El 19 de febrero de 2026, una gran cantidad de desarrolladores informaron que el modelo gemini-3-pro-image-preview devuelve constantemente errores 503: no es un problema de tu cuenta, es una sobrecarga en los servidores de Google. El mensaje de error indica claramente: "This model is currently experiencing high demand" (Este modelo está experimentando una alta demanda en este momento), y aunque no genera cargos, tampoco permite generar imágenes en absoluto.
Lo más importante es que no es un caso aislado. Desde finales de 2025 hasta hoy, el modelo de imagen de Gemini ha sufrido sobrecargas similares en periodos de alta demanda en varias ocasiones. Al mismo tiempo, la primera generación de gemini-2.5-flash-image (el modelo original Nano Banana Pro) y la serie de texto de Gemini funcionan con normalidad, lo que indica que el problema se concentra en la asignación de potencia de cómputo para Gemini 3 Pro Image.
Valor central: Al terminar de leer este artículo, dominarás el método de resolución de errores 503, conocerás 5 modelos de imagen alternativos y fiables, y aprenderás a implementar una arquitectura de recuperación ante desastres automática multimodelo.
Análisis completo del error 503 en Gemini 3 Pro Image
¿Qué significa realmente el error 503?
Cuando recibes un mensaje de error como el siguiente:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
Se trata de un problema de capacidad del servidor, no de un error del cliente. A diferencia del error 429 (límite de cuota personal excedido), el 503 indica que el clúster de servidores de inferencia asignado por Google para el modelo Gemini 3 Pro Image Preview está completamente sobrecargado, afectando a todos los usuarios.
Comparativa: Error 503 vs. otros errores comunes
| Código de error | Significado | ¿Se factura? | Alcance del impacto | Tiempo de recuperación |
|---|---|---|---|---|
| 503 | Sobrecarga del servidor | ❌ No | Todos los usuarios globales | 30-120 minutos |
| 429 | Cuota personal agotada | ❌ No | Solo la cuenta actual | Esperar a que se reinicie la cuota |
| 400 | Error en los parámetros | ❌ No | Solo la solicitud actual | Corregir los parámetros |
| 500 | Error interno del servidor | ❌ No | Incierto | Generalmente pocos minutos |
¿Por qué ocurre el error 503 con tanta frecuencia?
Gemini 3 Pro Image se encuentra actualmente en fase Preview y se ejecuta en un grupo compartido de servidores de inferencia. Según los datos de monitoreo de la comunidad, las tasas de error 503 son más altas en los siguientes periodos:
| Horario (Hora de Pekín) | Tasa de error | Análisis de la causa |
|---|---|---|
| 00:00 – 02:00 | Aprox. 35% | Pico de horario laboral en Norteamérica |
| 09:00 – 11:00 | Aprox. 40% | Pico matutino de pruebas de desarrolladores en Asia-Pacífico |
| 20:00 – 23:00 | Aprox. 45% | Pico global superpuesto |
| Otros horarios | Aprox. 5-10% | Fluctuaciones normales |
🎯 Consejo práctico: Si tu negocio depende de la generación de imágenes por IA, no basta con un solo modelo. Recomendamos acceder a múltiples modelos de imagen a través de APIYI (apiyi.com) para implementar una conmutación automática por error y evitar que un único punto de falla afecte a tu servicio.
