2026年2月19日、多くの開発者から gemini-3-pro-image-preview モデルが継続的に 503 エラーを返すという報告が相次いでいます。これはあなたのアカウントの問題ではなく、Google 側のサーバー過負荷によるものです。エラーメッセージには明確に「This model is currently experiencing high demand(このモデルは現在リクエストが集中しています)」と記載されており、課金は発生しませんが、画像の生成も全くできない状態です。
さらに重要なのは、これが一過性の現象ではないということです。2025年末から現在にかけて、Gemini の画像モデルでは同様のピーク時の過負荷が何度も発生しています。一方で、第一世代の gemini-2.5-flash-image(いわゆる Nano Banana Pro 初代モデル)や Gemini テキストシリーズは正常に動作しており、問題は Gemini 3 Pro Image の計算リソース割り当てに集中していることがわかります。
この記事の価値: 読み終える頃には、503 エラーの切り分け方法、5 つの信頼できる代替画像生成モデル、そして実用的なマルチモデル自動フェイルオーバー(容災)アーキテクチャを習得できるはずです。

Gemini 3 Pro Image 503 エラー完全解析
503 エラーが意味するもの
以下のようなエラーメッセージを受け取った場合:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
これはサーバー側のキャパシティの問題であり、クライアント側のエラーではありません。429 エラー(個人のクォータ制限)とは異なり、503 は Google が Gemini 3 Pro Image Preview モデルに割り当てている推論サーバークラスターが全体的に過負荷になっており、すべてのユーザーが影響を受けていることを示しています。
503 エラーと他の一般的なエラーの比較
| エラーコード | 意味 | 課金の有無 | 影響範囲 | 復旧までの時間 |
|---|---|---|---|---|
| 503 | サーバー過負荷 | ❌ なし | 全ユーザー | 30〜120 分 |
| 429 | 個人の配額(クォータ)不足 | ❌ なし | 当該アカウントのみ | 配額のリセット待ち |
| 400 | リクエストパラメータ不正 | ❌ なし | 当該リクエストのみ | パラメータ修正で即時 |
| 500 | 内部サーバーエラー | ❌ なし | 不確定 | 通常数分以内 |
なぜ 503 が頻繁に発生するのか
Gemini 3 Pro Image は現在 Preview 段階にあり、共有の推論サーバープールで動作しています。コミュニティのモニタリングデータによると、以下の時間帯に 503 エラー率が高くなる傾向があります。
| 時間帯 (日本時間 JST) | エラー率 | 原因の分析 |
|---|---|---|
| 01:00 – 03:00 | 約 35% | 北米のコアタイムによる負荷増 |
| 10:00 – 12:00 | 約 40% | アジア太平洋地域の開発者による利用ピーク |
| 21:00 – 00:00 | 約 45% | 世界的なトラフィックの重なり |
| その他の時間帯 | 約 5-10% | 通常の変動 |
🎯 実戦アドバイス: もしあなたのビジネスが AI 画像生成に依存しているなら、単一のモデルだけに頼るのは危険です。APIYI (apiyi.com) を通じて複数の画像モデルを導入し、自動フェイルオーバー(切り替え)構成を構築することで、単一障害点によるビジネスへの影響を回避することをお勧めします。
