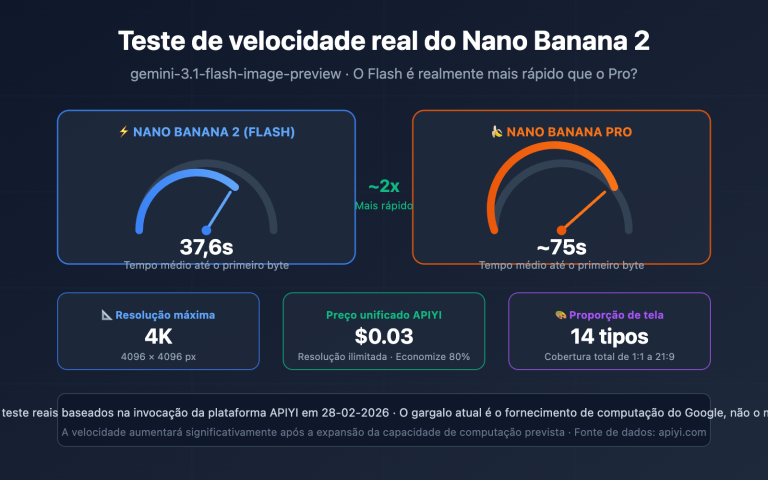
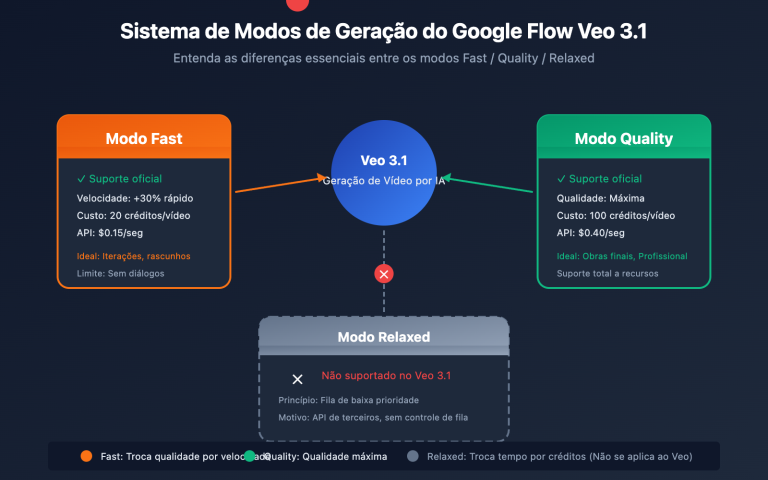
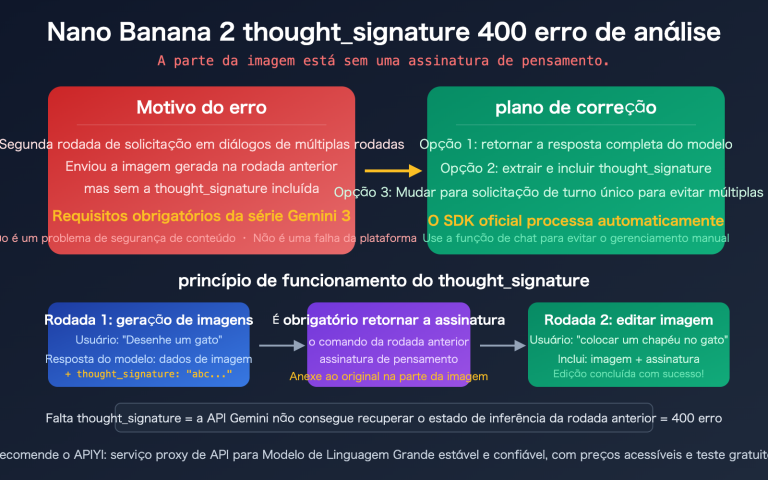
Em 19 de fevereiro de 2026, um grande número de desenvolvedores relatou que o modelo gemini-3-pro-image-preview estava retornando erros 503 de forma contínua — isso não é um problema com a sua conta, é uma sobrecarga nos servidores do Google. A mensagem de erro diz claramente: "This model is currently experiencing high demand" (Este modelo está enfrentando alta demanda no momento), e embora não gere cobranças, ele simplesmente não consegue gerar imagens.
