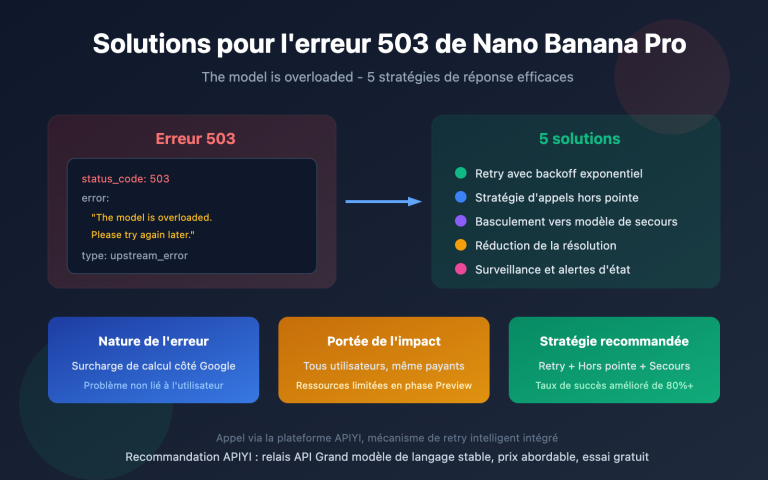
Le 19 février 2026, de nombreux développeurs ont signalé que le modèle gemini-3-pro-image-preview renvoyait systématiquement des erreurs 503 — ce n'est pas un problème lié à votre compte, mais une surcharge des serveurs du côté de Google. Le message d'erreur indique clairement : « This model is currently experiencing high demand » (Ce modèle fait actuellement l'objet d'une forte demande). Aucune facturation n'est générée, mais il est totalement impossible de produire des images.
Plus important encore, ce n'est pas un cas isolé. Depuis fin 2025, les modèles d'image Gemini ont connu plusieurs surcharges similaires lors des pics d'utilisation. Au même moment, la première génération gemini-2.5-flash-image (le modèle initial Nano Banana Pro) et la série textuelle Gemini fonctionnent normalement — ce qui prouve que le problème se concentre sur l'allocation des ressources de calcul de Gemini 3 Pro Image.
Valeur ajoutée : En lisant cet article, vous apprendrez à diagnostiquer les erreurs 503, découvrirez 5 modèles d'image alternatifs fiables et maîtriserez une architecture de basculement automatique multi-modèles prête à l'emploi.
Analyse complète de l'erreur 503 de Gemini 3 Pro Image
Que signifie réellement l'erreur 503 ?
Lorsque vous recevez le message d'erreur suivant :
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
Il s'agit d'un problème de capacité côté serveur, et non d'une erreur client. Contrairement à l'erreur 429 (limite de quota personnel), la 503 indique que le cluster de serveurs d'inférence alloué par Google pour le modèle Gemini 3 Pro Image Preview est globalement surchargé. Tous les utilisateurs sont alors impactés.
Comparaison : Erreur 503 vs autres erreurs courantes
| Code d'erreur | Signification | Facturé ? | Portée de l'impact | Temps de rétablissement |
|---|---|---|---|---|
| 503 | Surcharge serveur | ❌ Non | Tous les utilisateurs | 30-120 minutes |
| 429 | Quota personnel épuisé | ❌ Non | Compte actuel uniquement | Attendre le refresh du quota |
| 400 | Paramètres invalides | ❌ Non | Requête actuelle uniquement | Modifier les paramètres |
| 500 | Erreur interne serveur | ❌ Non | Incertain | Généralement quelques minutes |
Pourquoi l'erreur 503 est-elle si fréquente ?
