Note de l'auteur : OpenAI a officiellement lancé gpt-image-2 (ChatGPT Images 2.0) le 21/04/2026. Cet article présente en détail ses capacités principales, sa résolution 2K, la gestion du texte multilingue, le raisonnement de type Agent, la tarification officielle (8 $/30 $ par million de tokens) et le chemin d'accès à l'API.
OpenAI a officiellement lancé gpt-image-2 (ChatGPT Images 2.0) le 21 avril 2026. Il s'agit de la troisième génération de modèle d'image phare, succédant au gpt-image-1 d'avril 2025 et au gpt-image-1.5 de décembre 2025. Depuis le 22 avril, tous les utilisateurs de ChatGPT et de Codex peuvent l'utiliser, et l'API sera ouverte aux développeurs début mai.
Il ne s'agit pas d'une mise à jour classique, mais de la première tentative d'OpenAI d'intégrer les "capacités de raisonnement de la série O" dans un modèle d'image. Avant de générer, gpt-image-2 étudie, planifie et raisonne activement sur la structure de l'image, ce qui en fait le premier véritable modèle de génération d'images de type Agent.
Valeur ajoutée : En lisant cet article, vous comprendrez clairement les capacités principales, la structure tarifaire et les scénarios d'utilisation de gpt-image-2, tout en maîtrisant le chemin d'accès le plus rapide à l'API.

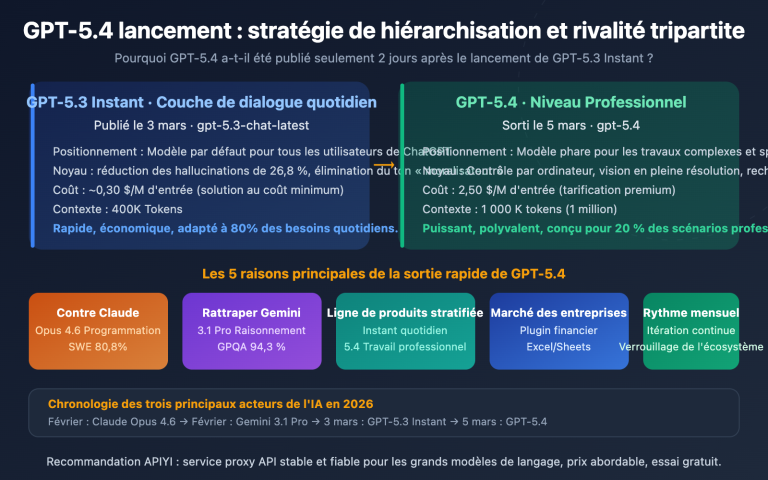
Points clés de gpt-image-2
| Caractéristique | Description | Valeur pour les débutants |
|---|---|---|
| Disponibilité officielle | Ouvert à tous les utilisateurs de ChatGPT/Codex depuis le 22/04/2026 | Pas de liste d'attente |
| Résolution 2K | Sortie native en 2048 pixels | Qualité d'impression |
| Raisonnement Agentique | Planification de la structure avant le rendu | Réussite dès le premier essai |
| Texte multilingue | Texte clair en japonais, coréen, chinois, hindi, bengali | Idéal pour la création locale |
| Intégration Web | Recherche en temps réel pour vérifier les faits | Infographies précises |
| API début mai | Facturation basée sur les jetons | Coûts prévisibles |
L'importance du lancement de gpt-image-2
Le premier modèle d'image doté de capacités de raisonnement. gpt-image-2 intègre les "capacités de réflexion" de la série O d'OpenAI. Avant de générer le premier pixel, le modèle étudie la signification de l'invite, planifie la structure de la composition et raisonne sur les contraintes de détail avant de lancer le rendu. Comme le souligne TechCrunch, cette approche agentique augmente considérablement le taux de réussite dès le premier essai pour les scènes complexes (mise en page de magazines, bandes dessinées multi-panneaux, infographies).
Le texte et les détails sont la percée majeure. OpenAI souligne officiellement que gpt-image-2 peut rendre avec précision les petits textes, les icônes, les éléments d'interface utilisateur, les compositions denses et les contraintes de style subtiles — ce qui était le point faible de tous les modèles d'image précédents. VentureBeat a noté dans son évaluation qu'il "semble avoir parfaitement maîtrisé le texte multilingue, les infographies complètes, les diapositives, les cartes et même les bandes dessinées".
