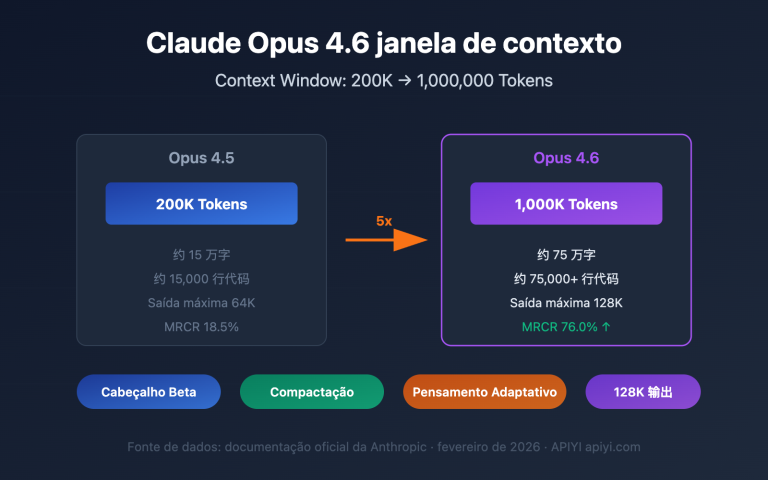
Como usar mais de 200 mil tokens de contexto em chamadas de API é uma necessidade real para cada vez mais desenvolvedores. A Anthropic lançou o recurso de Janela de Contexto de 1 Milhão de Tokens (1M Context Window) da Claude API, permitindo que uma única requisição processe cerca de 750 mil palavras — o equivalente a ler toda a obra de "Guerra e Paz" e ainda sobrar espaço.
Valor principal: Ao ler este artigo, você dominará o método completo para ativar a janela de contexto de 1M da Claude API, entenderá as regras de cálculo de preço e terá acesso a modelos de código para 5 cenários reais.

Detalhes de Preços da Janela de Contexto de 1M da API do Claude
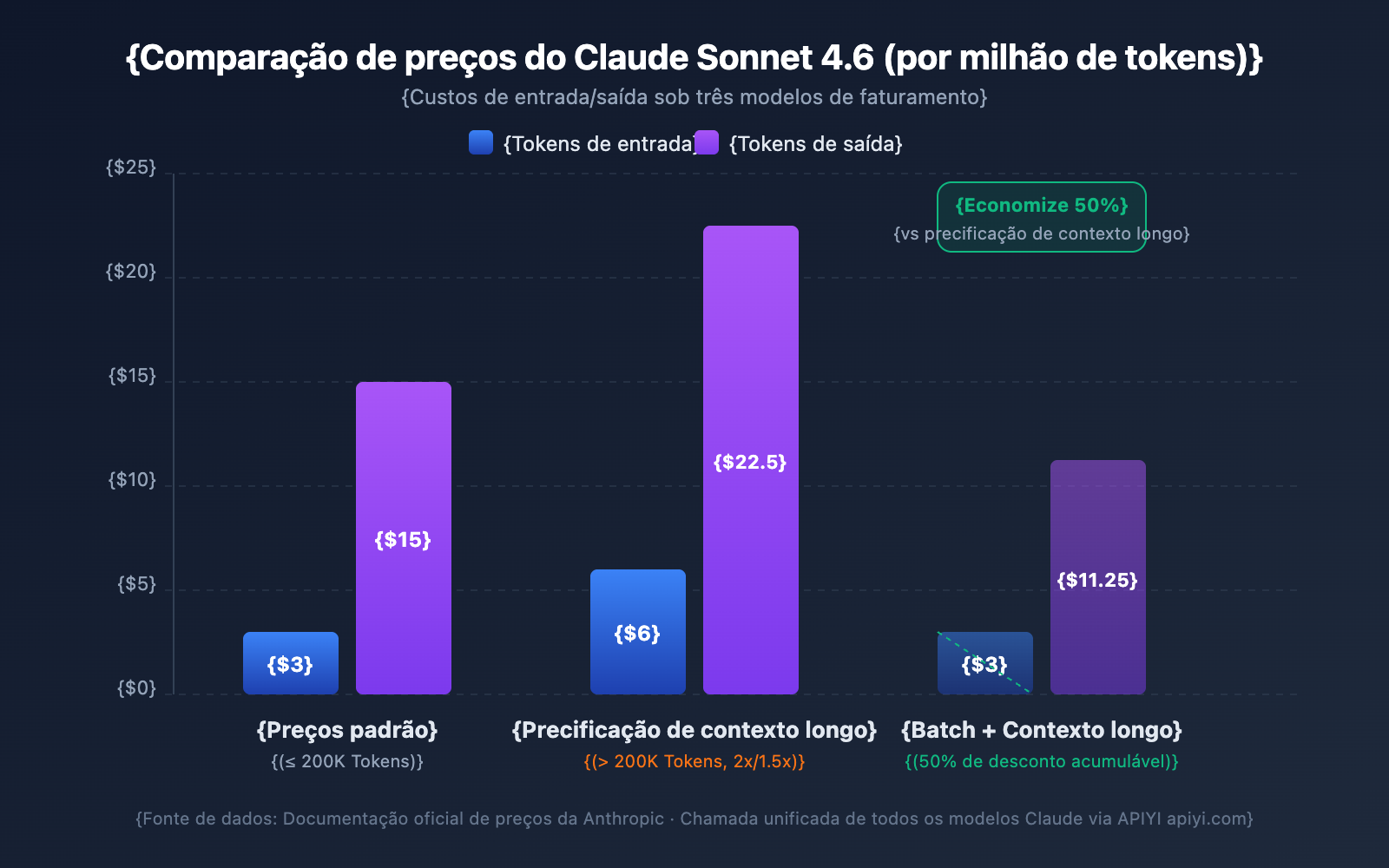
O preço para contextos longos é uma das maiores preocupações dos desenvolvedores. A API do Claude adotou uma estratégia de tarifação segmentada — o fato de os tokens de entrada ultrapassarem ou não os 200K determina a sua faixa de cobrança.
Comparação de Preços de Contexto Longo por Modelo
| Modelo | Entrada Padrão (≤200K) | Entrada de Contexto Longo (>200K) | Saída Padrão | Saída de Contexto Longo | Multiplicador |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $10/MTok | $25/MTok | $37.50/MTok | Entrada 2x / Saída 1.5x |
