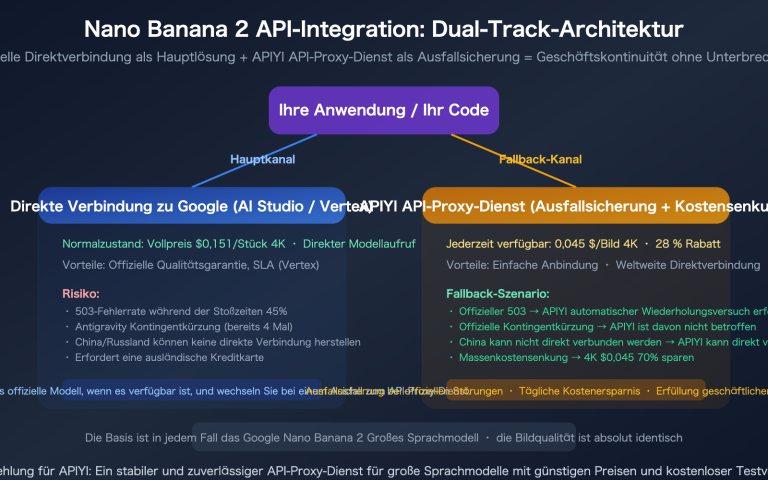
Am 19. Februar 2026 meldeten zahlreiche Entwickler, dass das Modell gemini-3-pro-image-preview kontinuierlich 503-Fehler zurückgibt – das ist kein Problem Ihres Kontos, sondern eine Überlastung der Google-Server. Die Fehlermeldung besagt eindeutig: „This model is currently experiencing high demand“. Es fallen zwar keine Gebühren an, aber es können auch keinerlei Bilder generiert werden.
Noch wichtiger ist, dass dies kein Einzelfall ist. Seit Ende 2025 kam es bei den Gemini-Bildmodellen bereits mehrfach zu ähnlichen Überlastungen während der Stoßzeiten. Zur gleichen Zeit liefen die erste Generation gemini-2.5-flash-image (das ursprüngliche Nano Banana Pro Modell) und die Gemini-Textserie normal – was darauf hindeutet, dass das Problem spezifisch bei der Rechenleistungskapazität für Gemini 3 Pro Image liegt.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die Methoden zur Fehlerbehebung bei 503-Fehlern, 5 zuverlässige alternative Bildgenerierungsmodelle und eine implementierbare Multi-Modell-Disaster-Recovery-Architektur beherrschen.
Vollständige Analyse des Gemini 3 Pro Image 503-Fehlers
Was der 503-Fehler wirklich bedeutet
Wenn Sie die folgende Fehlermeldung erhalten:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
Handelt es sich um ein serverseitiges Kapazitätsproblem, nicht um einen Client-Fehler. Im Gegensatz zum 429-Fehler (persönliches Kontingentlimit) bedeutet 503, dass der von Google für das Gemini 3 Pro Image Preview-Modell zugewiesene Inferenz-Server-Cluster insgesamt überlastet ist und alle Nutzer betroffen sind.
503-Fehler vs. andere häufige Fehler im Vergleich
| Fehlercode | Bedeutung | Abrechnung? | Auswirkungsbereich | Wiederherstellungszeit |
|---|---|---|---|---|
| 503 | Serverüberlastung | ❌ Nein | Global alle Nutzer | 30-120 Minuten |
| 429 | Kontingent erschöpft | ❌ Nein | Nur aktuelles Konto | Warten auf Refresh |
| 400 | Parameterfehler | ❌ Nein | Nur aktuelle Anfrage | Parameter korrigieren |
| 500 | Interner Serverfehler | ❌ Nein | Unklar | Meist wenige Minuten |
Warum 503 so häufig auftritt
Gemini 3 Pro Image befindet sich derzeit in der Preview-Phase und läuft auf einem gemeinsam genutzten Inferenz-Server-Pool. Laut Community-Monitoring-Daten ist die 503-Fehlerrate zu folgenden Zeiten am höchsten:
| Zeitraum (Pekinger Zeit) | Fehlerrate | Ursachenanalyse |
|---|---|---|
| 00:00 – 02:00 | ca. 35% | Peak während der nordamerikanischen Arbeitszeit |
| 09:00 – 11:00 | ca. 40% | Peak durch morgendliche Tests asiatischer Entwickler |
| 20:00 – 23:00 | ca. 45% | Globaler kumulierter Peak |
| Andere Zeiten | ca. 5-10% | Reguläre Schwankungen |
🎯 Praxistipp: Wenn Ihr Geschäft von KI-Bildgenerierung abhängt, reicht ein einzelnes Modell nicht aus. Wir empfehlen den Zugriff auf verschiedene Bildmodelle über APIYI (apiyi.com), um einen automatischen Disaster-Recovery-Wechsel zu implementieren und Single-Point-of-Failure-Risiken zu vermeiden.