O mais importante é que este não é um caso isolado. Desde o final de 2025, os modelos de imagem do Gemini passaram por várias sobrecargas semelhantes em horários de pico. Ao mesmo tempo, o gemini-2.5-flash-image de primeira geração (o modelo original Nano Banana Pro) e a série de texto do Gemini funcionam normalmente — o que indica que o problema está concentrado na alocação de poder computacional do Gemini 3 Pro Image.
Valor central: Ao terminar de ler este artigo, você dominará os métodos de diagnóstico do erro 503, conhecerá 5 modelos alternativos confiáveis e aprenderá uma arquitetura de tolerância a falhas (failover) automática para múltiplos modelos.

Análise completa do erro 503 no Gemini 3 Pro Image
O que o erro 503 realmente significa
Quando você recebe uma mensagem de erro como esta:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
Trata-se de um problema de capacidade do servidor, não um erro do cliente. Diferente do erro 429 (limite de cota pessoal), o 503 indica que o cluster de servidores de inferência alocado pelo Google para o modelo Gemini 3 Pro Image Preview está globalmente sobrecarregado, afetando todos os usuários.
Comparação: Erro 503 vs Outros erros comuns
| Código de Erro | Significado | É cobrado? | Escopo do impacto | Tempo de recuperação |
|---|---|---|---|---|
| 503 | Sobrecarga do servidor | ❌ Não | Global (todos os usuários) | 30-120 minutos |
| 429 | Cota pessoal esgotada | ❌ Não | Apenas conta atual | Aguardar reset da cota |
| 400 | Erro nos parâmetros | ❌ Não | Apenas requisição atual | Corrigir parâmetros |
| 500 | Erro interno do servidor | ❌ Não | Incerto | Geralmente minutos |
Por que o 503 ocorre com frequência?
O Gemini 3 Pro Image está atualmente em fase Preview, rodando em um pool compartilhado de servidores de inferência. De acordo com dados de monitoramento da comunidade, as taxas de erro 503 são mais altas nos seguintes períodos:
| Período (Horário de Pequim) | Taxa de Erro | Análise da Causa |
|---|---|---|
| 00:00 – 02:00 | Cerca de 35% | Pico do horário comercial na América do Norte |
| 09:00 – 11:00 | Cerca de 40% | Pico de testes matinais de desenvolvedores na Ásia-Pacífico |
| 20:00 – 23:00 | Cerca de 45% | Pico global acumulado |
| Outros horários | Cerca de 5-10% | Flutuação normal |
🎯 Dica prática: Se o seu negócio depende da geração de imagens por IA, confiar em apenas um modelo não é suficiente. Recomendamos utilizar a APIYI (apiyi.com) para acessar múltiplos modelos de imagem, permitindo a alternância automática em caso de falha e evitando que problemas pontuais parem sua operação.
5 Alternativas de Modelos de Geração de Imagem ao Gemini 3 Pro Image
Quando o Gemini 3 Pro Image não estiver disponível, estes 5 modelos podem servir como alternativas confiáveis.
