Anmerkung des Autors: OpenAI hat am 21.04.2026 offiziell gpt-image-2 (ChatGPT Images 2.0) veröffentlicht. Dieser Artikel bietet einen vollständigen Überblick über die Kernfunktionen, die 2K-Auflösung, die mehrsprachige Textunterstützung, das agentische Schlussfolgern, die offizielle Preisgestaltung (8 $ / 30 $ pro Million Token) sowie den API-Zugangsweg.
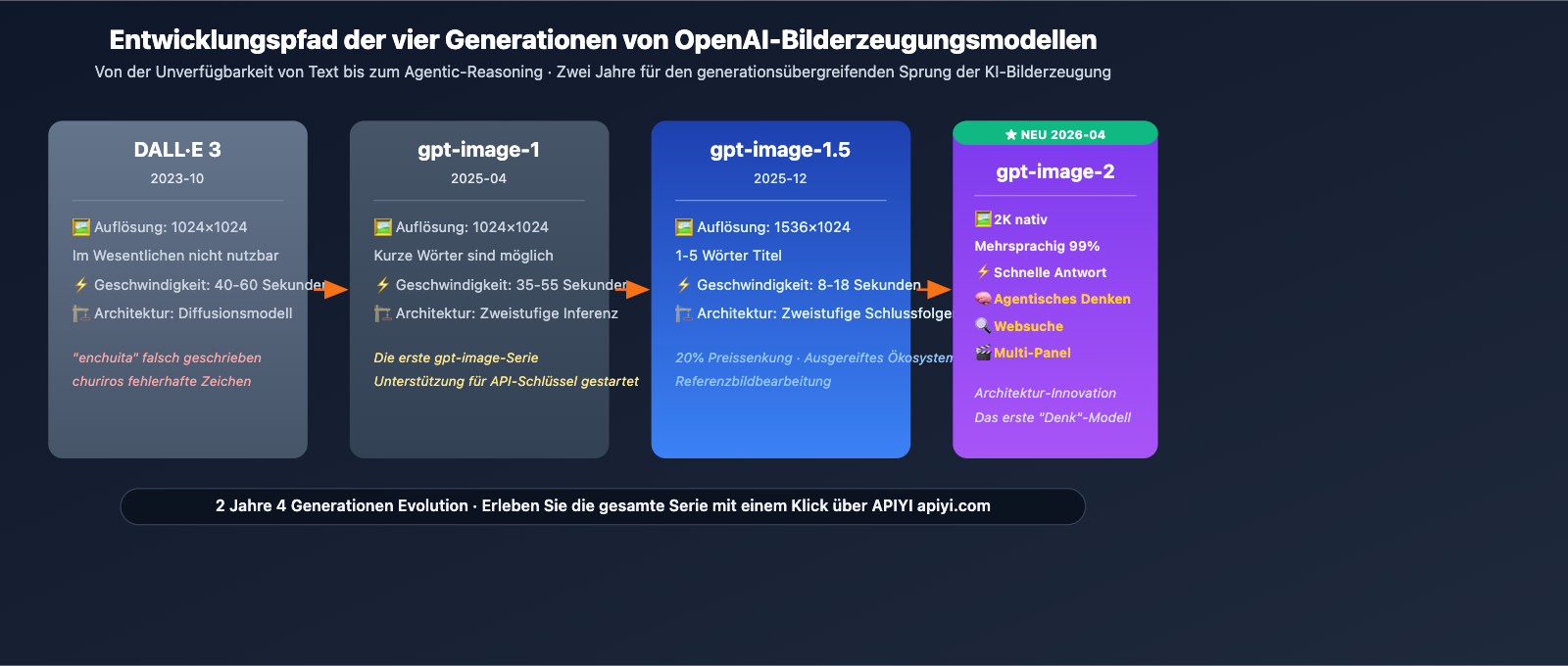
OpenAI hat am 21. April 2026 offiziell gpt-image-2 (ChatGPT Images 2.0) veröffentlicht. Dies ist das dritte Flaggschiff-Bildmodell nach gpt-image-1 (April 2025) und gpt-image-1.5 (Dezember 2025). Ab dem 22. April steht es allen ChatGPT- und Codex-Nutzern zur Verfügung; die API wird Anfang Mai für Entwickler freigeschaltet.
Dies ist kein gewöhnliches Upgrade, sondern der erste Versuch von OpenAI, die „O-Serie-Schlussfolgerungsfähigkeiten“ in ein Bildmodell zu integrieren. gpt-image-2 analysiert, plant und schlussfolgert aktiv über die Bildstruktur, bevor es mit dem Zeichnen beginnt. Es ist das branchenweit erste echte agentische Modell zur Bilderzeugung.
