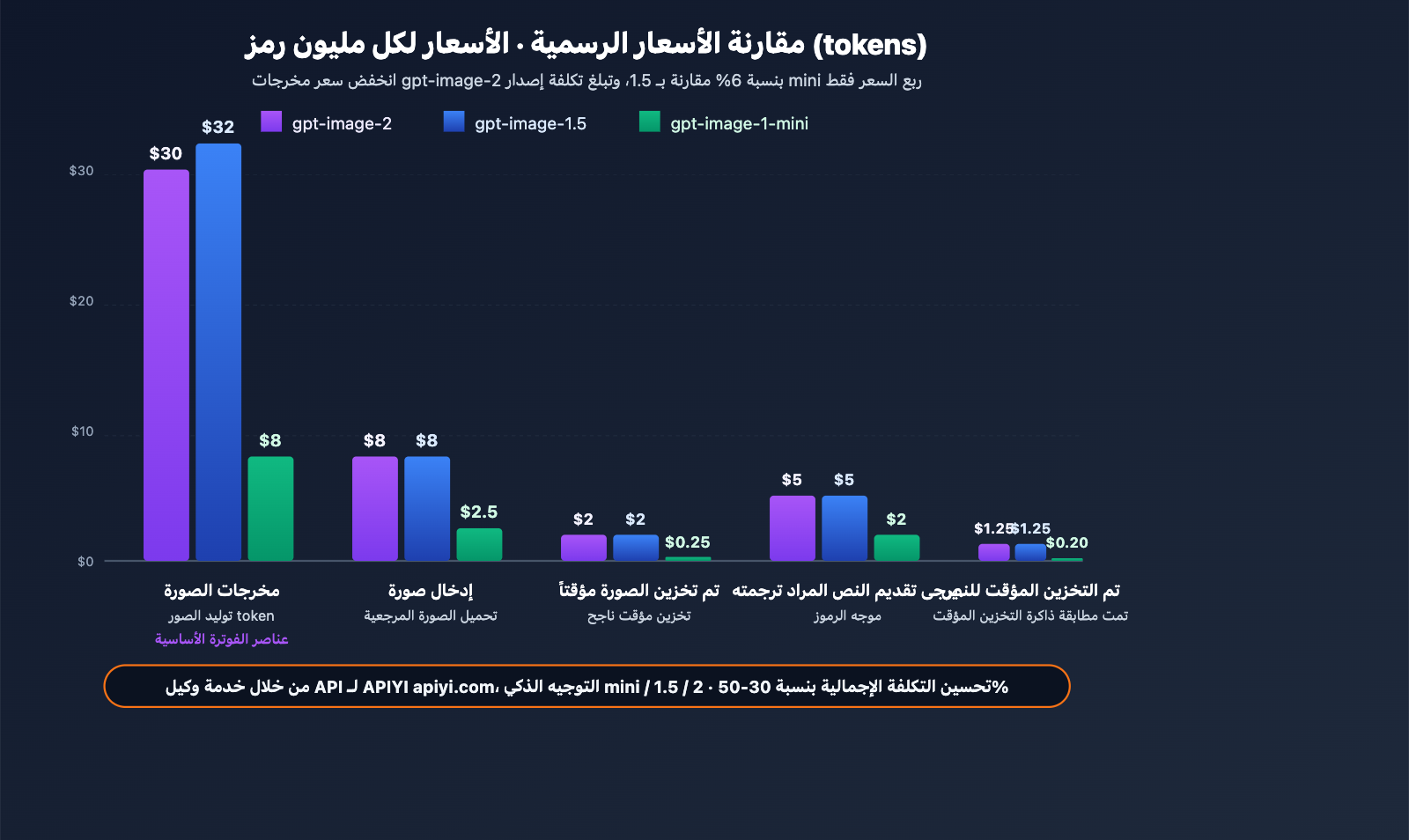
جدول التسعير الرسمي (لكل مليون رمز/token)
| النموذج | إدخال الصورة | صورة مخزنة مؤقتاً | إخراج الصورة | إدخال النص | نص مخزن مؤقتاً | إخراج النص |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
قراءة تحليلية
منطق التسعير: يتم المحاسبة بناءً على عدد رموز (tokens) الإدخال والإخراج، وليس بناءً على عدد الصور. هذا يعني أن التكلفة الفردية للدقة العالية والموجهات المعقدة ستكون أعلى، بينما تكون المهام ذات التعقيد المنخفض أوفر—وهو نهج أكثر مرونة من "الرسوم الثابتة لكل عملية".