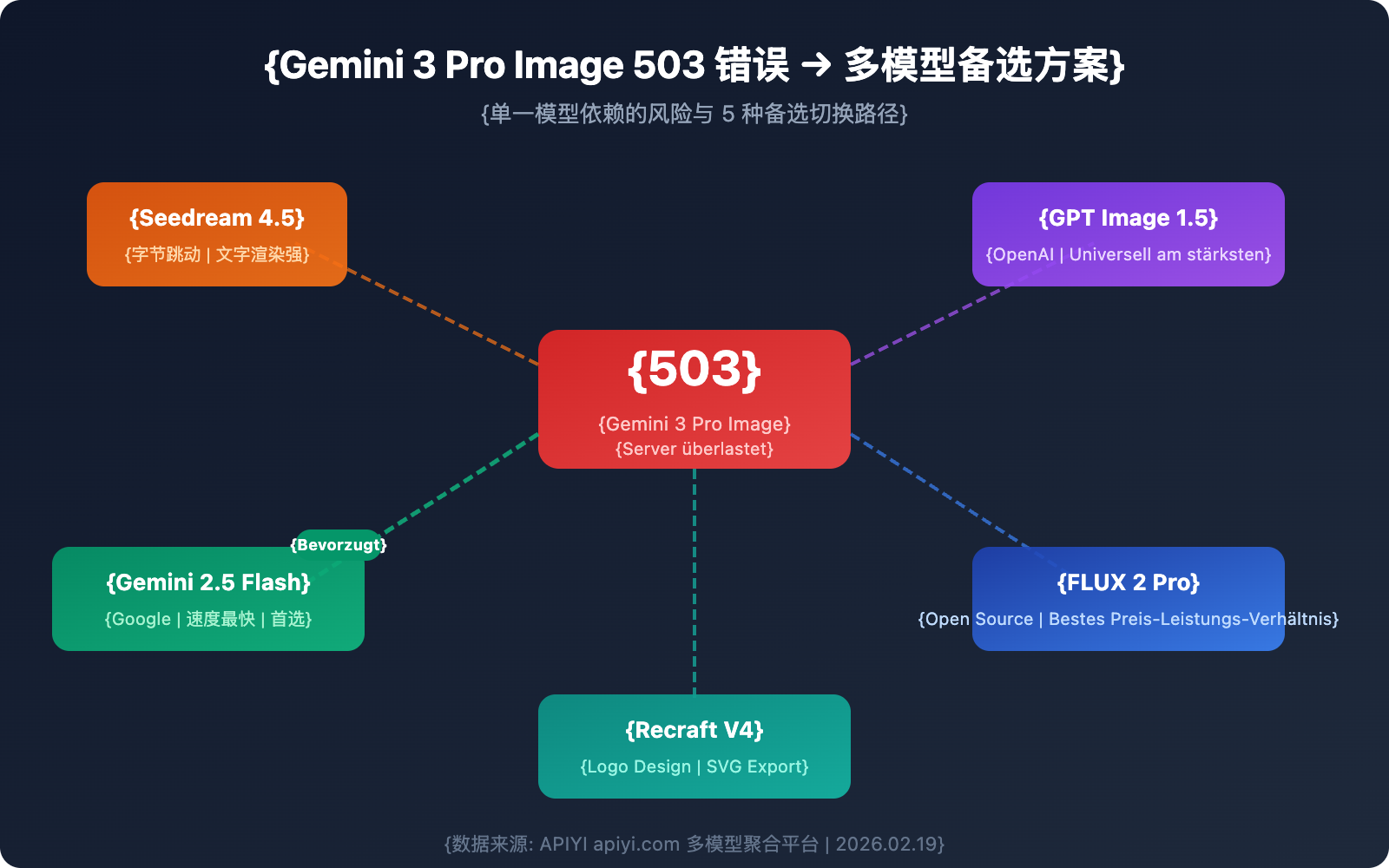
5 Alternativen zu Gemini 3 Pro Image für die Bildgenerierung
Wenn Gemini 3 Pro Image nicht verfügbar ist, können die folgenden 5 Modelle als zuverlässige Alternativen dienen.

