2026 年 2 月 19 日,大量开发者反馈 gemini-3-pro-image-preview 模型持续返回 503 错误——这不是你的账号问题,是谷歌侧服务器过载。错误信息明确写着:「This model is currently experiencing high demand」,且不会产生计费,但也完全无法生成图片。
更关键的是,这并非个例。从 2025 年底至今,Gemini 图片模型已多次出现类似的高峰期过载。同一时间,第一代 gemini-2.5-flash-image(即 Nano Banana Pro 初代模型)和 Gemini 文本系列运行正常——说明问题集中在 Gemini 3 Pro Image 的算力分配上。
核心价值: 读完本文,你将掌握 503 错误的排查方法、5 种可靠的备选图片生成模型,以及一套可落地的多模型自动容灾架构。

Gemini 3 Pro Image 503 错误完整解析
503 错误到底意味着什么
当你收到如下错误信息时:
{
"error": {
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"code": "upstream_error",
"status": 503
}
}
这是一个服务端容量问题,不是客户端错误。与 429 错误(个人配额限制)不同,503 表示谷歌为 Gemini 3 Pro Image Preview 模型分配的推理服务器集群整体过载,所有用户都会受影响。
503 错误 vs 其他常见错误对比
| 错误码 | 含义 | 是否计费 | 影响范围 | 恢复时间 |
|---|---|---|---|---|
| 503 | 服务器过载 | ❌ 不计费 | 全局所有用户 | 30-120 分钟 |
| 429 | 个人配额耗尽 | ❌ 不计费 | 仅当前账号 | 等待配额刷新 |
| 400 | 请求参数错误 | ❌ 不计费 | 仅当前请求 | 修改参数即可 |
| 500 | 内部服务器错误 | ❌ 不计费 | 不确定 | 通常几分钟 |
为什么 503 频繁发生
Gemini 3 Pro Image 目前处于 Preview 阶段,运行在共享推理服务器池上。根据社区监控数据,以下时段 503 错误率最高:
| 时段 (北京时间) | 错误率 | 原因分析 |
|---|---|---|
| 00:00 – 02:00 | 约 35% | 北美工作时间高峰 |
| 09:00 – 11:00 | 约 40% | 亚太开发者早间测试高峰 |
| 20:00 – 23:00 | 约 45% | 全球叠加高峰 |
| 其他时段 | 约 5-10% | 常规波动 |
🎯 实战建议: 如果你的业务依赖 AI 图片生成,仅靠单一模型是不够的。我们建议通过 API易 apiyi.com 接入多种图片模型,实现自动容灾切换,避免单点故障影响业务。
5 种 Gemini 3 Pro Image 备选图片生成模型
当 Gemini 3 Pro Image 不可用时,以下 5 种模型可以作为可靠备选方案。

备选方案 1: Seedream 4.5 (字节跳动)
Seedream 4.5 是字节跳动推出的图片生成模型,在 LM Arena 排行榜上排名第 10,得分 1147。
核心优势:
- 文字渲染能力突出: 能在图片中准确生成可读文本,适合营销材料、海报
- 高分辨率输出: 支持 2048×2048 像素,达到 4K 级别
- 一致性强: 角色、物体、环境细节在多张图片间保持一致
- 电影级美学: 色彩和构图接近专业摄影水准
适用场景: 电商产品图、品牌营销素材、需要精确文字渲染的图片
值得关注: Seedream 5.0 预计 2026 年 2 月 24 日发布,将新增网络搜索、示例编辑和逻辑推理能力。
备选方案 2: GPT Image 1.5 (OpenAI)
OpenAI 于 2025 年 12 月发布的最新图片生成模型,是目前通用场景下最强的文生图模型之一。
核心优势:
- 精确编辑: 上传图片后精确修改指定部分,不破坏其他元素
- 世界知识丰富: 能根据上下文推断场景细节(如输入「1969年纽约伯特利」能推断出伍德斯托克音乐节)
- 文字渲染清晰: 字体排版精准,对比度高
- 速度提升: 比 GPT Image 1.0 快 4 倍
价格: $0.04-$0.12/张(取决于质量设置),比 GPT Image 1.0 便宜 20%
备选方案 3: FLUX 2 Pro (Black Forest Labs)
FLUX 系列是开源图片生成领域的标杆,FLUX 2 Pro 在质量和性价比之间取得了优秀平衡。
核心优势:
- 性价比极高: 约 $0.03/张,是最经济的高质量选择
- 开源生态完善: 可私有化部署,数据安全有保障
