Nota do autor: A OpenAI lançou oficialmente o gpt-image-2 (ChatGPT Images 2.0) em 21/04/2026. Este artigo apresenta uma visão completa de suas capacidades principais, resolução 2K, suporte a texto multilíngue, raciocínio Agentic, precificação oficial (US$ 8/US$ 30 por milhão de tokens) e o caminho de integração via API.
Em 21 de abril de 2026, a OpenAI lançou oficialmente o gpt-image-2 (ChatGPT Images 2.0), a terceira geração de seu modelo de imagem emblemático, sucedendo o gpt-image-1 (abril de 2025) e o gpt-image-1.5 (dezembro de 2025). Desde 22 de abril, todos os usuários do ChatGPT e Codex já podem utilizá-lo, e a API será aberta aos desenvolvedores no início de maio.
Esta não é apenas uma atualização convencional, mas a primeira tentativa da OpenAI de integrar as "capacidades de raciocínio da série O" em um modelo de imagem. O gpt-image-2 estuda, planeja e raciocina ativamente sobre a estrutura da imagem antes de começar a desenhar, tornando-o o primeiro modelo de geração de imagens verdadeiramente Agentic do setor.
Valor central: Ao terminar de ler este artigo, você, como iniciante, entenderá claramente as capacidades principais do gpt-image-2, sua estrutura de preços, cenários de aplicação e aprenderá o caminho mais rápido para a integração via API.

Pontos principais do gpt-image-2
| Característica | Descrição | Valor para iniciantes |
|---|---|---|
| Disponibilidade oficial | Aberto a todos os usuários do ChatGPT/Codex desde 22/04/2026 | Sem lista de espera |
| Resolução 2K | Saída nativa de 2048 pixels | Materiais com qualidade de impressão |
| Raciocínio Agentic | Planeja a estrutura antes de desenhar | Resultados precisos em cenas complexas |
| Texto multilíngue | Texto claro em japonês, coreano, chinês, hindi e bengali | Ideal para criações localizadas |
| Integração com busca Web | Consulta fatos em tempo real | Infográficos precisos |
| API disponível em maio | Cobrança baseada em tokens | Custos previsíveis |
O significado do lançamento do gpt-image-2
O primeiro modelo de imagem com capacidade de raciocínio. O gpt-image-2 introduz as "Capacidades de Pensamento" da série O da OpenAI — antes de gerar o primeiro pixel, o modelo estuda o significado do comando, planeja a estrutura da composição e raciocina sobre as restrições de detalhes, para só então começar a renderizar. Relatórios do TechCrunch apontam que essa abordagem Agentic aumenta drasticamente a taxa de sucesso de primeira em cenas complexas (como layouts de revistas, quadrinhos de vários painéis e infográficos).
Texto e detalhes são o maior avanço. A OpenAI enfatiza que o gpt-image-2 pode renderizar com precisão textos pequenos, ícones, elementos de interface, composições densas e restrições de estilo sutis — o calcanhar de Aquiles de todos os modelos de imagem anteriores. O VentureBeat avaliou que ele "parece ter concluído de forma impecável textos multilíngues, infográficos completos, slides, mapas e até quadrinhos".

Detalhamento das 5 principais capacidades do gpt-image-2
Capacidade 1: Resolução nativa de 2K
O gpt-image-2 oferece suporte nativo a uma resolução máxima de 2K (2048 pixels), o que é suficiente para atender às demandas de diagramação de revistas, impressão comercial e conteúdo para monitores de alta definição. Embora algumas informações vazadas anteriormente mencionassem 4K, a oficialização confirmou 2K — o que já é mais do que suficiente para a grande maioria dos cenários comerciais.