Gemini 3 Pro Image の代わりとなる画像生成モデル 5 選
Gemini 3 Pro Image が利用できない場合、以下の 5 つのモデルが信頼できる代替案となります。

代替案 1: Seedream 4.5 (ByteDance)
Seedream 4.5 は ByteDance がリリースした画像生成モデルで、LM Arena ランキングで 10 位(スコア 1147)にランクインしています。
主なメリット:
- 卓越したテキスト描画能力: 画像内に読み取り可能なテキストを正確に生成でき、マーケティング資料やポスターに最適です。
- 高解像度出力: 2048×2048 ピクセルをサポートし、4K レベルの品質を実現します。
- 高い一貫性: キャラクター、物体、環境のディテールを複数の画像間で一貫して保持できます。
- 映画のような美学: プロのカメラマンが撮影したような色彩と構図が特徴です。
活用シーン: ECサイトの商品画像、ブランドマーケティング素材、正確なテキスト描画が必要な画像
注目ポイント: 2026 年 2 月 24 日に Seedream 5.0 がリリース予定。Web 検索、サンプル編集、論理推論能力が新たに追加される見込みです。
代替案 2: GPT Image 1.5 (OpenAI)
OpenAI が 2025 年 12 月に発表した最新の画像生成モデルで、現在、汎用的なシーンにおいて最強の文生図(Text-to-Image)モデルの一つです。
主なメリット:
- 精密な編集: 画像をアップロードした後、他の要素を壊さずに指定した部分だけを正確に修正できます。
- 豊富な世界知識: 文脈からシーンの詳細を推測可能(例:「1969 年のニューヨーク州ベセル」と入力すると、ウッドストック・フェスティバルを推測して描写)。
- クリアなテキスト描画: フォントの配置が正確で、コントラストも高いです。
- スピード向上: GPT Image 1.0 よりも 4 倍高速化されています。
価格: 1 枚あたり $0.04 – $0.12(品質設定による)。GPT Image 1.0 より 20% 安価です。
代替案 3: FLUX 2 Pro (Black Forest Labs)
FLUX シリーズはオープンソース画像生成分野のベンチマークであり、FLUX 2 Pro は品質とコストパフォーマンスのバランスに優れています。
主なメリット:
- 圧倒的なコスパ: 1 枚あたり約 $0.03 と、高品質な選択肢の中では最も経済的です。
- 充実したオープンソースエコシステム: ローカル環境へのデプロイが可能で、データセキュリティも確保できます。
- 活発なコミュニティ: 多数のファインチューニングモデルや LoRA が利用可能です。
- バッチ処理に最適: 大規模な画像生成タスクに適しています。
活用シーン: 大量コンテンツ制作、予算重視のプロジェクト、ローカルデプロイが必要な企業
代替案 4: Gemini 2.5 Flash Image (Nano Banana Pro 初代)
Google エコシステムに属していますが、アーキテクチャが異なるため、Gemini 3 Pro Image がダウンしている時でも影響を受けないことが多いです。
主なメリット:
- 最速のスピード: 1 枚あたり約 3〜5 秒と、他のモデルよりも圧倒的に速いです。
- 高い安定性: プレビュー段階ではサーバー負荷が比較的低く、503 エラーからの復旧も通常 5〜15 分程度です。
- Gemini 3 との補完性: 独立したアーキテクチャのため、単一障害点になりにくいです。
- 低コスト: リーズナブルな価格設定で、高頻度の呼び出しに適しています。
活用シーン: スピードが求められるリアルタイムアプリ、Gemini 3 の第一候補となるフォールバック(代替)プラン