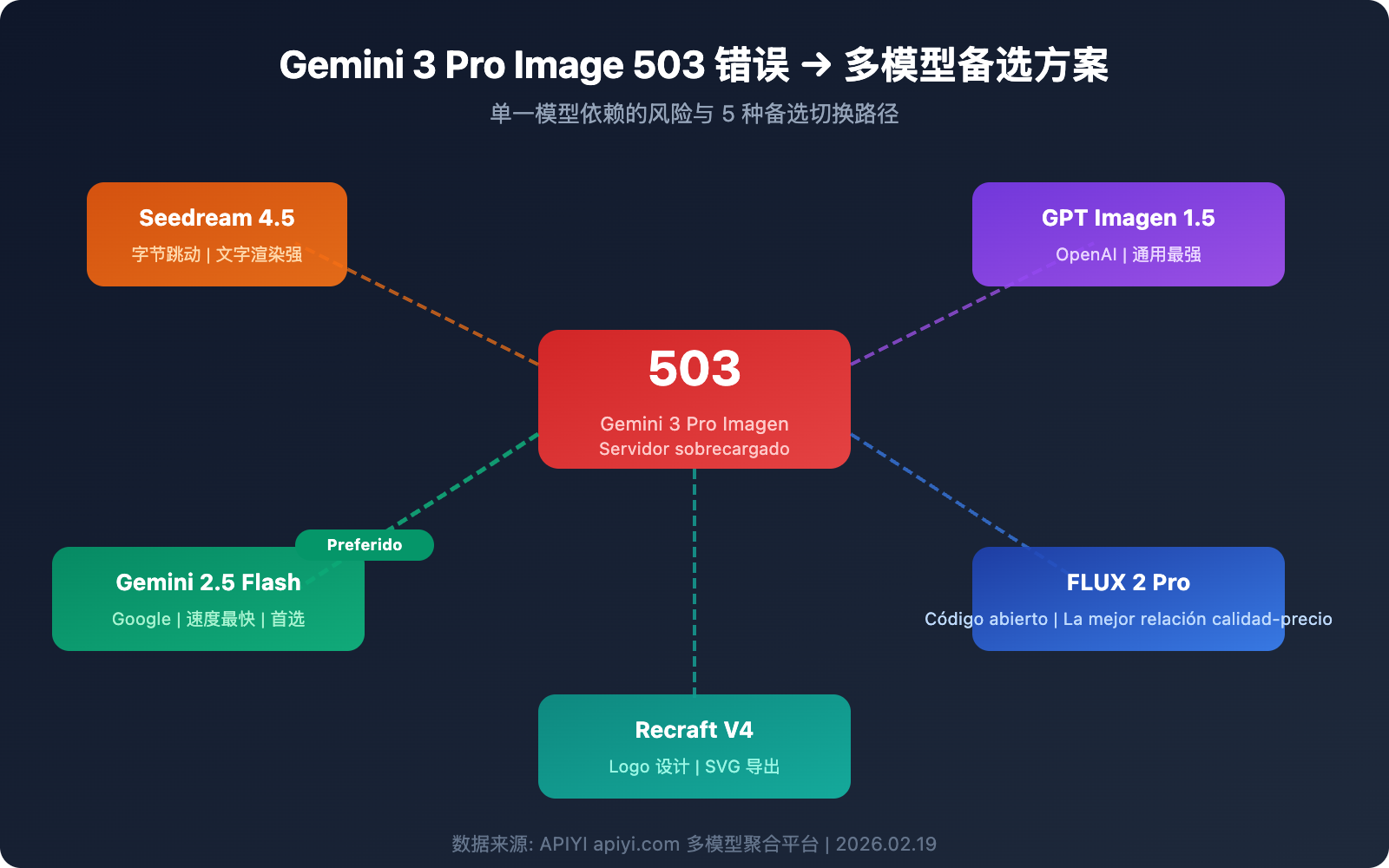
5 modelos alternativos de generación de imágenes a Gemini 3 Pro Image
Cuando Gemini 3 Pro Image no está disponible, estos 5 modelos pueden servir como alternativas fiables.

Alternativa 1: Seedream 4.5 (ByteDance)
Seedream 4.5 es el modelo de generación de imágenes lanzado por ByteDance, que ocupa el décimo lugar en el ranking de LM Arena con una puntuación de 1147.
Ventajas clave:
- Capacidad de renderizado de texto sobresaliente: Puede generar texto legible con precisión dentro de las imágenes, ideal para materiales de marketing y carteles.