- 社区活跃: 大量微调模型和 LoRA 可用
- 批量处理友好: 适合大规模图片生成任务
适用场景: 批量内容生产、预算敏感项目、需要私有化部署的企业
备选方案 4: Gemini 2.5 Flash Image (Nano Banana Pro 初代)
同属谷歌生态,但架构不同,当 Gemini 3 Pro Image 宕机时往往不受影响。
核心优势:
- 速度最快: 约 3-5 秒/张,远快于其他模型
- 稳定性高: Preview 阶段服务器负载较低,503 恢复通常只需 5-15 分钟
- 与 Gemini 3 互补: 架构独立,不存在单点故障
- 成本低: 定价友好,适合高频调用
适用场景: 对速度要求高的实时应用、作为 Gemini 3 的首选降级方案
备选方案 5: Recraft V4
Recraft V4 在 HuggingFace 基准测试中排名第一,尤其擅长 Logo 和品牌设计。
核心优势:
- Logo 设计最强: 2026 年 AI Logo 生成领域公认第一
- 支持 SVG 导出: 生成矢量图形,可无限缩放
- 品牌风格工具: 内置品牌色板和风格一致性控制
- 专业设计级输出: 适合正式的商业和设计用途
适用场景: Logo 设计、品牌视觉、需要矢量输出的场景
5 种备选模型综合对比
| 模型 | 速度 | 质量 | 价格 | 文字渲染 | 稳定性 | 可用平台 |
|---|---|---|---|---|---|---|
| Seedream 4.5 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/张 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| GPT Image 1.5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | $0.04-0.12/张 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| FLUX 2 Pro | ⭐⭐⭐ | ⭐⭐⭐⭐ | ~$0.03/张 | ⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| Gemini 2.5 Flash | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 极低 | ⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
| Recraft V4 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ~$0.04/张 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API易 apiyi.com 等 |
多模型自动容灾架构设计
仅仅知道备选方案还不够,真正的生产环境需要自动化的容灾切换机制。以下是一套经过验证的多模型容灾架构。
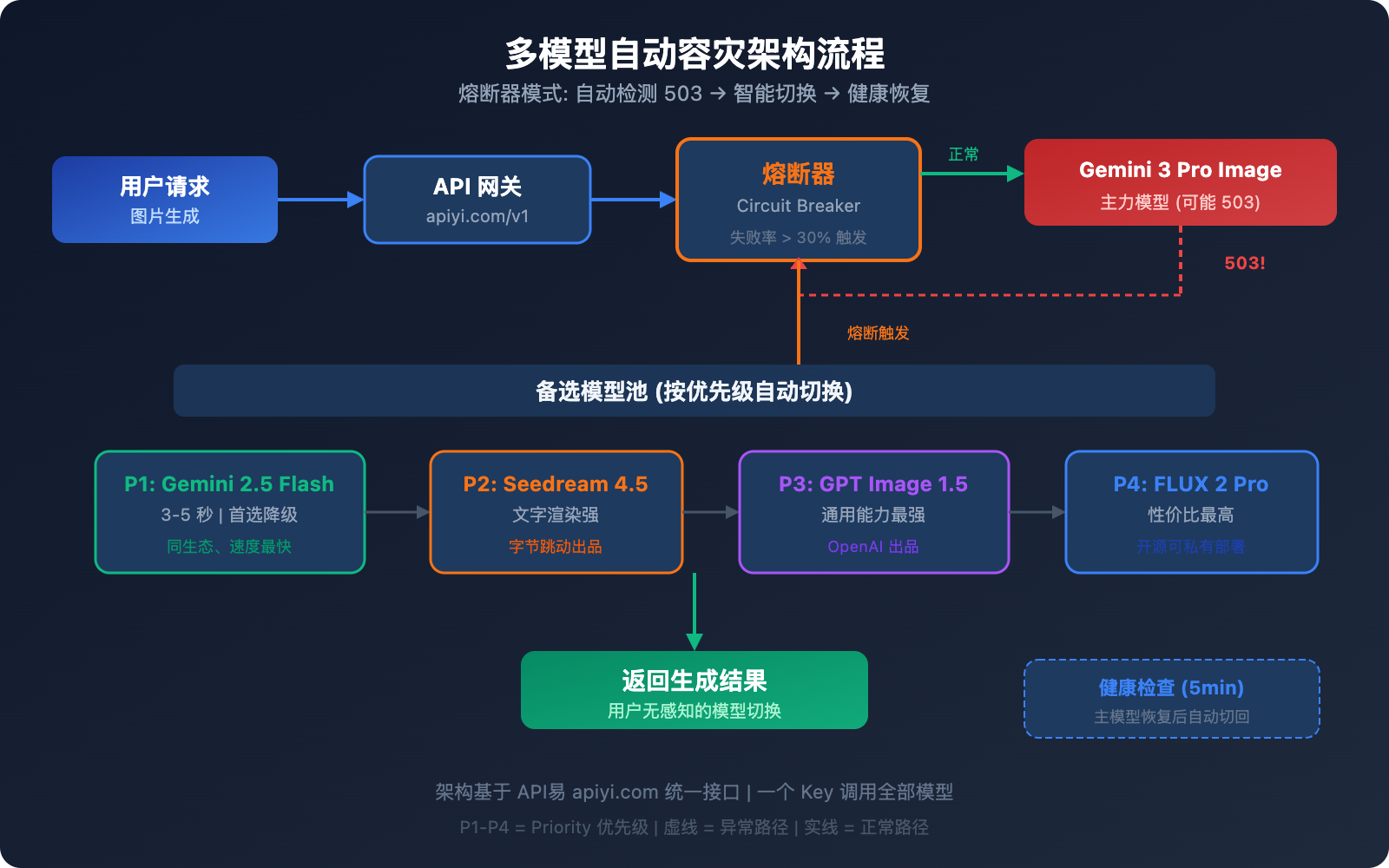
架构核心: 熔断器模式
熔断器(Circuit Breaker)通过滑动窗口追踪失败率,当故障率超过阈值时自动切换到备选模型:
import openai
import time
# 多模型容灾配置
MODELS = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口,一个 key 调用所有模型
)
def generate_with_fallback(prompt, models=MODELS):
"""多模型容灾图片生成"""
for model in models:
try:
response = client.images.generate(
model=model["name"],
prompt=prompt,
size="1024x1024"
)
return {"success": True, "model": model["name"], "data": response}
except Exception as e:
if "503" in str(e) or "overloaded" in str(e):
print(f"[容灾切换] {model['name']} 不可用,切换下一个模型")
continue
raise e
return {"success": False, "error": "所有模型均不可用"}
查看完整熔断器实现代码
import openai
import time
from collections import deque
