【著者注】OpenAIは2026年4月21日に「gpt-image-2」(ChatGPT Images 2.0)を正式発表しました。本記事では、その核心的な能力、2K解像度、多言語テキスト対応、Agentic推論、公式価格(100万トークンあたり8ドル/30ドル)、およびAPI接続方法について詳しく解説します。
OpenAIは2026年4月21日、gpt-image-2(ChatGPT Images 2.0)を正式にリリースしました。これは2025年4月の「gpt-image-1」、2025年12月の「gpt-image-1.5」に続く、第3世代のフラッグシップ画像生成モデルです。4月22日よりすべてのChatGPTおよびCodexユーザーが利用可能となっており、APIは5月初旬に開発者向けに公開される予定です。
これは単なる通常のアップデートではありません。 OpenAIが「Oシリーズの推論能力」を画像モデルに統合した初の試みです。gpt-image-2は描画を開始する前に、画像構造を自律的に研究、計画、推論します。業界初となる、真の意味でのAgentic(自律的)な画像生成モデルと言えます。
核心的価値: 本記事を読み終えることで、初心者の方でもgpt-image-2の核心的な能力、価格体系、適用シーンを理解し、最短のAPI接続方法を習得できます。

gpt-image-2 核心要点
| 特性 | 说明 | 初心者へのメリット |
|---|---|---|
| 正式リリース | 2026年4月22日より全ChatGPT/Codexユーザーに開放 | ウェイティングリスト不要 |
| 2K解像度 | ネイティブ2048ピクセル出力 | 印刷品質の素材作成が可能 |
| エージェント推論 | 描画前に構造を計画 | 複雑なシーンも一発で生成 |
| 多言語テキスト | 日・韓・中・印・ベンガル語が鮮明 | ローカライズされたクリエイティブに最適 |
| Web検索統合 | リアルタイムで事実確認 | 正確なインフォグラフィック作成 |
| API 5月初旬開放 | トークン課金制 | コスト予測が容易 |
gpt-image-2 リリースの意義
推論能力を備えた初の画像生成モデル。gpt-image-2 は、OpenAI Oシリーズの「思考能力(Thinking Capabilities)」を導入しました。最初のピクセルを描画する前に、モデルがプロンプトの意味を解釈し、構図を計画し、詳細な制約を推論してからレンダリングを開始します。TechCrunchの報道によると、このエージェント的なアプローチにより、雑誌のレイアウトやマルチパネルの漫画、インフォグラフィックといった複雑なシーンの一発成功率が大幅に向上しました。
テキストと細部の描写が最大のブレイクスルー。OpenAI公式は、gpt-image-2 が小さな文字、アイコン、UI要素、密度の高い構図、微妙なスタイルの制約を正確にレンダリングできると強調しています。これは、従来のすべての画像生成モデルが抱えていた最大の弱点でした。VentureBeatの評価では、「多言語テキスト、完全なインフォグラフィック、スライド、地図、さらには漫画まで、シームレスに完成させている」と評されています。

gpt-image-2 の5つの核心能力を徹底解説
能力1:2Kネイティブ解像度
gpt-image-2は、最大2K解像度(2048ピクセル)をネイティブでサポートしています。これは、雑誌レベルのレイアウト、商業印刷、高精細ディスプレイでの表示といったニーズを十分に満たす性能です。一部の初期リーク情報では4Kという噂もありましたが、公式には2Kであることが確認されました。しかし、大半の商用シーンにおいてこれで十分な品質と言えます。
能力2:多言語テキストの精密レンダリング