مقارنة مع gpt-image-1.5:
- انخفض سعر إخراج الصورة من $32 إلى $30 (-6%).
- ظلت تكاليف إدخال/تخزين الصور ثابتة.
- ظلت تكاليف إدخال/تخزين النصوص ثابتة، ولكن تم إلغاء بند محاسبة إخراج النص (حيث يركز gpt-image-2 على توليد الصور فقط).
- الخلاصة: التكلفة الإجمالية لـ gpt-image-2 انخفضت قليلاً، لكن القدرات تحسنت بشكل كبير، مما يجعل القيمة مقابل السعر ممتازة.
أهمية نسخة mini: بالنسبة للسيناريوهات التي لا تتطلب جودة فائقة (الصور المصغرة الجماعية، المسودات، المعاينات)، توفر gpt-image-1-mini القدرات الأساسية بـ حوالي ربع السعر، وهي مناسبة للسيناريوهات الحساسة للتكلفة على نطاق واسع.
تقدير تكلفة السيناريوهات النموذجية
| السيناريو | تقدير لكل صورة | ملاحظات |
|---|---|---|
| صورة قياسية بموجه بسيط | $0.04-$0.08 | استهلاك منخفض للرموز |
| صورة إعلانية متوسطة التعقيد | $0.10-$0.15 | استهلاك متوسط للرموز |
| رسم بياني عالي التعقيد | $0.20-$0.35 | عناصر متعددة + موجه طويل |
| تحرير ودمج صور متعددة | $0.15-$0.30 | استخدام صورة مرجعية |
نصيحة لتحسين التكلفة: من خلال إدارة الحساب الموحدة عبر خدمة وكيل API (APIYI – apiyi.com)، يمكنك التوجيه التلقائي بناءً على نوع المهمة؛ استخدم
gpt-image-1-miniللمعاينة البسيطة ($8 للإخراج)، وgpt-image-2للتسليم عالي الجودة ($30 للإخراج)، مما يحسن التكلفة الإجمالية بنسبة 30-50%.
دليل البدء السريع لـ gpt-image-2
مثال بسيط للاستدعاء
import openai
# إعداد العميل باستخدام مفتاح API الخاص بك
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
# استدعاء النموذج لتوليد صورة
response = client.images.generate(
model="gpt-image-2",
prompt="غلاف مجلة بدقة 2K، علامة تجارية للقهوة 'Moonlight Baking'، "
"الرؤية البصرية الرئيسية بدرجات البني الداكن، "
"العنوان الرئيسي بالصينية 'Slow Cooking Time'، العنوان الفرعي 'Issue 042 · 2026 Spring Edition'",
size="2048x2048"
)
print(response.data[0].url)
عرض كود التنفيذ الكامل (يدعم تعدد اللغات، دمج الصور، والترقية الذكية)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
توجيه ذكي: اختيار النموذج الأمثل بناءً على مستوى الجودة المطلوب
Args:
prompt: وصف الصورة
quality_tier:
- mini: للمعاينة الجماعية / المسودات (gpt-image-1-mini، أرخص بـ 4 مرات)
- standard: للتسليمات العادية (gpt-image-1.5)
- premium: جودة عالية + قدرات وكيل ذكي (gpt-image-2)
size: أبعاد الصورة الناتجة
Returns:
رابط الصورة المولدة
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"فشل التوليد: {e}")
return None
# أمثلة بلغات متعددة
multilingual_examples = {
"japanese": "غلاف مانغا ياباني، العنوان '月の向こうへ'، العنوان الفرعي '第1話'",
"korean": "غلاف ألبوم K-pop، عنوان كبير '봄이 올 때'",
"hindi": "ملصق فيلم بوليوود، العنوان 'मानसून की रात'",
"arabic": "ملصق خط عربي، المحتوى 'مرحبا بالعالم'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
نصيحة المنصة: من خلال APIYI (apiyi.com)، يمكنك استدعاء نماذج gpt-image-2 وgpt-image-1.5 وgpt-image-1-mini في وقت واحد، واستخدام مفتاح API واحد لإدارة "التوجيه الذكي" (استخدام mini للمسودات، وpremium للنسخ النهائية).