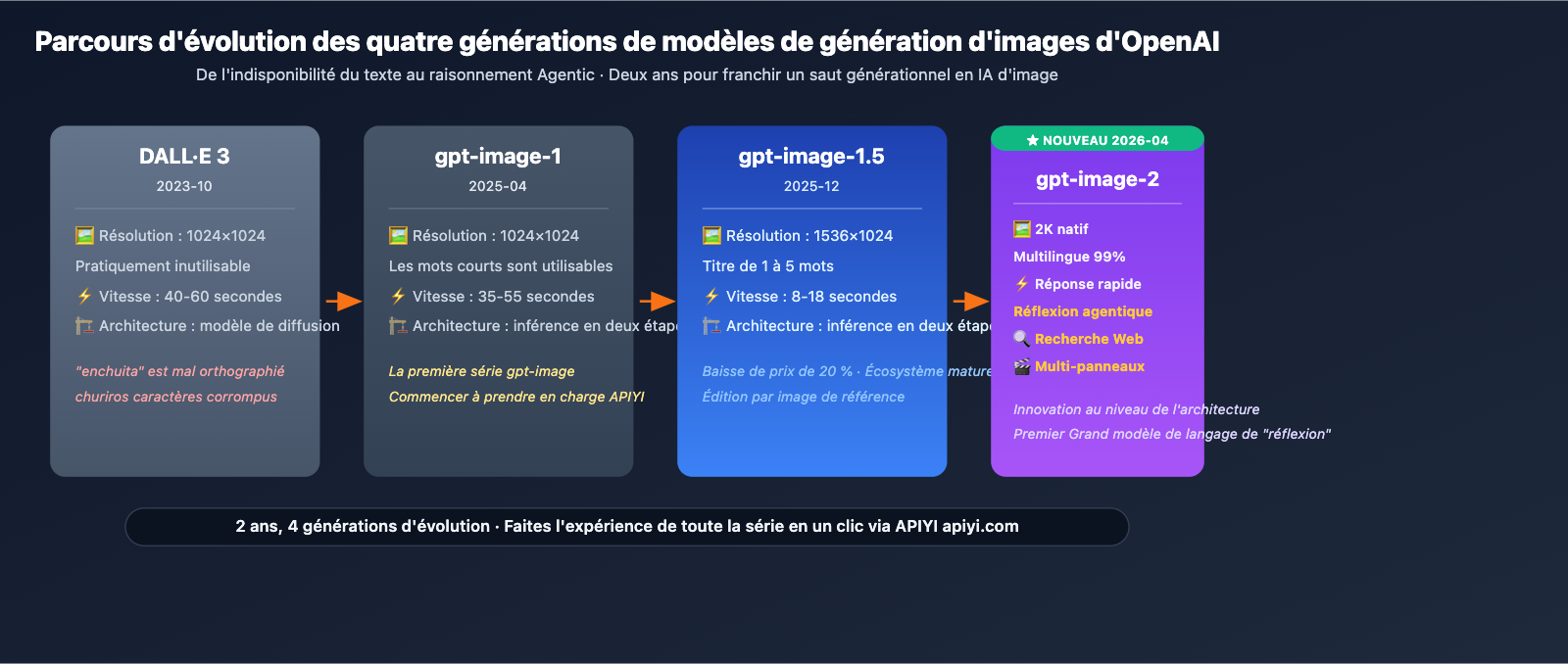
Analyse détaillée des 5 capacités clés de gpt-image-2
Capacité 1 : Résolution native 2K
gpt-image-2 prend nativement en charge une résolution allant jusqu'au 2K (2048 pixels), ce qui est largement suffisant pour la mise en page de magazines, l'impression commerciale et les contenus destinés aux écrans haute définition. Bien que certaines fuites initiales aient évoqué la 4K, le chiffre officiel est bien de 2K, ce qui s'avère parfaitement adapté à la grande majorité des cas d'usage professionnels.