代替案 5: Recraft V4
Recraft V4 は HuggingFace のベンチマークで 1 位を獲得しており、特にロゴやブランドデザインに特化しています。
主なメリット:
- 最強のロゴデザイン: 2026 年の AI ロゴ生成分野で公認のナンバーワンです。
- SVG 出力をサポート: ベクターグラフィックスを生成でき、無限に拡大縮小が可能です。
- ブランドスタイルツール: ブランドカラーパレットやスタイルの一貫性を制御する機能が組み込まれています。
- プロフェッショナルなデザイン出力: 正式なビジネスやデザイン用途に適しています。
活用シーン: ロゴデザイン、ブランドビジュアル、ベクター出力が必要なシーン
5 つの代替モデルの総合比較
| モデル | 速度 | 品質 | 価格 | テキスト描画 | 安定性 | 利用可能プラットフォーム |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/枚 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com) など |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | $0.04-0.12/枚 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com) など |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~$0.03/枚 | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com) など |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 極めて低価格 | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com) など |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/枚 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com) など |
多モデル自動災対(DR)アーキテクチャ設計
代替案を知っているだけでは不十分です。実際の運用環境には、自動化された災対(災害対策)切り替えメカニズムが必要です。以下に、検証済みの多モデル災対アーキテクチャを紹介します。
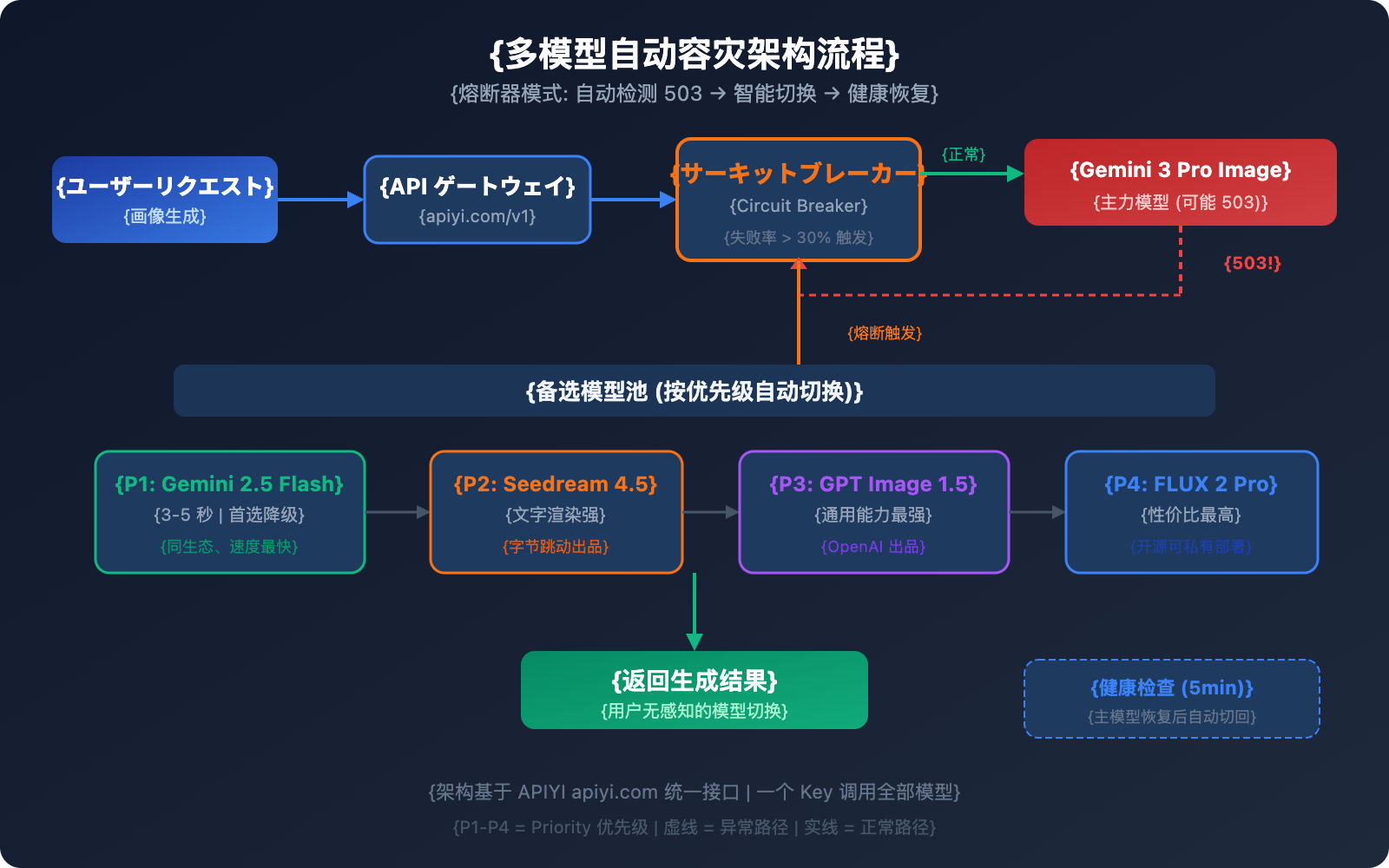
アーキテクチャの核心:サーキットブレーカー・パターン
サーキットブレーカー(Circuit Breaker)は、スライディングウィンドウを通じて失敗率を追跡し、故障率がしきい値を超えた場合に自動的に代替モデルへと切り替えます。
import openai
import time
# 多モデル災対(DR)設定
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI統合インターフェース。1つのKeyですべてのモデルを呼び出し可能
)
def generate_with_fallback(prompt, models=MODELS):
"""多モデル災対画像生成"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[災対切り替え] {model['name']} が利用不可です。次のモデルに切り替えます")
continue
raise e
return {"success": False, "error": "すべてのモデルが利用不可です"}