Alternative 1: Seedream 4.5 (ByteDance)
Seedream 4.5 ist ein von ByteDance entwickeltes Bildgenerierungsmodell, das auf der LM Arena Bestenliste mit 1147 Punkten den 10. Platz belegt.
Kernvorteile:
- Herausragendes Text-Rendering: Kann lesbaren Text präzise in Bildern generieren, ideal für Marketingmaterialien und Poster.
- Hochauflösende Ausgabe: Unterstützt bis zu 2048×2048 Pixel (4K-Niveau).
- Hohe Konsistenz: Details von Charakteren, Objekten und Umgebungen bleiben über mehrere Bilder hinweg konsistent.
- Filmreife Ästhetik: Farben und Komposition entsprechen professionellen Fotografie-Standards.
Anwendungsbereiche: E-Commerce-Produktbilder, Marken-Marketingmaterialien, Bilder mit präzisem Text-Rendering.
Beachtenswert: Seedream 5.0 wird voraussichtlich am 24. Februar 2026 veröffentlicht und soll neue Funktionen wie Websuche, Beispiel-Editierung und logisches Denken bieten.
Alternative 2: GPT Image 1.5 (OpenAI)
Das neueste Bildgenerierungsmodell von OpenAI, veröffentlicht im Dezember 2025, ist eines der leistungsstärksten Text-zu-Bild-Modelle für allgemeine Szenarien.
Kernvorteile:
- Präzise Bearbeitung: Ermöglicht das gezielte Ändern bestimmter Bildbereiche nach dem Hochladen, ohne andere Elemente zu beeinträchtigen.
- Umfangreiches Weltwissen: Kann Szenendetails basierend auf dem Kontext ableiten (z. B. führt die Eingabe „Bethel, New York, 1969“ zur Darstellung des Woodstock-Festivals).
- Klares Text-Rendering: Präzise Typografie mit hohem Kontrast.
- Geschwindigkeitsschub: Viermal schneller als GPT Image 1.0.
Preis: 0,04 $ – 0,12 $ pro Bild (je nach Qualitätseinstellung), etwa 20 % günstiger als GPT Image 1.0.
Alternative 3: FLUX 2 Pro (Black Forest Labs)
Die FLUX-Serie ist der Maßstab im Bereich der Open-Source-Bildgenerierung. FLUX 2 Pro bietet eine exzellente Balance zwischen Qualität und Preis-Leistung.
Kernvorteile:
- Extrem wirtschaftlich: Mit ca. 0,03 $ pro Bild die kostengünstigste Wahl für hohe Qualität.
- Ausgereiftes Open-Source-Ökosystem: Kann privat bereitgestellt werden (On-Premise), was die Datensicherheit garantiert.
- Aktive Community: Eine große Anzahl an Fine-tuned Modellen und LoRAs ist verfügbar.
- Ideal für Stapelverarbeitung: Bestens geeignet für die Generierung großer Bildmengen.
Anwendungsbereiche: Massenproduktion von Inhalten, budgetsensitive Projekte, Unternehmen mit Bedarf an privater Bereitstellung.
Alternative 4: Gemini 2.5 Flash Image (Erste Generation Nano Banana Pro)
Gehört ebenfalls zum Google-Ökosystem, nutzt jedoch eine andere Architektur. Wenn Gemini 3 Pro Image ausfällt, bleibt dieses Modell oft unbeeinflusst.
Kernvorteile:
- Höchste Geschwindigkeit: Ca. 3–5 Sekunden pro Bild, deutlich schneller als andere Modelle.
- Hohe Stabilität: Während der Preview-Phase ist die Serverlast geringer; 503-Fehler werden meist innerhalb von 5–15 Minuten behoben.
- Ergänzung zu Gemini 3: Durch die unabhängige Architektur gibt es keinen "Single Point of Failure".
- Geringe Kosten: Attraktive Preisgestaltung, ideal für hochfrequente Aufrufe.
Anwendungsbereiche: Echtzeitanwendungen mit hohen Geschwindigkeitsanforderungen, primäre Fallback-Lösung für Gemini 3.
