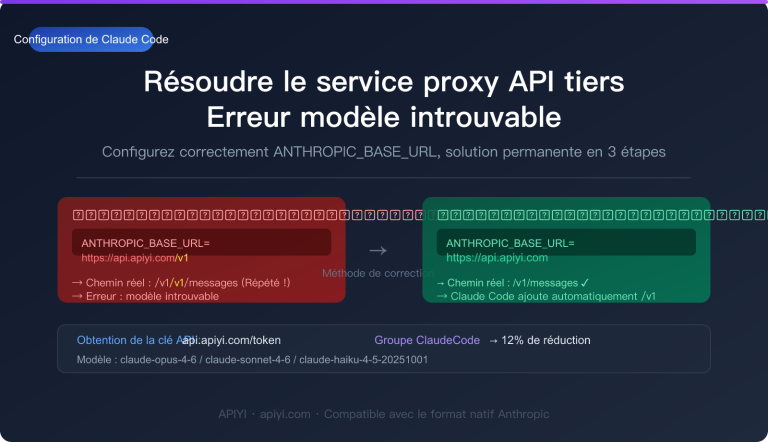
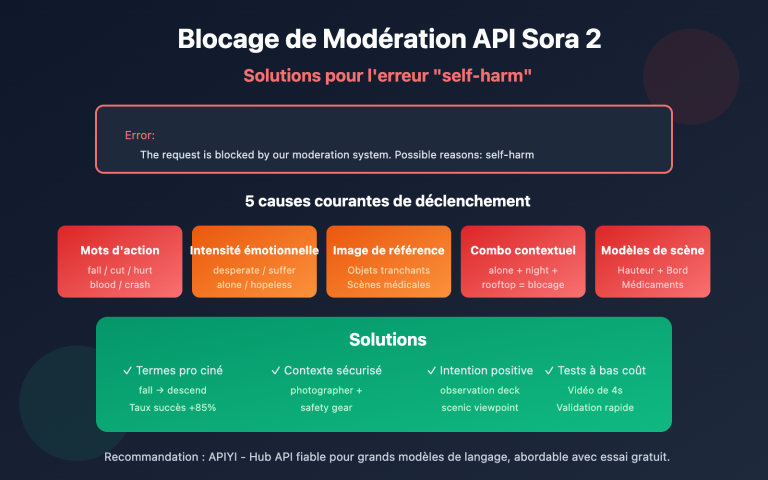
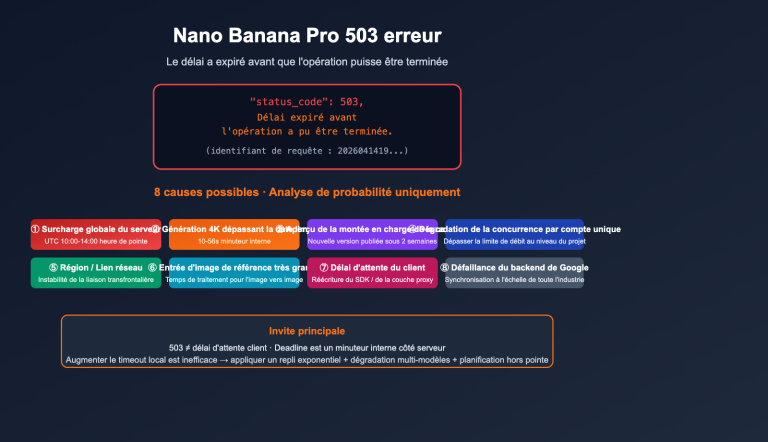
Comment utiliser un contexte ultra-long dépassant les 200 000 tokens dans vos appels API est un besoin de plus en plus concret pour les développeurs. Anthropic a lancé la fonctionnalité fenêtre de contexte de 1 million de tokens (1M Context Window) de l'API Claude, permettant de traiter environ 750 000 mots en une seule requête — l'équivalent de lire d'une traite l'intégralité du Rêve dans le pavillon rouge et de l'Histoire des Trois Royaumes.
Valeur ajoutée : En lisant cet article, vous maîtriserez la méthode complète pour activer la fenêtre de contexte 1M de l'API Claude, comprendrez les règles de calcul de la tarification et obtiendrez des modèles de code pour 5 scénarios réels.

Points clés de la fenêtre de contexte 1M de l'API Claude
Avant d'entrer dans les détails de la configuration, voici les informations essentielles sur cette fonctionnalité.
| Point clé | Description | Valeur |
|---|---|---|
| Fonctionnalité Bêta | Activée via l'en-tête context-1m-2025-08-07 |
Pas de demande nécessaire, ajoutez simplement l'en-tête |
| Modèles supportés | Opus 4.6, Sonnet 4.6, Sonnet 4.5, Sonnet 4 | Couvre les principales séries de modèles |
| Seuil d'utilisation | Nécessite le Tier 4 d'usage ou des limites de débit personnalisées | Atteignez le Tier 4 avec 400 $ de recharge cumulée |
| Règles de tarification | Bascule automatique vers le tarif long contexte après 200K tokens | Entrée 2x, Sortie 1,5x le prix standard |
| Support multi-plateforme | API Claude, AWS Bedrock, Google Vertex AI, Microsoft Foundry | Expérience unifiée sur toutes les plateformes |
Fonctionnement de la fenêtre de contexte 1M de l'API Claude
La fenêtre de contexte standard de l'API Claude est de 200K tokens. Une fois que vous avez activé la fenêtre de 1M via l'en-tête bêta, le modèle peut traiter jusqu'à 1 million de tokens en entrée dans une seule requête.