Gemini 3 Pro Image est actuellement en phase Preview et fonctionne sur un pool de serveurs d'inférence partagé. Selon les données de surveillance de la communauté, les taux d'erreur 503 sont les plus élevés durant ces créneaux (heure de Pékin) :
| Créneau (Heure de Pékin) | Taux d'erreur | Analyse de la cause |
|---|---|---|
| 00:00 – 02:00 | Env. 35% | Pic des heures de bureau en Amérique du Nord |
| 09:00 – 11:00 | Env. 40% | Pic des tests matinaux des développeurs en Asie-Pacifique |
| 20:00 – 23:00 | Env. 45% | Pic de superposition mondiale |
| Autres créneaux | Env. 5-10% | Fluctuations normales |
🎯 Conseil pratique : Si votre activité dépend de la génération d'images par IA, s'appuyer sur un seul modèle ne suffit pas. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour accéder à plusieurs modèles d'image, permettant ainsi un basculement automatique en cas de panne et évitant qu'un point de défaillance unique ne paralyse votre service.
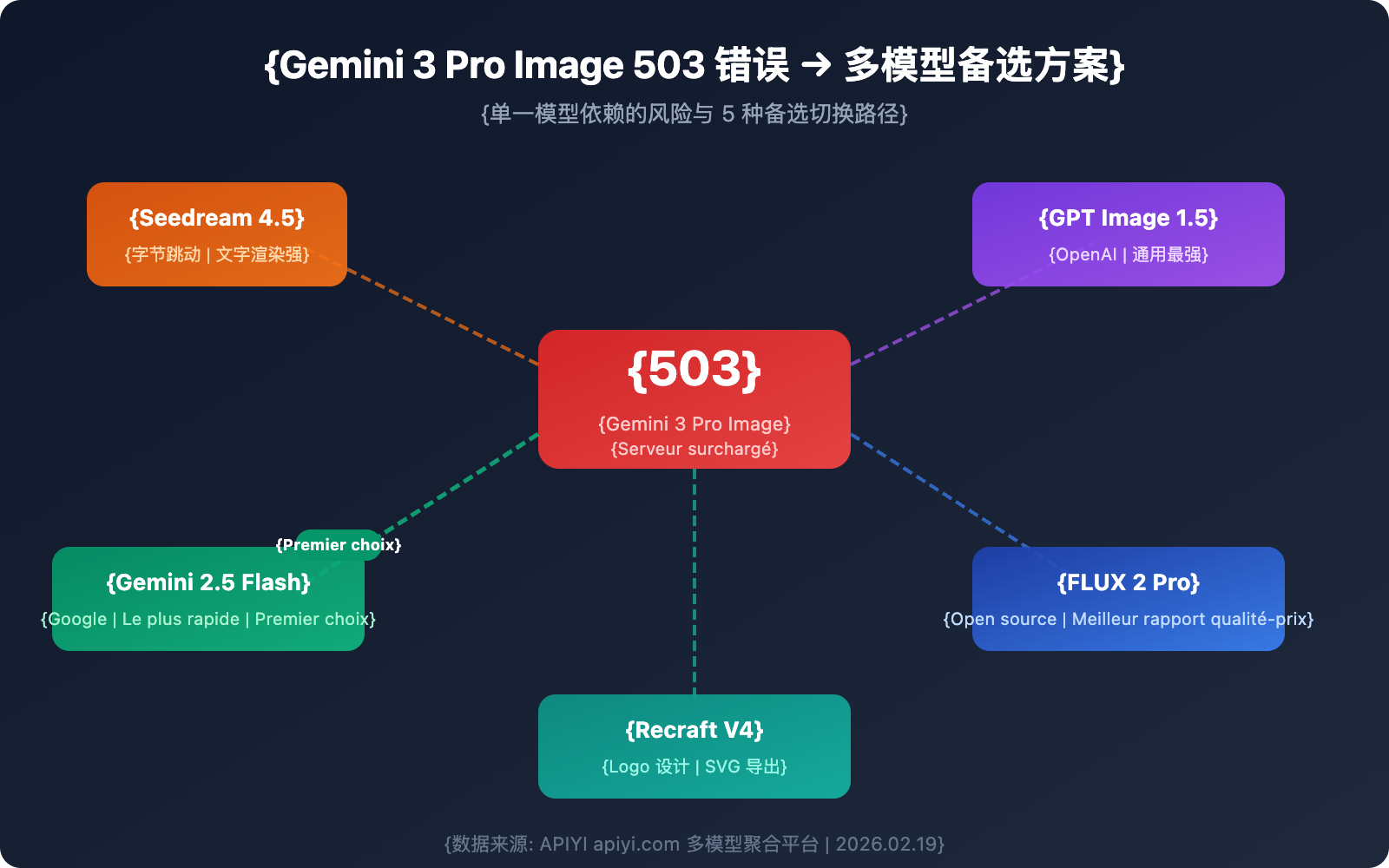
5 alternatives au modèle de génération d'images Gemini 3 Pro
Lorsque Gemini 3 Pro Image n'est pas disponible, ces 5 modèles constituent des solutions de rechange fiables.