Kernnutzen: Nach dem Lesen dieses Artikels werden Sie als Einsteiger die Kernfunktionen, die Preisstruktur und die Einsatzszenarien von gpt-image-2 genau verstehen und den schnellsten Weg zur API-Anbindung kennen.

Kernpunkte von gpt-image-2
| Merkmal | Beschreibung | Mehrwert für Einsteiger |
|---|---|---|
| Offiziell verfügbar | Seit dem 22.04.2026 für alle ChatGPT/Codex-Nutzer | Keine Warteliste erforderlich |
| 2K-Auflösung | Native Ausgabe mit 2048 Pixeln | Material in Druckqualität |
| Agentic-Reasoning | Strukturelle Planung vor der Generierung | Komplexe Szenen gelingen auf Anhieb |
| Mehrsprachiger Text | Klare Darstellung von Text in Japanisch, Koreanisch, Chinesisch, Hindi und Bengali | Ideal für lokalisierte Kreativprojekte |
| Web-Suche integriert | Echtzeit-Recherche für Fakten | Präzise Infografiken |
| API ab Anfang Mai | Abrechnung pro Token | Vorhersehbare Kosten |
Die Bedeutung der Veröffentlichung von gpt-image-2
Das erste Bildmodell mit Schlussfolgerungsfähigkeit. gpt-image-2 führt die "Thinking Capabilities" der OpenAI O-Serie ein. Bevor das erste Pixel generiert wird, analysiert das Modell die Bedeutung der Eingabeaufforderung, plant die Bildstruktur und wägt Detailvorgaben ab, bevor der Render-Prozess beginnt. Laut TechCrunch erhöht dieser agentische Ansatz die Erfolgsquote bei komplexen Szenarien (wie Magazin-Layouts, mehrteiligen Comics oder Infografiken) massiv.
Text und Details als größter Durchbruch. OpenAI betont, dass gpt-image-2 in der Lage ist, kleinen Text, Icons, UI-Elemente, dichte Kompositionen und subtile Stilvorgaben präzise darzustellen – das war bisher die Achillesferse aller Bildmodelle. VentureBeat lobte in einer Bewertung, dass das Modell "nahtlos mehrsprachigen Text, vollständige Infografiken, Präsentationsfolien, Karten und sogar Comics" erstellt.
Detaillierte Analyse der fünf Kernfunktionen von gpt-image-2
Funktion 1: Native 2K-Auflösung
gpt-image-2 unterstützt nativ eine Auflösung von bis zu 2K (2048 Pixel), was für Anforderungen wie Magazin-Layouts, kommerziellen Druck und Inhalte für hochauflösende Displays völlig ausreicht. Obwohl frühe Leaks von 4K sprachen, hat der Hersteller offiziell 2K bestätigt – für die allermeisten kommerziellen Szenarien ist dies absolut ausreichend.
Funktion 2: Präzises Rendering mehrsprachiger Texte
Dies ist eine vom Hersteller hervorgehobene Kernverbesserung. Das Modell unterstützt die High-Fidelity-Texterzeugung für folgende Sprachen:
| Sprachkategorie | Beispielsprachen | Typische Anwendung |
|---|---|---|
| CJK | Chinesisch, Japanisch, Koreanisch | Lokalisierte Werbung |
| Südasiatisch | Hindi, Bengalisch | Inhalte für den südasiatischen Markt |
| Lateinisch | Englisch, Spanisch, Französisch | Globaler Hauptmarkt |
| Komplexe Zeichen | Arabisch, Hebräisch | Nahost-Markt |
Die Testfälle von VentureBeat umfassen: vollständige Key-Visual-Magazincover, mehrsprachige Restaurantmenüs, Beschriftungen für U-Bahn-Karten und Sprechblasen in japanischen Mangas – alle Texte wirken "nahtlos integriert".
Funktion 3: Agentische Schlussfolgerung ("Thinking")
Dies ist die eigentliche architektonische Innovation von gpt-image-2. Im Gegensatz zur bisherigen Pipeline "Eingabeaufforderung → direktes Rendering" geht das Modell wie folgt vor:
- Recherche (Research): Verstehen der in der Eingabeaufforderung enthaltenen Entitäten, Beziehungen und Einschränkungen.
- Planung (Plan): Konzeption des Bildlayouts, der Positionierung der Elemente und der visuellen Hierarchie.
