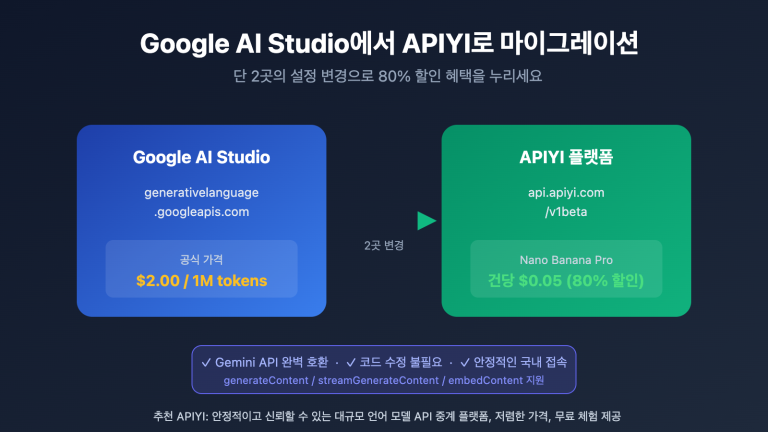
2026년 2월 19일, 많은 개발자들이 gemini-3-pro-image-preview 모델에서 503 오류가 계속 발생한다고 보고했습니다. 이건 여러분의 계정 문제가 아니라, 구글 측 서버 과부하 때문이에요. 오류 메시지에는 「This model is currently experiencing high demand」라고 명확히 적혀 있으며, 비용은 청구되지 않지만 이미지 생성도 전혀 되지 않는 상황입니다.
더 중요한 건 이게 일회성 사건이 아니라는 점입니다. 2025년 말부터 지금까지 Gemini 이미지 모델은 피크 시간대에 여러 번 과부하가 발생했습니다. 같은 시간대에 1세대 gemini-2.5-flash-image(즉, Nano Banana Pro 초기 모델)와 Gemini 텍스트 시리즈는 정상 작동했습니다. 이는 문제가 Gemini 3 Pro Image의 연산 자원 배분에 집중되어 있음을 보여줍니다.
핵심 가치: 이 글을 다 읽고 나면 503 오류 해결 방법, 믿을 만한 5가지 대체 이미지 생성 모델, 그리고 실제로 적용 가능한 다중 모델 자동 장애 복구(Failover) 아키텍처를 마스터하게 될 거예요.
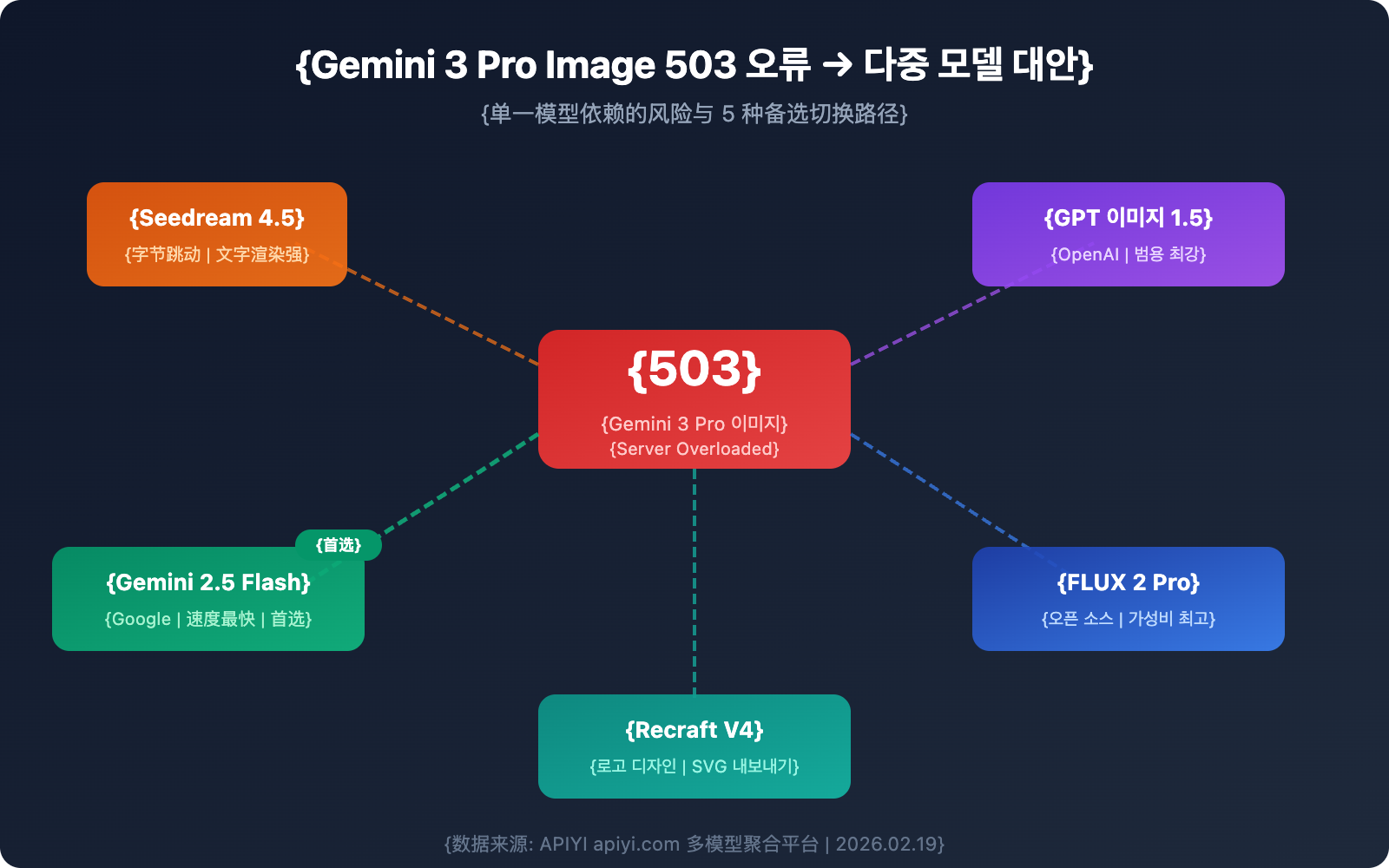
Gemini 3 Pro Image 503 오류 완전 분석
503 오류는 정확히 무엇을 의미하나요?
다음과 같은 오류 메시지를 받았다면:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