| Claude Sonnet 4.6 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Saída 1.5x |
| Claude Sonnet 4.5 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Saída 1.5x |
| Claude Sonnet 4 | $3/MTok | $6/MTok | $15/MTok | $22.50/MTok | Entrada 2x / Saída 1.5x |
MTok = Milhões de Tokens
Regras de Cálculo de Preços
Entenda algumas regras fundamentais para evitar custos inesperados:
- O limite de 200K é uma chave: Assim que o total de tokens de entrada ultrapassa 200K, todos os tokens da requisição são cobrados pelo preço de contexto longo, e não apenas a parte excedente.
- O total de tokens de entrada inclui o cache: A soma de
input_tokens+cache_creation_input_tokens+cache_read_input_tokensdetermina a faixa de preço. - Tokens de saída não afetam a faixa: A quantidade de tokens de saída não influencia se o preço de contexto longo será ativado, mas, uma vez ativado, a saída também é cobrada com o multiplicador de 1.5x.
- Abaixo de 200K continua no preço padrão: Mesmo que você ative o header beta, se a entrada não ultrapassar 200K, a cobrança será pelo preço padrão.
Exemplo de Cálculo de Custos
Cenário: Usar o Claude Sonnet 4.6 para analisar um documento longo de 500.000 tokens, gerando um relatório de análise de 2.000 tokens.