サーキットブレーカーの完全な実装コードを表示
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""モデルサーキットブレーカー - 故障を自動検出し切り替え"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 失敗率30%でサーキットブレーカー発動
self.window_size = window_size # 60秒のスライディングウィンドウ
self.recovery_time = recovery_time # 300秒の復旧待機
self.requests = deque()
self.state = "closed" # closed=正常, open=遮断, half_open=試行中
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# 期限切れの記録をクリーンアップ
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# 失敗率を確認
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open は試行リクエストを許可
class MultiModelImageGenerator:
"""多モデル災対画像生成器"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI統合インターフェース
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""サーキットブレーカー付き多モデル災対生成"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[遮断中] {name} はサーキットブレーカー発動中のためスキップします")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[成功] {name} を使用して生成が完了しました")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[失敗] {name}: {e}")
continue
return {"success": False, "error": "すべてのモデルが利用不可、または遮断されています"}
# 使用例
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("日差しの中でうたた寝をする可愛い猫")
if result["success"]:
print(f"使用モデル: {result['model']}")
災対切り替えの優先度に関する推奨事項
| 優先度 | モデル | 切り替え理由 | 復旧戦略 |
|---|---|---|---|
| メイン | Gemini 3 Pro Image | 品質が最高 | ヘルスチェック通過後に自動復旧 |
| 第1待機 | Gemini 2.5 Flash Image | 同一エコシステム、最速 | メイン復旧後に切り戻し |
| 第2待機 | Seedream 4.5 | 品質が近く、文字レンダリングに強い | メイン復旧後に切り戻し |
| 第3待機 | GPT Image 1.5 | 汎用性が最も高い | メイン復旧後に切り戻し |
| 第4待機 | FLUX 2 Pro | コスパが高く、オープンソースで制御可能 | メイン復旧後に切り戻し |
💡 アーキテクチャのアドバイス: APIYI(apiyi.com)の統合インターフェースを利用すれば、1つのAPI Keyだけで上記のすべてのモデルを呼び出すことができます。各ベンダーと個別に連携する必要がなく、多モデル災対の導入コストを大幅に削減できます。