Capacidade 2: Renderização precisa de texto em vários idiomas
Este é o principal upgrade destacado pela equipe oficial. O modelo suporta a geração de texto de alta fidelidade nos seguintes idiomas:
| Categoria de Idioma | Exemplos | Aplicação Típica |
|---|---|---|
| CJK | Chinês, Japonês, Coreano | Publicidade localizada |
| Sul-asiático | Hindi, Bengali | Conteúdo para o mercado sul-asiático |
| Latino | Inglês, Espanhol, Francês | Mercado global principal |
| Caracteres complexos | Árabe, Hebraico | Mercado do Oriente Médio |
Os casos de teste da VentureBeat incluíram: capas de revistas com Key Visual completo, menus de restaurantes multilíngues, sinalização de mapas de metrô e balões de diálogo de mangás — todos com textos que parecem "perfeitamente integrados".
Capacidade 3: Raciocínio Agentic ("Thinking")
Esta é a verdadeira inovação arquitetural do gpt-image-2. Diferente do pipeline anterior de "comando → renderização direta", ele agora segue estas etapas:
- Pesquisa (Research): Compreende as entidades, relações e restrições contidas no comando.
- Planejamento (Plan): Conceitua o layout da imagem, a posição dos elementos e a hierarquia visual.
- Raciocínio (Reason): Valida cruzadamente as restrições de detalhes (fontes, proporções, lógica de cores).
- Verificação pré-entrega (Double-check): Após a geração, verifica novamente se o resultado atende aos requisitos.
Essa abordagem Agentic faz com que ele tenha uma taxa de sucesso muito superior à geração anterior em infográficos, composição de múltiplos elementos e cenários com restrições rígidas.
Capacidade 4: Integração com busca na Web
O gpt-image-2 possui capacidade de busca na Web integrada, permitindo consultar em tempo real fatos recentes, logotipos de empresas e aparências de produtos antes da geração. Isso resolve o problema de viés da realidade causado pela "data de corte do treinamento" (a oficial confirmou que o conhecimento vai até dezembro de 2025).