- Schlussfolgerung (Reason): Kreuzvalidierung von Detailvorgaben (Schriftart, Proportionen, Farblogik).
- Selbstprüfung vor der Bereitstellung (Double-check): Nach der Generierung wird erneut geprüft, ob alle Anforderungen erfüllt sind.
Dieser agentische Ansatz führt dazu, dass die Erfolgsquote bei Infografiken, komplexen Kompositionen und Szenarien mit strengen Vorgaben deutlich höher ist als bei der Vorgängergeneration.
Funktion 4: Integration der Websuche
gpt-image-2 verfügt über eine integrierte Websuchfunktion – es kann vor der Generierung in Echtzeit nach aktuellen Fakten, Firmenlogos, Produktdesigns usw. suchen. Dies löst das Problem der "veralteten Trainingsdaten" (offiziell bestätigt: Wissensstand bis Dezember 2025).
Wenn man beispielsweise ein "Plakat für den Veranstaltungsort der Pariser Fashion Week 2026" generiert, prüft das Modell zuerst online den Namen des Veranstaltungsortes, das Datum und die gastgebenden Marken, bevor es mit dem kreativen Prozess beginnt.
Funktion 5: Ausgabe in mehreren Formaten gleichzeitig
gpt-image-2 kann basierend auf einer Eingabeaufforderung verschiedene Größenkombinationen für Marketingmaterialien oder mehrseitige Comics generieren. Im Praxistest von TechCrunch lieferte die Eingabe "Entwirf 4 Social-Media-Assets für eine neue Kaffeemarke" auf einen Schlag vier harmonisch aufeinander abgestimmte Grafiken in den Formaten 1:1, 9:16, 16:9 und 3:4.
Erläuterung der offiziellen Preisgestaltung von gpt-image-2
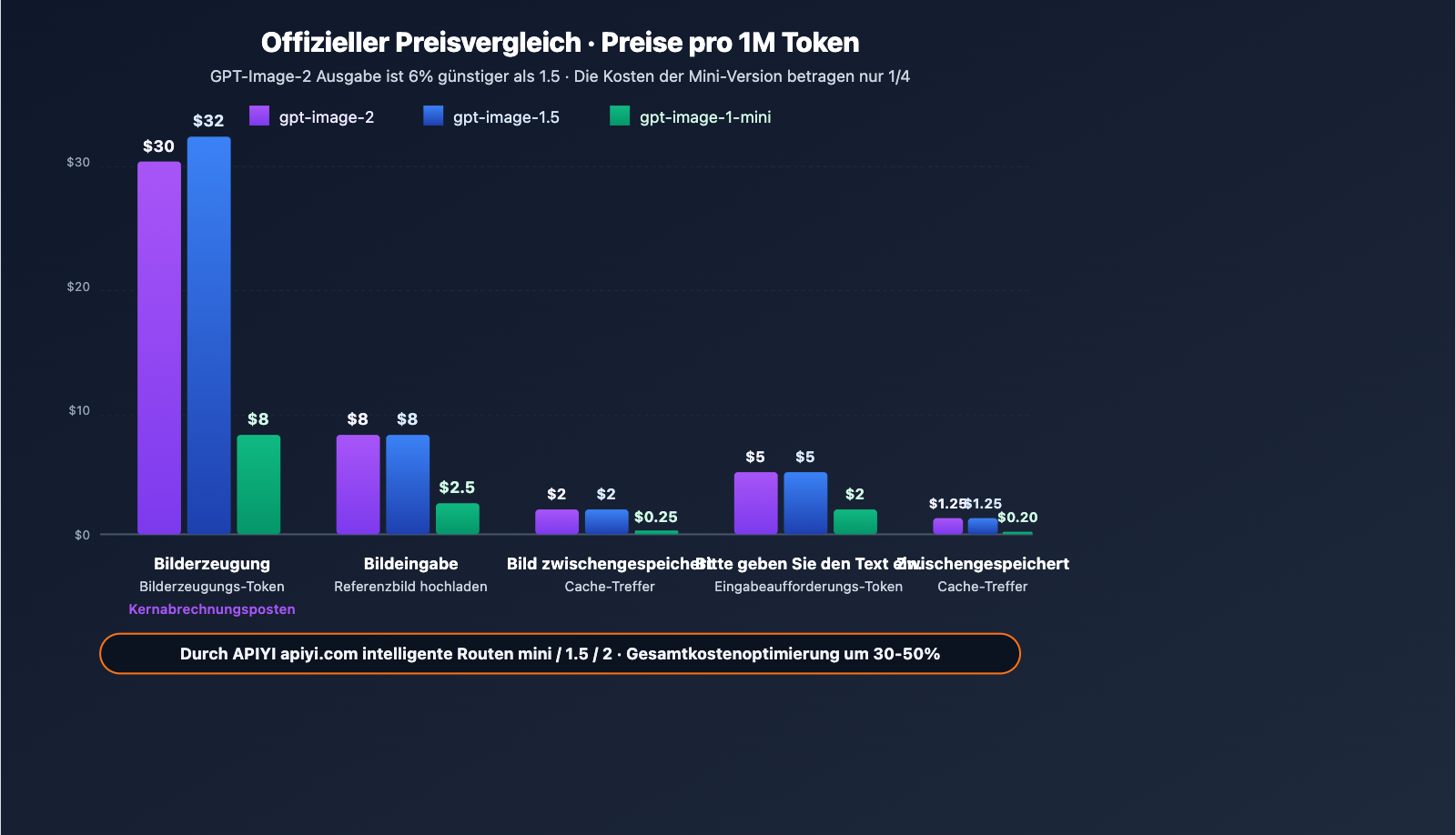
Offizielle Preisliste (pro Million Token)
| Modell | Image Input | Image Cached | Image Output | Text Input | Text Cached | Text Output |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
Wichtige Erkenntnisse
Preislogik: Die Abrechnung erfolgt nach Anzahl der Eingabe- und Ausgabe-Token, nicht nach der Anzahl der Bilder. Das bedeutet, dass die Kosten pro Bild bei hoher Auflösung und komplexen Eingabeaufforderungen höher sind, während einfache Aufgaben günstiger sind – dies ist flexibler als eine "feste Gebühr pro Bild".