Custo de Entrada: 500.000 Tokens × $6/MTok = $3.00
Custo de Saída: 2.000 Tokens × $22.50/MTok = $0.045
Total: $3.045
Para a mesma saída, se a entrada fosse de apenas 150.000 tokens:
Custo de Entrada: 150.000 Tokens × $3/MTok = $0.45
Custo de Saída: 2.000 Tokens × $15/MTok = $0.03
Total: $0.48
4 Estratégias para Economizar
| Estratégia | Redução de Custo | Cenário Aplicável |
|---|---|---|
| Prompt Caching | Apenas 10% do custo no cache hit | Reutilização do mesmo documento longo |
| Batch API | 50% de desconto em todos os custos | Tarefas de processamento em lote não em tempo real |
| Fast Mode (Opus 4.6) | Sem acréscimo de contexto longo | Cenários que exigem resposta rápida |
| Controlar entrada abaixo de 200K | Evita o preço 2x | Documentos que podem ser processados em partes |
💰 Otimização de Custos: Para projetos que exigem chamadas frequentes ao contexto longo do Claude, você pode obter planos de tarifação flexíveis através da plataforma APIYI (apiyi.com). Combinando Prompt Caching e Batch API, o custo por chamada pode ser reduzido em mais de 70%.
Limites de Taxa (Rate Limits) da Janela de Contexto de 1M da API do Claude
Ao ativar o contexto de 1M, as requisições de contexto longo (entrada superior a 200K tokens) possuem limites de taxa independentes, calculados separadamente dos limites das requisições padrão.
Limites de Taxa do Tier 4
| Tipo de Limite | Limite de Requisição Padrão | Limite de Requisição de Contexto Longo |
|---|---|---|
| Tokens de Entrada Máximos/Minuto (ITPM) | Sonnet: 2.000.000 / Opus: 2.000.000 | 1.000.000 |
| Tokens de Saída Máximos/Minuto (OTPM) | Sonnet: 400.000 / Opus: 400.000 | 200.000 |
| Requisições Máximas/Minuto (RPM) | 4.000 | Reduzido proporcionalmente |
Observações Importantes:
- Os limites de taxa de contexto longo e os limites padrão são calculados de forma independente e não interferem um no outro.
- Ao usar Prompt Caching, os tokens que resultam em cache hit não contam para o limite de ITPM (na maioria dos modelos).
- Se precisar de limites de taxa de contexto longo mais altos, você pode entrar em contato com a equipe de vendas da Anthropic para solicitar um limite personalizado.
Como Fazer o Upgrade para o Tier 4
| Tier | Requisito de Depósito Acumulado | Depósito Máximo Único | Limite de Gasto Mensal |
|---|---|---|---|
| Tier 1 | $5 | $100 | $100 |
| Tier 2 | $40 | $500 | $500 |
| Tier 3 | $200 | $1.000 | $1.000 |
| Tier 4 | $400 | $5.000 | $5.000 |
O upgrade é automático assim que o limite de depósito acumulado é atingido, sem necessidade de revisão manual.
5 Cenários Práticos para a Janela de Contexto de 1M da Claude API
Cenário 1: Análise de Grandes Bases de Código
Envie todo o código do seu projeto para o Claude para realizar revisões de arquitetura, depuração de bugs ou sugestões de refatoração.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Coleta todos os arquivos de código-fonte do tipo especificado no projeto"""
code_content = []
for root, dirs, files in os.walk(directory):
# Pula diretórios como node_modules
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Por favor, realize uma revisão completa da arquitetura da seguinte base de código:
{codebase}
Por favor, analise:
1. Prós e contras do design da arquitetura geral
2. Potenciais vulnerabilidades de segurança
3. Sugestões de otimização de desempenho
4. Pontos de melhoria na qualidade do código"""
}]
)
Cenário 2: Análise Abrangente de Documentos Longos
Processe documentos extensos, como contratos jurídicos, coleções de artigos de pesquisa e relatórios financeiros.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Abaixo está uma coleção de relatórios financeiros da empresa dos últimos 12 meses (aprox. 400 mil tokens):
{financial_reports}
Por favor, complete:
1. Análise de tendências dos principais indicadores financeiros trimestrais
2. Mudanças na estrutura de receita e inferência das causas
3. Avaliação da eficácia do controle de custos
4. Previsão de desempenho para o próximo trimestre e alertas de risco"""
}]
)
Cenário 3: Combinação de Diálogos Longos de Múltiplos Turnos com Extended Thinking
Ative o Extended Thinking em contextos longos para permitir que o Claude realize raciocínios profundos:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""Abaixo está a documentação técnica completa e o código-fonte de um sistema complexo:
{large_technical_document}
Por favor, analise profundamente a filosofia de design deste sistema e apresente um plano de melhoria."""