Por exemplo, ao gerar um "pôster para o local da Paris Fashion Week de 2026", o modelo primeiro se conecta à internet para confirmar o nome do local, a data e a marca organizadora antes de iniciar o processo de criação.
Capacidade 5: Saída em múltiplos formatos de uma só vez
O gpt-image-2 pode gerar combinações de materiais de marketing em diferentes tamanhos ou mangás de vários painéis a partir de um único comando. Em testes práticos do TechCrunch, ao inserir "crie 4 materiais de mídia social para uma nova marca de café", ele retorna quatro visuais coordenados nos formatos 1:1, 9:16, 16:9 e 3:4 de uma só vez.
Análise da precificação oficial do gpt-image-2
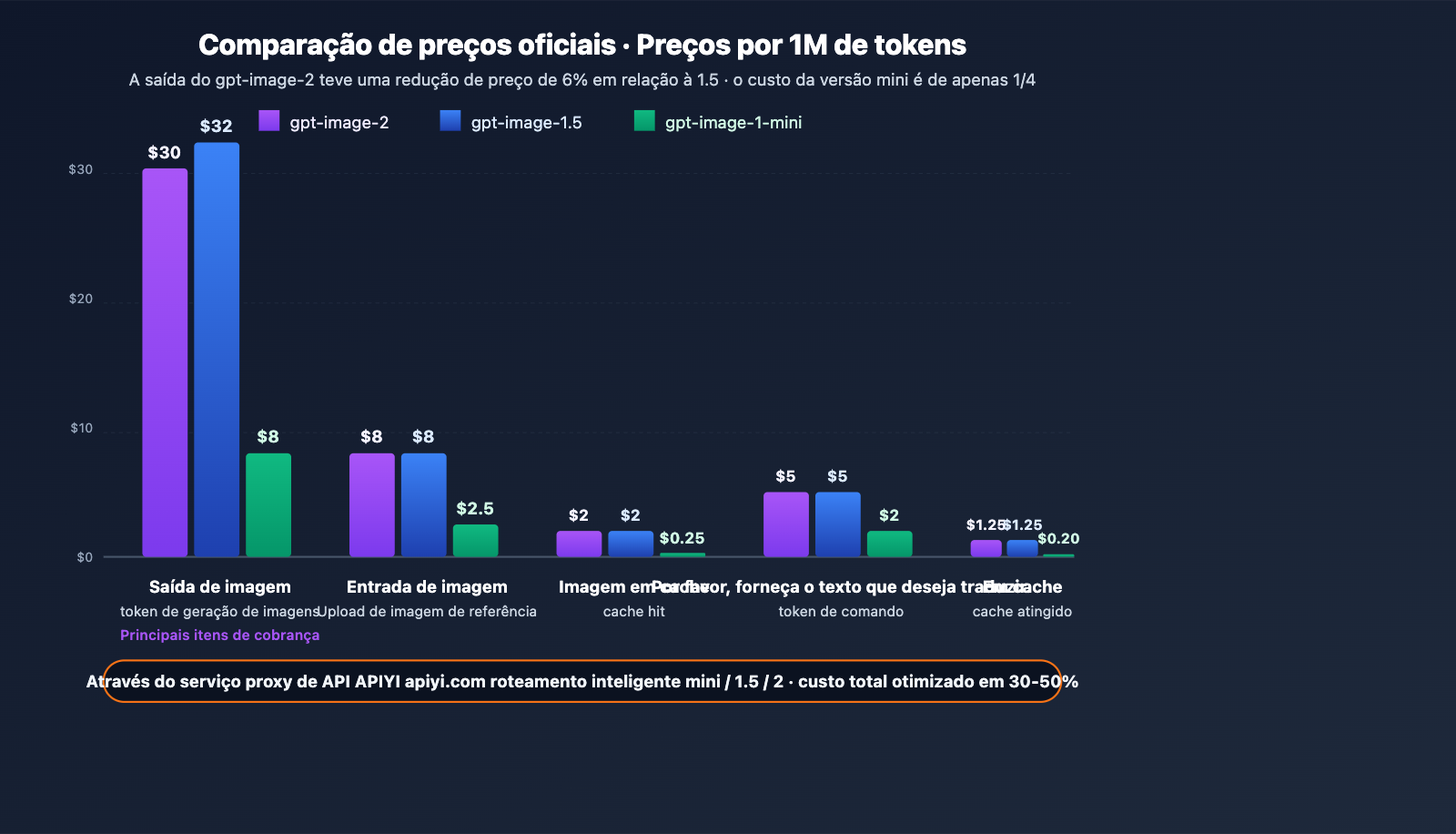
Tabela oficial de preços (por milhão de tokens)
| Modelo | Entrada de Imagem | Imagem em Cache | Saída de Imagem | Entrada de Texto | Texto em Cache | Saída de Texto |
|---|---|---|---|---|---|---|
| gpt-image-2 | $8.00 | $2.00 | $30.00 | $5.00 | $1.25 | – |
| gpt-image-1.5 | $8.00 | $2.00 | $32.00 | $5.00 | $1.25 | $10.00 |
| gpt-image-1-mini | $2.50 | $0.25 | $8.00 | $2.00 | $0.20 | – |
Interpretação chave
Lógica de precificação: A cobrança é feita com base no número de tokens de entrada e saída, e não por quantidade de imagens. Isso significa que o custo unitário de alta resolução e comandos complexos será maior, enquanto tarefas de baixa complexidade são mais econômicas — sendo mais flexível do que a "cobrança fixa por unidade".
Comparação com o gpt-image-1.5:
- A Saída de Imagem caiu de $32 para $30 (redução de preço de -6%).
- Entrada/Cache de Imagem permanecem inalterados.
- Entrada/Cache de Texto permanecem inalterados, mas o item de Saída de Texto foi removido (o gpt-image-2 é focado em geração de imagens e não gera mais texto).
- Conclusão: O custo total do gpt-image-2 diminuiu ligeiramente, mas a capacidade aumentou drasticamente, tornando o custo-benefício significativamente melhor.