이것은 서버 측 용량 문제이며, 클라이언트 오류가 아닙니다. 429 오류(개인 할당량 제한)와 달리, 503은 구글이 Gemini 3 Pro Image Preview 모델에 할당한 추론 서버 클러스터가 전체적으로 과부하 상태임을 나타내며, 모든 사용자에게 영향을 미칩니다.
503 오류 vs 기타 일반 오류 비교
| 오류 코드 | 의미 | 과금 여부 | 영향 범위 | 복구 시간 |
|---|---|---|---|---|
| 503 | 서버 과부하 | ❌ 미과금 | 전역 모든 사용자 | 30-120분 |
| 429 | 개인 할당량 소진 | ❌ 미과금 | 현재 계정만 해당 | 할당량 갱신 대기 |
| 400 | 요청 파라미터 오류 | ❌ 미과금 | 현재 요청만 해당 | 파라미터 수정 즉시 |
| 500 | 내부 서버 오류 | ❌ 미과금 | 불확실 | 보통 수 분 내 |
왜 503 오류가 빈번하게 발생하나요?
Gemini 3 Pro Image는 현재 Preview 단계에 있으며, 공유 추론 서버 풀에서 실행됩니다. 커뮤니티 모니터링 데이터에 따르면, 다음 시간대에 503 오류 발생률이 가장 높습니다.
| 시간대 (한국 시간) | 오류율 | 원인 분석 |
|---|---|---|
| 01:00 – 03:00 | 약 35% | 북미 업무 시간 피크 |
| 10:00 – 12:00 | 약 40% | 아시아 태평양 개발자 오전 테스트 피크 |
| 21:00 – 00:00 | 약 45% | 전 세계 중첩 피크 |
| 기타 시간대 | 약 5-10% | 일반적인 변동 |
🎯 실전 제언: 비즈니스가 AI 이미지 생성에 의존하고 있다면, 단일 모델에만 의존하는 것은 위험합니다. APIYI(apiyi.com)를 통해 다양한 이미지 모델을 연결하고, 자동 장애 복구 전환을 구현하여 단일 장애점이 비즈니스에 영향을 주지 않도록 하는 것을 추천합니다.