}]
)
# Os tokens de Extended Thinking não se acumulam em diálogos subsequentes
# A API remove automaticamente os blocos de pensamento de turnos anteriores
Cenário 4: Uso de Prompt Caching para Reduzir Custos de Contexto Longo
Quando você precisa realizar várias análises de diferentes dimensões no mesmo documento longo, o Prompt Caching pode reduzir drasticamente os custos:
# Primeira solicitação: Armazenar documento longo em cache
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # Marcado como cacheável
}],
messages=[{"role": "user", "content": "Resuma os argumentos centrais deste documento"}]
)
# Segunda solicitação: Cache hit, os tokens de entrada custam apenas 10% do valor original
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Extraia todas as tabelas de dados do documento"}]
)
Cenário 5: Processamento em Lote de Documentos Longos via Batch API
O uso da Batch API pode oferecer um desconto adicional de 50% sobre o preço do contexto longo:
# Criar solicitação em lote
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Analise o documento 1: {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Analise o documento 2: {doc2}"}]
}
}
]
)
🎯 Dica Prática: Em projetos reais, recomendamos realizar testes em pequena escala através da plataforma APIYI apiyi.com para confirmar se o uso de tokens e os custos estão de acordo com o esperado antes de realizar uma implantação em larga escala. A plataforma oferece um painel detalhado de estatísticas de uso para facilitar o controle preciso dos custos.
Sugestões de Escolha de Modelo para a Janela de Contexto de 1M da Claude API
Os 4 modelos que suportam contexto de 1M têm focos diferentes; escolher o modelo certo permite encontrar o melhor equilíbrio entre desempenho e custo.
