智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。

نظرة سريعة على المعلمات الأساسية لـ GLM-5
قبل الغوص في التفاصيل التقنية، دعونا نلقي نظرة على المعلمات الرئيسية لنموذج GLM-5:
| المعلمة | القيمة | التوضيح |
|---|---|---|
| إجمالي عدد المعلمات | 744B (744 مليار) | أحد أكبر النماذج مفتوحة المصدر حالياً |
| المعلمات النشطة | 40B (40 مليار) | المستخدمة فعلياً في كل عملية استدلال |
| نوع البنية | MoE (خليط الخبراء) | 256 خبيراً، يتم تفعيل 8 خبراء لكل توكن |
| نافذة السياق | 200,000 توكن | يدعم معالجة المستندات الطويلة جداً |
| الحد الأقصى للمخرجات | 128,000 توكن | يلبي احتياجات توليد النصوص الطويلة |
| بيانات التدريب المسبق | 28.5T توكن | زيادة بنسبة 24% عن الجيل السابق |
| الترخيص | Apache-2.0 | مفتوح المصدر بالكامل، يدعم الاستخدام التجاري |
| أجهزة التدريب | رقائق هواوي أسيند (Ascend) | قدرة حوسبة محلية بالكامل، لا تعتمد على أجهزة خارجية |
تتمثل إحدى الميزات البارزة لـ GLM-5 في أنه تم تدريبه بالكامل بناءً على رقائق هواوي أسيند وإطار عمل MindSpore، مما حقق تحققاً كاملاً من سلسلة الحوسبة المحلية. بالنسبة للمطورين، هذا يعني وجود خيار قوي آخر يضمن التحكم الذاتي في البنية التقنية.
تطور إصدارات سلسلة GLM
يعد GLM-5 الجيل الخامس من سلسلة GLM التابعة لشركة Zhipu AI، حيث شهد كل جيل قفزة نوعية في القدرات:
| الإصدار | تاريخ الإصدار | حجم المعلمات | الاختراق الأساسي |
|---|---|---|---|
| GLM-4 | 01-2024 | غير معلن | القدرات الأساسية متعددة الوسائط |
| GLM-4.5 | 03-2025 | 355B (32B نشطة) | إدخال بنية MoE لأول مرة |
| GLM-4.5-X | 06-2025 | نفس السابق | تعزيز الاستدلال، مكانة رائدة |
| GLM-4.7 | 10-2025 | غير معلن | وضع الاستدلال التفكيري (Thinking) |
| GLM-4.7-FlashX | 12-2025 | غير معلن | استدلال سريع بتكلفة منخفضة جداً |
| GLM-5 | 02-2026 | 744B (40B نشطة) | اختراق في قدرات الوكيل (Agent)، انخفاض معدل الهلوسة بنسبة 56% |
من 355 مليار معلمة في GLM-4.5 إلى 744 مليار في GLM-5، تضاعف إجمالي عدد المعلمات؛ وزادت المعلمات النشطة من 32 مليار إلى 40 مليار، بزيادة قدرها 25%؛ كما زادت بيانات التدريب المسبق من 23T إلى 28.5T توكن. وراء هذه الأرقام استثمار شامل من Zhipu AI في ثلاثة أبعاد: القوة الحوسبية، البيانات، والخوارزميات.
🚀 تجربة سريعة: يتوفر GLM-5 الآن على APIYI (apiyi.com)، والأسعار مطابقة للموقع الرسمي. مع عروض شحن الرصيد، يمكنك الاستمتاع بخصم يصل إلى 20% تقريباً، وهو خيار مثالي للمطورين الراغبين في تجربة هذا النموذج الرائد ذو الـ 744 مليار معلمة بسرعة.
التحليل التقني لبنية MoE في GLM-5
لماذا اختار GLM-5 بنية MoE؟
تعد بنية MoE (Mixture of Experts) المسار التقني السائد حالياً لتوسيع نماذج اللغة الكبيرة. مقارنة ببنية Dense (حيث تشارك جميع المعلمات في كل عملية استدلال)، تقوم بنية MoE بتنشيط جزء صغير فقط من شبكات الخبراء لمعالجة كل توكن، مما يحافظ على السعة المعرفية للنموذج الكبير مع تقليل تكاليف الاستدلال بشكل كبير.
تتميز بنية MoE في GLM-5 بالخصائص الرئيسية التالية:
| ميزة البنية | تنفيذ GLM-5 | القيمة التقنية |
|---|---|---|
| إجمالي عدد الخبراء | 256 خبيراً | سعة معرفية هائلة جداً |
| التفعيل لكل توكن | 8 خبراء | كفاءة استدلال عالية |
| معدل التشتت | 5.9% | استخدام جزء صغير فقط من المعلمات |
| آلية الانتباه | DSA + MLA | تقليل تكاليف النشر |
| تحسين الذاكرة | MLA يقلل 33% | استهلاك أقل لذاكرة الفيديو |
ببساطة، على الرغم من أن GLM-5 يحتوي على 744 مليار معلمة، إلا أنه ينشط 40 مليار معلمة فقط (حوالي 5.9%) في كل عملية استدلال. وهذا يعني أن تكلفة الاستدلال أقل بكثير من نماذج Dense ذات الحجم المماثل، بينما يستفيد في الوقت نفسه من المعرفة الغنية الكامنة في الـ 744 مليار معلمة.