Alternative 1 : Seedream 4.5 (ByteDance)
Seedream 4.5 est le modèle de génération d'images lancé par ByteDance. Il occupe la 10e place du classement LM Arena avec un score de 1147.
Atouts majeurs :
- Rendu du texte exceptionnel : Capable de générer du texte lisible et précis dans les images, idéal pour les supports marketing et les affiches.
- Sortie haute résolution : Supporte jusqu'à 2048×2048 pixels, atteignant le niveau 4K.
- Forte cohérence : Les détails des personnages, des objets et de l'environnement restent constants sur plusieurs images.
- Esthétique cinématographique : Les couleurs et la composition sont proches d'un rendu photographique professionnel.
Cas d'utilisation : Photos de produits e-commerce, visuels de marque, images nécessitant un rendu textuel précis.
À surveiller : La sortie de Seedream 5.0 est prévue pour le 24 février 2026. Elle devrait intégrer la recherche web, l'édition par l'exemple et des capacités de raisonnement logique.
Alternative 2 : GPT Image 1.5 (OpenAI)
Dernier modèle de génération d'images d'OpenAI publié en décembre 2025, c'est actuellement l'un des modèles de texte-vers-image les plus puissants pour un usage général.
Atouts majeurs :
- Édition précise : Permet de modifier précisément des parties spécifiques d'une image téléchargée sans altérer les autres éléments.
- Richesse des connaissances mondiales : Capable de déduire des détails de scène selon le contexte (par exemple, l'invite « Bethel, New York, 1969 » permet de déduire le festival de Woodstock).
- Rendu du texte net : Typographie précise et contraste élevé.
- Vitesse accrue : 4 fois plus rapide que GPT Image 1.0.
Prix : Entre 0,04 $ et 0,12 $ par image (selon les paramètres de qualité), soit environ 20 % moins cher que GPT Image 1.0.
Alternative 3 : FLUX 2 Pro (Black Forest Labs)
La série FLUX est la référence dans le domaine de la génération d'images open-source. FLUX 2 Pro offre un excellent équilibre entre qualité et rapport qualité-prix.
Atouts majeurs :
- Rapport qualité-prix imbattable : Environ 0,03 $ par image, c'est l'option de haute qualité la plus économique.
- Écosystème open-source complet : Possibilité de déploiement privé pour garantir la sécurité des données.
- Communauté active : De nombreux modèles affinés (fine-tuned) et LoRA sont disponibles.
- Adapté au traitement par lots : Idéal pour les tâches de génération d'images à grande échelle.
Cas d'utilisation : Production de contenu en masse, projets à budget limité, entreprises nécessitant un déploiement privé.
Alternative 4 : Gemini 2.5 Flash Image (Première génération de Nano Banana Pro)
Bien qu'appartenant à l'écosystème Google, son architecture est différente. Ainsi, lorsque Gemini 3 Pro Image subit une panne, ce modèle reste généralement opérationnel.
Atouts majeurs :
- Vitesse fulgurante : Environ 3 à 5 secondes par image, bien plus rapide que les autres modèles.
- Haute stabilité : En phase Preview, la charge serveur est plus faible ; les erreurs 503 sont généralement résolues en 5 à 15 minutes.
- Complémentaire à Gemini 3 : Architecture indépendante, évitant les points de défaillance uniques.
- Faible coût : Tarification avantageuse, adaptée aux appels fréquents.