Comparação Detalhada dos Modelos com Suporte a Contexto de 1M
| Dimensão de Comparação | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Nível de Inteligência | Máximo | Forte | Forte | Médio-alto |
| Preço de Entrada Padrão | $5/MTok | $3/MTok | $3/MTok | $3/MTok |
| Preço de Entrada de Contexto Longo | $10/MTok | $6/MTok | $6/MTok | $6/MTok |
| Fast Mode | Suportado (Preço 6x) | Não suportado | Não suportado | Não suportado |
| Percepção de Contexto | Não suportado | Suportado | Suportado | Não suportado |
| Interleaved Thinking | Suportado | Suportado | Não suportado | Suportado |
| Cenários Recomendados | Raciocínio complexo, análise de código | Processamento geral de documentos longos | Sessões de agentes de múltiplos turnos | Tarefas de análise rotineiras |
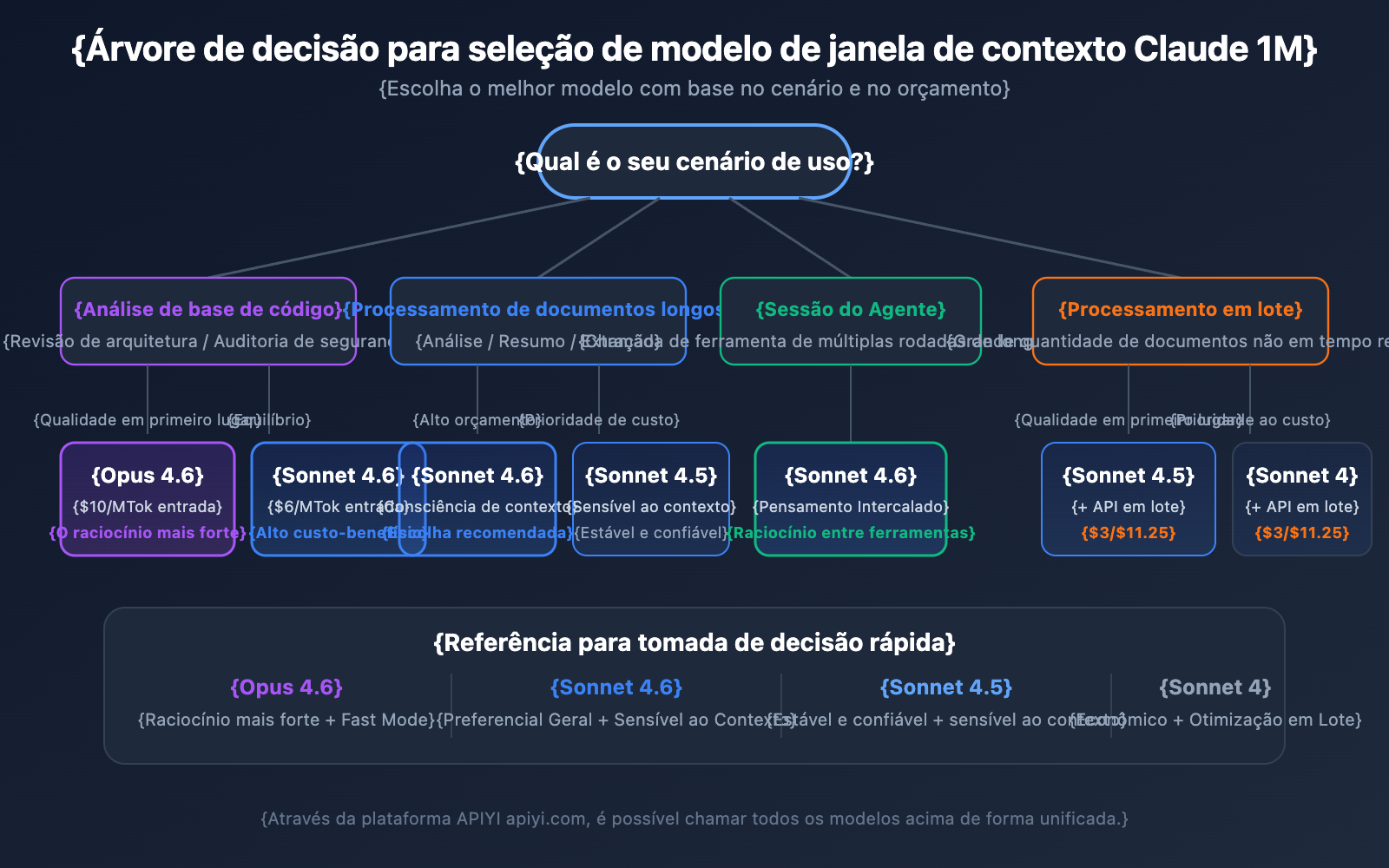
Escolha de Modelo por Cenário
Cenários para escolher o Claude Opus 4.6:
- Tarefas de análise complexas que exigem a maior capacidade de raciocínio.
- Revisão de arquitetura e auditoria de segurança de grandes bases de código.
- Cenários em tempo real que exigem Fast Mode (resposta rápida sem sobretaxa de contexto longo).
- Aplicações de nível empresarial com orçamento suficiente e prioridade na qualidade.
Cenários para escolher o Claude Sonnet 4.6:
- Análise diária de documentos longos e extração de resumos.
- Diálogos longos que exigem capacidade de percepção de contexto.
- Projetos sensíveis ao custo, mas que exigem alta qualidade.
- Necessidade de Interleaved Thinking para raciocínio entre chamadas de ferramentas.
Cenários para escolher o Claude Sonnet 4.5 / Sonnet 4:
- Processamento de documentos em lote (usando Batch API para reduzir custos).
