Многие дизайнеры, впервые сталкиваясь с GPT-Image-2, задаются вопросом: когда я загружаю фото и прошу «заменить одежду персонажа на синюю», ИИ действительно точечно правит пиксели, как в Photoshop, или он просто перерисовывает картинку с нуля? Ответ на этот вопрос напрямую влияет на то, как мы используем инструменты редактирования ИИ и насколько предсказуемыми будут результаты.
На самом деле, это глубоко заблуждение. В этой статье мы разберем принципы редактирования изображений ИИ, углубимся в механизмы работы авторегрессионных моделей нового поколения, таких как GPT-Image-2 и Nano Banana, и ответим на главный вопрос: «локальное редактирование или полная перерисовка». Мы также раскроем секрет того, как этим моделям удается сохранять поразительную визуальную согласованность при полной перерисовке изображения.

| Ключевой вопрос | Интуитивный ответ | Реальный ответ |
|---|---|---|
| Способ редактирования | Локальное наложение (как в PS) | Перерисовка токенов всего изображения |
| Источник согласованности | Сохранение нетронутых пикселей | Якорение признаков через механизм внимания |
| Основная архитектура | Диффузионное шумоподавление | Авторегрессионный Transformer |
| Многократное редактирование | Накопление артефактов | GPT-Image-2 без заметного дрейфа |
Разобравшись в этой теории, вы поймете, что написание промптов, использование масок и стратегии передачи эталонных изображений теперь имеют под собой четкую базу. Мы рекомендуем читателям тестировать GPT-Image-2 через платформу APIYI (apiyi.com), чтобы на практике увидеть, как эти принципы влияют на результат.
Принцип редактирования ИИ: не локальная правка, а интеллектуальная перерисовка
Многие пользователи, основываясь на опыте работы с веб-интерфейсом ChatGPT, ошибочно полагают, что ИИ редактирует фото как Photoshop: система находит область для правок, «закрашивает» её, а остальное оставляет нетронутым. Эта ментальная модель интуитивна, но в корне неверна.
Все современные модели редактирования изображений по своей сути работают через «перерисовку». Будь то GPT-Image-2, Nano Banana или семейство Stable Diffusion — все они сначала кодируют исходное изображение во внутреннее представление (токены или латентное пространство), затем модель «дорисовывает» новое состояние, и в конце происходит декодирование обратно в пиксели. Здесь нет никакого «рисования поверх оригинала».
Именно поэтому, когда вы просите ИИ изменить цвет одного глаза, вы можете заметить, что текстура волос или фон тоже слегка изменились. Модель не ленится — она действительно перерисовывает всё изображение, просто в большинстве областей она делает это максимально близко к оригиналу.
Возникает вопрос: если это перерисовка, почему изображения после GPT-Image-2 выглядят так похоже на оригинал и позволяют многократно редактировать их без потери качества? Ответ кроется в архитектуре. Если хотите проверить это на практике, вы можете вызвать эндпоинт /v1/images/edits для модели gpt-image-2 на платформе APIYI (apiyi.com), используя один и тот же промпт для повторного редактирования одного и того же файла.
Фундаментальные различия между PS и ИИ-перерисовкой
| Сравнение | Локальная правка в Photoshop | Интеллектуальная перерисовка GPT-Image-2 |
|---|---|---|
| Единица операции | Пиксель | Визуальный токен (блоки 8×8 или 16×16) |
| Неизмененные области | Физически остаются прежними | Проходят через кодирование-декодирование (возможны микро-изменения) |
| Гарантия согласованности | 100% (копирование пикселей) | Обеспечивается механизмом внимания модели |
| Семантическое понимание | Отсутствует, работа только с цветом | Понимание «одежды», «фона», «освещения» |
| Переходы границ | Требуется ручная растушевка | Автоматический естественный переход |
Photoshop — это «механическая правка» на уровне пикселей, а ИИ — это «понимание и перерисовка» на уровне смыслов. Именно поэтому ИИ способен на глобальные изменения, такие как «превратить день в сумерки», что в PS сделать крайне сложно — ведь он меняет семантическое представление изображения, а не просто значения RGB.