Capacité 2 : Rendu précis de texte multilingue
C'est l'amélioration majeure mise en avant par l'éditeur. Le modèle permet une génération de texte haute fidélité dans les langues suivantes :
| Catégorie linguistique | Langues représentatives | Applications typiques |
|---|---|---|
| CJK | Chinois, Japonais, Coréen | Publicités localisées |
| Langues d'Asie du Sud | Hindi, Bengali | Contenu pour le marché sud-asiatique |
| Langues latines | Anglais, Espagnol, Français | Marchés mondiaux principaux |
| Caractères complexes | Arabe, Hébreu | Marché du Moyen-Orient |
Les tests effectués par VentureBeat incluent : des visuels clés pour des couvertures de magazines, des menus de restaurants multilingues, des annotations de plans de métro et des bulles de dialogue pour mangas — avec un rendu de texte "parfaitement intégré".
Capacité 3 : Raisonnement "Agentic" (Thinking)
Il s'agit de la véritable innovation architecturale de gpt-image-2. Contrairement aux pipelines classiques "invite → rendu direct", le modèle procède par étapes :
- Recherche : Analyse de l'invite pour comprendre les entités, les relations et les contraintes.
- Planification : Conception de la mise en page, de l'emplacement des éléments et de la hiérarchie visuelle.
- Raisonnement : Vérification croisée des contraintes de détails (police, proportions, logique des couleurs).
- Auto-vérification avant livraison : Contrôle final après génération pour s'assurer de la conformité aux exigences.
Cette approche "Agentic" permet d'obtenir un taux de réussite bien supérieur à la génération précédente, notamment pour les infographies, les compositions multi-éléments et les scénarios à fortes contraintes.
Capacité 4 : Intégration de la recherche Web
gpt-image-2 intègre une capacité de recherche Web, permettant d'interroger en temps réel les faits les plus récents, les logos d'entreprises ou l'apparence de produits avant de lancer la génération. Cela résout le problème du décalage lié à la date de fin d'entraînement (officiellement fixée à décembre 2025).