from threading import Lock
class CircuitBreaker:
"""模型熔断器 - 自动检测故障并切换"""
def __init__(self, failure_threshold=0.3, window_size=60, recovery_time=300):
self.failure_threshold = failure_threshold # 30% 失败率触发熔断
self.window_size = window_size # 60秒滑动窗口
self.recovery_time = recovery_time # 300秒恢复等待
self.requests = deque()
self.state = "closed" # closed=正常, open=熔断, half_open=恢复中
self.last_failure_time = 0
self.lock = Lock()
def record(self, success: bool):
with self.lock:
now = time.time()
self.requests.append((now, success))
# 清理过期记录
while self.requests and self.requests[0][0] < now - self.window_size:
self.requests.popleft()
# 检查失败率
if len(self.requests) >= 5:
failure_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if failure_rate >= self.failure_threshold:
self.state = "open"
self.last_failure_time = now
def is_available(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.recovery_time:
self.state = "half_open"
return True
return False
return True # half_open 允许试探请求
class MultiModelImageGenerator:
"""多模型容灾图片生成器"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # API易统一接口
)
self.models = [
{"name": "gemini-3-pro-image-preview", "priority": 1},
{"name": "gemini-2.5-flash-image", "priority": 2},
{"name": "seedream-4.5", "priority": 3},
{"name": "gpt-image-1.5", "priority": 4},
{"name": "flux-2-pro", "priority": 5},
]
self.breakers = {m["name"]: CircuitBreaker() for m in self.models}
def generate(self, prompt: str, size: str = "1024x1024"):
"""带熔断器的多模型容灾生成"""
for model in self.models:
name = model["name"]
breaker = self.breakers[name]
if not breaker.is_available():
print(f"[熔断中] {name} 已熔断,跳过")
continue
try:
response = self.client.images.generate(
model=name,
prompt=prompt,
size=size
)
breaker.record(True)
print(f"[成功] 使用 {name} 生成完成")
return {"success": True, "model": name, "data": response}
except Exception as e:
breaker.record(False)
print(f"[失败] {name}: {e}")
continue
return {"success": False, "error": "所有模型均不可用或已熔断"}
# 使用示例
generator = MultiModelImageGenerator(api_key="YOUR_API_KEY")
result = generator.generate("一只可爱的猫咪在阳光下打盹")