Принцип редактирования gpt-image-2: как авторегрессионный трансформер «понимает» исходное изображение
Чтобы по-настоящему понять принцип редактирования gpt-image-2, нужно разобраться в ключевом архитектурном решении, принятом OpenAI при выпуске этой модели 21 апреля 2026 года: отказ от диффузионных моделей, используемых в серии DALL-E, в пользу авторегрессионного трансформера. Это решение было напрямую заимствовано из мультимодальной архитектуры GPT-4o.
Авторегрессионная генерация по своей сути работает по тому же принципу, что и написание текста в ChatGPT — предсказание следующего токена. Разница лишь в том, что здесь «токен» — это не слово, а визуальный токен. Модель выполняет следующие шаги:
- Токенизация изображения: с помощью механизма дискретизации, похожего на VQ-VAE, изображение разбивается примерно на 1024–1290 визуальных токенов, где каждый токен соответствует блоку исходного изображения размером 8×8 или 16×16 пикселей.
- Конкатенация последовательности: текстовый промпт пользователя и визуальные токены исходного изображения объединяются в длинную последовательность, которая подается в единый трансформер.
- Потокенная генерация: модель предсказывает каждый визуальный токен выходного изображения слева направо (или по растровой развертке). При генерации каждого нового токена модель «видит» все предыдущие входные данные и уже сгенерированный контент.
- Декодирование в пиксели: после того как все визуальные токены сгенерированы, декодер восстанавливает их в финальное изображение.
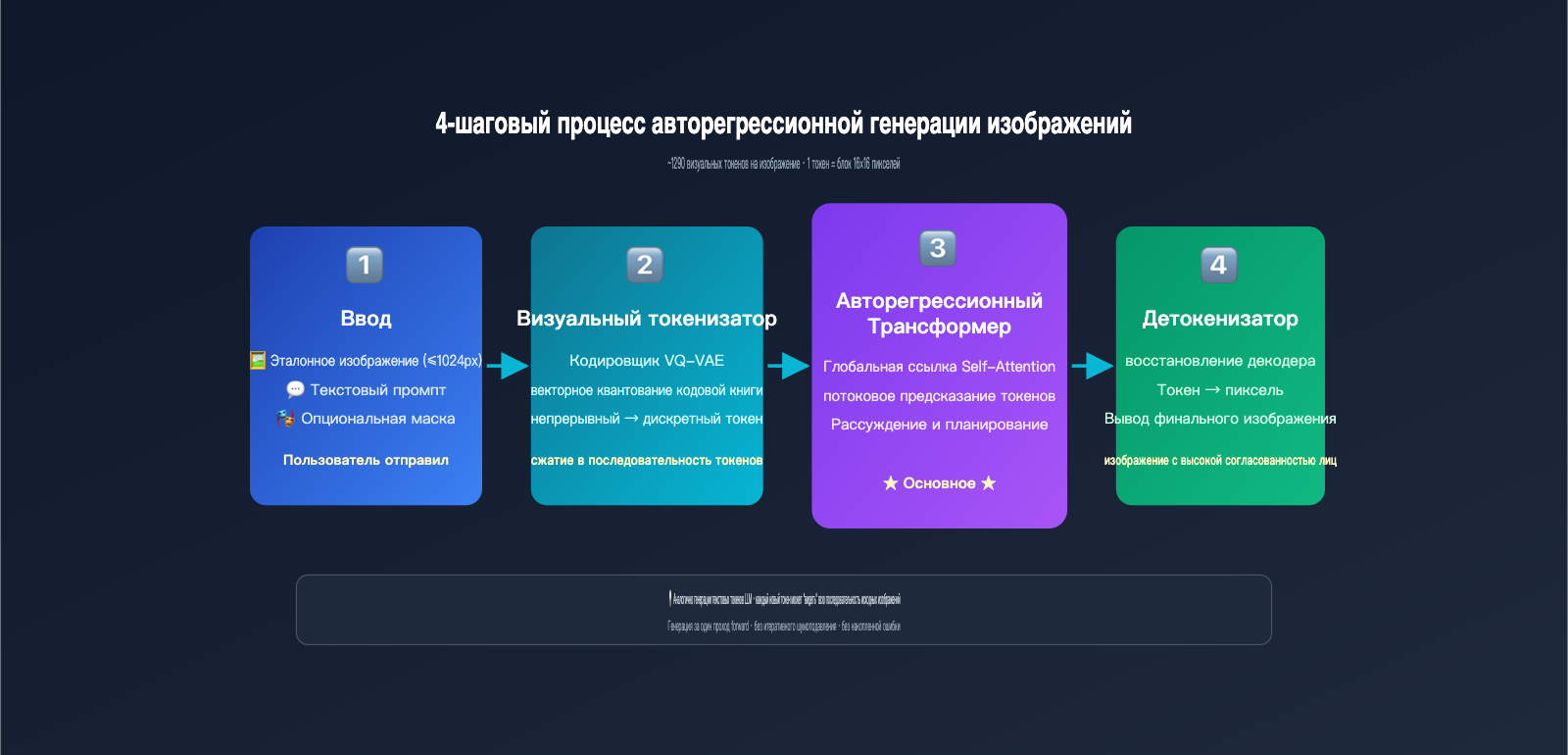
Ключевой инсайт здесь заключается в том, что при генерации нового изображения все токены исходного изображения находятся в «поле зрения» GPT-Image-2. Это работает точно так же, как в диалоге с ChatGPT, где модель «видит» все предыдущие сообщения. Механизм Self-Attention позволяет каждому новому токену «ссылаться» на характеристики любой части исходного изображения.
