2026 年 2 月 19 日,大量開發者反饋 gemini-3-pro-image-preview 模型持續返回 503 錯誤——這不是你的賬號問題,是谷歌側服務器過載。錯誤信息明確寫着:「This model is currently experiencing high demand」,且不會產生計費,但也完全無法生成圖片。
更關鍵的是,這並非個例。從 2025 年底至今,Gemini 圖片模型已多次出現類似的高峯期過載。同一時間,第一代 gemini-2.5-flash-image(即 Nano Banana Pro 初代模型)和 Gemini 文本系列運行正常——說明問題集中在 Gemini 3 Pro Image 的算力分配上。
核心價值: 讀完本文,你將掌握 503 錯誤的排查方法、5 種可靠的備選圖片生成模型,以及一套可落地的多模型自動容災架構。

Gemini 3 Pro Image 503 錯誤完整解析
503 錯誤到底意味着什麼
當你收到如下錯誤信息時:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
這是一個服務端容量問題,不是客戶端錯誤。與 429 錯誤(個人配額限制)不同,503 表示谷歌爲 Gemini 3 Pro Image Preview 模型分配的推理服務器集羣整體過載,所有用戶都會受影響。
503 錯誤 vs 其他常見錯誤對比
| 錯誤碼 | 含義 | 是否計費 | 影響範圍 | 恢復時間 |
|---|---|---|---|---|
| 503 | 服務器過載 | ❌ 不計費 | 全局所有用戶 | 30-120 分鐘 |
| 429 | 個人配額耗盡 | ❌ 不計費 | 僅當前賬號 | 等待配額刷新 |
| 400 | 請求參數錯誤 | ❌ 不計費 | 僅當前請求 | 修改參數即可 |
| 500 | 內部服務器錯誤 | ❌ 不計費 | 不確定 | 通常幾分鐘 |
爲什麼 503 頻繁發生
Gemini 3 Pro Image 目前處於 Preview 階段,運行在共享推理服務器池上。根據社區監控數據,以下時段 503 錯誤率最高:
| 時段 (北京時間) | 錯誤率 | 原因分析 |
|---|---|---|
| 00:00 – 02:00 | 約 35% | 北美工作時間高峯 |
| 09:00 – 11:00 | 約 40% | 亞太開發者早間測試高峯 |
| 20:00 – 23:00 | 約 45% | 全球疊加高峯 |
| 其他時段 | 約 5-10% | 常規波動 |
🎯 實戰建議: 如果你的業務依賴 AI 圖片生成,僅靠單一模型是不夠的。我們建議通過 API易 apiyi.com 接入多種圖片模型,實現自動容災切換,避免單點故障影響業務。
5 種 Gemini 3 Pro Image 備選圖片生成模型
當 Gemini 3 Pro Image 不可用時,以下 5 種模型可以作爲可靠備選方案。

備選方案 1: Seedream 4.5 (字節跳動)
Seedream 4.5 是字節跳動推出的圖片生成模型,在 LM Arena 排行榜上排名第 10,得分 1147。
核心優勢:
- 文字渲染能力突出: 能在圖片中準確生成可讀文本,適合營銷材料、海報
- 高分辨率輸出: 支持 2048×2048 像素,達到 4K 級別
- 一致性強: 角色、物體、環境細節在多張圖片間保持一致
- 電影級美學: 色彩和構圖接近專業攝影水準
適用場景: 電商產品圖、品牌營銷素材、需要精確文字渲染的圖片