- Salida de alta resolución: Soporta hasta 2048×2048 píxeles, alcanzando el nivel 4K.
- Gran consistencia: Los detalles de personajes, objetos y entornos se mantienen coherentes en múltiples imágenes.
- Estética cinematográfica: El color y la composición están a la altura de la fotografía profesional.
Casos de uso: Imágenes de productos para e-commerce, materiales de marketing de marca e imágenes que requieren un renderizado de texto preciso.
Dato a tener en cuenta: Se espera que Seedream 5.0 se lance el 24 de febrero de 2026, incluyendo nuevas capacidades de búsqueda web, edición basada en ejemplos y razonamiento lógico.
Alternativa 2: GPT Image 1.5 (OpenAI)
El modelo de generación de imágenes más reciente de OpenAI, lanzado en diciembre de 2025, es actualmente uno de los modelos de texto a imagen más potentes para propósitos generales.
Ventajas clave:
- Edición precisa: Permite modificar partes específicas de una imagen subida sin alterar el resto de los elementos.
- Amplio conocimiento del mundo: Capaz de inferir detalles de la escena según el contexto (por ejemplo, al introducir "Bethel, Nueva York, 1969", puede deducir el festival de Woodstock).
- Renderizado de texto nítido: Tipografía precisa y con alto contraste.
- Mejora en la velocidad: 4 veces más rápido que GPT Image 1.0.
Precio: Entre $0.04 y $0.12 por imagen (dependiendo de la configuración de calidad), un 20% más barato que GPT Image 1.0.
Alternativa 3: FLUX 2 Pro (Black Forest Labs)
La serie FLUX es un referente en el campo de la generación de imágenes de código abierto, y FLUX 2 Pro ofrece un equilibrio excelente entre calidad y precio.
Ventajas clave:
- Excelente relación calidad-precio: Aproximadamente $0.03 por imagen, siendo la opción de alta calidad más económica.
- Ecosistema de código abierto maduro: Permite el despliegue privado, garantizando la seguridad de los datos.
- Comunidad activa: Gran cantidad de modelos ajustados (fine-tuned) y LoRAs disponibles.
- Ideal para el procesamiento por lotes: Perfecto para tareas de generación de imágenes a gran escala.
Casos de uso: Producción de contenido masivo, proyectos con presupuesto ajustado y empresas que requieren despliegue privado.
Alternativa 4: Gemini 2.5 Flash Image (Primera generación de Nano Banana Pro)
Pertenece al mismo ecosistema de Google, pero con una arquitectura diferente, por lo que suele no verse afectado cuando Gemini 3 Pro Image sufre una caída.
Ventajas clave:
- El más rápido: Aproximadamente 3-5 segundos por imagen, mucho más rápido que otros modelos.
- Alta estabilidad: Durante su fase Preview, la carga del servidor es baja; las recuperaciones tras un error 503 suelen tardar solo entre 5 y 15 minutos.
- Complementario a Gemini 3: Arquitectura independiente, sin puntos únicos de fallo compartidos.
- Bajo coste: Precios muy competitivos, ideal para llamadas de alta frecuencia.
Casos de uso: Aplicaciones en tiempo real que requieren velocidad y como primera opción de respaldo ante fallos de Gemini 3.
Alternativa 5: Recraft V4
Recraft V4 ocupa el primer lugar en los benchmarks de HuggingFace, destacando especialmente en el diseño de logotipos y branding.
Ventajas clave:
- El mejor para diseño de logotipos: Reconocido como el número uno en generación de logos por IA en 2026.
- Soporte para exportación en SVG: Genera gráficos vectoriales que se pueden escalar infinitamente.
- Herramientas de estilo de marca: Incluye paletas de colores de marca y control de consistencia de estilo integrados.
- Resultados de nivel de diseño profesional: Adecuado para usos comerciales y de diseño formal.
Casos de uso: Diseño de logotipos, identidad visual de marca y escenarios que requieren salida vectorial.