Кроме того, OpenAI внедрила в GPT-Image-2 «режим мышления» (Thinking mode), который позволяет модели перед началом генерации визуальных токенов провести внутренний анализ: что именно хочет изменить пользователь, какие части нужно сохранить и как организовать пространственную компоновку. Это значительно повысило точность выполнения сложных инструкций по редактированию, достигнув 99% точности в передаче текста и точного расположения объектов. Если вам нужно протестировать эти возможности в продакшене, вы можете подключиться к gpt-image-2 через сервис-прокси API APIYI (apiyi.com), который предоставляет интерфейсы, соответствующие официальным стандартам, и удобное переключение между моделями.
Визуальный токенизатор: баланс между сжатием и сохранением информации
Визуальный токенизатор является «узким местом» всей системы авторегрессионной генерации изображений. Ему приходится балансировать между двумя целями:
- Высокая степень сжатия: чем меньше токенов, тем быстрее работает трансформер и тем ниже затраты.
- Высокое качество реконструкции: декодированные пиксели должны максимально точно соответствовать оригиналу без потери деталей.
Основной подход — использование VQ-VAE (векторно-квантованный вариационный автокодировщик): энкодер сжимает область изображения в непрерывный вектор, который затем сопоставляется с ближайшим индексом «кодовой книги» (codebook). Этот индекс и становится токеном. Изображение 1024×1024 обычно сжимается примерно до 1024 токенов с очень высокой плотностью информации.
Поскольку само по себе сжатие является процессом с потерями, ни один инструмент редактирования на базе ИИ не может гарантировать «100% сохранение пикселей в нетронутых областях». Это подводит нас к следующему важному вопросу — согласованности.
Основные механизмы согласованности AI-изображений: визуальная токенизация и якорение внимания
Раз GPT-Image-2 выполняет перерисовку всего изображения целиком, возникает вопрос: как именно достигается согласованность лиц? Почему при редактировании портрета ваши черты лица, цвет кожи и прическа не превращаются в другого человека? Ответ кроется на четырех уровнях.