Significado da versão mini: Para cenários que não exigem qualidade extrema (miniaturas em lote, rascunhos, pré-visualizações), o gpt-image-1-mini oferece capacidades básicas por cerca de 1/4 do preço, sendo ideal para cenários sensíveis a custos em larga escala.
Estimativa de custo para cenários típicos
| Cenário | Estimativa por imagem | Explicação |
|---|---|---|
| Imagem padrão com comando simples | $0.04-$0.08 | Baixo consumo de tokens |
| Imagem publicitária de complexidade média | $0.10-$0.15 | Consumo médio de tokens |
| Infográfico de alta complexidade | $0.20-$0.35 | Múltiplos elementos + comando longo |
| Edição com fusão de várias imagens | $0.15-$0.30 | Uso de imagem de referência (input) |
Dica de otimização de custos: Ao usar o gerenciamento unificado de contas da APIYI (apiyi.com), você pode rotear automaticamente as tarefas de acordo com o tipo — use o
gpt-image-1-mini($8 por saída) para pré-visualizações simples e ogpt-image-2($30 por saída) para entregas de alta qualidade, otimizando o custo total em 30-50%.
Primeiros passos com o gpt-image-2
Exemplo de invocação minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="Capa de revista 2K, marca de café 'Moonlight Roasting', "
"visual principal em tons de marrom escuro, "
"título principal em chinês 'Slow Cooking Time', "
"subtítulo 'Issue 042 · Spring 2026 Edition'",
size="2048x2048"
)
print(response.data[0].url)
Ver código de implementação completo (inclui suporte multilíngue, fusão de múltiplas imagens e fallback inteligente)
import openai
from typing import Optional, List, Literal
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_smart(
prompt: str,
quality_tier: Literal["mini", "standard", "premium"] = "standard",
size: str = "1024x1024"
) -> Optional[str]:
"""
Roteamento inteligente: seleciona o melhor modelo com base no nível de qualidade
Args:
prompt: descrição da imagem
quality_tier:
- mini: visualização em lote / rascunho (gpt-image-1-mini, 4x mais barato)
- standard: entrega convencional (gpt-image-1.5)
- premium: alta qualidade + Agentic (gpt-image-2)
size: tamanho da saída
Returns:
URL da imagem gerada
"""
model_map = {
"mini": "gpt-image-1-mini",
"standard": "gpt-image-1.5",
"premium": "gpt-image-2"
}
try:
response = client.images.generate(
model=model_map[quality_tier],
prompt=prompt,
size=size
)
return response.data[0].url
except Exception as e:
print(f"A geração falhou: {e}")
return None
multilingual_examples = {
"japonês": "Página de abertura de mangá, título '月の向こうへ', subtítulo '第1話'",
"coreano": "Capa de álbum K-pop, título em destaque '봄이 올 때' ",
"hindi": "Pôster de filme de Bollywood, título 'मानसून की रात'",
"árabe": "Pôster de caligrafia árabe, conteúdo 'مرحبا بالعالم'"
}
for lang, prompt in multilingual_examples.items():
url = generate_smart(prompt, quality_tier="premium", size="2048x2048")
print(f"[{lang}] {url}")
Sugestão da plataforma: Através da APIYI apiyi.com, você pode invocar simultaneamente os três níveis: gpt-image-2, gpt-image-1.5 e gpt-image-1-mini, utilizando uma única chave API para realizar o roteamento inteligente, usando o "mini para rascunhos e o premium para entregas oficiais".
Comparação do gpt-image-2 com concorrentes
| Modelo | Posicionamento | Vantagens principais | Preço oficial |
|---|---|---|---|
| gpt-image-2 | Flagship mais recente da OpenAI | Raciocínio Agentic + texto multilíngue | Output $30/M token |
| gpt-image-1.5 | Flagship da geração anterior | Maduro e estável + ecossistema API completo | Output $32/M token |
| gpt-image-1-mini | Entrada leve | Custo 1/4 · alta velocidade | Output $8/M token |
| Nano Banana Pro | Flagship do Google | 14 imagens de referência + SynthID | Por imagem $0.045-$0.151 |
| Midjourney v7 | Escolha para estilo artístico | Liderança em estética artística | Assinatura |
Análise comparativa do gpt-image-2
Nano Banana Pro: O Banana Pro mantém a liderança em consistência facial com múltiplas imagens de referência (14 imagens), maturidade de edição e marcas d'água de conformidade. No entanto, o gpt-image-2 oferece vantagens diferenciais em três dimensões: precisão de texto multilíngue, capacidade de raciocínio Agentic e integração com busca na Web.