Comparativa de los 5 modelos alternativos
| Modelo | Velocidad | Calidad | Precio | Renderizado de texto | Estabilidad | Plataformas disponibles |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/img | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com), etc. |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | $0.04-0.12/img | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com), etc. |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~$0.03/img | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com), etc. |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Muy bajo | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com), etc. |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/img | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI (apiyi.com), etc. |
Diseño de arquitectura de recuperación ante desastres automática multimodelo
No basta con conocer las alternativas; un entorno de producción real requiere un mecanismo de conmutación por error (failover) automatizado. A continuación, presentamos una arquitectura de recuperación ante desastres multimodelo probada.
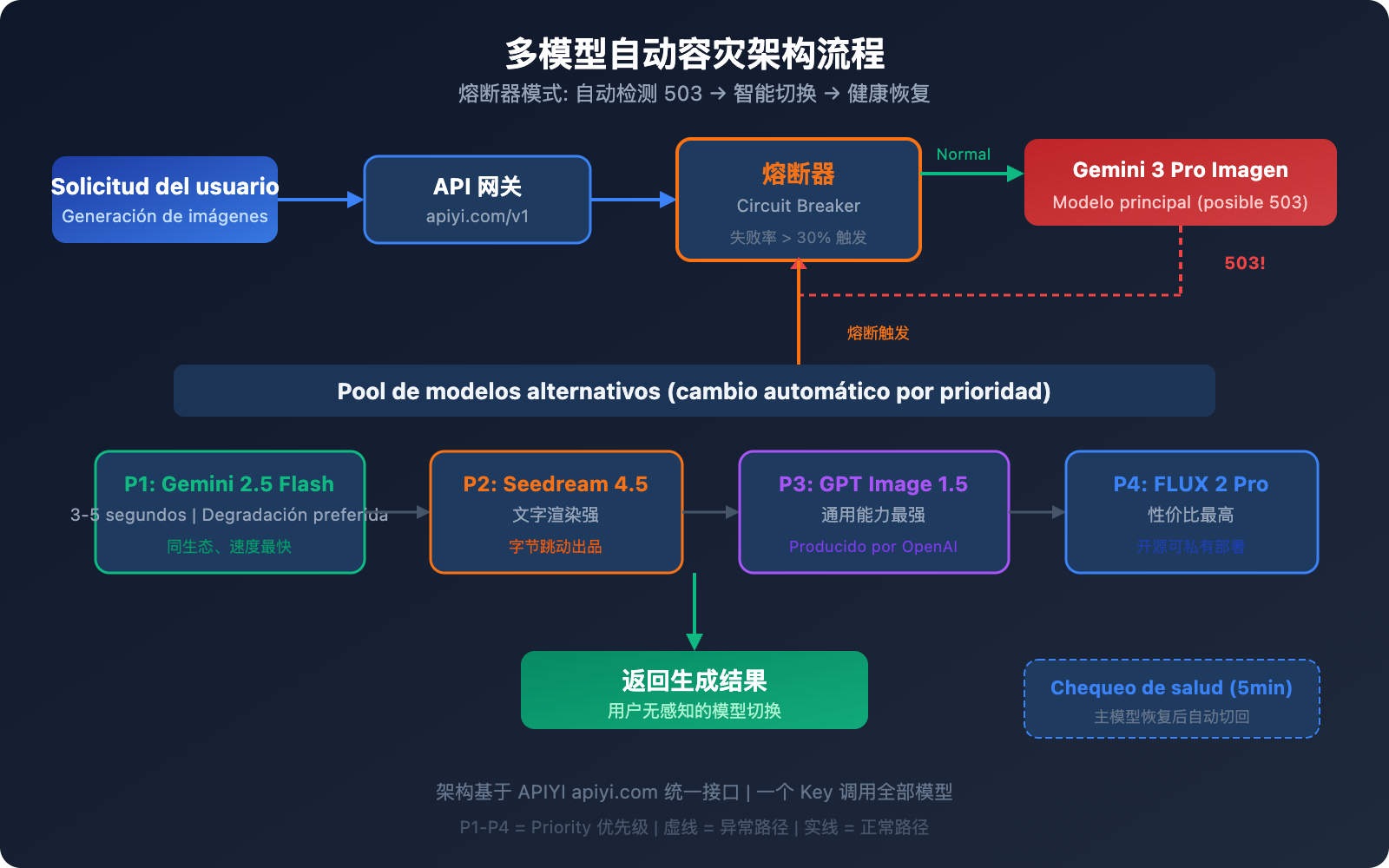
El núcleo de la arquitectura: El patrón Circuit Breaker (Disyuntor)
El disyuntor (Circuit Breaker) rastrea la tasa de fallos mediante una ventana deslizante; cuando la tasa de fallos supera un umbral determinado, cambia automáticamente a un modelo de reserva:
import openai
import time
# Configuración de recuperación ante desastres multimodelo
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI, una sola clave para todos los modelos
)
def generate_with_fallback(prompt, models=MODELS):
"""Generación de imágenes con recuperación ante desastres multimodelo"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[Conmutación por error] {model['name']} no disponible, cambiando al siguiente modelo")
continue
raise e
return {"success": False, "error": "Todos los modelos están fuera de servicio"}
Ver el código completo de implementación del disyuntor
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""Disyuntor de modelos - Detecta fallos y cambia automáticamente"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # El 30% de tasa de fallos activa el disyuntor
self.window_size = window_size # Ventana deslizante de 60 segundos
self.recovery_time = recovery_time # 300 segundos de espera para la recuperación
self.requests = deque()
self.state = "closed" # closed=normal, open=abierto (fallo), half_open=semi-abierto (recuperando)