Cas d'utilisation : Applications en temps réel exigeant de la rapidité, solution de repli prioritaire pour Gemini 3.
Alternative 5 : Recraft V4
Classé premier dans les benchmarks HuggingFace, Recraft V4 excelle particulièrement dans la création de logos et le design de marque.
Atouts majeurs :
- Le meilleur pour les logos : Reconnu comme le numéro 1 de la génération de logos par IA en 2026.
- Export SVG supporté : Génère des graphiques vectoriels redimensionnables à l'infini.
- Outils de style de marque : Palettes de couleurs intégrées et contrôle de la cohérence stylistique.
- Rendu de niveau design professionnel : Adapté aux usages commerciaux et de design officiels.
Cas d'utilisation : Création de logos, identité visuelle de marque, besoins en format vectoriel.
Comparaison synthétique des 5 alternatives
| Modèle | Vitesse | Qualité | Prix | Rendu du texte | Stabilité | Plateformes disponibles |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~0,04 $/img | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com, etc. |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 0,04-0,12 $/img | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com, etc. |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~0,03 $/img | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com, etc. |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Très bas | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com, etc. |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~0,04 $/img | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com, etc. |
Conception d'une architecture de reprise après sinistre multi-modèles
Il ne suffit pas de connaître les alternatives ; un véritable environnement de production nécessite un mécanisme de basculement (failover) automatisé. Voici une architecture de reprise après sinistre multi-modèles éprouvée.
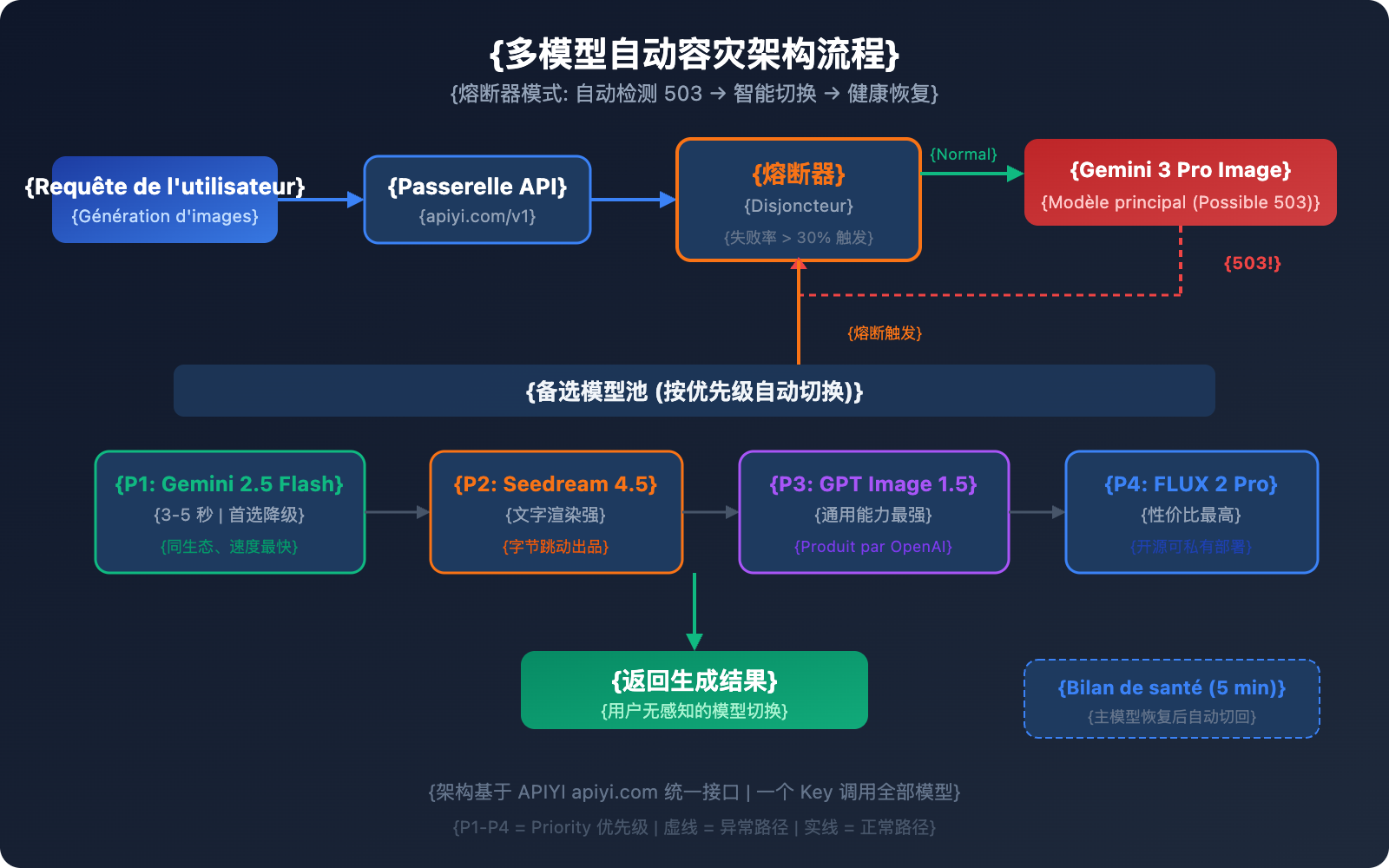
Cœur de l'architecture : Le pattern Disjoncteur (Circuit Breaker)
Le disjoncteur suit le taux d'échec via une fenêtre glissante. Lorsque le taux de défaillance dépasse un seuil défini, il bascule automatiquement vers les modèles de secours :
import openai
import time
# Configuration de la reprise après sinistre multi-modèles
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI, une seule clé pour tous les modèles
)
def generate_with_fallback(prompt, models=MODELS):
"""Génération d'images avec reprise après sinistre multi-modèles"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[Failover] {model['name']} indisponible, passage au modèle suivant")
continue
raise e