- Extração de informações estruturadas e organização de dados.
- Ambientes de produção estáveis que não exigem os recursos mais recentes do modelo.
💡 Sugestão de Escolha: A escolha do modelo depende principalmente do seu cenário de aplicação específico e do seu orçamento. Recomendamos realizar testes comparativos reais através da plataforma APIYI apiyi.com, que suporta uma interface unificada para todos os modelos mencionados, facilitando a troca rápida e a avaliação.
Referência de Estimativa de Tokens para a Janela de Contexto de 1M da Claude API
Ao planejar o uso de contextos longos, é muito importante entender o consumo de tokens para diferentes tipos de conteúdo:
| Tipo de Conteúdo | Quantidade Aproximada de Tokens | Capacidade na Janela de 1M |
|---|---|---|
| Texto em Inglês | ~1 Token / 4 caracteres | Aprox. 3 milhões de caracteres |
| Texto em Chinês | ~1 Token / 1.5 caracteres | Aprox. 750 mil caracteres |
| Código Python | ~1 Token / 3.5 caracteres | Aprox. 2,5 milhões de caracteres |
| Página Web Comum (10KB) | ~2.500 Tokens | Aprox. 400 páginas web |
| Documento Grande (100KB) | ~25.000 Tokens | Aprox. 40 documentos |
| Artigo de Pesquisa em PDF (500KB) | ~125.000 Tokens | Aprox. 8 artigos |
Janela de Contexto de 1M da API do Claude e Consciência de Contexto
O Claude Sonnet 4.6, Sonnet 4.5 e Haiku 4.5 possuem a capacidade de Context Awareness (Consciência de Contexto). O modelo consegue rastrear em tempo real a capacidade restante da janela de contexto, gerenciando o orçamento de tokens de forma mais inteligente em conversas longas.
Como funciona:
No início da conversa, o Claude recebe informações sobre a capacidade total do contexto:
<budget:token_budget>1000000</budget:token_budget>
Após cada chamada de ferramenta, o modelo recebe uma atualização da capacidade restante:
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Isso significa que, em uma janela de contexto de 1M, o Claude é capaz de:
- Gerenciar o orçamento de tokens com precisão: Evita esgotar o contexto repentinamente no final da conversa.
- Distribuir o comprimento da saída de forma equilibrada: Ajusta o nível de detalhe das respostas com base na capacidade restante.
- Suportar sessões de agentes ultra-longas: Executa tarefas continuamente em fluxos de trabalho de agentes até a sua conclusão.
Estratégia de Gerenciamento da Janela de Contexto de 1M da API do Claude: Compaction
Quando o comprimento da conversa se aproxima do limite da janela de contexto de 1M, a API do Claude oferece a função Compaction (Compactação) para dar continuidade ao diálogo. A compactação é um mecanismo de resumo no lado do servidor que comprime automaticamente o conteúdo inicial da conversa em um resumo conciso, liberando espaço de contexto e permitindo conversas ultra-longas que superam o limite original da janela.
Atualmente, a função Compaction está disponível em versão Beta no Claude Opus 4.6. Para desenvolvedores que precisam executar tarefas de agentes por longos períodos em um contexto de 1M, a compactação é a estratégia preferida para gerenciar o contexto.
Além disso, a API do Claude oferece capacidades de Context Editing (Edição de Contexto), incluindo:
- Tool Result Clearing (Limpeza de Resultados de Ferramentas): Limpa resultados de chamadas de ferramentas antigas em fluxos de trabalho de agentes para liberar tokens.
- Thinking Block Clearing (Limpeza de Blocos de Pensamento): Limpa proativamente o conteúdo de pensamento de rodadas anteriores, otimizando ainda mais o uso do contexto.
Essas estratégias podem ser usadas em conjunto com a janela de contexto de 1M para obter o melhor equilíbrio entre desempenho e custo em cenários de contexto ultra-longo.