これは公式が強調する核心的なアップグレードです。以下の言語において、高忠実度なテキスト生成を実現しています。
| 言語カテゴリ | 代表的な言語 | 主な用途 |
|---|---|---|
| CJK | 中国語、日本語、韓国語 | ローカライズ広告 |
| 南アジア系 | ヒンディー語、ベンガル語 | 南アジア市場向けコンテンツ |
| ラテン系 | 英語、スペイン語、フランス語 | グローバル市場 |
| 複雑な文字 | アラビア語、ヘブライ語 | 中東市場 |
VentureBeatの評価ケースには、完全なキービジュアルの雑誌表紙、多言語のレストランメニュー、地下鉄マップの注釈、日本語漫画のセリフ枠などが含まれており、すべてのテキストが「シームレスに馴染んでいる」と評価されています。
能力3:エージェント型推論(「Thinking」)
これはgpt-image-2における真のアーキテクチャレベルの革新です。従来の「プロンプト → 直接レンダリング」というパイプラインとは異なり、以下のステップを踏みます。
- リサーチ(Research): プロンプトに含まれるエンティティ、関係性、制約を理解する
- プランニング(Plan): 画面のレイアウト、要素の配置、視覚的な階層を構想する
- 推論(Reason): 詳細な制約(フォント、比率、色の論理など)をクロスチェックする
- 生成前自己チェック(Double-check): 生成完了後、要件を満たしているかを再度検証する
このエージェント型のアプローチにより、インフォグラフィック、多要素合成、厳格な制約があるシーンにおいて、一発で成功する確率が前世代よりも大幅に向上しました。
能力4:Web検索の統合
gpt-image-2にはWeb検索機能が内蔵されており、生成前に最新の事実、企業ロゴ、製品の外観などをリアルタイムで調査できます。これにより、「学習データのカットオフ」による現実との乖離問題が解決されました(公式発表による知識のカットオフは2025年12月です)。
例えば「2026年パリ・ファッションウィークの会場ポスター」を生成する場合、モデルはまずネットで会場名、日付、主催ブランドを確認してから創作プロセスに入ります。
能力5:複数フォーマットの一括出力
gpt-image-2は、プロンプトに応じて異なるサイズのマーケティング素材の組み合わせやマルチパネル漫画を生成できます。TechCrunchの実機テストでは、「新しいコーヒーブランドのために4つのSNS用素材をデザインして」と入力したところ、1:1、9:16、16:9、3:4の4つの調和のとれたビジュアルが一度に生成されました。
gpt-image-2 公式料金体系の解説
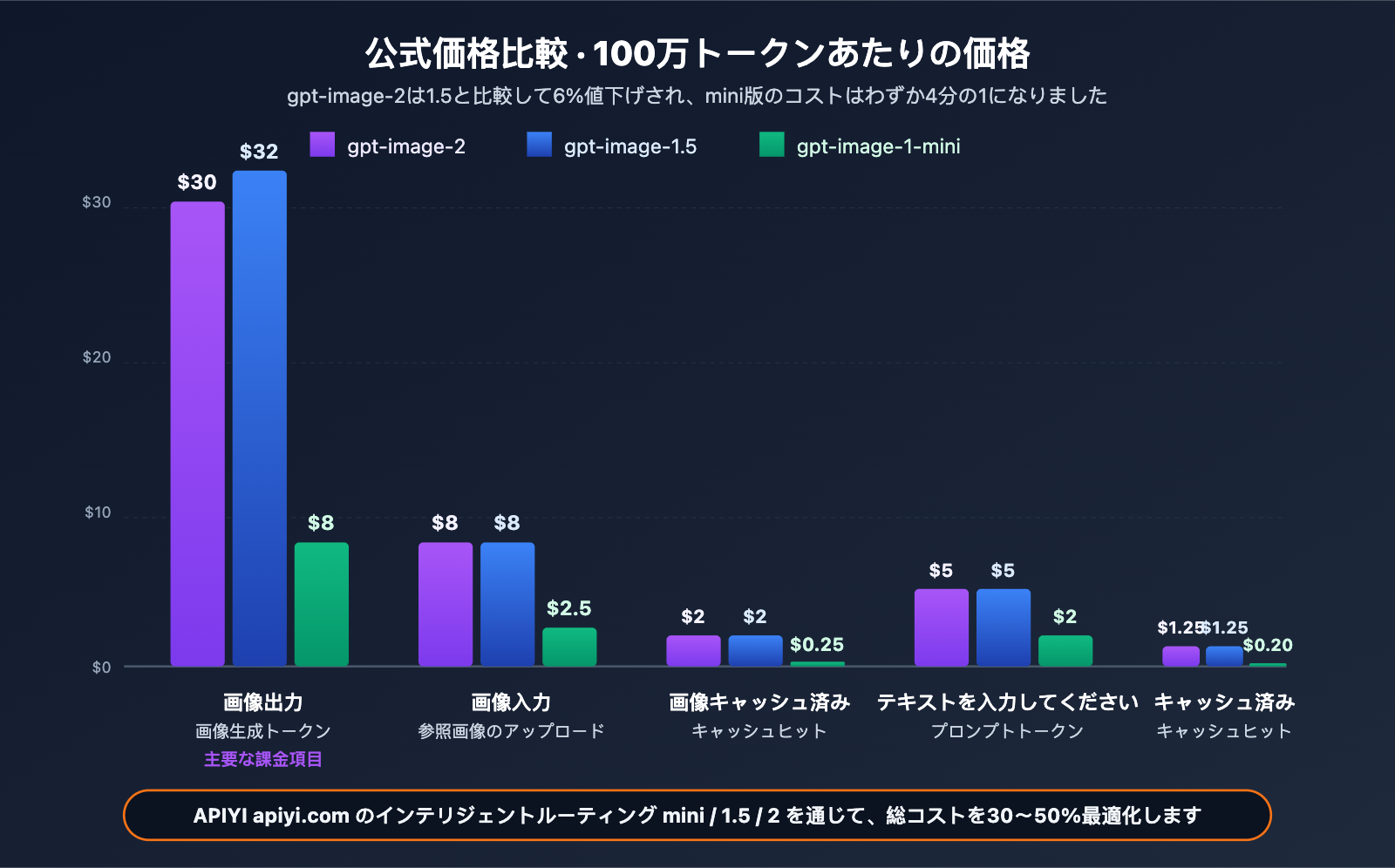
公式料金表(100万トークンあたり)
| モデル | Image Input | Image Cached | Image Output | Text Input | Text Cached | Text Output |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
重要なポイント
料金ロジック: 画像枚数ではなく、入力および出力トークン数に基づいて課金されます。つまり、高解像度や複雑なプロンプトを使用すると単価が高くなり、低複雑度のタスクではコストを抑えられるという、「回数固定課金」よりも柔軟な仕組みです。
gpt-image-1.5 との比較:
- Image Output が $32 から $30 へ値下げ(-6%)
- Image Input/Cached は据え置き
- Text Input/Cached は据え置きだが、Text Output 課金項目が廃止(gpt-image-2は画像生成に特化し、テキスト出力を行わないため)