Первый уровень: высокая степень абстракции визуальных токенов. После того как лицо проходит через токенизатор, сгенерированная последовательность токенов уже кодирует ключевые характеристики «этого человека» — форму лица, пропорции черт, оттенок кожи. Пока эти «токены идентичности» сохраняются при генерации нового изображения, персонаж остается прежним.
Второй уровень: глобальная ссылка через Self-Attention. Авторегрессионный трансформер при генерации каждого нового токена вычисляет веса внимания по отношению ко всем входным токенам (включая токены исходного изображения). Если пользователь не просил менять определенную область, модель присваивает высокий вес соответствующим токенам оригинала, по сути, «копируя» их.
Третий уровень: индуктивное смещение в обучающих данных. OpenAI использовала огромные массивы пар «оригинал — отредактированное изображение» для обучения GPT-Image-2. В процессе модель усвоила негласное правило: если промпт прямо не требует изменений, стараться сохранять остальные области неизменными. Это смещение закрепилось в весах и работает автоматически при инференсе.
Четвертый уровень: явное планирование в режиме Thinking. GPT-Image-2 сначала проводит внутренний анализ, определяя, «какие области нужно изменить, а какие сохранить», и только потом приступает к генерации. Это равносильно составлению списка исключений перед началом работы.
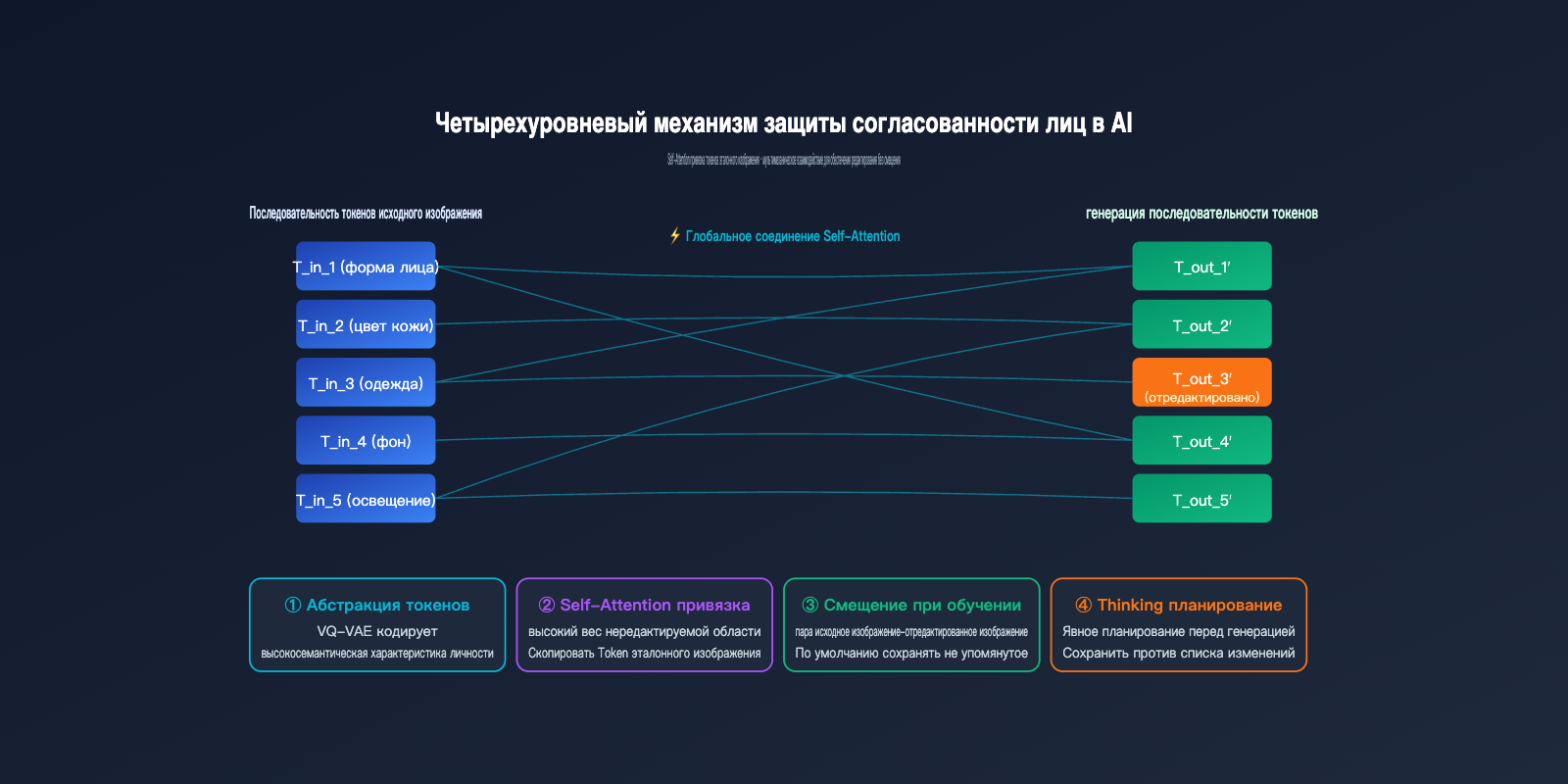
Сравнение уровней защиты согласованности
| Механизм | Область действия | Сценарии сбоя |
|---|---|---|
| Абстракция токенов | Глобальные признаки личности | Нехватка токенов из-за удаленности лица |
| Self-Attention | Якорение локальных деталей | Семантический конфликт промпта с оригиналом |
| Обучающее смещение | Сохранение нетронутых областей | Слишком агрессивный промпт |
| Планирование Thinking | Сложные инструкции редактирования | Требуется многократная настройка |