值得關注: Seedream 5.0 預計 2026 年 2 月 24 日發佈,將新增網絡搜索、示例編輯和邏輯推理能力。
備選方案 2: GPT Image 1.5 (OpenAI)
OpenAI 於 2025 年 12 月發佈的最新圖片生成模型,是目前通用場景下最強的文生圖模型之一。
核心優勢:
- 精確編輯: 上傳圖片後精確修改指定部分,不破壞其他元素
- 世界知識豐富: 能根據上下文推斷場景細節(如輸入「1969年紐約伯特利」能推斷出伍德斯托克音樂節)
- 文字渲染清晰: 字體排版精準,對比度高
- 速度提升: 比 GPT Image 1.0 快 4 倍
價格: $0.04-$0.12/張(取決於質量設置),比 GPT Image 1.0 便宜 20%
備選方案 3: FLUX 2 Pro (Black Forest Labs)
FLUX 系列是開源圖片生成領域的標杆,FLUX 2 Pro 在質量和性價比之間取得了優秀平衡。
核心優勢:
- 性價比極高: 約 $0.03/張,是最經濟的高質量選擇
- 開源生態完善: 可私有化部署,數據安全有保障
- 社區活躍: 大量微調模型和 LoRA 可用
- 批量處理友好: 適合大規模圖片生成任務
適用場景: 批量內容生產、預算敏感項目、需要私有化部署的企業
備選方案 4: Gemini 2.5 Flash Image (Nano Banana Pro 初代)
同屬谷歌生態,但架構不同,當 Gemini 3 Pro Image 宕機時往往不受影響。
核心優勢:
- 速度最快: 約 3-5 秒/張,遠快於其他模型
- 穩定性高: Preview 階段服務器負載較低,503 恢復通常只需 5-15 分鐘
- 與 Gemini 3 互補: 架構獨立,不存在單點故障
- 成本低: 定價友好,適合高頻調用
適用場景: 對速度要求高的實時應用、作爲 Gemini 3 的首選降級方案
備選方案 5: Recraft V4
Recraft V4 在 HuggingFace 基準測試中排名第一,尤其擅長 Logo 和品牌設計。
核心優勢:
- Logo 設計最強: 2026 年 AI Logo 生成領域公認第一
- 支持 SVG 導出: 生成矢量圖形,可無限縮放
- 品牌風格工具: 內置品牌色板和風格一致性控制
- 專業設計級輸出: 適合正式的商業和設計用途
適用場景: Logo 設計、品牌視覺、需要矢量輸出的場景
5 種備選模型綜合對比
| 模型 | 速度 | 質量 | 價格 | 文字渲染 | 穩定性 | 可用平臺 |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/張 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | $0.04-0.12/張 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~$0.03/張 | ⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 極低 | ⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/張 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
多模型自動容災架構設計
僅僅知道備選方案還不夠,真正的生產環境需要自動化的容災切換機制。以下是一套經過驗證的多模型容災架構。