Observações Importantes sobre a Janela de Contexto de 1M da API do Claude
Ao utilizar a janela de contexto de 1M na prática, existem alguns detalhes técnicos que podem ser facilmente ignorados:
-
Novos modelos retornam erro de validação em vez de truncamento silencioso: A partir do Claude Sonnet 3.7, quando a soma dos tokens do comando (prompt) e da saída excede a janela de contexto, a API retorna um erro de validação em vez de truncar o conteúdo silenciosamente. Recomendamos usar a API de Contagem de Tokens para estimar a quantidade de tokens antes de enviar a requisição.
-
O consumo de tokens de imagens e PDFs não é fixo: O cálculo de tokens para conteúdo multimodal é diferente do texto puro; imagens do mesmo tamanho podem consumir quantidades de tokens muito distintas. Ao usar muitas imagens, reserve uma margem de tokens suficiente.
-
Limites de Tamanho de Requisição (Request Size Limits): Mesmo que a janela de contexto suporte 1M de tokens, a requisição HTTP em si possui limites de tamanho. Ao enviar textos extremamente grandes, é necessário estar atento às limitações da camada HTTP.
-
Limites de taxa (rate limits) cientes de cache: Ao usar o Prompt Caching, os tokens que resultam em acerto no cache (cache hit) não são contabilizados nos limites de taxa ITPM. Isso significa que, em cenários de contexto de 1M, o uso inteligente do cache pode aumentar significativamente o rendimento (throughput) real.
Perguntas Frequentes
Q1: Como confirmar se minha requisição foi cobrada pelo preço de contexto longo?
Verifique o objeto usage na resposta da API. Some os campos input_tokens, cache_creation_input_tokens e cache_read_input_tokens. Se a soma ultrapassar 200.000, a requisição inteira será cobrada pelo preço de contexto longo. Ao fazer chamadas através da plataforma APIYI (apiyi.com), o painel de estatísticas de uso indicará claramente a faixa de tarifação de cada requisição.
Q2: Quais tipos de arquivo a janela de contexto de 1M suporta?
A janela de contexto de 1M da API do Claude suporta formatos de texto como texto puro, código e Markdown, além de imagens e arquivos PDF. No entanto, note que o consumo de tokens para imagens e PDFs costuma ser alto e variável. Quando muitas imagens são usadas com textos longos, você pode atingir os limites de tamanho de requisição (Request Size Limits). Recomendamos realizar testes em pequena escala na plataforma APIYI (apiyi.com) para confirmar o consumo real de tokens antes do uso em larga escala.
Q3: Os tokens de Extended Thinking ocupam o contexto de 1M?
Os tokens de Extended Thinking da rodada atual são contabilizados na janela de contexto. No entanto, a API do Claude remove automaticamente os blocos de pensamento (thinking blocks) de rodadas anteriores, evitando que se acumulem nas conversas subsequentes. Isso significa que você pode usar o Extended Thinking com segurança no contexto de 1M sem se preocupar com o processo de pensamento consumindo muito espaço de contexto.
Q4: O que fazer se eu não atender aos requisitos do Tier 4?
Atualmente, a janela de contexto de 1M está aberta apenas para organizações no Tier 4 ou com limites de taxa personalizados. Para atingir o Tier 4, basta acumular uma recarga de $400, e o upgrade será automático após o pagamento. Se você ainda não puder atingir o Tier 4, considere: ① Controlar a entrada abaixo de 200K através de processamento segmentado; ② Usar soluções de Geração Aumentada por Recuperação (RAG) para extrair conteúdo essencial; ③ Entrar em contato com a equipe de vendas da Anthropic para consultar planos personalizados.
Q5: Como ativar no AWS Bedrock e Google Vertex AI?
A janela de contexto de 1M está disponível no AWS Bedrock, Google Vertex AI e Microsoft Foundry. A forma de ativação varia ligeiramente entre as plataformas — no Bedrock, é feita especificando os parâmetros correspondentes na requisição InvokeModel; no Vertex AI, através da configuração da API. Consulte a documentação oficial de cada plataforma para obter os detalhes de configuração específicos.