Понимая эти четыре уровня защиты, вы сможете составлять более точные промпты, избегая «дрейфа» характеристик. Например, вместо фразы «перерисуй одежду этого человека» лучше сказать: «сохраняя личность персонажа неизменной, измени только цвет одежды с белого на синий». При тестировании GPT-Image-2 на APIYI (apiyi.com) мы заметили, что добавление явных ограничений, таких как «сохранить остальные элементы без изменений», позволяет режиму Thinking работать гораздо эффективнее.
Режим маски: как заставить перерисовку «притвориться» локальным изменением
Если пользователю нужен более предсказуемый результат при локальном редактировании, GPT-Image-2 предлагает параметр mask для эндпоинта /v1/images/edits. Вы можете передать бинарное изображение маски: белые области разрешают ИИ генерацию, черные — требуют сохранения оригинала.
Однако важно подчеркнуть: режим маски не меняет саму суть перерисовки. Его задача — добавить жесткое ограничение при генерации токенов: токены, соответствующие черным областям, должны в точности соответствовать токенам оригинала. Это «ограниченная генерация» внутри авторегрессионного фреймворка, а не просто наложение пикселей в стиле Photoshop.
Диффузионные модели против авторегрессионной генерации изображений: сравнение принципов работы
Чтобы по достоинству оценить преимущества GPT-Image-2, нужно систематически сравнить её с предыдущим поколением диффузионных моделей (Stable Diffusion, DALL-E 3, Midjourney). Эти два подхода имеют фундаментальные различия в принципах редактирования изображений с помощью ИИ.
Рабочий процесс диффузионных моделей начинается с изображения, состоящего из чистого шума, которое проходит через десятки итераций удаления шума, постепенно проявляя финальную картинку. При редактировании модель сначала сжимает исходное изображение в латентное пространство, добавляет туда немного шума, а затем использует промпт для управления процессом удаления шума, в конечном итоге декодируя результат обратно в пиксели. В режиме inpainting на каждом шаге удаления шума латентные данные вне маски сбрасываются до значений исходного изображения, что позволяет «зафиксировать» нередактируемые области.