return {"success": False, "error": "Aucun modèle n'est disponible"}
Voir le code complet de l’implémentation du disjoncteur
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""Disjoncteur de modèle - Détection automatique des pannes et basculement"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # Seuil de 30% d'échec pour déclencher
self.window_size = window_size # Fenêtre glissante de 60 secondes
self.recovery_time = recovery_time # Attente de 300 secondes avant récupération
self.requests = deque()
self.state = "closed" # closed=normal, open=ouvert (coupé), half_open=en récupération
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# Nettoyage des anciens enregistrements
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# Vérification du taux d'échec
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open autorise des requêtes de test
class MultiModelImageGenerator:
"""Générateur d'images multi-modèles avec reprise après sinistre"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""Génération multi-modèles avec disjoncteurs"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[Coupé] {name} est en mode disjoncteur, ignoré")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[Succès] Génération terminée avec {name}")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[Échec] {name}: {e}")
continue
return {"success": False, "error": "Tous les modèles sont indisponibles ou coupés"}
# Exemple d'utilisation
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("Un chat mignon faisant la sieste au soleil")
if result["success"]:
print(f"Modèle utilisé : {result['model']}")
Suggestions de priorité pour le basculement
| Priorité | Modèle | Raison du basculement | Stratégie de récupération |
|---|---|---|---|
| Principal | Gemini 3 Pro Image | Qualité optimale | Récupération auto après test de santé |
| Secours Niv. 1 | Gemini 2.5 Flash Image | Même écosystème, plus rapide | Rétrogradation après retour du principal |
| Secours Niv. 2 | Seedream 4.5 | Qualité proche, excellent rendu de texte | Rétrogradation après retour du principal |
| Secours Niv. 3 | GPT Image 1.5 | Capacité polyvalente maximale | Rétrogradation après retour du principal |
| Secours Niv. 4 | FLUX 2 Pro | Bon rapport qualité/prix, contrôlable | Rétrogradation après retour du principal |
💡 Conseil d'architecture : En utilisant l'interface unifiée d'APIYI (apiyi.com), vous n'avez besoin que d'une seule clé API pour appeler tous ces modèles. Pas besoin de gérer plusieurs fournisseurs séparément, ce qui réduit considérablement les coûts d'intégration d'une solution multi-modèles.