Gemini 3 Pro Image를 대체할 수 있는 5가지 이미지 생성 모델
Gemini 3 Pro Image를 사용할 수 없을 때, 다음 5가지 모델이 신뢰할 수 있는 대안이 될 수 있습니다.

대안 1: Seedream 4.5 (바이트댄스)
Seedream 4.5는 바이트댄스(ByteDance)에서 출시한 이미지 생성 모델로, LM Arena 랭킹 10위(1147점)를 기록하고 있는 강력한 모델입니다.
핵심 장점:
- 뛰어난 텍스트 렌더링: 이미지 내에 읽을 수 있는 텍스트를 정확하게 생성하여 마케팅 자료나 포스터 제작에 적합합니다.
- 고해상도 출력: 2048×2048 픽셀을 지원하여 4K급 화질을 제공합니다.
- 높은 일관성: 여러 장의 이미지 사이에서도 캐릭터, 사물, 환경의 디테일이 일정하게 유지됩니다.
- 시네마틱한 미학: 전문 사진 수준의 색감과 구도를 보여줍니다.
활용 시나리오: 이커머스 제품 이미지, 브랜드 마케팅 소재, 정확한 텍스트 포함이 필요한 이미지
참고: 2026년 2월 24일 출시 예정인 Seedream 5.0에서는 웹 검색, 예시 편집 및 논리적 추론 능력이 추가될 예정입니다.
대안 2: GPT Image 1.5 (OpenAI)
2025년 12월에 발표된 OpenAI의 최신 이미지 생성 모델로, 현재 범용 시나리오에서 가장 강력한 텍스트-투-이미지(Text-to-Image) 모델 중 하나입니다.
핵심 장점:
- 정밀한 편집: 이미지를 업로드한 후 다른 요소는 건드리지 않고 특정 부분만 정교하게 수정할 수 있습니다.
- 풍부한 배경 지식: 문맥을 통해 장면의 디테일을 추론합니다. (예: '1969년 뉴욕 베델' 입력 시 우드스탁 페스티벌 장면 추론)
- 선명한 텍스트 렌더링: 서체 배치가 정확하고 대비가 높습니다.
- 속도 향상: GPT Image 1.0보다 4배 더 빠릅니다.
가격: 장당 $0.04-$0.12 (품질 설정에 따라 다름), GPT Image 1.0보다 약 20% 저렴합니다.
대안 3: FLUX 2 Pro (Black Forest Labs)
FLUX 시리즈는 오픈 소스 이미지 생성 분야의 표준이며, FLUX 2 Pro는 품질과 가성비 사이에서 뛰어난 균형을 자랑합니다.
핵심 장점:
- 압도적인 가성비: 장당 약 $0.03로, 고품질 모델 중 가장 경제적인 선택지입니다.
- 완성도 높은 오픈 소스 생태계: 프라이빗 서버 배포가 가능하여 데이터 보안을 보장할 수 있습니다.
- 활발한 커뮤니티: 수많은 미세 조정(Fine-tuning) 모델과 LoRA를 활용할 수 있습니다.
- 대량 처리에 유리: 대규모 이미지 생성 작업에 최적화되어 있습니다.
활용 시나리오: 대량 콘텐츠 생산, 예산이 한정된 프로젝트, 자체 서버 배포가 필요한 기업
대안 4: Gemini 2.5 Flash Image (나노 바나나 프로 초대 모델)
구글 생태계에 속해 있지만 구조가 다르기 때문에, Gemini 3 Pro Image가 다운되었을 때도 영향을 받지 않는 경우가 많습니다.
핵심 장점:
- 가장 빠른 속도: 장당 약 3~5초로, 다른 모델보다 훨씬 빠릅니다.
- 높은 안정성: 프리뷰(Preview) 단계라 서버 부하가 적고, 503 에러 발생 시에도 보통 5~15분 내에 복구됩니다.
- Gemini 3와의 상호 보완: 독립적인 아키텍처로 설계되어 단일 장애점(Single Point of Failure) 문제가 없습니다.