gpt-image-1.5: A geração anterior continua sendo uma escolha estável e confiável, com o ecossistema de API mais maduro, sendo ideal para cenários convencionais que não exigem capacidades avançadas de Agentic. Para novos projetos, recomendamos o uso direto do gpt-image-2; projetos legados podem ser migrados gradualmente conforme o cenário.
Midjourney: No campo de estilo artístico, o Midjourney continua sendo o mais forte. O gpt-image-2 é mais adequado para cenários onde a usabilidade comercial é prioridade — como imagens de produtos, UI, infográficos e materiais de localização.
Nota de seleção: A escolha do modelo depende principalmente do seu cenário de aplicação específico e dos requisitos de qualidade. Recomendamos realizar testes práticos através da plataforma APIYI apiyi.com, onde uma única integração permite comparar diversos modelos líderes de mercado.
Cenários de aplicação típicos do gpt-image-2
Seis cenários ideais para iniciantes começarem rapidamente:
- Cenário 1 · Materiais de marketing – O raciocínio agentic garante que títulos, destaque do produto e hierarquia visual fiquem perfeitos de primeira.
- Cenário 2 · Infográficos/Ensino – Integração com busca na Web + texto multilíngue + etiquetas de dados precisas.
- Cenário 3 · Quadrinhos de vários painéis – Geração de várias cenas de uma só vez + balões de fala com texto claro.
- Cenário 4 · Layout de revistas – Resolução 2K + suporte a layouts complexos para impressão comercial.
- Cenário 5 · Publicidade localizada – Precisão em nível de caractere para CJK, hindi, bengali e árabe.
- Cenário 6 · Mockup de UI – Renderização precisa de textos pequenos, ícones e layouts densos.
Sugestão de cenário: Recomendamos que iniciantes comecem por "Materiais de marketing" e "Infográficos" — são os cenários onde é possível sentir de forma mais intuitiva o salto de capacidade do gpt-image-2 em relação à geração anterior. Você pode obter créditos de teste gratuitos na APIYI (apiyi.com) para experimentar rapidamente.
Perguntas Frequentes (FAQ)
Q1: O que é o gpt-image-2?
O gpt-image-2 é o modelo de geração de imagens de próxima geração lançado oficialmente pela OpenAI em 21/04/2026, também conhecido como "ChatGPT Images 2.0". É o primeiro modelo de imagem a introduzir as capacidades de raciocínio da série O, suportando resolução 2K, texto multilíngue, planejamento agentic e integração com busca na Web. Disponível para todos os usuários do ChatGPT/Codex desde 22 de abril, com a API prevista para o início de maio.
Q2: Qual é a maior atualização do gpt-image-2 em relação ao gpt-image-1.5?
Três atualizações principais: (1) Raciocínio Agentic — antes de gerar, o modelo pesquisa, planeja e raciocina sobre a estrutura da imagem, aumentando drasticamente a taxa de sucesso em cenas complexas; (2) Texto multilíngue — precisão em nível de caractere para idiomas não latinos, como japonês, coreano, chinês, hindi, bengali, etc.; (3) Integração com busca na Web — consulta fatos em tempo real, resolvendo o problema da data de corte de conhecimento. Além disso, o preço de saída de imagem (Image Output) caiu de $32/M tokens para $30, oferecendo melhor custo-benefício.
Q3: Quando a API oficial do gpt-image-2 estará disponível?