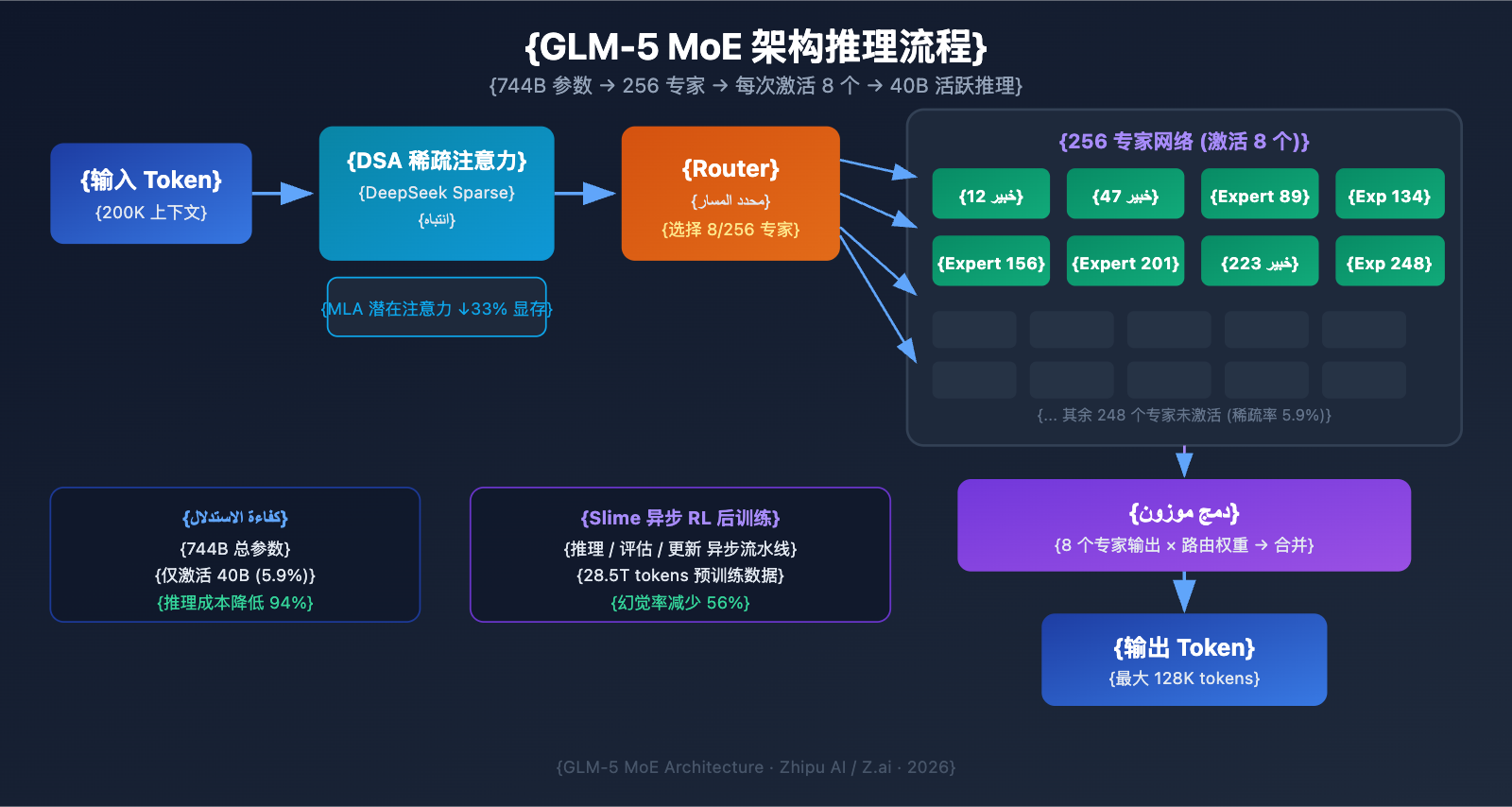
آلية DeepSeek Sparse Attention (DSA) في GLM-5
يدمج GLM-5 آلية DeepSeek Sparse Attention، وهي تقنية تقلل تكاليف النشر بشكل كبير مع الحفاظ على القدرة على معالجة السياقات الطويلة. وبالتعاون مع Multi-head Latent Attention (MLA)، يمكن لـ GLM-5 العمل بكفاءة حتى في ظل نافذة سياق طويلة جداً تصل إلى 200 ألف توكن.
بالتفصيل:
- DSA (DeepSeek Sparse Attention): يقلل من تعقيد حسابات الانتباه من خلال أنماط الانتباه المشتتة. آلية الانتباه الكاملة التقليدية تتطلب حسابات هائلة عند معالجة 200 ألف توكن، بينما يقلل DSA التكاليف من خلال التركيز الانتقائي على مواقع التوكنات الرئيسية مع الحفاظ على سلامة المعلومات.
- MLA (Multi-head Latent Attention): يضغط ذاكرة التخزين المؤقت (KV Cache) لرؤوس الانتباه في مساحة كامنة، مما يقلل من استهلاك الذاكرة بنسبة 33% تقريباً. في سيناريوهات السياق الطويل، عادة ما تكون ذاكرة التخزين المؤقت KV هي المستهلك الرئيسي لذاكرة الفيديو، ويخفف MLA هذا العنق الزجاجي بفعالية.
مزيج هاتين التقنيتين يعني: أنه حتى بالنسبة لنموذج بحجم 744 مليار معلمة، يمكن تشغيله على 8 وحدات معالجة رسومية (GPU) بعد تكميم FP8، مما يقلل بشكل كبير من عتبة النشر.
التدريب اللاحق لـ GLM-5: نظام Slime للتعلم التعزيزي غير المتزامن
اعتمد GLM-5 بنية تحتية جديدة للتعلم التعزيزي غير المتزامن تسمى "slime" للتدريب اللاحق. تعاني تدريبات التعلم التعزيزي (RL) التقليدية من اختناقات في الكفاءة، حيث توجد فترات انتظار طويلة بين خطوات التوليد والتقييم والتحديث. يحقق Slime تكرارات تدريب لاحق أكثر دقة من خلال جعل هذه الخطوات غير متزامنة، مما يزيد بشكل كبير من إنتاجية التدريب.
في عملية تدريب RL التقليدية، يحتاج النموذج أولاً إلى إكمال دفعة من الاستدلال، وانتظار نتائج التقييم، ثم إجراء تحديثات المعلمات، حيث يتم تنفيذ الخطوات الثلاث بالتسلسل. يقوم Slime بفك الارتباط بين هذه الخطوات الثلاث وتحويلها إلى خطوط أنابيب مستقلة غير متزامنة، مما يسمح بإجراء الاستدلال والتقييم والتحديث بالتوازي، وبالتالي تحسين كفاءة التدريب بشكل ملحوظ.
انعكس هذا التحسين التقني مباشرة على معدل الهلوسة في GLM-5، والذي انخفض بنسبة 56% مقارنة بالجيل السابق. سمحت تكرارات التدريب اللاحق الأكثر كفاية للنموذج بتحقيق تحسن واضح في دقة الحقائق.