Solution d'affichage de l'état de disponibilité pour les produits Grand Public (C-end)
Pour les produits destinés aux utilisateurs finaux, il est crucial que le frontend affiche clairement l'état lorsque le modèle est indisponible. C'est une solution de secours (fallback) ; on espère ne jamais en avoir besoin, mais elle permet de réduire considérablement les plaintes et le taux de désabonnement lors des moments critiques.

Points clés de la conception de l'affichage de l'état
Indicateurs d'état tricolores :
- 🟢 Normal : Le modèle est disponible, le temps de réponse est habituel.
- 🟡 Latence : Le modèle est disponible mais la réponse est lente (plus de 2 fois la valeur normale).
- 🔴 Indisponible : Le modèle renvoie une erreur 503 ou échoue de manière répétée.
Suggestions d'affichage frontend :
// Exemple d'appel API pour vérifier l'état du modèle
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
Stratégies d'optimisation de l'expérience utilisateur
| Stratégie | Description | Mise en œuvre |
|---|---|---|
| Page d'état en temps réel | Afficher l'état de disponibilité de chaque modèle sur la page produit. | Interrogation périodique (polling) + Push WebSocket |
| Basculement automatique | Changement de modèle côté backend invisible pour l'utilisateur. | Disjoncteur (Circuit Breaker) + File d'attente prioritaire |
| Indicateur de file d'attente | Afficher la position et le temps d'attente estimé pendant les pics. | File d'attente de requêtes + Push de progression |
| Note de dégradation | Informer l'utilisateur qu'un modèle alternatif est actuellement utilisé. | Notification Toast en frontend |
💰 Équilibre entre coût et expérience : Grâce à la plateforme APIYI (apiyi.com), vous pouvez implémenter toute la logique de vérification d'état et de basculement de modèle avec une interface unifiée, sans avoir à maintenir plusieurs SDK et systèmes d'authentification.
Procédure d'urgence pour l'erreur 503 de Gemini 3 Pro Image
En cas d'erreur 503, suivez cette procédure :
Étape 1 : Confirmer le type d'erreur
- Vérifiez si le message d'erreur contient
high demandouupstream_error. - Confirmez qu'il s'agit bien d'une 503 et non d'une 429 (quota dépassé) ou d'une 400 (paramètres incorrects).
Étape 2 : Évaluer l'étendue de l'impact
- Vérifiez si Gemini 2.5 Flash Image fonctionne normalement (généralement non affecté).
- Vérifiez si les modèles de texte Gemini fonctionnent (généralement non affectés).
- Si tous les modèles sont en panne, il s'agit probablement d'une panne GCP (Google Cloud Platform) plus large.
Étape 3 : Activer le basculement de secours (Failover)
- Si un disjoncteur (circuit breaker) est déployé : le système bascule automatiquement, aucune intervention manuelle n'est nécessaire.
- Si aucun n'est déployé : modifiez manuellement le paramètre
modelpour utiliser un modèle de secours.
Étape 4 : Surveiller le rétablissement
- Les erreurs 503 de Gemini 3 Pro Image sont généralement résolues en 30 à 120 minutes.
- Une fois le service rétabli, il est conseillé d'effectuer des tests sur un petit volume avant de rebasculer complètement.
🚀 Rétablissement rapide : Nous vous recommandons d'utiliser l'interface unifiée de la plateforme APIYI (apiyi.com) pour vos basculements de secours. Pas besoin de modifier l'URL de base (
base_url) dans votre code, il suffit de changer le paramètremodelpour passer d'un modèle à l'autre en toute fluidité.
Questions Fréquentes
Q1 : L’erreur 503 de Gemini 3 Pro Image est-elle facturée ?
Non. Une erreur 503 signifie que la requête n'a pas été traitée par le serveur, elle ne génère donc aucun frais. C'est différent d'une réponse 200 réussie : seules les requêtes ayant généré une image avec succès sont facturées. Cette règle s'applique également lors de l'utilisation de la plateforme APIYI (apiyi.com) ; les requêtes échouées ne sont pas décomptées.