مقارنة gpt-image-2 مع المنافسين
| النموذج | التصنيف | الميزة الأساسية | السعر الرسمي |
|---|---|---|---|
| gpt-image-2 | أحدث إصدار من OpenAI | استنتاج ذكي + نصوص متعددة اللغات | Output $30/M token |
| gpt-image-1.5 | الإصدار السابق | استقرار ونظام API متكامل | Output $32/M token |
| gpt-image-1-mini | خفيف للمبتدئين | تكلفة أقل بـ 4 مرات · سرعة عالية | Output $8/M token |
| Nano Banana Pro | إصدار Google | 14 صورة مرجعية + SynthID | $0.045-$0.151 لكل صورة |
| Midjourney v7 | الخيار الفني الأول | جماليات فنية رائدة | نظام اشتراك |
تحليل مقارن لـ gpt-image-2
Nano Banana Pro: يتفوق Banana Pro في اتساق الوجوه (باستخدام 14 صورة مرجعية)، ونضج التعديل، والعلامات المائية المتوافقة. ومع ذلك، يوفر gpt-image-2 ميزات تنافسية في دقة النصوص متعددة اللغات، وقدرات الاستنتاج الذكي، وتكامل البحث عبر الويب.
gpt-image-1.5: لا يزال الخيار الأكثر استقراراً وموثوقية، مع نظام API ناضج جداً، مما يجعله مناسباً للمشاريع التي لا تتطلب قدرات وكيل ذكي متقدمة. نوصي باستخدام gpt-image-2 للمشاريع الجديدة، بينما يمكن ترحيل المشاريع القديمة تدريجياً حسب الحاجة.
Midjourney: يظل Midjourney الأقوى في الجانب الفني. بينما يعد gpt-image-2 أكثر ملاءمة لسيناريوهات الاستخدام التجاري مثل صور المنتجات، واجهات المستخدم (UI)، الرسوم البيانية، والمواد المترجمة محلياً.
ملاحظة حول الاختيار: يعتمد اختيار النموذج على سيناريو تطبيقك ومتطلبات الجودة. نوصي بإجراء اختبارات فعلية عبر منصة APIYI (apiyi.com)، حيث يتيح لك ربط واحد مقارنة عدة نماذج رائدة بسهولة.
سيناريوهات التطبيق النموذجية لـ gpt-image-2
ستة سيناريوهات مثالية للمبتدئين للبدء بسرعة:
- السيناريو 1 · مواد التسويق – يتيح الاستدلال الوكيل (Agentic) ضبط العناوين، وإبراز المنتج، وتنسيق التسلسل البصري في محاولة واحدة.
- السيناريو 2 · الرسوم البيانية/التعليمية – بحث الويب + نصوص متعددة اللغات + دقة عالية في تسميات البيانات.
- السيناريو 3 · القصص المصورة متعددة اللوحات – توليد عدة إطارات في وقت واحد + وضوح نصوص فقاعات الحوار.
- السيناريو 4 · تنسيق المجلات – دقة 2K + دعم تخطيطات معقدة جاهزة للطباعة التجارية.
- السيناريو 5 · الإعلانات المحلية – دقة عالية على مستوى الأحرف للغات (الصينية، اليابانية، الكورية، الهندية، البنغالية، والعربية).
- السيناريو 6 · نماذج واجهة المستخدم (UI Mockup) – دقة في عرض النصوص الصغيرة، الأيقونات، والتخطيطات الكثيفة.