C向け製品における可用性ステータス表示案
エンドユーザー向けの製品において、モデルが利用できない場合にフロントエンドで明確なステータスを表示することは非常に重要です。これは一種の**フォールバック(切り札)**であり、普段は使う機会がありませんが、いざという時にユーザーの不満や離脱を大幅に抑えることができます。
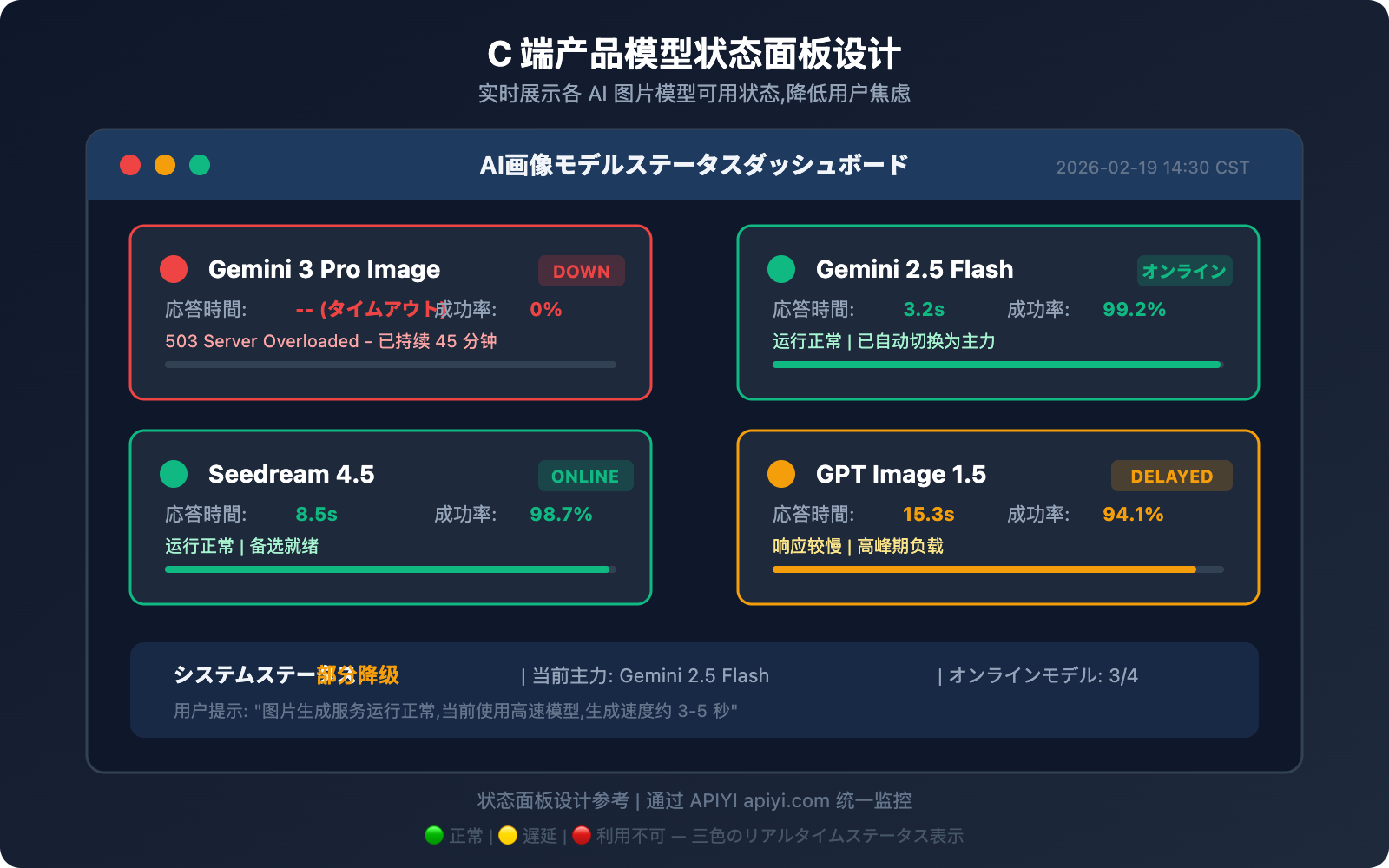
ステータス表示のデザインポイント
3色のステータス表示:
- 🟢 正常: モデル利用可能、レスポンス時間も正常
- 🟡 遅延: モデルは利用可能だがレスポンスが低下(通常値の2倍以上)
- 🔴 利用不可: モデルが503エラーを返す、または連続して失敗
フロントエンドでの表示に関するアドバイス:
// モデルステータス確認APIの呼び出し例
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
ユーザー体験(UX)最適化戦略
| 戦略 | 説明 | 実装方法 |
|---|---|---|
| リアルタイムステータスページ | 製品ページで各モデルの可用性を表示 | 定期的なポーリング + WebSocketプッシュ |
| モデルの自動切り替え | ユーザーに意識させないバックエンドでのモデル切り替え | サーキットブレーカー + 優先度付きキュー |
| 待機列の表示 | 混雑時に待ち順と予想待ち時間を表示 | リクエストキュー + 進捗プッシュ |
| 機能制限(デグレード)の説明 | 現在代替モデルを使用していることをユーザーに通知 | フロントエンドのトースト通知 |
💰 コストと体験の両立: APIYI (apiyi.com) プラットフォームを利用すれば、統一されたインターフェースでこれらすべてのステータス確認とモデル切り替えロジックを実現できます。複数のSDKや認証体系を管理する手間はもう不要です。
Gemini 3 Pro Image 503エラー緊急対応フロー
503エラーが発生した際は、以下のフローに従って対応してください。
ステップ1:エラータイプの確認
- エラーメッセージに
high demandまたはupstream_errorが含まれているか確認します。 - 429(クォータ制限)や400(パラメータエラー)ではなく、503であることを確認します。
ステップ2:影響範囲の特定
- Gemini 2.5 Flash Image が正常か確認します(通常は影響を受けません)。
- Gemini テキストモデルが正常か確認します(通常は影響を受けません)。
- すべてのモデルで異常が発生している場合は、より広範囲なGCP(Google Cloud Platform)の障害である可能性があります。
ステップ3:ディザスタリカバリ(切り替え)の実行
- サーキットブレーカーを導入済みの場合:システムが自動で切り替わるため、手動の介入は不要です。
- 未導入の場合:手動で
modelパラメータを代替モデルに変更します。
ステップ4:継続的な監視と復旧確認
- Gemini 3 Pro Image の503エラーは、通常30〜120分で復旧します。
- 復旧後は、まず少量のテストを行い、安定性を確認してから元のモデルに戻すことをお勧めします。
🚀 迅速な復旧: ディザスタリカバリの切り替えには、APIYI(apiyi.com)プラットフォームの統合インターフェースの使用を推奨します。コード内の
base_urlを変更することなく、modelパラメータを切り替えるだけで、異なるモデル間をシームレスに移行できます。
よくある質問
Q1:Gemini 3 Pro Image の503エラーで料金は発生しますか?