- 낮은 비용: 가격이 저렴하여 빈번한 호출이 필요한 작업에 적합합니다.
활용 시나리오: 속도가 중요한 실시간 애플리케이션, Gemini 3의 1순위 백업 솔루션
대안 5: Recraft V4
Recraft V4는 HuggingFace 벤치마크에서 1위를 차지했으며, 특히 로고 및 브랜드 디자인 분야에서 독보적입니다.
핵심 장점:
- 최강의 로고 디자인: 2026년 기준 AI 로고 생성 분야에서 공인된 1위 모델입니다.
- SVG 내보내기 지원: 벡터 그래픽을 생성하여 화질 저하 없이 무한 확대가 가능합니다.
- 브랜드 스타일 도구: 내장된 브랜드 팔레트와 스타일 일관성 제어 기능을 제공합니다.
- 전문 디자인급 출력: 공식적인 비즈니스 및 디자인 용도에 적합합니다.
활용 시나리오: 로고 디자인, 브랜드 비주얼, 벡터 출력이 필요한 상황
5가지 대안 모델 종합 비교
| 모델 | 속도 | 품질 | 가격 | 텍스트 렌더링 | 안정성 | 사용 가능 플랫폼 |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 장당 약 $0.04 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com 등 |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | $0.04-0.12/장 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com 등 |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | 장당 약 $0.03 | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com 등 |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 매우 낮음 | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com 등 |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 장당 약 $0.04 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com 등 |
다중 모델 자동 재해 복구(Disaster Recovery) 아키텍처 설계
단순히 대안을 아는 것만으로는 부족합니다. 실제 운영 환경에서는 자동화된 장애 복구(Failover) 전환 메커니즘이 필요하죠. 여기 검증된 다중 모델 재해 복구 아키텍처를 소개합니다.
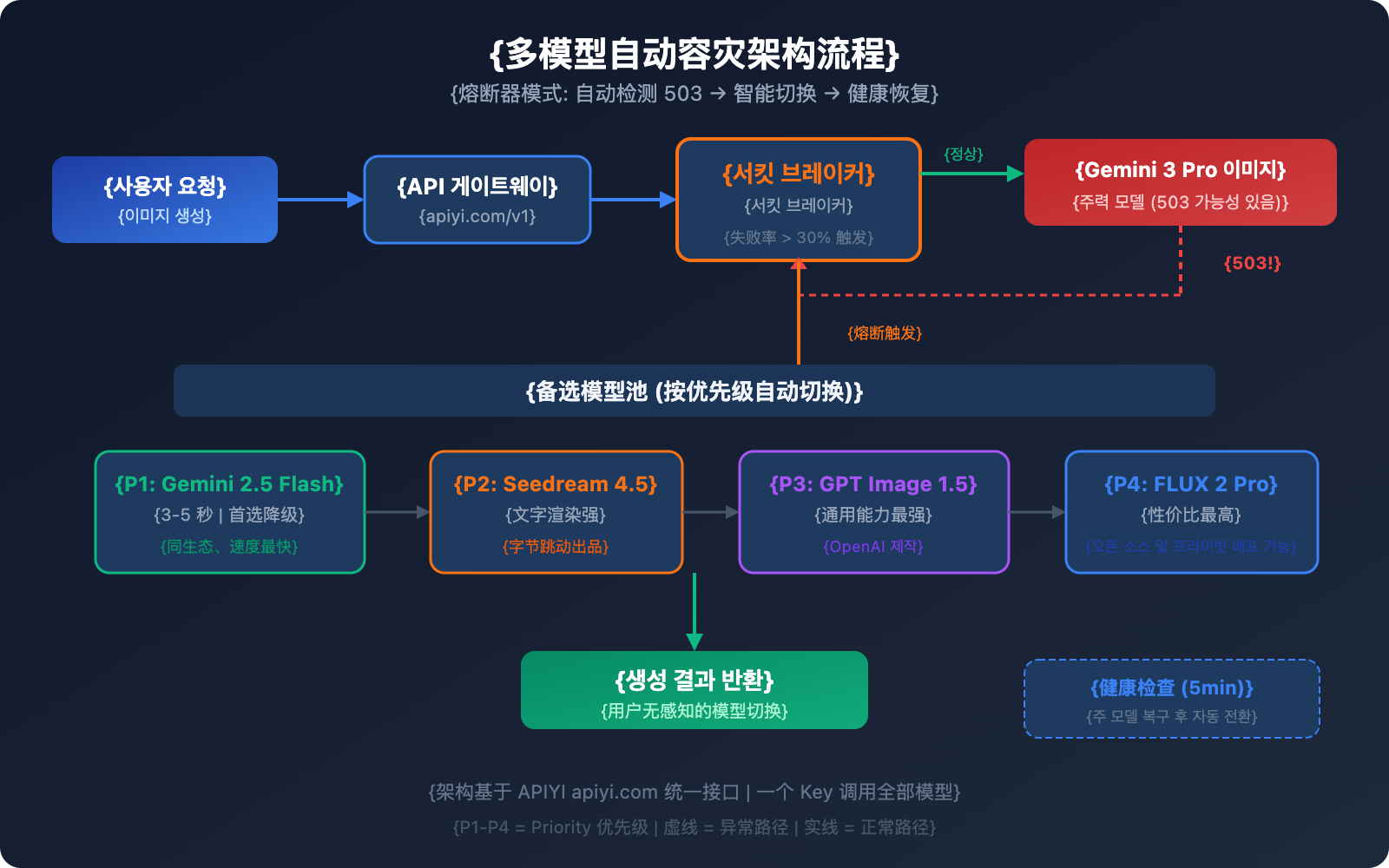
아키텍처의 핵심: 서킷 브레이커 패턴
서킷 브레이커(Circuit Breaker)는 슬라이딩 윈도우를 통해 실패율을 추적하며, 오류율이 임계치를 넘으면 자동으로 예비 모델로 전환합니다.
import openai
import time
# 다중 모델 재해 복구 설정
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스, 키 하나로 모든 모델 호출
)
def generate_with_fallback(prompt, models=MODELS):
"""다중 모델 재해 복구 이미지 생성"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[장애 복구 전환] {model['name']} 사용 불가, 다음 모델로 전환합니다")
continue
raise e