Vergleich mit gpt-image-1.5:
- Image Output wurde von $32 auf $30 gesenkt (-6 %).
- Image Input/Cached bleiben unverändert.
- Text Input/Cached bleiben unverändert, aber der Posten "Text Output" entfällt (gpt-image-2 konzentriert sich auf die Bilderzeugung und gibt keinen Text mehr aus).
- Fazit: Die Gesamtkosten für gpt-image-2 sind leicht gesunken, bei gleichzeitig deutlich gesteigerter Leistungsfähigkeit – ein hervorragendes Preis-Leistungs-Verhältnis.
Bedeutung der Mini-Version: Für Szenarien, in denen keine höchste Qualität erforderlich ist (Batch-Vorschaubilder, Entwürfe, Previews), bietet gpt-image-1-mini die Basisfunktionen zu etwa einem Viertel des Preises und eignet sich damit ideal für kostenintensive Großprojekte.
Kostenschätzung für typische Szenarien
| Szenario | Geschätzte Kosten pro Bild | Erläuterung |
|---|---|---|
| Einfache Standardbilder | $0.04-$0.08 | Geringer Token-Verbrauch |
| Werbebilder mittlerer Komplexität | $0.10-$0.15 | Mittlerer Token-Verbrauch |
| Hochkomplexe Infografiken | $0.20-$0.35 | Viele Elemente + lange Eingabeaufforderung |
| Fusion/Bearbeitung mehrerer Bilder | $0.15-$0.30 | Nutzung von Referenzbildern (Image Input) |
Tipp zur Kostenoptimierung: Durch die zentrale Kontoverwaltung über APIYI (apiyi.com) können Sie Aufgaben automatisch routen: Nutzen Sie
gpt-image-1-mini($8 Output) für einfache Vorschauen undgpt-image-2($30 Output) für hochwertige Ergebnisse. So lassen sich die Gesamtkosten um 30–50 % optimieren.
Schnelleinstieg in gpt-image-2
Minimalistisches Aufrufbeispiel
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="2K Magazin-Cover, Kaffeemarke 'Moonlight Roasting', Hauptmotiv in Dunkelbraun, "
"chinesischer Haupttitel 'Slow Brewed Time', Untertitel 'Issue 042 · Frühjahrsausgabe 2026'",
size="2048x2048"
)
print(response.data[0].url)
Vollständigen Implementierungscode anzeigen (inkl. Mehrsprachigkeit, Multi-Bild-Fusion, intelligentes Fallback)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
Intelligentes Routing: Wählt das optimale Modell basierend auf der Qualitätsstufe.