De acordo com o anúncio oficial da OpenAI, usuários do ChatGPT/Codex podem usar diretamente na interface web a partir de 22/04/2026, e a API do gpt-image-2 será aberta aos desenvolvedores no início de maio de 2026. Antes da abertura oficial da API, você pode acessar a nova capacidade de geração de imagens através da solução de proxy da APIYI (apiyi.com) com o modelo gpt-image-2-all ($0,03 por chamada), garantindo uma transição perfeita para o lançamento oficial.
Q4: Como entender a precificação de tokens de $8/$30?
Este é o preço unitário por milhão de tokens, seguindo a mesma lógica de cobrança de modelos de texto como o GPT-4o:
- Image Input $8: Custo de token de entrada quando o usuário faz upload de uma imagem de referência.
- Image Cached $2: Tokens de entrada que atingem o cache (grande redução de preço para imagens repetidas).
- Image Output $30: Custo de token de saída ao gerar a imagem.
- Text Input $5: Custo de entrada para o comando de texto.
O custo por imagem geralmente fica entre $0,04 e $0,35, dependendo da complexidade do comando e da resolução de saída.
Q5: Como acessar o gpt-image-2 via API?
O caminho mais rápido é através da APIYI (apiyi.com):
- Acesse apiyi.com, registre uma conta e obtenha sua chave API.
- Defina a
base_urlcomohttps://vip.apiyi.com/v1. - Use o SDK oficial da OpenAI, bastando chamar
model="gpt-image-2".
A APIYI lança novos modelos em sincronia com a OpenAI; sua chave API, saldo e faturas permanecem inalterados, e uma única conta suporta todos os modelos principais, como gpt-image-2 / gpt-image-1.5 / gpt-image-1-mini / Nano Banana Pro, etc.
Q6: Como escolher entre gpt-image-2 e gpt-image-1-mini?
Escolha com base na sensibilidade à qualidade:
- gpt-image-2: Image Output $30/M tokens, ideal para entregas finais (visuais publicitários, materiais de impressão, propostas para clientes).
- gpt-image-1-mini: Image Output $8/M tokens (cerca de 1/4 do preço), ideal para visualizações em lote, iteração de rascunhos, miniaturas e explorações experimentais.
Um fluxo de trabalho comum é a combinação de ambos: use o mini para iterar rapidamente 10-20 rascunhos e, após definir a direção, use o gpt-image-2 para gerar a versão final de alta qualidade.
Q7: Como a capacidade de “Pensamento” (Thinking) Agentic ajuda os iniciantes?
A maior ajuda para iniciantes é a redução da barreira de engenharia de comandos. Antes, era necessário ajustar meticulosamente o comando para evitar que a IA "desenhasse errado"; agora, o modelo raciocina proativamente sobre o que você deseja:
- Se você disser "capa de revista" -> ele planejará a hierarquia da fonte, o espaço em branco e a posição da imagem principal.
- Se você disser "infográfico" -> ele raciocinará sobre a precisão dos dados, a posição da legenda e a semântica das cores.
- Se você disser "quadrinhos de vários painéis" -> ele planejará o ritmo das cenas, a posição dos balões de fala e a consistência dos personagens.
Resultado: Iniciantes conseguem resultados de nível profissional mesmo com comandos simples.
Q8: Quais são as limitações conhecidas do gpt-image-2?
Três categorias de limitações:
- Corte de conhecimento em 31/12/2025: A geração de conteúdo envolvendo eventos/produtos de 2026 pode não ser precisa, dependendo da capacidade de busca na Web para complementar.
- Máximo de 2K por vez: Tamanhos superiores a 2048 exigem processamento de super-resolução posterior.
- Latência da API: O raciocínio agentic leva mais tempo do que a renderização direta; aplicações interativas precisam de um design cuidadoso de indicadores de carregamento (loading).
- Considerações de conformidade: A marca d'água SynthID + indenização de direitos autorais do Nano Banana Pro ainda são a escolha preferida para cenários sensíveis à conformidade.