いいえ、発生しません。503エラーはリクエストがサーバーで処理されなかったことを意味するため、費用は一切かかりません。これは200(成功)レスポンスとは異なり、画像の生成に成功したリクエストのみが課金対象となります。APIYI(apiyi.com)プラットフォーム経由で呼び出す場合も同様のルールが適用され、失敗したリクエストには課金されません。
Q2:503エラーはどのくらい続きますか?代替モデルを使用するとコストはどのくらい増えますか?
過去のデータによると、Gemini 3 Pro Image の503エラーは通常30〜120分間継続します。代替モデルのコスト差はそれほど大きくありません。例えば、Seedream 4.5 は約0.04ドル/枚、GPT Image 1.5 は約0.04〜0.12ドル/枚、FLUX 2 Pro は約0.03ドル/枚です。APIYI(apiyi.com)プラットフォームで統合的に呼び出すことで、よりお得な価格で利用でき、切り替えコストもほぼゼロに抑えられます。
Q3:503エラーが一時的な過負荷なのか、長時間の故障なのかをどう判断すればよいですか?
2つの指標を確認してください。1つ目は、同じエコシステム内の Gemini 2.5 Flash Image が正常かどうかです(正常であれば局所的な過負荷です)。2つ目は、Google公式のステータスページ(status.cloud.google.com)にアナウンスがあるかどうかです。2時間を経過しても復旧せず、公式のアナウンスもない場合は、代替モデルをメインとして使用するように切り替えることをお勧めします。
Q4:マルチモデル・ディザスタリカバリ構成の導入難易度は高いですか?
各ベンダーのAPIを個別に連携させる場合は、複数のSDK、認証キー、課金体系を管理する必要があるため、確かに複雑です。しかし、APIYI(apiyi.com)のような統合インターフェースプラットフォームを利用すれば、すべてのモデルで同じ base_url と APIキーを共有できるため、切り替えは model パラメータを変更するだけで済み、導入の難易度は非常に低くなります。
まとめ: ダウンタイムに強い AI 画像生成サービスの構築
Gemini 3 Pro Image の 503 エラーは、プレビュー(Preview)段階ではよくあることです。重要なのは、事前に対替となる複数のモデル案を用意しておくことです。
- 単一のモデルに依存しない: たとえ Google であっても、プレビュー版モデルの 100% の可用性を保証することはできません。
- 同一エコシステム内でのダウングレードを優先: Gemini 2.5 Flash Image は、最も低コストで選ぶべき第一の代替案です。
- マルチベンダーによる複数モデルの確保: Seedream 4.5、GPT Image 1.5、FLUX 2 Pro はそれぞれに長所があります。
- 自動障害復旧(容災)アーキテクチャの導入: サーキットブレーカー(Circuit Breaker)パターンにより、人の手を介さない自動切り替えを実現します。
- C向け製品でのステータス表示: 透明性のあるステータス情報は、沈黙の待ち時間よりもユーザーの離脱を防ぐことができます。
APIYI(apiyi.com)を利用すれば、マルチモデルによる障害対策案を素早く検証できます。統一されたインターフェース、1つの API キーで、多様なモデルをいつでも切り替え可能です。
参考資料
-
Google AI 開発者フォーラム: Gemini 3 Pro Image 503 エラーに関する議論
- リンク:
discuss.ai.google.dev - 説明: コミュニティのフィードバックと Google 公式の回答
- リンク:
-
Google AI Studio ステータスページ: リアルタイムのサービス状況
- リンク:
aistudio.google.com/status - 説明: 各モデルのリアルタイムな稼働状況を確認
- リンク:
-
Seedream 4.5 公式ページ: ByteDance の画像生成モデル
- リンク:
seed.bytedance.com/en/seedream4_5 - 説明: モデルの能力と API ドキュメント
- リンク:
-
OpenAI GPT Image 1.5 ドキュメント: 最新の画像生成モデル
- リンク:
platform.openai.com/docs/models/gpt-image-1.5 - 説明: モデルのパラメータと価格情報
- リンク:
📝 著者: APIYI Team | 技術交流は APIYI apiyi.com まで
📅 更新日: 2026 年 2 月 19 日
🏷️ キーワード: Gemini 3 Pro Image 503 エラー, AI 画像生成代替モデル, 障害耐性アーキテクチャ, Seedream 4.5, GPT Image 1.5