- 結論: gpt-image-2 は総合的なコストがわずかに低下しつつ、能力は大幅に向上しており、コストパフォーマンスが非常に高くなっています。
mini バージョンの意義: 究極の品質を必要としないシーン(大量のサムネイル作成、下書き、プレビューなど)では、gpt-image-1-mini が約1/4の価格で基本的な能力を提供するため、コストに敏感な大規模プロジェクトに適しています。
シーン別コスト試算
| シーン | 1枚あたりの推定コスト | 説明 |
|---|---|---|
| シンプルなプロンプトの標準画像 | $0.04-$0.08 | トークン消費が少ない |
| 中程度の複雑さの広告画像 | $0.10-$0.15 | トークン消費は中程度 |
| 高複雑度のインフォグラフィック | $0.20-$0.35 | 多要素 + 長いプロンプト |
| 複数画像の融合・編集 | $0.15-$0.30 | 参照画像(Image Input)を使用 |
コスト最適化のアドバイス: APIYI (apiyi.com) の統合アカウントを使用してタスクをルーティングすることで、タスクの種類に応じて自動的にモデルを使い分けることが可能です。簡単なプレビューには
gpt-image-1-mini($8 output)、高品質な納品物にはgpt-image-2($30 output) を使用することで、全体コストを30〜50%削減できます。
gpt-image-2 クイックスタート
シンプルな呼び出し例
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="2K 雑誌の表紙, コーヒーブランド「月光焙煎」, メインビジュアルはダークブラウン系,"
"中国語メインタイトル「慢煮时光(ゆっくり煮出す時間)」, サブタイトル「Issue 042 · 2026 春季号」",
size="2048x2048"
)
print(response.data[0].url)
完全な実装コードを表示(多言語対応、複数画像融合、インテリジェントなダウングレードを含む)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
インテリジェントルーティング: 品質レベルに応じて最適なモデルを選択
Args:
prompt: 画像のプロンプト
quality_tier:
- mini: バッチプレビュー / ドラフト用 (gpt-image-1-mini, 4倍安価)
- standard: 通常の出力用 (gpt-image-1.5)
- premium: 高品質 + エージェント機能 (gpt-image-2)
size: 出力サイズ
Returns:
生成された画像のURL
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"生成失敗: {e}")
return None
multilingual_examples = {
"japanese": "日本風漫画の扉絵,タイトル「月の向こうへ」,サブタイトル「第1話」",
"korean": "K-pop アルバムジャケット,大きなタイトル '봄이 올 때' ",
"hindi": "ボリウッド映画のポスター,タイトル 'मानसून की रात'",
"arabic": "アラビア書道のポスター,内容 'مرحبا بالعالم'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
プラットフォームからの提案: APIYI (apiyi.com) を通じて、gpt-image-2、gpt-image-1.5、gpt-image-1-mini の3つのグレードを同時に呼び出すことができます。1つのAPIキーで「ドラフトには mini、本番には premium」といったインテリジェントなルーティングが完結します。