Alternative 5: Recraft V4
Recraft V4 belegt in HuggingFace-Benchmarks den ersten Platz und ist besonders stark in den Bereichen Logo- und Brand-Design.
Kernvorteile:
- Bestes Logo-Design: Gilt im Jahr 2026 als die Nummer eins für KI-generierte Logos.
- SVG-Export: Generiert Vektorgrafiken, die unendlich skalierbar sind.
- Markenstil-Tools: Integrierte Farbpaletten und Kontrollen für die Markenkonsistenz.
- Professionelle Design-Ausgabe: Geeignet für formelle geschäftliche und gestalterische Zwecke.
Anwendungsbereiche: Logo-Design, Markenidentität, Szenarien, die Vektorausgaben erfordern.
Vergleich der 5 Alternativmodelle
| Modell | Geschwindigkeit | Qualität | Preis | Text-Rendering | Stabilität | Verfügbare Plattformen |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~0,04 $/Bild | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com etc. |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 0,04-0,12 $/Bild | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com etc. |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~0,03 $/Bild | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com etc. |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Extrem niedrig | ⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com etc. |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~0,04 $/Bild | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | APIYI apiyi.com etc. |
Design einer Multi-Modell-Architektur für automatische Disaster Recovery
Nur die Alternativen zu kennen reicht nicht aus; eine echte Produktionsumgebung benötigt einen automatisierten Failover-Mechanismus. Hier ist eine bewährte Multi-Modell-Architektur für die Disaster Recovery.
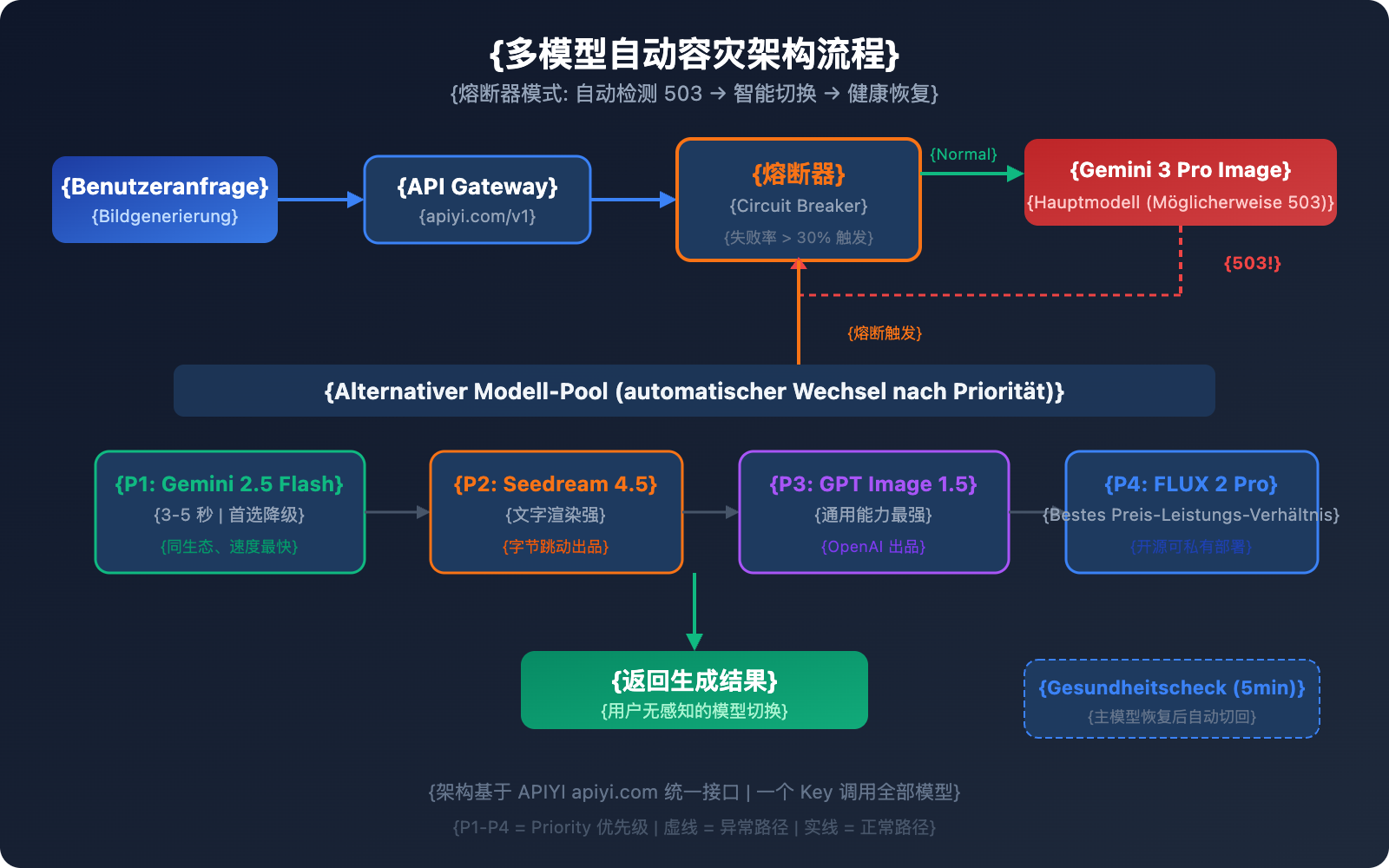
Kern der Architektur: Das Circuit-Breaker-Muster
Ein Circuit Breaker (Schutzschalter) verfolgt die Fehlerrate über ein gleitendes Zeitfenster (Sliding Window). Wenn die Fehlerrate einen Schwellenwert überschreitet, wird automatisch auf ein Alternativmodell umgeschaltet:
import openai
import time
# Konfiguration für Multi-Modell-Disaster-Recovery
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle, ein Key für alle Modelle
)
def generate_with_fallback(prompt, models=MODELS):
"""Bildgenerierung mit Multi-Modell-Failover"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[Failover] {model['name']} nicht verfügbar, wechsle zum nächsten Modell")
continue
raise e
return {"success": False, "error": "Alle Modelle sind nicht verfügbar"}
Vollständigen Implementierungscode des Circuit Breakers ansehen