if result["success"]:
print(f"使用模型: {result['model']}")
容灾切换优先级建议
| 优先级 | 模型 | 切换原因 | 恢复策略 |
|---|---|---|---|
| 主力 | Gemini 3 Pro Image | 质量最优 | 健康检查通过后自动恢复 |
| 一级备选 | Gemini 2.5 Flash Image | 同生态、速度最快 | 主力恢复后降级 |
| 二级备选 | Seedream 4.5 | 质量接近、文字渲染强 | 主力恢复后降级 |
| 三级备选 | GPT Image 1.5 | 通用能力最强 | 主力恢复后降级 |
| 四级备选 | FLUX 2 Pro | 性价比高、开源可控 | 主力恢复后降级 |
💡 架构建议: 通过 API易 apiyi.com 的统一接口,你只需一个 API Key 即可调用以上所有模型,无需分别对接不同厂商,大幅降低多模型容灾的接入成本。
C 端产品可用状态展示方案
对于面向终端用户的产品,当模型不可用时,前端应有清晰的状态展示。这是兜底方案,平时用不着,但关键时刻能大幅降低用户投诉和流失。
状态展示设计要点
三色状态指示:
- 🟢 正常: 模型可用,响应时间正常
- 🟡 延迟: 模型可用但响应变慢(超过正常值 2 倍)
- 🔴 不可用: 模型返回 503 或连续失败
前端展示建议:
// 模型状态检查 API 调用示例
const MODEL_STATUS_API = "https://api.apiyi.com/v1/models/status";
async function checkModelStatus() {
const models = [
"gemini-3-pro-image-preview",
"gemini-2.5-flash-image",
"seedream-4.5",
"gpt-image-1.5"
];
const statusMap = {};
for (const model of models) {
try {
const start = Date.now();
const res = await fetch(`${MODEL_STATUS_API}?model=${model}`);
const latency = Date.now() - start;
statusMap[model] = {
available: res.ok,
latency,
status: res.ok ? (latency > 5000 ? "delayed" : "normal") : "unavailable"
};
} catch {
statusMap[model] = { available: false, latency: -1, status: "unavailable" };
}
}
return statusMap;
}
用户体验优化策略
| 策略 | 说明 | 实现方式 |
|---|---|---|
| 实时状态页 | 在产品页面展示各模型可用状态 | 定时轮询 + WebSocket 推送 |
| 自动模型切换 | 用户无感知的后端模型切换 | 熔断器 + 优先级队列 |
| 排队提示 | 高峰期显示排队位置和预计等待时间 | 请求队列 + 进度推送 |
| 降级说明 | 告知用户当前使用的是备选模型 | 前端 Toast 提示 |
💰 成本与体验兼顾: 通过 API易 apiyi.com 平台,你可以用统一的接口实现以上所有状态检查和模型切换逻辑,无需维护多套 SDK 和认证体系。
Gemini 3 Pro Image 503 错误应急处理流程
遇到 503 错误时,按以下流程处理:
第一步: 确认错误类型
- 检查错误信息是否包含
high demand或upstream_error - 确认是 503 而非 429(配额)或 400(参数)
第二步: 判断影响范围
- 检查 Gemini 2.5 Flash Image 是否正常(通常不受影响)
- 检查 Gemini 文本模型是否正常(通常不受影响)
- 如果所有模型都异常,可能是更大范围的 GCP 故障
第三步: 启动容灾切换
- 若已部署熔断器:系统自动切换,无需手动干预
- 若未部署:手动将 model 参数改为备选模型
第四步: 持续监控恢复
- Gemini 3 Pro Image 的 503 通常 30-120 分钟恢复
- 恢复后建议先小批量测试,确认稳定再切回
🚀 快速恢复: 推荐使用 API易 apiyi.com 平台的统一接口进行容灾切换。无需修改代码中的 base_url,只需切换 model 参数即可在不同模型之间无缝切换。
常见问题
Q1: Gemini 3 Pro Image 503 错误会扣费吗?