Рабочий процесс авторегрессионных моделей совершенно иной: изображение кодируется в токены, а затем, подобно написанию текста, предсказывается по одному токену за раз. Здесь нет итеративного удаления шума, нет латентного шума — генерация происходит за один проход.

Разница в производительности этих двух парадигм при редактировании изображений огромна, подробности приведены в таблице ниже:
| Сравнительный параметр | Диффузионные модели (SD/DALL-E 3) | Авторегрессионные модели (GPT-Image-2/Nano Banana) |
|---|---|---|
| Способ генерации | Итеративное удаление шума | Потоковое предсказание токенов |
| Реализация маски | Сброс латентных данных вне маски | Жесткие ограничения на уровне токенов |
| Обработка границ | Часто возникают артефакты «склейки» | Естественный переход (семантический) |
| Рендеринг текста | Часто не удается | Точность около 99% |
| Многоэтапное редактирование | Накопление ошибок перекодирования | Почти без дрейфа качества |
| Сложные инструкции | Трудно добиться точной компоновки | Поддержка компоновки 100+ объектов |
| Скорость | Обычно 10–30 секунд | Примерно на 60% быстрее диффузии |
| Длинный текст | Сложно | Любой язык/скрипт |
Главная проблема диффузионных моделей заключается в потерях при перекодировании VAE — даже если теоретически области вне маски заблокированы, преобразование между латентным пространством и пикселями вносит микроскопические цветовые искажения. После многократного редактирования эти потери накапливаются, превращаясь в заметные глазу артефакты. GPT-Image-2 обходит эту проблему благодаря авторегрессионной архитектуре, где декодирование токенов происходит всего один раз.
Однако у авторегрессионного подхода есть своя цена. Стоимость генерации выше, в основном из-за большого количества токенов, каждый из которых требует полного прохода через Transformer. Мы рекомендуем использовать GPT-Image-2 (доступна через APIYI apiyi.com) для сценариев, где важна идеальная согласованность и качественный рендеринг текста, в то время как для высоконагруженных задач, чувствительных к стоимости, можно оставить серию Stable Diffusion в качестве дополнения.
Практика редактирования с GPT-Image-2: вызов API и оптимизация согласованности
Разобравшись с принципами редактирования в GPT-Image-2, давайте посмотрим, как эффективно использовать этот механизм на практике. Ниже представлен минимальный рабочий пример вызова интерфейса редактирования GPT-Image-2 через сервис-прокси APIYI:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
# Открываем исходное изображение
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Сохрани личность человека и фон без изменений, измени цвет верхней одежды с белого на темно-синий",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Обратите внимание на написание промпта: явно указывайте, что нужно сохранить, а что изменить. Это заставляет режим «мышления» (Thinking) GPT-Image-2 планировать генерацию именно так, как вы ожидаете. Если требуется точечное редактирование области, можно добавить параметр mask:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Измени белую одежду на темно-синий костюм",
size="1024x1024"
)
Маска — это PNG-файл того же размера, где белые области — это зоны, доступные для изменений, а черные — области, которые принудительно сохраняют токены исходного изображения.
5 практических советов по оптимизации согласованности
Основываясь на реальных тестах согласованности лиц и изображений, мы выделили 5 рекомендаций:
- Четко прописывайте в промпте, что нужно «сохранить»: не просто говорите «измени X», а «сохрани Y без изменений, измени X».
- Используйте умеренное разрешение эталонного изображения: OpenAI рекомендует, чтобы длинная сторона изображения не превышала 1024px; слишком большие файлы могут «размывать» внимание токенов.
- Используйте исходник как базу для всех итераций: не подавайте результат предыдущего редактирования на вход следующему. Лучше каждый раз редактировать оригинал, объединяя промпты.
- Разбивайте сложные задачи на этапы: вместо «замени человека на фон заката в японском стиле» сделайте два шага, меняя по одному параметру за раз.