مقارنة بين GLM-5 وبنية Dense
لفهم مزايا بنية MoE بشكل أفضل، يمكننا مقارنة GLM-5 بنموذج Dense افتراضي من نفس الحجم:
| بُعد المقارنة | GLM-5 (744B MoE) | نموذج Dense افتراضي (744B) | الفرق الفعلي |
|---|---|---|---|
| المعلمات لكل استدلال | 40B (5.9%) | 744B (100%) | MoE يقلل 94% |
| متطلبات ذاكرة الفيديو | 8x GPU (FP8) | حوالي 96x GPU | MoE أقل بكثير |
| سرعة الاستدلال | سريعة نسبياً | بطيئة جداً | MoE أنسب للنشر الفعلي |
| السعة المعرفية | معرفة كاملة بـ 744B | معرفة كاملة بـ 744B | متساوية |
| القدرة التخصصية | خبراء مختلفون لمهام مختلفة | معالجة موحدة | MoE أكثر دقة |
| تكلفة التدريب | عالية ولكن يمكن التحكم بها | عالية جداً | MoE أفضل في القيمة مقابل السعر |
تكمن الميزة الأساسية لبنية MoE في أنها تستخدم السعة المعرفية لـ 744 مليار معلمة، مقابل كفاءة عالية تتطلب تكلفة استدلال لـ 40 مليار معلمة فقط. وهذا هو السبب في أن GLM-5 يمكنه تقديم أداء رائد مع تسعير أقل بكثير من النماذج مغلقة المصدر من نفس الفئة.
البدء السريع في استدعاء واجهة برمجة تطبيقات (API) لنموذج GLM-5
تفاصيل معلمات طلب واجهة برمجة تطبيقات GLM-5
قبل كتابة الكود، دعنا نلقي نظرة على تكوين معلمات واجهة برمجة التطبيقات لنموذج GLM-5:
| المعلمة | النوع | مطلوب | القيمة الافتراضية | الوصف |
|---|---|---|---|---|
model |
string | ✅ | – | ثابتة على "glm-5" |
messages |
array | ✅ | – | رسائل بتنسيق الدردشة القياسي |
max_tokens |
int | ❌ | 4096 | أقصى عدد من الرموز (tokens) للمخرجات (الحد الأقصى 128 ألف) |
temperature |
float | ❌ | 1.0 | درجة حرارة العينة، كلما انخفضت زاد اليقين |
top_p |
float | ❌ | 1.0 | معلمة أخذ عينات النواة (Nucleus sampling) |
stream |
bool | ❌ | false | ما إذا كان سيتم استخدام مخرجات البث |
thinking |
object | ❌ | disabled | {"type": "enabled"} لتفعيل وضع التفكير |
tools |
array | ❌ | – | تعريف أدوات استدعاء الوظائف (Function Calling) |
tool_choice |
string | ❌ | auto | إستراتيجية اختيار الأداة |
مثال استدعاء بسيط للغاية لـ GLM-5
يتوافق GLM-5 مع تنسيق واجهة OpenAI SDK، كل ما عليك فعله هو تغيير معلمات base_url و model للوصول السريع:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "أنت خبير تقني مخضرم في الذكاء الاصطناعي"},
{"role": "user", "content": "اشرح مبدأ عمل ومزايا بنية خليط الخبراء (MoE)"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
هذا الكود يمثل الطريقة الأساسية لاستدعاء GLM-5. نستخدم معرف النموذج glm-5 والواجهة متوافقة تماماً مع تنسيق chat.completions الخاص بـ OpenAI، لذا فإن نقل المشاريع الحالية لا يتطلب سوى تعديل معلمتين فقط.
وضع الاستنتاج "التفكير" (Thinking) في GLM-5
يدعم GLM-5 وضع التفكير (Thinking)، وهو مشابه لقدرات التفكير الموسعة في DeepSeek R1 و Claude. عند تفعيله، سيقوم النموذج بإجراء استنتاج داخلي متسلسل قبل الإجابة، مما يحسن الأداء بشكل ملحوظ في المسائل الرياضية المعقدة والمنطق والبرمجة:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "أثبت أن: n^3 - n يقبل القسمة على 6 لكل عدد صحيح موجب n"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # يُنصح باستخدام 1.0 في وضع التفكير
)
print(response.choices[0].message.content)
توصيات استخدام وضع التفكير في GLM-5:
| السيناريو | هل يتم تفعيل التفكير؟ | اقتراح temperature | التوضيح |
|---|---|---|---|
| البراهين الرياضية/مسائل المسابقات | ✅ تفعيل | 1.0 | يتطلب استنتاجاً عميقاً |
| تصحيح الأخطاء البرمجية/تصميم البنية | ✅ تفعيل | 1.0 | يتطلب تحليلاً نظامياً |
| الاستنتاج المنطقي/التحليل | ✅ تفعيل | 1.0 | يتطلب تفكيراً متسلسلاً |
| المحادثات اليومية/الكتابة | ❌ إغلاق | 0.5-0.7 | لا يتطلب استنتاجاً معقداً |
| استخراج المعلومات/التلخيص | ❌ إغلاق | 0.3-0.5 | السعي وراء مخرجات مستقرة |
| إنشاء المحتوى الإبداعي | ❌ إغلاق | 0.8-1.0 | يتطلب تنوعاً |
مخرجات البث (Streaming) في GLM-5
بالنسبة للسيناريوهات التي تتطلب تفاعلاً في الوقت الفعلي، يدعم GLM-5 مخرجات البث، حيث يمكن للمستخدمين رؤية النتائج تدريجياً أثناء قيام النموذج بإنشائها:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "تنفيذ عميل HTTP مع ذاكرة تخزين مؤقت باستخدام بايثون"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
استدعاء الوظائف (Function Calling) وبناء الوكلاء (Agents) في GLM-5
يدعم GLM-5 استدعاء الوظائف بشكل أصلي، وهي القدرة الأساسية لبناء أنظمة الوكلاء (Agents). حقق GLM-5 نتيجة 50.4% في اختبار HLE w/ Tools متفوقاً على Claude Opus (43.4%)، مما يشير إلى أدائه المتميز في استدعاء الأدوات وتنسيق المهام:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "البحث عن المستندات ذات الصلة في قاعدة المعرفة",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "كلمات البحث"},
"top_k": {"type": "integer", "description": "عدد النتائج المسترجعة", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "تنفيذ كود بايثون في بيئة معزولة (Sandbox)",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "كود بايثون المراد تنفيذه"},
"timeout": {"type": "integer", "description": "وقت المهلة (بالثواني)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "أنت مساعد ذكاء اصطناعي قادر على البحث في المستندات وتنفيذ الأكواد"},
{"role": "user", "content": "ابحث لي عن المعلمات التقنية لـ GLM-5، ثم ارسم مخطط مقارنة للأداء باستخدام الكود"}
],
tools=tools,
tool_choice="auto"
)
# معالجة استدعاء الأداة
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"استدعاء الأداة: {tool_call.function.name}")
print(f"المعلمات: {tool_call.function.arguments}")
عرض مثال استدعاء cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "أنت مهندس برمجيات مخضرم"},
{"role": "user", "content": "صمم بنية نظام جدولة مهام موزعة"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 نصيحة تقنية: يتوافق GLM-5 مع تنسيق OpenAI SDK، ويمكن نقل المشاريع الحالية بمجرد تعديل معلمتي
base_urlوmodel. من خلال الاستدعاء عبر منصة APIYI apiyi.com، يمكنك الاستمتاع بإدارة موحدة للواجهات وعروض إضافية عند الشحن.