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# Limpiar registros expirados
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# Comprobar tasa de fallos
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open permite solicitudes de prueba
class MultiModelImageGenerator:
"""Generador de imágenes multimodelo con recuperación ante desastres"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""Generación multimodelo con disyuntor para recuperación ante desastres"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[Abierto] {name} disyuntor activado, omitiendo")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[Éxito] Generación completada con {name}")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[Fallo] {name}: {e}")
continue
return {"success": False, "error": "Todos los modelos están fuera de servicio o con disyuntor activado"}
# Ejemplo de uso
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("Un gatito adorable durmiendo la siesta bajo el sol")
if result["success"]:
print(f"Modelo utilizado: {result['model']}")
Sugerencias de prioridad para la conmutación por error
| Prioridad | Modelo | Motivo del cambio | Estrategia de recuperación |
|---|---|---|---|
| Principal | Gemini 3 Pro Image | Calidad superior | Recuperación automática tras pasar el control de salud |
| Reserva Nivel 1 | Gemini 2.5 Flash Image | Mismo ecosistema, el más rápido | Degradar tras la recuperación del principal |
| Reserva Nivel 2 | Seedream 4.5 | Calidad similar, renderizado de texto potente | Degradar tras la recuperación del principal |
| Reserva Nivel 3 | GPT Image 1.5 | Capacidad general más fuerte | Degradar tras la recuperación del principal |
| Reserva Nivel 4 | FLUX 2 Pro | Alta relación calidad-precio, código abierto controlable | Degradar tras la recuperación del principal |
💡 Sugerencia de arquitectura: A través de la interfaz unificada de APIYI (apiyi.com), solo necesitas una API Key para llamar a todos los modelos mencionados anteriormente. No es necesario integrar cada proveedor por separado, lo que reduce drásticamente los costos de implementación de la recuperación ante desastres multimodelo.
Estrategias de visualización de disponibilidad para productos para el usuario final
Para los productos orientados al consumidor final, cuando un modelo no está disponible, el frontend debe mostrar el estado de forma clara. Esta es una solución de respaldo (fallback); normalmente no se necesita, pero en momentos críticos puede reducir drásticamente las quejas y la pérdida de usuarios.