Il est important de noter que la fenêtre de contexte inclut tout le contenu :
- Tokens d'entrée : invite système, historique de conversation, message utilisateur actuel.
- Tokens de sortie : contenu de la réponse générée par le modèle.
- Tokens de réflexion : si l'Extended Thinking est activé, le processus de réflexion est également comptabilisé.
🎯 Conseil technique : La fenêtre de contexte 1M de l'API Claude est particulièrement adaptée à l'analyse de bases de code massives ou à la compréhension de documents longs. Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour valider rapidement vos solutions à long contexte, car elle prend en charge l'appel unifié de toute la gamme de modèles Claude.
Guide rapide pour la fenêtre de contexte de 1M de l'API Claude
Conditions préalables
Avant d'utiliser la fenêtre de contexte de 1M, assurez-vous de remplir les conditions suivantes :
| Condition | Exigence | Comment vérifier |
|---|---|---|
| Tier d'utilisation | Tier 4 ou limites de débit personnalisées | Console Claude → Settings → Limits |
| Recharge cumulée | ≥ 400 $ (seuil pour atteindre le Tier 4) | Consulter l'historique des recharges du compte |
| Sélection du modèle | Opus 4.6 / Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 | Les autres modèles ne supportent pas le contexte de 1M |
| Version de l'API | anthropic-version: 2023-06-01 |
À spécifier dans le header de la requête |
Exemple minimaliste
Il suffit d'ajouter une ligne de header beta à une requête API standard pour débloquer la fenêtre de contexte de 1M :
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Utilisation de l'interface unifiée APIYI
)
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{"role": "user", "content": "Veuillez analyser les arguments principaux du document long suivant..."}
],
betas=["context-1m-2025-08-07"],
)
print(response.content[0].text)
Appel équivalent avec cURL :
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [
{"role": "user", "content": "Analyser ce document long..."}
]
}'
Explications du code clé :
betas=["context-1m-2025-08-07"]: Syntaxe pour le SDK Python, qui ajoute automatiquement le headeranthropic-beta.anthropic-beta: context-1m-2025-08-07: Syntaxe du header pour les requêtes cURL / HTTP.- Lorsque les tokens d'entrée ne dépassent pas 200K, le tarif standard s'applique, même si le header beta est présent.
Voir le code TypeScript complet
import Anthropic from "@anthropic-ai/sdk";
import * as fs from "fs";
const anthropic = new Anthropic({
apiKey: "YOUR_API_KEY",
baseURL: "https://api.apiyi.com/v1" // Utilisation de l'interface unifiée APIYI
});
async function analyzeLongDocument(filePath: string) {
// Lecture du fichier volumineux
const document = fs.readFileSync(filePath, "utf-8");
const response = await anthropic.beta.messages.create({
model: "claude-opus-4-6",
max_tokens: 8192,
messages: [
{
role: "user",
content: `Veuillez effectuer une analyse complète du document suivant, incluant :
1. Résumé des arguments principaux
2. Extraction des données clés
3. Évaluation de la structure logique
4. Suggestions d'amélioration
Contenu du document :
${document}`
}
],
betas: ["context-1m-2025-08-07"]
});
console.log(response.content[0].text);
// Vérification de l'utilisation des tokens
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
}
analyzeLongDocument("./large-report.txt");
🚀 Démarrage rapide : Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester rapidement la fenêtre de contexte de 1M de Claude. Cette plateforme offre une interface compatible OpenAI, sans configuration complexe, et supporte toute la gamme des modèles Claude.

Détails de la tarification de la fenêtre de contexte de 1M de l'API Claude
La tarification du contexte étendu est l'une des préoccupations majeures des développeurs. L'API Claude utilise une stratégie de tarification par paliers : le fait que vos tokens d'entrée dépassent ou non les 200K détermine votre tranche tarifaire.