نصيحة للمبتدئين: يُنصح بالبدء بسيناريوهي "مواد التسويق" و"الرسوم البيانية"؛ فهما الأفضل لتجربة القفزة النوعية في قدرات gpt-image-2 مقارنة بالإصدارات السابقة. يمكنك الحصول على رصيد تجريبي مجاني عبر APIYI على apiyi.com للبدء فوراً.
الأسئلة الشائعة (FAQ)
س1: ما هو gpt-image-2؟
gpt-image-2 هو الجيل التالي من نماذج توليد الصور الذي أطلقته OpenAI رسمياً في 21 أبريل 2026، ويُعرف أيضاً باسم "ChatGPT Images 2.0". وهو أول نموذج صور يدمج قدرات الاستدلال من سلسلة O، ويدعم دقة 2K، والنصوص متعددة اللغات، والتخطيط الوكيل (Agentic)، وتكامل بحث الويب. أصبح متاحاً لجميع مستخدمي ChatGPT/Codex منذ 22 أبريل، وسيتم فتح الـ API في أوائل مايو.
س2: ما هي أكبر الترقيات في gpt-image-2 مقارنة بـ gpt-image-1.5؟
ثلاث ترقيات جوهرية: (1) الاستدلال الوكيل (Agentic) – يقوم النموذج بالبحث والتخطيط والاستدلال على هيكل الصورة قبل توليدها، مما يرفع نسبة النجاح في المشاهد المعقدة بشكل كبير؛ (2) النصوص متعددة اللغات – دقة على مستوى الأحرف للغات غير اللاتينية مثل اليابانية، الكورية، الصينية، الهندية، والبنغالية؛ (3) تكامل بحث الويب – استعلام عن الحقائق في الوقت الفعلي لحل مشكلة توقف المعرفة. بالإضافة إلى ذلك، انخفض سعر مخرجات الصور من 32 دولاراً لكل مليون رمز (token) إلى 30 دولاراً، مما يوفر قيمة أفضل مقابل التكلفة.
س3: متى سيكون API الرسمي لـ gpt-image-2 متاحاً؟
وفقاً لإعلان OpenAI الرسمي، يمكن لمستخدمي ChatGPT/Codex استخدامه مباشرة عبر الويب بدءاً من 22 أبريل 2026، وسيتم فتح API الخاص بـ gpt-image-2 للمطورين في أوائل مايو 2026. قبل الإطلاق الرسمي، يمكنك الوصول إلى أحدث قدرات توليد الصور عبر خدمة APIYI على apiyi.com باستخدام حل gpt-image-2-all (بتكلفة 0.03 دولار لكل محاولة)، مع إمكانية الانتقال السلس للخدمة الرسمية عند إطلاقها.
س4: كيف نفهم تسعير الرموز (token) مثل 8 دولار / 30 دولار؟
هذا هو سعر الوحدة لكل مليون رمز (token)، وهو يتبع نفس منطق محاسبة نماذج النصوص مثل GPT-4o:
- مدخلات الصور (Image Input) 8 دولار: تكلفة الرموز عند قيام المستخدم برفع صورة مرجعية.
- الصور المخزنة مؤقتاً (Image Cached) 2 دولار: تكلفة الرموز للمدخلات التي تطابق ذاكرة التخزين المؤقت (تخفيض كبير للصور المكررة).
- مخرجات الصور (Image Output) 30 دولار: تكلفة الرموز عند توليد الصور.
- مدخلات النصوص (Text Input) 5 دولار: تكلفة مدخلات الموجه (prompt) النصي.
تتراوح تكلفة الصورة الواحدة عادةً بين 0.04 و 0.35 دولار، اعتماداً على تعقيد الموجه ودقة المخرجات.
س5: كيف يمكن الوصول إلى gpt-image-2 عبر API؟
أسرع طريقة هي عبر APIYI على apiyi.com:
- قم بزيارة apiyi.com لإنشاء حساب والحصول على مفتاح API.
- اضبط
base_urlعلىhttps://vip.apiyi.com/v1. - استخدم حزمة تطوير البرمجيات (SDK) الرسمية من OpenAI، وقم باستدعاء النموذج باستخدام
model="gpt-image-2".