Args:
prompt: Bildbeschreibung
quality_tier:
- mini: Batch-Vorschau / Entwurf (gpt-image-1-mini, 4x günstiger)
- standard: Reguläre Bereitstellung (gpt-image-1.5)
- premium: Hohe Qualität + Agentic (gpt-image-2)
size: Ausgabegröße
Returns:
URL des generierten Bildes
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"Generierung fehlgeschlagen: {e}")
return None
multilingual_examples = {
"japanisch": "Japanisches Manga-Cover, Titel 'Jenseits des Mondes', Untertitel 'Kapitel 1'",
"koreanisch": "K-Pop Album-Cover, großer Titel 'Wenn der Frühling kommt'",
"hindi": "Bollywood-Filmplakat, Titel 'Nacht des Monsuns'",
"arabisch": "Arabisches Kalligrafie-Plakat, Inhalt 'Hallo Welt'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
Plattform-Empfehlung: Über APIYI (apiyi.com) können Sie die drei Stufen gpt-image-2, gpt-image-1.5 und gpt-image-1-mini gleichzeitig aufrufen. Ein einziger API-Schlüssel reicht aus, um intelligentes Routing von "Entwurf mit mini" bis "Produktion mit premium" zu realisieren.
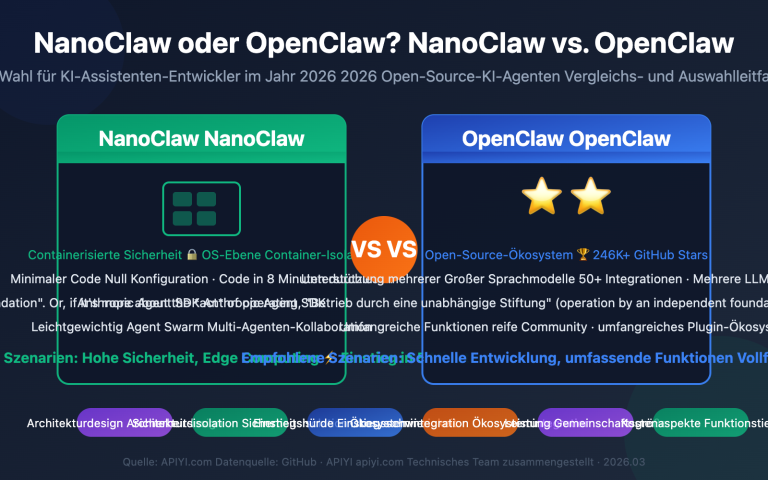
Vergleich von gpt-image-2 mit Wettbewerbern
| Modell | Positionierung | Kernvorteile | Offizieller Preis |
|---|---|---|---|
| gpt-image-2 | Aktuelles OpenAI-Flaggschiff | Agentic-Reasoning + mehrsprachiger Text | Output $30/M Token |
| gpt-image-1.5 | Vorheriges Flaggschiff | Stabil & ausgereift + vollständiges API-Ökosystem | Output $32/M Token |
| gpt-image-1-mini | Leichtgewicht/Einstieg | 1/4 der Kosten · hohe Geschwindigkeit | Output $8/M Token |
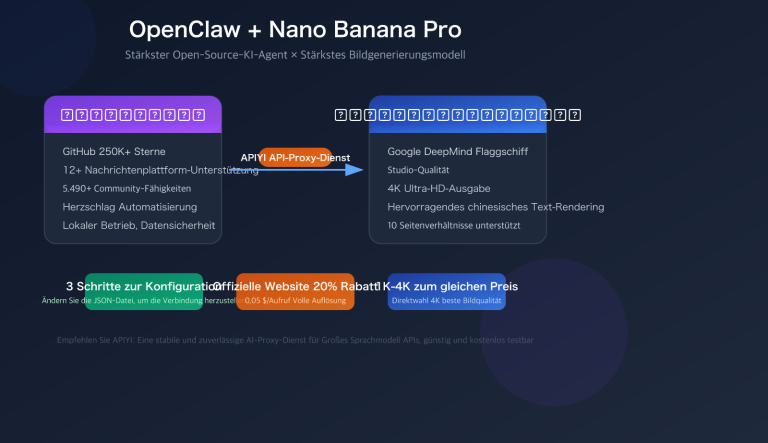
| Nano Banana Pro | Google-Flaggschiff | 14 Referenzbilder + SynthID | $0,045-$0,151 pro Bild |
| Midjourney v7 | Erste Wahl für Kunststil | Führende Ästhetik | Abonnement |
Analyse von gpt-image-2 im Vergleich
Nano Banana Pro: Banana Pro bleibt führend bei der Konsistenz mehrerer Referenzbilder (14 Bilder), der Bearbeitungsreife und den konformen Wasserzeichen. gpt-image-2 bietet jedoch differenzierte Vorteile bei der Genauigkeit mehrsprachiger Texte, der Agentic-Reasoning-Fähigkeit und der Web-Suchintegration.
gpt-image-1.5: Das Vorgängermodell bleibt eine stabile und zuverlässige Wahl. Das API-Ökosystem ist am ausgereiftesten und eignet sich für reguläre Szenarien, die keine hohen Agentic-Fähigkeiten erfordern. Für neue Projekte empfehlen wir den direkten Einsatz von gpt-image-2, während alte Projekte schrittweise migriert werden können.