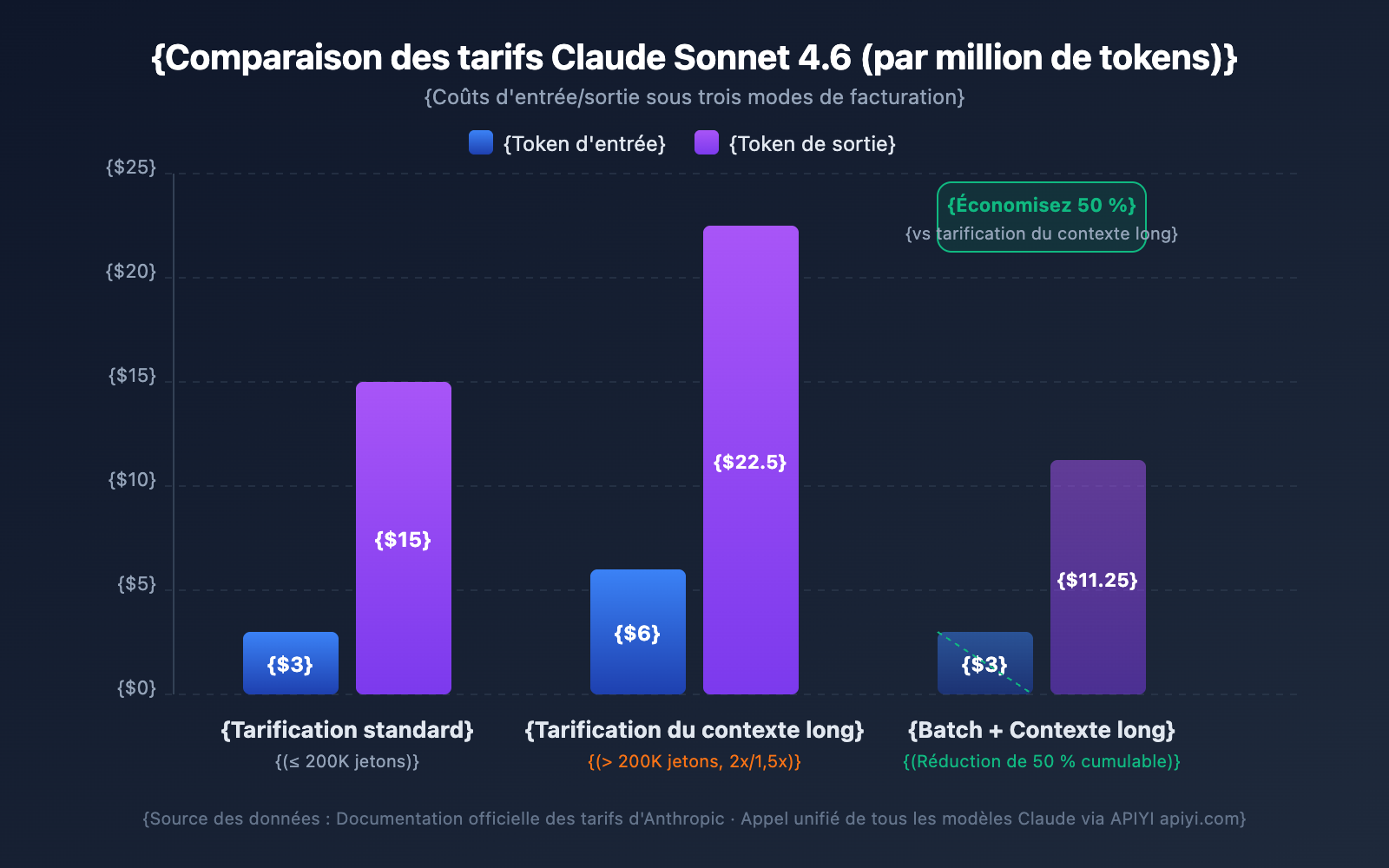
Comparaison des tarifs du contexte étendu par modèle
| Modèle | Entrée standard (≤200K) | Entrée contexte étendu (>200K) | Sortie standard | Sortie contexte étendu | Multiplicateur |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 5 $/MTok | 10 $/MTok | 25 $/MTok | 37,50 $/MTok | Entrée 2x / Sortie 1,5x |
| Claude Sonnet 4.6 | 3 $/MTok | 6 $/MTok | 15 $/MTok | 22,50 $/MTok | Entrée 2x / Sortie 1,5x |
| Claude Sonnet 4.5 | 3 $/MTok | 6 $/MTok | 15 $/MTok | 22,50 $/MTok | Entrée 2x / Sortie 1,5x |
| Claude Sonnet 4 | 3 $/MTok | 6 $/MTok | 15 $/MTok | 22,50 $/MTok | Entrée 2x / Sortie 1,5x |
MTok = Million de tokens
Règles de calcul de la tarification
Il est essentiel de comprendre quelques règles clés pour éviter que les coûts ne dépassent vos prévisions :
- Le seuil de 200K est un interrupteur : Dès que le total des tokens d'entrée dépasse 200K, tous les tokens de la requête sont facturés au prix du contexte étendu, et pas seulement la partie qui dépasse le seuil.
- Le total des tokens d'entrée inclut le cache : La somme de
input_tokens+cache_creation_input_tokens+cache_read_input_tokensdétermine le palier de tarification. - Les tokens de sortie n'influencent pas le palier : Le nombre de tokens de sortie ne déclenche pas la tarification du contexte étendu, mais une fois celle-ci activée, la sortie est également facturée 1,5 fois plus cher.
- En dessous de 200K, le tarif standard s'applique toujours : Même si vous avez activé le header beta, tant que l'entrée ne dépasse pas 200K, vous payez le tarif standard.
Exemple de calcul des coûts
Scénario : Utilisation de Claude Sonnet 4.6 pour analyser un document long de 500 000 tokens et générer un rapport d'analyse de 2 000 tokens.