اختبارات الأداء المرجعية (Benchmark) لنموذج GLM-5
بيانات الأداء المرجعية الأساسية لـ GLM-5
أظهر GLM-5 أقوى مستوى للنماذج مفتوحة المصدر في العديد من الاختبارات المرجعية الرائدة:
| الاختبار المرجعي | GLM-5 | Claude Opus 4.5 | GPT-5 | محتوى الاختبار |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | معرفة في 57 مادة دراسية |
| MMLU Pro | 70.4% | – | – | نسخة محسنة متعددة التخصصات |
| GPQA | 68.2% | 71.4% | 73.1% | علوم بمستوى الدراسات العليا |
| HumanEval | 90.0% | 93.2% | 92.5% | برمجة بايثون |
| MATH | 88.0% | 90.1% | 91.3% | الاستنتاج الرياضي |
| GSM8k | 97.0% | 98.2% | 98.5% | مسائل رياضية لفظية |
| AIME 2026 I | 92.7% | 93.3% | – | مسابقات الرياضيات |
| SWE-bench | 77.8% | 80.9% | 80.0% | هندسة برمجيات واقعية |
| HLE w/ Tools | 50.4% | 43.4% | – | الاستنتاج باستخدام الأدوات |
| IFEval | 88.0% | – | – | اتباع التعليمات |
| Terminal-Bench | 56.2% | 57.9% | – | عمليات الطرفية (Terminal) |
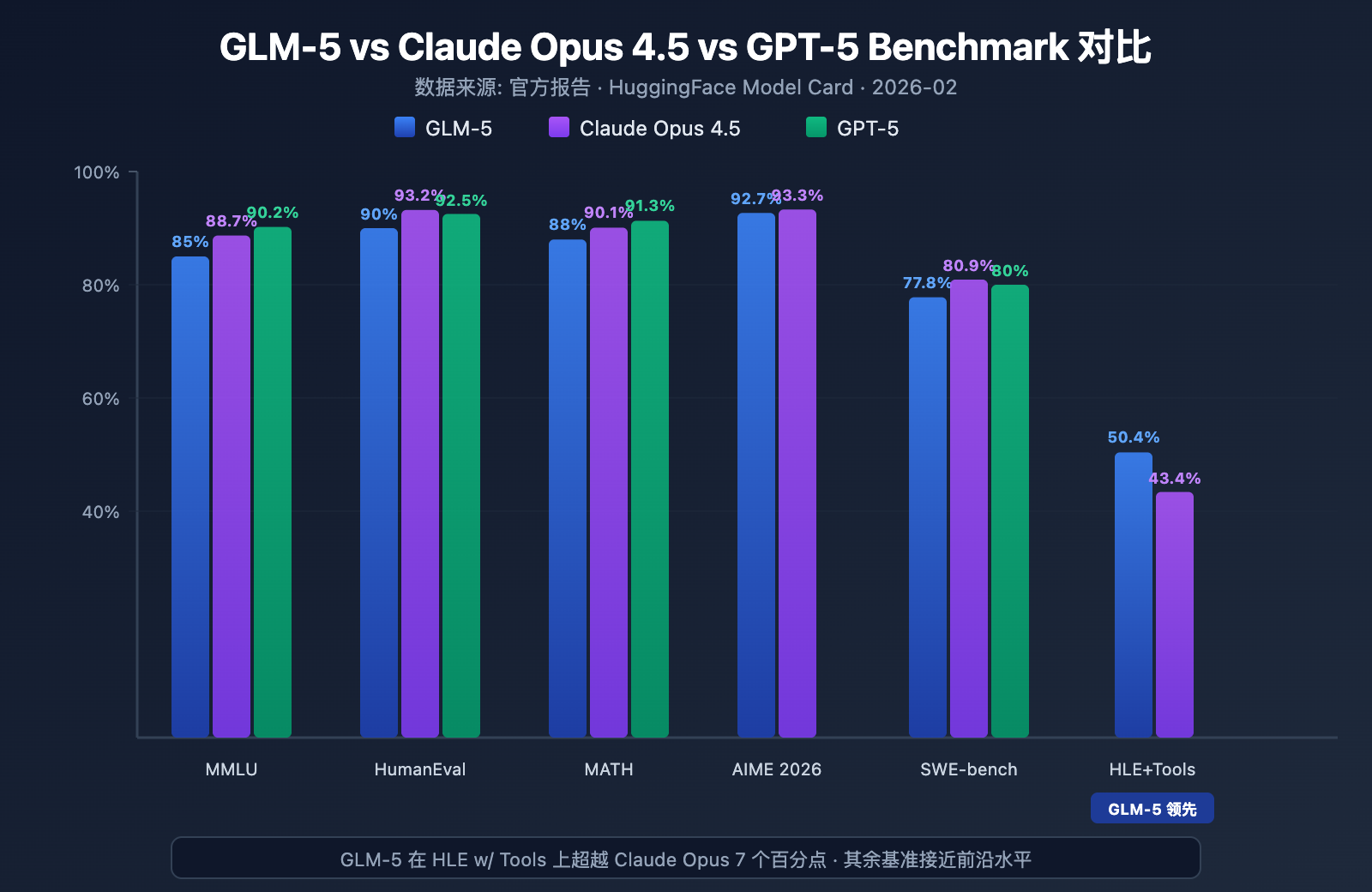
تحليل أداء GLM-5: 4 مزايا أساسية
من خلال بيانات الاختبارات المرجعية، يمكننا ملاحظة عدة نقاط جديرة بالاهتمام:
1. قدرات الوكيل (Agent) في GLM-5: اختبار HLE w/ Tools يتفوق على النماذج المغلقة
حقق GLM-5 نتيجة 50.4% في اختبار Humanity's Last Exam (مع استخدام الأدوات)، متفوقاً على Claude Opus الذي حقق 43.4%، وجاء في المرتبة الثانية بعد Kimi K2.5 الذي حقق 51.8%. هذا يشير إلى أن GLM-5 في سيناريوهات الوكلاء (Agents) – التي تتطلب التخطيط واستدعاء الأدوات والحل التكراري للمهام المعقدة – قد وصل بالفعل إلى مستوى النماذج الرائدة.