تطلق APIYI النماذج الجديدة بالتزامن مع OpenAI، مع بقاء مفاتيحك وأرصدتك وفواتيرك الحالية كما هي، حيث يدعم الحساب الواحد جميع النماذج الرئيسية مثل gpt-image-2 / gpt-image-1.5 / gpt-image-1-mini / Nano Banana Pro.
س6: كيف أختار بين gpt-image-2 و gpt-image-1-mini؟
الاختيار بناءً على حساسية الجودة:
- gpt-image-2: مخرجات الصور بتكلفة 30 دولاراً لكل مليون رمز، مناسب للمخرجات النهائية الرسمية (تصاميم إعلانية، مواد مطبوعة، مقترحات العملاء).
- gpt-image-1-mini: مخرجات الصور بتكلفة 8 دولار لكل مليون رمز (حوالي الربع)، مناسب للمعاينة الجماعية، تكرار المسودات، الصور المصغرة، والتجارب الاستكشافية.
سير العمل الشائع هو الاستخدام المشترك: استخدم mini لتكرار 10-20 مسودة بسرعة، وبعد اختيار الاتجاه المناسب، استخدم gpt-image-2 لاستخراج النسخة النهائية عالية الجودة.
س7: كيف تساعد قدرة “التفكير” (Thinking) الوكيل المبتدئين عملياً؟
تكمن أكبر مساعدة للمبتدئين في خفض عتبة هندسة الموجهات (prompt engineering). في السابق، كان الأمر يتطلب ضبطاً دقيقاً للموجه لتجنب "الرسم العشوائي" للذكاء الاصطناعي، أما الآن فيقوم النموذج بالاستدلال الاستباقي على ما تريده:
- إذا قلت "غلاف مجلة" ← سيخطط لتسلسل الخطوط، والمساحات الفارغة، وموقع الصورة الرئيسية.
- إذا قلت "رسم بياني" ← سيستدل على دقة البيانات، وموقع مفتاح الرسم، ودلالات الألوان.
- إذا قلت "قصة مصورة متعددة اللوحات" ← سيخطط لإيقاع اللقطات، وموقع فقاعات الحوار، واتساق الشخصيات.
النتيجة: يمكن للمبتدئين الحصول على مخرجات احترافية باستخدام موجهات بسيطة.
س8: ما هي القيود المعروفة لـ gpt-image-2؟
هناك ثلاث فئات من القيود:
- توقف المعرفة عند 2025-12: قد لا يكون توليد محتوى يتعلق بأحداث أو منتجات عام 2026 دقيقاً، ويعتمد على قدرات بحث الويب للتعويض.
- الحد الأقصى 2K في المرة الواحدة: الأحجام التي تتجاوز 2048 بكسل تتطلب معالجة لاحقة لرفع الدقة (Upscaling).
- تأخير الـ API: يستغرق الاستدلال الوكيل وقتاً أطول من العرض المباشر، لذا تتطلب التطبيقات التفاعلية تصميماً ذكياً لمؤشرات التحميل.
- اعتبارات الامتثال: لا تزال علامة SynthID المائية في Nano Banana Pro + تعويضات حقوق النشر هي الخيار الأول للمشاهد الحساسة للامتثال.
أبرز مميزات gpt-image-2
- الإطلاق الرسمي في 21 أبريل 2026: سيتم توفير الخدمة عبر واجهة الويب لـ ChatGPT/Codex في 22 أبريل، بينما ستتاح للمطورين عبر API في أوائل شهر مايو.
- أول نموذج صور ذكي (Agentic): يتميز بقدرات البحث المسبق، التخطيط، الاستدلال، والتدقيق الذاتي، مما يرفع بشكل كبير من معدل النجاح في المحاولات الأولى للمشاهد المعقدة.
- دعم اللغات المتعددة هو الاختراق الجوهري: دقة عالية على مستوى الحروف للغات غير اللاتينية مثل الصينية واليابانية والكورية (CJK)، الهندية، البنغالية، والعربية.
- التسعير الرسمي 8 دولار / 30 دولار (لكل مليون token): انخفاض في تكلفة مخرجات الصور بنسبة 6% مقارنة بـ gpt-image-1.5 مع تحسن هائل في القدرات.