Coração da Arquitetura: O Padrão de Disjuntor (Circuit Breaker)
O disjuntor (Circuit Breaker) rastreia a taxa de falha através de uma janela deslizante. Quando a taxa de erro ultrapassa um limite definido, ele alterna automaticamente para o modelo de reserva:
import openai
import time
# Configuração de tolerância a falhas multi-modelo
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI, uma única key para todos os modelos
)
def generate_with_fallback(prompt, models=MODELS):
"""Geração de imagem com tolerância a falhas multi-modelo"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[Failover] {model['name']} indisponível, alternando para o próximo modelo")
continue
raise e
return {"success": False, "error": "Todos os modelos estão indisponíveis"}
Ver código completo da implementação do disjuntor
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""Disjuntor de Modelo - Detecta falhas e alterna automaticamente"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 30% de taxa de falha ativa o disjuntor
self.window_size = window_size # Janela deslizante de 60 segundos
self.recovery_time = recovery_time # Tempo de espera para recuperação de 300 segundos
self.requests = deque()
self.state = "closed" # closed=normal, open=aberto (em falha), half_open=recuperando
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# Limpa registros expirados
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# Verifica taxa de falha
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open permite requisições de teste
class MultiModelImageGenerator:
"""Gerador de imagens com tolerância a falhas multi-modelo"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""Geração multi-modelo com disjuntor"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[Disjuntor Aberto] {name} está em modo de segurança, pulando")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[Sucesso] Geração concluída usando {name}")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[Falha] {name}: {e}")
continue
return {"success": False, "error": "Todos os modelos estão indisponíveis ou com disjuntor aberto"}
# Exemplo de uso
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("Um gato fofo tirando uma soneca ao sol")
if result["success"]:
print(f"Modelo utilizado: {result['model']}")
Sugestão de Prioridade para Alternância (Failover)
| Prioridade | Modelo | Motivo da Alternância | Estratégia de Recuperação |
|---|---|---|---|
| Principal | Gemini 3 Pro Image | Melhor qualidade | Recuperação automática após passar no teste de saúde |
| Reserva 1 | Gemini 2.5 Flash Image | Mesmo ecossistema, mais rápido | Rebaixar após o principal recuperar |