تتوافق هذه النتيجة مع فلسفة تصميم GLM-5: فقد تم تحسينه خصيصاً لسير عمل الوكلاء بدءاً من البنية التحتية وصولاً إلى مرحلة ما بعد التدريب. بالنسبة للمطورين الذين يرغبون في بناء أنظمة وكلاء ذكاء اصطناعي، يوفر GLM-5 خياراً مفتوح المصدر وعالي الكفاءة من حيث التكلفة.
2. قدرات البرمجة في GLM-5: الدخول إلى الفئة الأولى
تشير نتائج HumanEval بنسبة 90% و SWE-bench Verified بنسبة 77.8% إلى أن GLM-5 قريب جداً من مستوى Claude Opus (80.9%) و GPT-5 (80.0%) في توليد الأكواد ومهام هندسة البرمجيات الواقعية. وباعتباره نموذجاً مفتوح المصدر، فإن تحقيق 77.8% في SWE-bench يعد اختراقاً مهماً – وهذا يعني أن GLM-5 أصبح قادراً على فهم مشكلات GitHub الحقيقية، وتحديد مواقع الأخطاء في الكود، وتقديم إصلاحات فعالة.
3. الاستنتاج الرياضي في GLM-5: الاقتراب من القمة
في اختبار AIME 2026 I، حقق GLM-5 نتيجة 92.7%، متأخراً بفارق 0.6 نقطة مئوية فقط عن Claude Opus. كما أن نتيجة 97% في GSM8k تشير إلى أن GLM-5 موثوق للغاية في المسائل الرياضية متوسطة الصعوبة. وبالمثل، تضعه نتيجة 88% في اختبار MATH ضمن الفئة الأولى.
4. التحكم في الهلوسة في GLM-5: انخفاض كبير
وفقاً للبيانات الرسمية، انخفض معدل الهلوسة في GLM-5 بنسبة 56% مقارنة بالإصدارات السابقة. يعود الفضل في ذلك إلى نظام Slime RL غير المتزامن الذي أتاح تكرارات أكثر كفاية في مرحلة ما بعد التدريب. في السيناريوهات التي تتطلب دقة عالية مثل استخراج المعلومات وتلخيص المستندات والإجابة على الأسئلة بناءً على قواعد المعرفة، يترجم انخفاض معدل الهلوسة مباشرة إلى جودة مخرجات أكثر موثوقية.
مكانة GLM-5 مقارنة بالنماذج مفتوحة المصدر المنافسة
في المشهد التنافسي الحالي للنماذج الكبيرة مفتوحة المصدر، تبدو مكانة GLM-5 واضحة:
| النموذج | حجم المعلمات | البنية | الميزة الأساسية | الترخيص |
|---|---|---|---|---|
| GLM-5 | 744B (40B نشط) | MoE | وكيل (Agent) + هلوسة منخفضة | Apache-2.0 |
| DeepSeek V3 | 671B (37B نشط) | MoE | كفاءة التكلفة + استنتاج | MIT |
| Llama 4 Maverick | 400B (17B نشط) | MoE | متعدد الوسائط + نظام بيئي | Llama License |
| Qwen 3 | 235B | Dense | متعدد اللغات + أدوات | Apache-2.0 |
تتجلى المزايا التنافسية لـ GLM-5 بشكل أساسي في ثلاثة جوانب: التحسين المتخصص لسير عمل الوكلاء (الريادة في HLE w/ Tools)، ومعدل الهلوسة المنخفض للغاية (انخفاض بنسبة 56%)، وأمن سلسلة التوريد الناتج عن التدريب باستخدام قدرات حوسبة محلية بالكامل. بالنسبة للمؤسسات التي تحتاج إلى نشر نماذج رائدة مفتوحة المصدر محلياً، يعد GLM-5 خياراً يستحق الاهتمام والتركيز.
تحليل تسعير وتكلفة GLM-5
التسعير الرسمي لـ GLM-5
| نوع الفوترة | السعر الرسمي (Z.ai) | سعر OpenRouter | التوضيح |
|---|---|---|---|
| رموز الإدخال (Input Tokens) | 1.00 دولار / مليون | 0.80 دولار / مليون | لكل مليون Token إدخال |
| رموز الإخراج (Output Tokens) | 3.20 دولار / مليون | 2.56 دولار / مليون | لكل مليون Token إخراج |
| الإدخال المخزن مؤقتاً | 0.20 دولار / مليون | 0.16 دولار / مليون | سعر الإدخال عند إصابة ذاكرة التخزين المؤقت |
| تخزين ذاكرة التخزين المؤقت | مجاني مؤقتاً | – | رسوم تخزين البيانات المخزنة مؤقتاً |
مقارنة أسعار GLM-5 مع المنافسين
تعتبر استراتيجية تسعير GLM-5 تنافسية للغاية، خاصة عند مقارنتها بالنماذج الرائدة مغلقة المصدر:
| النموذج | الإدخال ($/مليون) | الإخراج ($/مليون) | التكلفة بالنسبة لـ GLM-5 | تصنيف النموذج |
|---|---|---|---|---|
| GLM-5 | 1.00 دولار | 3.20 دولار | المعيار | نموذج رائد مفتوح المصدر |
| Claude Opus 4.6 | 5.00 دولار | 25.00 دولار | حوالي 5-8 أضعاف | نموذج رائد مغلق المصدر |
| GPT-5 | 1.25 دولار | 10.00 دولار | حوالي 1.3-3 أضعاف | نموذج رائد مغلق المصدر |
| DeepSeek V3 | 0.27 دولار | 1.10 دولار | حوالي 0.3 ضعف | مفتوح المصدر (قيمة مقابل سعر) |
| GLM-4.7 | 0.60 دولار | 2.20 دولار | حوالي 0.6-0.7 ضعف | الجيل الرائد السابق |
| GLM-4.7-FlashX | 0.07 دولار | 0.40 دولار | حوالي 0.07-0.13 ضعف | تكلفة منخفضة جداً |
من حيث السعر، يتموضع GLM-5 بين GPT-5 وDeepSeek V3؛ فهو أرخص بكثير من معظم النماذج الرائدة مغلقة المصدر، ولكنه أغلى قليلاً من النماذج مفتوحة المصدر خفيفة الوزن. وبالنظر إلى حجم المعلمات البالغ 744 مليار (744B) وأدائه الأقوى بين النماذج مفتوحة المصدر، فإن هذا التسعير يعتبر منطقياً.