Midjourney: Im Bereich des künstlerischen Stils ist Midjourney weiterhin ungeschlagen. gpt-image-2 eignet sich jedoch besser für Szenarien, bei denen die kommerzielle Nutzbarkeit im Vordergrund steht – wie Produktbilder, UI-Design, Infografiken und lokalisierte Materialien.
Auswahlhilfe: Welches Modell Sie wählen, hängt hauptsächlich von Ihrem spezifischen Anwendungsfall und Ihren Qualitätsanforderungen ab. Wir empfehlen, praktische Tests über die APIYI-Plattform (apiyi.com) durchzuführen, da Sie dort nach einmaliger Anbindung verschiedene Mainstream-Modelle direkt vergleichen können.
Typische Anwendungsszenarien für gpt-image-2
Sechs Szenarien, mit denen Einsteiger schnell durchstarten können:
- Szenario 1 · Marketingmaterialien – Agentic-Reasoning sorgt dafür, dass Überschriften, Produktfokus und visuelle Hierarchie auf Anhieb sitzen.
- Szenario 2 · Infografiken/Lehrmaterial – Web-Suche + mehrsprachiger Text + präzise Datenbeschriftung.
- Szenario 3 · Mehrteilige Comics – Generierung mehrerer Comic-Panels in einem Durchgang + klare Sprechblasen.
- Szenario 4 · Magazin-Layouts – 2K-Auflösung + Unterstützung für komplexe Layouts für den professionellen Druck.
- Szenario 5 · Lokalisierte Werbung – Zeichengenauigkeit für CJK, Indisch, Bengalisch und Arabisch.
- Szenario 6 · UI-Mockups – Präzise Wiedergabe von kleinem Text, Icons und dichten Layouts.
Empfehlung für Szenarien: Einsteigern empfehlen wir den Einstieg über "Marketingmaterialien" und "Infografiken" – diese beiden Szenarien verdeutlichen am besten den Leistungssprung von gpt-image-2 gegenüber der Vorgängergeneration. Kostenlose Testguthaben für einen schnellen Versuch erhalten Sie bei APIYI unter apiyi.com.
Häufig gestellte Fragen (FAQ)
Q1: Was ist gpt-image-2?
gpt-image-2 ist das am 21.04.2026 von OpenAI offiziell veröffentlichte Bildgenerierungsmodell der nächsten Generation, auch bekannt als "ChatGPT Images 2.0". Es ist das erste Bildmodell, das die O-Serie-Reasoning-Fähigkeiten einführt und 2K-Auflösung, mehrsprachigen Text, Agentic-Planung sowie die Integration der Web-Suche unterstützt. Seit dem 22. April ist es für alle ChatGPT/Codex-Nutzer verfügbar, die API folgt Anfang Mai.
Q2: Was sind die größten Upgrades von gpt-image-2 gegenüber gpt-image-1.5?
Drei Kern-Upgrades: (1) Agentic-Reasoning – vor der Generierung wird die Bildstruktur recherchiert, geplant und durchdacht, was die Erfolgsquote bei komplexen Szenen massiv erhöht; (2) Mehrsprachiger Text – zeichengenaue Darstellung in nicht-lateinischen Schriften wie Japanisch, Koreanisch, Chinesisch, Indisch, Bengalisch etc.; (3) Web-Suche-Integration – Echtzeit-Abfrage von Fakten zur Lösung des Wissens-Cutoff-Problems. Zudem wurde der Preis für die Bildausgabe von $32/M Token auf $30 gesenkt, was das Preis-Leistungs-Verhältnis verbessert.
Q3: Wann ist die offizielle gpt-image-2 API verfügbar?
Laut der offiziellen Ankündigung von OpenAI können ChatGPT/Codex-Nutzer das Modell ab dem 22.04.2026 direkt über das Web-Interface nutzen. Die gpt-image-2 API wird für Entwickler Anfang Mai 2026 freigeschaltet. Vor der offiziellen API-Veröffentlichung können Sie über APIYI (apiyi.com) mittels der gpt-image-2-all Reverse-Proxy-Lösung ($0,03/Aufruf) bereits vorab auf die neuesten Generierungsfunktionen zugreifen und am Tag der offiziellen Veröffentlichung nahtlos umstellen.