Par exemple, pour générer une "affiche pour la Fashion Week de Paris 2026", le modèle vérifiera d'abord en ligne le nom du lieu, les dates et les marques organisatrices avant d'entamer le processus de création.
Capacité 5 : Sortie multi-formats en une seule fois
gpt-image-2 peut générer des combinaisons de supports marketing de différentes tailles ou des planches de bandes dessinées à partir d'une seule invite. Lors des tests de TechCrunch, une demande pour "concevoir 4 visuels de réseaux sociaux pour une nouvelle marque de café" a permis d'obtenir simultanément quatre visuels cohérents aux formats 1:1, 9:16, 16:9 et 3:4.
Analyse de la tarification officielle de gpt-image-2
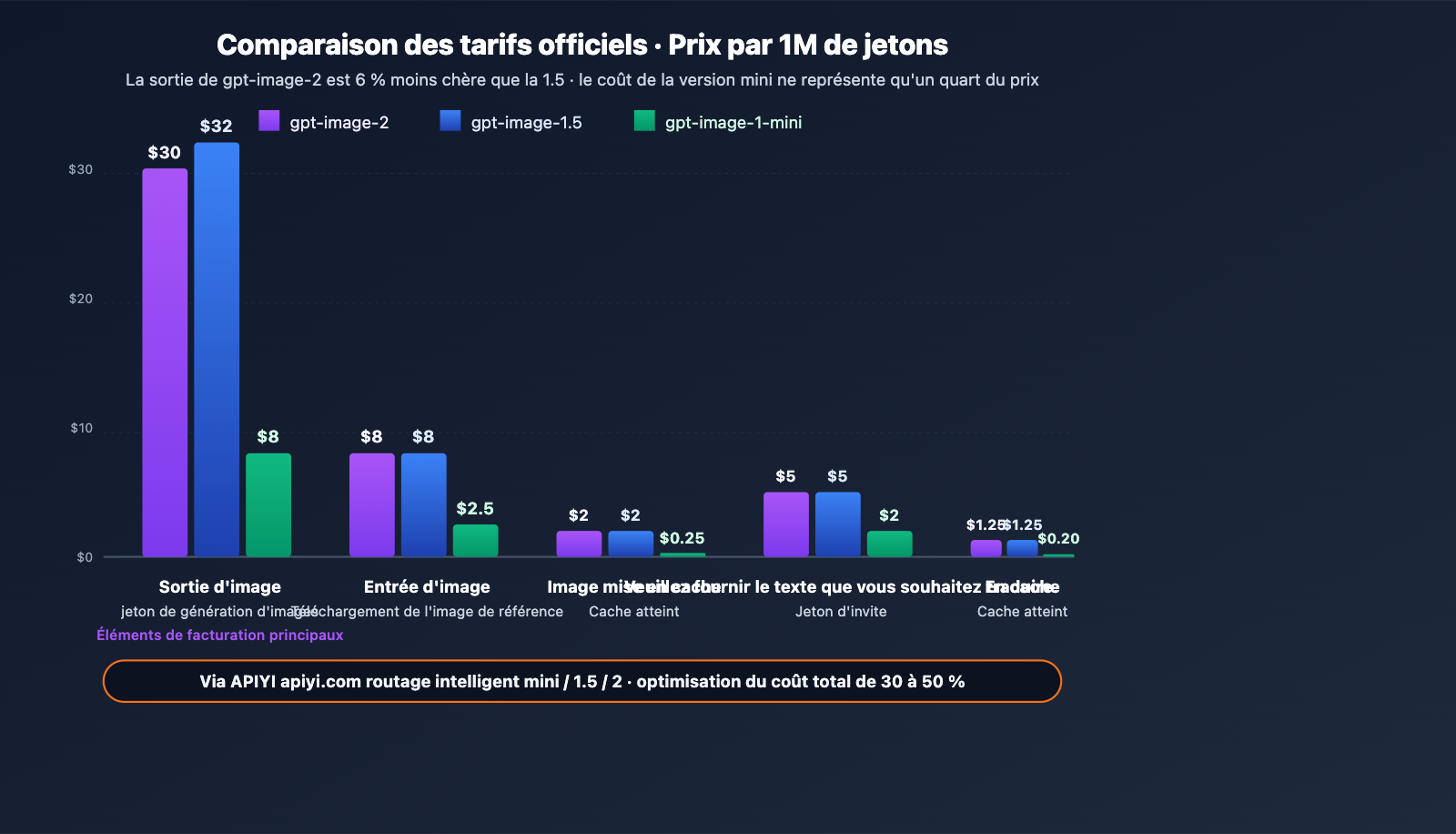
Tableau tarifaire officiel (par million de jetons)
| Modèle | Entrée image | Image en cache | Sortie image | Entrée texte | Texte en cache | Sortie texte |
|---|---|---|---|---|---|---|
| gpt-image-2 | 8,00 $ | 2,00 $ | 30,00 $ | 5,00 $ | 1,25 $ | – |
| gpt-image-1.5 | 8,00 $ | 2,00 $ | 32,00 $ | 5,00 $ | 1,25 $ | 10,00 $ |
| gpt-image-1-mini | 2,50 $ | 0,25 $ | 8,00 $ | 2,00 $ | 0,20 $ | – |
Analyse des points clés
Logique tarifaire : La facturation se base sur le nombre de jetons (tokens) en entrée et en sortie, et non sur le nombre d'images. Cela signifie que les haute résolution et les invites complexes coûtent plus cher à l'unité, tandis que les tâches simples sont plus économiques — une approche beaucoup plus flexible qu'une tarification fixe par image.
Comparaison avec gpt-image-1.5 :
- Le coût de sortie d'image (Image Output) passe de 32 $ à 30 $ (baisse de 6 %).
- Les coûts d'entrée et de cache d'image restent inchangés.
- Les coûts d'entrée et de cache de texte restent inchangés, mais la facturation de la sortie de texte est supprimée (gpt-image-2 se concentre sur la génération d'images et ne génère plus de texte).
- Conclusion : Le coût global de gpt-image-2 est légèrement inférieur, tout en offrant des capacités nettement supérieures, ce qui en fait un excellent rapport qualité-prix.