سلسلة منتجات GLM الكاملة وتسعيرها
إذا كان GLM-5 لا يناسب احتياجاتك تماماً، فإن Zhipu توفر خط إنتاج متكامل للاختيار من بينه:
| النموذج | الإدخال ($/مليون) | الإخراج ($/مليون) | حالات الاستخدام المناسبة |
|---|---|---|---|
| GLM-5 | 1.00 دولار | 3.20 دولار | الاستدلال المعقد، الوكلاء (Agents)، المستندات الطويلة |
| GLM-5-Code | 1.20 دولار | 5.00 دولار | مخصص لتطوير البرمجيات |
| GLM-4.7 | 0.60 دولار | 2.20 دولار | المهام العامة متوسطة التعقيد |
| GLM-4.7-FlashX | 0.07 دولار | 0.40 دولار | استدعاءات متكررة بتكلفة منخفضة |
| GLM-4.5-Air | 0.20 دولار | 1.10 دولار | توازن بين الخفة والأداء |
| GLM-4.7/4.5-Flash | مجاني | مجاني | تجربة المبتدئين والمهام البسيطة |
💰 تحسين التكلفة: يتوفر GLM-5 الآن على منصة APIYI (apiyi.com)، وبنفس الأسعار الرسمية لـ Z.ai. ومن خلال عروض شحن الرصيد الإضافية على المنصة، يمكن خفض تكلفة الاستخدام الفعلية إلى حوالي 80% من السعر الرسمي، مما يجعله مناسباً للفرق والمطورين الذين لديهم احتياجات استدعاء مستمرة.
حالات الاستخدام وتوصيات الاختيار لـ GLM-5
ما هي السيناريوهات المناسبة لـ GLM-5؟
بناءً على الخصائص التقنية لـ GLM-5 وأدائه في الاختبارات المعيارية (Benchmarks)، إليك التوصيات المحددة:
سيناريوهات نوصي بها بشدة:
- سير عمل الوكلاء (Agent Workflows): تم تصميم GLM-5 خصيصاً لمهام الوكلاء ذات الدورات الطويلة، حيث حقق 50.4% في اختبار HLE مع الأدوات متفوقاً على Claude Opus، مما يجعله مناسباً لبناء أنظمة وكلاء ذاتية التخطيط وقادرة على استدعاء الأدوات.
- مهام هندسة البرمجيات: حقق 90% في HumanEval و77.8% في SWE-bench، وهو كفء في توليد الأكواد، وإصلاح الأخطاء (Bugs)، ومراجعة الأكواد، وتصميم البنية التحتية.
- الاستدلال الرياضي والعلمي: حقق 92.7% في AIME و88% في MATH، مما يجعله مناسباً للبراهين الرياضية، واشتقاق المعادلات، والحسابات العلمية.
- تحليل المستندات الطويلة جداً: بفضل نافذة سياق تصل إلى 200 ألف Token، يمكنه معالجة قواعد بيانات برمجية كاملة، ومستندات تقنية، وعقود قانونية، وغيرها من النصوص الطويلة جداً.
- الأسئلة والأجوبة مع تقليل الهلوسة: انخفض معدل الهلوسة بنسبة 56%، مما يجعله مناسباً للأسئلة والأجوبة المبنية على قواعد المعرفة، وتلخيص المستندات، والسيناريوهات التي تتطلب دقة عالية.
سيناريوهات قد تفكر فيها في حلول أخرى:
- المهام متعددة الوسائط: يدعم GLM-5 النصوص فقط حالياً؛ إذا كنت بحاجة لفهم الصور، يرجى اختيار نماذج بصرية مثل GLM-4.6V.
- زمن استجابة منخفض للغاية: سرعة الاستدلال في نموذج MoE بحجم 744B ليست بسرعة النماذج الصغيرة؛ للسيناريوهات ذات التردد العالي وزمن الاستجابة المنخفض، نقترح استخدام GLM-4.7-FlashX.
- المعالجة الجماعية بتكلفة منخفضة جداً: إذا كانت متطلبات الجودة ليست عالية جداً لمعالجة كميات ضخمة من النصوص، فإن DeepSeek V3 أو GLM-4.7-FlashX يوفران تكلفة أقل.
مقارنة الاختيار بين GLM-5 وGLM-4.7
| بُعد المقارنة | GLM-5 | GLM-4.7 | توصية الاختيار |
|---|---|---|---|
| حجم المعلمات | 744B (40B نشطة) | غير معلن | GLM-5 أكبر |
| قدرة الاستدلال | 92.7% (AIME) | ~85% | للاستدلال المعقد اختر GLM-5 |
| قدرات الوكلاء | 50.4% (HLE w/ Tools) | ~38% | لمهام الوكلاء اختر GLM-5 |
| قدرات البرمجة | 90% (HumanEval) | ~85% | لتطوير البرمجيات اختر GLM-5 |
| التحكم في الهلوسة | تقليل بنسبة 56% | المعيار الأساسي | للدقة العالية اختر GLM-5 |
| سعر الإدخال | 1.00 دولار / مليون | 0.60 دولار / مليون | إذا كانت التكلفة أولوية اختر GLM-4.7 |
| سعر الإخراج | 3.20 دولار / مليون | 2.20 دولار / مليون | إذا كانت التكلفة أولوية اختر GLM-4.7 |
| طول السياق | 200K | 128K+ | للمستندات الطويلة اختر GLM-5 |

💡 نصيحة الاختيار: إذا كان مشروعك يتطلب قدرات استدلال من الدرجة الأولى، أو سير عمل وكلاء، أو معالجة سياق طويل جداً، فإن GLM-5 هو الخيار الأفضل. أما إذا كانت الميزانية محدودة وتعقيد المهام متوسطاً، فإن GLM-4.7 يظل خياراً ممتازاً من حيث القيمة مقابل السعر. يمكن استدعاء كلا النموذجين عبر منصة APIYI (apiyi.com)، مما يسهل التبديل بينهما للاختبار في أي وقت.
الأسئلة الشائعة حول استدعاء واجهة برمجة تطبيقات (API) GLM-5
س1: ما الفرق بين GLM-5 و GLM-5-Code؟
نموذج GLM-5 هو النموذج الرائد العام (المدخلات 1.00 دولار/مليون رمز، المخرجات 3.20 دولار/مليون رمز)، وهو مناسب لمختلف المهام النصية. أما GLM-5-Code فهو نسخة معززة مخصصة للأكواد (المدخلات 1.20 دولار/مليون رمز، المخرجات 5.00 دولار/مليون رمز)، حيث تم تحسينه بشكل إضافي لمهام توليد الأكواد، وتصحيح الأخطاء، والمهام الهندسية. إذا كان سيناريو الاستخدام الأساسي لديك هو تطوير البرمجيات، فإن GLM-5-Code يستحق التجربة. يدعم كلا النموذجين الاستدعاء عبر واجهة موحدة متوافقة مع OpenAI.