return {"success": False, "error": "모든 모델을 사용할 수 없습니다"}
전체 서킷 브레이커 구현 코드 보기
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""모델 서킷 브레이커 - 장애 자동 감지 및 전환"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 실패율 30% 시 서킷 브레이크 발동
self.window_size = window_size # 60초 슬라이딩 윈도우
self.recovery_time = recovery_time # 300초 복구 대기
self.requests = deque()
self.state = "closed" # closed=정상, open=차단(용단), half_open=복구 중
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# 만료된 기록 정리
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# 실패율 확인
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open 상태에서는 테스트 요청 허용
class MultiModelImageGenerator:
"""다중 모델 재해 복구 이미지 생성기"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""서킷 브레이커가 적용된 다중 모델 재해 복구 생성"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[차단 중] {name} 서킷 브레이커 발동 중, 건너뜁니다")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[성공] {name} 모델을 사용하여 생성 완료")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[실패] {name}: {e}")
continue
return {"success": False, "error": "모든 모델을 사용할 수 없거나 차단된 상태입니다"}
# 사용 예시
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("햇살 아래에서 낮잠을 자는 귀여운 고양이")
if result["success"]:
print(f"사용된 모델: {result['model']}")
재해 복구 전환 우선순위 제안
| 우선순위 | 모델 | 전환 사유 | 복구 전략 |
|---|---|---|---|
| 메인 | Gemini 3 Pro Image | 최고 품질 | 헬스 체크 통과 후 자동 복구 |
| 1순위 예비 | Gemini 2.5 Flash Image | 동일 생태계, 가장 빠른 속도 | 메인 모델 복구 시 원복 |
| 2순위 예비 | Seedream 4.5 | 유사한 품질, 뛰어난 텍스트 렌더링 | 메인 모델 복구 시 원복 |
| 3순위 예비 | GPT Image 1.5 | 가장 강력한 범용 성능 | 메인 모델 복구 시 원복 |
| 4순위 예비 | FLUX 2 Pro | 높은 가성비, 오픈소스 제어 가능 | 메인 모델 복구 시 원복 |
💡 아키텍처 제안: APIYI(apiyi.com)의 통합 인터페이스를 통하면 단 하나의 API Key로 위의 모든 모델을 호출할 수 있습니다. 업체별로 일일이 연동할 필요가 없어 다중 모델 재해 복구 시스템 구축 비용을 획기적으로 줄여줍니다.