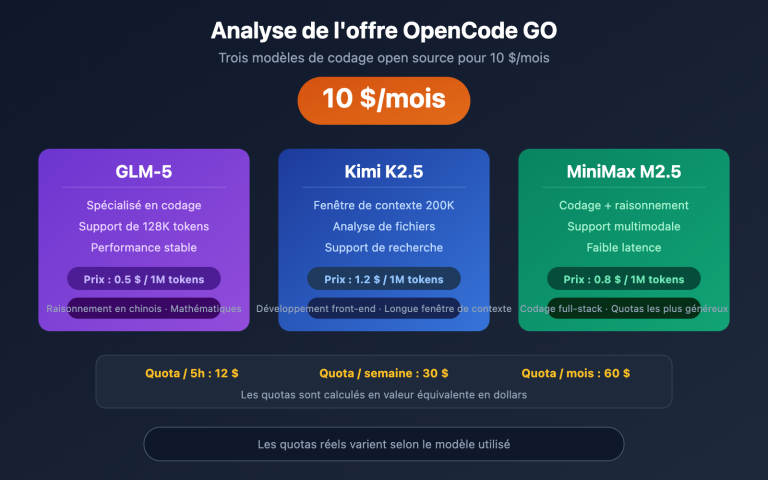
L'intérêt de la version mini : Pour les scénarios ne nécessitant pas une qualité extrême (miniatures en masse, brouillons, prévisualisations), gpt-image-1-mini offre des capacités de base pour environ 1/4 du prix, ce qui est idéal pour les projets à grande échelle sensibles aux coûts.
Estimation des coûts par scénario typique
| Scénario | Estimation par image | Explication |
|---|---|---|
| Image standard (invite simple) | 0,04 $ – 0,08 $ | Faible consommation de jetons |
| Image publicitaire complexe | 0,10 $ – 0,15 $ | Consommation de jetons modérée |
| Infographie haute complexité | 0,20 $ – 0,35 $ | Multi-éléments + invite longue |
| Édition par fusion d'images | 0,15 $ – 0,30 $ | Utilisation d'image de référence |
Conseil d'optimisation des coûts : En utilisant un service proxy API comme APIYI (apiyi.com), vous pouvez automatiser le routage selon le type de tâche : utilisez
gpt-image-1-mini(8 $ en sortie) pour les prévisualisations simples etgpt-image-2(30 $ en sortie) pour les livrables de haute qualité, permettant ainsi d'optimiser vos coûts globaux de 30 à 50 %.
Prise en main rapide de gpt-image-2
Exemple d'invocation minimaliste
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="Couverture de magazine 2K, marque de café 'Moonlight Baking', visuel principal dans les tons brun foncé,"
"titre principal en chinois 'Slow Cooking Time', sous-titre 'Issue 042 · Printemps 2026'",
size="2048x2048"
)
print(response.data[0].url)
Voir le code complet (incluant multilingue, fusion d’images et dégradation intelligente)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
Routage intelligent : sélectionne le modèle optimal selon le niveau de qualité
Args:
prompt: Description de l'image
quality_tier:
- mini: Prévisualisation par lots / brouillon (gpt-image-1-mini, 4 fois moins cher)
- standard: Livraison classique (gpt-image-1.5)
- premium: Haute qualité + Agentic (gpt-image-2)
size: Taille de sortie
Returns:
URL de l'image générée
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"Échec de la génération : {e}")
return None
multilingual_examples = {
"japonais": "Page de garde de manga japonais, titre 'Vers la lune', sous-titre 'Épisode 1'",
"coréen": "Couverture d'album K-pop, titre en gros caractères 'Quand le printemps arrive'",
"hindi": "Affiche de film Bollywood, titre 'Nuit de mousson'",
"arabe": "Affiche de calligraphie arabe, contenu 'Bonjour le monde'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
Conseil de la plateforme : Via APIYI (apiyi.com), vous pouvez invoquer simultanément les trois niveaux de modèles (gpt-image-2, gpt-image-1.5, gpt-image-1-mini). Une seule clé API suffit pour mettre en place un routage intelligent : "mini pour les brouillons, premium pour la production".