- طريقة البدء: يمكنك استدعاء gpt-image-2 / 1.5 / mini عبر التوجيه الذكي باستخدام مفتاح API واحد من APIYI (apiyi.com).
ملخص
تتمثل النقاط الجوهرية لنموذج gpt-image-2 في الآتي:
- قفزة نوعية في القدرات: إدخال سلسلة O للاستدلال يمنح نموذج الصور لأول مرة قدرة على "التفكير"، مما يؤدي إلى تحسن جذري في معدل النجاح من المحاولة الأولى في المشاهد المعقدة.
- أولوية الاستخدام التجاري: دقة 2K، دعم اللغات المتعددة، وتكامل البحث عبر الويب، كلها مؤشرات تهدف إلى جعل النموذج جاهزاً للاستخدام الإنتاجي المباشر وليس فقط للترفيه.
- تسعير شفاف وقابل للتنبؤ: المحاسبة بناءً على الـ token توفر مرونة أكبر مقارنة بالرسوم الثابتة لكل عملية، ومع وجود فئة mini، يمكنك بناء خط إنتاج صور بأقل تكلفة ممكنة.
بالنسبة لقرارات فريقك، نوصي بالبدء فوراً في تجربة gpt-image-2 عبر APIYI (apiyi.com). توفر APIYI رصيداً مجانياً، ويمكنك الوصول للخدمة ببساطة عبر تبديل base_url في حزمة تطوير البرمجيات (SDK) الرسمية لـ OpenAI. كما تدعم المنصة التوجيه الذكي بين فئات mini / 1.5 / 2، مما يساعدك على التحقق من الحل الأمثل لكل سيناريو بأقل التكاليف.
قراءة إضافية
إذا كنت مهتماً بنموذج gpt-image-2، نوصي بمتابعة القراءة حول المواضيع التالية:
- 📘 gpt-image-2 مقابل gpt-image-1.5: تحليل شامل للترقيات الثماني – لفهم الأسباب الجوهرية لهذا القفزة في القدرات.
- 📊 تحليل شامل لستة سيناريوهات تطبيقية لنموذج gpt-image-2 – لإتقان مسارات التنفيذ في الأعمال الفعلية.
- 🚀 مقارنة متعمقة: gpt-image-2 مقابل Nano Banana Pro – لاختيار النموذج الأمثل بعقلانية.
- ⚡ حل بديل لـ gpt-image-2-all بتكلفة 0.03 دولار لكل عملية – قناة استدعاء مستقرة قبل الإطلاق الرسمي لـ API.
📚 المراجع
-
إعلان OpenAI الرسمي: إطلاق ChatGPT Images 2.0
- الرابط:
openai.com/index/new-chatgpt-images-is-here - الوصف: مواصفات القدرات الرسمية وتحديد موقع منتج gpt-image-2.
- الرابط:
-
تقييم VentureBeat: اختبارات عملية للنصوص متعددة اللغات، الرسوم البيانية، الخرائط، والرسوم الهزلية
- الرابط:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - الوصف: تحقق مستقل من قدرات النموذج في التعامل مع اللغات المتعددة والتنسيقات المعقدة.
- الرابط:
-
تقرير TechCrunch: تقييم متعمق لقدرات عرض النصوص
- الرابط:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - الوصف: مقارنة تفصيلية مع النماذج السابقة مثل DALL-E 3.
- الرابط:
-
تحليل PetaPixel: تفسير قدرات "التفكير" الوكيل (Agentic Thinking)
- الرابط:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - الوصف: كيف يتم دمج استدلال سلسلة O في عملية توليد الصور.
- الرابط:
-
تسعير OpenAI الرسمي: جدول الأسعار لكل مليون رمز (token)
- الرابط:
openai.com/api/pricing - الوصف: معلومات التسعير الكاملة لنماذج gpt-image-2 / 1.5 / mini.
- الرابط:
الكاتب: فريق APIYI التقني
تبادل تقني: نرحب بمناقشاتكم في قسم التعليقات، ولمزيد من المعلومات يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com