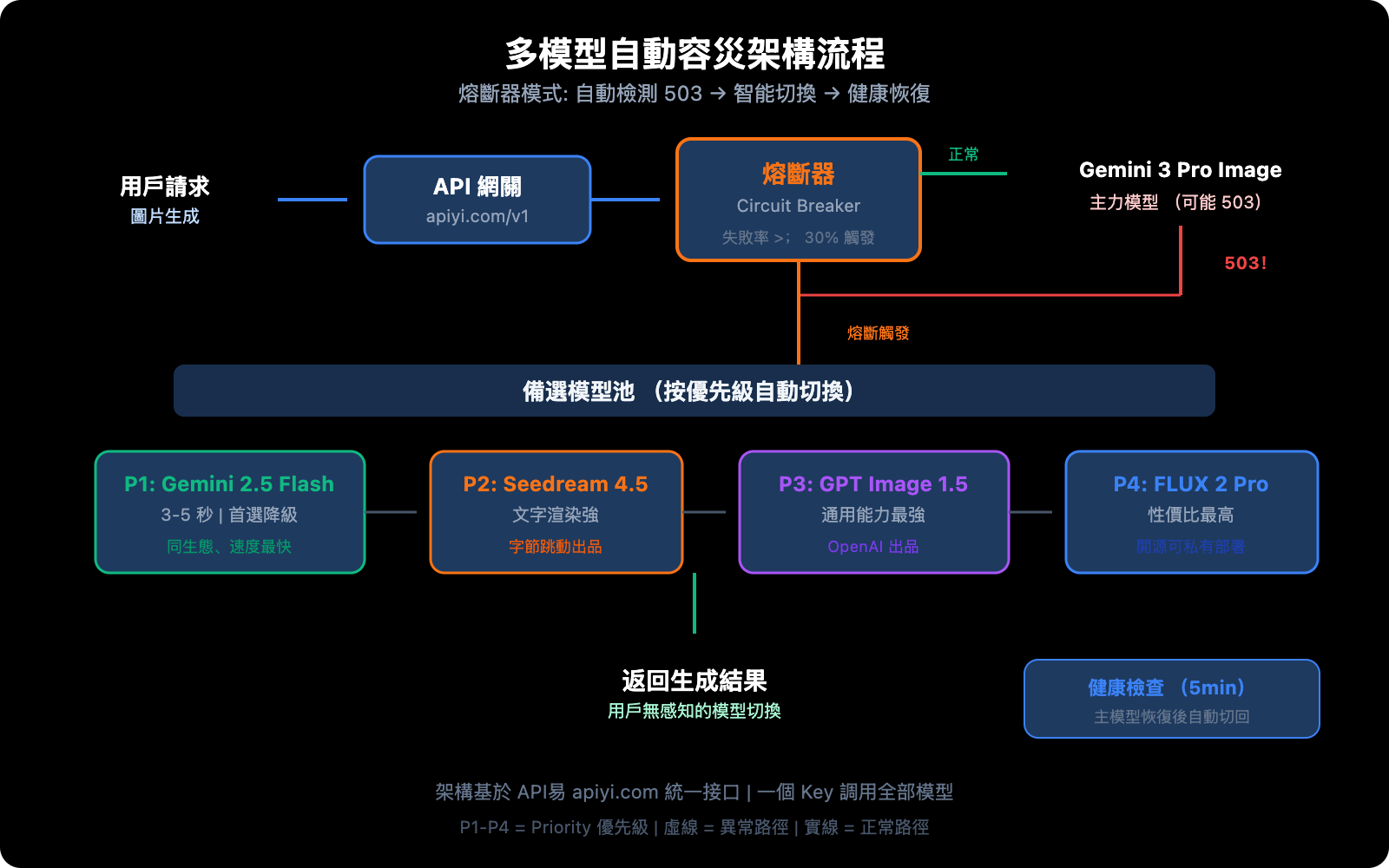
架構核心: 熔斷器模式
熔斷器(Circuit Breaker)通過滑動窗口追蹤失敗率,當故障率超過閾值時自動切換到備選模型:
import openai
import time
# 多模型容災配置
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口,一個 key 調用所有模型
)
def generate_with_fallback(prompt, models=MODELS):
"""多模型容災圖片生成"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[容災切換] {model['name']} 不可用,切換下一個模型")
continue
raise e
return {"success": False, "error": "所有模型均不可用"}
查看完整熔斷器實現代碼
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""模型熔斷器 - 自動檢測故障並切換"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 30% 失敗率觸發熔斷
self.window_size = window_size # 60秒滑動窗口
self.recovery_time = recovery_time # 300秒恢復等待
self.requests = deque()
self.state = "closed" # closed=正常, open=熔斷, half_open=恢復中
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# 清理過期記錄
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# 檢查失敗率
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open 允許試探請求
class MultiModelImageGenerator:
"""多模型容災圖片生成器"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # API易統一接口
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""帶熔斷器的多模型容災生成"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[熔斷中] {name} 已熔斷,跳過")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[成功] 使用 {name} 生成完成")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[失敗] {name}: {e}")
continue
return {"success": False, "error": "所有模型均不可用或已熔斷"}
# 使用示例
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("一隻可愛的貓咪在陽光下打盹")
if result["success"]:
print(f"使用模型: {result['model']}")
容災切換優先級建議
| 優先級 | 模型 | 切換原因 | 恢復策略 |
|---|---|---|---|
| 主力 | Gemini 3 Pro Image | 質量最優 | 健康檢查通過後自動恢復 |
| 一級備選 | Gemini 2.5 Flash Image | 同生態、速度最快 | 主力恢復後降級 |
| 二級備選 | Seedream 4.5 | 質量接近、文字渲染強 | 主力恢復後降級 |
| 三級備選 | GPT Image 1.5 | 通用能力最強 | 主力恢復後降級 |
| 四級備選 | FLUX 2 Pro | 性價比高、開源可控 | 主力恢復後降級 |
💡 架構建議: 通過 API易 apiyi.com 的統一接口,你只需一個 API Key 即可調用以上所有模型,無需分別對接不同廠商,大幅降低多模型容災的接入成本。
C 端產品可用狀態展示方案
對於面向終端用戶的產品,當模型不可用時,前端應有清晰的狀態展示。這是兜底方案,平時用不着,但關鍵時刻能大幅降低用戶投訴和流失。
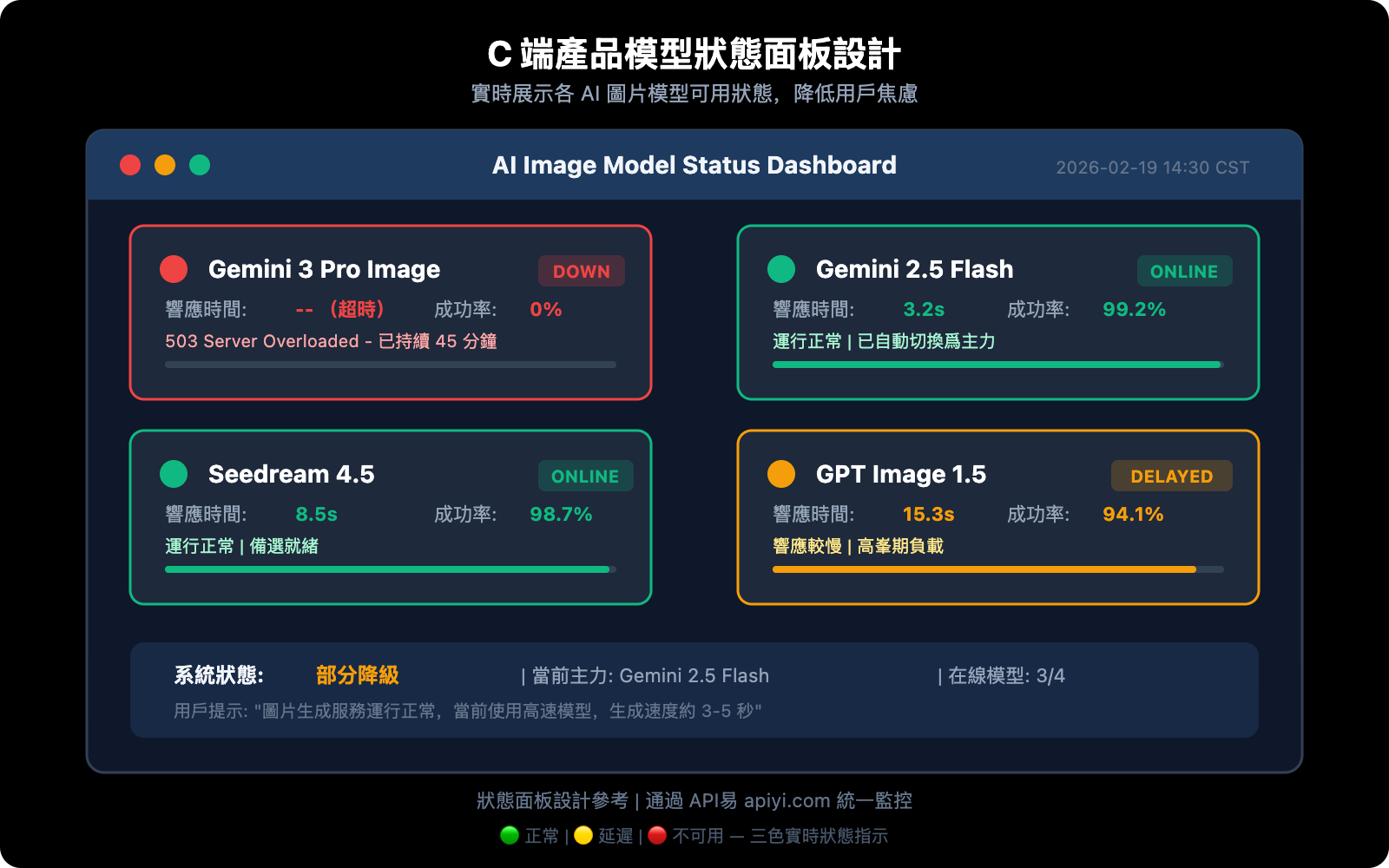
狀態展示設計要點
三色狀態指示:
- 🟢 正常: 模型可用,響應時間正常
- 🟡 延遲: 模型可用但響應變慢(超過正常值 2 倍)
- 🔴 不可用: 模型返回 503 或連續失敗
前端展示建議:
// 模型狀態檢查 API 調用示例
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
用戶體驗優化策略
| 策略 | 說明 | 實現方式 |
|---|---|---|
| 實時狀態頁 | 在產品頁面展示各模型可用狀態 | 定時輪詢 + WebSocket 推送 |
| 自動模型切換 | 用戶無感知的後端模型切換 | 熔斷器 + 優先級隊列 |
| 排隊提示 | 高峯期顯示排隊位置和預計等待時間 | 請求隊列 + 進度推送 |
| 降級說明 | 告知用戶當前使用的是備選模型 | 前端 Toast 提示 |
💰 成本與體驗兼顧: 通過 API易 apiyi.com 平臺,你可以用統一的接口實現以上所有狀態檢查和模型切換邏輯,無需維護多套 SDK 和認證體系。
Gemini 3 Pro Image 503 錯誤應急處理流程
遇到 503 錯誤時,按以下流程處理:
第一步: 確認錯誤類型
- 檢查錯誤信息是否包含
high demand或upstream_error - 確認是 503 而非 429(配額)或 400(參數)
第二步: 判斷影響範圍
- 檢查 Gemini 2.5 Flash Image 是否正常(通常不受影響)
- 檢查 Gemini 文本模型是否正常(通常不受影響)
- 如果所有模型都異常,可能是更大範圍的 GCP 故障
第三步: 啓動容災切換
- 若已部署熔斷器:系統自動切換,無需手動干預
- 若未部署:手動將 model 參數改爲備選模型
第四步: 持續監控恢復
- Gemini 3 Pro Image 的 503 通常 30-120 分鐘恢復
- 恢復後建議先小批量測試,確認穩定再切回
🚀 快速恢復: 推薦使用 API易 apiyi.com 平臺的統一接口進行容災切換。無需修改代碼中的 base_url,只需切換 model 參數即可在不同模型之間無縫切換。
常見問題
Q1: Gemini 3 Pro Image 503 錯誤會扣費嗎?