Puntos clave del diseño de estados
Indicador de estado de tres colores:
- 🟢 Normal: El modelo está disponible y el tiempo de respuesta es adecuado.
- 🟡 Latencia: El modelo está disponible pero la respuesta es lenta (más del doble del valor normal).
- 🔴 No disponible: El modelo devuelve un error 503 o falla consecutivamente.
Sugerencias para el frontend:
// Ejemplo de llamada a la API de verificación de estado del modelo
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
Estrategias de optimización de la experiencia de usuario (UX)
| Estrategia | Descripción | Implementación |
|---|---|---|
| Página de estado en tiempo real | Muestra la disponibilidad de cada modelo en la página del producto. | Sondeo periódico (polling) + Notificaciones WebSocket. |
| Cambio automático de modelo | Cambio de modelo en el backend imperceptible para el usuario. | Interruptor de circuito (Circuit Breaker) + Cola de prioridad. |
| Aviso de cola de espera | Muestra la posición en la cola y el tiempo estimado durante picos de tráfico. | Cola de solicitudes + Notificaciones de progreso. |
| Aviso de degradación | Informa al usuario que se está utilizando un modelo alternativo. | Notificación Toast en el frontend. |
💰 Equilibrio entre costo y experiencia: A través de la plataforma APIYI (apiyi.com), puedes implementar toda la lógica de verificación de estado y cambio de modelos con una interfaz unificada, sin necesidad de mantener múltiples SDK y sistemas de autenticación.
Procedimiento de emergencia para errores 503 en Gemini 3 Pro Image
Cuando te encuentres con un error 503, sigue este flujo de trabajo:
Paso 1: Confirmar el tipo de error
- Verifica si el mensaje de error contiene
high demandoupstream_error. - Confirma que se trata de un error 503 y no de un 429 (cuota) o 400 (parámetros).
Paso 2: Evaluar el alcance del impacto
- Comprueba si Gemini 2.5 Flash Image funciona con normalidad (generalmente no se ve afectado).
- Verifica si los modelos de texto de Gemini funcionan bien (normalmente no se ven afectados).
- Si todos los modelos presentan anomalías, podría tratarse de un fallo de GCP a mayor escala.
Paso 3: Activar la conmutación por error (failover)
- Si ya tienes desplegado un disyuntor (circuit breaker): el sistema cambiará automáticamente, no se requiere intervención manual.
- Si no está desplegado: cambia manualmente el parámetro
modelpor un modelo alternativo.
Paso 4: Monitoreo continuo y recuperación
- Los errores 503 en Gemini 3 Pro Image suelen recuperarse en un lapso de 30 a 120 minutos.
- Tras la recuperación, se recomienda realizar primero pruebas en lotes pequeños para confirmar la estabilidad antes de volver al modelo original.
🚀 Recuperación rápida: Se recomienda utilizar la interfaz unificada de la plataforma APIYI (apiyi.com) para realizar la conmutación por error. No es necesario modificar la
base_urlen tu código; solo tienes que cambiar el parámetromodelpara alternar sin interrupciones entre diferentes modelos.
Preguntas frecuentes
Q1: ¿Se cobrará por los errores 503 de Gemini 3 Pro Image?
No. El error 503 indica que la solicitud no fue procesada por el servidor, por lo que no genera ningún cargo. Esto es diferente de una respuesta exitosa 200: solo se facturan las solicitudes que generan imágenes con éxito. Al realizar llamadas a través de la plataforma APIYI (apiyi.com), se sigue esta misma regla y las solicitudes fallidas no se cobran.
Q2: ¿Cuánto dura el error 503? ¿Cuánto aumentará el costo al usar modelos alternativos?