Coût d'entrée : 500 000 tokens × 6 $/MTok = 3,00 $
Coût de sortie : 2 000 tokens × 22,50 $/MTok = 0,045 $
Total : 3,045 $
Pour la même sortie, si l'entrée n'était que de 150 000 tokens :
Coût d'entrée : 150 000 tokens × 3 $/MTok = 0,45 $
Coût de sortie : 2 000 tokens × 15 $/MTok = 0,03 $
Total : 0,48 $
4 stratégies pour réduire les coûts
| Stratégie | Économies | Cas d'utilisation |
|---|---|---|
| Prompt Caching | Le cache utilisé ne coûte que 10% | Réutilisation répétée du même document long |
| Batch API | 50% de réduction sur tous les coûts | Tâches de traitement par lots non temps réel |
| Fast Mode (Opus 4.6) | Pas de surcoût pour le contexte étendu | Scénarios nécessitant une réponse rapide |
| Contrôler l'entrée sous 200K | Éviter la tarification 2x | Documents pouvant être traités par segments |
💰 Optimisation des coûts : Pour les projets nécessitant des appels fréquents au contexte étendu de Claude, vous pouvez obtenir des plans de facturation flexibles via la plateforme APIYI (apiyi.com). En combinant le Prompt Caching et l'API Batch, le coût par appel peut être réduit de plus de 70%.
Limites de débit pour la fenêtre de contexte de 1M de l'API Claude
Une fois la fenêtre de 1M activée, les requêtes à contexte étendu (entrée > 200K tokens) ont des limites de débit indépendantes, calculées séparément des limites des requêtes standards.
Limites de débit pour le Tier 4
| Type de limite | Limite requêtes standards | Limite requêtes contexte étendu |
|---|---|---|
| Tokens d'entrée max / minute (ITPM) | Sonnet : 2 000 000 / Opus : 2 000 000 | 1 000 000 |
| Tokens de sortie max / minute (OTPM) | Sonnet : 400 000 / Opus : 400 000 | 200,000 |
| Requêtes max / minute (RPM) | 4 000 | Réduite proportionnellement |
Remarques importantes :
- Les limites de débit du contexte étendu sont calculées indépendamment des limites standards et ne s'influencent pas mutuellement.
- Lors de l'utilisation du Prompt Caching, les tokens qui frappent le cache ne sont pas comptabilisés dans la limite ITPM (pour la plupart des modèles).
- Si vous avez besoin de limites de débit plus élevées pour le contexte étendu, vous pouvez contacter l'équipe commerciale d'Anthropic pour demander des quotas personnalisés.
Comment passer au Tier 4
| Tier | Dépôt cumulé requis | Dépôt maximum unique | Limite de dépense mensuelle |
|---|---|---|---|
| Tier 1 | 5 $ | 100 $ | 100 $ |
| Tier 2 | 40 $ | 500 $ | 500 $ |
| Tier 3 | 200 $ | 1 000 $ | 1 000 $ |
| Tier 4 | 400 $ | 5 000 $ | 5 000 $ |
Le passage au niveau supérieur est automatique une fois le seuil de dépôt cumulé atteint, sans examen manuel requis.
5 scénarios réels pour la fenêtre de contexte de 1M de l'API Claude
Scénario 1 : Analyse de bases de code volumineuses
Envoyez l'intégralité du code de votre projet à Claude pour effectuer une revue d'architecture, un débogage ou obtenir des suggestions de refactorisation.
import anthropic
import os
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def collect_codebase(directory, extensions=(".py", ".ts", ".js")):
"""Collecte tous les fichiers sources du type spécifié dans le projet"""
code_content = []
for root, dirs, files in os.walk(directory):
# Ignorer les répertoires comme node_modules, .git, etc.
dirs[:] = [d for d in dirs if d not in ("node_modules", ".git", "__pycache__")]
for file in files:
if file.endswith(extensions):
filepath = os.path.join(root, file)
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
code_content.append(f"### {filepath}\n```\n{content}\n```")
return "\n\n".join(code_content)
codebase = collect_codebase("./my-project")
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=8192,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Veuillez effectuer une revue d'architecture complète de la base de code suivante :
{codebase}
Veuillez analyser :
1. Les points forts et les points faibles de la conception architecturale globale
2. Les failles de sécurité potentielles
3. Des suggestions d'optimisation des performances
4. Des points d'amélioration de la qualité du code"""
}]
)
Scénario 2 : Analyse synthétique de documents longs
Traitez des contrats juridiques, des recueils de thèses de recherche, des rapports financiers et d'autres documents ultra-longs.
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
messages=[{
"role": "user",
"content": f"""Voici une compilation des rapports financiers de l'entreprise pour les 12 derniers mois (environ 400 000 tokens) :
{financial_reports}
Veuillez réaliser :
1. Une analyse des tendances des indicateurs financiers clés par trimestre
2. Une déduction des changements de structure des revenus et de leurs causes
3. Une évaluation de l'efficacité du contrôle des coûts
4. Des prévisions de performance pour le prochain trimestre et des alertes sur les risques"""
}]
)
Scénario 3 : Combinaison de conversations longues multi-tours et de l'Extended Thinking
Activez l'Extended Thinking dans un contexte long pour permettre à Claude d'effectuer un raisonnement approfondi :
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
betas=["context-1m-2025-08-07"],
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[{
"role": "user",
"content": f"""Voici la documentation technique complète et le code source d'un système complexe :
{large_technical_document}
Veuillez analyser en profondeur la philosophie de conception de ce système et proposer un plan d'amélioration."""