Comparaison de gpt-image-2 avec la concurrence
| Modèle | Positionnement | Avantages clés | Prix officiel |
|---|---|---|---|
| gpt-image-2 | Nouveau fleuron d'OpenAI | Raisonnement Agentic + texte multilingue | Sortie 30 $/M token |
| gpt-image-1.5 | Ancien fleuron | Mature et stable + écosystème API complet | Sortie 32 $/M token |
| gpt-image-1-mini | Entrée de gamme légère | Coût divisé par 4 · Vitesse élevée | Sortie 8 $/M token |
| Nano Banana Pro | Fleuron de Google | 14 images de référence + SynthID | 0,045 $ – 0,151 $ par image |
| Midjourney v7 | Référence artistique | Esthétique artistique de pointe | Par abonnement |
Analyse comparative de gpt-image-2
Nano Banana Pro : Le Banana Pro reste en tête sur la cohérence faciale (14 images de référence), la maturité de l'édition et les filigranes de conformité. Cependant, gpt-image-2 offre des avantages différenciés sur trois axes : la précision du texte multilingue, les capacités de raisonnement Agentic et l'intégration de la recherche Web.
gpt-image-1.5 : Ce modèle reste un choix fiable et stable, avec l'écosystème API le plus mature, idéal pour les scénarios classiques ne nécessitant pas de capacités Agentic avancées. Pour les nouveaux projets, nous recommandons de passer directement à gpt-image-2, tandis que les anciens projets peuvent migrer progressivement selon les besoins.
Midjourney : Dans le domaine du style artistique, Midjourney reste le plus puissant. gpt-image-2 est plus adapté aux scénarios où la viabilité commerciale est prioritaire : images de produits, interfaces utilisateur (UI), infographies et supports localisés.
Note sur la sélection : Le choix du modèle dépend principalement de votre cas d'usage spécifique et de vos exigences de qualité. Nous vous recommandons d'effectuer des tests réels via la plateforme APIYI (apiyi.com) ; une seule intégration vous permet de comparer plusieurs modèles leaders du marché.
Cas d'utilisation typiques de gpt-image-2
Voici six scénarios idéaux pour permettre aux débutants de prendre rapidement en main l'outil :
- Scénario 1 · Supports marketing – Le raisonnement agentique permet d'obtenir du premier coup des titres percutants, une mise en avant des produits et une hiérarchie visuelle cohérente.
- Scénario 2 · Infographies / Enseignement – Recherche Web + texte multilingue + étiquettes de données précises.
- Scénario 3 · Bandes dessinées multi-panneaux – Génération de planches complètes en une seule fois avec des bulles de dialogue parfaitement lisibles.
- Scénario 4 · Mise en page de magazines – Résolution 2K et gestion de mises en page complexes adaptées à l'impression commerciale.
- Scénario 5 · Publicités localisées – Précision au niveau des caractères pour le CJK (chinois, japonais, coréen), l'hindi, le bengali et l'arabe.
- Scénario 6 · Maquettes d'UI – Rendu fidèle des petits textes, des icônes et des mises en page denses.
Conseil d'utilisation : Pour les débutants, nous recommandons de commencer par les "Supports marketing" et les "Infographies". Ce sont les deux scénarios qui permettent de ressentir le plus intuitivement le saut qualitatif de gpt-image-2 par rapport à la génération précédente. Vous pouvez obtenir des crédits de test gratuits sur APIYI (apiyi.com) pour essayer rapidement.
FAQ – Questions fréquentes
Q1 : Qu’est-ce que gpt-image-2 ?
gpt-image-2 est le modèle de génération d'images de nouvelle génération officiellement lancé par OpenAI le 21 avril 2026, également appelé "ChatGPT Images 2.0". C'est le premier modèle d'image à intégrer les capacités de raisonnement de la série O, prenant en charge une résolution 2K, le texte multilingue, la planification agentique et l'intégration de la recherche Web. Il est disponible pour tous les utilisateurs de ChatGPT/Codex depuis le 22 avril, et l'API sera ouverte début mai.
Q2 : Quelles sont les principales améliorations de gpt-image-2 par rapport à gpt-image-1.5 ?
Trois mises à jour majeures : (1) Raisonnement agentique — analyse, planification et réflexion sur la structure de l'image avant la génération, ce qui augmente considérablement le taux de réussite pour les scènes complexes ; (2) Texte multilingue — précision au niveau des caractères pour les langues non latines comme le japonais, le coréen, le chinois, l'hindi, le bengali, etc. ; (3) Intégration de la recherche Web — interrogation en temps réel pour vérifier les faits et résoudre les problèmes de coupure de connaissances. De plus, le prix de la génération d'images est passé de 32 $ à 30 $ par million de tokens, offrant un meilleur rapport qualité-prix.