gpt-image-2 と競合モデルの比較
| モデル | 位置付け | 主な強み | 公式価格 |
|---|---|---|---|
| gpt-image-2 | OpenAI 最新フラッグシップ | エージェント推論 + 多言語テキスト | Output $30/M token |
| gpt-image-1.5 | 前世代フラッグシップ | 安定した成熟度 + 完全なAPIエコシステム | Output $32/M token |
| gpt-image-1-mini | 軽量エントリーモデル | コスト1/4 · 高速 | Output $8/M token |
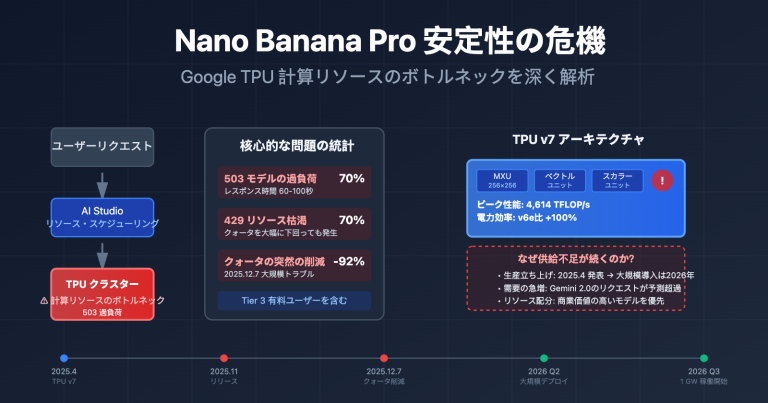
| Nano Banana Pro | Google フラッグシップ | 14枚の参照画像 + SynthID | 画像あたり $0.045-$0.151 |
| Midjourney v7 | アートスタイル重視 | 芸術的センスがトップクラス | サブスクリプション制 |
gpt-image-2 の分析
Nano Banana Pro: Banana Pro は、複数の参照画像の一貫性(14枚)、編集の成熟度、コンプライアンス透かしの面でリードしています。しかし、gpt-image-2 は多言語テキストの正確性、エージェント推論能力、Web検索統合の3つの側面で差別化された優位性を提供します。
gpt-image-1.5: 前世代モデルは依然として安定的で信頼できる選択肢です。APIエコシステムが最も成熟しており、エージェント機能を必要としない通常のタスクに適しています。新規プロジェクトには直接 gpt-image-2 を推奨し、既存プロジェクトはシナリオに応じて段階的に移行することをお勧めします。
Midjourney: アートスタイルの領域では依然として Midjourney が最強です。gpt-image-2 は、ビジネスでの実用性を優先するシーン(製品画像、UI、インフォグラフィック、ローカライズ素材など)により適しています。
選定のアドバイス: どのモデルを選択するかは、具体的なアプリケーションシナリオと品質要件によって異なります。APIYI (apiyi.com) プラットフォームで実際にテストを行い、1つの接続で複数の主要モデルを比較することをお勧めします。
gpt-image-2 の典型的な活用シーン
初心者の方がすぐに使いこなせる6つのシーンをご紹介します。
- シーン 1 · マーケティング素材 – エージェント的な推論により、タイトル文字、製品の強調、視覚的な階層構成が一発で決まります。
- シーン 2 · インフォグラフィック/教材 – Web検索 + 多言語テキスト + データラベルの正確な配置が可能です。
- シーン 3 · マルチパネル漫画 – 一度の生成で複数コマの漫画を作成でき、セリフ枠の文字も鮮明です。
- シーン 4 · 雑誌レイアウト – 2K解像度と複雑なレイアウトに対応し、商用印刷にも耐えうる品質です。
- シーン 5 · ローカライズ広告 – 日本語、中国語、韓国語、インド諸言語、アラビア語などの文字を正確に描画します。
- シーン 6 · UIモックアップ – 小さな文字、アイコン、密度の高いレイアウトを正確に再現します。
活用のヒント: 初心者の方は、まず「マーケティング素材」と「インフォグラフィック」から始めるのがおすすめです。これらは、gpt-image-2 が前世代からどれほど進化したかを最も直感的に体験できるシーンです。APIYI (apiyi.com) で無料のテスト枠を取得して、ぜひ試してみてください。
よくある質問 (FAQ)
Q1: gpt-image-2 とは何ですか?