}]
)
# Les tokens d'Extended Thinking ne s'accumulent pas dans les conversations suivantes
# L'API supprime automatiquement les blocs de réflexion des tours précédents
Scénario 4 : Utiliser le Prompt Caching pour réduire les coûts du contexte long
Lorsque vous devez analyser un même document long sous plusieurs angles différents, le Prompt Caching peut réduire considérablement les coûts :
# Première requête : mise en cache du document long
response1 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"} # Marqué comme pouvant être mis en cache
}],
messages=[{"role": "user", "content": "Résume les arguments clés de ce document"}]
)
# Deuxième requête : succès du cache, les tokens d'entrée ne coûtent que 10 % du prix
response2 = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["context-1m-2025-08-07"],
system=[{
"type": "text",
"text": large_document,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "Extrais tous les tableaux de données du document"}]
)
Scénario 5 : Traitement par lots de documents longs via l'API Batch
L'utilisation de l'API Batch permet de bénéficier d'une réduction supplémentaire de 50 % sur les tarifs déjà avantageux du contexte long :
# Création d'une requête par lots
batch = client.beta.messages.batches.create(
betas=["context-1m-2025-08-07"],
requests=[
{
"custom_id": "doc-analysis-1",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": f"Analyser le document 1 : {doc1}"}]
}
},
{
"custom_id": "doc-analysis-2",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Analyser le document 2 : {doc2}"}]
}
}
]
)
🎯 Conseil pratique : Pour vos projets réels, nous vous suggérons d'effectuer d'abord des tests à petite échelle via la plateforme APIYI (apiyi.com). Une fois que vous avez confirmé que la consommation de tokens et les coûts correspondent à vos attentes, vous pouvez passer à un déploiement massif. La plateforme propose un tableau de bord détaillé des statistiques d'utilisation pour un contrôle précis des coûts.
Conseils pour choisir le modèle Claude API avec fenêtre de contexte de 1M
Les 4 modèles prenant en charge le contexte de 1M ont chacun leurs points forts. Choisir le bon modèle permet de trouver le meilleur équilibre entre performance et coût.
Comparaison détaillée des modèles supportant le contexte de 1M
| Dimension de comparaison | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | Claude Sonnet 4 |
|---|---|---|---|---|
| Niveau d'intelligence | Le plus fort | Fort | Fort | Moyen-Haut |
| Prix d'entrée standard | 5 $/MTok | 3 $/MTok | 3 $/MTok | 3 $/MTok |
| Prix d'entrée contexte long | 10 $/MTok | 6 $/MTok | 6 $/MTok | 6 $/MTok |
| Fast Mode | Supporté (prix x6) | Non supporté | Non supporté | Non supporté |
| Conscience du contexte | Non supporté | Supporté | Supporté | Non supporté |
| Interleaved Thinking | Supporté | Supporté | Non supporté | Supporté |
| Scénarios recommandés | Raisonnement complexe, analyse de code | Traitement de documents longs général | Sessions d'agents multi-tours | Tâches d'analyse quotidiennes |
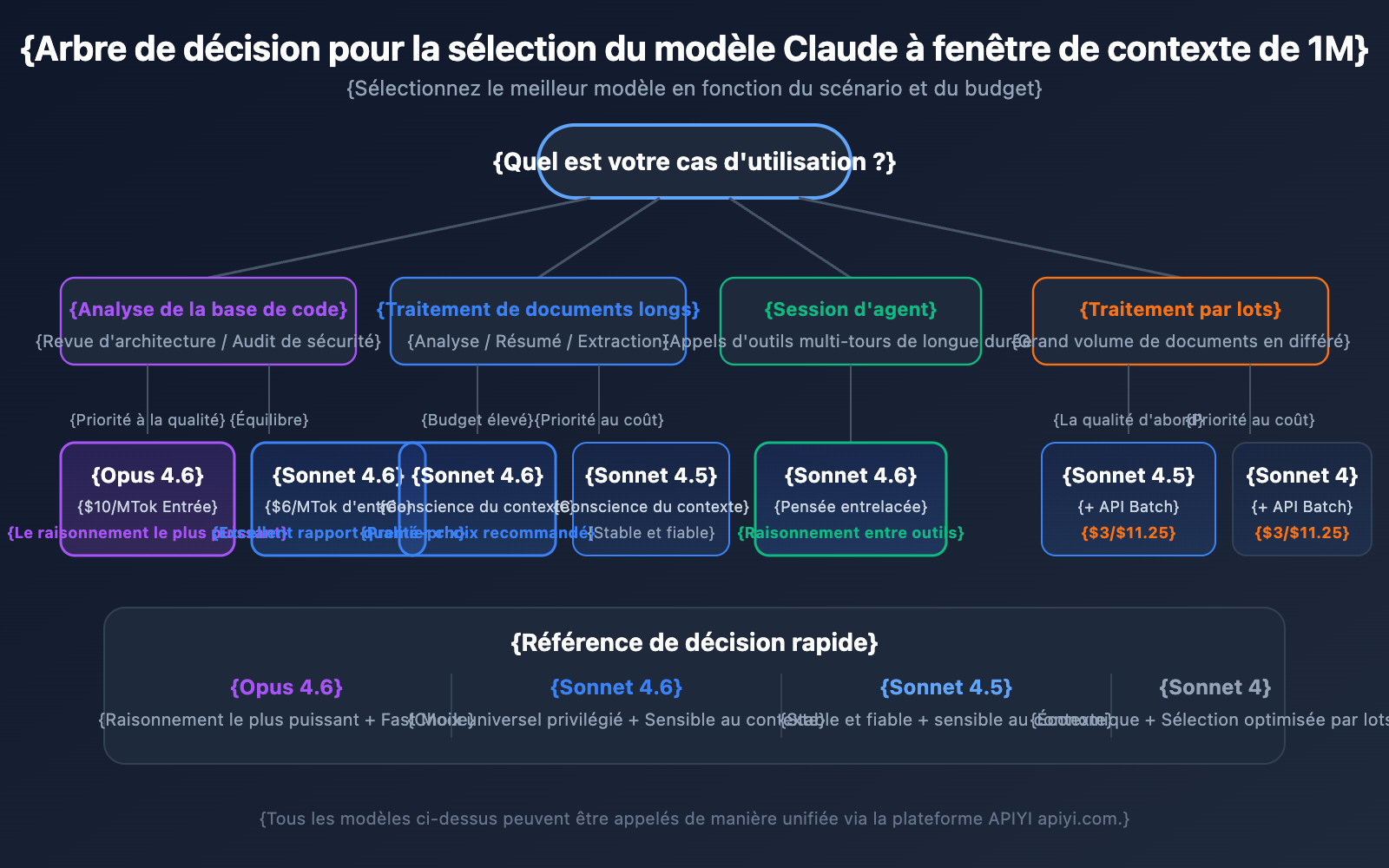