Q3 : Quand l’API officielle de gpt-image-2 sera-t-elle disponible ?
Selon l'annonce officielle d'OpenAI, les utilisateurs de ChatGPT/Codex peuvent l'utiliser directement sur le Web depuis le 22 avril 2026, et l'API gpt-image-2 sera ouverte aux développeurs début mai 2026. Avant l'ouverture officielle, vous pouvez accéder aux dernières capacités de génération via la solution "reverse proxy" gpt-image-2-all d'APIYI (apiyi.com) à 0,03 $ par requête, avec une transition transparente lors de l'ouverture officielle.
Q4 : Comment comprendre la tarification par token à 8 $ / 30 $ ?
Il s'agit du prix unitaire par million de tokens, suivant la même logique de facturation que les modèles textuels comme GPT-4o :
- Image Input 8 $ : coût des tokens d'entrée lors du téléchargement d'une image de référence par l'utilisateur.
- Image Cached 2 $ : tokens d'entrée correspondant à une image en cache (réduction importante pour les images répétées).
- Image Output 30 $ : coût des tokens de sortie lors de la génération de l'image.
- Text Input 5 $ : coût d'entrée pour l'invite textuelle.
Le coût par image se situe généralement entre 0,04 $ et 0,35 $, selon la complexité de l'invite et la résolution de sortie.
Q5 : Comment accéder à gpt-image-2 via l’API ?
Le moyen le plus rapide est de passer par APIYI (apiyi.com) :
- Visitez apiyi.com pour créer un compte et obtenir une clé API.
- Configurez la
base_urlsurhttps://vip.apiyi.com/v1. - Utilisez le SDK officiel d'OpenAI avec
model="gpt-image-2"pour effectuer l'invocation du modèle.
APIYI met à jour ses modèles en synchronisation avec OpenAI. Vos clés API, votre solde et votre historique de facturation restent inchangés. Un seul compte prend en charge tous les modèles principaux tels que gpt-image-2, gpt-image-1.5, gpt-image-1-mini et Nano Banana Pro.
Q6 : Comment choisir entre gpt-image-2 et gpt-image-1-mini ?
Choisissez selon votre niveau d'exigence de qualité :
- gpt-image-2 : 30 $ par million de tokens en sortie, idéal pour les livrables finaux (visuels publicitaires, supports d'impression, propositions clients).
- gpt-image-1-mini : 8 $ par million de tokens en sortie (environ 1/4 du prix), idéal pour les prévisualisations en masse, les itérations de brouillons, les vignettes et l'expérimentation.
Un flux de travail courant consiste à combiner les deux : utilisez le modèle "mini" pour itérer rapidement sur 10 à 20 brouillons, puis, une fois la direction choisie, utilisez gpt-image-2 pour générer la version finale de haute qualité.
Q7 : En quoi la capacité de « réflexion » (Thinking) agentique aide-t-elle les débutants ?
L'aide principale pour les débutants est la réduction de la barrière de l'ingénierie d'invite. Auparavant, il fallait ajuster minutieusement les invites pour éviter que l'IA ne "fasse n'importe quoi". Désormais, le modèle raisonne activement sur ce que vous voulez :
- Vous dites "couverture de magazine" -> Il planifie la hiérarchie des polices, les espaces blancs et l'emplacement de l'image principale.
- Vous dites "infographie" -> Il déduit l'exactitude des données, l'emplacement de la légende et la sémantique des couleurs.
- Vous dites "bande dessinée multi-panneaux" -> Il planifie le rythme du storyboard, l'emplacement des bulles et la cohérence des personnages.
Résultat : Les débutants obtiennent des résultats de niveau professionnel avec des invites simples.
Q8 : Quelles sont les limites connues de gpt-image-2 ?
Voici trois types de limites à noter :
- Coupure des connaissances au 31/12/2025 : Le contenu impliquant des événements ou des produits de 2026 peut être inexact ; il faut s'appuyer sur la capacité de recherche Web pour compléter.
- Maximum 2K par génération : Les dimensions supérieures à 2048 nécessitent un traitement d'upscaling ultérieur.
- Latence de l'API : Le raisonnement agentique prend plus de temps qu'un rendu direct ; les applications interactives doivent prévoir des indicateurs de chargement appropriés.