gpt-image-2 は、OpenAI が2026年4月21日に正式リリースした次世代画像生成モデルで、「ChatGPT Images 2.0」とも呼ばれます。Oシリーズの推論能力を初めて導入した画像モデルであり、2K解像度、多言語テキスト、エージェント的な計画立案、Web検索統合をサポートしています。4月22日よりすべての ChatGPT/Codex ユーザーに公開され、API は5月初旬に公開予定です。
Q2: gpt-image-1.5 と比較した最大のアップグレードは何ですか?
3つの核心的なアップグレード: (1) エージェント的な推論——生成前に画面構造を調査・計画・推論するため、複雑なシーンの成功率が大幅に向上しました。(2) 多言語テキスト——日本語、中国語、韓国語、インド諸言語など、非ラテン文字圏の言語を正確に描画します。(3) Web検索統合——事実をリアルタイムで検索し、知識のカットオフ問題を解決します。さらに、画像出力価格が $32/M トークンから $30 に引き下げられ、コストパフォーマンスが向上しました。
Q3: gpt-image-2 の公式 API はいつ使えますか?
OpenAI の公式発表によると、ChatGPT/Codex ユーザーは2026年4月22日から Web 版で直接利用可能であり、gpt-image-2 API は 2026年5月初旬に開発者向けに公開されます。公式 API の公開前でも、APIYI (apiyi.com) の gpt-image-2-all 官逆(公式リバース)プラン($0.03/回)を通じて最新の生成能力を先行して利用でき、公式公開時にはシームレスに切り替え可能です。
Q4: $8/$30 といったトークン課金はどう理解すればいいですか?
これは 100万トークンあたりの単価であり、GPT-4o などのテキストモデルと同じ課金ロジックです。
- Image Input $8: ユーザーが参照画像をアップロードする際の入力トークンコスト
- Image Cached $2: キャッシュがヒットした入力トークン(重複画像は大幅に値下げ)
- Image Output $30: 画像生成時の出力トークンコスト
- Text Input $5: テキストプロンプトの入力コスト
画像1枚あたりのコストは通常 $0.04〜$0.35 の範囲で、プロンプトの複雑さと出力解像度によって変動します。
Q5: API を通じて gpt-image-2 に接続するには?
最も早い方法は APIYI (apiyi.com) を経由することです。
- apiyi.com にアクセスしてアカウントを登録し、APIキーを取得します。
base_urlをhttps://vip.apiyi.com/v1に設定します。- OpenAI 公式 SDK を使用し、
model="gpt-image-2"を指定して呼び出します。
APIYI は OpenAI と同期して新モデルをリリースするため、既存のキー、残高、請求情報はそのまま利用可能です。1つのアカウントで gpt-image-2 / gpt-image-1.5 / gpt-image-1-mini / Nano Banana Pro など、すべての主要モデルをサポートしています。
Q6: gpt-image-2 と gpt-image-1-mini はどう使い分ければいいですか?
品質への要求度で選んでください:
- gpt-image-2: 画像出力 $30/M トークン。正式な納品物(広告のメインビジュアル、印刷素材、クライアントへの提案資料)に適しています。
- gpt-image-1-mini: 画像出力 $8/M トークン(約1/4の価格)。大量のプレビュー、草案の反復、サムネイル、実験的な探索に適しています。
実際のワークフローでは組み合わせて使うのが一般的です。mini で10〜20枚の草案を素早く作成し、方向性を決めた後に gpt-image-2 で高品質な最終版を出力します。
Q7: エージェント的な「思考(Thinking)」能力は、初心者にどのようなメリットがありますか?
初心者にとって最大のメリットは、プロンプトエンジニアリングのハードルが下がることです。以前は「AIが変な絵を描かないように」プロンプトを細かく調整する必要がありましたが、現在はモデルがユーザーの意図を自ら推論します。
- 「雑誌の表紙」と言えば → フォントの階層、余白、メイン画像の配置を計画します。
- 「インフォグラフィック」と言えば → データの正確性、凡例の位置、色の意味論を推論します。
- 「マルチパネル漫画」と言えば → コマ割りのリズム、セリフ枠の位置、キャラクターの一貫性を計画します。
結果: 初心者でもシンプルなプロンプトでプロレベルの出力を得られます。
Q8: gpt-image-2 にはどのような制限がありますか?