不会。503 错误表示请求未被服务器处理,不会产生任何费用。这与 200 成功响应不同——只有成功生成图片的请求才会计费。通过 API易 apiyi.com 平台调用时同样遵循此规则,失败请求不计费。
Q2: 503 错误持续多久?用备选模型会增加多少成本?
根据历史数据,Gemini 3 Pro Image 的 503 错误通常持续 30-120 分钟。备选模型的成本差异不大:Seedream 4.5 约 $0.04/张,GPT Image 1.5 约 $0.04-0.12/张,FLUX 2 Pro 约 $0.03/张。通过 API易 apiyi.com 平台统一调用,可以获得更优惠的价格,且切换成本几乎为零。
Q3: 如何判断 503 是临时过载还是长时间故障?
观察两个指标:一是同生态的 Gemini 2.5 Flash Image 是否正常(正常说明是局部过载);二是谷歌官方状态页 status.cloud.google.com 是否有公告。如果超过 2 小时未恢复且无官方通告,建议主动切换到备选模型作为主力。
Q4: 多模型容灾架构的接入复杂度高吗?
如果分别对接各厂商 API,确实复杂——需要维护多套 SDK、认证密钥和计费体系。但通过统一接口平台(如 API易 apiyi.com),所有模型共用同一个 base_url 和 API Key,容灾切换只需修改 model 参数,接入复杂度极低。
总结: 构建不怕宕机的 AI 图片生成服务
Gemini 3 Pro Image 503 错误是 Preview 阶段的常态,关键是提前做好多模型备选方案:
- 不要依赖单一模型: 即便是谷歌,也无法保证 Preview 模型的 100% 可用性
- 优先选择同生态降级: Gemini 2.5 Flash Image 是最低成本的首选备选
- 跨厂商多模型储备: Seedream 4.5、GPT Image 1.5、FLUX 2 Pro 各有所长
- 部署自动容灾架构: 熔断器模式实现零人工干预的自动切换
- C 端产品做好状态展示: 透明的状态信息比沉默的等待更能留住用户
推荐通过 API易 apiyi.com 快速验证多模型容灾方案——统一接口、一个密钥、多种模型随时切换。
参考资料
-
Google AI 开发者论坛: Gemini 3 Pro Image 503 错误讨论
- 链接:
discuss.ai.google.dev - 说明: 社区反馈和谷歌官方回复
- 链接:
-
Google AI Studio 状态页: 实时服务状态
- 链接:
aistudio.google.com/status - 说明: 查看各模型实时可用状态
- 链接:
-
Seedream 4.5 官方页面: 字节跳动图片生成模型
- 链接:
seed.bytedance.com/en/seedream4_5 - 说明: 模型能力和 API 文档
- 链接:
-
OpenAI GPT Image 1.5 文档: 最新图片生成模型
- 链接:
platform.openai.com/docs/models/gpt-image-1.5 - 说明: 模型参数和定价信息
- 链接:
📝 作者: APIYI Team | 技术交流请访问 API易 apiyi.com
📅 更新时间: 2026 年 2 月 19 日
🏷️ 关键词: Gemini 3 Pro Image 503 错误, AI 图片生成多模型备选, 容灾架构, Seedream 4.5, GPT Image 1.5