- Considérations de conformité : Le filigrane SynthID de Nano Banana Pro et l'indemnisation des droits d'auteur restent le choix privilégié pour les scénarios sensibles en matière de conformité.
Points clés de gpt-image-2
- Lancement officiel le 21/04/2026 : Disponible sur le web pour ChatGPT/Codex le 22/04, accès API pour les développeurs début mai.
- Premier modèle d'image de type Agent : Recherche, planification, raisonnement et auto-vérification avant la génération ; amélioration significative du taux de réussite du premier coup dans les scénarios complexes.
- Percée majeure sur le texte multilingue : Précision au niveau des caractères pour les langues non latines, notamment le CJK, l'hindi, le bengali et l'arabe.
- Tarification officielle de 8 $ / 30 $ (par million de jetons) : Le coût de la génération d'images est en baisse de 6 % par rapport à gpt-image-1.5, pour des capacités largement supérieures.
- Prise en main : Utilisez une seule clé API via APIYI (apiyi.com) pour accéder au routage intelligent entre gpt-image-2, 1.5 et mini.
Résumé
Voici les points essentiels à retenir sur gpt-image-2 :
- Saut générationnel des capacités : L'intégration du raisonnement de la série O permet pour la première fois à un modèle d'image de "réfléchir", offrant une amélioration qualitative du taux de réussite dès la première tentative dans les situations complexes.
- Priorité à l'usage commercial : La résolution 2K, la gestion du texte multilingue et l'intégration de la recherche web convergent vers un objectif clair : une utilisation directe en production, et non plus seulement pour le divertissement.
- Tarification transparente et prévisible : La facturation au jeton est plus flexible qu'un tarif fixe par requête. Combinée au modèle "mini", elle permet de concevoir des pipelines de génération optimisés en termes de coûts.
Pour vos décisions d'équipe, nous vous recommandons de commencer immédiatement à tester gpt-image-2 via APIYI (apiyi.com). APIYI propose un crédit gratuit et permet une intégration simple en utilisant le SDK officiel d'OpenAI avec un changement de base_url. Vous bénéficierez également d'un routage intelligent entre les versions mini, 1.5 et 2, vous aidant à valider les meilleures solutions pour chaque scénario au moindre coût.
Lectures complémentaires
Si gpt-image-2 vous intéresse, nous vous recommandons de poursuivre votre lecture avec ces articles :
- 📘 gpt-image-2 vs gpt-image-1.5 : analyse complète des 8 améliorations majeures – Comprendre les raisons fondamentales de ce saut technologique.
- 📊 Analyse complète des 6 scénarios d'application de gpt-image-2 – Maîtriser les chemins de déploiement métier concrets.
- 🚀 Comparaison approfondie : gpt-image-2 vs Nano Banana Pro – Choisir rationnellement le modèle le plus adapté.
- ⚡ Solution alternative gpt-image-2-all à 0,03 $/appel – Un canal d'invocation stable avant l'ouverture officielle de l'API.
📚 Références
-
Annonce officielle d'OpenAI : Lancement de ChatGPT Images 2.0
- Lien :
openai.com/index/new-chatgpt-images-is-here - Description : Spécifications techniques et positionnement produit officiels de gpt-image-2.
- Lien :
-
Évaluation par VentureBeat : Tests sur le texte multilingue, les infographies, les cartes et les bandes dessinées
- Lien :
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - Description : Vérification indépendante des capacités multilingues et de mise en page complexe.
- Lien :
-
Reportage de TechCrunch : Évaluation approfondie des capacités de rendu de texte
- Lien :
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - Description : Comparaison détaillée avec les modèles précédents comme DALL-E 3.
- Lien :
-
Analyse de PetaPixel : Interprétation des capacités de « réflexion » (Agentic Thinking)
- Lien :
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - Description : Comment le raisonnement de la série O est intégré au processus de génération d'images.
- Lien :
-
Tarification officielle d'OpenAI : Grille tarifaire par million de tokens
- Lien :
openai.com/api/pricing - Description : Informations complètes sur la tarification de gpt-image-2 / 1.5 / mini.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à participer à la discussion dans les commentaires. Pour plus d'informations, consultez le centre de documentation APIYI sur docs.apiyi.com.