| Reserva 2 | Seedream 4.5 | Qualidade próxima, forte em texto | Rebaixar após o principal recuperar |
| Reserva 3 | GPT Image 1.5 | Maior capacidade geral | Rebaixar após o principal recuperar |
| Reserva 4 | FLUX 2 Pro | Ótimo custo-benefício, controlado | Rebaixar após o principal recuperar |
💡 Dica de Arquitetura: Através da interface unificada da APIYI (apiyi.com), você precisa de apenas uma API Key para chamar todos os modelos acima. Isso elimina a necessidade de integrar individualmente com diferentes fornecedores, reduzindo drasticamente o custo de implementação de tolerância a falhas multi-modelo.
C 端产品可用状态展示方案
对于面向终端用户的产品,当模型不可用时,前端应有清晰的状态展示。这是兜底方案,平时用不着,但关键时刻能大幅降低用户投诉和流失。
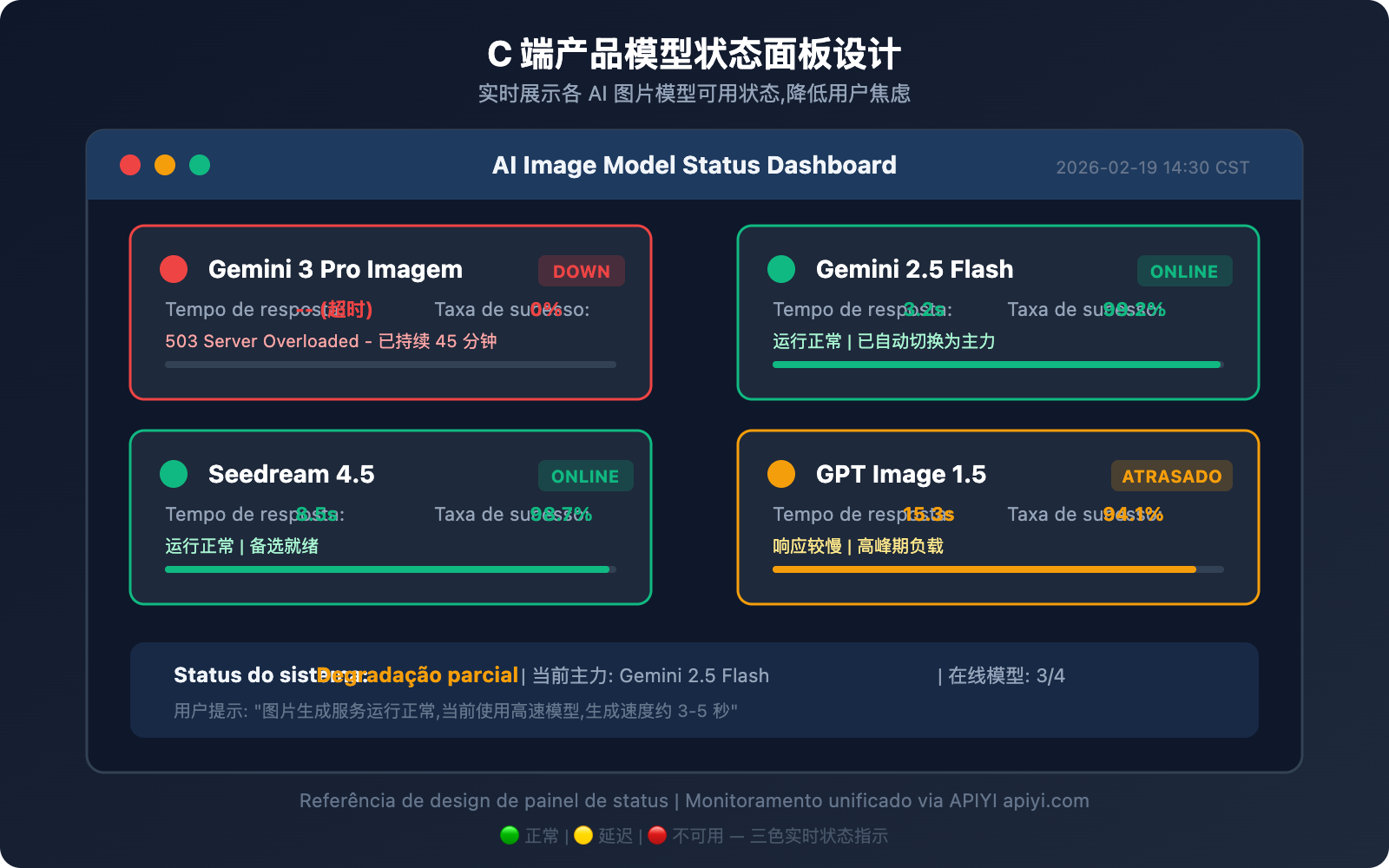
状态展示设计要点
三色状态指示:
- 🟢 正常: 模型可用,响应时间正常
- 🟡 延迟: 模型可用但响应变慢(超过正常值 2 倍)
- 🔴 不可用: 模型返回 503 或连续失败
前端展示建议:
// 模型状态检查 API 调用示例
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
用户体验优化策略
| 策略 | 说明 | 实现方式 |
|---|---|---|
| 实时状态页 | 在产品页面展示各模型可用状态 | 定时轮询 + WebSocket 推送 |
| 自动模型切换 | 用户无感知的后端模型切换 | 熔断器 + 优先级队列 |
| 排队提示 | 高峰期显示排队位置和预计等待时间 | 请求队列 + 进度推送 |
| 降级说明 | 告知用户当前使用的是备选模型 | 前端 Toast 提示 |
💰 成本与体验兼顾: 通过 APIYI apiyi.com 平台,你可以用统一的接口实现以上所有状态检查和模型切换逻辑,无需维护多套 SDK 和认证体系。
Fluxo de tratamento de emergência para erro 503 no Gemini 3 Pro Image
Ao encontrar um erro 503, siga este fluxo de resolução:
Passo 1: Confirmar o tipo de erro
- Verifique se a mensagem de erro contém
high demandouupstream_error. - Confirme se é um erro 503 e não um 429 (cota excedida) ou 400 (parâmetros inválidos).
Passo 2: Avaliar o alcance do impacto
- Verifique se o Gemini 2.5 Flash Image está funcionando normalmente (geralmente não é afetado).
- Verifique se os modelos de texto do Gemini estão normais (geralmente não são afetados).
- Se todos os modelos apresentarem anomalias, pode ser uma falha mais ampla do GCP (Google Cloud Platform).
Passo 3: Iniciar a alternância para redundância (Failover)
- Se você já tiver um disjuntor (circuit breaker) implementado: o sistema alternará automaticamente, sem necessidade de intervenção manual.
- Se não tiver: altere manualmente o parâmetro
modelpara um modelo alternativo.
Passo 4: Monitorar a recuperação
- Os erros 503 do Gemini 3 Pro Image costumam ser resolvidos em 30 a 120 minutos.
- Após a recuperação, recomenda-se realizar testes em pequena escala para confirmar a estabilidade antes de voltar totalmente ao modelo original.
🚀 Recuperação rápida: Recomendamos utilizar a interface unificada da plataforma APIYI (apiyi.com) para realizar a alternância de redundância. Não é necessário alterar a
base_urlno seu código; basta trocar o parâmetromodelpara alternar entre diferentes modelos de forma transparente.
Perguntas Frequentes
P1: O erro 503 no Gemini 3 Pro Image gera cobrança?