س2: هل يؤثر “وضع التفكير” (Thinking mode) في GLM-5 على سرعة المخرجات؟
نعم، يؤثر. في وضع التفكير، يقوم GLM-5 أولاً بتوليد سلسلة استدلال داخلية قبل إعطاء الإجابة النهائية، لذا سيزداد زمن وصول أول رمز (TTFT). بالنسبة للأسئلة البسيطة، ننصح بإيقاف وضع التفكير للحصول على استجابة أسرع. أما بالنسبة للمسائل الرياضية والبرمجية والمنطقية المعقدة، فننصح بتفعيله؛ فرغم أنه أبطأ قليلاً، إلا أن دقة النتائج ستتحسن بشكل ملحوظ.
س3: ما هي التعديلات البرمجية المطلوبة للانتقال من GPT-4 أو Claude إلى GLM-5؟
الانتقال بسيط للغاية، كل ما عليك فعله هو تعديل معلمين (parameters) فقط:
- تغيير
base_urlإلى عنوان واجهة APIYI:https://api.apiyi.com/v1 - تغيير معلم
modelإلى"glm-5"
يتوافق GLM-5 تماماً مع تنسيق واجهة chat.completions الخاصة بـ OpenAI SDK، بما في ذلك أدوار النظام/المستخدم/المساعد (system/user/assistant)، والمخرجات المتدفقة (streaming)، واستدعاء الدوال (Function Calling)، وغيرها. ومن خلال منصة APIYI الموحدة، يمكنك أيضاً التبديل بين نماذج الشركات المصنعة المختلفة باستخدام نفس مفتاح API، مما يجعل اختبارات A/B مريحة للغاية.
س4: هل يدعم GLM-5 إدخال الصور؟
لا يدعم ذلك. نموذج GLM-5 في جوهره هو نموذج نصي فقط، ولا يدعم إدخال الصور أو الصوت أو الفيديو. إذا كنت بحاجة إلى قدرات فهم الصور، يمكنك استخدام النماذج البصرية من Zhipu مثل GLM-4.6V أو GLM-4.5V.
س5: كيف يمكن استخدام خاصية تخزين السياق مؤقتاً (Context Caching) في GLM-5؟
يدعم GLM-5 خاصية تخزين السياق مؤقتاً (Context Caching)، حيث يبلغ سعر المدخلات المخزنة مؤقتاً 0.20 دولار/مليون رمز فقط، وهو ما يمثل 1/5 من سعر المدخلات العادية. في المحادثات الطويلة أو السيناريوهات التي تتطلب معالجة متكررة لنفس البادئة، يمكن لخاصية التخزين المؤقت تقليل التكاليف بشكل كبير. تخزين الذاكرة المؤقتة مجاني حالياً لفترة مؤقتة. في المحادثات متعددة الجولات، سيتعرف النظام تلقائياً على بادئات السياق المتكررة ويقوم بتخزينها مؤقتاً.
س6: ما هو أقصى طول للمخرجات في GLM-5؟
يدعم GLM-5 طول مخرجات يصل إلى 128,000 رمز (token). بالنسبة لمعظم السيناريوهات، يكفي الطول الافتراضي البالغ 4096 رمزاً. إذا كنت بحاجة إلى توليد نصوص طويلة (مثل الوثائق التقنية الكاملة أو كتل برمجية ضخمة)، يمكنك تعديل ذلك عبر معلم max_tokens. يرجى ملاحظة أنه كلما زاد طول المخرجات، زاد استهلاك الرموز ووقت الانتظار وفقاً لذلك.
أفضل الممارسات لاستدعاء واجهة برمجة تطبيقات GLM-5
عند استخدام GLM-5 في الواقع العملي، يمكن أن تساعدك الخبرات التالية في الحصول على نتائج أفضل:
تحسين موجه النظام (System Prompt) لنموذج GLM-5
تتمتع استجابة GLM-5 لموجه النظام بجودة عالية، وتصميم موجه النظام بشكل منطقي يمكن أن يحسن جودة المخرجات بشكل كبير:
# توصية: تعريف واضح للدور + متطلبات تنسيق المخرجات
messages = [
{
"role": "system",
"content": """أنت مهندس معماري خبير في الأنظمة الموزعة.
يرجى اتباع القواعد التالية:
1. يجب أن تكون الإجابة منظمة، باستخدام تنسيق Markdown.
2. قدم حلولاً تقنية محددة بدلاً من الحديث العام.
3. إذا كان الأمر يتعلق بكود برمي، فقدم مثالاً قابلاً للتشغيل.
4. حدد المخاطر المحتملة والملاحظات الهامة في المواضع المناسبة."""
},
{
"role": "user",
"content": "صمم نظام طابور رسائل (Message Queue) يدعم ملايين الاتصالات المتزامنة"
}
]
دليل ضبط درجة الحرارة (temperature) لنموذج GLM-5
تختلف حساسية المهام المختلفة لدرجة الحرارة، وإليك التوصيات بناءً على الاختبارات الفعلية:
- temperature 0.1-0.3: للمهام التي تتطلب مخرجات دقيقة مثل توليد الأكواد، واستخراج البيانات، وتحويل التنسيقات.
- temperature 0.5-0.7: للوثائق التقنية، والأسئلة والأجوبة، والملخصات، حيث تتطلب استقراراً مع قدر من المرونة في التعبير.
- temperature 0.8-1.0: للمهام التي تتطلب تنوعاً مثل الكتابة الإبداعية والعصف الذهني.
- temperature 1.0 (وضع التفكير): لمهام الاستدلال العميق مثل الاستدلال الرياضي والبرمجة المعقدة.
تقنيات التعامل مع السياق الطويل في GLM-5
يدعم GLM-5 نافذة سياق تصل إلى 200 ألف رمز (200K tokens)، ولكن يجب مراعاة ما يلي عند الاستخدام الفعلي:
- وضع المعلومات المهمة في البداية: ضع أهم سياق في بداية الموجه (prompt) وليس في نهايته.
- المعالجة المجزأة: بالنسبة للمستندات التي تتجاوز 100 ألف رمز، ننصح بمعالجتها على أجزاء ثم دمجها للحصول على مخرجات أكثر استقراراً.
- الاستفادة من التخزين المؤقت: في المحادثات متعددة الجولات، سيتم تخزين محتوى البادئة المتطابق تلقائياً، وسعر المدخلات المخزنة مؤقتاً هو 0.20 دولار/مليون رمز فقط.