Q4: Wie ist die Token-Preisgestaltung von $8/$30 zu verstehen?
Dies ist der Stückpreis pro Million Token, basierend auf der gleichen Abrechnungslogik wie bei Textmodellen wie GPT-4o:
- Image Input $8: Kosten für Eingabe-Token beim Hochladen eines Referenzbildes.
- Image Cached $2: Eingabe-Token bei Treffern im Cache (deutlich günstiger bei wiederholten Bildern).
- Image Output $30: Kosten für Ausgabe-Token bei der Bilderzeugung.
- Text Input $5: Kosten für die Eingabe des Text-Prompts.
Die Kosten pro Bild liegen meist im Bereich von $0,04 bis $0,35, abhängig von der Komplexität des Prompts und der Ausgabeauflösung.
Q5: Wie binde ich gpt-image-2 über die API ein?
Der schnellste Weg führt über APIYI (apiyi.com):
- Besuchen Sie apiyi.com, registrieren Sie sich und erhalten Sie Ihren API-Schlüssel.
- Setzen Sie die
base_urlaufhttps://vip.apiyi.com/v1. - Verwenden Sie das offizielle OpenAI SDK und rufen Sie das Modell mit
model="gpt-image-2"auf.
APIYI schaltet neue Modelle zeitgleich mit OpenAI frei. Ihre bestehenden Schlüssel, Guthaben und Abrechnungen bleiben unverändert. Ein Konto unterstützt gleichzeitig alle gängigen Modelle wie gpt-image-2, gpt-image-1.5, gpt-image-1-mini und Nano Banana Pro.
Q6: Wie entscheide ich mich zwischen gpt-image-2 und gpt-image-1-mini?
Wählen Sie nach Qualitätsanspruch:
- gpt-image-2: Image Output $30/M Token, geeignet für finale Ergebnisse (Werbe-Visuals, Druckmaterialien, Kundenpräsentationen).
- gpt-image-1-mini: Image Output $8/M Token (ca. 1/4), geeignet für Batch-Vorschauen, Entwurfs-Iterationen, Thumbnails und experimentelle Explorationen.
Ein gängiger Workflow ist die Kombination: Nutzen Sie mini für die schnelle Iteration von 10-20 Entwürfen und verwenden Sie nach der Auswahl der Richtung gpt-image-2 für die finale, hochwertige Version.
Q7: Welchen praktischen Nutzen hat die Agentic-„Thinking“-Fähigkeit für Einsteiger?
Der größte Vorteil für Einsteiger ist die Senkung der Hürde für Prompt-Engineering. Früher musste man Prompts mühsam optimieren, um zu verhindern, dass die KI "irgendetwas" zeichnet. Jetzt denkt das Modell aktiv mit, was Sie erreichen möchten:
- Sie sagen "Magazin-Cover" → Es plant die Schrift-Hierarchie, Weißraum und die Position des Hauptbildes.
- Sie sagen "Infografik" → Es schlussfolgert die Datengenauigkeit, Legendenposition und Farbsemantik.
- Sie sagen "Mehrteiliger Comic" → Es plant den Erzählrhythmus, die Position der Sprechblasen und die Konsistenz der Charaktere.
Ergebnis: Einsteiger erhalten auch mit einfachen Prompts professionelle Ergebnisse.
Q8: Welche bekannten Einschränkungen hat gpt-image-2?
Hier sind drei objektive Einschränkungen:
- Wissens-Cutoff 12/2025: Inhalte zu Ereignissen oder Produkten aus dem Jahr 2026 könnten ungenau sein; hier ist die Web-Suche zur Ergänzung erforderlich.
- Maximal 2K pro Durchgang: Größen über 2048 erfordern eine nachträgliche Hochskalierung.
- API-Latenz: Agentic-Reasoning benötigt mehr Zeit als direktes Rendering; interaktive Anwendungen sollten entsprechende Lade-Indikatoren vorsehen.
- Compliance: Für rechtlich sensible Szenarien bleibt das Nano Banana Pro mit SynthID-Wasserzeichen und Urheberrechtsschutz die erste Wahl.
Wichtige Erkenntnisse zu gpt-image-2
- Offizielle Veröffentlichung am 21.04.2026: Verfügbar im Web-Interface von ChatGPT/Codex ab dem 22.04., für Entwickler via API ab Anfang Mai.