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""Modell-Schutzschalter - erkennt Fehler automatisch und schaltet um"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 30% Fehlerrate löst Schutzschalter aus
self.window_size = window_size # Gleitendes Fenster von 60 Sekunden
self.recovery_time = recovery_time # 300 Sekunden Wartezeit vor Wiederherstellung
self.requests = deque()
self.state = "closed" # closed=Normalbetrieb, open=Schutzschalter aktiv, half_open=Wiederherstellungsversuch
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# Veraltete Datensätze bereinigen
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# Fehlerrate prüfen
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open erlaubt Testanfragen
class MultiModelImageGenerator:
"""Multi-Modell-Bildgenerator mit Disaster Recovery"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""Generierung mit Multi-Modell-Failover und Circuit Breaker"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[Circuit Breaker] {name} ist aktiv, überspringe")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[Erfolg] Generierung mit {name} abgeschlossen")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[Fehler] {name}: {e}")
continue
return {"success": False, "error": "Alle Modelle sind nicht verfügbar oder durch Schutzschalter blockiert"}
# Anwendungsbeispiel
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("Eine süße Katze, die in der Sonne döst")
if result["success"]:
print(f"Verwendetes Modell: {result['model']}")
Empfehlungen zur Failover-Priorität
| Priorität | Modell | Grund für Wechsel | Wiederherstellungsstrategie |
|---|---|---|---|
| Hauptmodell | Gemini 3 Pro Image | Beste Qualität | Automatisch nach bestandenem Health Check |
| Alternative 1 | Gemini 2.5 Flash Image | Gleiches Ökosystem, am schnellsten | Downgrade nach Wiederherstellung des Hauptmodells |
| Alternative 2 | Seedream 4.5 | Ähnliche Qualität, starkes Text-Rendering | Downgrade nach Wiederherstellung des Hauptmodells |
| Alternative 3 | GPT Image 1.5 | Stärkste Allround-Fähigkeiten | Downgrade nach Wiederherstellung des Hauptmodells |
| Alternative 4 | FLUX 2 Pro | Gutes Preis-Leistungs-Verhältnis, Open Source kontrollierbar | Downgrade nach Wiederherstellung des Hauptmodells |
💡 Architektur-Tipp: Über die einheitliche Schnittstelle von APIYI (apiyi.com) können Sie alle oben genannten Modelle mit nur einem einzigen API-Key aufrufen. Sie müssen sich nicht separat mit verschiedenen Anbietern verbinden, was die Implementierungskosten für Multi-Modell-Disaster-Recovery drastisch senkt.