Según datos históricos, los errores 503 en Gemini 3 Pro Image suelen durar entre 30 y 120 minutos. La diferencia de costo con los modelos alternativos es mínima: Seedream 4.5 cuesta aproximadamente $0.04 por imagen, GPT Image 1.5 entre $0.04 y $0.12 por imagen, y FLUX 2 Pro unos $0.03 por imagen. Al usar la plataforma APIYI (apiyi.com) de forma unificada, puedes obtener precios más competitivos y el costo de cambiar de modelo es prácticamente nulo.
Q3: ¿Cómo saber si el 503 es una sobrecarga temporal o un fallo prolongado?
Observa dos indicadores: primero, si Gemini 2.5 Flash Image (del mismo ecosistema) funciona con normalidad (si es así, se trata de una sobrecarga local); segundo, revisa si hay anuncios en la página oficial de estado de Google status.cloud.google.com. Si pasan más de 2 horas sin recuperación y no hay avisos oficiales, se recomienda cambiar proactivamente al modelo alternativo como opción principal.
Q4: ¿Es muy compleja la integración de una arquitectura de recuperación ante desastres multimodelo?
Si conectas las API de cada proveedor por separado, definitivamente es complejo: requiere mantener múltiples SDK, claves de autenticación y sistemas de facturación. Sin embargo, a través de una plataforma de interfaz unificada como APIYI (apiyi.com), todos los modelos comparten la misma base_url y API Key. La conmutación por error solo requiere modificar el parámetro model, por lo que la complejidad de integración es extremadamente baja.
Resumen: Cómo construir un servicio de generación de imágenes por IA a prueba de caídas
Los errores 503 en Gemini 3 Pro Image son habituales durante la fase Preview. La clave está en preparar con antelación una estrategia de respaldo con múltiples modelos:
- No dependas de un solo modelo: Incluso Google no puede garantizar una disponibilidad del 100% para sus modelos en fase Preview.
- Prioriza el downgrade dentro del mismo ecosistema: Gemini 2.5 Flash Image es la opción de respaldo más económica y directa.
- Mantén una reserva de modelos de distintos proveedores: Seedream 4.5, GPT Image 1.5 y FLUX 2 Pro tienen fortalezas únicas.
- Implementa una arquitectura de recuperación automática: El patrón de "disyuntor" (circuit breaker) permite realizar cambios automáticos sin necesidad de intervención manual.
- Muestra el estado del servicio en productos para el usuario final: Informar de forma transparente sobre el estado del servicio ayuda a retener a los usuarios mucho mejor que una espera en silencio.
Te recomendamos usar APIYI apiyi.com para validar rápidamente tus planes de contingencia: una interfaz unificada, una sola clave y la posibilidad de cambiar entre múltiples modelos al instante.
Referencias
-
Foro de desarrolladores de Google AI: Discusión sobre errores 503 en Gemini 3 Pro Image
- Enlace:
discuss.ai.google.dev - Descripción: Comentarios de la comunidad y respuestas oficiales de Google.
- Enlace:
-
Página de estado de Google AI Studio: Estado del servicio en tiempo real
- Enlace:
aistudio.google.com/status - Descripción: Consulta la disponibilidad en tiempo real de cada modelo.
- Enlace:
-
Página oficial de Seedream 4.5: El modelo de generación de imágenes de ByteDance
- Enlace:
seed.bytedance.com/en/seedream4_5 - Descripción: Capacidades del modelo y documentación de la API.
- Enlace:
-
Documentación de OpenAI GPT Image 1.5: El modelo más reciente de generación de imágenes
- Enlace:
platform.openai.com/docs/models/gpt-image-1.5 - Descripción: Parámetros del modelo e información de precios.
- Enlace:
📝 Autor: APIYI Team | Para consultas técnicas, visita APIYI apiyi.com
📅 Fecha de actualización: 19 de febrero de 2026
🏷️ Palabras clave: Error 503 Gemini 3 Pro Image, alternativas de modelos para generación de imágenes por IA, arquitectura de tolerancia a fallos, Seedream 4.5, GPT Image 1.5