Checklist de Melhores Práticas para a Janela de Contexto de 1M da Claude API
Ao integrar a janela de contexto de 1M em projetos reais, sugerimos seguir estas melhores práticas:
Fase de Desenvolvimento
- Estime primeiro com a API de Contagem de Tokens: Antes de enviar a requisição real, use a API de Contagem de Tokens para estimar a quantidade de tokens de entrada e evitar surpresas com a precificação de contexto longo.
- Configure um
max_tokensadequado: O parâmetromax_tokensnão afeta o cálculo do limite de taxa (o OTPM é calculado com base na saída real). Você pode definir um valor alto para garantir que a resposta não seja cortada. - Teste em etapas: Valide a eficácia do seu modelo de comando (prompt) com conjuntos de dados menores antes de aumentar gradualmente a escala de entrada.
Ambiente de Produção
- Priorize o Prompt Caching: Para documentos longos reutilizados, o Prompt Caching pode reduzir o custo de entrada da parte em cache para apenas 10% do preço padrão. Além disso, os tokens que atingem o cache não contam para o limite de taxa ITPM.
- Use a Batch API para tarefas não em tempo real: A Batch API oferece um desconto adicional de 50% sobre o preço de contexto longo. Combinando ambos, o custo cai para cerca de 60% do preço padrão.
- Monitore o campo
usage: Verifique o objetousagena resposta de cada requisição e estabeleça mecanismos de alerta para monitoramento de custos. - Retentativa em caso de erro 429: Requisições de contexto longo possuem limites de taxa independentes. Ao encontrar um erro 429, verifique o cabeçalho
retry-afterpara realizar a retentativa de forma adequada.
Controle de Custos
- Controle o limite de 200K: Se a entrada estiver próxima de 200K, considere simplificar o comando para evitar o acionamento da precificação de 2x.
- Escolha o modelo certo: A série Sonnet é cerca de 40% mais barata que o Opus. Para tarefas rotineiras, dê prioridade ao Sonnet.
- Use o cache para reduzir a pressão dos limites de taxa: Com uma taxa de acerto de cache de 80%, o rendimento real (throughput) pode chegar a 5 vezes o limite nominal.
Resumo da Janela de Contexto de 1M da Claude API
A janela de contexto de 1M da Claude API permite que desenvolvedores processem cerca de 750 mil palavras de uma só vez, oferecendo capacidades poderosas para análise de bases de código, processamento de documentos extensos e diálogos complexos. Recapitulação dos pontos principais:
- Ative com uma linha de código: Basta adicionar o cabeçalho
anthropic-beta: context-1m-2025-08-07. - Suporte para 4 modelos: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5 e Sonnet 4.
- Preços transparentes: Acima de 200K tokens, a entrada custa 2x e a saída 1.5x; abaixo de 200K, o preço padrão permanece.
- Limites de taxa independentes: Requisições de contexto longo não afetam a cota de requisições padrão.
- Diversas formas de otimização: Prompt Caching, Batch API e Fast Mode podem ser combinados para reduzir custos.
Recomendamos utilizar a APIYI (apiyi.com) para experimentar rapidamente o poder da janela de contexto de 1M do Claude e encontrar a melhor solução para o seu cenário de negócio.
Referências
-
Documentação Oficial da Anthropic – Context Windows: Especificações técnicas sobre a janela de contexto da API do Claude
- Link:
platform.claude.com/docs/en/build-with-claude/context-windows
- Link:
-
Documentação Oficial da Anthropic – Pricing: Tabela de preços completa da API do Claude
- Link:
platform.claude.com/docs/en/about-claude/pricing
- Link:
-
Documentação Oficial da Anthropic – Rate Limits: Explicações sobre limites de taxa e níveis de uso (Usage Tiers)
- Link:
platform.claude.com/docs/en/api/rate-limits
- Link:
📝 Autor: APIYI Team | Para mais tutoriais sobre o uso de APIs de modelos de IA, visite a Central de Ajuda da APIYI em apiyi.com