Statusanzeige-Lösungen für Endkunden-Produkte
Für Produkte, die sich an Endnutzer richten, sollte das Frontend eine klare Statusanzeige bieten, wenn ein Modell nicht verfügbar ist. Dies ist eine Fallback-Lösung, die im Alltag selten benötigt wird, aber in kritischen Momenten Nutzerbeschwerden und Abwanderung massiv reduziert.
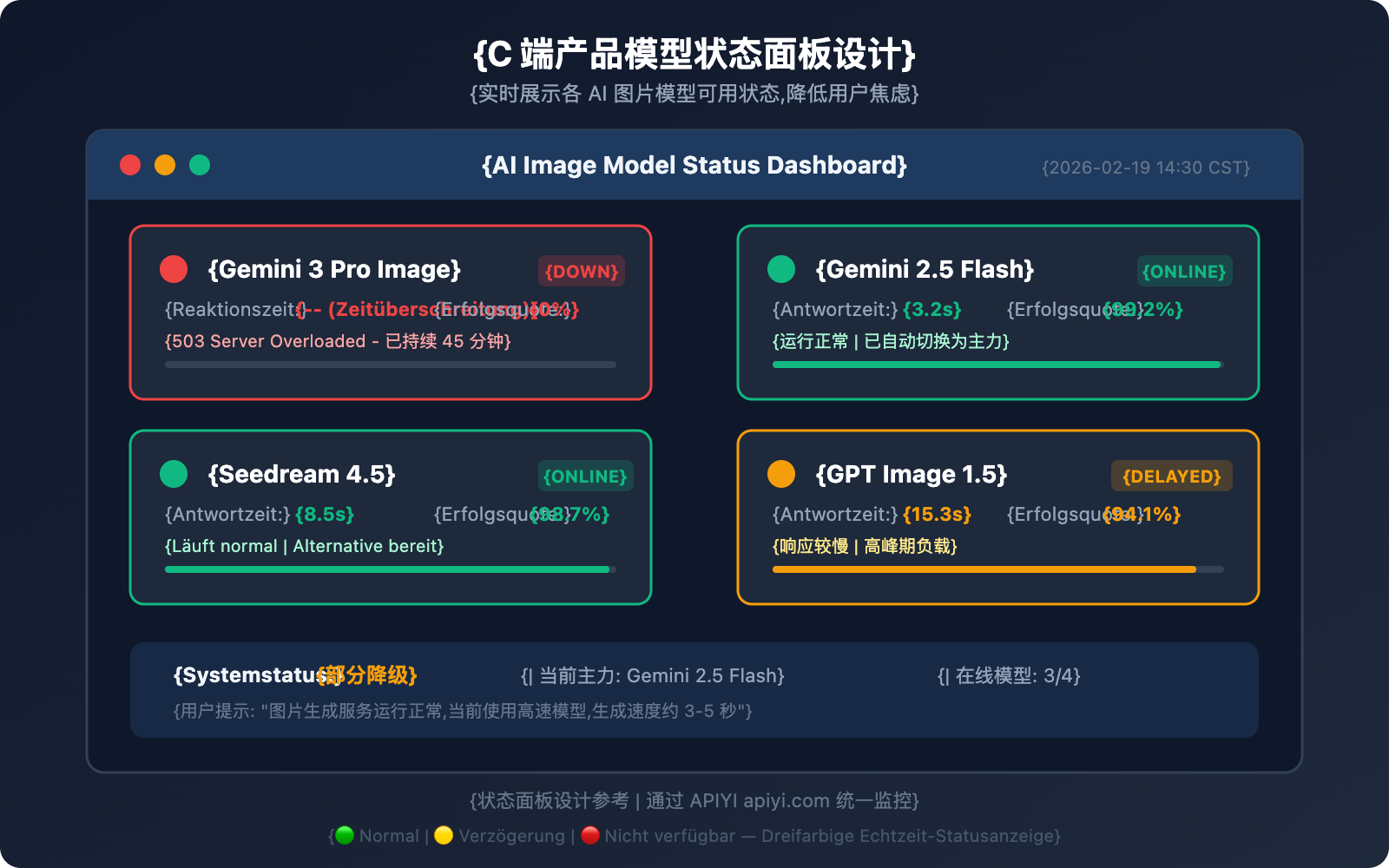
Wichtige Punkte beim Design der Statusanzeige
Drei-Farben-Statusanzeige:
- 🟢 Normal: Modell ist verfügbar, Antwortzeiten liegen im Normbereich.