C 端产品可用状态展示方案
对于面向终端用户的产品,当模型不可用时,前端应有清晰的状态展示。这是兜底方案,平时用不着,但关键时刻能大幅降低用户投诉和流失。
状态展示设计要点
三色状态指示:
- 🟢 正常: 模型可用,响应时间正常
- 🟡 延迟: 模型可用但响应变慢(超过正常值 2 倍)
- 🔴 不可用: 模型返回 503 或连续失败
前端展示建议:
// 模型状态检查 API 调用示例
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
用户体验优化策略
| 策略 | 说明 | 实现方式 |
|---|---|---|
| 实时状态页 | 在产品页面展示各模型可用状态 | 定时轮询 + WebSocket 推送 |
| 自动模型切换 | 用户无感知的后端模型切换 | 熔断器 + 优先级队列 |
| 排队提示 | 高峰期显示排队位置和预计等待时间 | 请求队列 + 进度推送 |
| 降级说明 | 告知用户当前使用的是备选模型 | 前端 Toast 提示 |
💰 成本与体验兼顾: 通过 APIYI apiyi.com 平台,你可以用统一的接口实现以上所有状态检查和模型切换逻辑,无需维护多套 SDK 和认证体系。
Gemini 3 Pro Image 503 오류 비상 대응 프로세스
503 오류가 발생했을 때, 다음 프로세스에 따라 대응해 보세요:
1단계: 오류 유형 확인
- 오류 메시지에
high demand또는upstream_error가 포함되어 있는지 확인합니다. - 429(할당량 초과)나 400(파라미터 오류)이 아닌 503 오류인지 다시 한번 확인합니다.
2단계: 영향 범위 판단
- Gemini 2.5 Flash Image가 정상인지 확인합니다 (보통 영향을 받지 않습니다).
- Gemini 텍스트 모델이 정상인지 확인합니다 (보통 영향을 받지 않습니다).
- 만약 모든 모델이 비정상이라면, 더 광범위한 GCP(Google Cloud Platform) 장애일 가능성이 큽니다.
3단계: 재해 복구(DR) 전환 시작
- 서킷 브레이커(Circuit Breaker)가 배포된 경우: 시스템이 자동으로 전환되므로 수동 개입이 필요 없습니다.
- 배포되지 않은 경우:
model파라미터를 수동으로 예비 모델로 변경합니다.
4단계: 지속적인 모니터링 및 복구
- Gemini 3 Pro Image의 503 오류는 보통 30~120분 이내에 복구됩니다.
- 복구 후에는 먼저 소량으로 테스트하여 안정성을 확인한 뒤 다시 전환하는 것을 권장합니다.
🚀 빠른 복구 팁: APIYI(apiyi.com) 플랫폼의 통합 인터페이스를 사용하면 재해 복구 전환이 훨씬 간편해집니다. 코드의
base_url을 수정할 필요 없이,model파라미터만 변경하면 다양한 모델 간에 매끄럽게 전환할 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: Gemini 3 Pro Image 503 오류 발생 시 비용이 청구되나요?
아니요, 청구되지 않습니다. 503 오류는 요청이 서버에서 처리되지 않았음을 의미하므로 어떠한 비용도 발생하지 않습니다. 이는 200 성공 응답과 다릅니다. 이미지가 성공적으로 생성된 요청에 대해서만 비용이 발생합니다. APIYI(apiyi.com) 플랫폼을 통해 호출할 때도 동일한 규칙이 적용되어 실패한 요청은 과금되지 않습니다.
Q2: 503 오류는 얼마나 지속되나요? 예비 모델을 쓰면 비용이 얼마나 늘어날까요?