Q2 : Combien de temps dure une erreur 503 ? Quel est le surcoût lié à l’utilisation d’un modèle de secours ?
D'après les données historiques, les erreurs 503 de Gemini 3 Pro Image durent généralement entre 30 et 120 minutes. La différence de coût avec les modèles de secours est minime : Seedream 4.5 coûte environ 0,04 $/image, GPT Image 1.5 environ 0,04-0,12 $/image, et FLUX 2 Pro environ 0,03 $/image. En passant par l'interface unifiée d'APIYI (apiyi.com), vous bénéficiez de tarifs avantageux et le coût de transition est quasi nul.
Q3 : Comment savoir si la 503 est une surcharge temporaire ou une panne prolongée ?
Observez deux indicateurs : d'abord, vérifiez si Gemini 2.5 Flash Image (du même écosystème) fonctionne (si oui, c'est une surcharge locale) ; ensuite, consultez la page d'état officielle de Google sur status.cloud.google.com. Si le service n'est pas rétabli après 2 heures et qu'il n'y a pas d'annonce officielle, il est conseillé de passer activement sur un modèle de secours comme solution principale.
Q4 : L’intégration d’une architecture multi-modèles pour la tolérance aux pannes est-elle complexe ?
Si vous vous connectez séparément aux API de chaque fournisseur, c'est effectivement complexe : il faut gérer plusieurs SDK, clés d'authentification et systèmes de facturation. En revanche, via une plateforme d'interface unifiée comme APIYI (apiyi.com), tous les modèles partagent la même base_url et la même clé API. Le basculement ne nécessite que la modification du paramètre model, ce qui rend l'intégration extrêmement simple.
Résumé : Construire un service de génération d'images IA résistant aux pannes
L'erreur 503 de Gemini 3 Pro Image est monnaie courante durant la phase Preview. La clé est de prévoir des solutions de secours multi-modèles à l'avance :
- Ne dépendez pas d'un seul modèle : même Google ne peut garantir une disponibilité à 100 % pour ses modèles en phase Preview.
- Privilégiez le repli au sein du même écosystème : Gemini 2.5 Flash Image est l'option de secours la plus économique et la plus rapide.
- Constituez une réserve multi-fournisseurs : Seedream 4.5, GPT Image 1.5 et FLUX 2 Pro ont chacun leurs points forts.
- Déployez une architecture de tolérance aux pannes : utilisez le modèle "Circuit Breaker" (disjoncteur) pour un basculement automatique sans intervention humaine.
- Soignez l'affichage d'état côté client : une information transparente sur l'état du service est bien plus efficace pour retenir l'utilisateur qu'une attente silencieuse.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement vos solutions de secours : une interface unique, une seule clé API et une multitude de modèles prêts à prendre le relais.
Ressources
-
Forum des développeurs Google AI : Discussions sur l'erreur 503 de Gemini 3 Pro Image
- Lien :
discuss.ai.google.dev - Description : Retours de la communauté et réponses officielles de Google.
- Lien :
-
Page d'état de Google AI Studio : État du service en temps réel
- Lien :
aistudio.google.com/status - Description : Pour vérifier la disponibilité réelle de chaque modèle.
- Lien :
-
Page officielle de Seedream 4.5 : Modèle de génération d'images de ByteDance
- Lien :
seed.bytedance.com/en/seedream4_5 - Description : Capacités du modèle et documentation API.
- Lien :
-
Documentation OpenAI GPT Image 1.5 : Le dernier modèle de génération d'images
- Lien :
platform.openai.com/docs/models/gpt-image-1.5 - Description : Paramètres du modèle et informations tarifaires.
- Lien :
📝 Auteur : Équipe APIYI | Pour toute discussion technique, visitez APIYI apiyi.com
📅 Dernière mise à jour : 19 février 2026
🏷️ Mots-clés : Erreur Gemini 3 Pro Image 503, solutions de secours multi-modèles IA, architecture de tolérance aux pannes, Seedream 4.5, GPT Image 1.5