- 🟡 Verzögerung: Modell ist verfügbar, aber die Antwortzeit ist deutlich erhöht (mehr als das Doppelte des Normalwerts).
- 🔴 Nicht verfügbar: Modell gibt 503 zurück oder weist kontinuierliche Fehler auf.
Empfehlungen für die Frontend-Anzeige:
// Beispiel für den API-Aufruf zur Überprüfung des Modellstatus
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
Strategien zur Optimierung der User Experience
| Strategie | Beschreibung | Implementierung |
|---|---|---|
| Echtzeit-Statusseite | Anzeige der Verfügbarkeit aller Modelle direkt im Produkt | Regelmäßiges Polling + WebSocket-Push |
| Automatischer Modellwechsel | Für den Nutzer unsichtbarer Wechsel auf ein Backup-Modell im Backend | Circuit Breaker + Prioritätswarteschlange |
| Warteschlangen-Hinweis | Anzeige der Position in der Warteschlange und geschätzte Wartezeit bei hoher Last | Request-Queue + Fortschritts-Push |
| Fallback-Hinweis | Information an den Nutzer, dass aktuell ein Alternativmodell verwendet wird | Frontend Toast-Benachrichtigung |
💰 Kosten und Nutzererlebnis im Einklang: Über die Plattform APIYI (apiyi.com) können Sie alle oben genannten Statusprüfungen und Modellwechsel-Logiken mit einer einheitlichen Schnittstelle implementieren, ohne mehrere SDKs und Authentifizierungssysteme warten zu müssen.
Notfall-Prozess bei Gemini 3 Pro Image 503-Fehlern
Wenn ein 503-Fehler auftritt, gehen Sie nach folgendem Prozess vor:
Schritt 1: Fehlertyp bestätigen
- Prüfen Sie, ob die Fehlermeldung
high demandoderupstream_errorenthält. - Stellen Sie sicher, dass es sich um einen 503-Fehler handelt und nicht um 429 (Quote) oder 400 (Parameter).
Schritt 2: Umfang der Auswirkungen beurteilen
- Prüfen Sie, ob Gemini 2.5 Flash Image normal funktioniert (meistens nicht betroffen).
- Prüfen Sie, ob Gemini-Textmodelle normal funktionieren (meistens nicht betroffen).
- Sollten alle Modelle gestört sein, liegt möglicherweise ein umfassenderer GCP-Ausfall vor.
Schritt 3: Disaster-Recovery-Umschaltung einleiten
- Falls ein Circuit Breaker (Schutzschalter) implementiert ist: Das System schaltet automatisch um, kein manuelles Eingreifen erforderlich.
- Falls nicht implementiert: Ändern Sie den
model-Parameter manuell auf ein Alternativmodell.
Schritt 4: Kontinuierliche Überwachung der Wiederherstellung
- Ein 503-Fehler bei Gemini 3 Pro Image wird normalerweise innerhalb von 30 bis 120 Minuten behoben.
- Nach der Wiederherstellung wird empfohlen, zunächst kleine Testmengen durchzuführen, um die Stabilität zu bestätigen, bevor Sie vollständig zurückschalten.
🚀 Schnelle Wiederherstellung: Wir empfehlen die Nutzung der einheitlichen Schnittstelle der Plattform APIYI (apiyi.com) für die Disaster Recovery. Die
base_urlim Code muss nicht geändert werden – passen Sie einfach denmodel-Parameter an, um nahtlos zwischen verschiedenen Modellen zu wechseln.
Häufig gestellte Fragen (FAQ)
Q1: Werden für Gemini 3 Pro Image 503-Fehler Gebühren berechnet?
Nein. Ein 503-Fehler bedeutet, dass die Anfrage nicht vom Server verarbeitet wurde; es entstehen keine Kosten. Dies unterscheidet sich von einer erfolgreichen 200-Antwort – nur Anfragen, die erfolgreich ein Bild generieren, werden abgerechnet. Bei Aufrufen über die Plattform APIYI (apiyi.com) gilt dieselbe Regel: Fehlgeschlagene Anfragen werden nicht berechnet.
Q2: Wie lange dauert ein 503-Fehler? Wie stark erhöhen sich die Kosten bei Nutzung von Alternativmodellen?