과거 데이터에 따르면, Gemini 3 Pro Image의 503 오류는 보통 30120분 정도 지속됩니다. 예비 모델의 비용 차이는 크지 않습니다. Seedream 4.5는 장당 약 $0.04, GPT Image 1.5는 약 $0.04$0.12, FLUX 2 Pro는 약 $0.03 정도입니다. APIYI(apiyi.com) 플랫폼을 통해 통합 호출을 이용하면 더 저렴한 가격으로 이용할 수 있으며, 전환 비용도 거의 제로에 가깝습니다.
Q3: 503 오류가 일시적인 과부하인지 장시간 장애인지 어떻게 판단하나요?
두 가지 지표를 살펴보세요. 첫째, 같은 생태계인 Gemini 2.5 Flash Image가 정상인지 확인합니다(정상이라면 국지적 과부하입니다). 둘째, 구글 공식 상태 페이지인 status.cloud.google.com에 공지사항이 있는지 확인합니다. 만약 2시간 이상 복구되지 않고 공식 공지도 없다면, 예비 모델을 주 모델로 전환하여 사용하는 것이 좋습니다.
Q4: 다중 모델 재해 복구 아키텍처를 도입하는 게 복잡하지 않나요?
각 제조사의 API를 개별적으로 연결하려면 확실히 복잡합니다. 여러 개의 SDK, 인증 키, 결제 시스템을 관리해야 하기 때문이죠. 하지만 APIYI(apiyi.com)와 같은 통합 인터페이스 플랫폼을 사용하면 모든 모델이 동일한 base_url과 API Key를 공유합니다. 따라서 model 파라미터만 수정하면 되므로 도입 및 전환 난이도가 매우 낮습니다.
요약: 서비스 중단 걱정 없는 AI 이미지 생성 서비스 구축하기
Gemini 3 Pro Image의 503 오류는 프리뷰(Preview) 단계에서 흔히 발생하는 현상입니다. 핵심은 여러 모델을 활용한 예비 플랜을 미리 준비하는 것입니다.
- 단일 모델에 의존하지 마세요: 구글이라 할지라도 프리뷰 모델의 100% 가용성을 보장할 수는 없습니다.
- 동일 생태계 내의 다운그레이드 옵션 우선 선택: Gemini 2.5 Flash Image는 비용 효율이 가장 좋은 첫 번째 대안입니다.
- 여러 제조사의 모델 확보: Seedream 4.5, GPT Image 1.5, FLUX 2 Pro 등은 각기 다른 장점을 가지고 있습니다.
- 자동 장애 복구(Failover) 아키텍처 배포: 서킷 브레이커(Circuit Breaker) 패턴을 구현하여 사람의 개입 없이 자동으로 모델을 전환하세요.
- B2C 제품의 상태 표시 개선: 투명한 상태 정보를 제공하는 것이 아무런 설명 없이 기다리게 하는 것보다 사용자 유지에 훨씬 효과적입니다.
APIYI(apiyi.com)를 통해 다중 모델 장애 복구 솔루션을 빠르게 검증해 보세요. 통합 인터페이스와 하나의 API 키로 다양한 모델을 언제든지 자유롭게 전환할 수 있습니다.
참고 자료
-
Google AI 개발자 포럼: Gemini 3 Pro Image 503 오류 관련 토론
- 링크:
discuss.ai.google.dev - 설명: 커뮤니티 피드백 및 구글 공식 답변 확인 가능
- 링크:
-
Google AI Studio 상태 페이지: 실시간 서비스 상태
- 링크:
aistudio.google.com/status - 설명: 각 모델의 실시간 가용 상태 확인
- 링크:
-
Seedream 4.5 공식 페이지: 바이트댄스(ByteDance)의 이미지 생성 모델
- 링크:
seed.bytedance.com/en/seedream4_5 - 설명: 모델 성능 및 API 문서
- 링크:
-
OpenAI GPT Image 1.5 문서: 최신 이미지 생성 모델
- 링크:
platform.openai.com/docs/models/gpt-image-1.5 - 설명: 모델 파라미터 및 가격 정보
- 링크:
📝 작성자: APIYI Team | 기술 교류 및 문의는 APIYI(apiyi.com)를 방문해 주세요.
📅 업데이트 날짜: 2026년 2월 19일
🏷️ 키워드: Gemini 3 Pro Image 503 오류, AI 이미지 생성 다중 모델 대안, 장애 복구 아키텍처, Seedream 4.5, GPT Image 1.5