Principais destaques do gpt-image-2
- Lançamento oficial em 21/04/2026: Disponível na interface web do ChatGPT/Codex em 22/04, com API aberta para desenvolvedores no início de maio.
- Primeiro modelo de imagem agente: Realiza pesquisa, planejamento, raciocínio e autoavaliação antes da geração, aumentando significativamente a taxa de sucesso em cenas complexas na primeira tentativa.
- Texto multilíngue como avanço central: Precisão em nível de caractere para idiomas não latinos, incluindo CJK (Chinês, Japonês, Coreano), Hindi, Bengali e Árabe.
- Preço oficial de $8/$30 (por milhão de tokens): O custo de saída de imagem é 6% menor que o do gpt-image-1.5, com um salto expressivo em capacidade.
- Como começar: Utilize a APIYI (apiyi.com) com uma única chave API para acessar o roteamento inteligente entre gpt-image-2 / 1.5 / mini.
Resumo
Os pontos principais do gpt-image-2 são:
- Salto geracional de capacidade: A introdução do raciocínio da série O permite que o modelo de imagem tenha, pela primeira vez, a capacidade de "pensar", resultando em uma melhoria qualitativa na taxa de sucesso em cenas complexas.
- Prioridade na viabilidade comercial: Resolução 2K, suporte a textos multilíngues e integração com busca na web apontam para um objetivo claro: pronto para produção, não apenas para entretenimento.
- Precificação transparente e previsível: A cobrança por token é mais flexível do que a taxa fixa por uso. Combinada com o nível "mini", permite construir pipelines de geração com custo otimizado.
Para a tomada de decisão da sua equipe, recomendamos começar a testar o gpt-image-2 imediatamente através da APIYI (apiyi.com). A APIYI oferece créditos gratuitos e permite a integração usando o SDK oficial da OpenAI apenas alterando a base_url. Além disso, o suporte ao roteamento inteligente entre as versões mini / 1.5 / 2 ajuda você a validar a melhor solução para diferentes cenários com o menor custo possível.
Leitura Complementar
Se você se interessou pelo gpt-image-2, recomendo continuar a leitura:
- 📘 gpt-image-2 vs gpt-image-1.5: Análise completa das oito grandes atualizações – Entenda os motivos fundamentais por trás do salto de capacidade.
- 📊 gpt-image-2: Análise completa de seis cenários de aplicação – Domine os caminhos para a implementação prática em negócios.
- 🚀 gpt-image-2 vs Nano Banana Pro: Comparação profunda – Escolha o melhor modelo de forma racional.
- ⚡ gpt-image-2-all: Solução oficial alternativa por $0,03/uso – Canal de invocação estável antes da abertura da API oficial.
📚 Referências
-
Comunicado oficial da OpenAI: Lançamento do ChatGPT Images 2.0
- Link:
openai.com/index/new-chatgpt-images-is-here - Descrição: Especificações oficiais de capacidade e posicionamento de produto do gpt-image-2.
- Link:
-
Avaliação da VentureBeat: Testes práticos com textos multilíngues, infográficos, mapas e quadrinhos
- Link:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - Descrição: Verificação independente das capacidades de multilinguismo e layout complexo.
- Link:
-
Relatório do TechCrunch: Avaliação profunda da capacidade de renderização de texto
- Link:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - Descrição: Comparação específica com modelos anteriores, como o DALL-E 3.
- Link:
-
Análise do PetaPixel: Interpretação da capacidade de "raciocínio" (Agentic Thinking)
- Link:
petapixel.com/2026/04/21/openai-claims-chatgpt-images-2-0-can-think - Descrição: Como o raciocínio da série O é integrado ao fluxo de geração de imagens.
- Link:
-
Preços oficiais da OpenAI: Tabela de preços por milhão de tokens
- Link:
openai.com/api/pricing - Descrição: Informações completas de preços para gpt-image-2 / 1.5 / mini.
- Link:
Autor: Equipe técnica da APIYI
Troca técnica: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, acesse o centro de documentação da APIYI em docs.apiyi.com.