- Выбирайте качество high: низкое качество уменьшает количество токенов, что напрямую снижает согласованность.
Баланс цены и качества в GPT-Image-2
| Комбинация параметров | Стоимость за фото | Сценарий использования |
|---|---|---|
| 1024×1024 low | $0.006 | Креативные наброски / быстрый превью |
| 1024×1024 medium | $0.053 | Контент для соцсетей |
| 1024×1024 high | $0.211 | Коммерческое редактирование / итерации |
| 4K high | $0.50+ | Печать / демонстрация в высоком разрешении |
Стоимость и согласованность напрямую связаны: режим высокого качества выделяет модели больше токенов, что позволяет сохранить больше деталей оригинала. Для продакшена мы рекомендуем использовать режим high, а с помощью Batch API на платформе APIYI (apiyi.com) можно дополнительно снизить затраты на 50%.
FAQ по принципам редактирования изображений и будущие тренды
Q1: GPT-Image-2 — это локальное редактирование как в Photoshop или перерисовка?
A: Это перерисовка. Все авторегрессионные модели изображений должны кодировать исходник в токены, затем генерировать полную последовательность выходных токенов и декодировать их в новое изображение. Даже с маской это лишь наложение ограничений в процессе перерисовки, а не простое наложение пикселей.
Q2: Если это перерисовка, почему отредактированное изображение выглядит почти идентично?
A: Благодаря четырехуровневому механизму согласованности: абстракция признаков визуальных токенов, глобальная ссылка на оригинал через Self-Attention, индуктивное смещение обучающих данных и явное планирование в режиме Thinking. Эти механизмы заставляют ИИ «активно выбирать» сохранение областей, которые не были упомянуты.
Q3: Считается ли inpainting в диффузионных моделях настоящим локальным изменением?
A: Нет. Inpainting в Stable Diffusion также прогоняет не замаскированные области через VAE-кодировщик/декодировщик, что приводит к микропотерям при перекодировании. Многократное редактирование накапливает артефакты — именно поэтому GPT-Image-2 перешли на авторегрессионный подход. Вы можете сравнить обе модели через APIYI (apiyi.com).
Q4: Почему GPT-Image-2 позволяет редактировать многократно без «дрейфа»?
A: Потому что авторегрессионная архитектура при каждой генерации обращается к полной последовательности токенов оригинала, без накопления ошибок итеративного удаления шума. В сочетании с планированием в режиме Thinking стабильность многократного редактирования намного выше, чем у диффузионных моделей.
Q5: Что лучше использовать: маску или только промпт?
A: Сначала пробуйте промпт с четкими инструкциями по сохранению — это задействует планирование Thinking. Маску стоит добавлять только тогда, когда границы изменений должны быть предельно точными (например, при работе с конкретными частями лица).
Q6: Как будет развиваться редактирование изображений ИИ?
A: Три тренда: (1) Повышение плотности информации в токенизаторах для снижения затрат; (2) Мультимодальное единство: текст, изображения и видео будут использовать один и тот же Transformer; (3) Усиление логического мышления (Thinking), поддержка длинных цепочек редактирования. Рекомендуем следить за обновлениями моделей на APIYI (apiyi.com).
Итог: понимание принципов — ключ к успеху
Авторегрессионные модели, такие как GPT-Image-2, меняют наше представление об «ИИ-редактировании». Это не Photoshop, а интеллектуальная перерисовка. Понимание того, как работают токены, Self-Attention и режим Thinking, поможет вам составлять эффективные промпты, избегать ошибок и находить баланс между ценой и качеством. Тестируйте возможности GPT-Image-2, Nano Banana и Stable Diffusion через единый интерфейс на APIYI (apiyi.com).
Статья подготовлена командой APIYI на основе официальных данных OpenAI, Google DeepMind и результатов собственных тестов. Для интеграции GPT-Image-2 в ваш проект посетите APIYI: apiyi.com.