- Erstes agentenbasiertes Bildmodell: Integriert Recherche, Planung, logisches Schlussfolgern und Selbstprüfung vor der Generierung, was die Erfolgsquote bei komplexen Szenen massiv steigert.
- Durchbruch bei mehrsprachigem Text: Zeichengenaue Darstellung von CJK, Hindi, Bengalisch, Arabisch und anderen nicht-lateinischen Schriften.
- Offizielle Preisgestaltung 8 $ / 30 $ (pro Million Token): Die Kosten für die Bilderzeugung sinken gegenüber gpt-image-1.5 um 6 % bei deutlich gesteigerter Leistungsfähigkeit.
- Einstieg: Nutzen Sie einen einzigen API-Schlüssel über APIYI (apiyi.com) für den Zugriff auf gpt-image-2, 1.5 und mini via intelligentes Routing.
Zusammenfassung
Die Kernpunkte von gpt-image-2:
- Generationensprung bei der Leistungsfähigkeit: Durch die Einführung der O-Serie für logisches Schlussfolgern erhalten Bildmodelle erstmals eine „Denkfähigkeit“, was die Erfolgsrate bei komplexen Aufgaben qualitativ verbessert.
- Fokus auf kommerzielle Nutzbarkeit: 2K-Auflösung, Unterstützung für mehrsprachigen Text und die Integration von Websuchen zielen auf ein klares Ziel ab: Direkt produktionsreif statt nur für Unterhaltungszwecke.
- Transparente und planbare Preisgestaltung: Die Abrechnung nach Token ist flexibler als feste Gebühren pro Aufruf. In Kombination mit der „mini“-Stufe lassen sich kosteneffiziente Pipelines für die Bilderzeugung aufbauen.
Für Entscheidungsträger in Teams: Wir empfehlen, gpt-image-2 umgehend über APIYI (apiyi.com) zu testen. APIYI bietet ein kostenloses Kontingent und lässt sich einfach über das offizielle OpenAI-SDK durch Anpassen der base_url integrieren. Dank des intelligenten Routings zwischen den Stufen mini, 1.5 und 2 können Sie die optimale Lösung für Ihre spezifischen Anforderungen kosteneffizient validieren.
Weiterführende Artikel
Wenn Sie sich für gpt-image-2 interessieren, empfehlen wir Ihnen folgende Lektüre:
- 📘 gpt-image-2 vs. gpt-image-1.5: Analyse der acht wichtigsten Upgrades – Verstehen Sie die tieferliegenden Gründe für den Leistungssprung.
- 📊 gpt-image-2: Analyse der sechs wichtigsten Anwendungsszenarien – Meistern Sie den Weg zur praktischen Umsetzung im Unternehmen.
- 🚀 gpt-image-2 vs. Nano Banana Pro: Detaillierter Vergleich – Treffen Sie eine rationale Entscheidung für das optimale Modell.
- ⚡ gpt-image-2-all: Offizielle Proxy-Lösung für $0,03/Aufruf – Ein stabiler Kanal für Modellaufrufe noch vor der offiziellen API-Freigabe.
📚 Referenzen
-
Offizielle Ankündigung von OpenAI: Veröffentlichung von ChatGPT Images 2.0
- Link:
openai.com/index/new-chatgpt-images-is-here - Beschreibung: Offizielle Leistungsspezifikationen und Produktpositionierung von gpt-image-2.
- Link:
-
VentureBeat-Testbericht: Praxistest zu mehrsprachigen Texten, Infografiken, Karten und Comics
- Link:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - Beschreibung: Unabhängige Validierung der Fähigkeiten bei Mehrsprachigkeit und komplexen Layouts.
- Link:
-
TechCrunch-Bericht: Detaillierte Bewertung der Text-Rendering-Fähigkeiten
- Link:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - Beschreibung: Spezifischer Vergleich mit Vorgängermodellen wie DALL-E 3.
- Link:
-
PetaPixel-Analyse: Interpretation der agentischen "Denk"-Fähigkeiten
- Link:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - Beschreibung: Wie das Schlussfolgern der O-Serie in den Prozess der Bilderzeugung integriert wird.
- Link:
-
Offizielle Preisgestaltung von OpenAI: Preisliste pro Million Token
- Link:
openai.com/api/pricing - Beschreibung: Vollständige Preisinformationen zu gpt-image-2 / 1.5 / mini.
- Link:
Autor: APIYI-Technikteam
Technischer Austausch: Wir freuen uns auf Ihre Diskussionen in den Kommentaren. Weitere Informationen finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.