Choisir un modèle par scénario
Scénarios pour Claude Opus 4.6 :
- Tâches d'analyse complexes nécessitant la plus grande capacité de raisonnement.
- Revue d'architecture et audit de sécurité de bases de code volumineuses.
- Scénarios en temps réel nécessitant le Fast Mode (réponse rapide sans surcoût pour le contexte long).
- Applications d'entreprise où le budget est suffisant et la qualité est la priorité absolue.
Scénarios pour Claude Sonnet 4.6 :
- Analyse quotidienne de documents longs et extraction de résumés.
- Conversations longues nécessitant une conscience du contexte.
- Projets sensibles aux coûts mais exigeant une qualité élevée.
- Besoin d'Interleaved Thinking pour le raisonnement entre les appels d'outils.
Scénarios pour Claude Sonnet 4.5 / Sonnet 4 :
- Traitement de documents par lots (en combinaison avec l'API Batch pour réduire les coûts).
- Extraction d'informations structurées et organisation de données.
- Environnements de production stables ne nécessitant pas les dernières fonctionnalités des modèles les plus récents.
💡 Conseil de sélection : Le choix du modèle dépend principalement de votre scénario d'application spécifique et de votre budget. Nous vous recommandons d'effectuer des tests comparatifs réels via la plateforme APIYI (apiyi.com), qui prend en charge une interface unifiée pour tous les modèles mentionnés, facilitant ainsi le basculement et l'évaluation rapides.
Référence d'estimation des tokens pour la fenêtre de contexte de 1M de l'API Claude
Lors de la planification de l'utilisation d'un contexte long, il est crucial de comprendre la consommation de tokens selon le type de contenu :
| Type de contenu | Nombre approximatif de tokens | Capacité de la fenêtre 1M |
|---|---|---|
| Texte anglais | ~1 Token / 4 caractères | Env. 3 millions de caractères |
| Texte chinois | ~1 Token / 1,5 caractère | Env. 750 000 caractères |
| Code Python | ~1 Token / 3,5 caractères | Env. 2,5 millions de caractères |
| Page web standard (10 Ko) | ~2 500 Tokens | Env. 400 pages web |
| Document volumineux (100 Ko) | ~25 000 Tokens | Env. 40 documents |
| PDF de thèse de recherche (500 Ko) | ~125 000 Tokens | Env. 8 thèses |
Fenêtre de contexte de 1M et conscience du contexte de l'API Claude
Claude Sonnet 4.6, Sonnet 4.5 et Haiku 4.5 disposent de la capacité de Conscience du contexte (Context Awareness). Le modèle est capable de suivre en temps réel la capacité restante de la fenêtre de contexte, permettant une gestion plus intelligente du budget de jetons (tokens) lors de conversations prolongées.
Fonctionnement :
Au début de la conversation, Claude reçoit les informations sur la capacité totale du contexte :
<budget:token_budget>1000000</budget:token_budget>
Après chaque appel d'outil, le modèle reçoit une mise à jour de la capacité restante :
<system_warning>Token usage: 350000/1000000; 650000 remaining</system_warning>
Cela signifie que dans une fenêtre de contexte de 1M, Claude est capable de :
- Gérer précisément le budget de jetons : Évite l'épuisement soudain du contexte en fin de conversation.