Não. O erro 503 indica que a requisição não foi processada pelo servidor, portanto, não gera nenhum custo. Isso difere de uma resposta de sucesso 200 — apenas requisições que geram imagens com sucesso são faturadas. Ao utilizar a plataforma APIYI (apiyi.com), essa regra também se aplica: requisições falhas não são cobradas.
P2: Quanto tempo dura o erro 503? O uso de modelos alternativos aumenta muito o custo?
Com base em dados históricos, os erros 503 do Gemini 3 Pro Image costumam durar entre 30 e 120 minutos. A diferença de custo para modelos alternativos é pequena: Seedream 4.5 custa cerca de $0,04/imagem, GPT Image 1.5 entre $0,04 e $0,12/imagem, e FLUX 2 Pro cerca de $0,03/imagem. Através da chamada unificada da APIYI (apiyi.com), você consegue preços mais competitivos e o custo de transição é praticamente zero.
P3: Como saber se o 503 é uma sobrecarga temporária ou uma falha prolongada?
Observe dois indicadores: primeiro, veja se o Gemini 2.5 Flash Image (do mesmo ecossistema) está funcionando (se estiver, a sobrecarga é local); segundo, verifique a página de status oficial do Google em status.cloud.google.com. Se o problema persistir por mais de 2 horas sem um comunicado oficial, recomendamos mudar para um modelo alternativo como sua opção principal temporariamente.
P4: A complexidade de implementar uma arquitetura de redundância multi-modelo é alta?
Se você for integrar a API de cada fornecedor individualmente, sim, é complexo — você precisaria manter vários SDKs, chaves de autenticação e sistemas de faturamento. No entanto, usando uma plataforma de interface unificada como a APIYI (apiyi.com), todos os modelos compartilham a mesma base_url e API Key. A alternância para redundância exige apenas a alteração do parâmetro model, tornando a implementação extremamente simples.
Resumo: Construindo um serviço de geração de imagens por IA à prova de falhas
Erros 503 no Gemini 3 Pro Image são comuns na fase Preview; o segredo é preparar planos de contingência com múltiplos modelos antecipadamente:
- Não dependa de um único modelo: Mesmo o Google não garante 100% de disponibilidade para modelos em Preview.
- Priorize o downgrade dentro do mesmo ecossistema: O Gemini 2.5 Flash Image é a primeira escolha de baixo custo como alternativa imediata.
- Reserva de múltiplos modelos de diferentes fornecedores: Seedream 4.5, GPT Image 1.5 e FLUX 2 Pro — cada um tem seus pontos fortes.
- Implemente uma arquitetura de recuperação de desastres automática: O padrão Circuit Breaker (disjuntor) permite a troca automática sem intervenção humana.
- Exiba o status para o usuário final: Informações de status transparentes retêm mais usuários do que um silêncio de espera frustrante.
Recomendamos usar o APIYI (apiyi.com) para validar rapidamente soluções de tolerância a falhas multi-modelo — interface unificada, uma única chave e troca de modelos a qualquer momento.
Referências
-
Fórum de Desenvolvedores do Google AI: Discussão sobre erros 503 no Gemini 3 Pro Image
- Link:
discuss.ai.google.dev - Descrição: Feedback da comunidade e respostas oficiais do Google.
- Link:
-
Página de Status do Google AI Studio: Status do serviço em tempo real
- Link:
aistudio.google.com/status - Descrição: Verifique o status de disponibilidade em tempo real de cada modelo.
- Link:
-
Página oficial do Seedream 4.5: Modelo de geração de imagens da ByteDance
- Link:
seed.bytedance.com/en/seedream4_5 - Descrição: Capacidades do modelo e documentação da API.
- Link:
-
Documentação do OpenAI GPT Image 1.5: Modelo de geração de imagens mais recente
- Link:
platform.openai.com/docs/models/gpt-image-1.5 - Descrição: Parâmetros do modelo e informações de preços.
- Link:
📝 Autor: APIYI Team | Para troca de conhecimentos técnicos, visite APIYI apiyi.com
📅 Data de atualização: 19 de fevereiro de 2026
🏷️ Palavras-chave: Erro 503 Gemini 3 Pro Image, alternativas multi-modelo para geração de imagens por IA, arquitetura de recuperação de desastres, Seedream 4.5, GPT Image 1.5