不會。503 錯誤表示請求未被服務器處理,不會產生任何費用。這與 200 成功響應不同——只有成功生成圖片的請求才會計費。通過 API易 apiyi.com 平臺調用時同樣遵循此規則,失敗請求不計費。
Q2: 503 錯誤持續多久?用備選模型會增加多少成本?
根據歷史數據,Gemini 3 Pro Image 的 503 錯誤通常持續 30-120 分鐘。備選模型的成本差異不大:Seedream 4.5 約 $0.04/張,GPT Image 1.5 約 $0.04-0.12/張,FLUX 2 Pro 約 $0.03/張。通過 API易 apiyi.com 平臺統一調用,可以獲得更優惠的價格,且切換成本幾乎爲零。
Q3: 如何判斷 503 是臨時過載還是長時間故障?
觀察兩個指標:一是同生態的 Gemini 2.5 Flash Image 是否正常(正常說明是局部過載);二是谷歌官方狀態頁 status.cloud.google.com 是否有公告。如果超過 2 小時未恢復且無官方通告,建議主動切換到備選模型作爲主力。
Q4: 多模型容災架構的接入複雜度高嗎?
如果分別對接各廠商 API,確實複雜——需要維護多套 SDK、認證密鑰和計費體系。但通過統一接口平臺(如 API易 apiyi.com),所有模型共用同一個 base_url 和 API Key,容災切換隻需修改 model 參數,接入複雜度極低。
總結: 構建不怕宕機的 AI 圖片生成服務
Gemini 3 Pro Image 503 錯誤是 Preview 階段的常態,關鍵是提前做好多模型備選方案:
- 不要依賴單一模型: 即便是谷歌,也無法保證 Preview 模型的 100% 可用性
- 優先選擇同生態降級: Gemini 2.5 Flash Image 是最低成本的首選備選
- 跨廠商多模型儲備: Seedream 4.5、GPT Image 1.5、FLUX 2 Pro 各有所長
- 部署自動容災架構: 熔斷器模式實現零人工干預的自動切換
- C 端產品做好狀態展示: 透明的狀態信息比沉默的等待更能留住用戶
推薦通過 API易 apiyi.com 快速驗證多模型容災方案——統一接口、一個密鑰、多種模型隨時切換。
參考資料
-
Google AI 開發者論壇: Gemini 3 Pro Image 503 錯誤討論
- 鏈接:
discuss.ai.google.dev - 說明: 社區反饋和谷歌官方回覆
- 鏈接:
-
Google AI Studio 狀態頁: 實時服務狀態
- 鏈接:
aistudio.google.com/status - 說明: 查看各模型實時可用狀態
- 鏈接:
-
Seedream 4.5 官方頁面: 字節跳動圖片生成模型
- 鏈接:
seed.bytedance.com/en/seedream4_5 - 說明: 模型能力和 API 文檔
- 鏈接:
-
OpenAI GPT Image 1.5 文檔: 最新圖片生成模型
- 鏈接:
platform.openai.com/docs/models/gpt-image-1.5 - 說明: 模型參數和定價信息
- 鏈接:
📝 作者: APIYI Team | 技術交流請訪問 API易 apiyi.com
📅 更新時間: 2026 年 2 月 19 日
🏷️ 關鍵詞: Gemini 3 Pro Image 503 錯誤, AI 圖片生成多模型備選, 容災架構, Seedream 4.5, GPT Image 1.5