以下の3つの制限事項があります。
- 知識のカットオフは2025年12月: 2026年の出来事や製品に関する生成は不正確になる可能性があるため、Web検索能力で補う必要があります。
- 単一生成の最大サイズは2K: 2048ピクセルを超えるサイズが必要な場合は、後処理でのアップスケーリングが必要です。
- API の遅延: エージェント的な推論は直接レンダリングするよりも時間がかかるため、インタラクティブなアプリでは適切な読み込み(ローディング)表示の設計が必要です。
- コンプライアンス: Nano Banana Pro の SynthID 透かしや著作権賠償制度は、コンプライアンスが重視されるシーンでは依然として優先的な選択肢です。
gpt-image-2 の主要ポイント
- 2026年4月21日 正式リリース: ChatGPT/Codex Web版は4月22日公開、APIは5月初旬に開発者向け公開予定
- 初の「エージェント型」画像生成モデル: 生成前のリサーチ、計画、推論、自己検証を行い、複雑なシーンでの一発成功率が大幅に向上
- 多言語テキストの正確性が飛躍的に向上: CJK(中日韓)、ヒンディー語、ベンガル語、アラビア語など、非ラテン文字の文字レベルでの正確性を実現
- 公式価格 $8/$30(100万トークンあたり): 画像出力コストは gpt-image-1.5 より6%削減されつつ、能力は大幅に向上
- 利用開始方法: APIYI (apiyi.com) のAPIキー1つで、gpt-image-2 / 1.5 / mini のインテリジェントルーティングを利用可能
まとめ
gpt-image-2 の核心となるポイントは以下の通りです:
- 世代を超えた能力の飛躍: Oシリーズの推論機能を導入したことで、画像生成モデルが初めて「思考」できるようになりました。複雑なシーンにおける一発成功率が劇的に向上しています。
- 商用利用を最優先: 2K解像度、多言語テキスト対応、Web検索統合といった機能はすべて、「単なる娯楽ではなく、実務で直接使える」という目標に向けられています。
- 透明かつ予測可能な価格設定: 回数制ではなくトークン課金制を採用することで柔軟性が増しました。miniモデルと組み合わせることで、コストを最適化した生成パイプラインを構築できます。
チームでの導入をご検討中であれば、今すぐ APIYI (apiyi.com) を通じて gpt-image-2 を試してみることを強くおすすめします。APIYIでは無料枠が提供されており、OpenAI公式SDKの base_url を切り替えるだけで簡単に接続可能です。また、mini / 1.5 / 2 の3つのモデルをインテリジェントにルーティングできるため、コストを抑えながら、あらゆるシナリオで最適なソリューションを検証できます。
関連資料・関連記事
gpt-image-2 に興味をお持ちの方は、ぜひ以下の記事も併せてご覧ください。
- 📘 gpt-image-2 vs gpt-image-1.5 8つの進化ポイントを徹底解説 – 能力飛躍の根底にある理由を理解する
- 📊 gpt-image-2 6つの活用シーンを徹底解説 – 具体的なビジネス導入の道筋を把握する
- 🚀 gpt-image-2 vs Nano Banana Pro 詳細比較 – 最適なモデルを理性的に選択する
- ⚡ gpt-image-2-all 公式代替案 $0.03/回 – 公式 API 公開前の安定した呼び出しルート
📚 参考資料
-
OpenAI 公式発表: ChatGPT Images 2.0 リリース
- リンク:
openai.com/index/new-chatgpt-images-is-here - 説明: gpt-image-2 の公式能力仕様と製品ポジショニング
- リンク:
-
VentureBeat レビュー: 多言語テキスト、インフォグラフィック、地図、漫画の実機テスト
- リンク:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - 説明: 多言語対応および複雑なレイアウト能力に関する独立検証
- リンク:
-
TechCrunch レポート: テキストレンダリング能力の深掘りレビュー
- リンク:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - 説明: DALL-E 3 などの前世代モデルとの具体的な比較
- リンク:
-
PetaPixel 分析: エージェント型「思考」能力の解説
- リンク:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - 説明: O シリーズの推論能力がどのように画像生成プロセスに組み込まれているか
- リンク:
-
OpenAI 公式料金表: 100万トークンあたりの価格表
- リンク:
openai.com/api/pricing - 説明: gpt-image-2 / 1.5 / mini の詳細な料金情報
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料は APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。