- Allouer judicieusement la longueur de sortie : Ajuste le niveau de détail des réponses en fonction de la capacité restante.
- Prendre en charge des sessions d'agent ultra-longues : Exécute des tâches en continu dans un flux de travail d'agent jusqu'à leur achèvement.
Stratégie de gestion de la fenêtre de contexte 1M de l'API Claude : la Compaction
Lorsque la longueur de la conversation approche de la limite de la fenêtre de contexte de 1M, l'API Claude propose une fonctionnalité de Compaction pour poursuivre l'échange. La compaction est un mécanisme de résumé côté serveur qui compresse automatiquement le contenu initial de la conversation en un résumé succinct, libérant ainsi de l'espace pour supporter des dialogues dépassant les limites de la fenêtre.
Actuellement, la fonction de Compaction est disponible en version bêta sur Claude Opus 4.6. Pour les développeurs ayant besoin d'exécuter des tâches d'agent sur de longues durées dans un contexte de 1M, la compaction est la stratégie de gestion privilégiée.
De plus, l'API Claude offre des capacités d'Édition de contexte (Context Editing), notamment :
- Nettoyage des résultats d'outils (Tool Result Clearing) : Supprime les anciens résultats d'appels d'outils dans les flux d'agents pour libérer des jetons.
- Nettoyage des blocs de réflexion (Thinking Block Clearing) : Supprime activement les réflexions des tours précédents pour optimiser davantage l'utilisation du contexte.
Ces stratégies peuvent être combinées avec la fenêtre de contexte de 1M pour obtenir le meilleur équilibre entre performance et coût dans des scénarios à contexte ultra-long.
Points d'attention concernant la fenêtre de contexte 1M de l'API Claude
Lors de l'utilisation réelle de la fenêtre de contexte de 1M, certains détails techniques sont souvent négligés :
-
Les nouveaux modèles renvoient une erreur de validation au lieu d'une troncature silencieuse : À partir de Claude Sonnet 3.7, lorsque le total des jetons de l'invite et de la sortie dépasse la fenêtre de contexte, l'API renvoie une erreur de validation au lieu de tronquer discrètement le contenu. Il est recommandé d'utiliser l'API de comptage de jetons (Token Counting API) pour estimer le nombre de jetons avant d'envoyer la requête.
-
La consommation de jetons pour les images et les PDF n'est pas fixe : Le calcul des jetons pour le contenu multimodal diffère du texte pur. Des images de même taille peuvent consommer des quantités de jetons très différentes. Prévoyez une marge de jetons suffisante lors d'une utilisation massive d'images.
-
Limites de taille de requête (Request Size Limits) : Même si la fenêtre de contexte supporte 1M de jetons, la requête HTTP elle-même a des limites de taille. Lors de l'envoi de textes extrêmement volumineux, il faut prêter attention aux restrictions au niveau de la couche HTTP.
-
Limites de débit sensibles au cache : Lors de l'utilisation du Prompt Caching (mise en cache des invites), les jetons qui frappent le cache ne sont pas comptabilisés dans les limites de débit ITPM. Cela signifie que dans des scénarios de contexte de 1M, une utilisation judicieuse du cache peut augmenter considérablement le débit réel.
Questions Fréquentes
Q1 : Comment confirmer si ma requête est facturée au tarif « long contexte » ?
Vérifiez l'objet usage dans la réponse de l'API. Additionnez les trois champs input_tokens, cache_creation_input_tokens et cache_read_input_tokens. Si le total dépasse 200 000, l'intégralité de la requête est facturée au prix du long contexte. Lors d'un appel via la plateforme APIYI (apiyi.com), le panneau de statistiques de consommation indiquera clairement le palier de facturation de chaque requête.
Q2 : Quels types de fichiers sont supportés par la fenêtre de contexte de 1M ?
La fenêtre de contexte de 1M de l'API Claude supporte les formats texte brut, code, Markdown, ainsi que les images et les fichiers PDF. Notez toutefois que la consommation de jetons pour les images et les PDF est généralement élevée et variable. L'utilisation combinée de nombreuses images et de textes longs peut atteindre les limites de taille de requête (Request Size Limits). Il est conseillé d'effectuer des tests à petite échelle sur la plateforme APIYI (apiyi.com) pour confirmer la consommation réelle de jetons avant une utilisation massive.
Q3 : Est-ce que les jetons de la Réflexion Étendue (Extended Thinking) occupent le contexte de 1M ?
Les jetons de la Réflexion Étendue du tour actuel sont comptabilisés dans la fenêtre de contexte. Cependant, l'API Claude supprime automatiquement les blocs de réflexion (thinking blocks) des tours précédents, de sorte qu'ils ne s'accumulent pas dans la suite de la conversation. Cela signifie que vous pouvez utiliser la Réflexion Étendue en toute sécurité dans un contexte de 1M sans craindre que le processus de réflexion ne sature l'espace contextuel.
Q4 : Que faire si je ne remplis pas les conditions du Tier 4 ?