- التحكم في طول المخرجات: عند إدخال سياق طويل، قم بضبط
max_tokensبشكل مناسب لتجنب المخرجات الطويلة جداً التي تزيد من التكاليف غير الضرورية.
مرجع النشر المحلي لنموذج GLM-5
إذا كنت بحاجة إلى نشر GLM-5 على بنيتك التحتية الخاصة، فإليك طرق النشر الرئيسية:
| طريقة النشر | الأجهزة الموصى بها | الدقة | المميزات |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | إطار عمل استدلال شائع، يدعم فك التشفير التخميني |
| SGLang | 8x H100/B200 | FP8 | استدلال عالي الأداء، تحسينات لمعالجات Blackwell GPU |
| xLLM | Huawei Ascend NPU | BF16/FP8 | مواءمة مع قدرات الحوسبة المحلية (الصينية) |
| KTransformers | بطاقات GPU استهلاكية | تكميم (Quantization) | تسريع الاستدلال باستخدام GPU |
| Ollama | أجهزة استهلاكية | تكميم (Quantization) | أسهل تجربة تشغيل محلي |
يوفر GLM-5 أوزان النموذج بتنسيقين: الدقة الكاملة BF16 وتنسيق FP8 المكمّم، ويمكن تحميلهما من HuggingFace (huggingface.co/zai-org/GLM-5) أو ModelScope. يقلل إصدار FP8 المكمّم من متطلبات ذاكرة الفيديو (VRAM) بشكل كبير مع الحفاظ على معظم الأداء.
التكوينات الرئيسية المطلوبة لنشر GLM-5:
- توازي الموتر (Tensor Parallel): 8 طرق (tensor-parallel-size 8)
- معدل استخدام ذاكرة الفيديو: يُنصح بضبطه على 0.85
- محلل استدعاء الأدوات: glm47
- محلل الاستدلال: glm45
- فك التشفير التخميني: يدعم طريقتي MTP و EAGLE
بالنسبة لمعظم المطورين، يعد استدعاء النموذج عبر واجهة برمجة التطبيقات (API) هو الطريقة الأكثر كفاءة، حيث يوفر تكاليف النشر والصيانة، مما يسمح لك بالتركيز فقط على تطوير التطبيقات. للحالات التي تتطلب نشراً خاصاً، يمكنك الرجوع إلى المستندات الرسمية:
github.com/zai-org/GLM-5
ملخص استدعاء واجهة برمجة التطبيقات (API) لنموذج GLM-5
نظرة سريعة على القدرات الأساسية لنموذج GLM-5
| بُعد القدرة | أداء GLM-5 | حالات الاستخدام المناسبة |
|---|---|---|
| الاستدلال | AIME 92.7%, MATH 88% | البراهين الرياضية، الاستدلال العلمي، التحليل المنطقي |
| البرمجة | HumanEval 90%, SWE-bench 77.8% | توليد الأكواد، إصلاح الأخطاء (Bugs)، تصميم البنية التحتية |
| الوكيل (Agent) | HLE w/ Tools 50.4% | استدعاء الأدوات، تخطيط المهام، التنفيذ الذاتي |
| المعرفة | MMLU 85%, GPQA 68.2% | الأسئلة والأجوبة الأكاديمية، الاستشارات التقنية، استخراج المعرفة |
| التعليمات | IFEval 88% | المخرجات المنسقة، التوليد الهيكلي، الالتزام بالقواعد |
| الدقة | تقليل معدل الهلوسة بنسبة 56% | ملخصات المستندات، التحقق من الحقائق، استخراج المعلومات |
قيمة النظام البيئي مفتوح المصدر لنموذج GLM-5
يتم إصدار GLM-5 بموجب ترخيص Apache-2.0 مفتوح المصدر، مما يعني:
- حرية تجارية: يمكن للمؤسسات استخدامه وتعديله وتوزيعه مجاناً دون دفع رسوم ترخيص.
- التخصيص عبر الضبط الدقيق (Fine-tuning): يمكن إجراء ضبط دقيق لنموذج GLM-5 بناءً على مجالات محددة لبناء نماذج مخصصة للصناعة.
- النشر الخاص: البيانات الحساسة لا تخرج من الشبكة الداخلية، مما يلبي متطلبات الامتثال في القطاعات المالية والطبية والحكومية.
- النظام البيئي للمجتمع: يوجد بالفعل أكثر من 11 متغيراً مكمّماً و7 إصدارات مضبوطة دقيقاً على HuggingFace، والنظام البيئي في توسع مستمر.
باعتباره أحدث نموذج رائد من Zhipu AI، يضع GLM-5 معايير جديدة في مجال نماذج اللغة الكبيرة مفتوحة المصدر:
- بنية MoE بسعة 744 مليار معلمة: نظام يضم 256 خبيراً، يقوم بتنشيط 40 مليار معلمة في كل عملية استدلال، مما يحقق توازناً ممتازاً بين سعة النموذج وكفاءة الاستدلال.
- أقوى Agent مفتوح المصدر: حقق 50.4% في اختبار HLE مع الأدوات، متفوقاً على Claude Opus، وهو مصمم خصيصاً لسير عمل الوكلاء (Agents) ذوي الدورات الطويلة.
- تدريب بقدرات حوسبة محلية كاملة: تم التدريب باستخدام 100,000 شريحة Huawei Ascend، مما يثبت قدرة تقنيات الحوسبة المحلية على تدريب نماذج رائدة.
- فعالية عالية من حيث التكلفة: تكلفة الإدخال 1 دولار لكل مليون توكن، والمخرجات 3.2 دولار لكل مليون توكن، وهي أقل بكثير من النماذج المغلقة من نفس الفئة، مع إمكانية النشر والضبط الدقيق بحرية من قبل المجتمع.
- سياق فائق الطول 200K: يدعم المعالجة الفورية لقواعد الأكواد الكاملة والمستندات التقنية الضخمة، مع حد أقصى للمخرجات يصل إلى 128K توكن.
- هلوسة منخفضة بنسبة 56%: أدى التدريب اللاحق باستخدام Slime asynchronous RL إلى تحسين دقة الحقائق بشكل كبير.
نوصي بتجربة مختلف قدرات GLM-5 بسرعة عبر APIYI (apiyi.com)، حيث تتطابق أسعار المنصة مع الأسعار الرسمية، مع توفر عروض شحن إضافية تمنحك خصماً فعلياً يصل إلى 20%.
تمت كتابة هذا المقال بواسطة الفريق التقني لـ APIYI Team. لمزيد من الشروحات حول استخدام نماذج الذكاء الاصطناعي، يرجى متابعة مركز المساعدة في APIYI (apiyi.com).