Historischen Daten zufolge dauern 503-Fehler bei Gemini 3 Pro Image meist 30 bis 120 Minuten. Die Kostenunterschiede bei Alternativmodellen sind gering: Seedream 4.5 ca. $0,04/Bild, GPT Image 1.5 ca. $0,04–0,12/Bild, FLUX 2 Pro ca. $0,03/Bild. Durch die zentrale Nutzung über die Plattform APIYI (apiyi.com) können Sie günstigere Preise erhalten, und der Aufwand für den Wechsel ist nahezu null.
Q3: Wie unterscheide ich zwischen temporärer Überlastung und einem längeren Ausfall?
Beobachten Sie zwei Indikatoren: Erstens, ob Gemini 2.5 Flash Image im selben Ökosystem normal funktioniert (wenn ja, handelt es sich um eine lokale Überlastung). Zweitens, ob auf der offiziellen Google-Statusseite status.cloud.google.com Ankündigungen vorliegen. Wenn der Fehler länger als 2 Stunden anhält und keine offizielle Meldung vorliegt, empfiehlt es sich, aktiv auf ein Alternativmodell als Hauptmodell umzusteigen.
Q4: Ist der Aufwand für die Integration einer Multi-Modell-Architektur hoch?
Wenn Sie die APIs der verschiedenen Anbieter einzeln anbinden, ist dies in der Tat komplex – Sie müssten mehrere SDKs, Authentifizierungsschlüssel und Abrechnungssysteme verwalten. Über eine einheitliche Schnittstellenplattform wie APIYI (apiyi.com) nutzen jedoch alle Modelle dieselbe base_url und denselben API-Key. Die Disaster-Recovery-Umschaltung erfordert lediglich die Änderung des model-Parameters, was den Integrationsaufwand extrem gering hält.
Fazit: Aufbau eines ausfallsicheren KI-Bildgenerierungsdienstes
Gemini 3 Pro Image 503-Fehler sind in der Preview-Phase völlig normal. Der Schlüssel liegt darin, frühzeitig Multi-Modell-Fallback-Lösungen vorzubereiten:
- Verlassen Sie sich nicht auf ein einziges Modell: Selbst Google kann keine 100%ige Verfügbarkeit für Preview-Modelle garantieren.
- Bevorzugen Sie Downgrades innerhalb desselben Ökosystems: Gemini 2.5 Flash Image ist die kostengünstigste erste Wahl als Backup.
- Anbieterübergreifende Modellreserven: Seedream 4.5, GPT Image 1.5 und FLUX 2 Pro haben jeweils ihre eigenen Stärken.
- Implementieren Sie eine automatische Disaster-Recovery-Architektur: Das Circuit-Breaker-Muster ermöglicht einen automatischen Wechsel ohne manuelles Eingreifen.
- Statusanzeige für Endnutzer: Transparente Statusinformationen binden Nutzer besser als stilles Warten.
Wir empfehlen die schnelle Validierung von Multi-Modell-Ausfallsicherungen über APIYI (apiyi.com) – eine einheitliche Schnittstelle, ein API-Key und jederzeitiger Wechsel zwischen verschiedenen Modellen.
Referenzen
-
Google AI Entwicklerforum: Diskussion über Gemini 3 Pro Image 503-Fehler
- Link:
discuss.ai.google.dev - Beschreibung: Community-Feedback und offizielle Antworten von Google.
- Link:
-
Google AI Studio Statusseite: Echtzeit-Dienststatus
- Link:
aistudio.google.com/status - Beschreibung: Einsehen der Echtzeit-Verfügbarkeit der einzelnen Modelle.
- Link:
-
Offizielle Seite von Seedream 4.5: Bildgenerierungsmodell von ByteDance
- Link:
seed.bytedance.com/en/seedream4_5 - Beschreibung: Modellfunktionen und API-Dokumentation.
- Link:
-
OpenAI GPT Image 1.5 Dokumentation: Das neueste Bildgenerierungsmodell
- Link:
platform.openai.com/docs/models/gpt-image-1.5 - Beschreibung: Modellparameter und Preisinformationen.
- Link:
📝 Autor: APIYI Team | Für technischen Austausch besuchen Sie bitte APIYI (apiyi.com)
📅 Aktualisierungsdatum: 19. Februar 2026
🏷️ Schlagworte: Gemini 3 Pro Image 503-Fehler, Multi-Modell-Alternativen für KI-Bildgenerierung, Disaster-Recovery-Architektur, Seedream 4.5, GPT Image 1.5