Actuellement, la fenêtre de contexte de 1M n'est ouverte qu'aux organisations de Tier 4 ou bénéficiant de limites de débit personnalisées. Pour atteindre le Tier 4, il suffit d'un cumul de recharge de 400 $, après quoi la mise à niveau est automatique. Si vous ne pouvez pas atteindre le Tier 4 pour le moment, vous pouvez envisager de : ① segmenter vos entrées pour rester sous les 200K ; ② utiliser une solution de RAG (Retrieval-Augmented Generation) pour extraire le contenu clé ; ③ contacter l'équipe commerciale d'Anthropic pour des solutions sur mesure.
Q5 : Comment l’activer sur AWS Bedrock et Google Vertex AI ?
La fenêtre de contexte de 1M est disponible sur AWS Bedrock, Google Vertex AI et Microsoft Foundry. Les modalités d'activation varient légèrement selon les plateformes : sur Bedrock, cela se fait en spécifiant les paramètres correspondants dans la requête InvokeModel, et sur Vertex AI via la configuration de l'API. Veuillez vous référer à la documentation officielle de chaque plateforme pour les détails de configuration.
Liste des meilleures pratiques pour la fenêtre de contexte de 1M de l'API Claude
Pour intégrer efficacement la fenêtre de contexte de 1M dans vos projets réels, il est recommandé de suivre ces meilleures pratiques :
Phase de développement
- Estimer d'abord avec l'API Token Counting : Avant d'envoyer des requêtes réelles, utilisez l'API Token Counting pour estimer le nombre de tokens en entrée. Cela permet d'éviter de déclencher accidentellement la tarification "long contexte".
- Définir un
max_tokensraisonnable : Le paramètremax_tokensn'influence pas le calcul des limites de débit (l'OTPM est calculé sur la sortie réelle). Vous pouvez donc définir une valeur élevée pour garantir que la réponse ne soit pas tronquée. - Tests incrémentaux : Validez d'abord l'efficacité de votre modèle d'invite avec de petits volumes de données, puis augmentez progressivement la taille de l'entrée.
Environnement de production
- Prioriser le Prompt Caching : Pour les documents longs réutilisés fréquemment, le Prompt Caching peut réduire les coûts d'entrée des parties en cache à 10 % du prix standard. De plus, les tokens en cache ne sont pas comptabilisés dans la limite de débit ITPM.
- Utiliser l'API Batch pour les tâches non temps réel : L'API Batch offre une réduction supplémentaire de 50 % sur le tarif long contexte. En cumulant les deux, le coût ne représente qu'environ 60 % du prix standard.
- Surveiller le champ
usage: Vérifiez l'objetusagedans la réponse après chaque requête et mettez en place un mécanisme d'alerte pour le suivi des coûts. - Gestion des erreurs 429 et tentatives : Les requêtes à long contexte ont des limites de débit indépendantes. En cas d'erreur 429, vérifiez l'en-tête
retry-afterpour effectuer des tentatives de manière raisonnable.
Contrôle des coûts
- Gérer le seuil des 200K : Si votre entrée approche les 200K, envisagez d'épurer votre invite pour éviter de déclencher la tarification x2.
- Choisir le modèle approprié : La série Sonnet est 40 % moins chère qu'Opus. Privilégiez Sonnet pour les tâches quotidiennes.
- Utiliser le cache pour réduire la pression sur les limites de débit : Avec un taux de réussite du cache de 80 %, le débit réel peut atteindre 5 fois la limite nominale.
Résumé de la fenêtre de contexte de 1M de l'API Claude
La fenêtre de contexte de 1M de l'API Claude permet aux développeurs de traiter environ 750 000 mots en une seule fois, offrant des capacités puissantes pour l'analyse de bases de code, le traitement de documents longs et les conversations complexes. Récapitulatif des points clés :
- Activation en une ligne : Il suffit d'ajouter l'en-tête
anthropic-beta: context-1m-2025-08-07. - 4 modèles compatibles : Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5 et Sonnet 4.
- Tarification transparente : Au-delà de 200K tokens, l'entrée est facturée 2x et la sortie 1,5x. En dessous de 200K, le prix standard s'applique.
- Limites de débit indépendantes : Les requêtes à long contexte n'affectent pas le quota des requêtes standards.
- Optimisations multiples : Le Prompt Caching, l'API Batch et le Fast Mode peuvent être cumulés pour réduire les coûts.
Nous vous recommandons de tester rapidement les capacités de la fenêtre de contexte de 1M de Claude via APIYI (apiyi.com) afin de trouver la solution la mieux adaptée à vos besoins métier.
Ressources
-
Documentation officielle d'Anthropic – Context Windows : Spécifications techniques de la fenêtre de contexte de l'API Claude
- Lien :
platform.claude.com/docs/en/build-with-claude/context-windows
- Lien :
-
Documentation officielle d'Anthropic – Pricing : Détails complets de la tarification de l'API Claude
- Lien :
platform.claude.com/docs/en/about-claude/pricing
- Lien :
-
Documentation officielle d'Anthropic – Rate Limits : Informations sur les limites de débit et les niveaux d'utilisation (Usage Tiers)
- Lien :
platform.claude.com/docs/en/api/rate-limits
- Lien :
📝 Auteur : APIYI Team | Pour plus de tutoriels sur l'utilisation des API de grands modèles de langage, visitez le centre d'aide d'APIYI sur apiyi.com